在之前的系统IO当中已经了解了“内存”级别的文件操作,了解了文件描述符、重定向、缓冲区等概念,在了解了这些的知识之后还封装出了我们自己的libc库。接下来在本篇当中将会将视角从内存转向磁盘,研究文件在内存当中是如何进行存储的,将从磁盘的硬件开始了解磁盘的基本结构,之后再引入文件系统的概念,详细了解当当用户要打开对应的文件时是如何进行路径解析从而得到文件的内容的,最后还要再了解软连接和硬链接这两个全新的概念。相信通过本篇的学习能让你理解文件是如何在磁盘当中存储的,又是如何被读取的,一起加油吧!!!

目录
1. 了解磁盘硬件结构
1.1 初识磁盘
1.2 磁盘内部结构
1.3 磁盘寻址方式
1.chs寻址
2. LBA寻址
2. LBA与CHS转换
CHS转成LBA
LBA转成CHS
2.引入文件系统
2.1 引入“块”概念
2.2 引入“分区”概念
3. 文件系统
3.1 文件系统管理方式
文件存储
目录存储
分区挂载
总结
4. 软硬链接
4.1 软链接
4.2 硬链接
1. 了解磁盘硬件结构
1.1 初识磁盘
通过之前的学习我们知道当磁盘当中的文件被打开之后会从磁盘当中加载到内存上,之后进行对应的IO操作,但是问题就来了当文件没有被打开的时候又是如何存储在磁盘当中的呢?
要解答以上的问题就需要先从硬件的角度了解磁盘硬件结构是样的。
一般的磁盘是如下所示的:

那么磁盘的内部结构又是怎么样的呢,来看以下的图示:
注:一定不要将你的磁盘打开,正常磁盘内部都是被封装为无尘的,当打开之后会使得磁盘的盘片在运转的时候和灰尘接触从而造成磁盘内部内容的丢失。


通过以上的图就可以看出以上磁盘的内部结构就可以以上的磁盘其实是一个机械设备,在现代的计算机当中机械硬盘是唯一的一个外部机械设备。
在此要注意的是以上的磁盘和现在正常笔记本当中的使用的基本都不是机械硬盘了,而是使用固态硬盘了。
这是因为相比原来的机械硬盘读取数据的速度更快,并且体积更小,那么是不是就说机械硬盘相比固态硬盘就没有任何的优势了呢?
事实上,机械硬盘在特定场景下仍有显著价值。固态硬盘虽快,但机械硬盘仍有其不可替代的优势,固态硬盘在读取速度方面确实是有很大的优势,但是对应的价格相比机械硬盘也要贵的多,同容量下固态硬盘价格是机械硬盘的3-5倍。因此在在一些领域机械硬盘还是在发挥着作用,例如服务器上,因为服务器需要存储大量的数据,那此时采用全固态存储方案成本过高,这时机械硬盘价格的优势就很明显了,Google数据中心采用机械硬盘存储冷数据,成本降低40%。



1.2 磁盘内部结构
接下来就来了解磁盘当中的结构是什么样的
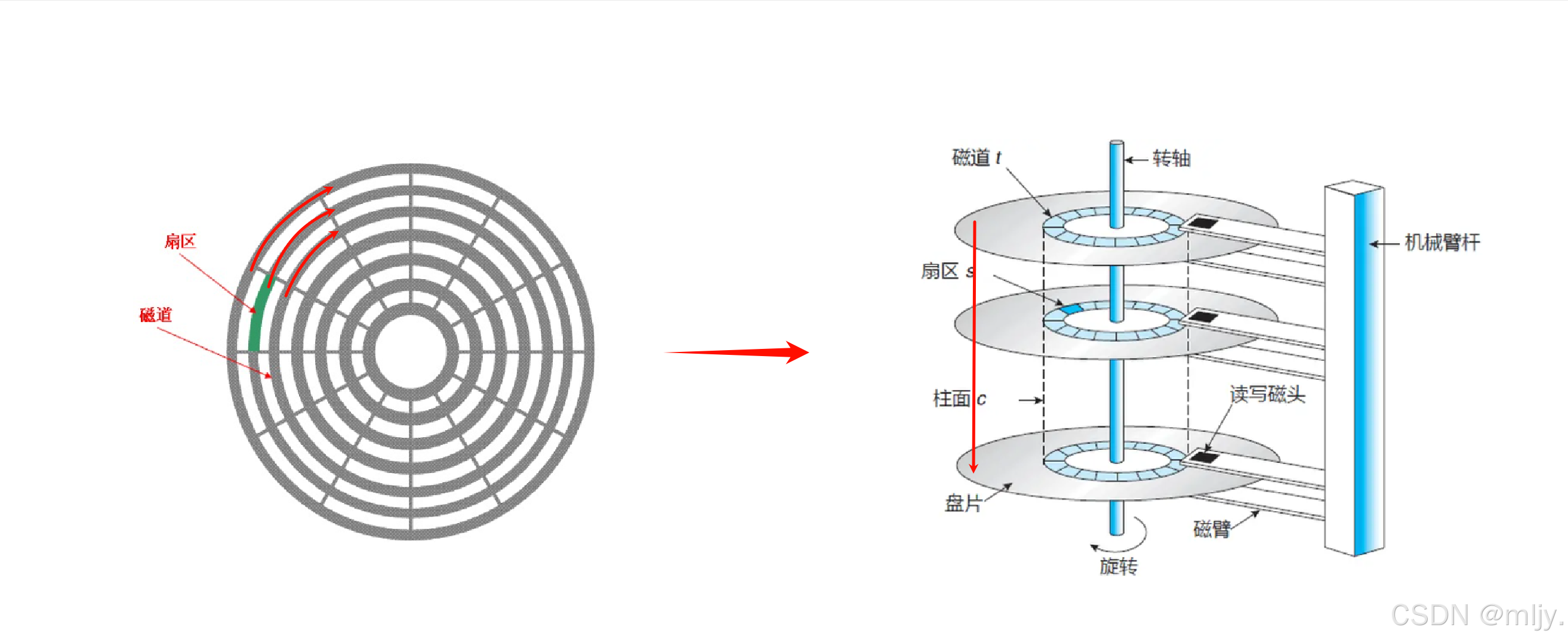
从磁盘的内部上看似乎只有一个盘片,但其实是磁盘是由多个盘片构成的
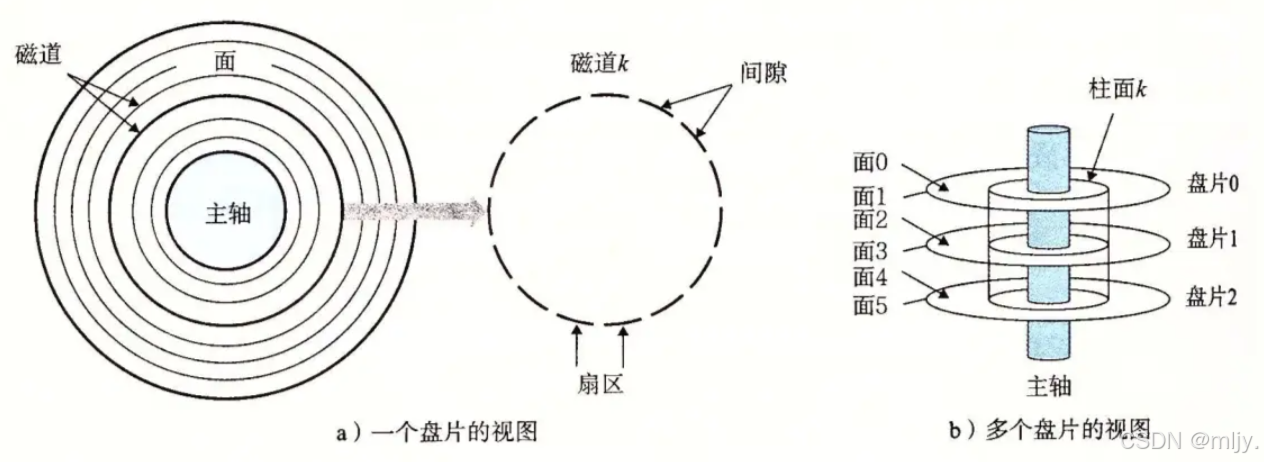
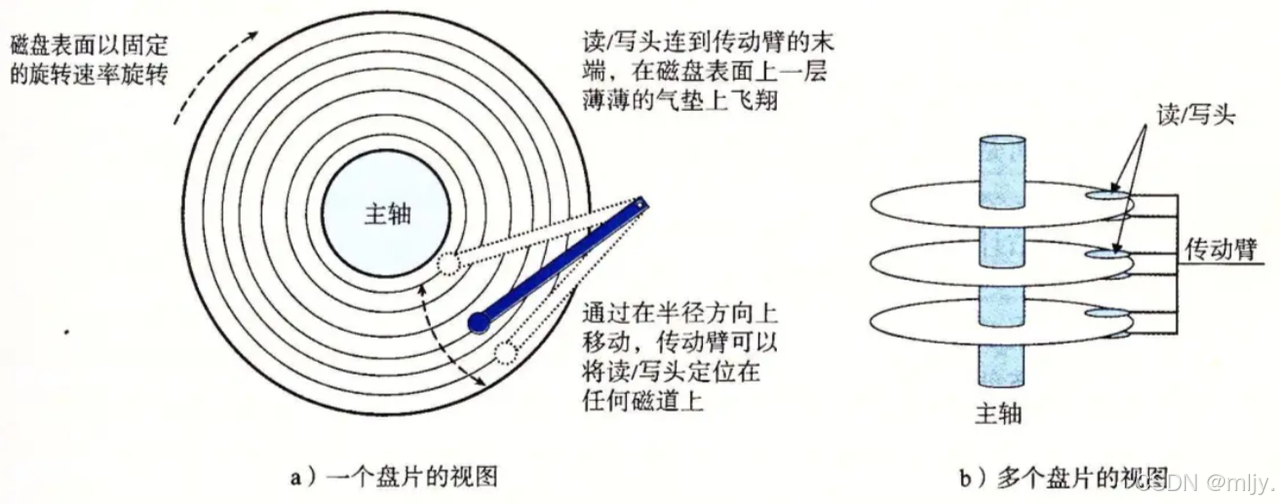
如以上的图所示,其实磁盘内是由多个盘片堆叠而成的,而且每一个盘片都有对应的磁针来实现读写,这些磁针又是在同一个磁头臂上的,因此磁盘当中的磁针是共进退的。
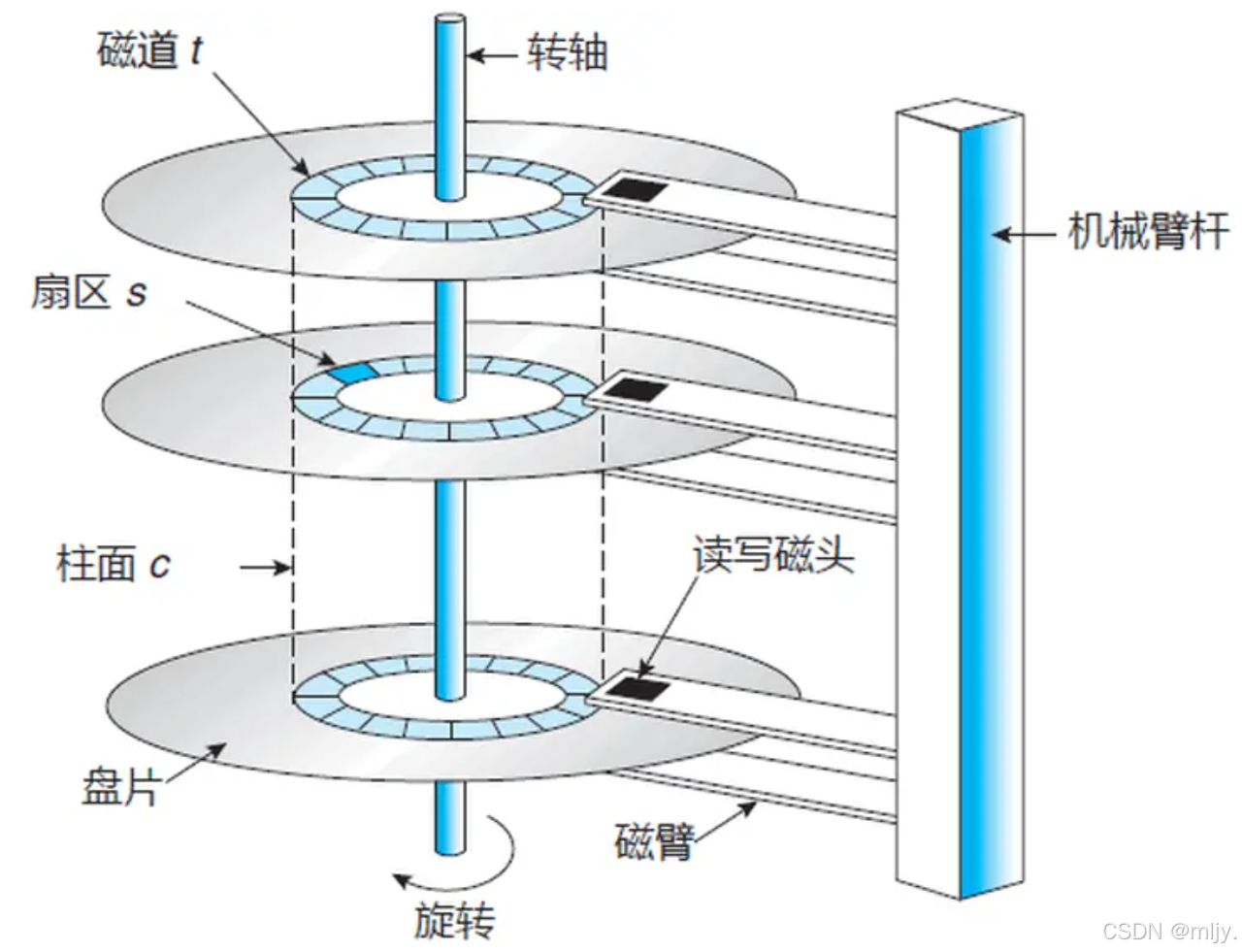
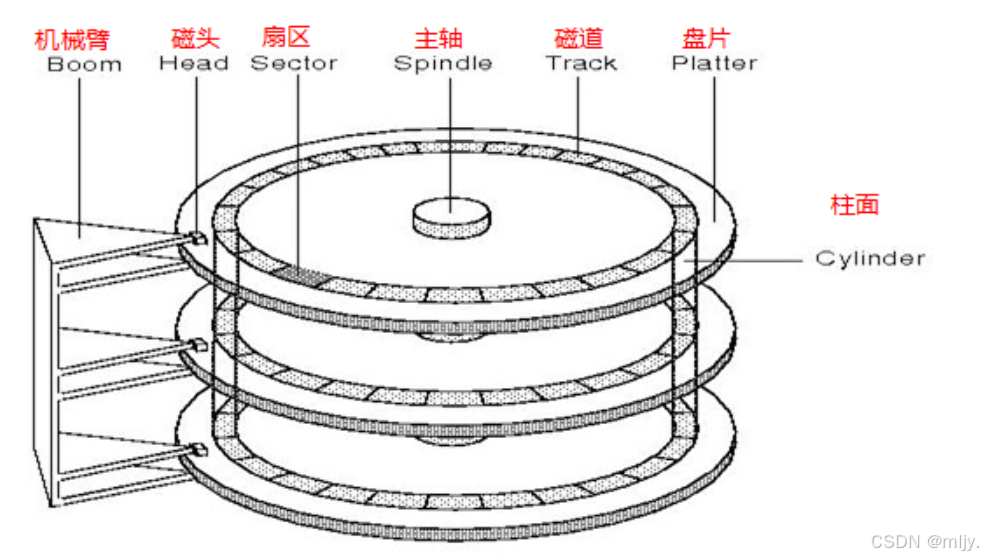
1.3 磁盘寻址方式
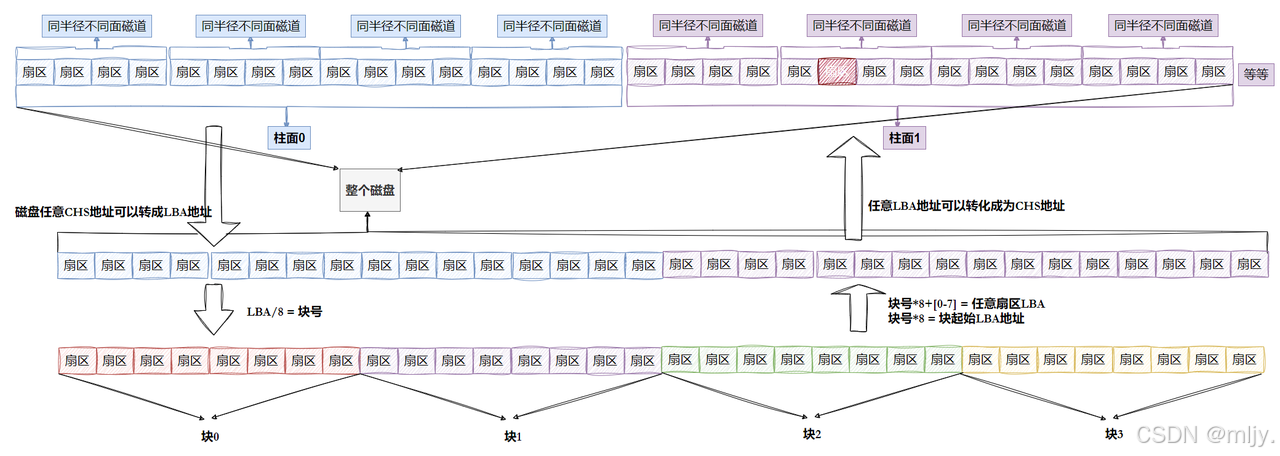
在磁盘当中每个盘片实际上都是有着许多的磁道的,在每个磁道当中继续进行划分将每512字节划分为1个扇区
在C磁盘当中扇区是进行存储的基本单位
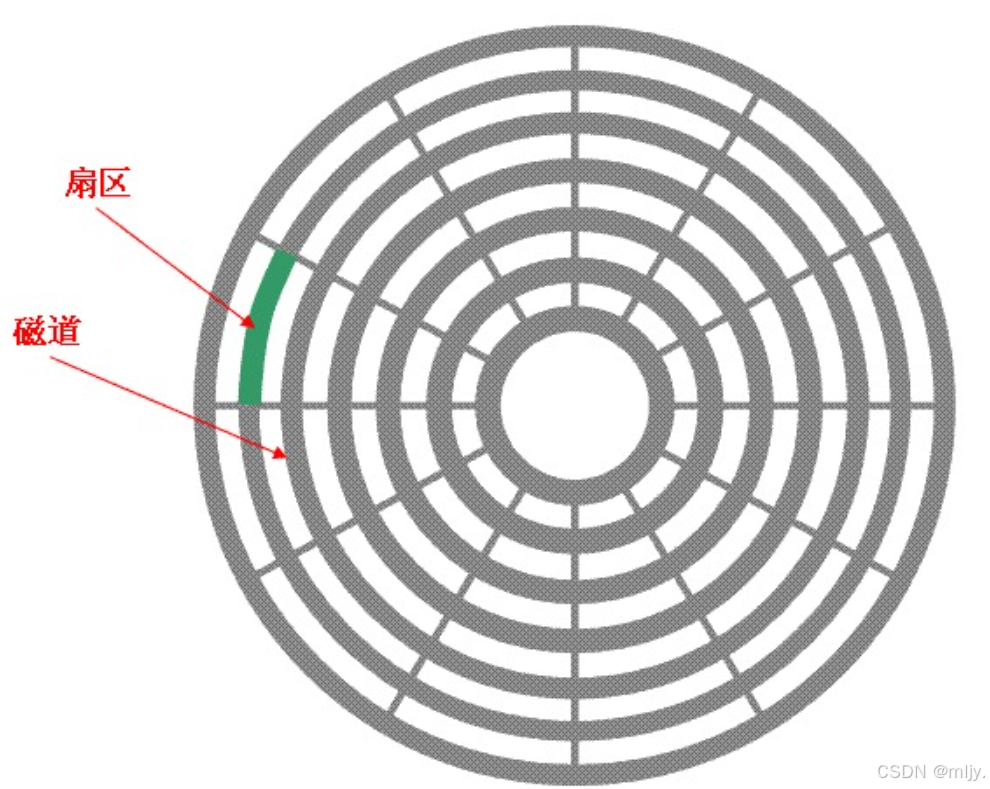
在磁盘当中还将不同盘片当中同一半径上的磁道称为柱面
1.chs寻址
以上初识了磁盘的内部结构,那么磁盘问题就来了,在磁盘内部要定位到对应的位置要通过什么方式来进行找到对应的扇区呢?
其实是可以通过以下的三步来实现
• 可以先定位磁头(header)
• 确定磁头要访问哪⼀个柱面(磁道)(cylinder)
• 定位⼀个扇区(sector)
以上三步当中就先进行的就是先找到对应的磁道,之后再定位要使用的磁针,最后定位扇区的位置,在此就以这三步当中对应英文单词的开头字母将该扇区寻址的方式命名为CHS。
再使用CHS方式进行定位时,最后磁针移动到了相应的磁道上之后要进行扇区的定位就需要转动磁盘,这时就可能会出现错过对应扇区的情况,那么这时就需要再将盘片进行旋转直到定位准确为止。在该过程当中就是区分机械硬盘性能的重要指标,在进行寻址过程中磁头定位准确性越高该磁盘的读写速度就越快,一般价格也越高,服务器上使用的磁盘相比桌面级的磁盘就要快的许多。
2. LBA寻址
实际上在计算机不是通过以上的CHS方式来定位对应的扇区的,这是因为这样的效率太低了,在计算机当中使用了一种更加高效的方式来进行扇区的定位,该方式就是LBA。
在了解LBA寻址的方式之前先要来了解在计算机当中是如何将磁盘这样多维的事物抽象为一维的。
我们知道在计算机当中本质上是只能存储一维的数据,例如之前学习到的二维数组本质上在计算机当中存储也是一维的,那么要将磁盘当中的一个个扇区也抽象为一维有什么方法呢?
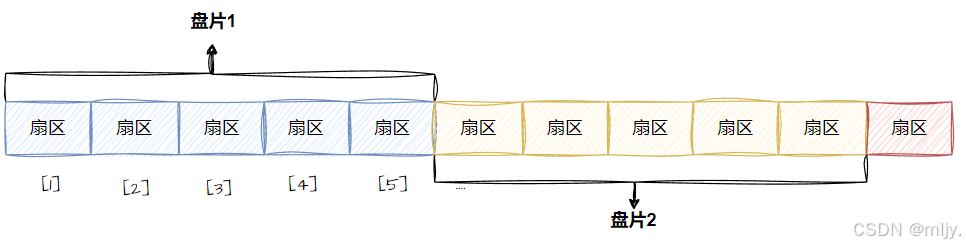
这时我们最容易想到的方式就是从磁盘当中的最上的盘片开始将盘片当中的扇区从外向内看作是一个连续的数组。
以上的方式确实能实现将磁盘进行抽象的操作,当时如果当要进行寻址的扇区的位置在磁盘当中的靠下时进行寻址就需要将磁盘搜索一遍,那么这样进行磁盘读写操作时的效率也太低了吧 。
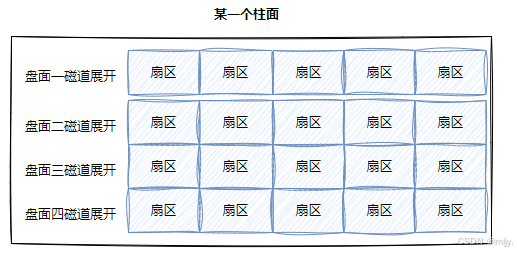
在此有另外一种方式相比以上的更好的就是可以先将磁盘看作是三维的,再将柱面看作是二维的,每个磁道就是一维的了
磁道展开看作是一维数组:

整个柱面就可以看作是一个二维数组:

整个磁盘就可以看作是一个三维数组:

通过之前的学习我们知道以上的三维数组本质是如下所示的一维数组

那么此时每个扇区都有一个对应的数组下标,这时就将该数组的下标叫做LBA(Logical Block Address)地址。
2. LBA与CHS转换
以上我们就了解了LBA和CHS的两种寻址的方式,在操作系统当中只需要有对应的扇区的LBA值即可,但是毕竟LBA对应的值是抽象出来的,最终在磁盘当中寻找扇区的时候还是要得到对应C,H,S的值,实际上将LBA转化为CHS的工作是由磁盘自己来实现的,将CHS转化为LBA也是。
那么接下来就来思考是如何进行LBA和CHS之间的转换的呢?
接下来就来讲解
CHS转成LBA
• 磁头数*每磁道扇区数 = 单个柱面的扇区总数
• LBA = 柱面号C*单个柱面的扇区总数 + 磁头号H*每磁道扇区数 + 扇区号S - 1
• 即:LBA = 柱面号C*(磁头数*每磁道扇区数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
注:扇区号通常是从1开始的,而在LBA中,地址是从0开始的, 柱面和磁道都是从0开始编号的
总柱面,磁道个数,扇区总数等信息,在磁盘内部会自动维护,上层开机的时候,会获取到这些参数。
LBA转成CHS
• 柱面号C = LBA // (磁头数*每磁道扇区数)【就是单个柱面的扇区总数】
• 磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
• 扇区号S = (LBA % 每磁道扇区数) + 1
注:"//": 表示除取整
所以:从此往后,在磁盘使用者看来,根本就不关心CHS地址,而是直接使用LBA地址,磁盘内部自己转换。从现在开始,磁盘就是⼀个 元素为扇区 的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS使用磁盘,就可以用个数字访问磁盘扇区了。
2.引入文件系统
以上了解了磁盘的物理结构是什么样的,那么接下来就在详细了解文件系统之前先来了解一些基本的概念
2.1 引入“块”概念
磁盘当中及基本单位是扇区,但实际上OS在访问文件系统时如果是一个一个扇区的加载这样IO的效率是很低的,因此操作系统当中OS文件系统访问磁盘是以“块”为单位。
那么在此提到的块具体的大小是多少呢?
在此是将磁盘当中连续8个扇区为一个磁盘块,由于扇区的大小是512字节,那么磁盘块的大小就是512字节*8=4kb。
有了LBA的值之后将LBA/8=块号,将块号*8+[0~7]=对应LBA值
2.2 引入“分区”概念
我们知道在计算机当中磁盘的大小一般都是很大的,例如在我们的Windows电脑当中,磁盘的大小一般都是512GB或者1TB,那么这时一般就会对一整块的磁盘进行分盘,划分出C、D、F……

在Windows当中进行分盘的上就是对磁盘进行分区,本质上就是对磁盘进行格式化。但是在LInux当中设备都是以文件的,那么这时在Linux当中又是如何进行分区的呢?
实际上在Linux当中就可以按照每个柱面来进行分区,本质上就是设置每个分区的起始柱面和结束柱面号。

将磁盘当中的进行分区之后就就可以使得原本要直接管理一块非常大的空间转为对一块块分区的管理,这样效率就高多了。

3. 文件系统
以上已经了解了文件系统当中一些基本的概念,那么接下来就可以开始详细的了解文件系统的相关知识了。在此我们以下了解的其实是Linux当中的ext2文件系统,该系统是Linux早期广泛使用的非日志文件系统。其实除了ext2在Linux当中还存在ext3和ext4文件系统,但ext3和ext4本质上是对基于ext2的增强版,其核心的设计是没有改变的,因此我们只需要了解ext2即可。
3.1 文件系统管理方式
在以上我们已经了解了在Linux当中磁盘当中是会进行分区的,但其实在进行分区之后的磁盘空间还是较大从而不利于管理,那么这时又会对每分区进行分组
文件存储
以下的图示就描述了进磁盘当中的空间进行分区之后再进行分组的形式
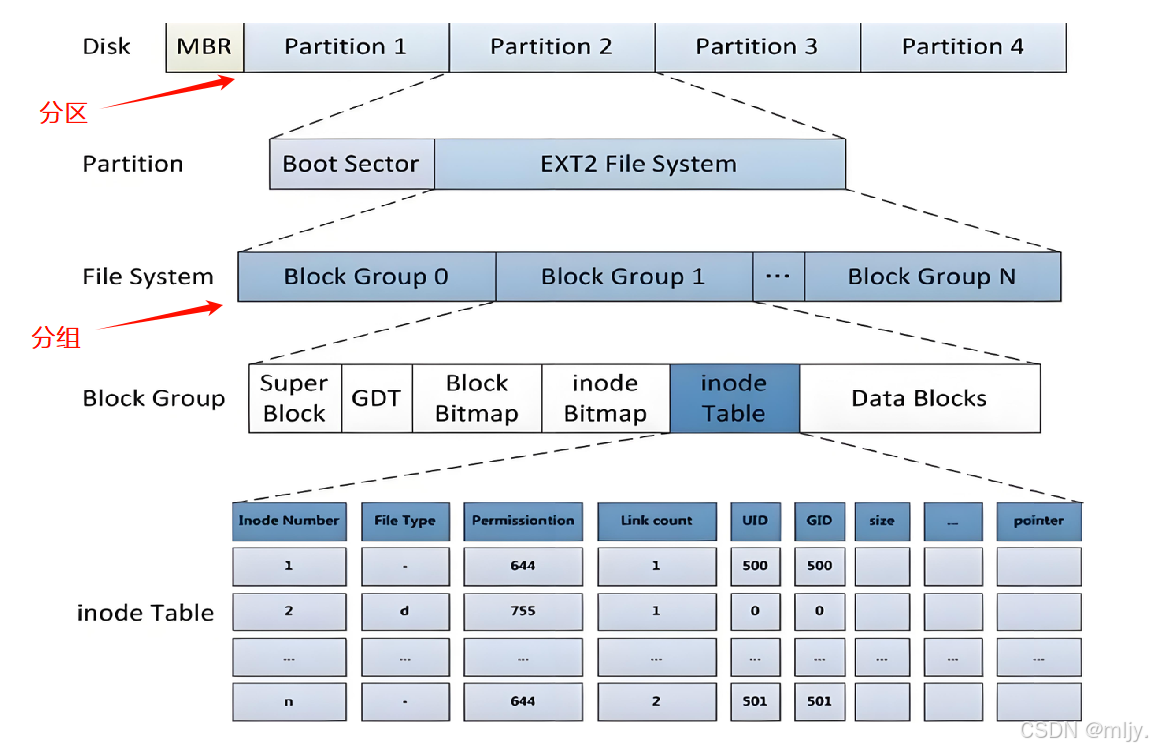
那么此时问题就来了在每个的组当中以上的图示当中显示出许多的属性,那么这些属性分别表示的是什么呢?
以下就来依次的讲解。
首先是在磁盘当中可以划分为一个个的Partition分区,而在这些的分区的开头会有MBR,其实这个给叫做主引导目录,是存储在磁盘当中的第一个扇区,在MRB当中存储着磁盘分区的的相应信息;主要作用就是进行分区的管理。
接下来在进入到分区当中在每个分区的开头都会有一个Boot Sector,这个叫做启动块,其作用是用来存储磁盘分区信息和启动的信息,注意如何文件都不能修改启动块。启动块的大小一般是1KB。在分区当中在启动块之后就是一个个Block Group分组。
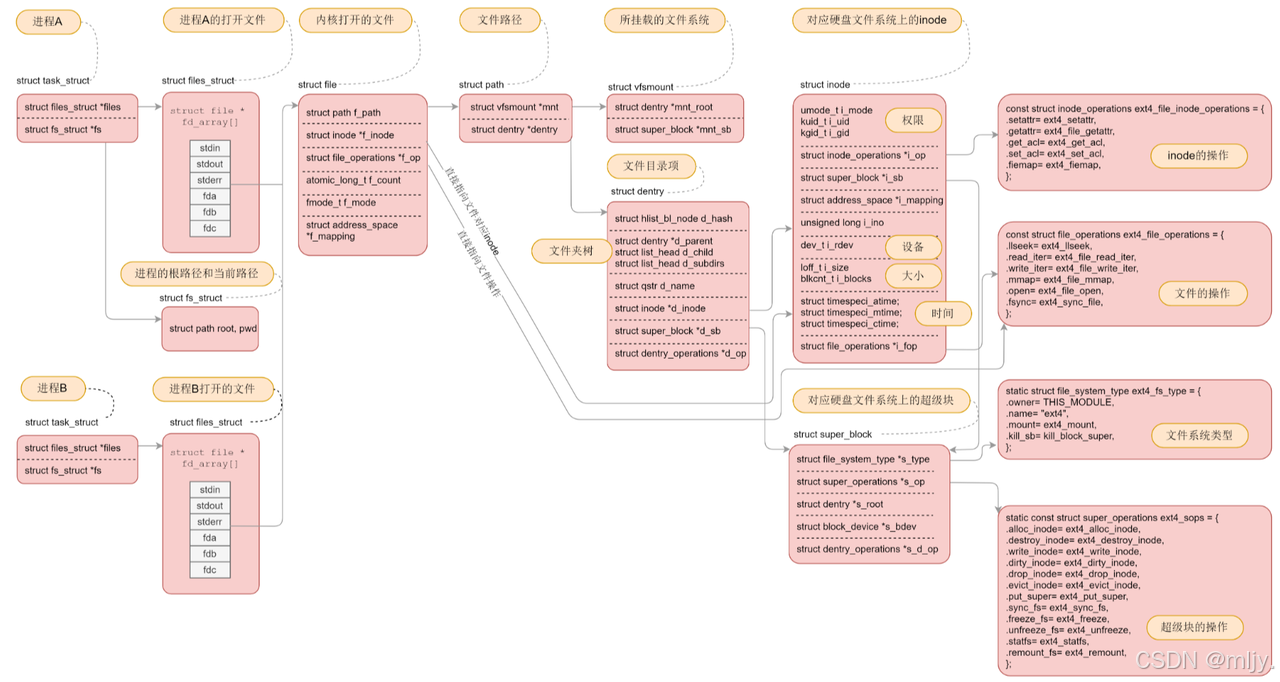
接下来在进行到每个分组当中会分为以上所示的六大的属性区。我们知道文件是由文件的内容加文件的属性构成的,在着六大的属性区当中inode Table就是用来存储文件的属性,但在详细的了解该区域内存储的是什么之前先要了解到的是实际上在磁盘当中是没有存储对应的文件名的而是使用inode来标识不同的文件的
接下来先来看以下的代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char *argv[])
{ if (argc != 2) { fprintf(stderr, "Usage: %s <directory>\n", argv[0]); exit(EXIT_FAILURE); } DIR *dir = opendir(argv[1]); if (!dir) { perror("opendir"); exit(EXIT_FAILURE); } struct dirent *entry; while ((entry = readdir(dir)) != NULL) {
// Skip the "." and ".." directory entries if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..")== 0) { continue; } printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino); } closedir(dir);
return 0;
}
以上使用了opendir系统调用来打开用户给定命令行参数当中的目录,使用该系统调用之后就会返回一个DIR*类型的目录流指针。
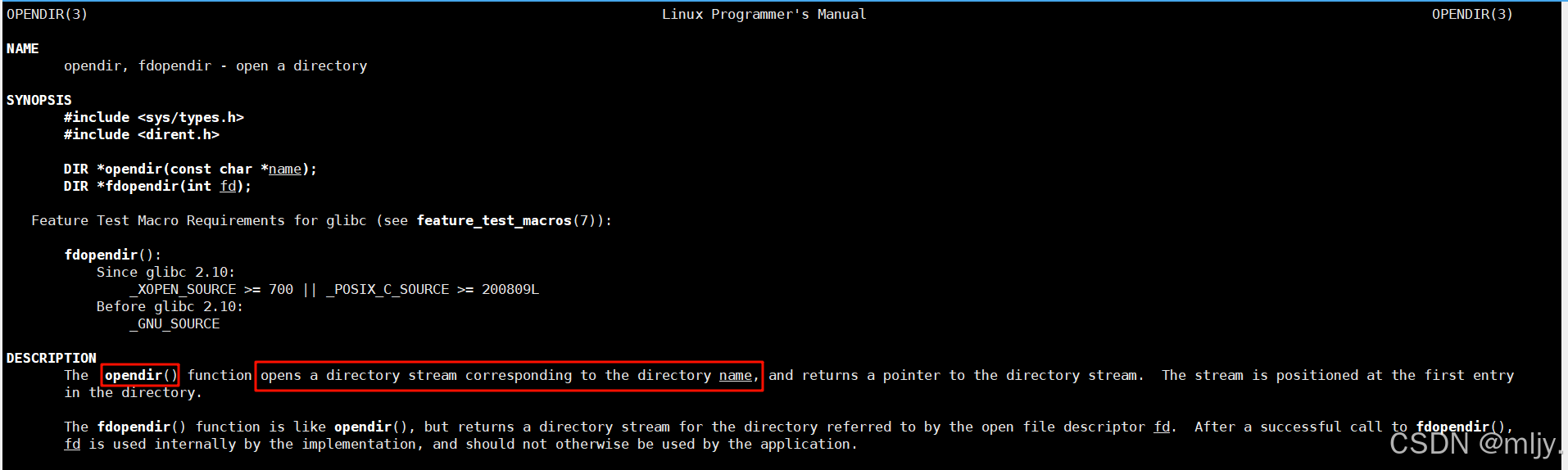
之后循环的调用readdir来读取指定的目录,跳过.和..,打印目录内对应的文件名和inode编号
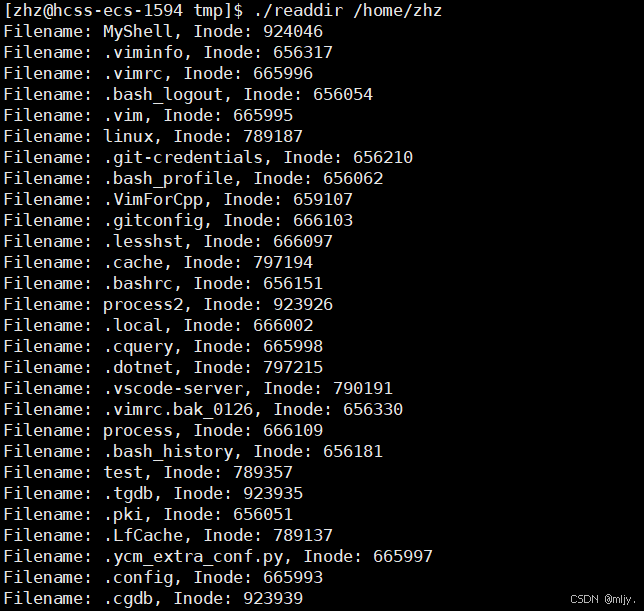
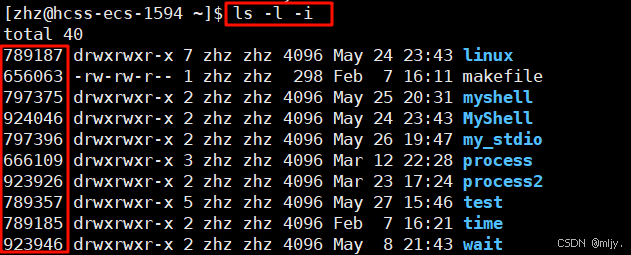
在Linux当中使用ls指令的时候带带上-i选项就可以看到对应文件的inode信息
在了解了以上的的性质之后接下来接着来了解每个分组当中的各个属性区分别存储着什么样的信息。
在Linux当中其实是会将同一个文件的内容和属性分开存储的,在分组当中就是将文件属性存储在inodeTable当中将文件的内容存储在Date Block当中。在inode Table当中会存储着各个文件的属性,在该属性区当中对应描述每个文件属性的结构体大小固定是128字节,由于磁盘进行管理的基本单位是4KB,那么一个inode table当中就会有4KB/128字节=32个inode的信息,对应上图所示的文件属性就是每一行
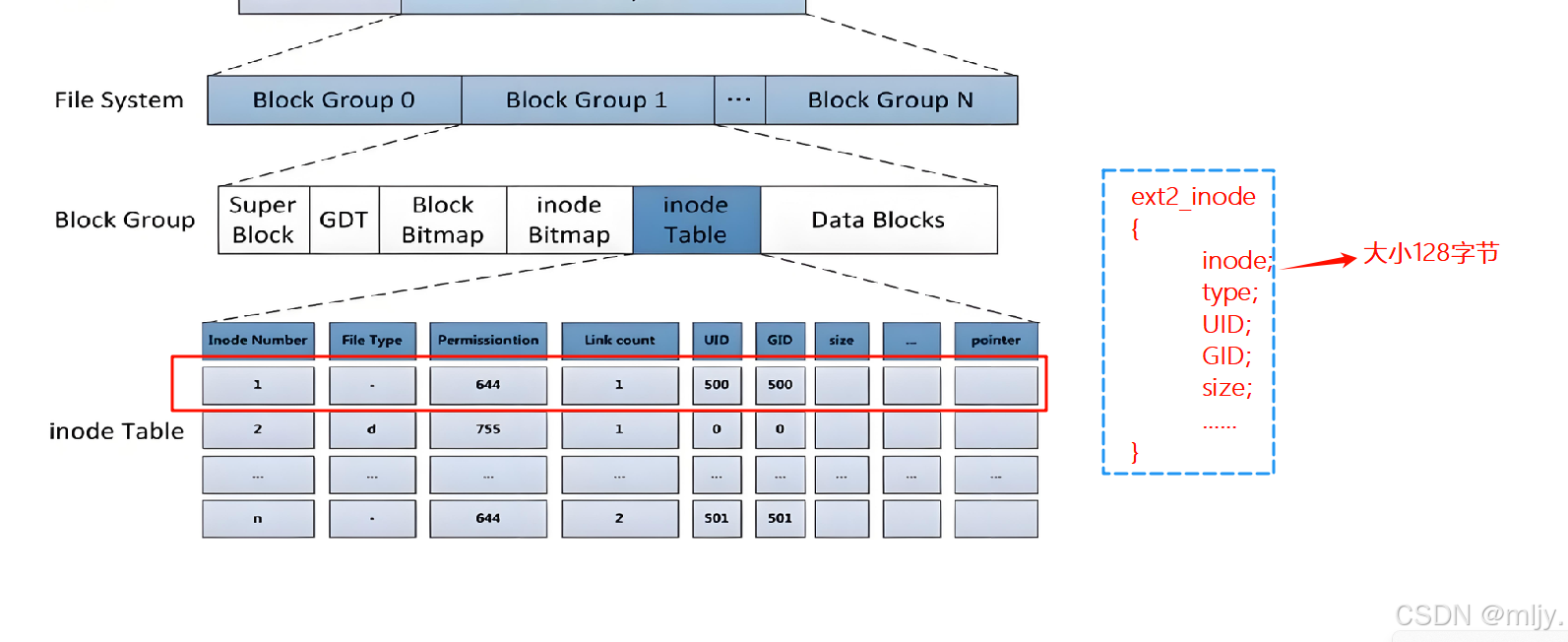
在inode table当中存储文件的属性,在 date block当中就存储文件的内容。
以上有存储文件的属性和内容的分区之后,那么在使用的时候怎么知道哪一块分区此时能使用呢?
在此在每个分组当中就提供了block bitmap和inode block来实现查看对应的数据块是否被使用,实际上这两块区域的本质就是位图,当对应的inode table当中文件inode被使用时就会将inode bitmap的位置置为1,未使用时为0;当block bitmap当中对应的数据区域被使用时就会将block对应的位置置为1,未使用为0。通过以上的两个位图就可以在不遍历数据的情况下实现线性时间的查找。
其实有了以上的知识也可以解释为什么当我们在电脑中从U盘移动文件到硬盘当中是需要一定的时间的,但是在删除硬盘当中的文件时瞬间就结束了;其实在进行删除的操作时是没有真正的将硬盘当中的数据删除而只是将对应指向数据区位图的从1置为0,那么在之后存储新的数据时这块硬盘的空间就是可以使用的,新进行存储的数据就会将用来的数据进行覆盖。这也是为什么当我们将一些文件误删之后只要不进行其他的操作还是有可能将文件恢复的,实际上这时用来的文件还是存储在磁盘当中,只不过是对应的位图区域被置为0。
以上就会发现一个奇怪的点,那就是文件名是没有存储在文件的属性当中的,但是在之前进行任何的操作时我都是使用文件名来进行的啊,没有使用什么inode来访问啊,那么inode和文件名是如何建立联系的呢?
这个问题要接下来等到目录的存储时能解释的清楚。
接下来先来继续了解分组当中的其他区域的作用是什么,首先在GDT是块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储⼀个块组 的描述信息,如在这个块组中从哪⾥开始是inode Table,从哪⾥开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有⼀份拷⻉。
而Super则称为超级块,存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:bolck 和 inode的总量,未使⽤的block和inode的数量,⼀个block和inode的大小,最近⼀次挂载的时间,最近⼀次写⼊数据的时间,最近⼀次检验磁盘的时间等其他⽂件系统的相关信息。Super Block的信息被破坏,可以说整个⽂件系统结构就被破坏了。
以上在每个分组当中都存储着所在的分区当中的结构信息,这样就可以使得即使一个组当中的Super Block损坏了也可以从其他的组当中获取。
以上就了解了分组当中各个区域存储着哪些信息,在此还需要了解到的时实际上在磁盘当中,inode和数据块是可以跨组编号的,但是是不能跨分区编号的,这就是说明在同一个分区当中inode的编号和块号都是唯一的。
那么当得到对应的inode编号之后是如何找到对应的数据块呢?
实际上在inode结构体当中是会有对应数据块的数组,这时得到对应的inode编号之后就可以直接通过该结构体内的数组来得到对应的那数据块。
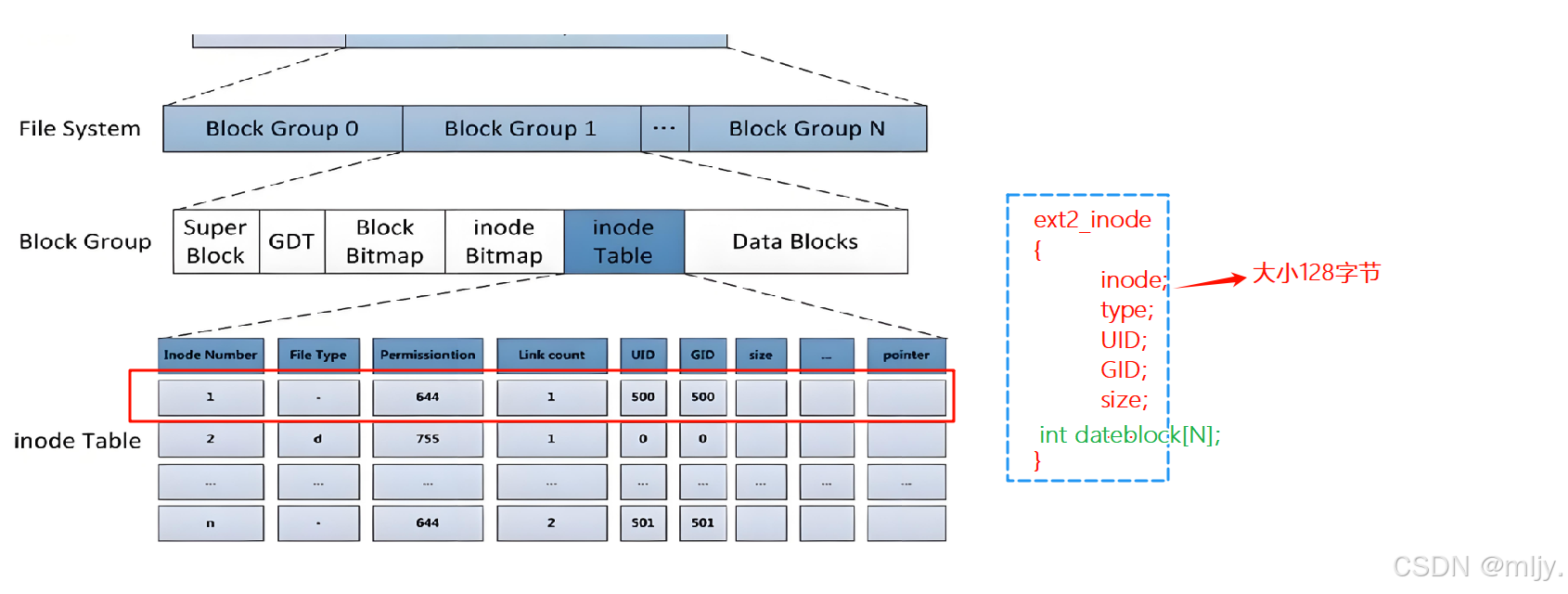
以上一个分组当中的数据块实际上可能会出现空间大小不足以存储所有文件的数据,那么这时就可以使得在inode当中有一部分的空间是由其他的分组提供的。

还有一个问题就是当得到对应文件的inode编号,接下来是如何定位到文件在磁盘当中的分组的呢?
因为在同一个分区当中inode编号是唯一的,而且每个分组的大小又是固定的,那么这时就可以通过相应的除和模运算来得到inode对应的分组。
目录存储
以上了解了文件是如何在磁盘当中存储的,那么这时就要思考目录又是如何存储在磁盘当中的呢?
实际上在磁盘当中是没有目录这一概念的,因为在磁盘当中目录也是像普通文件一样按照以上的方式进行存储,之后不过和之前普通文件有所不同的是在目录当中的文件内容是该目录当中文件和对应inode的映射关系。
那么在此也就可以解释了为什么在文件的inode当中没有存储文件名,这其实在文件所在的目录当中就已经完成了文件名和inode的映射,这样在磁盘当中就可以拿到对应的inode来实现读写的操作。
那么这时就可以解释为什么在访问任何的文件时都要有路径,因为只有通过文件所在目录的内容当中获取该文件的inode才能从磁盘当中找到该文件的存储位置。但是当前文件所在的目录不是在磁盘当中本质还是文件吗,那么这时就需要在通过该目录的上一级目录来得到该目录的inode,上级目录也是目录就需要做以上的操作,那么这时就需要一直重复以上的操作直到根目录为止。这时我们就可以得出要访问任何的文件都需要从根目录开始依次的打开每一个文件,再根据目录名来依次的访问每个目录下指定的目录,直到访问到对应的文件为止。
以上进行的其实就是路径解析。
实际上在通过环境变量CWD就可以得到当前所处的路径,当访问对应的文件时就要进行从根目录开始进行路径的解析,这样就需要一直进行磁盘的IO这样的的效率也太低了吧!
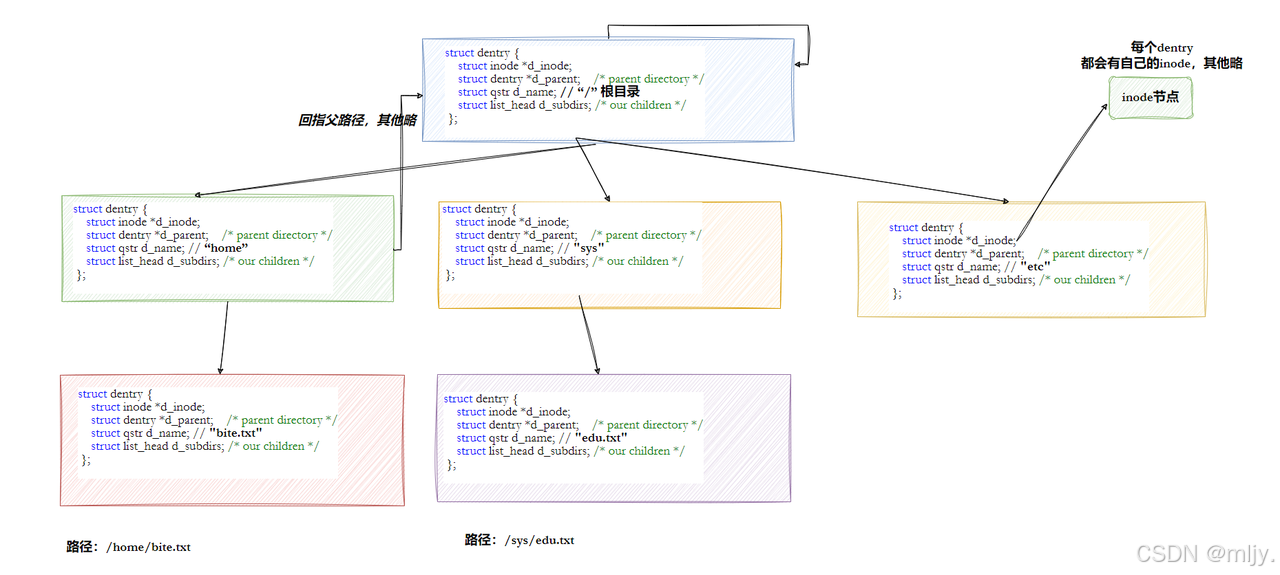
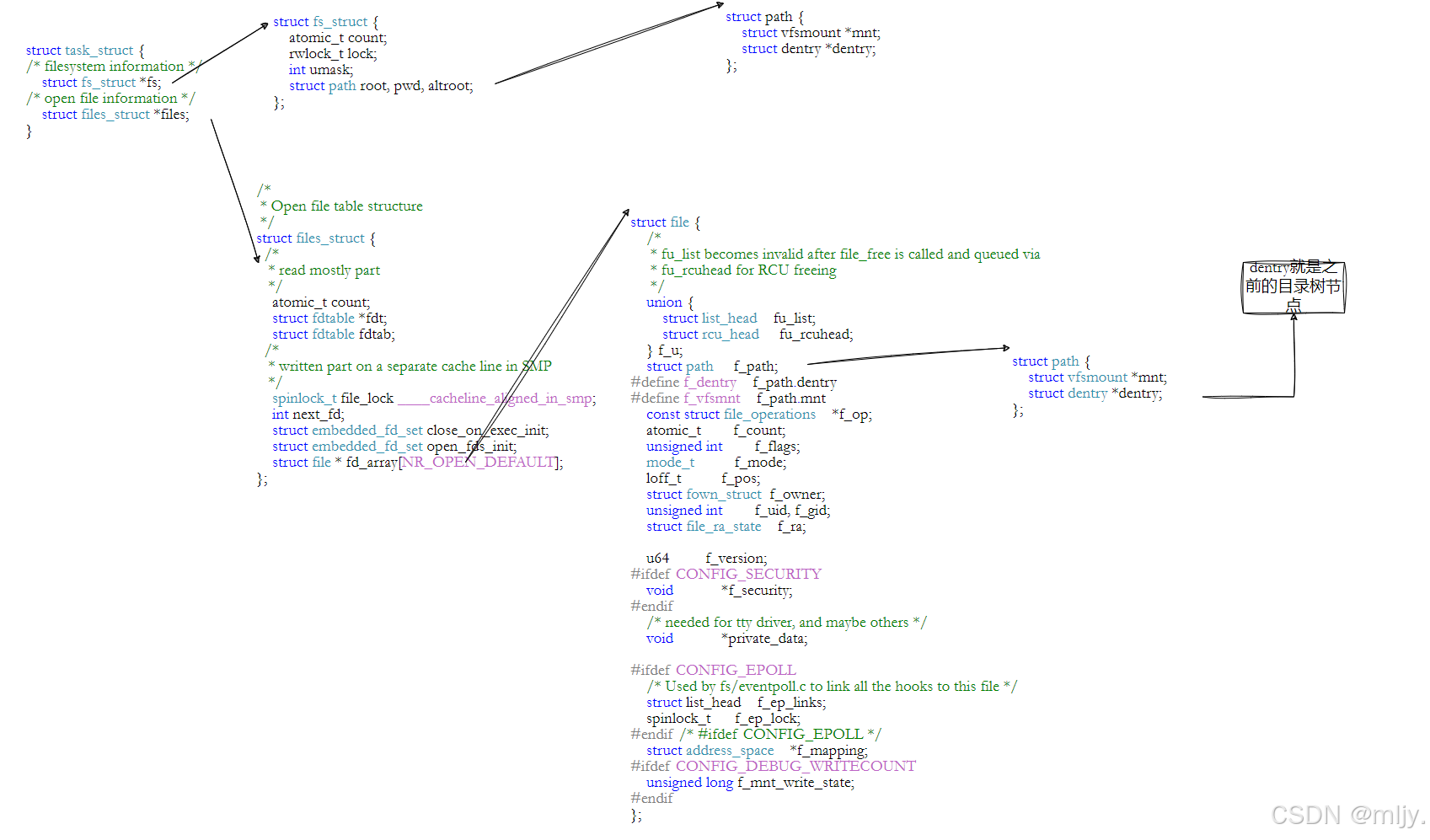
因此在Linux当中为了解决在路径解析过程当中效率低下的问题,就实现了dentry树来解决
以下时dentry结构体的源码:
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILING
struct dcookie_struct *d_cookie; /* cookie, if any */
#endif
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
}
以上就可以看出在dentry树每个节点当中都会存储对应文件的inode,此时只要有新的文件或者目录被打开就会在用来的dentry树当中创建新的节点,这样在对应的文件进行路径解析的时候就可以通过dentry树来实现快速的得到该文件的inode。更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何⽂件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径。
整个树形节点也同时会⾪属于LRU(Least Recently Used,最近最少使用)结构中,进⾏节点淘汰
分区挂载
在此有一个问题需要我们进行思考,那就是在Linux当中inode是不能跨分区的,那么当得到一个inode编号的时候怎么知道是在哪一个分区的呢?
在Linux当中为了解决以上的问题就引入的分区挂载的概念
首先来看以下的实验

首先制作一个大的磁盘块,将其当中磁盘的一块分区
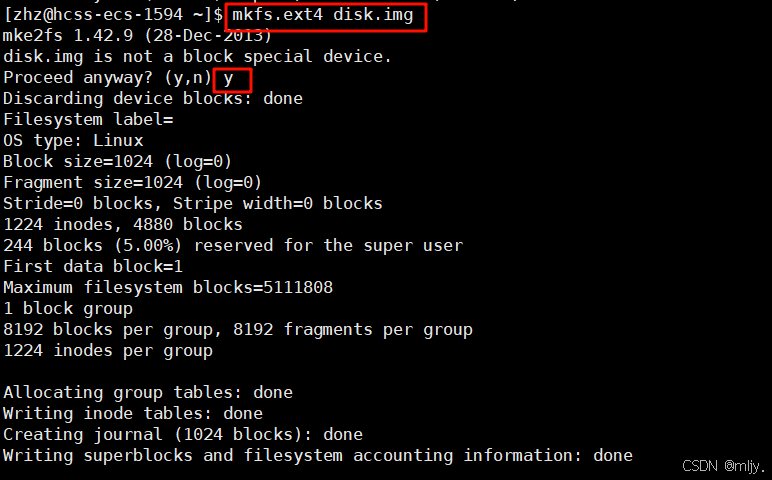
之后格式化写入文件系统
![]()
创建一个空的目录
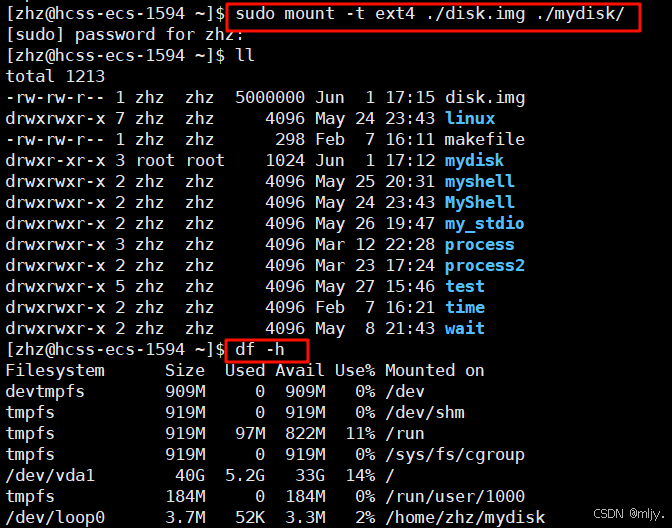
之后将之前创建的分区挂载到指定的目录当中
此在当前的目录下就创建出了一个mydisk的目录,接下来只要是在该目录当中创建文件就会存储在挂载的分区上

以上创建出新的分区之后若要进行卸载使用以下的指令
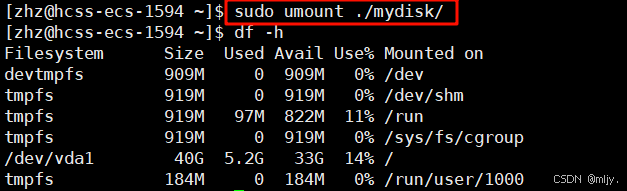
因此分区写入文件系统,无法直接使用,需要和指定的目录关联,进行挂载才能使用。
有了分区挂载之后当对于一个文件就可以根据当前文件的路径前缀来判断当前是处于哪一个分区
总结
通过以下的几张文件系统的图就能让我们将以上的知识串起来
4. 软硬链接
以上在了解了文件系统的相关知识之后接下来再来了解软硬链接的概念
4.1 软链接
在Linux当中当要通过一个文件来打开另外的一个文件就可以使用到软链接
使用方法:
ln -s 目标文件 链接文件例如以下示例:
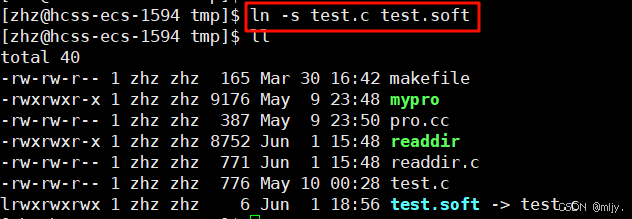
以上创建test.soft来链接test.c文件,在此就可以发现这两个文件的inode是不一样的
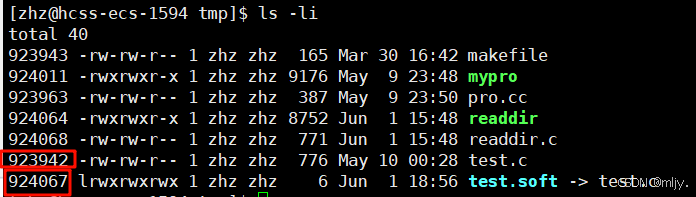 在此当我们对test.soft进行任何的操作时用来的test.c内容也会改变,因此软链接就可以看做是Windows当中的快捷方式 。
在此当我们对test.soft进行任何的操作时用来的test.c内容也会改变,因此软链接就可以看做是Windows当中的快捷方式 。
在软连接文件当中的内容其实存储的就是链接文件的路径。当出现当前路径下需要使用的文件和当前路径较为远时就可以使用软连接的方式来实现快速的定位到目标文件。
4.2 硬链接
以上我们知道了在磁盘当中真正用于表示不同的文件的是inode而不是文件名,那么这就可以使得多个不同文件名的文件对于同一个inode。在此就可以使用到硬链接。
使用方法:
ln 目标文件 链接文件例如以下示例:
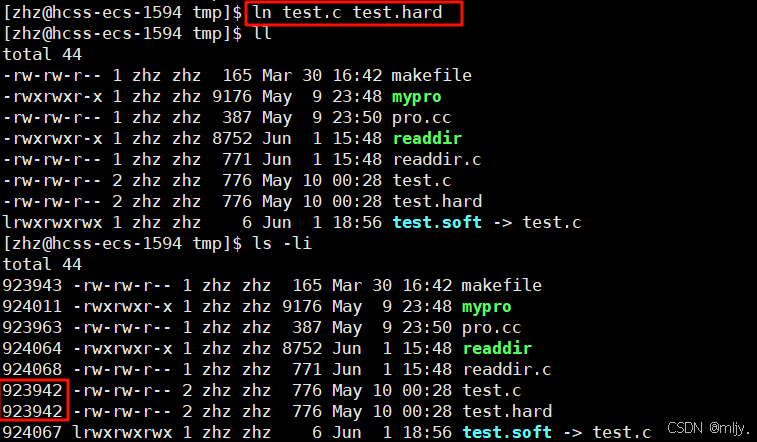
以上我们就给用来的test.c创建了一个硬链接test.hard,此时就会发现以上的两个文件的inode是一样的,这就说明这两个文件本质上是同一个文件。也就是说硬链接本质上是给目标文件起别名。
硬链接就是给对应的inode再创建了一组文件名和inode的映射关系。因此硬链接可以起到文件备份的作用。
以上在给test.c创建硬链接之后就会发现以上test.c和硬链接文件test.hard权限之后的数值变为了2,那么为什么在之前进行软连接的时候没有出现这样的现象呢?这时该数字表示的是什么呢?
其实该数字表示的就是文件名对应inode映射的文件名的个数,由于软连接的文件的inode是和目标文件的inode不一样的,这就不会使得目标文件的硬链接数增加。
此时会发现一个奇怪的点就是在当前路径下抽奖一个目录时,该命令的硬链接数默认就是2,这又是为什么呢?
其实进入到新创建的目录下使用ls指令就可以发现用来的.其实就是创建目录的硬链接目录
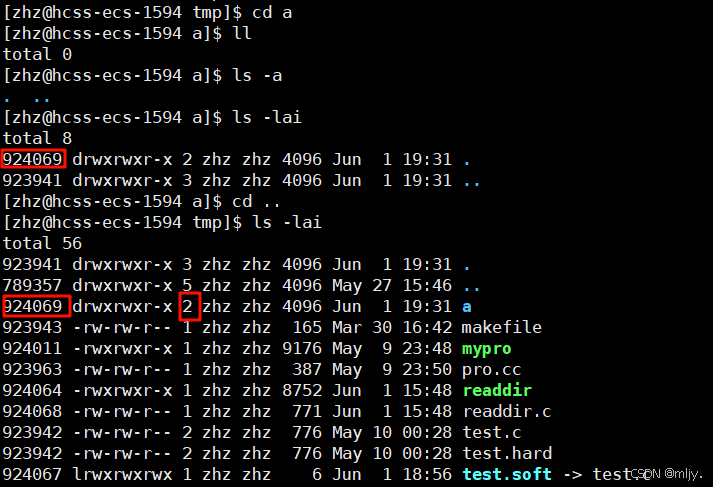
实际上目录当中的.和..都是目录的硬链接文件,但是在Linux当中只有操作系统能进行目录的硬链接,而用户是无法进行的,这是因为如果用户能随意的进行目录的链接,那么这时在系统当中就会很任意的形成路径环的问题。
-并建立socket连接发送和接收报文实例)






:chat_bot)











