| 栏目 | 内容 |
|---|---|
| 论文标题 | 大型语言扩散模型 (Large Language Diffusion Models) |
| 核心思想 | 提出LLaDA,一种基于扩散模型的LLM,通过前向掩码和反向预测过程建模语言分布,挑战自回归模型(ARM)在LLM领域的主导地位,并展示其在可扩展性、上下文学习、指令遵循和反向推理方面的强大能力。 |
| 模型名称 | LLaDA (Large Language Diffusion with mAsking - 大型语言掩码扩散模型) |
| 主要创新点 | 1. 新的LLM范式: 首次将掩码扩散模型(MDM)从头训练到8B参数规模用于通用语言建模,证明其作为ARM替代方案的可行性。 2. 强大的综合能力: LLaDA在预训练后展现出与顶尖ARM(如LLaMA3 8B)相当的上下文学习能力,SFT后展现出优秀的指令遵循能力。 3. 解决“反转诅咒”: LLaDA能有效处理需要反向推理的任务(如反向诗歌补全),表现优于GPT-40等强ARM。 4. 可扩展性验证: 实验证明LLaDA具备良好的可扩展性,性能随计算资源增加而提升,与ARM基线具有竞争力。 5. 有原则的生成方法: 通过优化似然界限,为概率推断提供了基于扩散的、有原则的生成途径。 |
| 解决的问题 | 1. 挑战“LLM必须是自回归模型”的普遍观念。 2. 探索克服ARM固有局限性(如顺序生成成本高、左到右偏差导致的某些推理能力弱)的新途径。 3. 为大型语言建模提供一种新的、有潜力的非自回归架构。 |
| 关键技术 | 掩码扩散模型(MDM)、前向掩码过程(随机比例掩码)、反向去噪/预测过程(Transformer预测掩码)、优化对数似然下界、监督微调(SFT)、低置信度重掩码、半自回归重掩码。 |
| 实验结果亮点 | LLaDA 8B Base在MMLU、GSM8K等基准上与LLaMA3 8B Base相当或更优;LLaDA 8B Instruct在多轮对话等指令任务上表现良好,并在反向诗歌补全任务中超越GPT-40。 |
| 未来展望 | 进一步扩大模型规模、探索多模态数据处理、集成提示调整技术、应用于基于Agent的系统、进行强化学习对齐等。 |
2)具体实现流程
LLaDA的实现流程主要包括预训练、监督微调(SFT)和推理三个阶段。
核心组件:掩码预测器 (Mask Predictor)
- 这是一个标准的Transformer解码器(但移除了因果掩码,使其可以双向关注上下文),用于根据部分掩码的输入序列
x_t来预测原始的、未掩码的词元x_0。
A. 预训练 (Pre-training)
- 目标: 训练掩码预测器
p_θ以学习通用的语言表示和生成能力。 - 输入:
- 大规模未标记文本语料库 (例如,论文中使用了2.3万亿词元)。
- 流程:
- 数据采样: 从语料库中随机抽取一个干净的文本序列
x_0。 - 时间步采样: 随机采样一个时间步(掩码比例)
t,其中t ~ Uniform(0, 1]。 - 前向掩码过程 (Forward Masking Process):
- 对于
x_0中的每个词元x_0^i,以概率t将其替换为特殊的[MASK]词元,以概率1-t保持其不变,得到部分掩码的序列x_t。 q(x_t | x_0):x_t^i = [MASK]with probt,x_t^i = x_0^iwith prob1-t.
- 对于
- 模型预测: 将部分掩码的序列
x_t输入到掩码预测器p_θ(· | x_t)。 - 损失计算: 模型的目标是预测
x_t中所有被[MASK]替换的原始词元。损失函数是只在被掩码位置计算的交叉熵损失的负值(公式3)。这个损失是模型负对数似然的一个上界(公式4)。
L(θ) = -E_{t,x_0,x_t} [ (1/t) * (1/L) * Σ_{i=1}^{L} 1[x_t^i = M] log p_θ(x_0^i | x_t) ]
(其中1[x_t^i = M]是指示函数,表示x_t的第i个词元是否为掩码) - 优化: 通过梯度下降更新模型参数
θ以最小化损失L(θ)。
- 数据采样: 从语料库中随机抽取一个干净的文本序列
- 输出:
- 预训练好的掩码预测器
p_θ(称为 LLaDA Base 模型)。
- 预训练好的掩码预测器
B. 监督微调 (Supervised Fine-Tuning - SFT)
- 目标: 使预训练的LLaDA模型具备遵循指令和特定任务的能力。
- 输入:
- 高质量的指令-响应对数据
(prompt, response),即(p_0, r_0)。
- 高质量的指令-响应对数据
- 流程:
- 数据采样: 从SFT数据集中获取一个
(p_0, r_0)对。 - 条件掩码: 保持提示
p_0不变。对响应r_0应用与预训练类似的前向掩码过程,得到掩码后的响应r_t。 - 模型预测: 将提示
p_0和掩码后的响应r_t一同(通常是拼接)输入到预训练好的掩码预测器p_θ(· | p_0, r_t)。 - 损失计算: 模型的目标是预测
r_t中被掩码的原始词元。损失函数仅在响应r_t的掩码位置计算交叉熵损失(公式5)。 - 优化: 更新模型参数
θ。
- 数据采样: 从SFT数据集中获取一个
- 输出:
- 经过SFT的LLaDA Instruct模型。
C. 推理/采样 (Inference/Sampling)
- 目标: 给定一个提示
p_0,生成连贯且相关的响应r_0。 - 输入:
- 用户提供的提示
p_0。 - 期望的生成长度
L_r(响应的长度)。 - 总采样步数
N。
- 用户提供的提示
- 反向去噪/生成过程 (Iterative Denoising/Generation Process):
- 初始化: 创建一个长度为
L_r的完全由[MASK]词元组成的序列r_1(时间步t=1)。 - 迭代生成: 进行
N个采样步骤。在每个步骤k(从1到N):
a. 当前时间步t_k = 1 - (k-1)/N,下一个时间步s_k = 1 - k/N。
b. 将当前提示p_0和部分掩码的响应r_{t_k}输入到训练好的掩码预测器p_θ。
c. 掩码预测器输出对r_{t_k}中所有[MASK]词元的预测(通常是概率分布)。
d. 根据预测结果,填充这些[MASK]位置(例如,通过贪心采样选择最可能的词元,或从分布中采样),得到一个对原始响应的临时估计r̂_0。
e. 重掩码 (Remasking): 为了过渡到下一个时间步s_k,需要对r̂_0进行重掩码,使其掩码比例符合s_k。将r_{t_k}中未被掩码的词元保持不变,对于那些在r_{t_k}中被掩码但在r̂_0中被填充的词元,根据目标掩码比例s_k和当前比例t_k,按一定策略决定是保持填充的词元,还是将其重新掩码为[MASK],得到r_{s_k}。
* 常见重掩码策略:
* 随机重掩码: 根据目标掩码比例s_k随机选择词元进行掩码。
* 低置信度重掩码: 优先将模型预测置信度最低的词元重新掩码,直到达到目标掩码比例s_k。
* 半自回归重掩码: 将序列分成块,从左到右依次生成每个块。在块内部,使用上述重掩码策略之一。 - 最终输出: 当所有
N步完成后 (即t趋近于0),得到的序列r_0即为最终生成的响应。
- 初始化: 创建一个长度为
- 输出:
- 生成的文本响应。
D. 条件对数似然评估 (用于评估任务)
- 目标: 评估模型对于给定提示
p_0生成特定候选响应r_0的可能性。 - 流程:
- 多次重复以下操作 (Monte Carlo 估计):
a. 随机选择要掩码的词元数量l(从1到r_0的长度L'均匀采样)。
b. 从r_0中随机选择l个词元进行掩码,得到r_l。
c. 将p_0和r_l输入模型,计算模型对r_0中被掩码的l个词元进行正确预测的对数概率之和。 - 对所有重复的对数概率取平均,作为
log p_θ(r_0 | p_0)的估计。
- 多次重复以下操作 (Monte Carlo 估计):
这个流程概述了LLaDA如何从数据中学习,并最终生成文本或评估文本。核心在于迭代地掩码和预测,通过扩散过程的思想来建模复杂的语言分布。
文章目录
- 摘要
- 1. 引言
- 2. 方法
- 2.1. 概率公式
- 2.2. 预训练
- 2.4. 推理
- 3. 实验
- 3.1. LLaDA在语言任务上的可扩展性
- 3.2. 基准测试结果
- 3.3. 反向推理和分析
- 3.4. 案例研究
- 4. 相关工作
- 5. 结论与讨论
摘要
自回归模型(ARMs)被广泛认为是大型语言模型(LLMs)的基石。我们通过引入LLaDA来挑战这一观念。LLaDA是一个在预训练和监督微调(SFT)范式下从头开始训练的扩散模型。LLaDA模型通过前向数据掩码过程和反向过程(由一个Vanilla Transformer参数化以预测掩码词元)来分布数据。通过优化似然界限,它为概率推断提供了一种有原则的生成方法。在广泛的基准测试中,LLaDA表现出强大的可扩展性,优于我们自建的ARM基线。值得注意的是,LLaDA 8B在上下文学习方面与像LLaMA3 8B这样的强大LLM具有竞争力,并且在SFT之后,在多轮对话等案例研究中展现出令人印象深刻的指令遵循能力。此外,LLaDA解决了反转诅咒问题,在反向诗歌补全任务中超越了GPT-40。我们的发现确立了扩散模型作为ARM的一种可行且有前景的替代方案,挑战了上述关键LLM能力本质上与ARM相关的假设。项目页面和代码:https://ml-gsai.github.io/LLaDA-demo/。
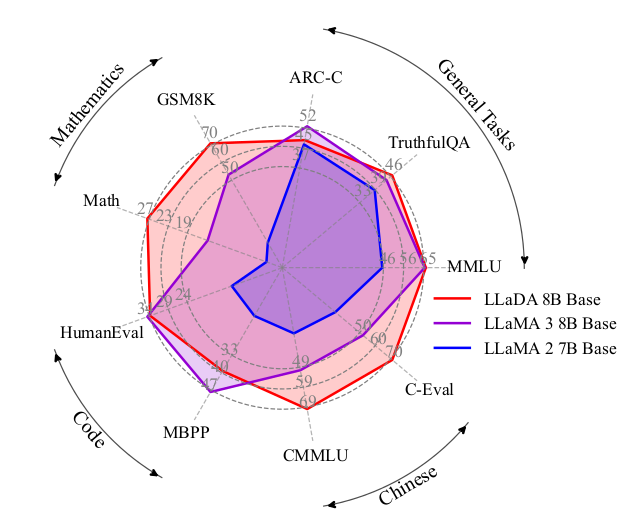
图1. 零/少样本基准测试。我们将LLaDA从头开始扩展到前所未有的8B参数规模,在与强大LLM(Dubey等人,2024)的对比中取得了有竞争力的性能。图表为一个雷达图,中心有LLaDA 8B Base, LLaMA 3 8B Base, LLaMA 2 7B Base的图例。坐标轴包括Mathematics (GSM8K, Math), Code (HumanEval, MBPP), Chinese (CMMLU, C-Eval), General Tasks (TruthfulQA, MMLU, ARC-C)。数据显示LLaDA 8B Base(红色)在多个任务上与LLaMA 3 8B Base(紫色)表现接近或更好,并优于LLaMA 2 7B Base(蓝色)。
1. 引言
现在被证明的,曾经仅仅是想象。
——威廉·布莱克
大型语言模型(LLMs)(Zhao等人,2023)完全属于生成建模的框架。具体来说,LLMs旨在通过优化模型分布pθ(·)来捕捉真实但未知的语言分布Pdata(·),方法是最大似然估计,或等效地最小化两个分布之间的KL散度:

主要方法依赖于自回归建模(ARM)——通常称为下一词元预测范式——来定义模型分布:
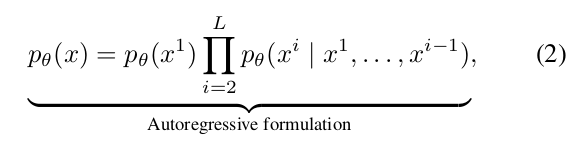
其中x是一个长度为L的序列,xⁱ是第i个词元。
这种范式已被证明非常有效(Radford,2018;Radford等人,2019;Brown,2020;OpenAI,2022),并已成为当前LLM的基础。尽管其被广泛采用,一个基本问题仍未得到解答:自回归范式是实现LLM所展现智能的唯一可行路径吗?
我们认为答案并非简单的“是”。先前被忽略的关键洞察在于:是生成建模原理(即公式(1)),而非自回归公式(即公式(2))本身,从根本上支撑了LLM的基本属性,如下文详述。然而,LLM的某些固有局限性可以直接追溯到其自回归特性。
特别地,我们认为可扩展性主要是Transformers(Vaswani,2017)、模型和数据规模以及由公式(1)中的生成原理引导的Fisher一致性¹(Fisher,1922)之间相互作用的结果,而非ARM的独特成果。扩散Transformer(Bao等人,2023;Peebles & Xie,2023)在视觉数据(Brooks等人,2024)上的成功支持了这一论点。
此外,指令遵循和上下文学习(Brown,2020)的能力似乎是所有结构一致的语言任务上合适的条件生成模型的内在属性,而非ARM的专属优势。另外,虽然ARM可以被解释为无损数据压缩器(Deletang等人;Huang等人,2024b),任何充分表达的概率模型都可以实现类似的能力(Shannon,1948)。
然而,LLM的自回归特性带来了显著的挑战。例如,逐个词元顺序生成会产生高计算成本,而从左到右的建模限制了其在反向推理任务中的有效性(Berglund等人,2023)。这些固有的局限性约束了LLM处理更长和更复杂任务的能力。
受这些洞察的启发,我们引入LLaDA(Large Language Diffusion with mAsking,大型语言掩码扩散模型),以研究LLM所展现的能力是否可以从公式(2)之外的生成建模原理中产生,从而解决前面提出的基本问题。与传统ARM不同,LLaDA利用掩码扩散模型(MDM)(Austin等人,2021a;Lou等人,2023;Shi等人,2024;Sahoo等人,2024;Ou等人,2024),该模型包含一个离散随机掩码过程,并训练一个掩码预测器来近似其逆过程。这种设计使LLaDA能够构建具有双向依赖性的模型分布,并优化其对数似然的下界,为现有LLM提供了一种未被探索且有原则的替代方案。
我们采用数据准备、预训练、监督微调(SFT)和评估的标准流程,将LLaDA扩展到前所未有的8B规模的语言扩散模型。具体来说,LLaDA 8B在2.3万亿词元上从头开始预训练,使用了0.13百万H800 GPU小时,然后在450万对数据上进行SFT。在包括语言理解、数学、代码和中文在内的各种任务中,LLaDA展示了以下贡献:
可扩展性。 LLaDA有效地扩展到10²³ FLOPs的计算预算,在六个任务(如MMLU和GSM8K)上,其结果与在相同数据上训练的自建ARM基线相当。
上下文学习。 值得注意的是,LLaDA 8B在几乎所有15个标准的零/少样本学习任务上都超过了LLaMA2 7B(Touvron等人,2023),同时与LLaMA3 8B(Dubey等人,2024)表现相当。
指令遵循。 LLaDA在SFT后显著增强了遵循指令的能力,如在多轮对话等案例研究中所示。
反向推理。 LLaDA有效地打破了反转诅咒(Berglund等人,2023),在前向和反向任务中表现出一致的性能。值得注意的是,它在反向诗歌补全任务中优于GPT-40。
2. 方法
在本节中,我们介绍LLaDA的概率公式²,以及预训练、监督微调和推理过程,如图2所示。
2.1. 概率公式
与公式(2)中的ARM不同,LLaDA通过前向过程和反向过程(Austin等人,2021a;Ou等人,2024)定义模型分布pθ(x₀)。前向过程逐渐独立地掩码x₀中的词元,直到在t=1时序列完全被掩码。对于t ∈ (0,1),序列xₜ部分被掩码,每个词元以概率t被掩码,或以概率1-t保持未掩码。反向过程通过在t从1向0移动时迭代预测掩码词元来恢复数据分布。
LLaDA的核心是一个掩码预测器,一个参数模型pθ(x₀|xₜ),它以xₜ为输入并同时预测所有掩码词元(表示为M)。它使用仅在掩码词元上计算的交叉熵损失进行训练:
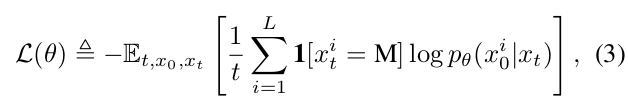
其中x₀从训练数据中采样,t从[0,1]中均匀采样,xₜ从前向过程中采样。指示函数1[·]确保损失仅在掩码词元上计算。
一旦训练完成,我们可以模拟一个由掩码预测器参数化的反向过程(详见2.4节),并将模型分布pθ(x₀)定义为边际分布。
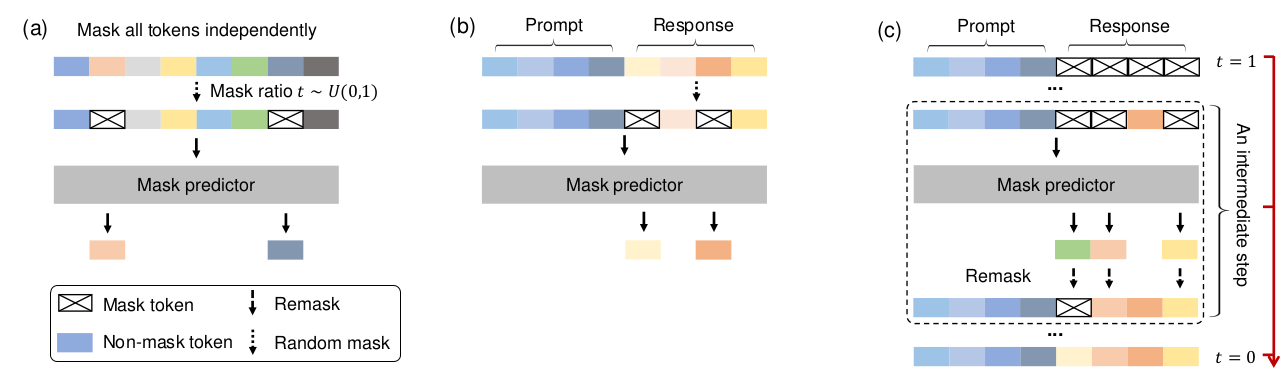
图2. LLaDA概念概览。(a) 预训练。LLaDA在文本上进行训练,文本中的所有词元以相同比例 t ~ U[0, 1] 独立随机掩码。(b) SFT。仅响应词元可能被掩码。© 采样。LLaDA模拟一个从t=1(完全掩码)到t=0(未掩码)的扩散过程,在每个步骤中同时预测所有掩码,并采用灵活的重掩码策略。图(a)显示一个序列,所有词元独立掩码,掩码比例t从U(0,1)采样,然后通过掩码预测器。图(b)显示提示和响应,只有响应部分可能被掩码,然后通过掩码预测器。图©显示一个从t=1开始的迭代过程,通过掩码预测器和重掩码步骤,逐步去掩码直到t=0,其中包含一个中间步骤的示意。
在t=0时诱导产生。值得注意的是,公式(3)中的损失已被证明是模型分布负对数似然的一个上界(Shi等人,2024;Ou等人,2024):
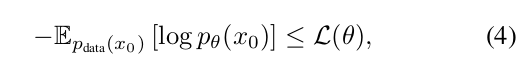
使其成为生成建模的一个有原则的目标。
值得注意的是,LLaDA采用在0和1之间随机变化的掩码比例,而掩码语言模型(Devlin,2018)使用固定的比例。这些细微的差异具有显著的影响,尤其是在大规模情况下:如公式(4)所示,LLaDA是一个有原则的生成模型,具有自然执行上下文学习的潜力,类似于LLM。此外,其生成视角确保了在极端情况下的Fisher一致性(Fisher,1922),表明其在大数据和模型方面的强大可扩展性。
2.2. 预训练
LLaDA采用Transformer(Vaswani,2017)作为掩码预测器,其架构类似于现有的LLM。然而,LLaDA不使用因果掩码,因为其公式允许它看到整个输入进行预测。
我们训练了两种不同大小的LLaDA变体:10亿(B)和8B。我们在此总结了LLaDA 8B和LLaMA3 8B(Dubey等人,2024)的模型架构,并在附录B.2中提供了详细信息。我们确保了大多数超参数的一致性,同时进行了一些必要的修改。为简单起见,我们使用标准的自注意力机制而非分组查询注意力(Ainslie等人,2023),因为LLaDA与KV缓存不兼容,导致键和值头的数量不同。因此,注意力层有更多参数,我们减少了FFN维度以保持相当的模型大小。此外,由于对我们的数据调整了分词器(Brown,2020),词汇表大小略有不同。
LLaDA模型在一个包含2.3万亿(T)词元的数据集上进行预训练,遵循与现有大型语言模型(LLM)(Touvron等人,2023;Chu等人,2024)紧密一致的数据协议,未加入任何特殊技术。数据来源于在线语料库,通过手动设计的规则和基于LLM的方法过滤低质量内容。除了通用文本外,数据集还包含高质量的代码、数学和多语言数据。数据源和领域的混合由缩小规模的ARM指导。预训练过程使用固定的4096词元序列长度,总计算成本为0.13百万H800 GPU小时,与相同规模和数据集大小的ARM相似。
对于一个训练序列x₀,我们随机采样t ∈ [0,1],以相同的概率t独立掩码每个词元得到xₜ(见图2(a)),并通过蒙特卡洛方法估计公式(3)进行随机梯度下降训练。此外,遵循Nie等人(2024)的方法,为了增强LLaDA处理可变长度数据的能力,我们将1%的预训练数据设置为从范围[1, 4096]中均匀采样的随机长度。
我们采用Warmup-Stable-Decay(Hu等人,2024)学习率调度器来监控训练过程,而不中断连续训练。具体来说,我们在最初的2000次迭代中将学习率从0线性增加到4 × 10⁻⁴,并将其保持在4 × 10⁻⁴。在处理了1.2T词元后,我们将学习率衰减到1 × 10⁻⁴,并在接下来的0.8T词元中保持不变以确保稳定训练。最后,在最后的0.3T词元中,我们将学习率从1 × 10⁻⁴线性降低到1 × 10⁻⁵。此外,我们使用了AdamW优化器(Loshchilov,2017),权重衰减为0.1,批量大小为1280,每个GPU的本地批量大小为4。8B实验执行了一次,没有任何超参数调整。
2.3. 监督微调
我们通过使用配对数据(p₀, r₀)进行监督微调(SFT)来增强LLaDA遵循指令的能力,其中p₀是提示,r₀表示响应。这是LLM最简单和最基本的后训练方法。技术上,这需要在预训练中建模条件分布pθ(r₀|p₀)而非pθ(x₀)。
实现与预训练类似。如图2(b)所示,我们保持提示不变,并独立地掩码响应中的词元,如同对x₀所做的那样。然后,我们将提示和掩码后的响应rₜ都输入到预训练的掩码预测器中,以计算SFT的损失:
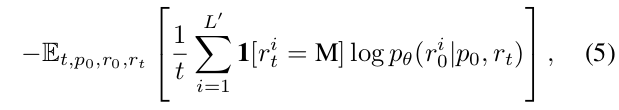
其中L’表示稍后指定的动态长度,所有其他符号与之前相同。
注意,这种方法与预训练完全兼容。本质上,p₀和r₀的串联可以被视为干净的预训练数据x₀,而p₀和rₜ的串联则作为掩码版本xₜ。该过程与预训练相同,唯一的区别是所有掩码词元都恰好出现在r₀部分。
LLaDA 8B模型在一个包含450万对数据的数据集上进行SFT。与预训练过程一致,数据准备和训练都遵循现有LLM中使用的SFT协议(Chu等人,2024;Yang等人,2024),没有引入任何额外的技术来优化LLaDA的性能。数据集涵盖多个领域,包括代码、数学、指令遵循和结构化数据理解。我们在每个小批量中的短对末尾附加|EOS|词元,以确保所有数据的长度相等。我们在训练期间将|EOS|视为普通词元,并在采样期间将其移除,从而使LLaDA能够自动控制响应长度。
我们在SFT数据上训练3个周期,使用与预训练阶段类似的调度。学习率在最初50次迭代中从0线性增加到2.5 × 10⁻⁵,然后保持不变。在最后10%的迭代中,它线性降低到2.5 × 10⁻⁶。此外,我们将权重衰减设置为0.1,全局批量大小为256,每个GPU的本地批量大小为2。SFT实验执行了一次,没有任何超参数调整。
2.4. 推理
作为一个生成模型,LLaDA既能采样新文本,也能评估候选文本的似然。
我们从采样开始。如图2©所示,给定一个提示p₀,我们离散化反向过程以从模型分布pθ(r₀|p₀)中采样,从完全掩码的响应开始。总采样步数是一个超参数,这自然为LLaDA提供了效率和样本质量之间的权衡,如3.3节所分析。我们默认使用均匀分布的时间步。此外,生成长度也被视为一个超参数,指定采样过程开始时完全掩码句子的长度。如附录B.4详述,由于预训练和SFT都是在可变长度的数据集上进行的,最终结果对这个长度超参数不敏感。
在从时间t ∈ (0,1]到s ∈ [0,t)的中间步骤中,我们将p₀和rₜ都输入掩码预测器,并同时预测所有掩码词元。随后,我们期望地对预测的词元进行重掩码以获得rₛ,确保反向过程的转换与前向过程对齐以进行准确采样(Austin等人,2021a)。
原则上,重掩码策略应该是纯随机的。然而,受LLM采样中退火技巧(Holtzman等人,2019;Brown,2020)的启发,我们探索了两种确定性但有效的重掩码策略。具体来说,类似于Chang等人(2022),我们基于预测的置信度,重掩码预测词元中置信度最低的那些,称为低置信度重掩码。此外,对于SFT后的LLaDA,我们可以将序列分成几个块,并从左到右生成它们,称为半自回归重掩码。在每个块内,我们应用反向过程进行采样。我们在附录B.3中提供了更多细节和消融研究。
对于条件似然评估,我们可以自然地利用公式(5)中的上界。然而,我们发现以下等效形式(Ou等人,2024)表现出更低的方差并且评估更稳定:
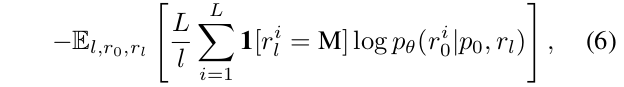
其中l从{1, 2, …, L’}中均匀采样,rₗ是通过从r₀中无放回地均匀采样l个词元进行掩码得到的。此外,我们采用了无监督的分类器无关引导(Nie等人,2024)。我们请读者参阅附录A.2了解更多细节。
我们在附录A中介绍了训练、采样和似然评估算法,以及理论细节。
3. 实验
我们在标准基准上评估LLaDA的可扩展性、指令遵循和上下文学习能力,随后在更受控的数据集上进行分析和案例研究,以提供全面的评估。
3.1. LLaDA在语言任务上的可扩展性
我们首先研究LLaDA在下游任务上与我们构建的ARM基线的可扩展性比较。
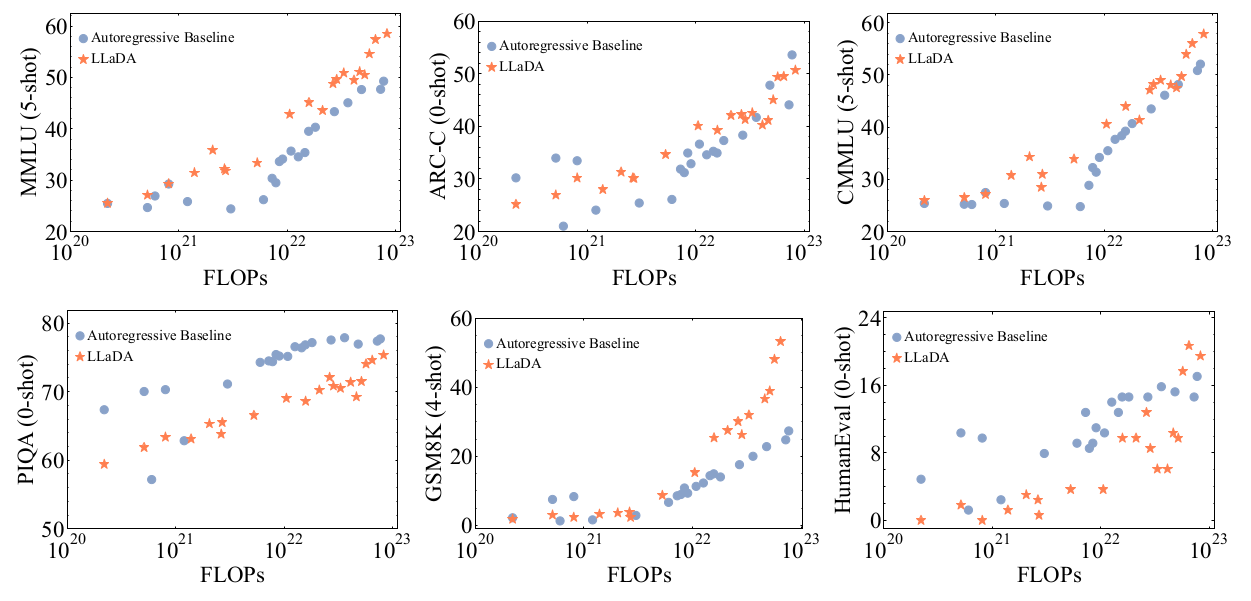
图3. LLaDA的可扩展性。我们评估了LLaDA和我们在相同数据上训练的ARM基线在计算FLOPs增加时跨六个任务的性能。LLaDA表现出强大的可扩展性,在六个任务上的整体性能与ARM相当。图表包含六个子图,分别对应MMLU (5-shot), ARC-C (0-shot), CMMLU (5-shot), PIQA (0-shot), GSM8K (4-shot), HumanEval (0-shot)。每个子图的X轴是FLOPs (从10²⁰到10²³),Y轴是对应任务的得分。图例显示“• Autoregressive Baseline”和“★ LLaDA”。在MMLU和GSM8K上,LLaDA(橙色星号)的趋势线似乎比自回归基线(蓝色圆点)略陡峭,表明更好的可扩展性。在其他任务上,两者趋势相似或LLaDA略逊一筹但差距随FLOPs增加而缩小。
具体来说,在1B规模上,我们确保LLaDA和ARM共享相同的架构、数据和所有其他配置。在更大规模上,由于资源限制,我们还报告了LLaDA和ARM模型在略有不同大小、但在相同数据上训练的结果,详见附录B.2。我们使用计算成本作为统一的扩展度量。评估时,我们关注六个标准且多样化的任务。
如图3所示,LLaDA表现出令人印象深刻的可扩展性,其总体趋势与ARM高度竞争。值得注意的是,在MMLU和GSM8K等任务中,LLaDA表现出更强的可扩展性。即使在PIQA等性能落后的任务上,LLaDA在更大规模时也缩小了与ARM的差距。为了解释异常值的显著影响,我们选择不拟合定量的扩展曲线,避免潜在的误解。尽管如此,结果清楚地证明了LLaDA的可扩展性。
Nie等人(2024)指出,MDM需要比ARM多16倍的计算才能达到相同的似然。然而,有一些关键差异使得本研究的结论更具普适性。特别地,似然对于下游任务性能而言是一个相对间接的度量,并且扩散模型优化的是似然的一个界限,使其不能直接与ARM比较。此外,我们将Nie等人(2024)中的扩展范围从10¹⁸ ~ 10²⁰扩展到本工作中的10²⁰ ~ 10²³。
3.2. 基准测试结果
为了全面评估LLaDA 8B的上下文学习和指令遵循能力,我们与现有类似规模的LLM(Touvron等人,2023;Dubey等人,2024;Chu等人,2024;Yang等人,2024;Bi等人,2024;Jiang等人,2023)进行了详细比较。任务的选择和评估协议与现有研究一致,涵盖了通用任务、数学、代码和中文领域的15个流行基准。更多细节在附录B.5中提供。为了更直接的比较,我们在我们的实现中重新评估了代表性的LLM(Touvron等人,2023;Dubey等人,2024)。
如表1所示,在2.3T词元上预训练后,LLaDA 8B表现出卓越的性能,在几乎所有任务上都超过了LLaMA2 7B,并且总体上与LLaMA3 8B具有竞争力。LLaDA在数学和中文任务上显示出优势。我们推测其优势与在某些任务上表现相对较弱的原因相同——数据质量和分布的差异,这很大程度上是由于LLM数据集的闭源情况。
值得注意的是,我们通过以GSM8K为例仔细排除了数据泄露的可能性。首先,如图3所示,LLaDA在GSM8K方面优于ARM基线。此外,结论在一个完全未见的类似GSM8K的任务(Ye等人,2024)上仍然成立,详见附录B.7。
此外,表2比较了LLaDA 8B Instruct与现有LLM的性能。我们观察到SFT提高了LLaDA在大多数下游任务上的性能。一些指标,如MMLU,有所下降,我们推测这可能是由于SFT数据质量欠佳所致。总体而言,由于我们没有进行强化学习(RL)对齐,我们的结果略逊于LLaMA3 8B Instruct,尽管许多指标的差距仍然很小。值得注意的是,即使仅通过SFT,LLaDA也展现出令人印象深刻的。
表1. 预训练LLM的基准测试结果。 * 表示LLaDA 8B Base、LLaMA2 7B Base和LLaMA3 8B Base在相同协议下评估,详见附录B.5。†和‡标记的结果分别来源于Chu等人(2024);Yang等人(2024)和Bi等人(2024)。括号中的数字表示评估使用的shot数。“-”表示未知数据。
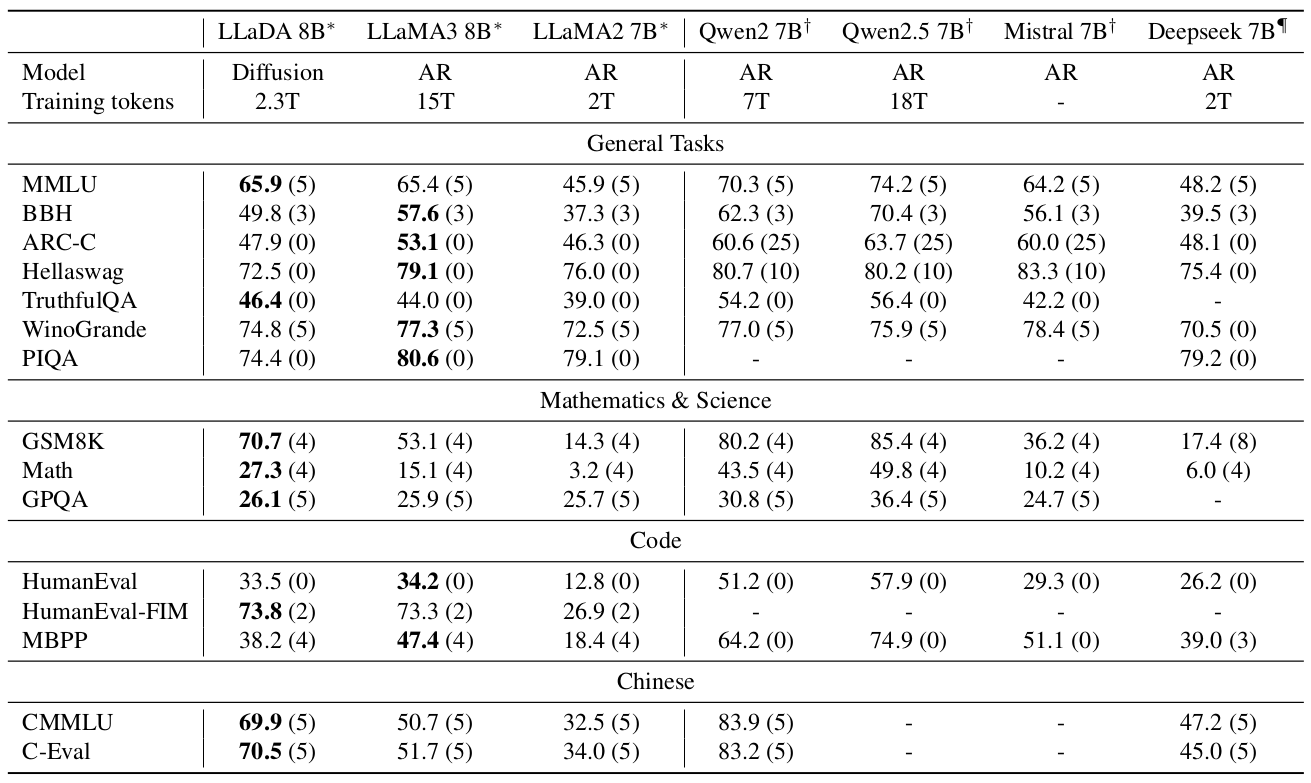
表2. 后训练LLM的基准测试结果。 LLaDA仅采用SFT程序,而其他模型有额外的强化学习(RL)对齐。* 表示LLaDA 8B Instruct、LLaMA2 7B Instruct和LLaMA3 8B Instruct在相同协议下评估,详见附录B.5。†和‡标记的结果分别来源于Yang等人(2024)和Bi等人(2024)。括号中的数字表示上下文学习使用的shot数。“-”表示未知数据。
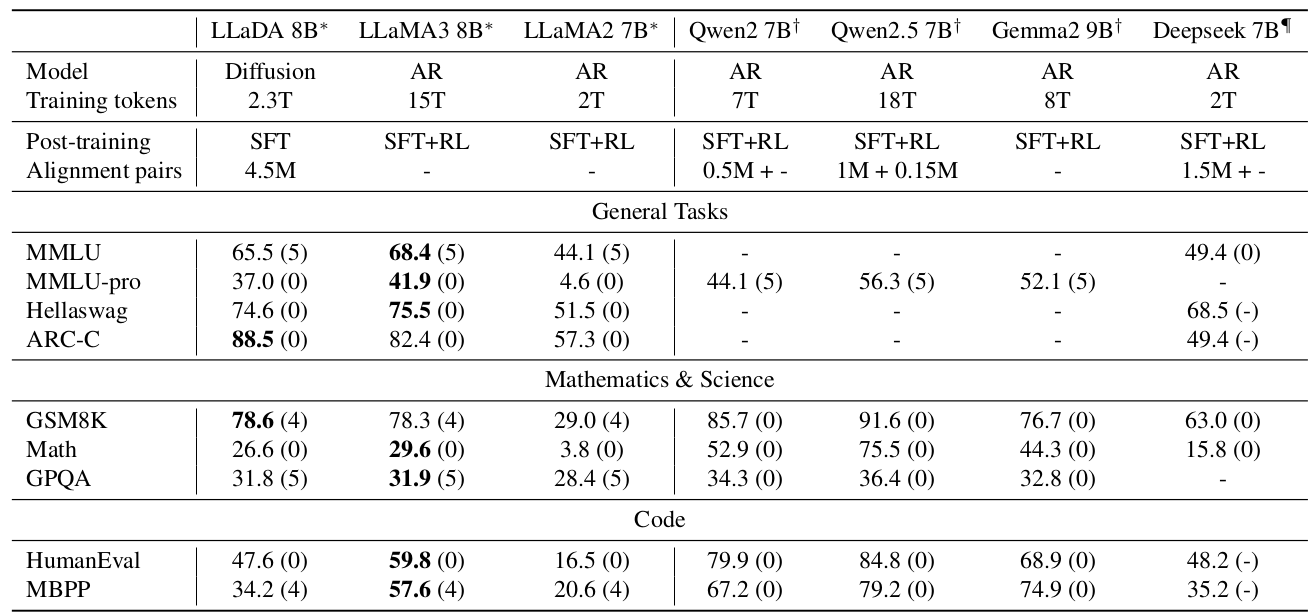
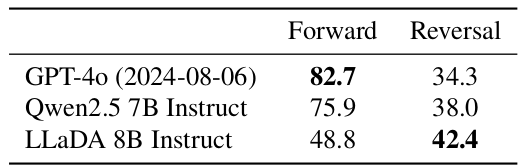
表3. 诗歌补全任务中的比较。
指令遵循能力,详见3.4节。我们将基于RL的对齐留作未来工作。
总的来说,尽管数据透明度不足,我们已尽一切努力采用标准化程序并引入多样化的任务,我们相信它们足以证明LLaDA的非凡能力,据我们所知,这是唯一具有竞争力的非自回归模型。
3.3. 反向推理和分析
为了量化模型的反向推理能力(Berglund等人,2023),我们遵循Allen-Zhu & Li(2023)建立的协议。具体来说,我们构建了一个包含496对著名中国古诗句的数据集。给定一首诗中的一句,模型任务是生成下一句(正向)或前一句(反向),无需额外微调。示例可在附录B.8中找到。与以往研究(Nie等人,2024;Kitouni等人,2024)相比,此设置提供了更直接和更现实的评估。
如表3所示,LLaDA有效地解决了反转诅咒(Berglund等人,2023),在正向和反向任务中均表现出一致的零样本性能。相比之下,Qwen 2.5和GPT-40在这两者之间都表现出显著的差距。正向生成的结果证实了这两个ARM都很强大,受益于远大于LLaDA的数据集和计算资源。然而,LLaDA在反向任务中大幅优于两者。
我们强调,我们没有为反向任务设计任何特殊的东西。直观地说,LLaDA统一对待词元而没有归纳偏置,从而导致平衡的性能。更多细节请参见附录A.2。
我们还在附录B.3和附录B.6中分析了重掩码策略和采样步骤的影响。
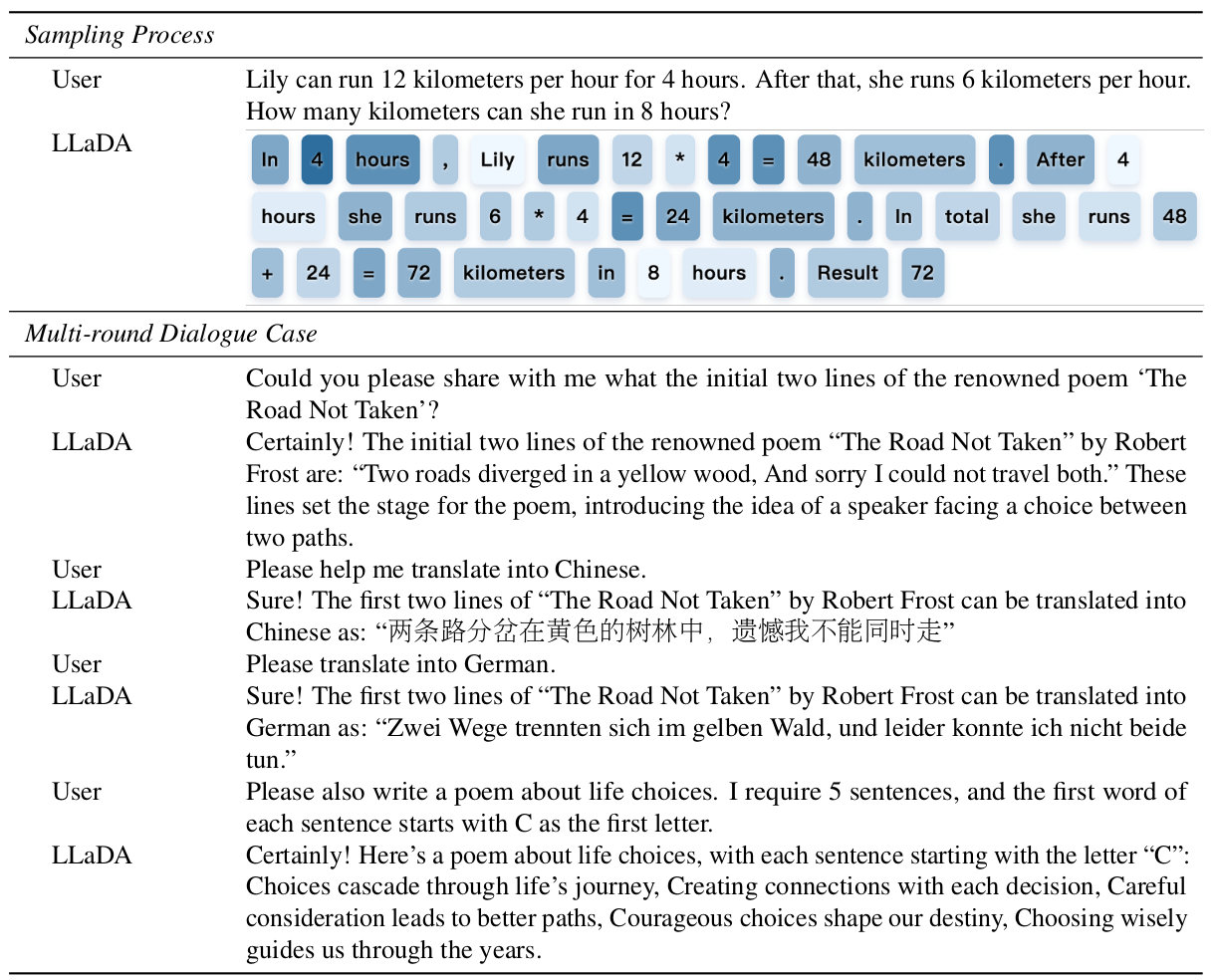
3.4. 案例研究
我们在表4中展示了LLaDA 8B Instruct生成的样本,展示了其指令遵循能力。首先,该表说明了LLaDA以非自回归方式生成连贯、流畅和扩展文本的能力。其次,它突出了模型的多轮对话能力,能够跨多种语言有效地保留对话历史并产生上下文适当的响应。LLaDA的这种聊天能力令人印象深刻,因为据我们所知,这是它首次偏离传统ARM。更多关于重掩码和推理任务的案例研究见附录B.9。
4. 相关工作
扩散模型(Sohl-Dickstein等人,2015;Ho等人,2020;Song等人,2020)在视觉领域表现出色,但尽管付出了大量努力,在LLM方面仍未得到验证。
一种简单的方法是将文本数据连续化并直接应用扩散模型(Li等人,2022;Gong等人,2022;Han等人,2022;Strudel等人,2022;Chen等人,2022;Dieleman等人,2022;Richemond等人,2022;Wu等人,2023;Mahabadi等人,2024;Ye等人,2023b)。或者,一些方法转而对离散分布的连续参数进行建模(Lou & Ermon,2023;Graves等人,2023;Lin等人,2023;Xue等人,2024)。然而,可扩展性仍然是一个挑战,因为一个1B参数模型需要ARM 64倍的计算才能达到相当的性能(Gulrajani & Hashimoto,2024)。
另一种方法是用具有新的前向和反向动态的离散过程取代连续扩散(Austin等人,2021a),从而产生了许多变体(Hoogeboom等人,2021b;a;He等人,2022;Campbell等人,2022;Meng等人,2022;Reid等人,2022;Sun等人,2022;Kitouni等人,2023;Zheng等人,2023;Chen等人,2023;Ye等人,2023a;Gat等人,2024;Zheng等人,2024;Sahoo等人,2024;Shi等人,2024)。值得注意的是,Lou等人(2023)表明,掩码扩散作为离散扩散的一种特殊情况,在GPT-2规模上实现了与ARM相当或超过ARM的困惑度。Ou等人(2024)建立了基本的理论结果,这启发了我们的模型设计、训练和推理(见附录A)。Nie等人(2024)探索了如何在GPT-2规模上利用MDM进行语言任务,如问答。Gong等人(2024)在MDM公式中微调ARM。然而,改进仅限于某些指标,并且尚不清楚这种方法是否能在全面评估下产生与强大LLM相当的基础模型。
相比之下,本研究将MDM从头开始扩展到前所未有的8B参数规模,实现了与LLaMA 3等领先LLM相当的性能。
此外,图像生成方面的一系列并行工作(Chang等人,2022;2023)与MDM在文本数据上的应用非常吻合。此外,MDM在蛋白质生成等领域也显示出潜力(Wang等人,2024b;c),并取得了有希望的结果。值得注意的是,Kou等人(2024);Xu等人(2025)展示了使用蒸馏加速MDM采样的潜力,进一步提高其效率。
表4. 采样过程和生成的多轮对话可视化。 在LLaDA的响应中,较深的颜色表示在采样后期预测的词元,而较浅的颜色对应于较早的预测。
5. 结论与讨论
困难之中蕴藏机遇。
——阿尔伯特·爱因斯坦
我们引入LLaDA,一种基于扩散模型的、有原则且先前未被探索的大型语言建模方法。LLaDA在可扩展性、上下文学习和指令遵循方面表现出强大的能力,实现了与强大LLM相当的性能。此外,LLaDA提供了独特的优势,如双向建模和增强的鲁棒性,有效地解决了现有LLM的一些固有局限性。我们的发现不仅确立了扩散模型作为一种可行且有前景的替代方案,而且挑战了这些基本能力本质上与ARM相关的普遍假设。
尽管前景看好,扩散模型的全部潜力仍有待充分探索。这项工作的几个局限性为未来的研究提供了重要机会。
由于计算限制,LLaDA和ARM之间的直接比较——例如在相同数据集上训练——被限制在小于10²³ FLOPs的计算预算内。为了分配资源训练尽可能大的LLaDA模型并展示其潜力,我们未能将ARM基线扩展到相同程度。此外,没有为LLaDA设计专门的注意力机制或位置嵌入,也没有应用任何系统级的架构优化。在推理方面,我们对引导机制(Dhariwal & Nichol,2021;Ho & Salimans,2022)的探索仍处于初步阶段,LLaDA目前对推理超参数表现出敏感性。此外,LLaDA尚未经历与强化学习的对齐(Ouyang等人,2022;Rafailov等人,2024),这对于提高其性能和与人类意图的对齐至关重要。
展望未来,LLaDA的规模仍小于领先的对应模型(Achiam等人,2023;Dubey等人,2024;Google,2024;Anthropic,2024;Yang等人,2024;Liu等人,2024),这突出表明需要进一步扩展以全面评估其能力。此外,LLaDA处理多模态数据的能力仍未被探索。LLaDA对提示调整技术(Wei等人,2022)的影响及其与基于代理的系统(Park等人,2023;Wang等人,2024a)的集成尚待充分理解。最后,对LLaDA进行系统的后训练研究可能有助于开发类O1系统(OpenAI,2024;Guo等人,2025)。
算法1 LLaDA的预训练
需要: 掩码预测器 pθ, 数据分布 Pdata
1: repeat
2: x₀ ~ Pdata, t ~ U(0, 1] # 以1%的概率,x₀的序列长度遵循U[1, 4096]
3: xₜ ~ qₜ|₀(xₜ|x₀) # qₜ|₀ 定义在公式(7)
4: 计算 L = - (1/(t*L)) * Σ_{i=1}^{L} 1[xₜⁱ = M] log pθ(x₀ⁱ|xₜ) # L是x₀的序列长度
5: 计算 ∇θL 并运行优化器。
6: until 收敛
7: Return pθ
算法2 LLaDA的监督微调
需要: 掩码预测器 pθ, 配对数据分布 Pdata
1: repeat
2: p₀, r₀ ~ Pdata, t ~ U(0, 1] # SFT数据处理详情请参阅附录B.1
3: rₜ ~ qₜ|₀(rₜ|r₀) # qₜ|₀ 定义在公式(7)
4: 计算 L = - (1/(t*L’)) * Σ_{i=1}^{L’} 1[rₜⁱ = M] log pθ(r₀ⁱ|p₀, rₜ) # L’是r₀的序列长度
5: 计算 ∇θL 并运行优化器。
6: until 收敛
7: Return pθ
算法3 LLaDA的条件对数似然评估
需要: 掩码预测器 pθ, 提示 p₀, 响应 r₀, 蒙特卡洛估计次数 nmc
1: log_likelihood = 0
2: for i ← 1 to nmc do
3: l ~ {1, 2, …, L} # L是r₀的序列长度
4: 通过从r₀中无放回地均匀采样l个词元进行掩码得到rᵢ
5: log_likelihood = log_likelihood + (1/l) * Σ_{j=1}^{L} 1[rᵢʲ = M] log pθ(r₀ʲ|p₀, rᵢ)
6: end for
7: log_likelihood = log_likelihood / nmc
8: Return log_likelihood






string的模拟实现)
![学习笔记(24): 机器学习之数据预处理Pandas和转换成张量格式[2]](http://pic.xiahunao.cn/学习笔记(24): 机器学习之数据预处理Pandas和转换成张量格式[2])
)




)
![[概率论基本概念4]什么是无偏估计](http://pic.xiahunao.cn/[概率论基本概念4]什么是无偏估计)




