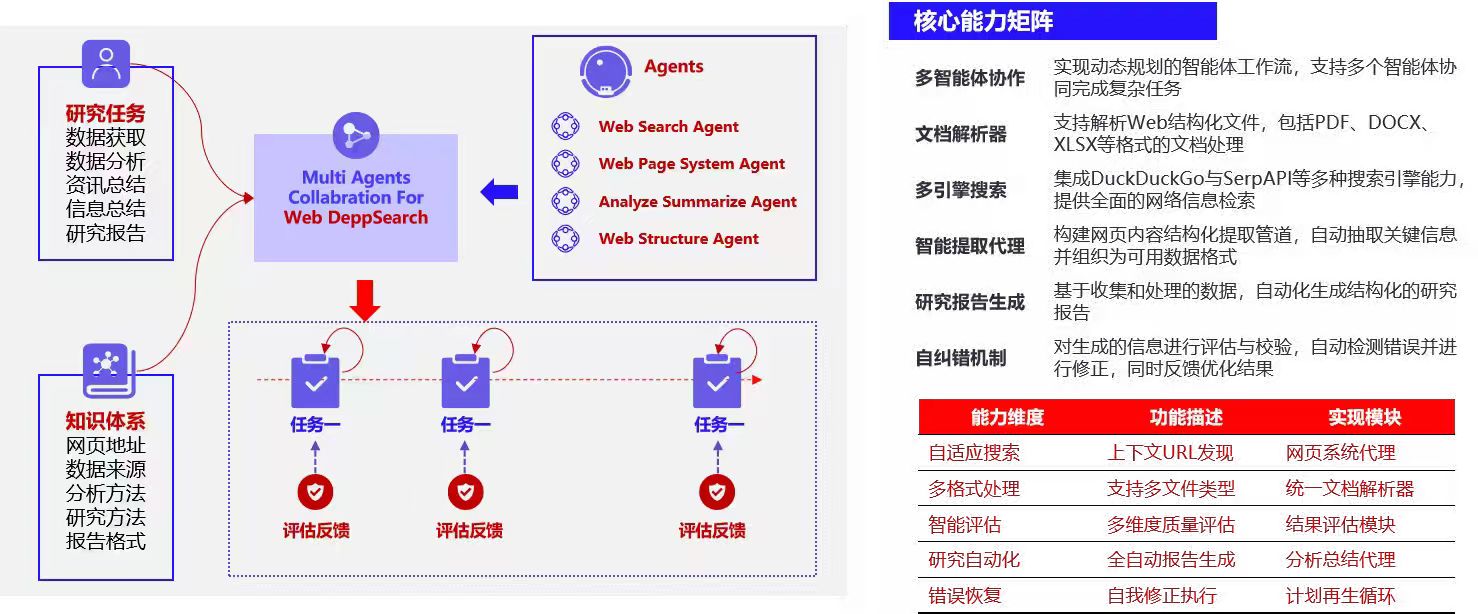
背景:多智能体协作驱动网络信息处理的范式革新
随着大型语言模型(LLM)能力的突破性进展,人工智能正从“单点赋能”向“系统协同”演进。传统单一智能体在复杂业务场景中逐渐显露局限:面对需多维度知识整合、动态任务拆解、闭环反馈优化的深度信息处理需求时,其往往难以满足效率与精度的双重诉求。尤其在金融分析、市场调研、学术研究等依赖多源数据融合的领域,人工主导的信息采集与分析流程存在效率低下、易出错、难扩展等问题,而现有工具链又缺乏对“搜索-解析-评估-总结”全流程的自动化闭环支持。
在此背景下,多智能体协作系统 (Multi-Agent System, MAS)成为突破瓶颈的关键路径。通过模拟团队协作模式,系统可将复杂任务拆解为子任务,由具备差异化能力的智能体并行或串行处理,最终通过知识融合与逻辑整合输出结果。然而,构建此类系统面临三大核心挑战:
- 高定制化门槛 :不同业务场景需定义差异化智能体角色、协作流程及知识库接入方式,传统开发模式周期长、成本高;
- 动态协作复杂度:如何实现智能体间任务路由、冲突消解与结果验证,需解决非线性交互带来的工程难题;
- 容错与自优化能力:面对网络波动、数据缺失、模型幻觉等干扰因素,系统需具备评估反馈与自动纠错机制。
针对上述痛点,我们推出Multi Agents Collaboration OS :Web DeepSearch System系统聚焦于信息检索与深度分析场景,通过多智能体动态协作架构 ,实现了从“人工信息筛选”到“自动化深度报告生成”的跨越式升级。其核心创新在于:
- 多智能体协作 实现动态规划的智能体工作流,支持多个智能体协同完成复杂任务
- 文档解析器 支持解析Web结构化文件,包括PDF、DOCX、XLSX等格式的文档处理
- 多引擎搜索 集成DuckDuckGo与SerpAPI等多种搜索引擎能力,提供全面的网络信息检索
- 智能提取代理 构建网页内容结构化提取管道,自动抽取关键信息并组织为可用数据格式
- 研究报告生成 基于收集和处理的数据,自动化生成结构化的研究报告
- 自纠错机制 对生成的信息进行评估与校验,自动检测错误并进行修正,同时反馈优化结果
核心模块与代码实践
- 智能体设计
- Web Search Agent :联网搜索获取与用户诉求相关的网页地址,集合serpapi、tavily_search、duck duckgo等联网搜索能力框架
# --- 联网搜索智能体 ---
def web_search(query, max_results=10):"""Perform web search using SerpAPI"""params = {"engine": "google","q": query,"api_key": "your api key", # Use environment variable"num": max_results # Explicitly request number of results}try:search = GoogleSearch(params)time.sleep(5)results_dict = search.get_dict() # Get full responsereturn [{"url": item.get("link"),"title": item.get("title"),"content": item.get("snippet")[:2000]}for item in results_dict.get("organic_results", [])if all([item.get("link"), item.get("title"), item.get("snippet")])][:max_results]except Exception as e:print(f"Search failed: {str(e)}")return []
from tavily import TavilyClientdef tavily_search(query, max_results=10):"""Perform a search using the Tavily API and return the results.Args:query (str): The search query.max_results (int): The maximum number of results to return.Returns:list: A list of dictionaries containing the search results."""# Initialize the Tavily clienttavily = TavilyClient(api_key="your API key")# Perform the searchresults = tavily.search(query=query, max_results=max_results)# Extract relevant information from the resultssearch_results = [{"url": result["url"],"title": result["title"],"content": result["content"]}for result in results["results"]]return search_results
#联网搜索智能体:根据用户的诉求获取网址
def search_duckduckgo(query, max_results=10, timelimit_='y'):"""Search DuckDuckGo with error handling."""try:with DDGS() as ddgs:results = ddgs.text(query, max_results=max_results, timelimit=timelimit_)time.sleep(5)return [result['href'] for result in results]except Exception as e:print(f"Search failed: {e}")return []- Web Page System Agent:网页页面操作,获取具体网页页面相关的二级甚至多级页面地址及信息,带自纠错机制
#网页操作自纠错及评估
def evaluate_page_relevance(html_content: str, user_request: str) -> bool:"""使用LLM判断页面内容是否包含与用户诉求相关的信息。返回True表示相关,False表示不相关。"""llm = ChatOpenAI(model=model_use, temperature=0.2)prompt = f"""你是一个网页内容分析助手。请根据以下HTML内容,判断该页面是否包含与用户诉求相关的信息。用户诉求为: "{user_request}"页面HTML内容如下:{html_content[:4000]} # 只取前4000字符防止超长请只回答"相关"或"不相关"。"""human_message = f"Evaluating relevance for the request: {user_request}"response = llm.invoke([("system", prompt), ("human", human_message)])answer = response.content.strip()return "相关" in answer
#网页系统智能体:自动判断页面是否包含用户诉求相关信息,若无则尝试翻页/搜索等操作,获取新的业务系统url
def webpage_system_agent(url_list: list, user_request: str, max_iterations: int = 5):"""处理多个URL的增强版本,保持原始输出格式不变"""final_results = []for target_url in url_list:if not target_url.startswith(('http://', 'https://')):print(f"⚠️ 无效URL格式已跳过: {target_url}")continueprint(f"\n🚀 处理初始URL: {target_url}")try:headers = {'User-Agent': 'MyGenericAgent/1.0 (LanguageModelBot; +http://mybot.example.com/info)'}response = requests.get(target_url, headers=headers, timeout=30)response.raise_for_status()current_url = response.urlhtml_content = response.textprint(f"\n🔄 从页面提取模块URL: {current_url}")# 原有提取逻辑保持不变llm = ChatOpenAI(model=model_use, temperature=0.2)prompt = f"""...""" # 保持原有prompt不变human_message = f"Extracting relevant module URLs for: {user_request}"response = llm.invoke([("system", prompt), ("human", human_message)])# 保持原有JSON解析逻辑json_str = response.content.replace("```json", "").replace("```", "").strip()try:result = json.loads(json_str)except Exception as e:print(f"JSON解析错误: {e}")result = {"urls": []}collected_urls = result.get("urls", [])print(f"🧠 提取到{len(collected_urls)}个相关URL")# 保持原有评估逻辑if evaluate_page_relevance(html_content, user_request):print(f"✅ 当前页面包含所需信息: {current_url}")final_results.append(current_url)continue# 保持原有迭代逻辑visited = set()for iteration in range(max_iterations):found = Falsefor url in collected_urls:abs_url = url if url.startswith("http") else urljoin(current_url, url)if abs_url in visited:continuevisited.add(abs_url)print(f"🔗 尝试访问模块页面: {abs_url}")try:response = requests.get(abs_url, headers=headers, timeout=30)response.raise_for_status()html = response.textif evaluate_page_relevance(html, user_request):print(f"✅ 找到相关页面: {abs_url}")final_results.append(abs_url)found = Truebreakexcept Exception as e:print(f"访问失败: {abs_url} - {str(e)}")if not found:print(f"第{iteration+1}轮未找到新页面")breakexcept Exception as e:print(f"处理URL {target_url} 时发生错误: {str(e)}")# 去重并保持原始输出格式return list(set(final_results)) if final_results else None
- Web Structure Agent:网页结构化信息提取,表格、文件、图片及网页文本内容
def fetch_html(url: str):import requeststry:headers = {'User-Agent': 'MyGenericAgent/1.0 (LanguageModelBot; +http://mybot.example.com/info)'}response = requests.get(url, headers=headers, timeout=30)response.raise_for_status()return response.textexcept Exception as e:print(f"Error fetching URL {url}: {e}")return Nonedef extract_text_content(html_content: str, url: str) -> str:"""从HTML中提取所有文本内容并保存到文件(支持中文)"""soup = BeautifulSoup(html_content, 'html.parser')# 移除脚本和样式标签for script_or_style in soup(["script", "style"]):script_or_style.decompose()# 获取文本,用换行符分隔,并去除多余空白text = soup.get_text(separator='\n', strip=True)# 文件名基于URL (简化版)time_ = datetime.now().strftime("%Y%m%d_%H%M%S")parsed_url = urlparse(url)filename = f"{parsed_url.netloc.replace('.', '_')}_{time_}_text.txt"filepath = OUTPUT_DIR / filenametry:with open(filepath, 'w', encoding='utf-8') as f: # 确保使用UTF-8编码f.write(text)return str(filepath.relative_to(pathlib.Path.cwd())) # 返回相对路径except IOError as e:print(f"Error saving text content to {filepath}: {e}")return Nonedef extract_image_urls(html_content: str, base_url: str) -> list:"""从HTML中提取所有图片的绝对URL"""soup = BeautifulSoup(html_content, 'html.parser')image_urls = []for img_tag in soup.find_all('img'):src = img_tag.get('src')if src:# 将相对URL转换为绝对URLabsolute_url = urljoin(base_url, src)image_urls.append(absolute_url)return list(set(image_urls)) # 去除重复项
def extract_file_links(html_content: str, base_url: str) -> list:"""提取PDF/Excel/Word/TXT等文件链接"""soup = BeautifulSoup(html_content, 'html.parser')file_links = []# 匹配常见文档格式的正则表达式pattern = re.compile(r'\.(pdf|xlsx?|docx?|txt)$', re.IGNORECASE)for tag in soup.find_all(['a', 'link']):href = tag.get('href')if href and pattern.search(href):absolute_url = urljoin(base_url, href)file_links.append(absolute_url)return list(set(file_links)) # 去除重复项
def extract_structured_data_tables(html_content: str, url: str) -> str:"""从HTML中提取所有表格数据,并保存为JSON文件。这是一个非常基础的表格提取示例。"""soup = BeautifulSoup(html_content, 'html.parser')tables_data = []for table_index, table_tag in enumerate(soup.find_all('table')):current_table_data = []headers = [header.get_text(strip=True) for header in table_tag.find_all('th')]for row_tag in table_tag.find_all('tr'):cells = row_tag.find_all(['td', 'th']) # 包括表头单元格以防万一if not cells:continuerow_data = [cell.get_text(strip=True) for cell in cells]# 如果表头存在且与行数据长度匹配,可以构造成字典列表if headers and len(headers) == len(row_data) and any(h for h in headers): # 确保表头不为空current_table_data.append(dict(zip(headers, row_data)))else: # 否则,作为列表存储current_table_data.append(row_data)if current_table_data:tables_data.append({"table_index": table_index,"data": current_table_data})if not tables_data:return None# 文件名基于URL (简化版)parsed_url = urlparse(url)time_ = datetime.now().strftime("%Y%m%d_%H%M%S")filename = f"{parsed_url.netloc.replace('.', '_')}_{time_}_structured_tables.json"filepath = OUTPUT_DIR / filenametry:with open(filepath, 'w', encoding='utf-8') as f:json.dump(tables_data, f, ensure_ascii=False, indent=4)return str(filepath.relative_to(pathlib.Path.cwd())) # 返回相对路径except IOError as e:print(f"Error saving structured data to {filepath}: {e}")return Noneexcept TypeError as e:print(f"Error serializing structured data for {url}: {e}")return Nonedef generate_consolidated_output_json(data_list: list):"""Generate a single JSON file consolidating metadata from all URLs."""time_ = datetime.now().strftime("%Y%m%d_%H%M%S")filename = f"{time_}_consolidated_metadata.json"filepath = OUTPUT_DIR / filenametry:with open(filepath, 'w', encoding='utf-8') as f:json.dump(data_list, f, ensure_ascii=False, indent=4)return str(filepath.relative_to(pathlib.Path.cwd()))except (IOError, TypeError) as e:print(f"Error saving consolidated metadata JSON: {e}")return None
#网页信息提取智能体:提取网页信息并生成元数据
# 该智能体负责提取网页信息,包括文本、图片、表格等,并生成元数据
def intelligent_agent(url_list: list):"""Intelligent agent function that integrates all modules to process multiple URLs:- Fetch HTML content via each URL- Extract text content (supports Chinese)- Extract image URLs- Extract structured data (tables)- Generate consolidated metadata JSON for all URLs"""consolidated_data = []for target_url in url_list:if not target_url.startswith(('http://', 'https://')):print(f"Invalid URL format: {target_url}. Skipping.")continueprint(f"Processing URL: {target_url}")html = fetch_html(target_url)if not html:print(f"Failed to fetch content for {target_url}.")continueprint("HTML content loaded successfully.")# Extract and save text contenttext_path = extract_text_content(html, target_url)print(f"Text content saved to: {text_path}" if text_path else "Text extraction failed.")# Extract image URLsimage_urls = extract_image_urls(html, target_url)print(f"Extracted {len(image_urls)} image URLs.")# Extract structured data (tables)structured_data_path = extract_structured_data_tables(html, target_url)print(f"Structured data saved to: {structured_data_path}" if structured_data_path else "Table extraction failed.")file_links = extract_file_links(html, target_url)print(f"Extracted {len(file_links)} file links.")# Append individual URL data to consolidated listconsolidated_data.append({"page_url": target_url,"text_content_file_path": text_path,"image_urls": image_urls,"structured_data_file_path": structured_data_path,"document_path": file_links,})# Generate consolidated output JSONfinal_json_path = generate_consolidated_output_json(consolidated_data)if final_json_path:print(f"Consolidated metadata JSON generated at: {final_json_path}")return final_json_pathelse:print("Failed to generate consolidated metadata JSON.")return None
- Analyze Summarize Agent:内容聚合与总结
## 分析及总结智能体:根据用户的问题进行网页信息分析及总结
def analyze_and_summarize(webpage_content_path: str, user_request: str):"""根据用户问题,对网页内容进行深度分析,并生成一份包含数据、图表等元素的深度研究报告。"""with open(webpage_content_path, 'r', encoding='utf-8') as f:webpage_content_list = json.load(f)# 获取网页表格内容if not isinstance(webpage_content_list, list):raise ValueError("Expected a list of webpage metadata dicts")aggregated_text = []aggregated_tables = []aggregated_images = set()aggregated_urls = []# Process each metadata dict in the listfor webpage_content in webpage_content_list:# 1. 获取网页文本内容text_content_info = Nonetext_content_path = webpage_content.get('text_content_file_path')if text_content_path:try:with open(text_content_path, 'r', encoding='utf-8') as f:text_content_info = f.read()aggregated_text.append(text_content_info)except Exception as e:print(f"❌ Failed to read text content from {text_content_path}: {e}")# 2. 获取网页表格数据table_data_info = Nonetable_data_path = webpage_content.get('structured_data_file_path')if table_data_path:try:with open(table_data_path, 'r', encoding='utf-8') as f:table_data_info = json.load(f)aggregated_tables.extend(table_data_info)except Exception as e:print(f"❌ Failed to read table data from {table_data_path}: {e}")# 3. 获取网页图片链接image_urls = webpage_content.get('image_urls', [])if image_urls:aggregated_images.update(url for url in image_urls if url.startswith(('http://', 'https://')))web_url = webpage_content.get('page_url')if web_url:aggregated_urls.append(web_url)# 合并所有文本内容document_path = webpage_content.get('document_path', [])# web_browser_auto_page.pyimport pathlib# 修改后的文档处理逻辑if document_path:for doc_path in document_path:try:if not pathlib.Path(doc_path).exists():print(f"文件不存在: {doc_path}")continuefile_content = FileParser.parse(doc_path)aggregated_text.append({"file_path": doc_path,"content": file_content[:10000] # 截取前5000字符防止过大})except Exception as e:print(f"文档解析失败 ({doc_path}): {str(e)}")aggregated_text.append({"file_path": doc_path,"error": str(e)})time.sleep(4) # 避免请求过快# 生成分析和总结的提示web_content_prompt = f"""网页链接是: {aggregated_urls}网页文本内容是: {aggregated_text}网页图片链接是: {aggregated_images}网页表格数据是: {aggregated_tables}请根据以上信息,分析并总结出与用户诉求相关的信息。"""llm = ChatOpenAI(model=model_use, temperature=0.2,max_tokens=118000)prompt = f"""你是一个网页内容分析助手。请根据以下HTML内容,分析并总结出与用户诉求相关的信息。用户诉求为: "{user_request}"页面HTML内容及图片、表格、文本等信息如下:{web_content_prompt[:50000]} 请生成一份包含数据、图表等元素的深度研究报告。报告要求:1.输出内容以markdown格式呈现,包含标题、段落、列表等结构。2.输出内容包括:研究背景、研究方法、研究结果、结论和建议等部分,其中背景部分200-500字;方法部分200-500字,方法部分需要输出数据来源,如网址、文件等;结果部分400-700字,对于数据需要使用表格形式输出,结论和建议部分200-500字。3.数据可视化:引用网页提供的合适的图表图片,以markdown语法嵌入图片,如:。4.输出内容应简洁明了,但是必须足够丰富,输出内容有极强的洞察,同时避免冗长的描述。【注意】你需要完整根据用户诉求和所有网页内容进行分析和总结,输出一份完整的深度研究报告。"""human_message = f"Analyzing and summarizing for the request: {user_request}"response = llm.invoke([("system", prompt), ("human", human_message)])return response.content.strip()
- 协作机制设计
-智能体信息聚合:#上述各类智能体信息集合:智能体名称,智能体详细描述信息(功能、角色、使用方式),参数,预期输入,预期输出。
agents_info = {"intelligent_agent": {"description": "网页信息提取智能体:提取网页信息并生成元数据","function": "负责提取网页信息,包括文本、图片、表格等,并生成元数据,输出网页元数据文件地址","parameters": {"url_list": {"type": "dict","description": "目标网页的URL list,格式为['https://example.com/page1', 'https://example.com/page2']"}}},"webpage_system_agent": {"description": "网页系统智能体:自动判断页面是否包含用户诉求相关信息,若无则尝试翻页/搜索等操作,获取新的业务系统url","function": "1.自动判断页面是否包含用户诉求相关信息,若无则尝试翻页/搜索等操作,获取新的业务系统url;2.可以深度研究用户网页系统,提取相关模块URL","parameters": {"url_list": {"type": "list","description": "目标网页的URL list,格式为['https://example.com/page1', 'https://example.com/page2']"},"user_request": {"type": "string","description": "用户的请求"},"max_iterations": {"type": "integer","description": "最大迭代次数"}}},"analyze_and_summarize": {"description": "分析及总结智能体:根据用户的问题进行网页信息分析及总结","function": "根据用户问题,处理网页元数据信息,根据元信息对网页内容进行深度分析,并生成一份包含数据、图表等元素的深度研究报告","parameters": {"webpage_content_path": {"type": "string","description": "网页元数据文件地址,数据的文件地址,如xxx_metadata.json"},"user_request": {"type": "string","description": "用户的请求"}}},"web_search": {"description": "联网搜索智能体:根据用户的诉求获取网址列表","function": "负责联网搜索,根据用户的诉求获取相关网页的URL列表","parameters": {"target_url": {"type": "string","description": "目标网页的URL"}}}
}
- 智能体参数设计及聚合
#只抽取智能体的参数
agent_parameters_info = {"intelligent_agent": {"url_list": {"type": "list","description": "目标网页的URL list,格式为['https://example.com/page1', 'https://example.com/page2']"},},"webpage_system_agent": {"url_list": {"type": "list","description": "目标网页的URL list,格式为['https://example.com/page1', 'https://example.com/page2']"},"user_request": {"type": "string","description": "用户的请求" }, },"analyze_and_summarize": {"webpage_content_path": {"type": "string","description": "基础网页源信息文件地址,网页列表元数据文件地址,如xxx_metadata.json"},"user_request": {"type": "string","description": "用户的请求"}},"web_search": {"query": {"type": "string","description": "用户输入的查询"},"max_results": {"type": "integer","description": "最大结果数"}},
}
- 智能体协作机制设计
– 智能体参数生成
##定义一个智能体信息共享路由:根据用户的问题获取智能体的输入参数
def get_agent_parameters(user_prompt: str,last_agent_response=None,agents_info=agent_parameters_info):llm = ChatOpenAI(model=model_use, temperature=0.2)message = f"""你是一个智能体信息共享助手。根据用户的问题,获取智能体的输入参数。用户问题为: "{user_prompt}"智能体信息为: {agents_info}前一个智能体的输出为: {last_agent_response}请根据用户问题,获取智能体的输入参数。[警告]请不要杜撰智能体参数信息,根据各个智能体的输出,准确的完整的输出各个智能体的输入参数。【建议】涉及到网址搜索的,最大搜索结果数至少为10个。你应该输出一个JSON对象,包含智能体的名称和输入参数。输出的信息格式如下:'''json{{"<agent_name>": {{"target_url": "https://example.com"}},.....}}'''"""human_message = f"根据用户问题,获取智能体的输入参数: {user_prompt}"response = llm.invoke([("system", message), ("human", human_message)])json_str = response.content.replace("```json", "").replace("```", "").strip()try:result = json.loads(json_str)except Exception as e:print(f"❌ JSON parse error: {e}")result = {"agent_name": None, "input_parameters": {}}return result– 多智能体协作机制
#定义一个多智能体协作机制设计和输出的模块:输出多智能体协作的方案,包括步骤信息,各步骤选择的智能体及其任务,各个步骤的预期输出
def multi_agent_cooperation(user_request: str,agents_info=agents_info,feedback=None,uesr_initial_url=None):llm = ChatOpenAI(model=model_use, temperature=0.2)uesr_initial_prompt = None#解析初始网页内容:if uesr_initial_url:uesr_initial_prompt = fetch_html(uesr_initial_url)message = f"""你是一个多智能体协作助手。根据用户问题,选择合适的智能体进行任务处理。用户问题为: "{user_request}"智能体信息为: {agents_info}。【警告】你只能使用上述智能体,不可以添加新的智能体。用户提供的初始网址信息: {uesr_initial_prompt if uesr_initial_prompt else "无"}可以提供的历史任务输出反馈信息为: {feedback if feedback else "无"}请判断用户问题与用户提供的初始网址信息的关联性。请根据用户问题,选择合适的智能体进行任务处理。首先评估初始网页系统是否满足用户需求,如果不满足,使用智能体 webpage_system_agent 进行页面信息提取和评估。如果智能体历史执行结果没有输出用户的诉求相关信息,则需要重新设计智能体协作策略,尝试使用 webpage_system_agent 进行页面信息提取和评估,获取更多的网页地址。业务场景及智能体协作方案:[注意]如果用户的初始诉求未提供网址信息,则需要使用智能体 web_search 进行联网搜索,获取相关网页的URL列表。(一)场景一:确定的业务场景,用户需要提取网页信息并生成元数据。1.用户提供的url与用户的问题强关联,不需要评估是否需要对页面进行翻页/搜索等操作。2.只需要使用智能体 intelligent_agent 进行网页信息提取。3.根据提取的网页信息,使用智能体 analyze_and_summarize 生成一份包含数据、图表等元素的深度研究报告。(二)场景二:1.用户提供的url与用户的问题弱关联,可能需要对页面进行翻页/搜索等操作。2.使用智能体 webpage_system_agent 进行页面信息提取和评估,获取新的网页信息及url。3.循环迭代使用智能体 intelligent_agent 进行上述获取的网页地址网页信息提取,直到获取到完整信息。4.根据提取的网页信息,使用智能体 analyze_and_summarize 生成一份包含数据、图表等元素的深度研究报告。(三)场景三:1.协作方案可能会有调整,请根据上一次协作方案执行情况,动态调整智能体协作策略。2.协作方案执行历史中有些内容可以使用,请根据用户诉求、协作方案执行评估情况、协作历史信息,动态调整智能体协作策略。【注意】多智能体协作过程中可能会有报错信息,这意味着网页信息提取不完整或无法获取到用户诉求相关信息,需要重新设计智能体协作策略。你应该输出一个JSON对象,包含多智能体协作的方案,包括步骤信息,各步骤选择的智能体及其任务,各个步骤的预期输出。输出的信息格式如下:'''json{{"steps": [{{"step_name": "步骤1","step_description": "描述步骤1的功能","agent_name": "intelligent_agent",}},...],"task_name":"<总结一个任务名称,如:金融市场分析>",}}'''"""human_message = f"根据用户问题,选择合适的智能体进行任务处理: {user_request}"response = llm.invoke([("system", message), ("human", human_message)])json_str = response.content.replace("```json", "").replace("```", "").strip()try:result = json.loads(json_str)except Exception as e:print(f"❌ JSON parse error: {e}")result = {"steps": []}return result
- 评估与反馈机制设计
- 智能体输出结果反馈及自纠错
#结果评估及反馈模块:根据智能体的输出结果,评估结果是否符合预期,并给出反馈
def evaluate_and_feedback(agent_output, user_request):llm = ChatOpenAI(model=model_use, temperature=0.2)message = f"""你是一位资深的智能体输出评估与反馈专家。你的任务是基于用户请求和智能体的输出来进行严谨、细致的评估,并提供有建设性的反馈。**评估标准:*请综合考虑以下方面对智能体的输出进行评估:1. **相关性 (Relevance):** 输出是否直接回应了用户的请求?是否跑题?2. **准确性 (Accuracy):** 输出中的信息是否事实正确?是否存在误导性内容?3. **完整性 (Completeness):** 输出是否完整地回答了用户问题的所有方面?是否遗漏了关键信息?4. **清晰度 (Clarity):** 输出是否易于理解?语言是否表达清晰、简洁?5. **帮助性 (Helpfulness):** 输出是否真正帮助用户解决了问题或满足了其需求?6. **安全性与恰当性 (Safety & Appropriateness):** 输出是否包含不当、冒犯、有害或偏见内容?(如果适用)7. **遵循指令 (Instruction Following):** 如果用户请求中包含特定格式、角色或其他指令,智能体是否遵循了这些指令?8. **内容评估**:核心诉求满足即可,对网址、文档、图表、数据等并非一定需要的,需要根据用户的诉求进行评估。根据智能体的输出结果,评估结果是否符合预期,并给出反馈。智能体输出结果为: "{agent_output}"用户问题为: "{user_request}"请根据智能体的输出结果,评估结果是否符合预期,并给出反馈。【注意】请完整准确的评估智能体的输出是否符合用户诉求,对要求输出数据、网址、文件、结果等格外关注,保证输出的准确性。【警告】你不能杜撰智能体的输出结果,你只能根据智能体的输出结果进行评估和反馈。你应该输出一个JSON对象,包含评估结果和反馈信息。输出的信息格式如下:'''json{{"evaluation": "符合预期"、"不符合预期"或"基本符合预期","feedback": "具体的反馈信息""last_dialog_summary": "上一次对话的总结信息"}}'''"""human_message = f"根据智能体的输出结果,评估结果是否符合预期,并给出反馈。"response = llm.invoke([("system", message), ("human", human_message)])json_str = response.content.replace("```json", "").replace("```", "").strip()result = json.loads(json_str)return result
- ***对话历史总结:***多轮对话历史
##历史对话总结智能体
def summarize_last_dialog(user_request: str, last_agent_response: str):message = [("system","你是一个历史对话总结智能体,你需要根据用户的输入和智能体的输出,总结用户的对话内容。""请注意,你需要根据用户的输入和智能体的输出,准确的总结用户的对话内容。""1.重点关注智能体应对用户问题的回答情况。""2.请勿重复输出用户输入。""3.对生成的网址、文件地址等重点关注,需要准确的总结。""4.整体内容输出不超过500字。"),("human",f"用户输入:{user_request},智能体输出:{last_agent_response}")]llm = ChatOpenAI(model=model_use, temperature=0.2)response = llm.invoke(message)return response.content
- ***智能体输出 优化:***使其符合人类阅读习惯
#结果输出整理:对智能体的输出结果进行整理,生成符合用户需求和人类阅读偏好的内容
def organize_agent_output(agent_output: str, user_request: str):message = [("system","你是一个结果输出整理智能体,你需要根据智能体的输出结果,生成符合用户需求和人类阅读偏好的内容。""请注意,你需要根据智能体的输出结果,准确的生成符合用户需求和人类阅读偏好的内容。""1.重点关注智能体应对用户问题的回答情况。""2.关注智能体的解决方案,输出核心内容:网址、文件、信息等。""3.对生成的网址、文件地址等重点关注,需要准确的生成。""4.数据和核心数据需要使用表格形式展示。""5.内容使用markdown格式,核心内容加粗,图片使用markdown语法嵌入图片,如:。""6.如果需要输出“深度研究报告”,请参考输出内容包括:研究背景、研究方法、研究结果、结论和建议等部分,其中背景部分200-500字;方法部分200-500字,方法部分需要输出数据来源,如网址、文件等;结果部分1000-2000字,对于数据需要使用表格形式输出,结论和建议部分200-500字,""7.[注意]智能体没有输出的内容不要生成,禁止你自己发挥。"),("human",f"用户输入:{user_request},智能体输出:{agent_output}")]llm = ChatOpenAI(model=model_use, temperature=0.2)response = llm.invoke(message)return response.content
- 用户系统
def recognize_speech():recognizer = sr.Recognizer()with sr.Microphone() as source:# 使用 empty 占位符来动态更新状态status_placeholder = st.empty()status_placeholder.info("🎤 正在聆听,请说话...")try:audio = recognizer.listen(source, timeout=3) # 设置超时时间text = recognizer.recognize_google(audio, language="zh-CN") # 支持中文识别status_placeholder.success(f"✅ 语音识别已完成:{text}")return textexcept sr.WaitTimeoutError:status_placeholder.warning("⚠️ 您没有说话或麦克风未检测到输入。")return Noneexcept sr.UnknownValueError:status_placeholder.error("❌ 无法理解音频")return Noneexcept sr.RequestError as e:status_placeholder.error(f"❌ 请求错误: {e}")return Nonedef process_input(prompt):# 初始化 session_state.messagesif "webmessages" not in st.session_state:st.session_state.webmessages = []#历史对话信息if "webhistory" not in st.session_state:st.session_state.webhistory = Noneif "voice_input" not in st.session_state:st.session_state.voice_input = Nonefor webmessages in st.session_state.webmessages:if webmessages["role"] == "user":with st.chat_message("user"):st.markdown(webmessages["content"])elif webmessages["role"] == "assistant":with st.chat_message("assistant"):st.markdown(webmessages["content"])agents_response_history = None# 假设你的视频文件名为 my_video.mp4 并且在与你的 Streamlit 脚本相同的目录下if prompt :st.session_state.webmessages.append({"role": "user", "content": prompt})st.chat_message("user").markdown(prompt)prompt = f"用户问题: {prompt}\n\n,历史对话信息: {st.session_state.webhistory if st.session_state.webhistory else '无'}"with st.spinner('正在思考(Thinking)...'):with st.expander("智能体协作方案设计", expanded=True):multi_agent_plan = multi_agent_cooperation(prompt, agents_info=agents_info, feedback=st.session_state.webhistory) st.write("### 智能体协作方案:")st.json(multi_agent_plan)agent_response = Nonelast_error = Nonemax_retries = 10retries = 0retry_count = 0success = Falsesuccess = Falsemax_evaluation_retries = 10 # Separate counter for evaluation retrieswhile retries < max_retries and retry_count < max_evaluation_retries and not success:try:# Reset plan for each retrycurrent_plan = multi_agent_plan["steps"].copy()for step in current_plan:agent_name = step["agent_name"]# Get parameters with history contextagent_parameters = get_agent_parameters(str(step), agent_response)# Execute agentagent_response = agent_functions[agent_name](**agent_parameters.get(agent_name, {}))# Process and display responseagent_response_ = organize_agent_output(agent_response, str(step))agents_response_history = summarize_last_dialog(str(step), agent_response_)with st.expander(f"智能体 {agent_name} 输出结果", expanded=True):st.chat_message("assistant").markdown(f"##### 智能体{agent_name}输出结果:\n{agent_response_}")# Evaluate resultsevaluation_result = evaluate_and_feedback(agent_response, str(step))if evaluation_result["evaluation"] == "不符合预期":st.warning(f"⚠ 评估未通过: {evaluation_result['feedback']}")# Generate new plan with feedbackmulti_agent_plan = multi_agent_cooperation(prompt + f"\n评估反馈: {evaluation_result},最新智能体输出: {agents_response_history}")retry_count += 1break # Exit current plan executionelse:st.success("✅ 评估通过")st.session_state.webmessages.append({"role": "assistant", "content": agent_response})else: # Only executed if all steps completed successfullysuccess = Trueexcept Exception as e:error_msg = f"执行异常: {str(e)}"st.error(error_msg)last_error = error_msg# Generate new plan with error contextmulti_agent_plan = multi_agent_cooperation(prompt + f"\n执行错误: {last_error}")retries += 1if not success:st.error("❌ 达到最大重试次数仍未完成请求")if st.session_state.webmessages: history_summary = summarize_last_dialog(prompt,str(st.session_state.webmessages[:-5]))##最后的对话信息st.session_state.messages[:-1]保存为markdown格式文件:地址为 output_data/deep_search/__deep_search.md#判断文件是否存在,不存在则创建if not os.path.exists("output_data/deep_search"):os.makedirs("output_data/deep_search")##设计一个文件名称,需要包含任务情况特色try:deep_search_file_name = f"{multi_agent_plan['task_name']}__deep_search.md" deep_search_file_path = os.path.join("output_data/deep_search", deep_search_file_name)with open(deep_search_file_path, "w") as f:f.write(st.session_state.webmessages[-1]['content'])#提供一个下载按钮,可以下载markdown文件st.download_button(label="下载深度研究报告",data=open(deep_search_file_path, "rb").read(),file_name=deep_search_file_name,mime="text/markdown")except Exception as e:st.error(f"保存文件时出错: {str(e)}")st.session_state.webhistory = history_summarydef web_browser_auto_page():# Initialize voice input in session stateif 'voice_input' not in st.session_state:st.session_state.voice_input = ""with st.sidebar:if st.button("🎤 语音输入"):user_input = recognize_speech()if user_input:st.session_state.voice_input = user_inputst.rerun()st.title("🌍 Web Infomation DeepSearch")st.write("🗽该助手可以自动提取网页信息,包括文本、图片、表格等,并生成一份包含数据、图表等元素的深度研究报告。")with st.sidebar:if st.button("🗑️ Clear Chat History"):st.session_state.webmessages = []st.session_state.webhistory = Nonest.rerun() st.markdown("""<style>.main {background-color: #f8f9fa;padding: 20px;border-radius: 10px;}.welcome-message {font-size: 1.2em;color: #1f2937;line-height: 1.6;}.feature-bullet {color: #0066cc;font-weight: bold;}.example-box {background-color: #e0f2ff;padding: 15px;border-radius: 8px;margin: 10px 0;}.assistant-chat-message {float: left;background-color: #f1f8e9;border-radius: 20px;padding: 10px 15px;margin: 10px 0;max-width: 70%;} </style>""", unsafe_allow_html=True)# 显示平台LOGO# 欢迎消息与功能指引st.markdown("""<div class="welcome-message">🌟 欢迎使用**网页信息提取助手**!我可以帮您完成以下任务:<ul><li class="feature-bullet">🔗 联网搜索获取目标网页</li><li class="feature-bullet">📄 提取网页文本/图片/表格</li><li class="feature-bullet">📊 生成深度数据分析报告</li><li class="feature-bullet">🔍 智能评估结果相关性</li></ul>🔍 <strong>使用建议:</strong><div class="example-box">示例问题:<br>"获取5月生猪市场价格数据,并生成分析报告"<br>"从[中指云](https://www.cih-index.com/),分析房地产市场趋势,生成房市深度研究报告"<br>"提取指定网页的表格信息:https://zhujia.zhuwang.com.cn/indexov.shtml"</div>请直接输入您的需求,我将为您智能规划执行方案。</div>""", unsafe_allow_html=True)# Handle voice input after normal chat inputif st.session_state.voice_input:prompt = st.session_state.voice_inputst.session_state.voice_input = "" # Clear after useprocess_input(prompt)# Regular chat inputif prompt := st.chat_input("欢迎使用网页信息提取助手!请问有什么可以帮助您的吗?"):process_input(prompt)
Multi Agents Collaboration OS:Web DeepSearch System —>Demo
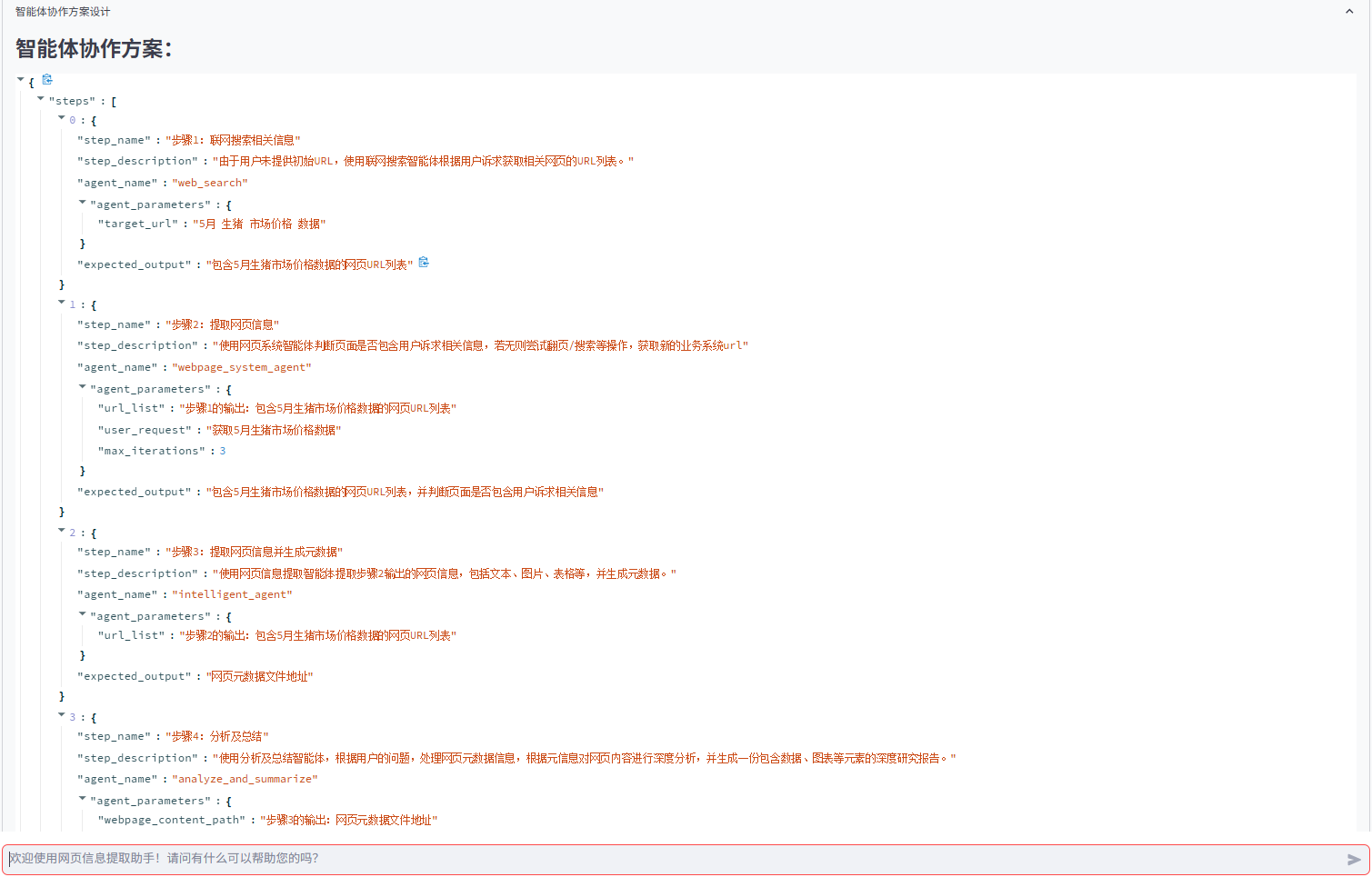
- 任务一:获取5月生猪市场价格数据,并生成分析报告 <——无具体网址信息
-
协作方案生成
-
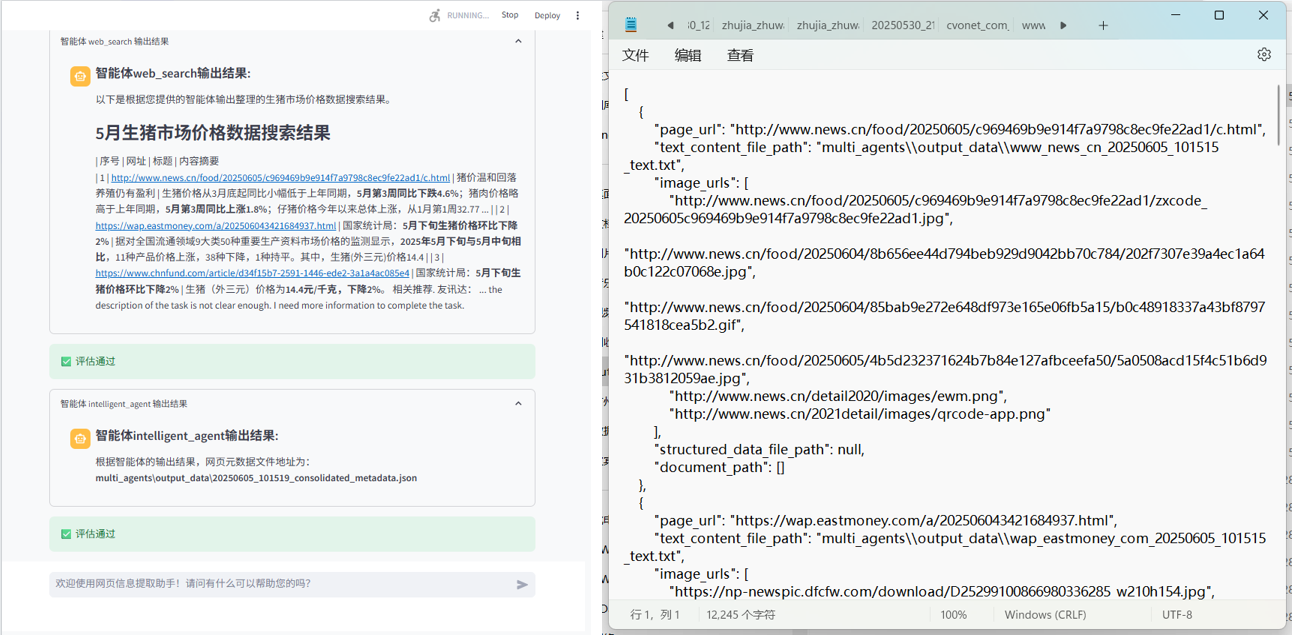
执行与结果
-
联网搜索网址结果以及结构化信息提起
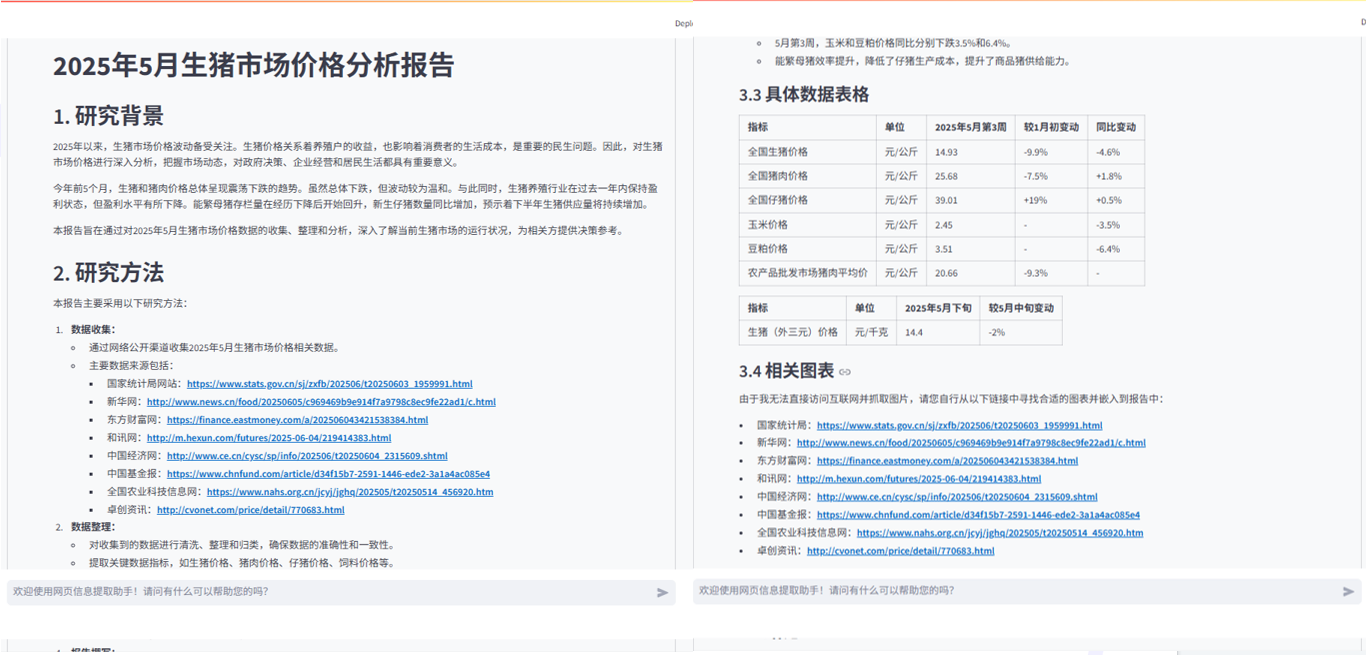
-
最终研究报告生成
- 任务二:从中指云 https://www.cih-index.com/),分析房地产市场趋势,生成房市深度研究报告 <——有具体网址信息
- 智能体协作方案
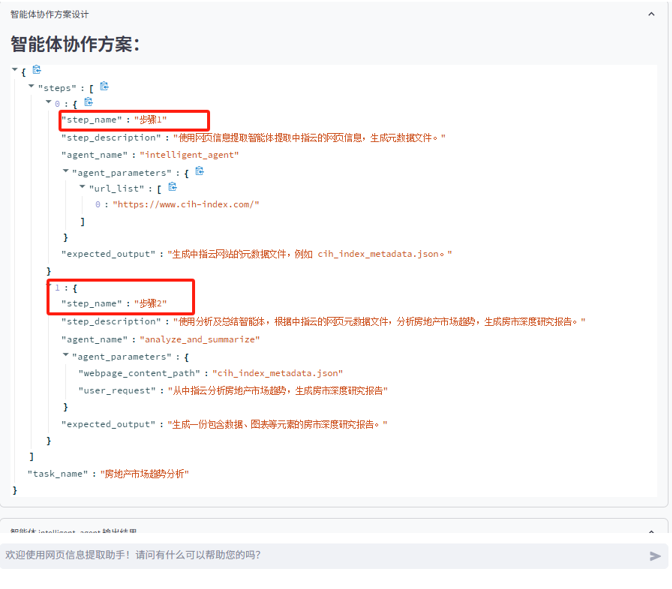
- 智能体执行结果
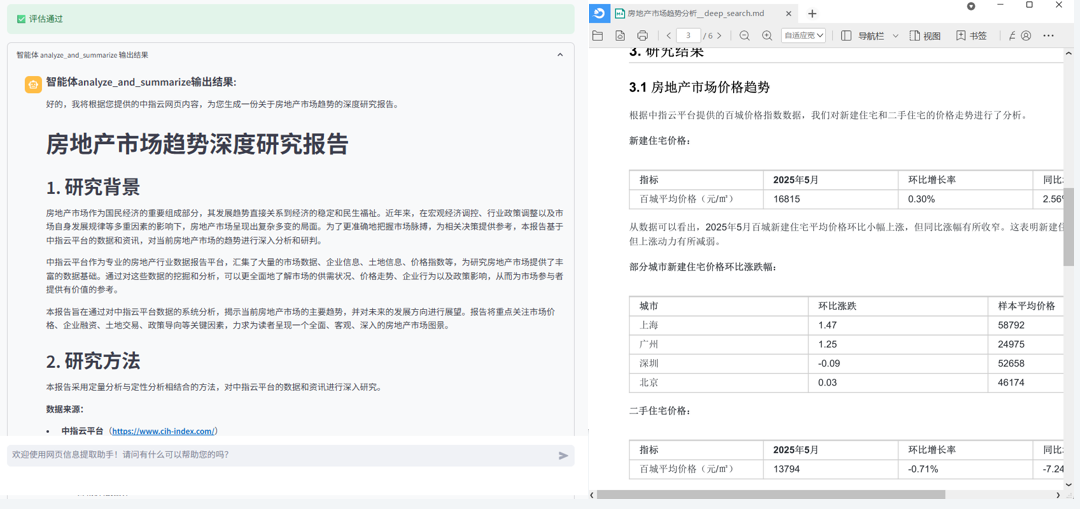
- 深度研究报告生成
总结:Web DeepSearch System
现存问题分析
1. 联网搜索质量优化
当前系统通过 web_search 和 search_duckduckgo 实现多引擎搜索,但搜索结果质量受限于API返回数据的结构化程度。代码中虽采用结果过滤机制(extract_webpage_info),但缺乏智能排序算法和可信度评估模块。建议引入BERT重排序技术,结合网页PageRank值和内容质量评估模型(如 evaluate_page_relevance 的增强版),在保证成本可控的前提下提升优质结果的召回率。
2. 专业报告生成质量
analyze_and_summarize 函数采用单一LLM生成模式,对专业领域知识的处理存在局限性。代码中 prompt 设计未充分融入领域术语和结构化模版,导致生成内容学术性不足。可扩展为分层生成架构:先由 FileParser 提取结构化数据,再通过RAG模式调用领域知识库,最后采用CoT思维链生成技术报告,提升专业术语使用准确性和分析深度。
3. 迭代生成成本控制
webpage_system_agent 的5轮迭代机制导致API调用次数线性增长。代码中 max_iterations 采用固定阈值,缺乏动态终止策略。建议引入成本感知模块,在 multi_agent_cooperation 中集成执行轨迹分析,当连续3轮评估分数(evaluate_and_feedback)提升小于10%时自动终止迭代,同时优化Playwright实例的复用率(async_playwright 上下文管理)。
系统扩展方向
1. 网页操作自动化增强
基于现有 fetch_html_async 的Playwright能力,可扩展实现:
- 表单智能填充(
page.type+ CSS选择器语义映射) - 分页导航(
page.click+ DOM树结构分析) - 动态数据捕获(
page.wait_for_selector+ XPath模式库)
建立网页操作DSL描述语言,将agent_parameters_info扩展为可配置的操作指令集。
2. 智能体能力矩阵构建
在 agents_info 体系内集成:
- 数据分析智能体:对接
extract_structured_data_tables输出,扩展PandasAI交互接口 - 可视化智能体:基于
aggregated_images实现Altair/Vega-Lite自动图表生成 - 看板组装智能体:通过
organize_agent_output增强Markdown组件化输出能力
构建智能体间数据流管道,通过generate_consolidated_output_json实现中间结果标准化交换。
3. 垂直场景深度适配
扩展 multi_agent_cooperation 的任务模版库:
- 金融领域:集成巨潮资讯/东方财富数据规范,预置PE Ratio分析工作流
- 电商领域:构建价格监控模版(
web_urls_process_query+ 历史价格曲线分析) - 学术领域:连接CrossRef API,实现文献综述自动生成链路
通过领域特征注入(model config.json)和评估标准定制化(evaluate_and_feedback规则引擎),提升场景化任务的完成度。

![[arthas]arthas安装使用](http://pic.xiahunao.cn/[arthas]arthas安装使用)

![[论文阅读] 软件工程 | 量子计算如何赋能软件工程(Quantum-Based Software Engineering)](http://pic.xiahunao.cn/[论文阅读] 软件工程 | 量子计算如何赋能软件工程(Quantum-Based Software Engineering))








)



与常用操作系统操作指南)


