Kafka 介绍
想象一下你正在运营一个大型电商平台,每秒都有成千上万的用户浏览商品、下单、支付,同时后台系统还在记录用户行为、更新库存、处理物流信息。这些海量、持续产生的数据就像奔腾不息的河流,你需要一个强大、可靠且实时的系统来接收、存储并处理这些数据洪流,让不同的业务部门(比如实时推荐、库存管理、风险控制、用户行为分析)都能及时获取他们需要的信息。这就是Apache Kafka大展拳脚的舞台。
本质上,Kafka是一个开源的、分布式的流处理平台。它最核心的能力是作为一个高吞吐量、低延迟、可水平扩展且持久化的发布-订阅消息系统。你可以把它想象成一个超级高效、永不丢失的“消息管道”或“数据中枢”。它的设计哲学就是处理源源不断产生的实时数据流(Data Streams)。
我们看几个具体的例子:
-
构建实时数据管道和流处理: 这是Kafka的看家本领。比如在金融行业,一家证券交易所需要实时处理每秒产生的巨量股票交易订单数据。Kafka作为核心枢纽,可靠地接收来自各个交易终端发来的订单消息,持久化存储它们。然后,风控系统可以实时订阅这些数据流,毫秒级地检测异常交易模式防止欺诈;交易撮合引擎订阅数据进行实时匹配;同时,另一个消费者可能将这些数据实时推送到数据仓库或Hadoop集群,供分析师进行更深入的历史趋势研究。所有系统都通过Kafka这个统一、可靠的管道获取实时数据,避免了复杂的点对点集成。
-
网站活动追踪和日志聚合: 想象一下像滴滴这样的大型应用。每当乘客打开APP、搜索地点、呼叫车辆、司机接单、车辆移动、行程结束、支付完成,每一步都会产生一条事件日志。这些日志数量巨大且分散在各个服务器上。Kafka提供了一个中心化的地方,让所有服务器都可以轻松地将这些活动事件(比如“用户A在时间T点击了按钮B”)作为消息发布到特定的主题(Topics)里。下游的各种系统可以按需订阅:实时监控系统订阅这些流来监控APP的实时健康状态和用户行为漏斗;用户画像系统订阅来更新用户的实时偏好和行为轨迹;安全团队订阅来实时检测可疑活动(如异常频繁的登录尝试)。同时,这些日志也可以被消费到像Elasticsearch这样的系统中提供快速的搜索和可视化,或者到HDFS做长期存储和离线分析。Kafka高效地统一了日志收集的入口。
-
物联网数据集成: 在智能工厂或智慧城市项目中,成千上万的传感器(温度、湿度、压力、位置、摄像头图像元数据等)每时每刻都在产生数据。这些传感器设备(或边缘网关)将采集到的数据发送到Kafka。Kafka凭借其高吞吐量和分布式特性,轻松承接这些海量、高速的传感器数据流。实时监控中心订阅这些数据流,可以立刻在大屏上展示工厂设备的运行状态或城市的交通流量;预测性维护系统分析设备传感器数据流,实时判断机器是否可能出现故障;数据湖则消费这些数据,存储起来供后续训练AI模型优化生产流程或城市规划。
-
解耦微服务通信: 在一个由许多小型、独立服务(微服务)构成的现代应用架构中,服务之间需要通信。Kafka可以作为它们之间的可靠“缓冲带”或“通信总线”。例如,在一个电商系统中,“订单服务”处理完一个新订单后,它不需要直接调用“库存服务”、“支付服务”和“物流服务”,而是简单地将一条“新订单创建”的消息发布到Kafka的一个主题里。各个相关的服务(库存扣减、支付处理、物流调度)都独立地订阅这个主题。这样,“订单服务”只需要快速把消息发出去就完成任务了,不用等待或关心下游服务何时处理、是否成功(下游服务自己保证消费可靠性),大大提高了系统的整体响应速度、可扩展性和容错性。即使某个下游服务(如物流服务)暂时宕机,消息也会安全地保存在Kafka中,等它恢复后继续处理。
-
事件溯源和变更数据捕获: 在一些需要精确记录状态变化历史的系统中(如银行核心系统、审计系统),Kafka可以用来存储所有导致状态变化的事件序列。例如,一个银行账户的每次存款、取款、转账操作都被记录为一个不可变的事件,发布到Kafka。通过重放这些事件流,可以精确地重建账户在任何历史时刻的状态,提供了强大的审计追踪能力。同时,数据库的变更(CDC - Change Data Capture)也可以通过工具捕获(如读取数据库的binlog),转换成事件流发布到Kafka,让其他系统能够近乎实时地感知到数据库的变动。
总结来说,Kafka的核心价值在于它能够:
-
可靠地处理海量实时数据流:像一个永不堵塞的高速公路。
-
持久化存储数据流:数据可以保留很长时间(几天、几周甚至几个月),允许不同的消费者按自己的节奏重放历史数据。
-
连接不同的系统和应用:作为统一、可靠的数据中枢,简化系统架构,实现松耦合。
-
支撑实时处理和分析:为需要即时响应的业务场景(监控、风控、推荐、告警)提供实时数据源。
Kafka角色和流程
Kafka角色
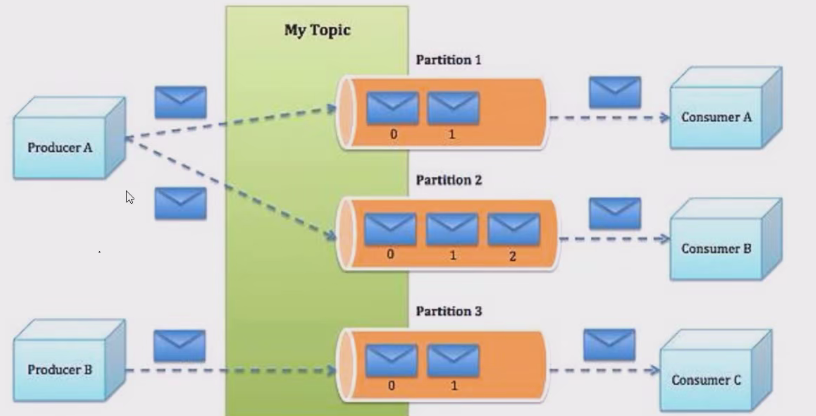
-
Producer: Producer即生产者,消息的产生者,是消息的入口。负责发布消息到Kafka broker。
-
Consumer: 消费者,用于消费消息,即处理消息
-
Broker:Broker是kafka实例,每个服务器上可以有一个或多个kafka的实例,假设每个broker对应一台服务器,每个kafka集群内的broker都有一个不重复的编号,如: broker-0, broker-1等……
-
Topic: 消息的主题,可以理解为消息的分类,相当于Redis的Key和ES中的索引,kafka的数据就保存在Topic,在每个broker上都可以创建多个Topic,物理上不同 topic 的消息分开存储在不同的文件夹,逻辑上一个 topic的消息虽然保存于一个或多个broker 上,但用户只需指定消息的Topic即可生成声明数据而不必关心数据存于何处。Topic 在逻辑上对record记录、日志进行分组保存,消费者需要订阅相应的Topic才能满足Topic中的消息。
-
Consumer group: 每个consumer 属于一个特定的consumer group(可为每个consumer 指定 group name,若不指定 group name 则属于默认的group),同一topic的一条消息只能被同一个consumer group 内的一个consumer 请求,类似于一对一的单播机制,但多个consumer group 可同时请求这一消息,类似于一对多的多播机制
-
Partition:是物理上的概念,每个topic 分别为一个或多个partition,即一个topic划分为多份创建 topic的可指定 partition 数量。partition的表现形式就是一个一个的文件夹,该文件夹下存储该partition的数据和索引文件,分区的作用还可以实现负载均衡,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,一般Partition数不要超过节点数。注意同一个partition数据是有顺序的,但不同partition则是无序的。
-
Replication: 同样数据的副本,包括leader和follower的副本数基本于数据安全,建议至少2个,是Kafka的高可靠性的保障。和ES的副本有所不同,Kafka中的副本数包括主分片数,而ES中的副本数不包括主分片数
-
AR:Assigned Replicas,分区中的所有副本的统称,包括leader和 follower。AR= ISR+ OSR
-
ISR:In Sync Replicas,所有与leader副本保持同步的副本 follower和leader本身组成的集合,包括leader和 follower,是AR的子集
-
OSR:out-of-Sync Replied,所有与leader副本同步不能同步的 follower的集合,是AR的子集
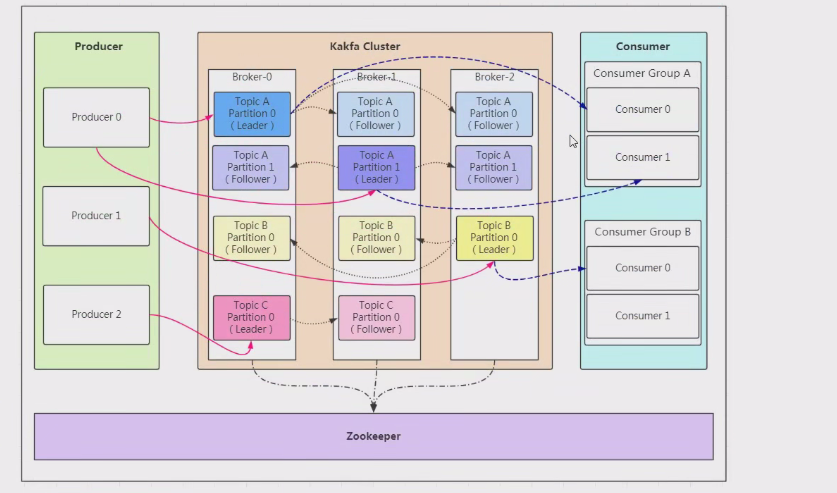
Kafka写入消息流程
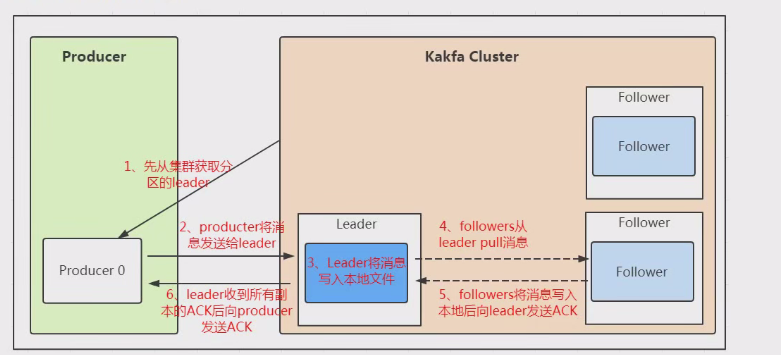
Kafka 配置文件说明
配置文件说明# 配置文件 ./conf/server.properties 内部说明******** Server Basics ********# broker 的 id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=1******** Socket Server Settings ********# kafka 监听端口,默认 9092
listeners=PLAINTEXT://10.0.0.101:9092# 处理网络请求的线程数量,默认为 3 个
num.network.threads=3# 执行磁盘 IO 操作的线程数量,默认为 8 个
num.io.threads=8# socket 服务发送数据的缓冲区大小,默认 100kB
socket.send.buffer.bytes=102400# socket 服务接受数据的缓冲区大小,默认 100kB
socket.receive.buffer.bytes=102400# socket 服务所能接受的一个请求的最大大小,默认为 100M
socket.request.max.bytes=104857600******** Log Basics ********# kafka 存储消息数据的目录
log.dirs=../data# 每个 topic 的默认 partition 数量
num.partitions=1# 设置默认副本数量为 3。如果 Leader 副本故障,会进行故障自动转移。
default.replication.factor=3# 在启动时恢复数据和关闭时刷数据前,每个数据目录使用的线程数量
num.recovery.threads.per.data.dir=1******** Log Flush Policy ********# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000# 消息刷新到磁盘中的最大时间间隔, 1s
log.flush.interval.ms=1000******************************************************* Log Retention Policy *******************************************************# 日志保留时间,超时会自动删除,默认为 7 天 (168 小时)
log.retention.hours=168# 日志保留大小,超出大小会自动删除,默认为 1GB
log.retention.bytes=1073741824# 单个日志段文件的大小限制,最大为 1GB,超出后则创建一个新的日志段文件
log.segment.bytes=1073741824# 每隔多长时间检测数据是否达到删除条件, 300s (5 分钟)
log.retention.check.interval.ms=300000******** Zookeeper ********# Zookeeper 连接信息,如果是 Zookeeper 集群,则以逗号隔开
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181# 连接 Zookeeper 的超时时间, 6s
zookeeper.connection.timeout.ms=6000# 是否允许删除 topic,默认为 false(topic 只会被标记为待删除)。设置为 true 则允许物理删除。
delete.topic.enable=true
Kafka 集群部署
| version | IP | |
|---|---|---|
| Zookeeper | 3.8.4 | 192.168.80.11-80.33 |
| Kafka | 3.8.0 | 192.168.80.11-80.33 |
一键安装脚本
每个节点分别执行
#!/bin/bash
KAFKA_VERSION=3.8.0
SCALA_VERSION=2.13
KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/${KAFKA_VERSION}/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz"
ZK_VERSION=3.8.4ZK_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-${ZK_VERSION}/apache-zookeeper-${ZK_VERSION}-bin.tar.gz"ZK_INSTALL_DIR=/usr/local/zookeeper
KAFKA_INSTALL_DIR=/usr/local/kafkaNODE1=192.168.80.11
NODE2=192.168.80.12
NODE3=192.168.80.13HOST=$(hostname -I | awk '{print $1}')
. /etc/os-releaseprint_status() {local msg=$1local status=$2local GREEN='\033[0;32m'local RED='\033[0;31m'local YELLOW='\033[0;33m'local NC='\033[0m'case $status insuccess)color=$GREENsymbol="[ OK ]";;failure)color=$REDsymbol="[FAILED]";;warning)color=$YELLOWsymbol="[WARNING]";;esacprintf "%-50s ${color}%s${NC}\n" "$msg" "$symbol"
}detect_node_id() {if [[ $HOST == $NODE1 ]]; thenMYID=1elif [[ $HOST == $NODE2 ]]; thenMYID=2elif [[ $HOST == $NODE3 ]]; thenMYID=3elsewhile true; doread -p "输入节点编号 (1-3): " MYIDif [[ $MYID =~ ^[1-3]$ ]]; thenbreakelseprint_status "无效的节点编号" warningfidonefiprint_status "节点ID: $MYID" success
}install_java() {if [[ $ID == 'centos' || $ID == 'rocky' ]]; thenyum -y install java-1.8.0-openjdk-develelseapt updateapt install -y openjdk-8-jdkfiif java -version &>/dev/null; thenprint_status "Java安装成功" successelseprint_status "Java安装失败" failureexit 1fi
}setup_zookeeper() {local src_dir="/usr/local/src"local pkg_name=$(basename $ZK_URL)if [[ ! -f "$src_dir/$pkg_name" ]]; thenwget -P $src_dir $ZK_URL || {print_status "ZooKeeper下载失败" failureexit 1}fitar xf "$src_dir/$pkg_name" -C /usr/local || {print_status "解压失败" failureexit 1}ln -sf /usr/local/apache-zookeeper-*-bin $ZK_INSTALL_DIRecho "PATH=$ZK_INSTALL_DIR/bin:\$PATH" > /etc/profile.d/zookeeper.shsource /etc/profile.d/zookeeper.shmkdir -p $ZK_INSTALL_DIR/dataecho $MYID > $ZK_INSTALL_DIR/data/myidcat > $ZK_INSTALL_DIR/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=$ZK_INSTALL_DIR/data
clientPort=2181
maxClientCnxns=128
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
server.1=$NODE1:2888:3888
server.2=$NODE2:2888:3888
server.3=$NODE3:2888:3888
EOFcat > /etc/systemd/system/zookeeper.service <<EOF
[Unit]
Description=ZooKeeper Service
After=network.target[Service]
Type=forking
Environment="JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))"
ExecStart=$ZK_INSTALL_DIR/bin/zkServer.sh start
ExecStop=$ZK_INSTALL_DIR/bin/zkServer.sh stop
ExecReload=$ZK_INSTALL_DIR/bin/zkServer.sh restart
User=root
Group=root
Restart=on-failure
RestartSec=10[Install]
WantedBy=multi-user.target
EOFsystemctl daemon-reloadsystemctl enable --now zookeeper.serviceif systemctl is-active --quiet zookeeper.service; thenprint_status "ZooKeeper启动成功" successelseprint_status "ZooKeeper启动失败" failureexit 1fi
}setup_kafka() {local src_dir="/usr/local/src"local pkg_name=$(basename $KAFKA_URL)if [[ ! -f "$src_dir/$pkg_name" ]]; thenwget -P $src_dir $KAFKA_URL || {print_status "Kafka下载失败" failureexit 1}fitar xf "$src_dir/$pkg_name" -C /usr/local || {print_status "解压失败" failureexit 1}ln -sf /usr/local/kafka_* $KAFKA_INSTALL_DIRecho "PATH=$KAFKA_INSTALL_DIR/bin:\$PATH" > /etc/profile.d/kafka.shsource /etc/profile.d/kafka.shmkdir -p $KAFKA_INSTALL_DIR/datacat > $KAFKA_INSTALL_DIR/config/server.properties <<EOF
broker.id=$MYID
listeners=PLAINTEXT://$HOST:9092
log.dirs=$KAFKA_INSTALL_DIR/data
num.partitions=1
log.retention.hours=168
zookeeper.connect=$NODE1:2181,$NODE2:2181,$NODE3:2181
zookeeper.connection.timeout.ms=6000
EOFcat > /etc/systemd/system/kafka.service <<EOF
[Unit]
Description=Apache Kafka
After=network.target zookeeper.service[Service]
Type=simple
Environment="JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))"
ExecStart=$KAFKA_INSTALL_DIR/bin/kafka-server-start.sh $KAFKA_INSTALL_DIR/config/server.properties
ExecStop=/bin/kill -TERM \$MAINPID
Restart=on-failure
RestartSec=20[Install]
WantedBy=multi-user.target
EOFsystemctl daemon-reloadsystemctl enable --now kafka.serviceif systemctl is-active --quiet kafka.service; thenprint_status "Kafka启动成功" successelseprint_status "Kafka启动失败" failureexit 1fi
}detect_node_id
install_java
setup_zookeeper
setup_kafka
print_status "安装完成" success
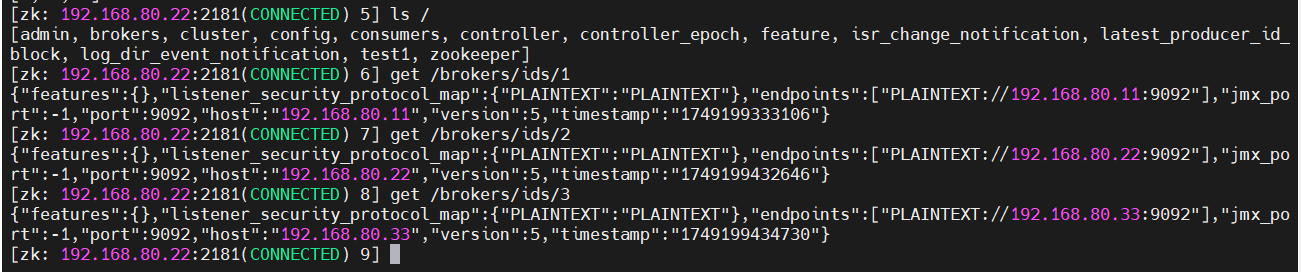
查看Kafka注册情况
创建Topic
/usr/local/kafka/bin/kafka-topics.sh --create --topic DBA --bootstrap-server 192.168.80.11:9092 --partitions 3 --replication-factor 2

获取所有 Topic
/usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 192.168.80.11:9092

获取Topic副详情
/usr/local/kafka/bin/kafka-topics.sh --describe --bootstrap-server 192.168.80.11:9092

Kafka 生产者产出数据
/usr/local/zookeeper/bin# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list 192.168.80.11:9092 --topic DBA

Kafka 消费者消费数据
/usr/local/kafka/bin/kafka-console-consumer.sh --topic DBA --bootstrap-server 192.168.80.22:9092 --from-beginning

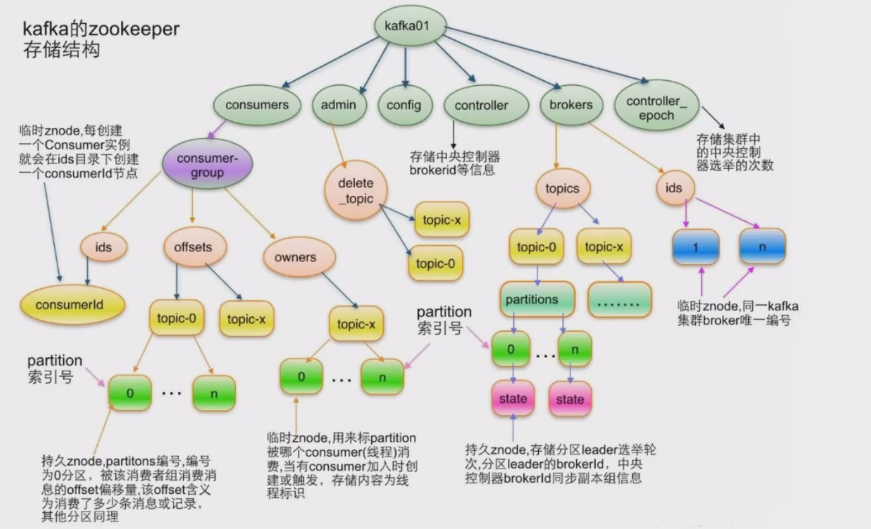
Kafka在Zookeeper中存储结构



对冲基金模拟系统:模范巴菲特、凯西·伍德的投资策略)



![[Java恶补day13] 53. 最大子数组和](http://pic.xiahunao.cn/[Java恶补day13] 53. 最大子数组和)




你好,三角形(Hello Triangle))





)
