25年4月来自新加坡技术和设计大学的论文“NORA: a Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks”。
现有的视觉-语言-动作 (VLA) 模型在零样本场景中展现出优异的性能,展现出令人印象深刻的任务执行和推理能力。然而,视觉编码的局限性也带来巨大的挑战,这可能导致诸如物体抓取等任务的执行失败。此外,这些模型通常由于规模庞大(通常超过 70 亿个参数)而导致计算开销高昂。虽然这些模型在推理和任务规划方面表现出色,但它们产生的大量计算开销使其不适用于实时机器人环境,因为在实时机器人环境中速度和效率至关重要。鉴于针对特定任务对 VLA 模型进行微调的常见做法,显然需要一个更小、更高效的模型,该模型可以在消费级 GPU 上进行微调。为了解决现有 VLA 模型的局限性, NORA,一个 30 亿个参数的模型,旨在降低计算开销的同时保持强大的任务性能。 NORA 采用 Qwen-2.5-VL-3B 多模态模型作为主干模型,利用其卓越的视觉语义理解能力来增强视觉推理和动作推理能力。此外,NORA 基于 97 万个真实机器人演示进行训练,并配备 FAST+ token 化器,可高效生成动作序列。实验结果表明,NORA 的表现优于现有的大规模 VLA 模型,在显著降低计算开销的同时实现了更优的任务性能,使其成为实时机器人自主控制的更实用的解决方案。
VLM
视觉语言模型 (VLM) 已成为强大的图像理解和推理框架,展现出基于视觉输入生成文本以及识别图像中物体的能力。这使其成为 VLA 的绝佳主干模型。基于预训练 VLM 进行微调的 VLA 显著受益于这些模型所经历的互联网规模的图像和文本预训练。这种预训练赋予 VLA 对视觉语义的丰富理解,使 VLA 能够将语言扎根于视觉世界中,并将这种理解转化为有意义的机器人动作。这种扎根有助于泛化到分布外的指令和环境中。例如,VLA 可以从先前的视觉语言经验中进行泛化,从而在之前未见过的场景中解释和执行“拿起玩具”之类的指令,即使在训练过程中没有遇到过完全相同的短语或上下文。
最近的视觉-语言模型 (VLM) 包含一个图像编码器 (Oquab,2023)、一个大语言模型 (LLM) 主干 (Touvron,2023) 和一个将视觉表征映射到共享嵌入空间的投影网络。这种架构使 LLM 能够有效地推理文本和图像模态。VLM 的预训练通常利用各种多模态数据集,包括交错的图像-文本对、视觉知识源、目标基础、空间推理和多模态问答数据集。
本文工作基于 Qwen2.5-VL 模型 (Bai,2025),这是一个最先进的开源 VLM。Qwen2.5-VL 的一个显著特点是它在训练期间使用原始图像分辨率,旨在增强模型对真实世界尺度和空间关系的感知。这种方法能够更准确地理解物体的大小和位置,从而提升物体检测和定位等任务的性能。可以利用 Qwen 2.5-VL 的落地和空间能力来构建 VLA,这将有利于机器人控制。
VLA
尽管 VLM 具有诸多优势,但它们的内在设计并非旨在直接生成适用于机器人技术中特定体现配置的策略。这一局限性促使视觉-语言-动作 (VLA) 模型的出现,该模型通过利用多模态输入(结合视觉观察和语言指令)来弥补这一差距,从而在多样化的多任务场景中生成自适应且广义的机器人动作。根据动作建模方法,VLA 模型大致可分为两类:连续动作模型(Octo Model Team,2024),通常采用扩散过程在连续动作空间中生成平滑轨迹;以及离散 token 模型(Brohan,2023b;c;Kim,2024;Sun,2024),其中机器人动作表示为离散 token 序列。在基于离散 token 的 VLA 模仿学习公式中,机器人在给定时间 t 的状态由多模态观察表征,包括视觉图像 I_t、文本指令 L_t 和先前状态上下文 S_t。目标是预测一系列离散标记 A_t,表示机器人可执行的动作。正式地说,该模仿学习策略模型 π_θ(A_t |I_t,L_t,S_t) 经过训练,可以复制专家提供的动作序列,使机器人能够将学习的行为泛化到由视觉语言提示引导的新场景中。
动作 token 化
在机器人系统中,动作通常表示为跨多个自由度 (DoF) 的连续控制信号,例如 (x, y, z) 方向的平移以及滚转、俯仰和偏航方向的旋转。为了兼容基于 Transformer 的语言主干,通常使用分箱方法将这些连续动作离散化 (Brohan et al., 2023c; b)。此过程使用基于分位数的策略将机器人动作的每个维度映射到 256 个离散箱中的一个,从而确保对异常值的鲁棒性,同时保持足够的粒度。OpenVLA (Kim et al., 2024) 通过覆盖 LLaMA token 化器中 256 个最少使用的 tokens,将这些动作 tokens 合并到语言模型的词汇表中,从而实现对动作序列的下一个 token 预测。为了进一步提高预训练效率,采用了一种快速 token 化方法 (Pertsch et al., 2025),该方法在每个时间步对动作维度应用离散余弦变换 (DCT)。这种方法可以去除联合动作分量的相关性,并支持使用字节对编码 (BPE) 将它们压缩为更短、更高效的 token 序列。由此产生的表征减少词汇量并加快收敛速度,同时使动作数据的结构与语言模型友好的 token 统计数据保持一致。在推理过程中,NORA 占用约 8.3GB 的 GPU 内存。
为机器人自主的神经编排器 (NORA),这是一个基于 Open X-Embodiment 数据集 (Collaboration et al., 2023) 训练的 3B 参数视觉-语言-动作 (VLA) 模型。NORA 建立在现有的视觉-语言模型 (VLM) 之上,充分利用其强大的通用世界知识、多模态推理、表征学习和指令遵循能力。特别地,采用开源多模态模型 Qwen-2.5-VL-3B (Bai et al., 2025) 作为 NORA 的 VLM 主干,因为它在同等规模下实现性能与效率之间的完美平衡。另一方面,利用 FAST+ token 化器(Pertsch,2025)来离散化连续动作 tokens,因为它在包括单臂、双手和移动机器人任务在内的各种动作序列中已被证明有效,使其成为训练自回归 VLA 模型的强大现成选择。
架构
模型 NORA,如图所示,利用预训练的视觉语言模型 (VLM)(记为 M)自回归地预测一个动作块,该动作块编码了从时间 t 到 t + N 的未来动作,记为 a_t:t+N = [a_t,…,a_t+N]。M 的输入包括自然语言任务指令 c 和时间 t 的 n 帧视觉观察 o_t = [I_t1,…,I_tn],它们连接起来形成整体输入 X_t = [o_t, c]。动作块 a_t:t+N 由一系列离散tokens R = [r_t,…,r_t+N] 表示,并在训练时使用 FAST+ 机器人 token 化器进行编码。 VLM M 通过自回归生成以 X_t 为条件的 token 序列 R 来预测此动作块。
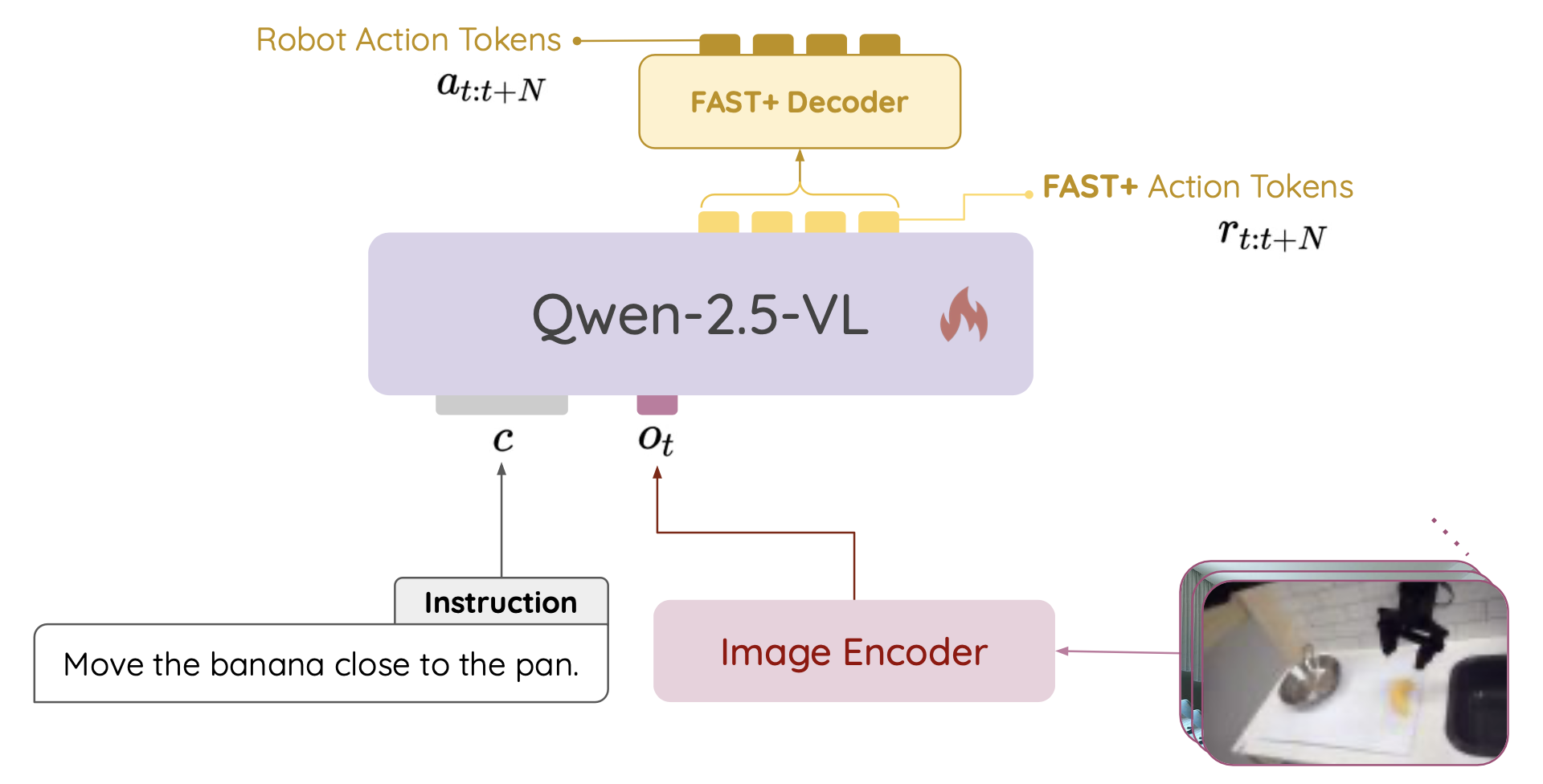
选择最先进的开源 VLM Qwen-2.5-VL (Bai et al., 2025) 作为主干模型,因为它的参数规模较小,只有 3B。此外,通过 FAST+ token 化器引入的 2048 个 tokens,扩充 VLM token 化器的词汇量。将观察结果限制在单个视觉帧内。动作块大小设为 1。随后,用标准语言建模目标函数(即下一个 token 预测损失函数)训练 NORA。
预训练
预训练阶段的目标是在自然语言指令的驱动下,赋予 NORA 广泛的机器人能力,并在各种任务、设置、模态和具体化方面实现强大的泛化能力。为此,在 Open X-Embodiment (Collaboration et al., 2023) (OXE) 数据集上训练 NORA,该数据集包含执行各种任务的不同机器人的轨迹,包括 BridgeV2 (Walke et al., 2023)、DROID (Khazatsky et al., 2024) 等子集。与 OpenVLA (Kim et al., 2024) 类似,将所有帧的大小调整为 224 x 224 像素以进行训练。
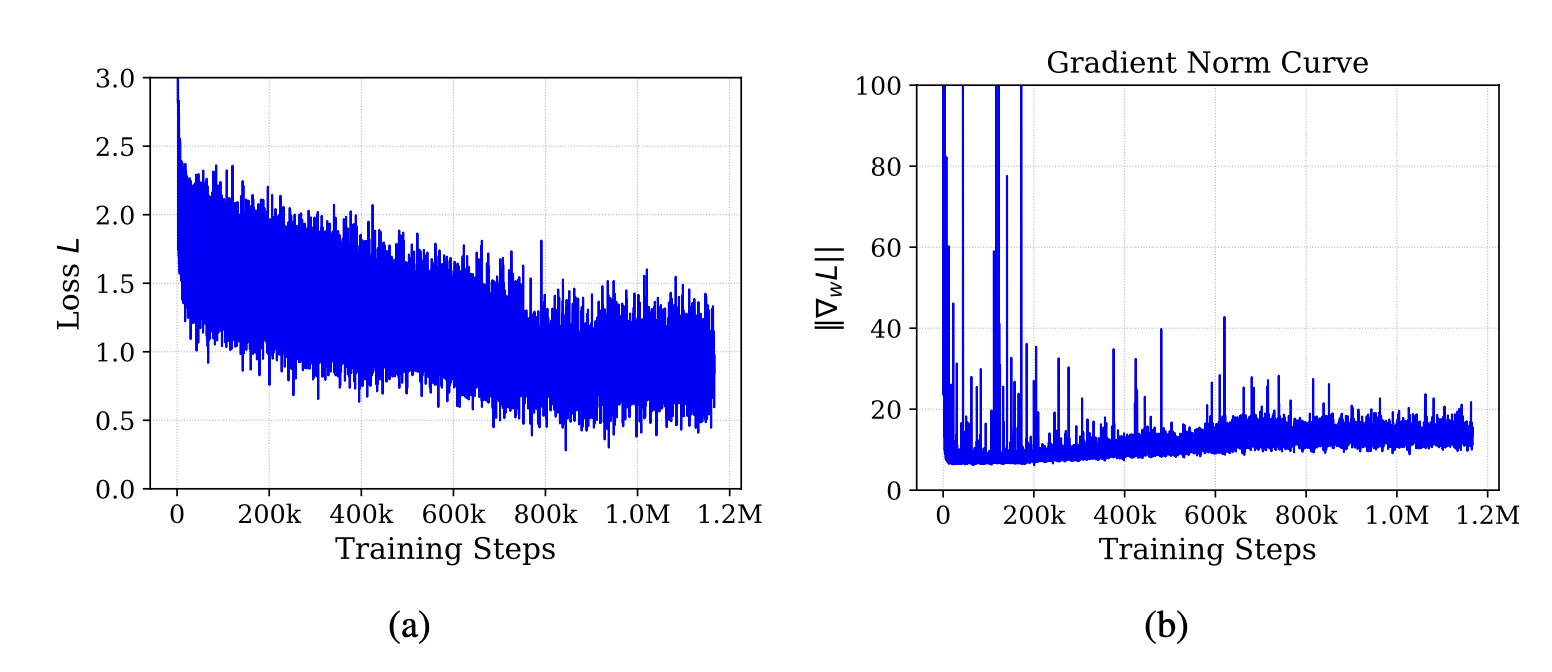
在 8xH100 GPU 的单节点上对 NORA 进行了大约三周的训练,总计约 4000 个 H100 GPU 小时。用 256 的批次大小,并使用 AdamW (Loshchilov & Hutter, 2017) 优化器执行了 110 万次梯度更新。在前 5 万步中,进行线性预热,使峰值学习率达到 5 × 10−5,然后以余弦衰减至零。为了提高训练效率并减少内存占用,用 FlashAttention 并以 bf16 精度进行训练。在下图 a 和 b 中报告训练损失和梯度范数曲线。训练过程中的损失曲线总体稳定,呈下降趋势,没有出现明显的峰值。虽然梯度范数曲线在整个训练过程中偶尔出现峰值,但这似乎并未扰乱损失的整体平稳增长。
NORA-LONG
一些研究表明,动作分块(即预测较长的动作范围而无需频繁重规划)可带来卓越的性能。(Zhao et al., 2023; Chi et al., 2024)。受这些发现的启发,训练 NORA 的一个变体,称为 NORA-LONG,其动作块大小为 5。NORA-LONG 与 NORA 的架构完全相同,但预测给定状态下的动作范围为 5 个动作。在与 NORA 相同的预训练数据集上对 NORA-LONG 进行 90 万步的预训练。
为了评估 NORA 在不同环境和机器人实现中的鲁棒性,用 (i) Walke (2023) 开发的真实 WidowX 机器人平台和 (ii) LIBERO (Liu,2023) 模拟基准,该基准包含 30 个程序生成的解缠结任务,这些任务需要深入理解不同的空间布局 (LIBERO-Spatial)、物体 (LIBERO-Object) 和任务目标 (LIBERO-Goal),以及 10 个长范围纠缠任务 (LIBERO-Long);该基准测试还附带一个训练数据集。在这两种情况下,策略模型都以第三人称摄像机画面和自然语言指令为输入,预测末端执行器的速度动作,从而在 500 次试验中控制机器人。在相应的数据集上对 NORA 进行了 150 次微调,批次大小为 128,学习率为 5 × 10−5。
为了确定策略模型的泛化能力,开发一套具有挑战性的评估任务,涉及域外 (OOD) 目标、空间关系和多个拾取和放置任务,如图所示。所有策略均在相同的真实世界设置下进行评估,确保摄像机角度、光照条件和背景一致。每项任务进行 10 次试验,遵循 Kim (2024) 的方法。

如果机器人成功完成提示指定的任务,则计为成功 (succ),得分为 1;否则,得分为 0:
为了与 NORA 进行比较评估,将其性能与以下基准方法进行比较。
OpenVLA (Kim,2024):VLA 模型基于 Llama 2 语言模型 (Touvron,2023) 构建,并结合视觉编码器,该编码器集成来自 DINOv2 (Oquab,2023) 和 SigLIP (Zhai,2023) 的预训练特征。该模型在 Open-X-Embodiment 数据集 (Collaboration,2023) 上进行预训练,该数据集包含 97 万个真实世界机器人演示。
SpatialVLA (Qu,2025):VLA 模型专注于机器人操控的空间理解,并融合空间运动等 3D 信息。它学习一种适用于各种机器人和任务的空间操控通用策略。 SpatialVLA 一次可预测四个动作。
TraceVLA(Zheng,2024):一个通过视觉轨迹提示增强时空推理的 VLA 模型。该模型基于机器人操作轨迹对 OpenVLA 进行微调,将状态-动作历史编码为视觉提示,从而提升交互任务中的操作性能。
RT-1(Brohan,2023c):一个可扩展的 Robotics Transformer 模型,旨在从大型任务无关数据集中迁移知识。RT-1 基于多种机器人数据进行训练,在各种机器人任务中实现高水平的泛化和任务特定性能,展现开放式任务无关高容量模型训练的价值。














)

)


