安装部署logstash 7.10.0详细教程
- 一、下载并安装
- 二、新建配置文件
- 三、赋权文件权限
- 四、检测文件grok语法是否异常
- 五、启动服务
- 六、安装启动常见问题
【背景】
- 整个elk安装是基于ubuntu 22.04和jdk 11环境。
- logstash采用 *.deb方式安装,需要服务器能联网。
- ubuntu 22.04 安装部署elk(elasticsearch/logstash/kibana) 7.10.0详细教程
一、下载并安装
# 下载安装包命令
sudo wget https://artifacts.elastic.co/downloads/logstash/logstash-7.10.0-amd64.deb
sudo wget https://artifacts.elastic.co/downloads/logstash/logstash-7.10.0-amd64.deb.sha512
# 开始安装
shasum -a 512 -c logstash-7.10.0-amd64.deb.sha512
# 校验成功出现 logstash-7.10.0-amd64.deb: OK
sudo dpkg -i logstash-7.10.0-amd64.deb
二、新建配置文件
命令:sudo vim /etc/logstash/conf.d/java_service_logs.conf
# java_service_logs.conf 内容详情如下
input {file {# 要监控的日志文件路径(支持通配符,匹配两个目录下的所有.log文件)path => ["/data/logs/java-admin/*.log","/data/logs/java-api/*.log"]# 日志读取起始位置:# - beginning:从文件开头开始读取(适合首次采集)# - end:从文件末尾开始读取(默认值,只采集新增内容)start_position => "beginning"# 自定义 sincedb 文件路径(记录文件读取进度,避免重复采集)# 默认路径在用户家目录,这里显式指定到 Logstash 数据目录sincedb_path => "/usr/share/logstash/data/java_service_logs_sincedb"# 忽略 15 天前修改的文件(自动清理旧日志文件)ignore_older => "15d" # ===== 多行日志合并配置 =====codec => multiline {# 正则匹配行首的时间戳格式(示例:[2023-10-01T12:34:56,789])pattern => "^\[%{TIMESTAMP_ISO8601}\]"# 匹配逻辑取反:当行不匹配时间戳模式时触发合并negate => true# 合并方向:将不匹配的行合并到前一行(适合 Java 异常堆栈等场景)what => "previous"# 最大合并行数限制(防止单条日志过大)max_lines => 500 # 自动刷新间隔(秒):超过该时间未匹配到新行则强制提交当前合并结果auto_flush_interval => 3 }# ===== 以下为可选调试参数(当前被注释) =====# sincedb_path => "/dev/null" # 测试时禁用 sincedb(每次重新读取全部内容)# ignore_older => 0 # 不忽略旧文件(需配合 start_position 使用)# stat_interval => 10 # 文件状态检查间隔(秒,默认1s)# discover_interval => 60 # 新文件发现间隔(秒,默认15s)}
}filter {# ===== 日志结构化解析 =====grok {match => {# 定义两种匹配模式(支持含/不含堆栈跟踪的日志)"message" => [# 模式1:包含堆栈跟踪的日志(如异常日志)"\[%{TIMESTAMP_ISO8601:log_timestamp}\]\s+\[%{DATA:log_thread}\]\s+\[%{LOGLEVEL:log_level}\]\s+%{DATA:log_class}\s+-\s+%{GREEDYDATA:log_message}\n%{GREEDYDATA:stack_trace}",# 模式2:普通日志(无堆栈跟踪)"\[%{TIMESTAMP_ISO8601:log_timestamp}\]\s+\[%{DATA:log_thread}\]\s+\[%{LOGLEVEL:log_level}\]\s+%{DATA:log_class}\s+-\s+%{GREEDYDATA:log_message}"]}# 用解析后的结构化字段覆盖原始 message 字段overwrite => ["message"]}# ===== 时间戳处理 =====date {# 将 log_timestamp 字段转换为 Logstash 时间戳(@timestamp)match => ["log_timestamp", "yyyy-MM-dd HH:mm:ss.SSS"]# 指定转换后的目标字段(默认会覆盖 @timestamp)target => "@timestamp"# 时区配置:将原始时间转换为印度时区(GMT+05:30)# 示例:原始时间 2025-06-01 18:30:00 → 转换后 @timestamp 为 2025-06-01 13:00:00(UTC时间)timezone => "Asia/Kolkata" }# ===== 堆栈跟踪处理 =====# 仅当存在 stack_trace 字段时执行if [stack_trace] {mutate {# 将堆栈跟踪中的换行符 \n 替换为转义字符 \\n# 避免 Elasticsearch 存储时丢失换行格式gsub => ["stack_trace", "\n", "\\n"]}}
}output {# ===== Elasticsearch 输出 =====elasticsearch {# ES 服务器地址(HTTP 协议)hosts => ["http://localhost:9200"]# 索引命名规则:按日期滚动(java_service_logs-2025.04.26)index => "java_service_logs-%{+YYYY.MM.dd}"# 认证信息(Basic Auth)user => "elastic"password => "密码"}# ===== 调试输出(注释状态)=====# stdout { codec => rubydebug } # 以 Ruby 格式输出到控制台(开发调试用)
}三、赋权文件权限
# 因新建文件权限可能是root账号的,所以需要授权
sudo chown -R logstash:logstash /etc/logstash/conf.d/*.conf
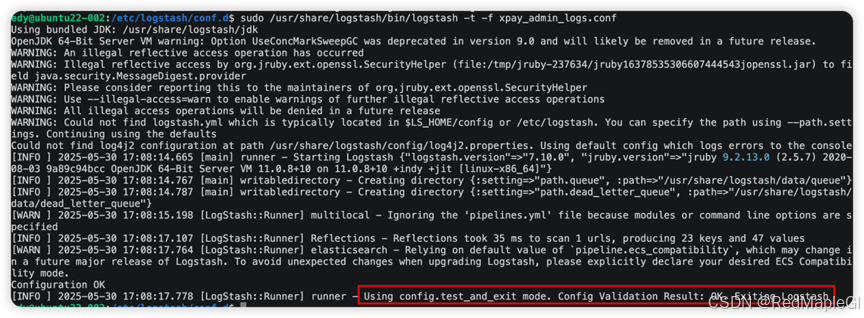
四、检测文件grok语法是否异常
# 启动前检查下文件中是否有语法错误,能更快排错
sudo /usr/share/logstash/bin/logstash -t -f /elc/logstash/conf.d/java_service_logs.conf
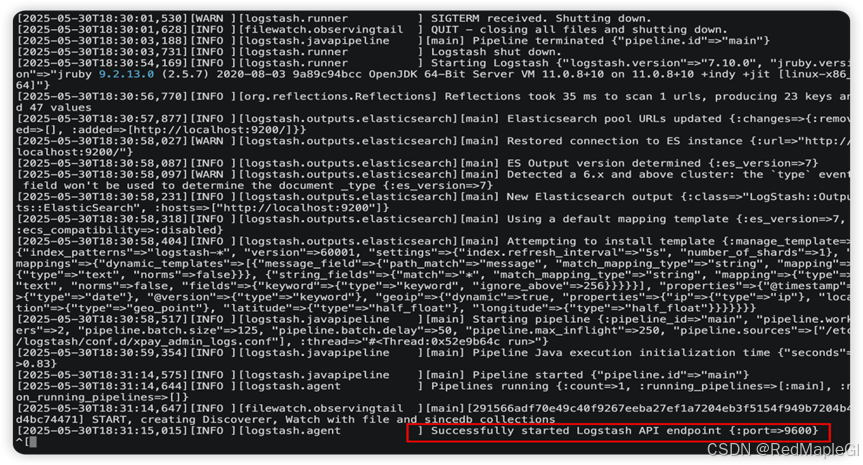
五、启动服务
sudo systemctl daemon-reload
sudo systemctl start logstash
sudo systemctl stop logstash
sudo systemctl restart logstash
sudo systemctl status logstash
六、安装启动常见问题
(1) 查看日志 sudo tail -100f /var/log/logstash/logstash-plain.log
(2) 对/etc/logstash/conf.d中文件没有授权,如上授权
sudo chown -R logstash:logstash /etc/logstash
(3) java_service_logs.conf的语法很容易错误,其次就是某些配置项与其版本不匹配,可以启动前测试下:
sudo /usr/share/logstash/bin/logstash -t -f java_service_logs.conf
(4) 对于logstash排错,可以先将logstash.yml 日志级别设置为 debug,便于排错
(5) 对于logstash不能收集日志到es,可以通过 stdout { codec => rubydebug } 将输出结果先打印出来,不要直接输入到es中。
还有对于input模块,ignore_older => 0 该参数慎用,可能读取不到。可以修改为 ignore_older => “15d”, 表示从当前15天到当前内容。
(6) 还可以利用打印到控制台去测试grok匹配的数据
sudo /usr/share/logstash/bin/logstash -e ‘input { stdin { } } filter { grok { match => { “message” => “[%{TIMESTAMP_ISO8601:log_timestamp}] [%{DATA:log_thread}] [%{LOGLEVEL:log_level}] %{DATA:log_class} - %{GREEDYDATA:log_message}” } } } output { stdout { codec => rubydebug } }’







MySQL学习笔记(9):索引(常见索引类型,查找结构的发展(二分查找法,二叉搜索树,平衡二叉树,B树,B+树)))
Linux)







- 快速版)


