2021 USENIX
GitHub - sylab/cacheus: The design and algorithms used in Cacheus are described in this USENIX FAST'21 paper and talk video: https://www.usenix.org/conference/fast21/presentation/rodriguez
Learning Cache Replacement with CACHEUS
1 intro
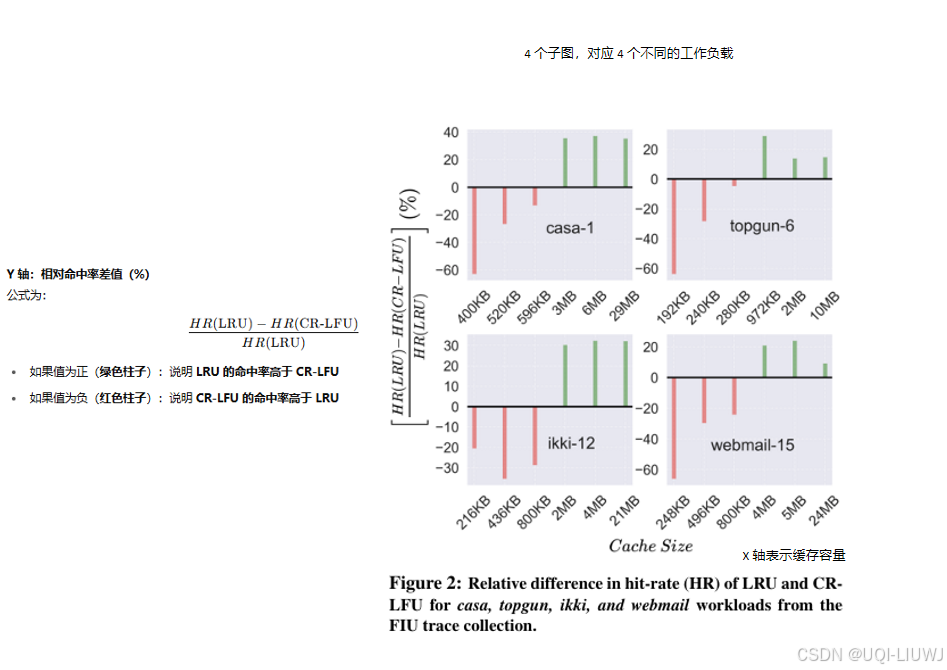
- 基于机器学习的 LeCaR 算法展示了:仅凭两个简单的策略——LRU 和 LFU——即可在某些生产级工作负载下超越 ARC。
- LeCaR 采用了一种名为“遗憾最小化”(regret minimization)的机器学习技术,用于在缓存缺失时动态选择其中一个策略
- 论文从分析和实证两个角度回顾 LeCaR,指出尽管其开创性地迈出了第一步,但仍存在重大局限。
- 在许多生产负载中,LeCaR 的表现不及当前先进算法如 ARC、LIRS 和 DLIRS
- 论文贡献1:识别出与缓存相关的工作负载特征
- 四种工作负载原型:LRU 友好型、LFU 友好型、扫描型(scan)和剧烈变动型(churn)
- 论文贡献2:提出了 CACHEUS
- 这一方案受 LeCaR 启发而来,但克服了其一个重要缺陷:完全自适应,取消了所有静态设置的超参数,因而具有高度的灵活性
- 论文贡献3:设计了两个轻量级专家策略:CR-LFU 和 SR-LRU
- CR-LFU 在 LFU 的基础上增加了对剧烈变动的适应能力
- SR-LRU 则在 LRU 的基础上增强了对扫描型访问模式的抵抗能力
- 当使用这两个专家策略时,CACHEUS 能够在绝大多数(工作负载,缓存容量)组合中表现出与先进算法相当甚至更优的性能
2 动机
2.1 理解工作负载
分析了来自 5 个不同生产环境的数据集中的 329 条生产存储访问轨迹
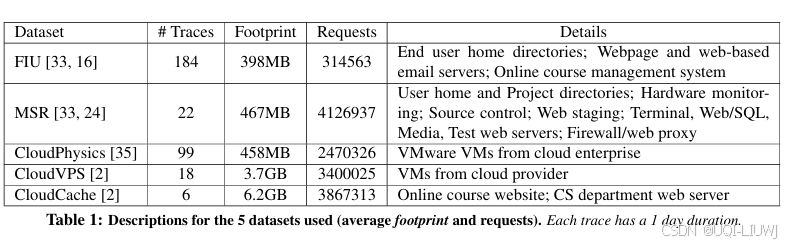
2.1.1 工作负载原型类型(Workload Primitive Types)
定义了以下几类工作负载原型类型(primitive types):
-
LRU 友好型(LRU-friendly):
-
其访问序列最适合采用**最近最少使用(LRU)**缓存算法处理。
-
-
LFU 友好型(LFU-friendly):
-
其访问序列最适合采用**最不常用(LFU)**缓存算法处理。
-
-
扫描型(Scan):
-
其访问序列中,有一部分数据项仅被访问一次。
-
-
剧烈变动型(Churn):
-
其访问序列中,对某一子集的数据反复访问,且每个项的访问概率相等。
-

- 这些原型之间并不完全互斥。例如,一个 LRU 友好的工作负载也可能呈现出 churn 的特征
- 大多数被分析的工作负载中至少包含一种以上的原型类型。
- 不过,不同工作负载在这些原型的组合和占比上差异显著
2.1.2 工作负载的组合结构(Composing Workloads)
- 现代存储工作负载通常是上述几类原型类型的组合
- 此外,随着缓存容量的变化,某个工作负载的原型类型也可能随之变化
- 例如,在缓存大小为 C1 时,某个工作负载表现为 LRU 友好型,但当缓存缩减到 C2(C2 < C1)时,其行为可能变为 churn 型
- 这种变化可能是因为原本处于工作集中的数据项,在再次被使用前就被缓存淘汰了。
2.2 缓存替换算法(Caching Algorithms)

2.2.1 自适应替换缓存 ARC(Adaptive Replacement Cache)
- 一种自适应缓存算法,旨在同时识别访问的**“最近性(recency)”和“频率(frequency)”**特征
- ARC 将缓存划分为两个 LRU 列表:T1 和 T2。
-
T1:存储只被访问过一次的条目。
-
T2:存储自被加入缓存以来至少被访问过两次的条目。
-
-
虽然 T2 也是基于 LRU 实现的,但这限制了 ARC 对访问频率分布的全面捕捉,因此它在 LFU-friendly 工作负载下表现不佳。
-
对于扫描型工作负载(Scan),新项会进入 T1,进而保护 T2 中那些更频繁使用的旧项;
-
对于剧烈变动型工作负载(Churn),ARC 无法区分那些“同等重要”的项,导致缓存被频繁替换,性能下降【29】
2.2.2 低干扰最近性集合 LIRS(Low Interference Recency Set)
- LIRS是一种基于重用距离(reuse distance)的先进缓存算法。
- 它通过一个短的过滤列表 Q 来引导仅被访问一次的条目,因此对于扫描型工作负载处理效果很好。
- 然而,LIRS 的自适应能力受限于 固定长度的 Q 列表:
- 当某些条目的重用距离超过 Q 长度(如超过缓存的 1%)时,LIRS 难以及时识别这些条目的重用。
- 此外,和 ARC 一样,LIRS 无法获得完整的访问频率分布,因此在 LFU-friendly 工作负载中表现受限。
2.2.3 动态 LIRS(DLIRS)
- DLIRS是对 LIRS 的改进版本,引入了动态调整机制
- 根据条目的重用距离动态分配缓存空间,使得高重用率和低重用率的条目能分别被优化处理
- 该策略在某些缓存配置中能达到与 ARC 相当的性能,尤其是在 LRU-friendly 工作负载下,同时保持了 LIRS 在扫描场景下的优势。
- 论文的实验证明:
-
DLIRS 的表现在不同工作负载间不够稳定;
-
它依然继承了 LIRS 在 LFU-friendly 情形下的缺陷。
-
2.2.4 学习型缓存替换算法 LeCaR(Learning Cache Replacement)
- 采用**强化学习(reinforcement learning)和遗憾最小化(regret minimization)**方法,在缓存缺失时动态地在 LRU 和 LFU 之间做出选择
- LeCaR 在 小缓存容量下可在多个真实工作负载上优于 ARC
-
但 LeCaR 也存在以下问题:
-
自适应能力有限
-
运算开销较大
-
对 churn 工作负载支持较差
-
2.3 为何需要一种新方法(Need for a New Approach)
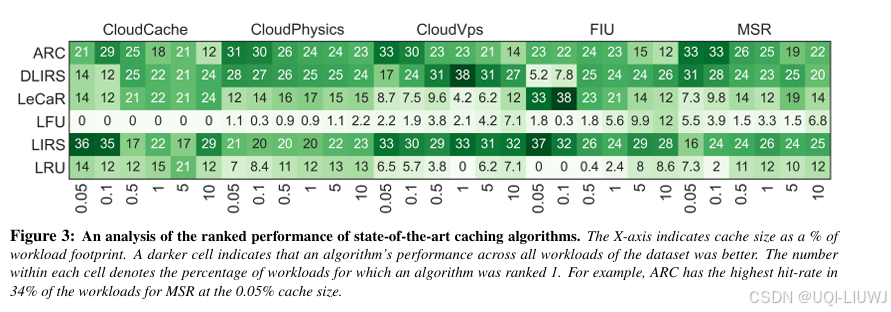
- 现有的最先进缓存替换算法,各自只能应对某些特定类型的工作负载原型。
- 为了系统评估它们的表现,论文进行了大规模的实证研究:
- 使用来自 5 个不同生产系统的 329 条存储 I/O 轨迹,并在 6 种缓存配置下测试算法表现,这些缓存容量从工作负载数据占用量的 0.05% 到 10% 不等。
- 为了比较在如此大规模实验中的相对性能,对每个算法在每条工作负载下的 命中率(hit-rate) 进行排序:
-
表现最好的算法被评为 排名 1;
-
其他命中率在 相对 5% 误差范围内 的算法也同样被归为排名 1。
-
例如,如果某算法命中率为 40%,那么所有命中率在 38% 到 40% 之间的算法也算作“并列第一”
-
命中率低于 38% 的算法则被评为排名 2 或更高。
-
-
-
统计每个算法在每组工作负载中,被评为排名 1 的工作负载比例
-
-
—》在所有被评估的最先进缓存算法中,没有任何一个算法在所有场景下始终优胜。
-
3 CACHEUS
- 鉴于工作负载原型类型具有显著差异性,且会随着时间在同一工作负载中动态变化,缓存替换算法需要同时具备灵活性与自适应能力。
- ——>CACHEUS 利用在线强化学习与 遗憾最小化(regret minimization) 构建了一种可应对动态变化工作负载原型类型的缓存替换算法
- 其设计在很大程度上借鉴了 LeCaR
3.1 LeCaR:回顾
- LeCaR 展示了将强化学习与遗憾最小化应用于缓存系统的可行性
-
在每次驱逐(eviction)时,从两个基础专家策略中动态选择一个:
-
LRU(最近最少使用)
-
LFU(最不常用)
-
-
选择哪个策略由对应的权重(
w_LRU和w_LFU)以概率方式决定-
这些权重会随着每次驱逐的“是否正确”而动态更新:若某策略导致错误驱逐,将受到惩罚,其权重降低
-
-
LeCaR 使用两个核心参数控制其在线学习过程:
-
学习率(learning rate)
-
折扣率(discount rate):控制模型停止学习的速度
-
-
3.2 对 LeCaR 的问题诊断
针对 329 条不同工作负载,在 共 17766 次模拟实验 中测试了 LeCaR 的表现。发现:
-
在相当数量的工作负载中,有些策略明显优于 LRU 和 LFU;
-
特别是 LRU 和 LFU 并不能有效应对 Scan 和 Churn 类型的工作负载原型。
- 此外,LeCaR 在实际应用中还存在第二个挑战:两个内部参数(学习率和折扣率)需手动设定
- 论文的实证结果表明:
-
移除折扣率(discount rate) 对 LeCaR 性能几乎没有影响;
-
不同工作负载 对最优学习率的需求不同
-
-
甚至在同一工作负载中,随着时间推移,其特征也会显著变化,变化的速度(velocity)与幅度(magnitude)也不断波动。
-
-
——>为适应这种动态性,不同时间点下应使用不同的学习率值,而不是一个静态的全局值
- 论文的实证结果表明:
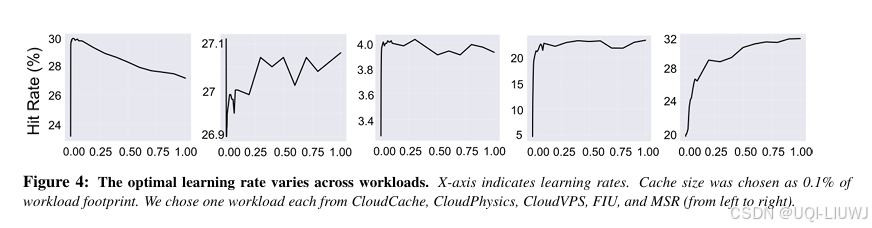
3.3 CACHEUS
- 首先,CACHEUS 完全移除了折扣率
- 其次,为了实现对学习率超参数的自适应更新,论文评估了多种策略,包括:
- 网格搜索(grid search)
- 随机搜索(random search)
- 高斯搜索、贝叶斯优化、种群进化方法
- 梯度优化方法(gradient-based optimization)
- 最终,我们选择了一种基于梯度的随机爬山算法(stochastic hill climbing with random restart),因为它在实践中表现最稳定。


4 抗扫描能力(Scan Resistance)
CACHEUS(LRU, LFU) 无法有效应对扫描(scan)型工作负载
- 为了理解扫描对经典缓存算法的影响,论文构造了合成工作负载,将扫描阶段与可重用数据阶段交错进行。
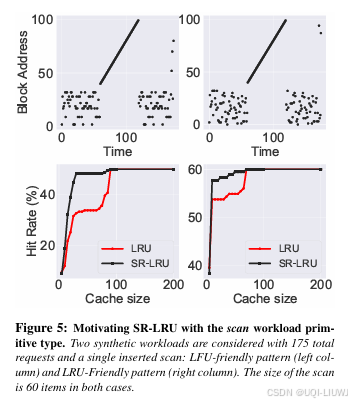
- 每次扫描涉及 60 个页面,穿插在其他可重用项的访问之间
- 这时,像 LRU 这样的经典缓存算法为了接纳新的扫描项,会主动淘汰驻留缓存中的工作集项,期待将来能再次使用这些新项
- 但实际上,扫描项很快就不会再被使用了,这种替换导致缓存命中率严重下降。
4.1 其他缓存替换算法的抗扫描机制
ARC、LIRS 和 DLIRS 各自实现了不同的抗扫描机制:
-
ARC:限制其 T1 列表的大小(T1 用于存储新访问的项),以此保留 T2(频繁访问项)中的可重用数据。但 ARC 的扫描抵抗机制在处理 扫描后接 churn 的负载时会失效——在 churn 阶段 ARC 会持续从 T1 驱逐,退化为类似 LRU 的行为。
-
LIRS:通过一个名为 Q 的栈存储扫描项,Q 的大小固定为缓存容量的 1%,难以适应动态工作集,因此适用性受限。
-
DLIRS:对 LIRS 的 Q 区进行自适应调整,尽管理论上是自适应的,但在实际表现中反而不如 LIRS。
4.2 SR-LRU
- 论文设计了一个新的 LRU 变种,命名为 SR-LRU(Scan-Resistant LRU),它既适配 LRU 友好型负载,也具备扫描识别能力。
SR-LRU 仿照 ARC 和 LIRS 的思想,将缓存划分为两个区域:
-
R 区:只包含被访问多次的项(可重用性强)
-
SR 区:存放只被访问一次的项或老旧但频繁访问过的项(可能不再有用)
-
SR 区是扫描缓冲区:避免新项直接挤掉 R 区的重要数据;
-
只从 SR 区驱逐数据;
-
当发生缓存未命中、缓存已满时,SR-LRU 会从 SR 区中驱逐 LRU 项;
-
被访问次数多的旧项,会从 R 区降级到 SR 区,保持 R 区的“纯净度”;
-
此外,SR-LRU 还维护了一个 历史列表 H,大小等于缓存,用于记录最近被驱逐的项。

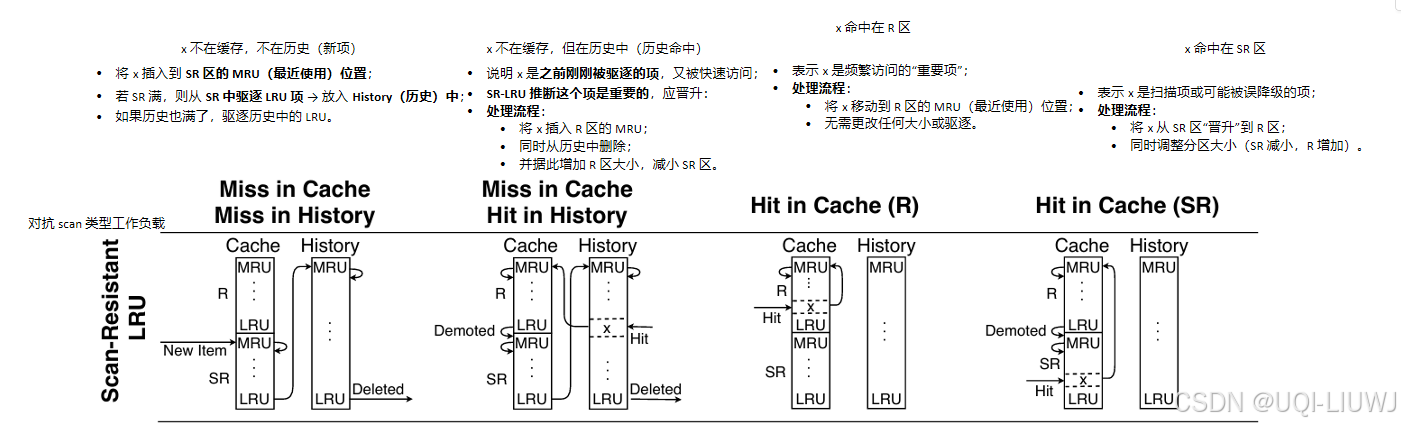
5 抗抖动能力(Churn Resistance)
- 对于 churn 类型的工作负载原型,如果正在访问的项数量大于缓存容量,那么基于 LRU 的算法会导致缓存频繁抖动(churning)——也就是说,数据不断被插入与驱逐,几乎没有命中。
- 相比之下,经典的 LFU(最不常用算法)将相同频率的所有项视为等价。但在 churn 工作负载中,所有项的访问频率都一样,这些项可能按顺序访问,也可能是无序的。
- 论文发现只需对经典 LFU 做一个简单的修改,就足以应对 churn 类型负载,并保持 LFU 原有的优势。
- ——>提出了 抗抖动 LFU(CR-LFU),其核心在于:当存在多个项具有最低访问频率时,不是随机选一个驱逐,而是选择最“最近使用”的那一个(MRU)来驱逐。
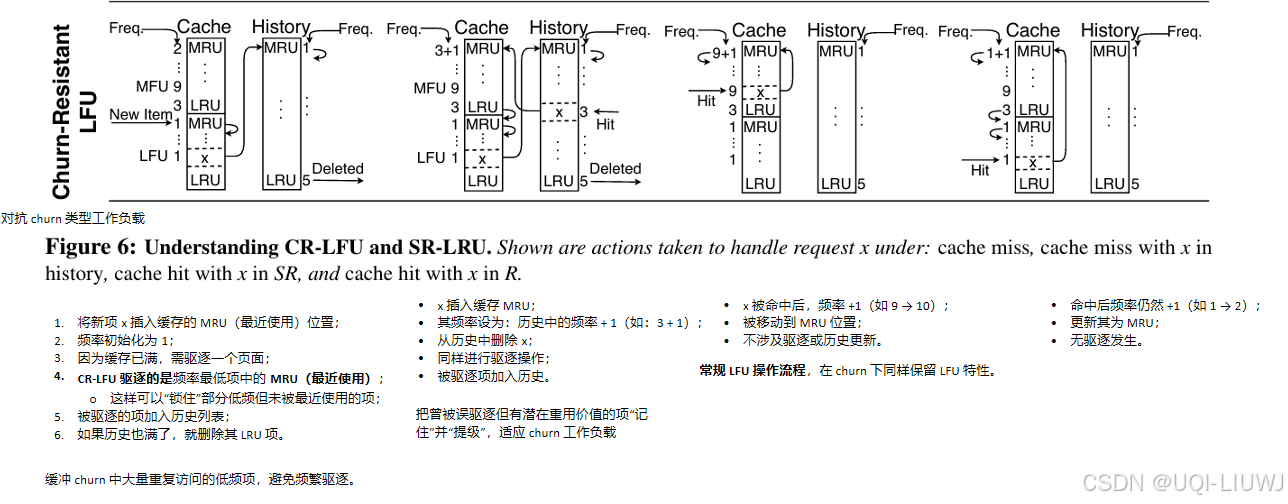

)






)










