卷积的定义
卷积是图像处理中最核心的操作之一,其本质是通过卷积核(滤波器)与图像进行滑动窗口计算(像素值乘积之和),实现对图像特征的提取、增强或抑制。
一、二维卷积--针对二维矩阵进行处理
1.1单通道
见得最多的卷积形式,它只有一个通道。
形式:
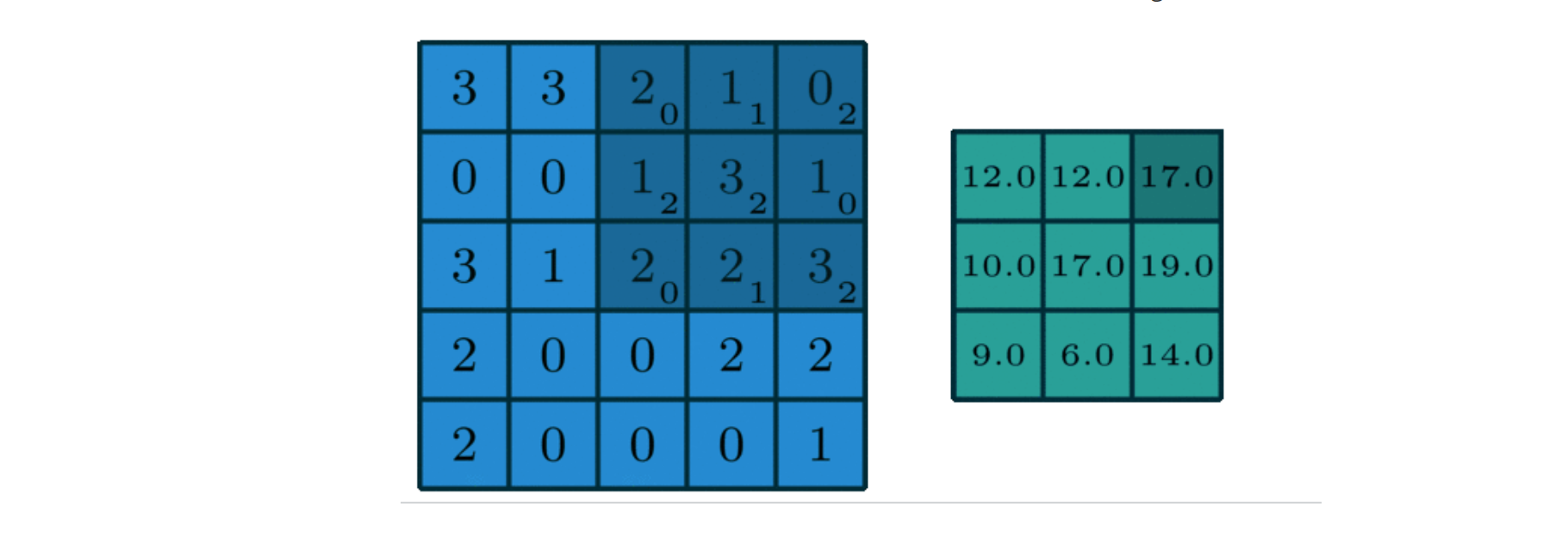
解释:这里的卷积不是旁边绿色的矩阵图,右边绿色的矩阵图叫做特征图(feature map),一般是卷积核与原图进行卷积后的结果图。这里的卷积核是
[0,1,2]
[2,2,0]
[0,1,2]
卷积的过程就是从上到下,从左到右依次开卷,然后乘积求和相加。
1.2多通道
多通道卷积的通道数不在局限于1个,它的通道数是多个的,一般用在图像为多通道图像上,每一个通道的原图形像素值与对应通道的卷积核进行计算,最后再进行多通道的合并(元素相加,在通道上进行特征融合)。
形式:
# 第1个子核(对应输入的R通道)
[[w11, w12, w13],[w21, w22, w23],[w31, w32, w33]
]# 第2个子核(对应输入的G通道)
[[u11, u12, u13],[u21, u22, u23],[u31, u32, u33]
]# 第3个子核(对应输入的B通道)
[[v11, v12, v13],[v21, v22, v23],[v31, v32, v33]
]二、三维卷积
在空间的长、宽两个维度基础上,再增加一个深度(或时间)维度进行卷积操作。
核心特点:
- 卷积核是三维的:比如尺寸为
3×3×3(长 × 宽 × 深度),像一个 “小立方体”。 - 作用对象是三维数据:比如视频的连续帧(宽 × 高 × 时间帧)、CT/MRI 的立体医学影像(长 × 宽 × 切片层)等。
三、反卷积
卷积的反向操作,但不是严格反向。卷积是将原图的特征进行提取,会把原图变小。卷积为计算Y。
反卷积也称为转置卷积,它是将小尺寸的特征图恢复为大尺寸。反卷积为计算X。
四、膨胀卷积
膨胀卷积也叫空洞卷积,主要是为了让卷积核的元素之间插入空格进行膨胀,扩大感受野。一般膨胀率参数L默认为1,公式为L-1。
感受野(Receptive Field):输出特征图上的一个像素点,对应输入图像(或原始数据)中多大范围的区域。
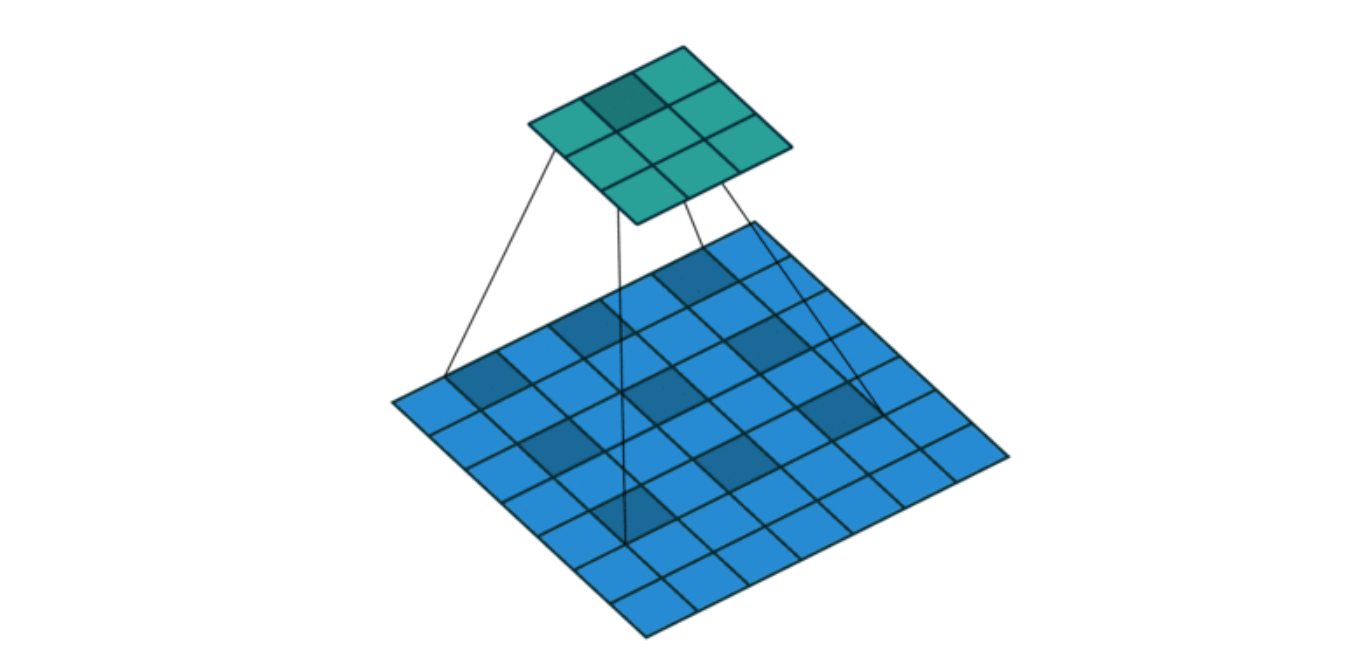
API:nn.Conv2d(dilation = 2) -----这表示空一格
代码:
import torch
import torch.nn as nn
def test():c1 = nn.Conv2d(in_chanels=3,out_chanels=1,kernel_size=3,stride=1,paddiong=0,dilation=2)out = c1(input_data)print(out.shape)if __name__ == '__main__':input_data = torch.randn(1,3,7,7) #1表示批次,3表示通道,7表示高度,7表示宽度test()结果:
torch.Size([1, 1, 3, 3])
解释:特征图out根据公式可以得到现在的宽高,torchsize里的参数分别表示(batch,channel,height,weight)
计算公式:

五、可分离卷积
5.1空间可分离卷积
将卷积核拆分成可以用数学公式相乘得到的两个卷积核。用这两个分别的独立的核对原图形进行操作。
拆分的目的:降低计算量。
API:nn.Conv2d(kernel_size = (x,y))
代码:
def test1():c1 = nn.Conv2d(in_channels=3,out_channels=1,kernel_size=(3,1),stride=1,padding=0,dilation=1)out = c1(input_data)print(out.shape)c2 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=(1,3),stride=1,padding=0,dilation=1)out1 = c2(out)print(out1.shape)if __name__ == '__main__':input_data = torch.randn(1,3,7,7) #1表示批次,3表示通道,7表示高度,7表示宽度test1()结果:
torch.Size([1, 1, 5, 7])
torch.Size([1, 1, 5, 5])
根据结果可以观察到,最终的结果仍然是一样的,计算公式可以用上图计算得到。
#可分离卷积的另一种写法
class SeparbleConv(nn.Module):def __init__(self):super(SeparbleConv,self).__init__()self.c1 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size=(3,1),stride=1,padding=0,dilation=1)self.c2 = nn.Conv2d(in_channels=64,out_channels=16,kernel_size=(1,3),stride=1,padding=0,dilation=1)def forward(self,x):x = self.c1(x)out = self.c2(x)return outif __name__ == '__main__':input_data = torch.randn(1,32,214,214)model = SeparbleConv()out = model(input_data)print(out.shape)weight_desc = model.named_parameters()for name, param in weight_desc:print(name, param.shape)结果:
torch.Size([1, 16, 212, 212])
c1.weight torch.Size([64, 32, 3, 1])
c1.bias torch.Size([64])
c2.weight torch.Size([16, 64, 1, 3])
c2.bias torch.Size([16])
5.2深度可分离卷积
深度可分离卷积的卷积核分为两部分,一部分为深度卷积核,一部分为1*1卷积(点卷积)。
卷积过程:
(1)输入图的每一个通道都有对应的卷积核,通道数有多少,卷积核的个数就有多少。
(2)对前一个深度可分离卷积的结果进行1*1卷积,对上一个特征图进行特征融合,形成新的特征图结果。这里不会改变形状大小,只是把重要的特征凸显出来,不重要的信息逐渐抹去。
注意:深度卷积时,要对其进行分组。
分组是为了减少参数量和计算量,如果仍按照传统的全连接层网络创建的话,参数会多的多。
eg:
传统卷积中,每个输出通道都依赖于所有输入通道的信息。 例如:输入 64 通道,输出 128 通道,传统卷积需要 64×128 个 3×3 卷积核,总参数量为 64×128×3×3 = 73,728。 这种 “全连接” 方式计算开销极大,尤其在深层网络中会导致参数量爆炸。
分组卷积将输入通道和输出通道按组隔离,每组内独立进行卷积,最后拼接结果。 例如:同样是输入 64 通道、输出 128 通道,若设置groups=2:
输入被分为 2 组(每组 32 通道);
输出也被分为 2 组(每组 64 通道);
每组内的卷积:每个输出通道只连接到对应的输入组(如第一组的 64 个输出通道仅由第一组的 32 个输入通道计算得到)。
此时,每组需要 32×64 个 3×3 卷积核,两组总参数量为 2×(32×64×3×3) = 36,864,相比传统卷积减少近一半!
代码验证:
#深度可分离卷积
class depthConv(nn.Module):def __init__(self):super(depthConv,self).__init__()self.c1 = nn.Conv2d(in_channels=8,out_channels=8, #参数量3*3*1*1*8 = 72kernel_size=(3,3),stride=1,padding=0,dilation=1,groups=8) #分组卷积# 这里的c1是深度可分离卷积中的depthwise卷积# 下面的c2是深度可分离卷积中的pointwise卷积self.c2 = nn.Conv2d(in_channels=8,out_channels=8, #参数量8*8*1*1 =64kernel_size=(1,1),stride=1,padding=0,dilation=1,)def forward(self,x):x = self.c1(x)out = self.c2(x)return out#普通卷积
class Conv(nn.Module):def __init__(self):super(Conv,self).__init__()self.c1 = nn.Conv2d(in_channels=8,out_channels=8, #参数量3*3*8*8 = 576kernel_size=(3,3),stride=1,padding=0,dilation=1,)def forward(self,x):out = self.c1(x)return outif __name__ == '__main__':input_data = torch.randn(1,8,32,32) #1表示批次,8表示通道,7表示高度,7表示宽度model = depthConv()out = model(input_data)print(out.shape)moedl2 = Conv()out2 = moedl2(input_data)print(out2.shape)#打印权重参数weight = model.named_parameters()for name,para in weight:print(name,para.shape)print('------------------------')weight2 = moedl2.named_parameters()for name,para in weight2:print(name,para.shape)结果:
torch.Size([1, 8, 30, 30])
torch.Size([1, 8, 30, 30])
c1.weight torch.Size([8, 1, 3, 3])
c1.bias torch.Size([8])
c2.weight torch.Size([8, 8, 1, 1])
c2.bias torch.Size([8])
------------------------
c1.weight torch.Size([8, 8, 3, 3])
c1.bias torch.Size([8])
六、扁平卷积
将标准卷积拆分成3个1*1的卷积核,然后分别对输入层进行卷积计算。
七、分组卷积
将卷积分组放到两个GPU中并发执行。这里的分组和前边深度可分离卷积的分组一样,都是为了解决参数量和计算量的问题。
代码:
#分组卷积
class GroupConv(nn.Module):def __init__(self):super(GroupConv,self).__init__()self.c1 = nn.Conv2d(in_channels=32,out_channels=256, #参数量4*32*3*3*8 = 9216kernel_size=3,stride=1,padding=0,dilation=1,groups=8)def forward(self,x):out = self.c1(x)return outclass Conv(nn.Module):def __init__(self):super(Conv,self).__init__()self.c1 = nn.Conv2d(in_channels=32,out_channels=256, #参数量32*256*3*3 = 73728kernel_size=3,stride=1,padding=0,dilation=1,groups=1)def forward(self,x):out = self.c1(x)return out
if __name__ == '__main__':input_data = torch.randn(1,32,512,512) #1表示批次,32表示通道,512表示高度,512表示宽度model = Conv() #普通卷积out = model(input_data)print(out.shape)model1 = GroupConv() #分组卷积out = model1(input_data)print(out.shape)weight_group = model1.named_parameters()for name,weight in weight_group:print(name,weight.shape)print('上面的是分组权重信息,下面的是普通全连接权重信息------------------------')weight = model.named_parameters()for name,weight in weight:print(name,weight.shape)结果:
torch.Size([1, 256, 510, 510])
torch.Size([1, 256, 510, 510])
c1.weight torch.Size([256, 4, 3, 3])
c1.bias torch.Size([256])
上面的是分组权重信息,下面的是普通全连接权重信息------------------------
c1.weight torch.Size([256, 32, 3, 3])
c1.bias torch.Size([256])
八、混洗分组卷积
分组卷积中最终结果会按照原先的顺序进行合并组合,阻碍了模型在训练时特征信息在通道间流动,削弱了特征表示。混洗分组卷积,主要是将分组卷积后的计算结果混合交叉在一起输出。
九、整体结构--卷积神经网络案例
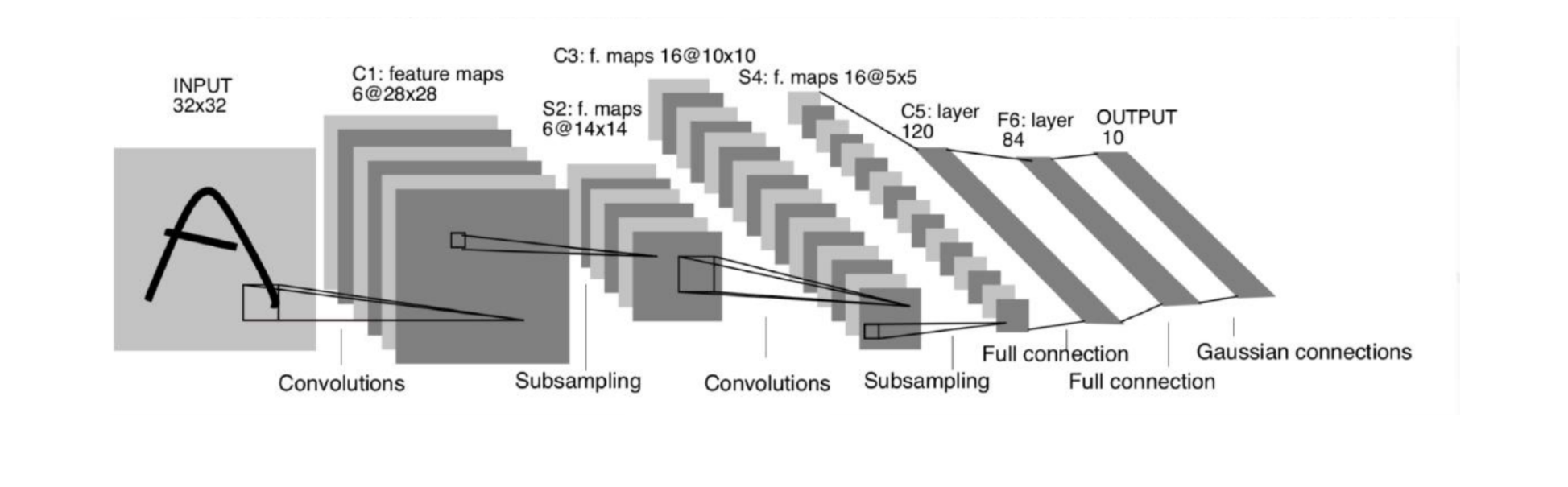
根据该图定义一个可以识别手写数字的卷积神经网络案例:
步骤:
(1)导入数据集
(2)加载数据集
(3)构建网络模型
(4)定义设备、轮次、学习率、优化器、损失函数、数据加载器;
(5)开始训练
(6)模型保存----在代码中暂未体现
(7)模型预测----在代码中暂未体现
代码:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
import os
from torchvision.datasets import MNIST
import torch.optim as optim#定义数据预处理
#数据地址
file_path = os.path.relpath(os.path.join(os.path.dirname(__file__), 'data'))
#定义数据集
train_data = MNIST(root=file_path,train=True,transform=transforms.ToTensor(),download=False)
#查看文件类别,标签
class_names = train_data.classes
print(class_names)#定义数据加载器
train_loader = DataLoader(train_data,batch_size=32,shuffle=True,drop_last=True)
#当设置 drop_last=True 时:
# 如果训练数据总量不能被 batch_size 整除,最后一个样本数量不足 batch_size 的批次会被丢弃。
# 如果设置为 False,最后一个样本数量不足 batch_size 的批次会被保留,但可能会导致训练结果不稳定。#定义网络结构
class MyNet(nn.Module):def __init__(self):super(MyNet,self).__init__()#定义网络结构self.c1 = nn.Sequential(nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5),nn.ReLU())self.s2 = nn.AdaptiveAvgPool2d(14) #自适应地调整为指定大小(这里是 14×14),而无需手动计算核大小、步长等参数。self.c3 = nn.Sequential(nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5),nn.ReLU())self.s4 = nn.AdaptiveAvgPool2d(5)self.l5 = nn.Sequential(nn.Linear(16*5*5,120),nn.ReLU())self.l6 = nn.Sequential(nn.Linear(120,84),nn.ReLU())self.l7 = nn.Linear(84,10)def forward(self,x):#前向传播x = self.c1(x)x = self.s2(x)x = self.c3(x)x = self.s4(x)x = x.view(x.size(0),-1)x = self.l5(x)x = self.l6(x)out = self.l7(x)return out#定义设备、学习率等参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MyNet()
model.to(device)epochs = 20
lr = 0.001
opt = optim.Adam(model.parameters(),lr=lr)
criterion = nn.CrossEntropyLoss()#训练
for epoch in range(epochs):model.train()total_loss = 0acc_total = 0for i,(x,y) in enumerate(train_loader):x,y = x.to(device),y.to(device)opt.zero_grad() #梯度清零out = model(x)out = torch.argmax(out, dim=1)acc_total += (out == y).sum().item()loss = criterion(out,y)total_loss += loss.item()loss.backward() #反向传播opt.step()if i%10 == 0: #每训练10个batch打印一次print(f'epoch:{epoch},loss:{loss.item()}')print("epoch:", epoch, "loss:", total_loss/ len(train_loader.dataset), "acc:", acc_total / len(train_loader.dataset))







)

)









