SCRFD算法核心解析
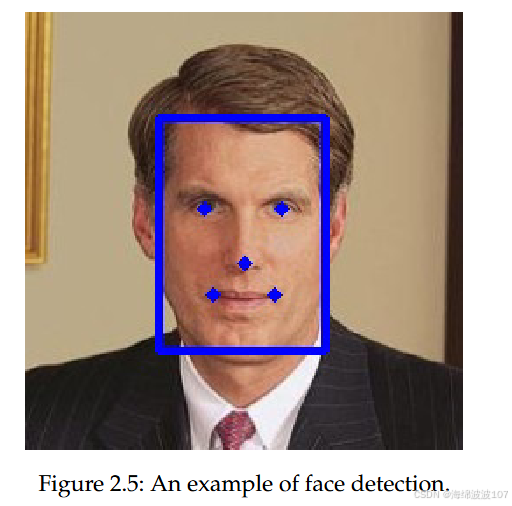
1. 算法定义与背景
SCRFD(Sample and Computation Redistribution for Efficient Face Detection)由Jia Guo等人于2021年在arXiv提出,是一种高效、高精度的人脸检测算法,其核心创新在于:
- 双重重分配策略:
- 样本重分配(SR) :动态增强关键训练阶段的样本数据。
- 计算重分配(CR) :通过神经架构搜索(NAS)优化骨干网络(Backbone)、颈部(Neck)和头部(Head)的计算负载。
- 轻量化设计:支持从0.5GF到34GF的多规格模型,兼顾移动端与高性能设备。

2. 技术架构与创新
架构组成
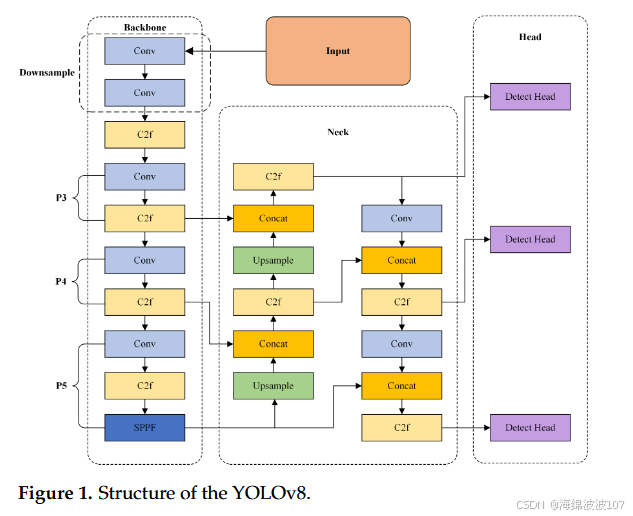
- 骨干网络(Backbone):
- 基于ResNet变体(如CSPDarknet),通过残差连接解决深层网络训练难题。
- 支持量化(FP16/INT8)降低计算量。
- 基于ResNet变体(如CSPDarknet),通过残差连接解决深层网络训练难题。
- 颈部(Neck):
- 采用 特征金字塔网络(FPN) 实现多尺度特征融合,增强小目标检测。
- 引入PANet优化特征传递路径。
- 头部(Head):
- 基于FCOS(Focal Loss)实现无锚框检测,简化输出层。
- 采用八参数回归直接预测边界框坐标。
核心创新机制
- 计算重分配搜索算法:
- 训练阶段:通过NAS动态分配Backbone/Neck/Head的计算比例,最大化资源利用率。
- 硬件加速:
- 存内计算:权重映射至硬件加速单元,减少数据传输。
- 异构加速:支持GPU/TPU/NPU多平台部署。
- 量化优化:FP16/INT8量化降低推理延迟。
3. 性能基准
WIDER FACE数据集表现
| 模型 | Easy AP (%) | Medium AP (%) | Hard AP (%) | 推理延迟 (ms) |
|---|---|---|---|---|
| SCRFD-34GF | 96.06 | 94.92 | 85.29 | 11.7 (V100) |
| RetinaFace-R50 | 94.92 | 91.90 | 64.17 | 21.7 (V100) |
| 数据来源: |
- 效率优势:
- SCRFD-34GF比RetinaFace-R50快 47%(11.7ms vs 21.7ms)。
- SCRFD-0.5GF比RetinaFace-MobileNet0.25快 45.57%。
跨设备优化
- 边缘设备适配:
- 深度可分离卷积(如MobileNet)降低参数量。
- 模型压缩:剪枝/蒸馏技术减少冗余计算。
- 部署实践:
- NVIDIA Jetson系列:支持120 FPS实时推理。
- 内存优化:Memssqueezer架构提升缓存命中率。
4. 与RetinaFace的深度对比
技术差异
| 维度 | SCRFD | RetinaFace |
|---|---|---|
| 检测机制 | 无锚框(FCOS) | 基于锚框 |
| 计算分配 | 动态重分配(CR策略) | 固定计算结构 |
| 硬件适配 | 支持FP16/INT8量化 | 依赖ResNet/MobileNet骨干 |
| 小目标检测 | FPN+多尺度融合优化 | 传统特征金字塔 |
实战性能
- 精度:SCRFD在Hard AP上领先RetinaFace 21.12%(85.29% vs 64.17%)。
- 资源效率:SCRFD-34GF计算量仅为竞品TinaFace的 20%。
- 局限性:批量处理时RetinaFace可能更快。
5. 实现与应用
开源生态
- 代码仓库:`https://github.com/deepinsight/insightface/tree/master/detection/scrfd。
- 训练流程:
- 数据加载:WIDER FACE/MS1M数据集。
- NAS搜索:优化Backbone/Neck/Head计算比例。
- 量化训练:FP16/INT8转换提升推理速度。
- 部署示例:
# FastDeploy示例[[223]] from fastdeploy.vision import SCRFD model = SCRFD("scrfd_10g_fp32.onnx") results = model.predict(image)
论文资源
- 核心文献:
Sample and Computation Redistribution for Efficient Face Detection(arXiv:2105.04714, 2021)。 - 扩展研究:
后续改进融入Transformer架构及遥感检测。
结论
SCRFD通过三重革新——动态计算分配、无锚框检测及量化硬件适配——解决了人脸检测在精度与效率间的矛盾。其在WIDER FACE上85.29%的Hard AP及11.7ms的V100推理延迟,显著优于传统方案(如RetinaFace)。未来方向包括:
- 与Transformer架构结合强化遮挡处理。
- 自适应计算分配支持动态场景。
- 跨平台编译优化进一步压缩延迟。
代码:
class ONNXRuntimeModel:"""一个通用的ONNX模型推理封装类"""def __init__(self, onnx_path):# 使用ONNX Runtime的CUDA执行器providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']self.session = ort.InferenceSession(onnx_path, providers=providers)self.input_name = self.session.get_inputs()[0].nameself.output_names = [output.name for output in self.session.get_outputs()]def __call__(self, input_tensor):# ONNX Runtime 需要 numpy array 作为输入input_feed = {self.input_name: input_tensor.cpu().numpy()}outputs = self.session.run(self.output_names, input_feed)return outputsclass SCRFD():def __init__(self, onnxmodel, confThreshold=0.5, nmsThreshold=0.5):self.inpWidth = 640self.inpHeight = 640self.confThreshold = confThresholdself.nmsThreshold = nmsThresholdself.session = ort.InferenceSession(onnxmodel, providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])self.keep_ratio = Trueself.fmc = 3self._feat_stride_fpn = [8, 16, 32]self._num_anchors = 2def resize_image(self, srcimg):padh, padw, newh, neww = 0, 0, self.inpHeight, self.inpWidthif self.keep_ratio and srcimg.shape[0] != srcimg.shape[1]:hw_scale = srcimg.shape[0] / srcimg.shape[1]if hw_scale > 1:newh, neww = self.inpHeight, int(self.inpWidth / hw_scale)img = cv2.resize(srcimg, (neww, newh), interpolation=cv2.INTER_AREA)padw = int((self.inpWidth - neww) * 0.5)img = cv2.copyMakeBorder(img, 0, 0, padw, self.inpWidth - neww - padw, cv2.BORDER_CONSTANT,value=0) # add borderelse:newh, neww = int(self.inpHeight * hw_scale) + 1, self.inpWidthimg = cv2.resize(srcimg, (neww, newh), interpolation=cv2.INTER_AREA)padh = int((self.inpHeight - newh) * 0.5)img = cv2.copyMakeBorder(img, padh, self.inpHeight - newh - padh, 0, 0, cv2.BORDER_CONSTANT, value=0)else:img = cv2.resize(srcimg, (self.inpWidth, self.inpHeight), interpolation=cv2.INTER_AREA)return img, newh, neww, padh, padwdef distance2bbox(self, points, distance, max_shape=None):x1 = points[:, 0] - distance[:, 0]y1 = points[:, 1] - distance[:, 1]x2 = points[:, 0] + distance[:, 2]y2 = points[:, 1] + distance[:, 3]if max_shape is not None:x1 = x1.clamp(min=0, max=max_shape[1])y1 = y1.clamp(min=0, max=max_shape[0])x2 = x2.clamp(min=0, max=max_shape[1])y2 = y2.clamp(min=0, max=max_shape[0])return np.stack([x1, y1, x2, y2], axis=-1)def distance2kps(self, points, distance, max_shape=None):preds = []for i in range(0, distance.shape[1], 2):px = points[:, i % 2] + distance[:, i]py = points[:, i % 2 + 1] + distance[:, i + 1]if max_shape is not None:px = px.clamp(min=0, max=max_shape[1])py = py.clamp(min=0, max=max_shape[0])preds.append(px)preds.append(py)return np.stack(preds, axis=-1)def detect(self, srcimg):img, newh, neww, padh, padw = self.resize_image(srcimg)blob = cv2.dnn.blobFromImage(img, 1.0 / 128, (self.inpWidth, self.inpHeight), (127.5, 127.5, 127.5), swapRB=True)blob = np.ascontiguousarray(blob)# onnxruntime输入通常是NCHWort_inputs = {self.session.get_inputs()[0].name: blob}ort_outs = self.session.run(None, ort_inputs)outs = ort_outs # 结构与原OpenCV DNN输出一致# 后续逻辑保持不变scores_list, bboxes_list, kpss_list = [], [], []for idx, stride in enumerate(self._feat_stride_fpn):scores = outs[idx][0]bbox_preds = outs[idx + self.fmc * 1][0] * stridekps_preds = outs[idx + self.fmc * 2][0] * strideheight = blob.shape[2] // stridewidth = blob.shape[3] // strideanchor_centers = np.stack(np.mgrid[:height, :width][::-1], axis=-1).astype(np.float32)anchor_centers = (anchor_centers * stride).reshape((-1, 2))if self._num_anchors > 1:anchor_centers = np.stack([anchor_centers] * self._num_anchors, axis=1).reshape((-1, 2))pos_inds = np.where(scores >= self.confThreshold)[0]bboxes = self.distance2bbox(anchor_centers, bbox_preds)pos_scores = scores[pos_inds]pos_bboxes = bboxes[pos_inds]scores_list.append(pos_scores)bboxes_list.append(pos_bboxes)kpss = self.distance2kps(anchor_centers, kps_preds)kpss = kpss.reshape((kpss.shape[0], -1, 2))pos_kpss = kpss[pos_inds]kpss_list.append(pos_kpss)scores = np.vstack(scores_list).ravel()bboxes = np.vstack(bboxes_list)kpss = np.vstack(kpss_list)bboxes[:, 2:4] = bboxes[:, 2:4] - bboxes[:, 0:2]ratioh, ratiow = srcimg.shape[0] / newh, srcimg.shape[1] / newwbboxes[:, 0] = (bboxes[:, 0] - padw) * ratiowbboxes[:, 1] = (bboxes[:, 1] - padh) * ratiohbboxes[:, 2] = bboxes[:, 2] * ratiowbboxes[:, 3] = bboxes[:, 3] * ratiohkpss[:, :, 0] = (kpss[:, :, 0] - padw) * ratiowkpss[:, :, 1] = (kpss[:, :, 1] - padh) * ratioh# NMS# 可用PyTorch或onnxruntime自带的NMS,也可以保留cv2.dnn.NMSBoxesif len(bboxes) == 0:return []bboxes_xyxy = np.stack([bboxes[:,0], bboxes[:,1], bboxes[:,0]+bboxes[:,2], bboxes[:,1]+bboxes[:,3]], axis=1)keep = torch.ops.torchvision.nms(torch.tensor(bboxes_xyxy, dtype=torch.float32), torch.tensor(scores, dtype=torch.float32), self.nmsThreshold)detections = []for i in keep:i = i.item()x1, y1 = int(bboxes[i, 0]), int(bboxes[i, 1])x2, y2 = int(bboxes[i, 0] + bboxes[i, 2]), int(bboxes[i, 1] + bboxes[i, 3])box = [x1, y1, x2, y2]score = float(scores[i])kps = kpss[i]detections.append([box, score, kps])return detections这段代码实现了一个功能完整的人脸检测器。它使用了名为 SCRFD 的先进人脸检测模型,并通过 ONNX Runtime 库来运行这个模型,从而可以在不同的硬件(CPU或GPU)上高效执行。
代码的核心目标是:输入一张图片,输出图片中所有检测到的人脸信息,包括位置(边界框)、置信度分数和五官关键点。
1. 整体结构概览
这个 SCRFD 类可以看作一个“黑盒子”。你只需要关心两件事:
-
初始化 (__init__): 告诉它你的模型文件在哪里,以及你对检测结果的要求(置信度、重叠框合并的阈值)。
-
检测 (detect): 给它一张图片,它会返回检测结果。
所有复杂的中间步骤,比如图像预处理、模型推理、结果后处理,都被封装在了类的内部方法中。
2. __init__ 构造函数:初始化检测器
class SCRFD():def __init__(self, onnxmodel, confThreshold=0.5, nmsThreshold=0.5):# 1. 设置模型输入尺寸self.inpWidth = 640self.inpHeight = 640# 2. 设置阈值self.confThreshold = confThreshold # 置信度阈值self.nmsThreshold = nmsThreshold # NMS阈值# 3. 加载ONNX模型self.session = ort.InferenceSession(onnxmodel, providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])# 4. 设置模型相关参数self.keep_ratio = Trueself.fmc = 3 # Feature Map Count, 每个输出头(score/bbox/kps)有3个特征图self._feat_stride_fpn = [8, 16, 32] # FPN的步长self._num_anchors = 2 # 每个位置的锚点数量逐行解释:
-
self.inpWidth, self.inpHeight: 定义了模型需要的标准输入图像尺寸为 640x640 像素。任何输入图片都会被调整到这个尺寸。
-
self.confThreshold: 置信度阈值。模型会对每个可能的人脸位置给出一个分数(0到1之间),表示“这里是人脸”的可信度。只有分数高于这个阈值(默认0.5)的才会被认为是有效检测。
-
self.nmsThreshold: 非极大值抑制 (NMS) 阈值。模型可能会对同一个脸输出多个高度重叠的边界框。NMS算法会移除多余的框,只保留最好的一个。这个阈值决定了两个框重叠到什么程度才算“多余”。
-
self.session = ort.InferenceSession(...): 这是核心部分。它使用 onnxruntime 库加载你提供的 .onnx 模型文件。providers 参数指定了推理后端,'CUDAExecutionProvider' 表示优先使用NVIDIA GPU(如果可用),否则回退到 'CPUExecutionProvider' 使用CPU。
-
self.keep_ratio: 一个布尔标志,决定在调整图像大小时是否保持原始图像的宽高比。True 表示保持,这可以防止人脸变形,提高检测精度。
-
self.fmc, _feat_stride_fpn, _num_anchors: 这些是与SCRFD模型架构紧密相关的超参数。
-
_feat_stride_fpn = [8, 16, 32]: SCRFD使用了特征金字塔网络(FPN),它在不同大小的特征图上进行预测。步长(stride)为8的特征图用来检测小人脸,16的检测中等大小人脸,32的检测大人脸。
-
_num_anchors = 2: 在特征图的每个位置,模型会预设2个不同尺寸的“锚点框”(anchor),并基于这些锚点框进行预测。
-
3. resize_image 方法:图像预处理
def resize_image(self, srcimg):# ... (代码)这个函数负责将你输入的任意尺寸的原始图像 (srcimg) 转换成模型需要的 640x640 格式。
-
如果 self.keep_ratio 为 True (默认):
-
计算原始图像的宽高比。
-
将图像等比例缩放,使其最长边等于640。
-
为了补足到 640x640,在较短的那一边上下或左右填充黑边 (cv2.copyMakeBorder)。
-
返回处理后的图像 (img) 以及填充的尺寸信息 (padh, padw),这些信息在后续恢复坐标时至关重要。
-
-
如果 self.keep_ratio 为 False:
-
它会粗暴地将图像直接拉伸或压缩到 640x640,这可能会导致人脸变形。
-
4. distance2bbox 和 distance2kps 方法:解码模型输出
def distance2bbox(self, points, distance, max_shape=None):# ... (代码)
def distance2kps(self, points, distance, max_shape=None):# ... (代码)SCRFD模型的一个特点是,它不直接预测边界框的坐标 (x1, y1, x2, y2)。相反,它预测的是:
-
对于每个“锚点”,其中心到真实人脸边界框四条边的距离。
-
对于每个“锚点”,其中心到真实人脸每个关键点的位移。
这两个函数就是用来做逆运算的,将模型输出的“距离/位移”解码成我们能理解的“坐标”。
-
distance2bbox: 输入锚点中心坐标 (points) 和模型预测的4个距离值 (distance),计算出最终的边界框坐标 [x1, y1, x2, y2]。
-
distance2kps: 输入锚点中心坐标 (points) 和模型预测的关键点位移 (distance),计算出最终的5个关键点坐标 [x_eye1, y_eye1, x_eye2, y_eye2, ...]。
5. detect 方法:核心检测流程
这是整个类的“主心骨”,它串联起了所有步骤。
def detect(self, srcimg):# 步骤1: 图像预处理img, newh, neww, padh, padw = self.resize_image(srcimg)blob = cv2.dnn.blobFromImage(img, 1.0 / 128, (self.inpWidth, self.inpHeight), (127.5, 127.5, 127.5), swapRB=True)# 步骤2: 模型推理ort_inputs = {self.session.get_inputs()[0].name: blob}ort_outs = self.session.run(None, ort_inputs)# 步骤3: 结果后处理与解码# ... (循环处理不同stride的输出)for idx, stride in enumerate(self._feat_stride_fpn):# 从模型输出中提取 score, bbox, kps# 创建锚点网格# 筛选出分数 > confThreshold 的结果# 使用 distance2bbox 和 distance2kps 解码# ...# 步骤4: 整合与坐标还原# ... (合并所有stride的结果)# 将坐标从 640x640 的填充图映射回原始图像# 步骤5: 非极大值抑制 (NMS)# ...keep = torch.ops.torchvision.nms(...) # 使用PyTorch的NMS# 步骤6: 格式化输出# ...# 将最终保留下来的结果整理成 [box, score, kps] 的格式并返回return detections详细流程分解:
-
图像预处理:
-
调用 resize_image 将图片调整为带黑边填充的 640x640 图像。
-
cv2.dnn.blobFromImage: 这是非常关键的一步。它将图像转换为一个“Blob”,也就是模型需要的4D张量格式 (N, C, H, W)。同时,它还做了两件事:
-
归一化: 1.0 / 128 和 (127.5, 127.5, 127.5) 将像素值从 [0, 255] 范围转换到 [-1, 1] 范围。
-
通道转换: swapRB=True 将OpenCV默认的BGR顺序转换为模型需要的RGB顺序。
-
-
-
模型推理:
-
将 blob 作为输入,调用 self.session.run 执行模型推理,得到模型的原始输出 ort_outs。ort_outs 是一个包含多个Numpy数组的列表,分别对应人脸分数、边界框距离和关键点位移。
-
-
结果后处理与解码:
-
这是一个循环,分别处理来自步长8、16、32的三个特征图的预测结果。
-
对于每个特征图:
-
它首先生成该特征图上所有的锚点中心坐标 (anchor_centers)。
-
然后,它用 self.confThreshold 过滤掉所有置信度低的结果。
-
最后,对保留下来的高置信度结果,调用 distance2bbox 和 distance2kps 将其解码为实际的边界框和关键点坐标。
-
-
-
整合与坐标还原:
-
将三个特征图解码出的所有结果(框、分数、关键点)合并在一起。
-
坐标还原:这是至关重要的一步。因为之前的预测都是基于640x640的填充图像,现在需要利用 resize_image 返回的 ratioh, ratiow, padh, padw,通过数学计算,将坐标映射回原始输入图像的尺寸和位置。
-
-
非极大值抑制 (NMS):
-
此时,我们可能有很多重叠的框。torch.ops.torchvision.nms 函数会根据 self.nmsThreshold 剔除冗余的检测框,只为每个真实人脸保留一个得分最高的框。
-
-
格式化输出:
-
遍历NMS后保留下来的结果索引 keep。
-
将每个检测结果整理成一个包含 [边界框, 分数, 关键点] 的列表。
-
返回这个包含所有检测结果的列表。
-
总结
这个 SCRFD 类是一个高度封装、流程清晰的人脸检测器。其工作流可以总结为:
输入原图 -> 预处理(缩放/填充/归一化) -> 模型推理 -> 解码(将模型输出转为坐标) -> 坐标还原(映射回原图) -> NMS(去重) -> 输出最终结果。
你只需要准备好一个 scrfd_..._.onnx 模型文件(已发布在我的资源),然后像下面这样使用它:
import cv2
import numpy as np
import onnxruntime as ort
import torch # NMS需要torch# 假设你的 SCRFD 类代码保存在 scrfd.py 文件中# 1. 初始化检测器
model_path = "scrfd_2.5g_kps.onnx" # 你的模型路径
face_detector = SCRFD(onnxmodel=model_path, confThreshold=0.5, nmsThreshold=0.5)# 2. 读取图片
image = cv2.imread("your_image.jpg")# 3. 执行检测
detections = face_detector.detect(image)# 4. 可视化结果
if detections:print(f"检测到 {len(detections)} 张人脸。")for box, score, kps in detections:x1, y1, x2, y2 = box# 画框cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)# 画关键点for i in range(kps.shape[0]):cv2.circle(image, (int(kps[i, 0]), int(kps[i, 1])), 2, (0, 0, 255), -1)# 显示结果
cv2.imshow("Detected Faces", image)
cv2.waitKey(0)
cv2.destroyAllWindows()

)


线性表(上):SeqList 顺序表)

)
)


——PROJECT#0)




![[Dify] -进阶4-在 Dify 中实现 PDF 文档问答功能全流程](http://pic.xiahunao.cn/[Dify] -进阶4-在 Dify 中实现 PDF 文档问答功能全流程)


