目录
工具展示和使用说明
工具标注后文件展示说明
json转换成单个npy文件
数据获取补充
工具展示和使用说明
文件名labelV.py集于PySide6实现:
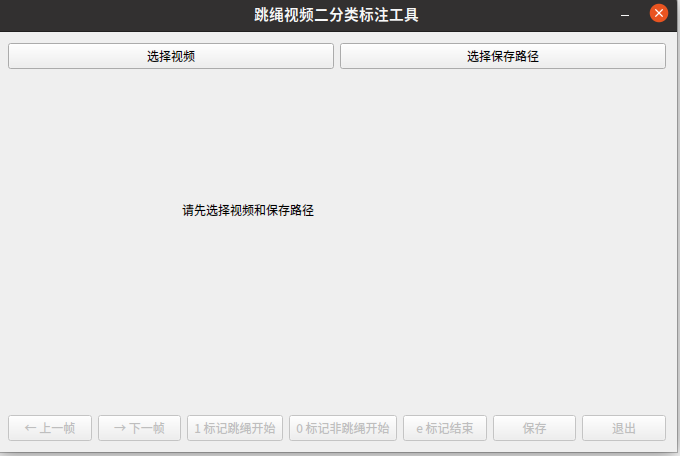
通过选择视频来选择你要标注的视频,然后选择保存路径:
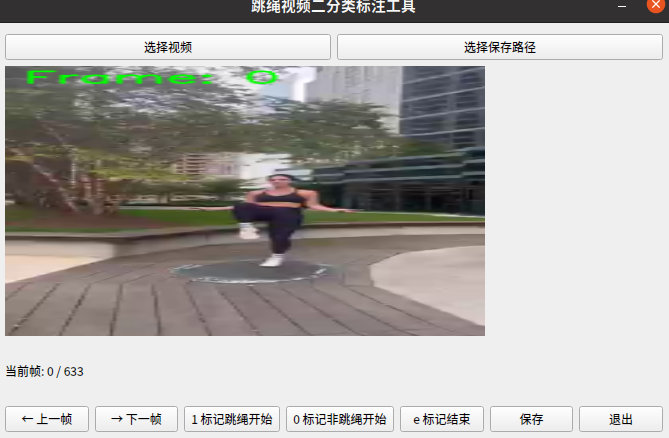
然后视频两个类别。当你看见视频中的人跳绳开始时,按键盘1或者点击来标记开始帧号,按键盘左右键调转上下帧,按e结束标记(这里我每一百帧标记一次)。
工具标注后文件展示说明
{"segments": [[36,140,1],[141,243,1],[255,360,1],[370,476,1],[477,590,1],[591,693,1],[706,776,1]]
}保存后会得到这样一个json文件,这里每一个列表中的内容分别代表开始事件帧数,结束事件帧数,事件类别。
json转换成单个npy文件
代码名jsonNpy.py,我这里用的时yolov8-pose模型,
def process_segment(video_path, start, end, label, output_name):cap = cv2.VideoCapture(video_path)T = end - start + 1skeleton = np.zeros((2, T, 17, 1), dtype=np.float32)valid = Truefor i, frame_idx in enumerate(range(start, end + 1)):cap.set(cv2.CAP_PROP_POS_FRAMES, frame_idx)ret, frame = cap.read()if not ret:print(f"[!] 无法读取帧 {frame_idx} in {video_path}")valid = Falsebreakkeypoints = extract_keypoints(frame)if keypoints is None or keypoints.shape != (17, 2):print(f"[!] 关键点提取失败 at frame {frame_idx}")valid = Falsebreakfor v in range(17):skeleton[0, i, v, 0] = keypoints[v][0]skeleton[1, i, v, 0] = keypoints[v][1]cap.release()if valid:out_path = os.path.join(OUTPUT_DIR, output_name)np.save(out_path, skeleton)label_list.append({"sample_name": output_name,"label": label})else:print(f"[✘] 放弃片段: {start}-{end} in {video_path}")通过opencv读取视频帧再根据标注文件json中的信息完成保存成npy文件,数组形状[2, T, 17, 1],2代表存储的关键点的x和y坐标,T代表帧数,这里我选择的是100,17代表关键点数量是17(这里根据你选择的模型来,比如openpose的话这里就是18)。1代表一个人。同时保存一个总的json文件,来记录每一个npy的类别:
{"sample_name": "nojump_output_0189.npy","label": 0},{"sample_name": "nojump_output_0190.npy","label": 0},{"sample_name": "nojump_output_0191.npy","label": 0},数据获取补充
鉴于自己标准视频实在是费时费力,本文提供了一个脚本autoLabel.py,
def main():# 加载现有 label.json(如果存在)label_list = []if os.path.exists(LABEL_JSON):with open(LABEL_JSON, "r") as f:label_list = json.load(f)# 处理 label1 文件夹(跳绳,类别 1)for video_file in os.listdir(LABEL1_DIR):if video_file.endswith((".mp4", ".avi", ".mov")):video_path = os.path.join(LABEL1_DIR, video_file)sample_prefix = f"jump_{Path(video_file).stem}"new_samples = extract_skeleton_from_video(video_path, label=1, output_dir=OUTPUT_DIR,sample_prefix=sample_prefix)label_list.extend(new_samples)# 处理 label0 文件夹(非跳绳,类别 0)for video_file in os.listdir(LABEL0_DIR):if video_file.endswith((".mp4", ".avi", ".mov")):video_path = os.path.join(LABEL0_DIR, video_file)sample_prefix = f"nojump_{Path(video_file).stem}"new_samples = extract_skeleton_from_video(video_path, label=0, output_dir=OUTPUT_DIR,sample_prefix=sample_prefix)label_list.extend(new_samples)# 保存 label.jsonwith open(LABEL_JSON, "w") as f:json.dump(label_list, f, indent=4)print(f"[✔] 骨架数据提取完成,保存到 {OUTPUT_DIR},标签更新到 {LABEL_JSON}")print(f"总样本数: {len(label_list)}")你可以将跳绳视频和非跳绳视频分别放到两个文件夹中,配置好相关信息,然后会自动帮你生成npy文件。
后续更新数据汇总和预处理



)














封装、继承和多态)
)