

7月15日,国产数据库厂商中电科金仓(北京)科技股份有限公司(以下简称“电科金仓”)在北京举行了一场技术发布会,集中发布四款核心产品:AI时代的融合数据库KES V9 2025、企业级统一管控平台KEMCC、数据库一体机(云数据库AI版)以及企业级智能海量数据集成平台KFS Ultra,并同步举行了“金兰组织2.0”启动仪式。
如果放在过去几年,这场发布会可能被归入“信创替代”的常规范畴。但这一次,电科金仓试图讲述的不再是“我们也能做、我们可以兼容”,而是“我们能不能定义下一代数据库形态”。
整个发布会贯穿了三个关键词:“融合”“AI”“平台能力”。这背后的核心逻辑是清晰的:在“去IOE”与“兼容Oracle”的红利渐近尾声之际,国产数据库厂商开始面对一个更加复杂、也更具挑战性的市场命题——如何在大模型时代支撑非结构化数据、高维向量检索和复杂语义计算的新需求?
正如我国数据库学科带头人王珊教授所说,数据库内核与AI能力的深度结合,已成为释放数据核心价值的关键路径,正催生着更智能、更自适应、更能应对复杂挑战的新一代数据库形态。这不仅是一个技术问题,更是产业方向选择的问题。而电科金仓,作为国产数据库厂商中的代表性玩家,选择了用“融合数据库”体系作为回应。
本文将试图厘清三个核心问题:
- “融合数据库”究竟意味着什么?它与传统数据库有何本质差异?
- 电科金仓的产品和技术体系是否真正构成了“融合能力”?它和“功能叠加”有何不同?
- 在AI深度嵌入企业业务的当下,这种融合路线是否能成为国产数据库的新锚点?
十年前,中国数据库行业的关键词是“去IOE”与“国产替代”。在国家自主可控政策推动下,以政府、电信、金融、能源等关键领域为代表,信息系统加速从Oracle、IBM DB2等国外数据库向国产方案迁移。在这一背景下,一批国产数据库厂商迅速崛起,其主要任务是完成“可用、可控、兼容”的目标:对上层业务保持接口一致性,对底层系统实现稳定承载。
金仓数据库正是在这一阶段建立了其在国产数据库行业的核心位置。凭借与Oracle高度兼容的技术路线、平滑迁移工具链以及在关键系统中的稳定表现,金仓数据库产品广泛应用于金融、电信、能源、交通、医疗、制造等多个重点行业,累计部署超100万套。多个行业数据显示,当前国产数据库在政府行业的渗透率已经较高,在金融、能源、电信等领域也实现规模化部署。
然而,随着“信创替代”阶段性任务逐步完成,国产数据库行业开始进入一个更具挑战性的“后信创时代”。这一阶段的核心问题不再是“是否兼容、替代Oracle”,而是能否适配AI驱动下的新一代数据需求和系统形态。
以大模型为代表的新型AI应用快速普及,数据模型不断增加:从结构化数据扩展至非结构化文本、图像、音频、视频;从二维表格拓展至高维向量、知识图谱与时序流。随之而来的,是更复杂的查询负载、更动态的部署形态、更高并发与低延迟的性能要求,以及对模型推理与语义理解能力的数据库原生支持。
与此同时,传统数据库产品“分门别类”的技术架构开始显露疲态:关系型数据库难以适配图数据与向量索引,专用数据库难以统一管控与调度,数据孤岛与工具链碎片化问题愈发严重。
也就是说,当数据库面对的不只是“存数据、查数据”,而是作为整个AI工作流的数据中枢时,其产品能力、架构底层、生态整合模式,都需要重构。
在这样的背景下,“融合数据库”成为国产数据库厂商所普遍关注的下一阶段技术路径。它不仅是一个产品概念,更是一种架构性、体系化的战略选择:打破不同数据模型、查询语法、运行环境、运维体系之间的壁垒,构建一个面向未来的数据处理基础设施平台。
对于国产数据库而言,这不仅是一条技术演进路线,也是一个新的战略方向。
“融合数据库”不是产品组合的宣传术语,而是一种架构层面的内生能力。电科金仓不是通过多个产品之间的拼接来构建所谓“融合能力”,而是选择把这一理念深度注入到其核心产品——KES V9 2025融合数据库引擎之中。
这是一款真正意义上的“底座级产品”,承载了电科金仓对下一代数据库形态的理解,也代表了国产数据库从“平替时代”向“范式定义”的跃迁尝试。
电科金仓提出的“五个一体化”融合理念,就落地于KES V9 2025的设计之中:
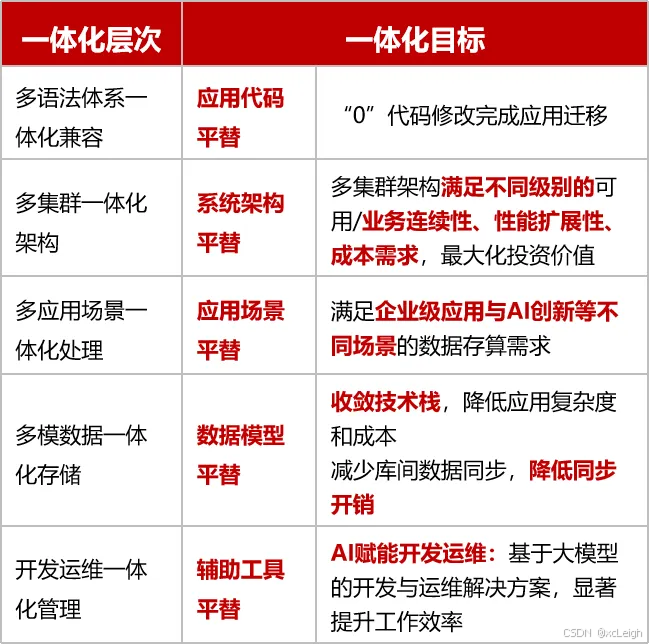
数据模型一体化:原生支持结构化、文档、图、时序、向量等五大主流数据模型,在同一个引擎中实现统一存储与查询;
语法兼容一体化:在异构兼容方面,KES V9 2025除覆盖Oracle、MySQL常用功能外,还新增了SQL Server和Sybase兼容模式,覆盖率分别达到99%与95%,大幅降低用户切换门槛;
部署形态一体化:支持集中式、分布式、读写分离、RAC等多种形态的灵活部署,满足从核心业务系统到边缘节点的多样化需求;
开发运维一体化:打通监控、调优、自愈、巡检等全生命周期运维能力,构建面向大规模集群的运维支撑体系;
应用场景一体化:从传统政务、金融等核心业务场景,到AI原生场景如语义检索、RAG问答等,均实现适配与优化。
更重要的是,这一切并非功能模块的拼装,而是通过内核级架构重构实现的“融合内生性” —— 多模数据无需切换引擎、查询无需跨系统协调、部署与运维无需分别建设。这使得KES V9 2025成为支撑“融合数据库”愿景的真正技术载体。
需要指出的是,电科金仓不是为了融合而融合,融合数据库是为了更好地支撑多场景下的应用、更好地满足市场上涌现的新需求,尤其是为AI的规模化商用奠定坚实基础。
围绕“AI for DB”和“DB for AI”两个维度,电科金仓打造了深入融合AI能力的产品体系,此次发布的四款产品均融入了AI能力,并构建起一套支撑AI应用与赋能数据库管理的完整能力矩阵。
☆KES V9 2025:智能融合主引擎
该产品在多数据模型融合上,新增了对键值、文档、向量数据模型支持,满足AI场景等新型业务需求,通过单条SQL就能完成跨模型复杂检索。在系统管理上,通过融合AI技术的智能优化器、全诊断过程支撑及SQL映射应急机制,实现从性能问题感知到自治优化的完整链路,大幅降低人工管理成本。
☆云数据库一体机(AI版):交付即智能
该一体机搭载“的卢运维智能体”,创新引入AI交互式运维模式,用户通过自然语言即可驱动数据库进行自治运维操作,通过AI驱动SQL优化,让数据库越用越快,并可通过AI实现告警自动处置闭环,故障预警准确率高达98%以上,大幅提升了运维效率与易用性。
AI版一体机可在分钟级完成部署,实现“开箱即用、自主运行”的交付体验。
☆KFS Ultra:打通数据流动的“动脉系统”
融合的前提是数据的广泛接入与调度。KFS Ultra作为金仓“数据动脉”,支持结构化、半结构化、非结构化数据的统一同步与管理。KFS Ultra还创新引入“掣电融合数据复制引”,日吞吐量可达千亿级。该产品通过AI智能算力调度,有效消除卡顿延迟,保障业务持续流畅运行。同时内置“K宝”智能助手,提供覆盖部署、优化、诊断的AI运维支持。
☆KEMCC:让数据库管理走向智能化
KEMCC作为融合体系的“管控大脑”,覆盖从部署到运维的整个生命周期管理。它提供集中式监控、自动巡检、优化建议输出,并内嵌AI辅助决策能力,支撑大规模、多实例数据库资产的统一调度。
在接受媒体采访时,电科金仓指出,这四款产品不是独立存在,而是面向AI应用构成“融合数据库平台”的四个维度:KES是内核,KFS是数据流动层,KEMCC是管控层,一体机是交付层,共同形成从底层到交付的全栈一体化平台。
此外,融合不是单靠数据库厂商自身能完成的。此次发布会上,电科金仓同步宣布品牌升级,正式推出“数据库平替用金仓”的新口号,意图强化其在国产数据库替代与智能化演进中的双重角色。
电科金仓在发布会上同步推出了“金兰组织2.0”计划,在1.0阶段基础上,金兰组织2.0不仅“破圈”聚合政产学研多方力量,还提出将影响力由中国拓展至全球,以共建技术生态、共享创新成果为目标,打造国产数据库走向国际的新平台。

这种协同体系,某种程度上是对Oracle+NVIDIA、Snowflake+OpenAI等国外组合形态的国产对标。
电科金仓透露,目前其融合数据库已在大量客户场景中部署了AI场景的向量能力,涵盖金融知识问答、交通图像查询、政务语义搜索等典型RAG应用场景。
过去几十年,数据库作为信息系统的“后端模块”,其核心使命是存储、组织与查询结构化数据。在这一范式下,SQL语言、关系模型、事务机制构成了现代数据库的基础逻辑,也塑造了像Oracle、MySQL这样的经典技术形态。
但AI时代的到来打破了这一认知边界。
1. 数据库需要被重新发明一次
大模型不仅在重写前端应用逻辑,也在倒逼后端数据系统彻底重构:
- 输入不再是清晰的字段,而是模糊的语义;
- 数据不再仅是表格,而是图谱、文档、视频、向量;
- 查询不再是规则匹配,而是理解意图后的智能召回。
这意味着,数据库不仅要处理数据,还要理解数据、参与计算、驱动推理。
电科金仓的“融合数据库”路线正是在这种背景下做出的回应。它不是某个单点技术的演进,而是一种底层架构与产品角色的集体重写——从“兼容Oracle”转向“AI双向赋能”;从“功能堆叠”转向“内核融合”;从“数据库工具”转向“数据基础设施平台”。
这条路径的特别之处在于,它标志着国产数据库厂商第一次在新一代技术范式转型中实现了“同步起跑”。
过去,在关系型数据库时代,中国厂商普遍追赶国外技术标准;在NoSQL和NewSQL浪潮中,受限于应用规模和场景契合度,多数厂商没有进入主舞台。而今天,AI对数据库提出的全新要求,让所有厂商都必须重新开始。而国产厂商,终于站在了同一起跑线上。
电科金仓选择从平台视角构建融合数据库,不再满足于“能用”“替代”,而是试图抓住“AI时代的结构性重构机会”,以“融合”作为切入点,对下一代数据库形态下注。这既是一次尝试,也是一种突破。
“数据库需要被重新发明一次”——AI不是加功能,而是改底座。而电科金仓为代表的国产数据库厂商,正在尝试拿回定义权。
2. 格局未定,谁都有机会登顶
数据库行业正在经历一次罕见的结构性重塑期。例如,Oracle正在重构其AI支撑能力,重新定义Exadata与OCI的位置;MongoDB早已放下“文档数据库”的标签,全力投入AI for DB与向量检索;Snowflake则不断将自己延展为数据云平台,与OpenAI展开深度集成。
这一切都说明:传统数据库巨头也必须进化才能在AI时代存活。
而对于国产数据库厂商而言,这是历史性机遇。以往,无论是事务模型、查询引擎还是集群架构,国产厂商都要从追赶开始;但今天,向量计算、知识索引、语义检索、RAG中枢,这些新能力没有明确标准,也没有绝对领先者。
这是一个“技术范式重启”的时代,第一次给予了国产厂商与全球同行“同步构建”的机会。
在这一波技术迁移中,电科金仓的动作已足够快——它不是唯一的探索者,但它是少数“明确提出融合、快速落地产品、形成体系闭环”的玩家之一。
这不仅是一次产品迭代,更是一场产业角色的转换。过去它是“国产替代者”,未来它可能成为“架构重构者”。在新一轮数据库形态变革中,电科金仓选择的“融合数据库平台”路线,既是基础能力的升级,也是一种未来图景的表达。
至于它能否成为中国版的“Oracle+Snowflake”,这一判断需要交给时间。但可以确定的是,它已经踏出了至关重要的第一步:不再问“我们能否替代”,而是问“我们能否定义”。
电科金仓董事长仲恺指出,数据库作为数字中国建设的核心支撑,正成为激活新质生产力的关键引擎。因此,随着数字经济、新质生产力的快速发展,国产数据库有广阔的市场前景。据中国通信标准化协会大数据技术标准推进委员会 (CCSA TC601) 发布的《数据库发展研究报告(2024年)》,预计到2028年,中国数据库市场总规模将达到930.29亿元,市场年复合增长率 (CAGR) 为12.23%。
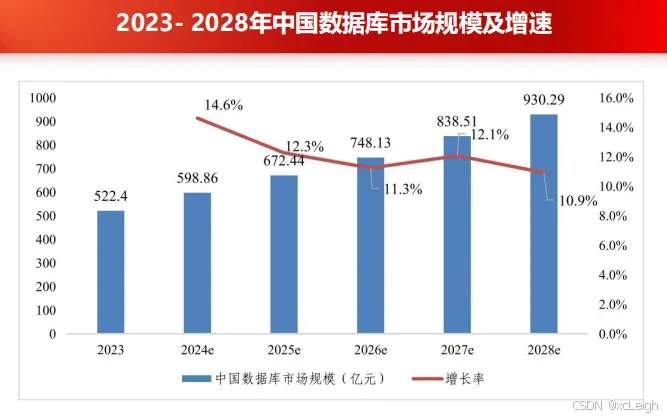
可谓天地宽阔,任君翱翔。天时、地利、人和,时代给了我们一次难得的机会,希望国产数据库厂商不要浪费了。
来源: 数据猿


设计原则之合成复用原则)
)

)


)





list的使用)




