文章目录
- 哈希表
- 哈希表知识点
- 哈希表概念
- 负载因子
- 哈希表的优缺点
- 哈希冲突
- 哈希函数
- 常见哈希函数
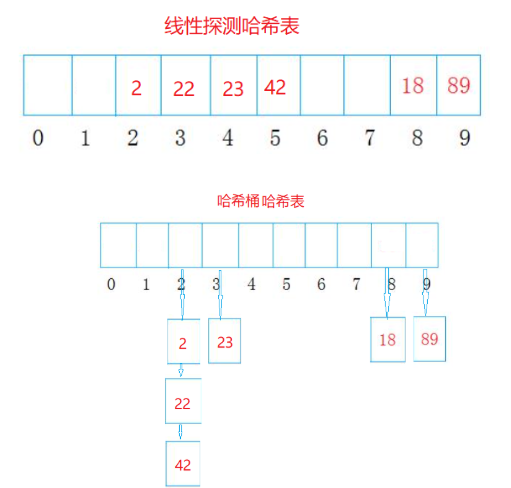
- 处理哈希冲突
- 开放定址法
- 线性探测
- 二次探测
- 链地址法
- 哈希表的实现
- 哈希表的核心:==HashMap==
- 核心函数:从创建到销毁
- 创建哈希表:hashmap_create()
- 销毁哈希表:hashmap_destroy
- 插入键值对:hashmap_put
- 查找键对应的值:hashmap_get
- 删除键值对:hashmap_remove
- 拷贝函数:strdup1(const char* s)
- 哈希函数
- 测试函数
- 完整代码
哈希表
哈希表知识点
哈希表概念
哈希表是一种以关联方式存储数据的数据结构。在哈希表中,数据以数组格式存储,其中每个数据值都有自己的唯一的索引值。哈希表也叫散列表,是根据关键码值(Key Value)而直接进行访问的数据结构。它通过把关键码之值映射到表中一个位置来访问记录。
简单来讲其实数组就是一张哈希表,如同所示:
负载因子
概念:衡量哈希表填充程度的核心指标,直接关联数据结构的存储效率与操作性能。其数值由已存元素数量除以哈希表总容量得出,合理控制负载因子能有效平衡空间利用率和操作速度。
假设哈希表中已经映射存储了N个值,哈希表的大小为M,那么负载因子为:
a = N/M
哈希表的优缺点
优点
简化了比较过程,效率大大提高。
缺点
1.散列技术不适合集合中重复元素很多的情形,因为这样的话同样的key;
2.散列技术不适合范围查找 也不适合查找最大值,最小值.这些都无法从散列函数中计算出来
3.散列函数需要很好的设计,应该保证简单 均匀 存储效率高
哈希冲突
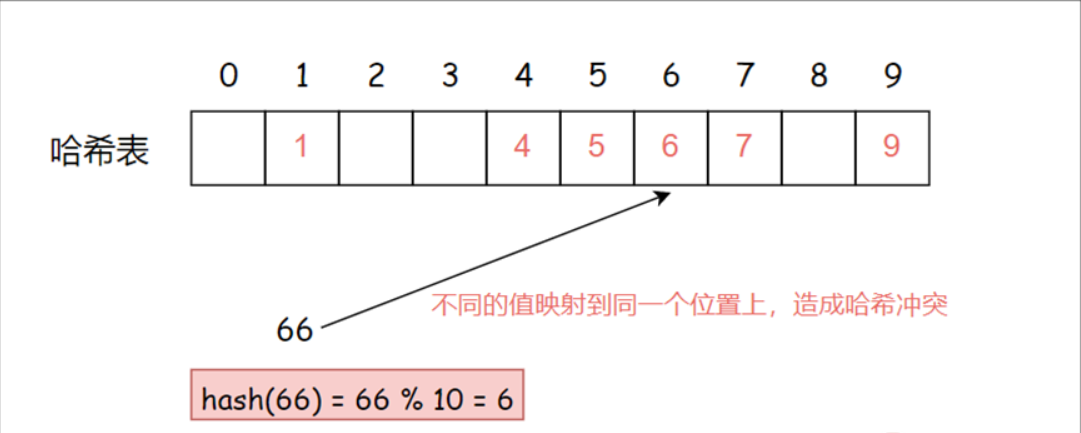
不同关键字通过相同哈希函数计算出相同的哈希地址,该现象称为哈希冲突或哈希碰撞
如果此时再将元素66插入到上面的哈希表,因为元素66通过哈希函数计算得到的哈希地址与元素6相同,那么就会产生哈希冲突。
哈希函数
基本概念:是将哈希表中元素的关键值映射为元素存储位置的函数
常见哈希函数
1.直接定址法(常用)
取关键字的某个线性函数为散列地址:Hash(Key) = A*Key + B
优点:简单,效率很高
缺点:需要事先知道关键字的分布情况
使用场景:适合查找数据比较小且连续的情况
2.除留余树法(常用)
设散列表中允许的地址数为 m,取一个不大于 m,但最接近或者等于 m 的质数 p 作为除数,按照哈希函数:Hash(key) = key % p (p <= m),将关键码转换成哈希地址
优点:使用场景广泛,不受限制
缺点:存在哈希冲突,需要解决哈希冲突,哈希冲突越多,效率下降越厉害
3.乘法散列法
乘法散列法对哈希表大小 M MM 没有要求,他的大致思路分为两步:
【第一步】用关键字key 乘上常数 A (0<A<1),并抽取出key × A 的小数部分。
【第二步】再用M 乘以k × A 的小数部分,再向下取整。
4.全域散列法
如果存在一个恶意的对手,他针对我们提供的散列函数,特意构造出一个发生严重冲突的数据集,比如,让所有关键字全部落入同一个位置中。这种情况是可以存在的,只要散列函数是公开且确定的,就可以实现此攻击。
给散列函数增加随机性,攻击者就无法找出确定可以导致最坏情况的数据,这种方法叫做全域散列。
处理哈希冲突
开放定址法
在开放定址法中所有的元素都放到哈希表里,当一个关键字key用哈希函数计算出的位置冲突了,则按照某种规则找到一个没有存储数据的位置进行存储。这里的规则有二种:线性探测、二次探测、链地址法
线性探测
从发生冲突的位置开始,一次线性向后探测,直到寻找到下一个没有存储数据的位置为止,如果走到哈希表尾,则回绕到哈希表头的位置
查找公式:hashi = hash(key) % N + i
其中:
hashi:冲突元素通过线性探测后得到的存放位置hash(key) % N:通过哈希函数对元素的关键码进行计算得到的位置N:哈希表的大小i从 1、2、3、4…一直自增
示例:
现在有这样一组数据集合 {10, 25, 3, 18, 54, 999} 我们用除留余数法将它们插入到表长为 10 的哈希表中
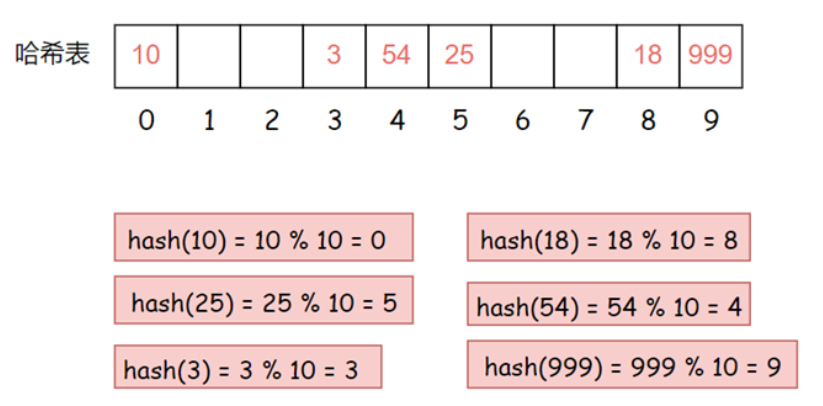
现在需要插入新元素 44,先通过哈希函数计算哈希地址,hashAddr 为 4,因此 44 理论上应该插在该位置,但是该位置已经放了值为 4 的元素,即发生哈希冲突,然后我们使用线性探测的计算公式hashi = 44% 10 + 1 = 5,但是下表为5的位置已经被占用了,那么继续计算hashi = 44% 10 + 2 = 6下标为6的位置没有被占用,那么就把44插入该位置
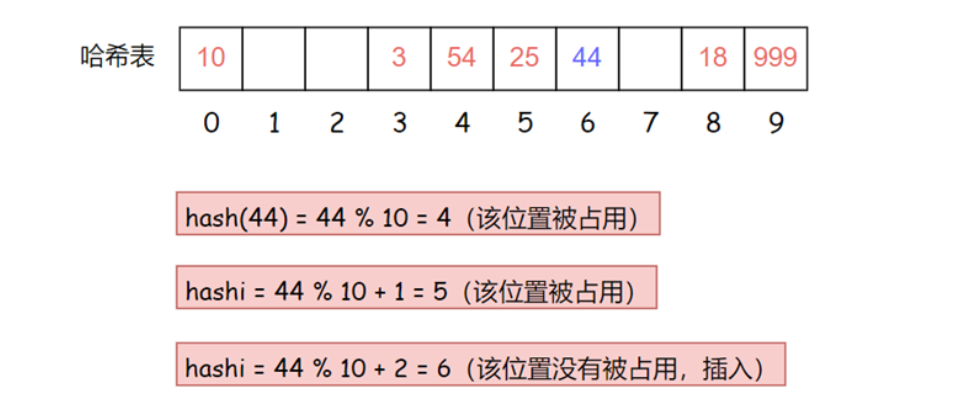
如果随着哈希表中数据的增多,产生哈希冲突的可能性也随着增加,假设现在要把 33 进行插入,那么会连续出现四次哈希冲突,我们将数据插入到有限的空间,那么空间中的元素越多,插入元素时产生冲突的概率也就越大,冲突多次后插入哈希表的元素,在查找时的效率必然也会降低。因此,哈希表当中引入了负载因子(载荷因子):
- 散列表的载荷因子定义为:α=填入表中的元素个数/散列表的长度
- 负载因子越大,产出冲突的概率越高,增删查改的效率越低
- 负载因子越小,产出冲突的概率越低,增删查改的效率越高
假设我们现在将哈希表的大小改为 20,再把上面的数据重新插入,可以看到完全没有产生的哈希冲突:

小贴士:
- 线性探测优点:实现非常简单
- 缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据堆积
二次探测
二次探测与线性探测类似但它地址的位置更稀松,找下一个空位置的方法为:hashi = hash(key) % N + i^2(i = 1、2、3、4…)
hashi:冲突元素通过线性探测后得到的存放位置hash(key) % N:通过哈希函数对元素的关键码进行计算得到的位置N:哈希表的大小。
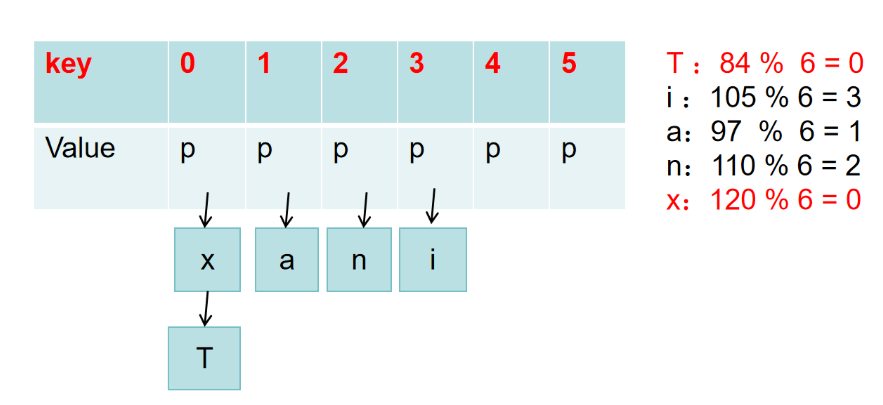
链地址法
拉链法中,哈希表中每个键对应的值都为一个链表的头节点,当发生哈希冲突时,新的键值对会被插入到相应的链表中。如下图所示,字符x发生哈希冲突时将其加入到链表头节点中:
哈希表的实现
哈希表的核心:HashMap
哈希表的本质是“数组+链表”的组合。每个链表节点保存具体的键值对
//哈希桶节点(链表节点)
typedef struct node_s
{KeyType key; // 键ValueType value; // 值struct node_s* next; // 指向下一个节点的指针
}KeyValueNode;//哈希表核心结构体
typedef struct
{KeyValueNode* buckets[HASHMAP_CAPACITY];//哈希桶数组uint32_t hash_seed; // 哈希种子(随机化)
}HashMap;关键点:
- buckets数组:确定了哈希表的整个大小,每一个元素是一个链表的头节点。当不同的键使用哈希函数映射的同一位置时,使用单链表用于处理哈希冲突(链地址法)
- hash_seed:哈希函数中的随机参数,通过time(NULL)在哈希表初始化时生成,作用是扩大地址范围,避免哈希冲突
核心函数:从创建到销毁
创建哈希表:hashmap_create()
参数:无
返回值:HashMap*
作用:创建需要初始化的数组和随机种子
HashMap* hashmap_create()
{HashMap* map = (HashMap*)malloc(sizeof(HashMap));if(!map){printf("hashmap_create failed\n");return NULL;}map->hash_seed = (uint32_t)time(NULL);//初始化随机种子return map;
}
关键点:
使用malloc动态申请分配哈希表内存
销毁哈希表:hashmap_destroy
参数:HashMap*
返回值:空
作用:销毁哈希表,释放所有节点的内存
void hashmap_destroy(HashMap* map)
{//判断哈希表是否已经创建,如果没有创建就直接返回,不需要释放内存if(!map) return;for(int i = 0;i < HASHMAP_CAPACITY;i++){KeyValueNode* current = map->buckets[i];while(current){KeyValueNode* next = current->next;//保存下一个节点free(current->key);//释放键free(current->value);//释放值free(current);//释放当前节点的内存current = next;//移动下一个节点}}free(map);//释放哈希表本身的内存
}
关键点:
- 遍历链表:通过current指针逐个释放链表节点
- 内存释放顺序:先释放节点的键和值,在释放节点本身,最后释放哈希表
插入键值对:hashmap_put
参数:HashMap* 、KeyType 、ValueType
返回值:ValueType
作用:插入新的键值对或更新值
ValueType hashmap_put(HashMap* map,KeyType key,ValueType val)
{if(!map || !key || !val) return NULL;//参数校验uint32_t index = hash(key,map->hash_seed);//计算获得的位置//查找键是否已经存在(更新值)KeyValueNode* current = map->buckets[index];while(current){if(strcmp(current->key,key) == 0){free(current->value);current->value = strdup1(val);return current->value; // 返回更新后的值}current = current->next;}//键不存在,创建新节点KeyValueNode* new_node = (KeyValueNode*)malloc(sizeof(KeyValueNode));//判断新节点是否创建成功if(!new_node){perror("Failed to allocate memory for new node"); }new_node->key = strdup1(key);new_node->value = strdup1(val);new_node->next = map->buckets[index];map->buckets[index] = new_node; // 将新节点插入到链表头部}
关键点:
- 哈希计算:通过哈希函数将键转换为索引
- 哈希冲突:如果键已经存在,更新对应的值;
- 性能优化:使用头插法插入(无需遍历到链表尾部),比尾插法更高效
查找键对应的值:hashmap_get
参数:HashMap*、KeyType
返回值:ValueType
作用:根据键查询对应的值
ValueType hashmap_get(HashMap* map,KeyType key)
{if(!map || !key) return NULL;uint32_t index = hash(key,map->hash_seed);//计算获得的位置//遍历链表查找键KeyValueNode* current = map->buckets[index];while(current){if(strcmp(current->key,key) == 0){return current->value; // 返回找到的值}current = current->next;}return NULL;
}
关键点:
- 参数校验:避免空指针导致的崩溃
- 线性查找:时间复杂度为O(1)
删除键值对:hashmap_remove
参数:HashMap*、KeyType
返回值:bool
作用:删除指定的键值对
bool hashmap_remove(HashMap* map,KeyType key)
{if(!map || !key) return false;uint32_t index = hash(key,map->hash_seed);KeyValueNode* current = map->buckets[index];KeyValueNode* prev = NULL;while(current){if(strcmp(current->key,key) == 0){//处理链表链接if(prev){prev->next = current->next;}else{map->buckets[index] = current->next;//删除头节点}//释放内存free(current->key);free(current->value);free(current);return true;}prev = current; //记录前一个节点current = current->next; //移动到下一个节点}return false; //未找到键
}
关键点:
- 头节点删除:若目标点是链表头,直接更新桶的头指针为current->next
- 中间/尾部删除:通过前一个节点prev的next指针跳过当前节点
拷贝函数:strdup1(const char* s)
参数:const char*
返回值:char*
作用:复制字符串
char* strdup1(const char* s)
{size_t len = strlen(s) + 1;char* p = (char*)malloc(len);if(p)memcpy(p,s,len);return p;
}哈希函数
static uint32_t hash(const char* key,uint32_t seed)
{uint32_t hash_val = 0;while(*key){hash_val = (hash_val* 31) + (uint32_t)*key++;}return (hash_val^seed) % HASHMAP_CAPACITY;
}设计思想:
- 多项式哈希:
hash_val = hash_val * 31 + *key是经典的字符串哈希算法(31是质数,能有效减少冲突) - 随机种子:通过
seed(时间戳)对哈希值取异或,避免相同输入生成相同哈希值(防御碰撞攻击) - 取模运算:将哈希值映射到
[0, HASHMAP_CAPACITY-1]的范围,确定桶的位置
测试函数
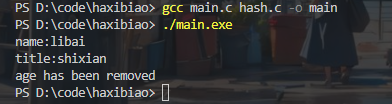
#include "hash.h"int main()
{//创建哈希表HashMap* map = hashmap_create();//判断哈希表是否创建成功if(!map){printf("create hashmap failed\n");return -1;}//插入键值对hashmap_put(map,"name","libai");hashmap_put(map,"age","66");hashmap_put(map,"location","changan");hashmap_put(map,"title","shixian");hashmap_put(map,"hobby","drink");//查询键对应的值ValueType name = hashmap_get(map,"name");if(name){printf("name:%s\n",name);}ValueType title = hashmap_get(map,"title");if(title){printf("title:%s\n",title);}//删除键值对hashmap_remove(map,"age");ValueType age = hashmap_get(map,"age");if(age == NULL){printf("age has been removed\n");}//销毁哈希表hashmap_destroy(map);}
输出结果:
完整代码
hash.h
#ifndef HASH_H
#define HASH_H#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define HASHMAP_CAPACITY 10//哈希表容量固定为10typedef char* KeyType;//键类型:字符串指针
typedef char* ValueType;//值类型:字符串指针//哈希桶节点(链表节点)
typedef struct node_s
{KeyType key; // 键ValueType value; // 值struct node_s* next; // 指向下一个节点的指针
}KeyValueNode;//哈希表核心结构体
typedef struct
{KeyValueNode* buckets[HASHMAP_CAPACITY];//哈希桶数组uint32_t hash_seed; // 哈希种子(随机化)
}HashMap;//初始化哈希表
HashMap* hashmap_create();//销毁哈希表
void hashmap_destroy(HashMap* map);//插入/更新键值对
ValueType hashmap_put(HashMap* map,KeyType key,ValueType val);//查询键对应的值
ValueType hashmap_get(HashMap* map,KeyType key);//删除键值对
bool hashmap_remove(HashMap* map,KeyType key);#endif
hash.c
#include "hash.h"//深拷贝字符串
char* strdup1(const char* s)
{size_t len = strlen(s) + 1;char* p = (char*)malloc(len);if(p)memcpy(p,s,len);return p;
}//创建哈希表
HashMap* hashmap_create()
{HashMap* map = (HashMap*)malloc(sizeof(HashMap));if(!map){printf("hashmap_create failed\n");return NULL;}map->hash_seed = (uint32_t)time(NULL);//初始化随机种子return map;
}//销毁哈希表(释放所有内存)
void hashmap_destroy(HashMap* map)
{//判断哈希表是否已经创建,如果没有创建就直接返回,不需要释放内存if(!map) return;for(int i = 0;i < HASHMAP_CAPACITY;i++){KeyValueNode* current = map->buckets[i];while(current){KeyValueNode* next = current->next;//保存下一个节点free(current->key);//释放键free(current->value);//释放值free(current);//释放当前节点的内存current = next;//移动下一个节点}}free(map);//释放哈希表本身的内存
}//哈希函数
static uint32_t hash(const char* key,uint32_t seed)
{uint32_t hash_val = 0;while(*key){hash_val = (hash_val* 31) + (uint32_t)*key++;}return (hash_val^seed) % HASHMAP_CAPACITY;
}//插入/更新键值对
ValueType hashmap_put(HashMap* map,KeyType key,ValueType val)
{if(!map || !key || !val) return NULL;//参数校验uint32_t index = hash(key,map->hash_seed);//计算获得的位置//查找键是否已经存在(更新值)KeyValueNode* current = map->buckets[index];while(current){if(strcmp(current->key,key) == 0){free(current->value);//防止内存泄漏current->value = strdup1(val);return current->value; // 返回更新后的值}current = current->next;}//键不存在,创建新节点KeyValueNode* new_node = (KeyValueNode*)malloc(sizeof(KeyValueNode));//判断新节点是否创建成功if(!new_node){perror("Failed to allocate memory for new node"); }new_node->key = strdup1(key);new_node->value = strdup1(val);new_node->next = map->buckets[index];map->buckets[index] = new_node; // 将新节点插入到链表头部}//查询键对应的值
ValueType hashmap_get(HashMap* map,KeyType key)
{if(!map || !key) return NULL;uint32_t index = hash(key,map->hash_seed);//计算获得的位置//遍历链表查找键KeyValueNode* current = map->buckets[index];while(current){if(strcmp(current->key,key) == 0){return current->value; // 返回找到的值}current = current->next;}return NULL;
}//删除键值对
bool hashmap_remove(HashMap* map,KeyType key)
{if(!map || !key) return false;uint32_t index = hash(key,map->hash_seed);KeyValueNode* current = map->buckets[index];KeyValueNode* prev = NULL;while(current){if(strcmp(current->key,key) == 0){//处理链表链接if(prev){prev->next = current->next;}else{map->buckets[index] = current->next;//删除头节点}//释放内存free(current->key);free(current->value);free(current);return true;}prev = current; //记录前一个节点current = current->next; //移动到下一个节点}return false; //未找到键
}main.c
#include "hash.h"int main()
{//创建哈希表HashMap* map = hashmap_create();//判断哈希表是否创建成功if(!map){printf("create hashmap failed\n");return -1;}//插入键值对hashmap_put(map,"name","libai");hashmap_put(map,"age","66");hashmap_put(map,"location","changan");hashmap_put(map,"title","shixian");hashmap_put(map,"hobby","drink");//查询键对应的值ValueType name = hashmap_get(map,"name");if(name){printf("name:%s\n",name);}ValueType title = hashmap_get(map,"title");if(title){printf("title:%s\n",title);}//删除键值对hashmap_remove(map,"age");ValueType age = hashmap_get(map,"age");if(age == NULL){printf("age has been removed\n");}//销毁哈希表hashmap_destroy(map);}

异常深度攻坚:从底层原理到架构级防御,老司机的实战经验)
 视频教程 - 主页-评论用户时间占比环形饼状图实现)















)
