Froxelizer主要是用于filament光照效果的实现,生成光照渲染时所需的必要信息,帮助渲染过程中明确哪些区域受哪些光源所影响,是Filament中保证光照效果渲染效率的核心所在。这部分的源码,可以结合filament官方文档中Light Path部分进行理解。
光照效果渲染
优秀的光照效果渲染一般都是影响引擎渲染性能的重要影响点,引擎也可能会对场景中可以使用的光的数量施加严格的限制,以此来保证渲染性能。3D引擎通常有两种主要的渲染方式:
- 前向渲染(forward rendering):像拍照一样,一次性把所有物体的颜色、光照等信息算好再绘制到屏幕上。
- 延迟渲染(deferred rendering):先记录每个像素的位置和材质信息,最后再统一计算光照效果,适合复杂场景。
一些现代3D引擎采用延迟渲染的方式,可以轻松支持数十、数百甚至数千个光源,但是往往需要很高的显存带宽。按照filament中默认的PBR材质模型,一个像素的渲染,可能就需要160到192 bits的G-Buffer占用,这就意味着非常高的显存带宽需求。
前向渲染过去一直难以处理多个光源。一种常见做法是 多次渲染场景(每个可见光源一次),然后将结果叠加。另一种方法是为每个物体分配固定的光源上限。但若场景中存在大片区域(如建筑、道路),这种方法会变得不切实际。
分格着色(Tiled Shading)可应用于前向和延迟渲染方法。这个想法是将屏幕分割成一个图块网格,对于每个图块,找到影响该图块中像素的灯光列表。这样做的优点是可以减少延迟渲染中的过度绘制和前向渲染中大型对象的着色计算。但是因为深度不连续的问题(如物体边缘),也可能导致大量无关的计算。
Filament的光照效果渲染以低带宽、每个像素支持多个动态光源为限定条件,另外期望能够轻松支持多重采样抗锯齿、透明度、多种材料模型等能力。
为了平衡光照渲染效果和渲染性能,Filament引入了一种称之为“分簇着色(Clustered Shading)”的前向渲染的变体方式。分簇着色扩展了分格着色的概念,但在z轴上添加了分段。“分簇”操作是在视图空间中完成的,方法是将视锥体分割成3D网格。这个过程,类似把一个2D图片分割成块,把3D空间分割成小立方块,只是这个分割是在是视锥空间进行的。如下图所示:
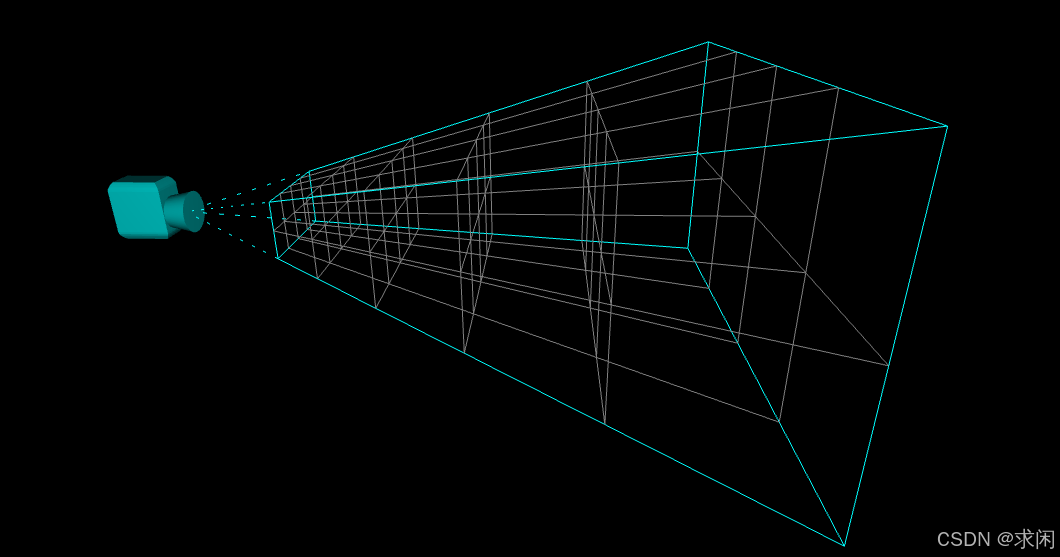
在Filament中,把分割的结果每块称之为Froxel(a voxel in frustum space,造词小能手结合了frustum和voxel,来表示在视锥空间下的体素)。
在渲染一帧画面之前,场景中的每个光源会被分配到所有它覆盖的Froxel中。这样,每个Froxel最终都会有一个它关联的光源列表。在实际渲染时,我们只需要找到当前像素片段所属的Froxel,就能直接获取影响该像素的所有光源。
Froxel的深度划分不是等距的,而是指数型增长的。因为人眼对靠近摄像机的物体更敏感(画面中近处的像素更多),所以我们会把靠近摄像机的位置划分得更细一些,而远处划分得更粗。这种指数型的Froxel深度划分方式,能让光源分配在最需要的地方更精确,提升渲染效率和呈现效果。
参考Froxelizer中的注释,froxel缓冲区的条目数量由最大UBO大小决定(见getFroxelBufferByteCount()函数)。 另外,因为增加froxel数量会加重"记录缓冲区"的压力(这个缓冲区负责存储每个froxel的光索引),filament中还设置记录缓冲区的容量限制为min(16K[UBO], 64K[uint16])条目。实际上,部分froxel并未被使用,因此我们能存储更多数据。
渲染实现流程
同通用的图像渲染流程一样,Filament中对于光照效果的渲染,从大的使用步骤上来看,也是经过材质的构建、Shader的编译、GPU Program的启用、Program参数的传递以及最后的DrawCall。前文所提到的Froxelizer,主要的工作是计算出需要传递Program的和光照信息相关的参数。
材质的使用
有OpenGL、DX、Vulkan等渲染基础的朋友都知道,需要使用这些图形API进行图像的渲染,一般都需要通过编写顶点着色器和片元着色器,构建出GPU执行的渲染程序,然后再渲染前设置好相关的程序参数(Attribute变量、Uniform变量等),最后材质DrawCall。
而在常见的渲染引擎或者游戏引擎中,如nity、Unreal等,都会通过材质的概念,将渲染程序以及渲染管线中的一些数据、状态等组织到一起,来进行渲染效果的实现。这样既方便资源的扩展与复用,又能解耦设计效果和渲染逻辑。
Filament中也存在材质的概念,其实现在MaterialBuilder中,官方有专门的文档来介绍Filament中的PBR材质,材质系统及自定义材质的方式,可优先参考官方文档。Filament中的材质构建流程,简单来说主要包括以下步骤:
- 编写材质文件:filament中的材质使用自定义的文件结构,定义了包括材质参数、顶点着色器、片元着色器等等各种信息。
- 材质编译:Filament提供了材质编译器(filament/tools/matc),将材质文件编译为二进制.
- 材质构建:使用
Material::Builder进行材质构建,package加载编译后的材质文件,constant设置常量,build方法构建出材质实例。 - 材质设置:构建出的材质对象,可以通过
setDefaultParameter来设置默认材质实例的参数。如果一个材质对象,需要传递不同的参数,应用到不同地方,可通过createInstance来创建不同的实例,然后修改其参数进行应用。 - 材质应用:参考Filament引擎(二) ——引擎的调用及接口层核心对象,将材质实例绑定给渲染实体。
Shader的构建
在filament中存在多种光照效果,关于光照的Shader模型如下:
/*** 支持的Shader模型*/
enum class Shading : uint8_t {UNLIT, //!< 不应用光照,可采用自发光方式LIT, //!< 默认的, 标准光照模型,模拟金属与非金属的刚体材质SUBSURFACE, //!< 次表面散射光照模型,模拟光线穿透材质内部的散射效果CLOTH, //!< 布料光照模型,模拟纺织物的纤维堆叠与散射特性SPECULAR_GLOSSINESS, //!< 镜面光泽度光照模型,兼容传统美术流程,通过镜面反射与光泽度参数替代金属度
};
以标准光照模型为例,matc中使用MaterialCompiler进行材质编译时,会先使用MaterialBuilder来进行材质的构建。参考MaterialBuilder::build函数实现,其内部会调用MaterialBuilder::generateShaders函数,进一步调用到ShaderGenerator中的createSurfaceVertexProgram和createSurfaceFragmentProgram函数。这两个函数中,在有光源时,都会通过调用generateSurfaceMaterialVariantDefines来在Shader中增加对应的宏,方向光增加宏VARIANT_HAS_DIRECTIONAL_LIGHTING。存在动态光源(有点光源及聚光灯光源),会增加宏VARIANT_HAS_DYNAMIC_LIGHTING。
在ShaderGenerator::createSurfaceFragmentProgram中,当在材质文件中指定了光照模型shadingModel: lit时,会调用CodeGenerator::generateSurfaceLit来将以下文件也写入到片元着色器的stream中:
- surface_lighting.fs
- 启用了阴影效果渲染时:surface_shadowing.fs
- surface_shading_model_standard.fs
- surface_brdf.fs
- surface_ambient_occlusion.fs
- surface_light_indirect.fs
- surface_shading_lit.fs
- 有方向光时:surface_light_directional.fs
- 有动态光时(即存在点光源或者聚光灯光源):surface_light_punctual.fs
后面CodeGenerator::generateSurfaceMain会将surface_main.vs和surface_main.fs分别写入到顶点着色器和片元着色器的stream中,这两个文件中包含着shader的mian函数。经过各种方式拼接出来的stream,会通过GLSLPostProcessor::process进行优化及转换,变成指定的Shader语言,GLSL、MSL、WGSL、SPirv等。
在需要进行包含动态光源的光照效果渲染时,以Lit光照模型为例,Shader的主要调用流程为:surface_main.fs: main -> surface_shading_lit.fs: evaluateMaterial -> surface_shading_lit: evaluateLights -> surface_light_punctual.fs: evaluatePunctualLights。在这个渲染过程中,需要用到Froxelizer生成的Froxel信息以及在场景中增加的光源信息,我们还需要确认下这部分信息的传递流程。
Froxel信息的传入
在Filament引擎(三) ——引擎渲染流程的分析中有提到,Filament会在每帧渲染前,view.prepare的过程中,判断存在点光源或者聚光灯光源时,进行Froxel化,计算出所有分簇被哪些光源所影响,并在Color Pass渲染之前,将这些信息提交到GPU中进行使用。
在filament中,UibGenerator被用来进行GPU缓冲区数据的生成和管理,在ShaderGenerator::createSurfaceFragmentProgram创建片元着色器时,如果存在动态光源,会通过CodeGenerator::generateUniforms在片元着色器中生成绑定点为RECORD_BUFFER和FROXEL_BUFFER的Uniform变量,关联对应的BufferInterfaceBlock对象。这样片元着色器中,就存在了后续用来接收Froxel数据的Uniform端点。
在FView构造函数中,Froxelizer中用来接收Froxel数据的Uniform Buffer Object对象mRecordsBuffer和mFroxelsBuffer,通过ColorPassDescriptorSet::init函数,生成分别与RECORD_BUFFER及FROXEL_BUFFER绑定点关联的描述信息,然后在FRenderer::renderJob中,通过 fg.addTrivialSideEffectPass("Prepare View Uniforms", xxx)发送任务到渲染线程,执行view.commitUniformsAndSamplers来真正实现的UBO和绑定点的关联。
在进行Color Pass的渲染之前,再通过fg.addTrivialSideEffectPass("Prepare Color Passes", xxx)发送任务到渲染线程,等待Froxel化及数据压缩完成,执行view.commitFroxels来提交压缩数据到GPU中对应的UBO中。这样片元着色器在需要进行光照渲染时就可以使用到mRecordsBuffer和mFroxelsBuffer对应的数据。
光源信息的传入
光照信息传入到Shader中的流程,与Froxel信息的传入类似。在ShaderGenerator::createSurfaceFragmentProgram创建片元着色器时,如果存在动态光源,会通过CodeGenerator::generateUniforms在片元着色器中生成绑定点位LIGHTS的Uniform变量,关联对应的BufferInterfaceBlock对象,用于后续接收光照信息的传入。ColorPassDescriptorSet::init函数在生成与Froxel绑定点关联的描述信息,也会生成与光照信息绑定点关联的描述信息。
FView.prepare时,会调用FView.prepareLighting,当存在动态光源时,它会调用scene->prepareDynamicLights来将LightSoa数据转换成LightsUib数组,传递到GPU中,在evaluatePunctualLights函数中同Froxel数据一起被使用。
Froxel准备过程
当FView进行prepare时,会进行是否存在动态光源的判断,即用户是否设置了点光源或者聚光灯。如果存在动态光源,就会进行Froxel的准备工作。在filament中一个场景下,动态光源的最大个数限制为256,在Froxelizer源码实现中,缓存相关的信息也是按照最大256个光源来进行实现的。
映射信息
Froxel的准备工作,主要是为了生成缓存信息。在Froxelizer中,有几个重要的对象:
- mFroxelShardedData:对象类型为
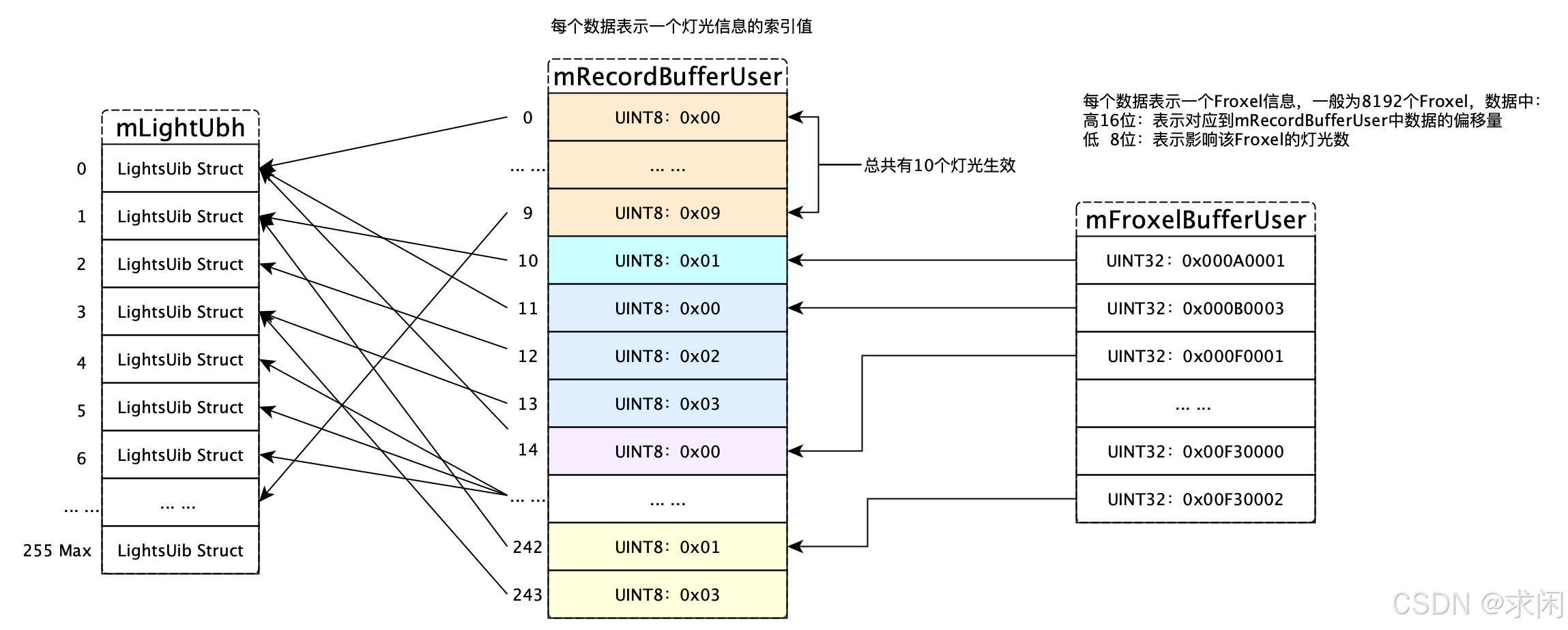
utils::Slice<FroxelThreadData>,每个FroxelThreadData实际上是数组LightGroupType[8192](LightGroupType实际上是一个uint32_t),切片大小为GROUP_COUNT(也就是8),实际占用256KiB的大小。数据在froxelizePointAndSpotLight函数中被填充,它记录的是所有Froxel哪些光源所影响。 - mFroxelBufferUser: 对象类型为
utils::Slice<FroxelEntry>, FroxelEntry结构体中只有一个uint32_t,高16位记录的是灯光信息的索引(相对mLightRecords),低8位记录的是灯光的数量。切片Size是mFroxelBufferEntryCount(不出意外就是8192),所以它的内存占用大概为32KiB。这部分数据会传递到GPU,用于着色器渲染时查询受哪些光源的影响。通过FroxelEntry可以在mRecordBufferUser中,找到哪些灯光对当前Froxel生效。 - mLightRecords:对象类型为
utils::Slice<LightRecord>, LightRecord结构体中只有一个256位的bitset,表示灯光索引,记录每个Froxel用到了哪些灯光。切片Size为mFroxelBufferEntryCount(8192),和所以它的内存占用大概也是256Kib。 - mRecordBufferUser: 对象类型为
utils::Slice<RecordBufferType>,RecordBufferType是一个uint8_t,记录的是“编码”后的灯光信息。按照filament中的实现,低3位记录了第几个分组,高5位记录了分组中的第几个。切片Size为RECORD_BUFFER_ENTRY_COUNT(16384),所以它的内存占用大概为16KiB。 数据也是在froxelizeAssignRecordsCompress函数中被填充。
在Froxelizer.h文件头部有一个图示,结合后面的分析重绘一下大致如下:
主要实现
由外部设置FView传入Viewport、投影矩阵等信息,Froxelizer会进行必要数值的计算,决定如何切分视锥。
在filament中Froxelizer::prepare过程中有几个重要的数值计算的伪代码如下:
// 记录Froxel索引的缓冲区大小,决定了一共可以分割多少个froxel出来。
// maxUniformBufferSize为打包多个Uniform变量的结构块的最大值(字节),OpenGL中通过`glGetIntegerv(GL_MAX_UNIFORM_BLOCK_SIZE, &maxUniformBufferSize)`获取
mFroxelBufferByteCount = min(8192 * 4, maxUniformBufferSize/16*16);
// Forxel的索引数。FroxelEntry结构体内部存储的是一个uint32_t,所以也就是4字节
mFroxelBufferEntryCount = getFroxelBufferByteCount()/sizeof(FroxelEntry);
// Z轴的切片固定位16段,上面有提到Froxel的深度划分不是等距离的,而是按照指数增长的方式切分。切分段数固定位16段。
mFroxelSliceCount = 16;
// 最大索引数固定了,Z方向分段固定,所以XY平面分块的最大值也就知道
mFroxelMaxXYPlaneCount = mFroxelBufferEntryCount / mFroxelSliceCount;
// XY平面分块的尺寸计算。分块的逻辑是按照Viewport的大小划分出接近mFroxelMaxXYPlaneCount个正方形,且保证分块的宽高是8的倍数,以优化Shader的性能。
mFroxelXYTiledDimension = maxRound8(ceil(width / sqrt(mFroxelMaxXYPlaneCount * width / height)), ceil(height / sqrt(mFroxelMaxXYPlaneCount * height / width)));
// 根据尺寸再计算出X和Y方向的切分,保证 mFroxelXCount * mFroxelYCount <= mFroxelMaxXYPlaneCount
mFroxelXCount = ceil(width / mFroxelXYTiledDimension);
mFroxelYCount = ceil(height / mFroxelXYTiledDimension);
根据计算的信息,去更新缓存数据的空间,缓存数据记录在一个LinearAllocatorArena中。主要记录的内容有:
- 用来表示Z轴切分点的
mFroxelSliceCount + 1(17)个float,记为mDistancesZ. - 用来表示视图空间下X平面的
mFroxelXCount + 1个float4,通过平面方程x * A + y * B + z * C + w = 0表示一个平面,记为mPlanesX,下面Y平面也类似。 - 用来表示视图空间下Y平面的
mFroxelYCount + 1个float4,记为mPlanesY。 - 用来表示包围球的
mFroxelXCount * mFroxelYCount * mFroxelSliceCount个float4(其中,xyz表示包围球中心,w表示球半径),记为mBoundingSpheres。
相机信息中一般包含相机的投影矩阵mProjection,用来将视图空间坐标转换成投影空间(或者叫裁切空间)的坐标。在Froxel中,期望存储的是视图空间下的6个平面信息,进行Froxel分割时,已经算出x、y、z三个方向上的切分份数,已知viewport大小,filament中通过以下方式,计算出视图空间下的X平面和Y平面信息。
// 投影矩阵的转置矩阵,用来将投影空间转换成视图空间
const mat4f trProjection(transpose(mProjection));for (size_t i = 0, n = mFroxelCountX; i <= n; ++i) {float const x = (float(i) * froxelWidthInClipSpace) - 1.0f;// float4{ -1, 0, 0, x } 表示一个平面方程: -1 * x' + 0 * y' + 0 * z' = x,X平面垂直于x轴。这里构建的是投影空间下的平面。// 通过投影矩阵转置后 与 X平面相乘,并进行归一化,得到视图空间下的X'平面方程float4 const p = trProjection * float4{ -1, 0, 0, x };planesX[i] = float4{ normalize(p.xyz), 0 };
}// 求视图空间下的Y'平面方程
for (size_t i = 0, n = mFroxelCountY; i <= n; ++i) {float const y = (float(i) * froxelHeightInClipSpace) - 1.0f;float4 const p = trProjection * float4{ 0, 1, 0, -y };planesY[i] = float4{ normalize(p.xyz), 0 }; // p.w is guaranteed to be 0
}
然后更新mBoundingSpheres,包围球的计算逻辑为:
- 每个Froxel因为是从视锥中截出来的,X、Y是等分的,Z是指数增长的,所以每个Froxel也是一个截锥体。
- 每个截锥体有6个面,XYZ三个面一定有一个交点,根据6个面求出截锥体的八个顶点。
- 八个顶点相加再除以8(乘0.125)就得到了球的中心。
- 计算八个点中离球中心最远的距离,作为球的半径。
最后,计算mParamsZ(float)的几个属性值,mParamsZ将被传入Shader中的参数,这部分的内容,在官方文档中8.4.2.4部分也有介绍,实际上zParamsZ的值大约为:
zParams[0] = 1.0f - Z_FAR / Z_NEAR;
zParams[1] = Z_FAR / Z_NEAR;
zParams[2] = (MAX_DEPTH_SLICES - 1) / log2(Z_SPECIAL_NEAR / Z_FAR);
zParams[3] = MAX_DEPTH_SLICES; // mFroxelSliceCount
Froxel化过程
参考Froxelizer::froxelizeLights方法。froxel化的过程主要有两步:先将所有的灯光的处理分组打包成多个任务(CONFIG_MAX_LIGHT_COUNT定义了最大灯光个数,LIGHT_PER_GROUP定义了每组灯光个数),抛到JobSystem中进行执行,将Froxel化的结果写到mFroxelShardedData中,然后再对Froxel化的结果mFroxelShardedData进行压缩。
froxelizePointAndSpotLight
froxelizeLoop函数负责将灯光的处理进行分组打包,并抛到JobSystem中执行。froxelizeLoop中构建的process,会以分组数(源码中固定为8)作为步长,以0-7分别作为offset,分成8个任务,对所有灯光信息进行遍历,并调用froxelizePointAndSpotLight来进行处理,填充mFroxelShardedData数据。
froxelizePointAndSpotLight的处理过程,主要就是确认指定的灯光对那些Froxel有影响,记录到mFroxelShardedData中,其实现步骤主要如下:
- 根据灯光的位置和半径,构建出灯光的包围盒。然后将相机的投影矩阵(裁切矩阵)参与计算,得到灯光包围盒投影后,在投影平面的八个点。
- 计算包围八个二维点的矩形框上两个角的点p1(min(x), min(y))和 p2(max(x), max(y))。前面有说到,Froxel化在XY两个方向上是进行等分的,用这两个点,就能算出光照影响到的Froxel的XY两个方向的Index方法。根据光源的中心位置和光源半径,知道光源影响的近点和远点,再结合Froxel在Z方向的指数增长的划分方式,可以算出光照影响在Z方向的两个Index。这6个Index(记作XMin、XMax、YMin、YMax、ZMin、ZMax),初步限定了光照影响Froxel的范围。
- 在Z方向上,从ZMin到ZMax进行遍历(记为z1),计算光照球和Z=z1的平面是否相交。相交的话(不包括相切),用相交形成的圆构建一个新的球,记为S1。如果z1和光照球中心所在的Z一致的话,不必计算新球,光照球就是S1。
- 计算出这个新球S1的球心,在投影平面上的点C1(x0,y0),和前面一样,用这个投影点,可以很容易计算出它对应的Froxel在XY两个方向上的Index。
- 在Y方向上,从YMin到YMax进行遍历(记为y1),计算球S1与当前Y平面是否相交。相交的话,用相交形成的圆可以再构建一个新球,记为S2。
- 在X方向上,从XMin到XMax进行遍历,计算球S2与当前X平面是否相交,找到与S2球相交的X平面区间 bx和ex。
- Froxel切分按照先X轴从小到大,再Y轴从小到大,最后Z轴从近到远的顺序进行Index计数。根据(bx, y1, z1) 计算得到X遍历时的Froxel的最小Index,记为fi。
fi到fi + ex - bx区间的Froxel,如果该光源是点光源,就都会被该光源影响。如果是聚光灯,就需要计算聚光灯的圆锥体和Froxel的包围球是否相交,相交的则是被该光源影响。- 被光源影响的Froxel,信息更新方式为:
froxelThread[fi++] |= LightGroupType(1) << bit。bit是froxelizePointAndSpotLight的入参,代表光源在分组中的Index。
Froxel化的过程,主要时出于计算效率的考虑,以分组的方式,将所有的光源对Froxel影响的计算,拆分到多个线程进行并行处理。在计算光源是否对Froxel有影响时,为了计算效率和准确性的双重考虑,按照Z->Y->X三个方向逐步判断,Z平面与光源球相交后,用相交的圆构建新球来圈定Z值固定时,光源对Y方向Froxel的影响。再以类似的方式,圈定Y值也固定时,光源对X方向Froxel的影响。通过这种方式,高效的确认所有被当前光源影响的Froxel,而不是对所有Froxel遍历判断是否被当前光源影响,以此提高Froxel化效率。
froxelizeAssignRecordsCompress
froxelizeAssignRecordsCompress顾名思义,主要用于将froxel的信息进行压缩。在froxelizeLoop中,为了提高Froxel化效率,将Froxel化过程拆成了8个分组,丢到8个线程中并行处理。最多256个灯光对于每个Froxel的影响,也被分别存储在8个int32_t中。在froxelizeAssignRecordsCompress中,会对这些数据进行压缩处理,降低对GPU的带宽需求,同时也便于后续的计算优化。其主要实现过程如下:
- 将Froxel数据(灯光信息,
mFroxelShardedData),从N组M位转换成一个256位的bitset(转换的结果存储在mLightRecords中),便于进行相邻比较和压缩。每一个froxel就对应着一个LightRecord(256位),记录哪些灯光针对该Froxel生效。 mLightRecords遍历进行或运算,得到被使用的所有灯光信息,allLights(LightRecord::bitset类型)。- 遍历allLights中被置为1的每一位用uint8_t来进行“编码”:以32个灯光为一组,一共分8组。低3位(0-7),表示属于哪一组,高5位(0-31),表示一组中的第几个。编码信息存储在
mRecordBufferUser中。 - 遍历
mLightRecords,对所有Froxel和影响它的光源信息,按照步骤3的方式,进行编码。编码信息同样存储到mRecordBufferUser。
按照以上的方式,如果只有两个灯光,都只对一半的Froxel生效,则只需要2 + 8192(Froxel总个数) * 0.5(一半的生效) * 2(灯光数)个uint_8,再加上8192个uint32(mFroxelBufferUser)记录FroxelEntry,即可存储所有的光源对所有Froxel的影响信息。而原始数据需要8192(Froxel总个数) * 256 (光源数) / 8 个uint_8。在实际的应用中,大量光源对大量Froxel都生效的情况毕竟是少数。
参考文档:
- DOOM (2016) - Graphics Study
- Filament官方文档
欢迎转载,转载请保留文章出处。求闲的博客[https://blog.csdn.net/junzia/article/details/149668651]






)
:LangChain + LlamaIndex 实现)



)
笔记)






