目录
(一)数据建模
1.以数据预测为核心的建模
2.以数据聚类为核心的建模
(二)基本数据分析
1.Numpy
2. Pandas
3.实例
4.Matplotlib
资料自取:
链接: https://pan.baidu.com/s/1PROmz-2hR3VCTd6Eei6lFQ?pwd=y8ys 提取码: y8ys
(一)数据建模
数据建模主要分为以数据预测为核心的建模与数据聚类为核心的建模
1.以数据预测为核心的建模
数据预测就是基于已有数据集,归纳出输入变量和输出变量之间的数量关系。数据预测可细分为回归预测和分类预测。对数值型输出变量的预测(对数值的预测)统称为回归预测。
对于自变量与因变量为非线性关系的情况:
拟合线性模型存在的潜在问题-CSDN博客
对分类型输出变量的预测(对类别的预测)统称为分类预测。如果输出变量仅有两个类别,则称其为二分类预测。如果输出变量有两个以上的类别,则称其为多分类预测。
2.以数据聚类为核心的建模
数据聚类就是发现数据重存在的更小的类,并通过小类刻画和揭示数据的内在组织结构。例如根据相同性别,年龄,收入对顾客群进行细分。
数据聚类和数据预测中的分类问题:
联系:数据聚类是给每个样本观测一个小类标签;分类问题是给输出变量一个分类值,本质也是给每个样本观测一个标签。
区别:分类问题中的变量有输入变量和输出变量之分,且分类标签(保存在输出变量中,如空气质量等级,顾客买或不买)的真实值是已知的;数据聚类中的变量没有输入变量和输出变量之分,所有变量都将被视为聚类变量参与数据分析,且小类标签(保存在聚类解变量中)的真实值是未知的。正是如此,数据聚类有着不同于数据分类的算法策略。
注:除了以上两种建模方式,还有关联分析和模式诊断。关联分析即探究不同事物之间的联系。模式是一个数据集合,具有随机和非常规性,例如下图中,少量变动的数据即为模式。
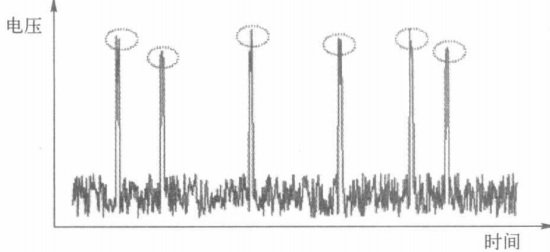
模式和统计学中的离群点不同:
尽管离群点与模式的数量都较少,且均表现出严重偏离数据全体的特征,但离群点通常由随机因素所致。模式则不然,它具有非随机性和潜在的形成机制。找到离群点的目的是剔除它们以消除对数据分析的影响,但模式很多时候就是人们关注的焦点,是不能剔除的。
(二)基本数据分析
1.Numpy
import numpy as np
data=np.array([1,2,3,4,5,6,7,8,9])
print('Numpy的1维数组:\n{0}'.format(data))
print('数据类型:%s'%data.dtype)
print('1维数组中各元素扩大10倍:\n{0}'.format(data*10))
print('访问第2个元素:{0}'.format(data[1]))
data=np.array([[1,3,5,7,9],[2,4,6,8,10]])
print('Numpy的2维数组:\n{0}'.format(data))
print('访问2维数组中第1行第2列元素:{0}'.format(data[0,1]))
print('访问2维数组中第1行第2至4列元素:{0}'.format(data[0,1:4]))
print('访问2维数组中第1行上的所有元素:{0}'.format(data[0,:]))#输出:
Numpy的1维数组:
[1 2 3 4 5 6 7 8 9]
数据类型:int32
1维数组中各元素扩大10倍:
[10 20 30 40 50 60 70 80 90]
访问第2个元素:2
Numpy的2维数组:
[[ 1 3 5 7 9][ 2 4 6 8 10]]
访问2维数组中第1行第2列元素:3
访问2维数组中第1行第2至4列元素:[3 5 7]
访问2维数组中第1行上的所有元素:[1 3 5 7 9]data=[[1,2,3,4,5,6,7,8,9],['A','B','C','D','E','F','G','H','I']]
print('data是Python的列表(list):\n{0}'.format(data))
MyArray1=np.array(data)
print('MyArray1是Numpy的N维数组:\n%s\nMyarray1的形状:%s'%(MyArray1,MyArray1.shape))#输出
data是Python的列表(list):
[[1, 2, 3, 4, 5, 6, 7, 8, 9], ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I']]
MyArray1是Numpy的N维数组:
[['1' '2' '3' '4' '5' '6' '7' '8' '9']['A' 'B' 'C' 'D' 'E' 'F' 'G' 'H' 'I']]
Myarray1的形状:(2, 9)MyArray2=np.arange(10)
print('MyArray2:\n{0}'.format(MyArray2))
print('MyArray2的基本描述统计量:\n均值:%f,标准差:%f,总和:%f,最大值:%f'%(MyArray2.mean(),MyArray2.std(),MyArray2.sum(),MyArray2.max()))
print('MyArray2的累计和:{0}'.format(MyArray2.cumsum()))
print('MyArray2开平方:{0}'.format(np.sqrt(MyArray2)))
np.random.seed(123) #复现随机数
MyArray3=np.random.randn(10) #生成包含10个元素且服从标准正态分布的1维数组
print('MyArray3:\n{0}'.format(MyArray3))
print('MyArray3排序结果:\n{0}'.format(np.sort(MyArray3)))
print('MyArray3四舍五入到最近整数:\n{0}'.format(np.rint(MyArray3)))
print('MyArray3各元素的正负号:{0}'.format(np.sign(MyArray3)))
print('MyArray3各元素非负数的显示"正",负数显示"负":\n{0}'.format(np.where(MyArray3>0,'正','负')))
print('MyArray2+MyArray3的结果:\n{0}'.format(MyArray2+MyArray3))#输出
MyArray2:
[0 1 2 3 4 5 6 7 8 9]
MyArray2的基本描述统计量:
均值:4.500000,标准差:2.872281,总和:45.000000,最大值:9.000000
MyArray2的累计和:[ 0 1 3 6 10 15 21 28 36 45]
MyArray2开平方:[0. 1. 1.41421356 1.73205081 2. 2.236067982.44948974 2.64575131 2.82842712 3. ]
MyArray3:
[-1.0856306 0.99734545 0.2829785 -1.50629471 -0.57860025 1.65143654-2.42667924 -0.42891263 1.26593626 -0.8667404 ]
MyArray3排序结果:
[-2.42667924 -1.50629471 -1.0856306 -0.8667404 -0.57860025 -0.428912630.2829785 0.99734545 1.26593626 1.65143654]
MyArray3四舍五入到最近整数:
[-1. 1. 0. -2. -1. 2. -2. -0. 1. -1.]
MyArray3各元素的正负号:[-1. 1. 1. -1. -1. 1. -1. -1. 1. -1.]
MyArray3各元素非负数的显示"正",负数显示"负":
['负' '正' '正' '负' '负' '正' '负' '负' '正' '负']
MyArray2+MyArray3的结果:
[-1.0856306 1.99734545 2.2829785 1.49370529 3.42139975 6.651436543.57332076 6.57108737 9.26593626 8.1332596 ]np.random.seed(123)
#通过random.normal()生成2行5列的数组,服从均值5,标准差1的正态分布。再通过floor得到各元素最近的最大整数。
X=np.floor(np.random.normal(5,1,(2,5)))
#用eye函数声称单位矩阵
Y=np.eye(5)
print('X:\n{0}'.format(X))
print('Y:\n{0}'.format(Y))
print('X和Y的点积:\n{0}'.format(np.dot(X,Y)))#输出
X:
[[3. 5. 5. 3. 4.][6. 2. 4. 6. 4.]]
Y:
[[1. 0. 0. 0. 0.][0. 1. 0. 0. 0.][0. 0. 1. 0. 0.][0. 0. 0. 1. 0.][0. 0. 0. 0. 1.]]
X和Y的点积:
[[3. 5. 5. 3. 4.][6. 2. 4. 6. 4.]]from numpy.linalg import inv,svd,eig,det
X=np.random.randn(5,5) #生成服从正态分布的5行5列矩阵
print(X)
#X的转置与X相乘的结果保存在mat中
mat=X.T.dot(X)
print(mat)
print('矩阵mat的逆:\n{0}'.format(inv(mat)))
print('矩阵mat的行列式值:\n{0}'.format(det(mat)))
print('矩阵mat的特征值和特征向量:\n{0}'.format(eig(mat)))
print('对矩阵mat做奇异值分解:\n{0}'.format(svd(mat)))#输出
[[-0.67888615 -0.09470897 1.49138963 -0.638902 -0.44398196][-0.43435128 2.20593008 2.18678609 1.0040539 0.3861864 ][ 0.73736858 1.49073203 -0.93583387 1.17582904 -1.25388067][-0.6377515 0.9071052 -1.4286807 -0.14006872 -0.8617549 ][-0.25561937 -2.79858911 -1.7715331 -0.69987723 0.92746243]]
[[ 1.6653281 0.3422329 -1.28839014 1.13288023 -0.47839144][ 0.3422329 15.75232012 6.94940128 5.8598402 -4.3525394 ][-1.28839014 6.94940128 13.06151953 1.58238781 0.94392314][ 1.13288023 5.8598402 1.58238781 3.30834132 -1.33134132][-0.47839144 -4.3525394 0.94392314 -1.33134132 3.52128471]]
矩阵mat的逆:
[[ 1.80352376 0.91697099 -0.13003481 -1.89987257 0.69500392][ 0.91697099 1.06125071 -0.33606314 -1.6733028 0.89378948][-0.13003481 -0.33606314 0.21904487 0.39759582 -0.34145532][-1.89987257 -1.6733028 0.39759582 3.24041446 -1.20785501][ 0.69500392 0.89378948 -0.34145532 -1.20785501 1.11805164]]
矩阵mat的行列式值:
105.54721777632028
矩阵mat的特征值和特征向量:
(array([23.58279263, 10.10645658, 2.29462217, 0.16661658, 1.1583058 ]), array([[-0.00179276, -0.18946636, -0.59452701, -0.46660531, -0.62683045],[ 0.77739059, -0.36419497, 0.09103298, -0.39431826, 0.31504284],[ 0.54092005, 0.77338945, 0.00371263, 0.10167527, -0.31451966],[ 0.27741393, -0.24680189, -0.58381349, 0.71576484, 0.09472503],[-0.16157864, 0.41523742, -0.54534269, -0.32270021, 0.63240505]]))
对矩阵mat做奇异值分解:
(array([[-0.00179276, 0.18946636, 0.59452701, 0.62683045, 0.46660531],[ 0.77739059, 0.36419497, -0.09103298, -0.31504284, 0.39431826],[ 0.54092005, -0.77338945, -0.00371263, 0.31451966, -0.10167527],[ 0.27741393, 0.24680189, 0.58381349, -0.09472503, -0.71576484],[-0.16157864, -0.41523742, 0.54534269, -0.63240505, 0.32270021]]), array([23.58279263, 10.10645658, 2.29462217, 1.1583058 , 0.16661658]), array([[-0.00179276, 0.77739059, 0.54092005, 0.27741393, -0.16157864],[ 0.18946636, 0.36419497, -0.77338945, 0.24680189, -0.41523742],[ 0.59452701, -0.09103298, -0.00371263, 0.58381349, 0.54534269],[ 0.62683045, -0.31504284, 0.31451966, -0.09472503, -0.63240505],[ 0.46660531, 0.39431826, -0.10167527, -0.71576484, 0.32270021]]))
2. Pandas
序列(Series):
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data=Series([1,2,3,4,5,6,7,8,9],index=['ID1','ID2','ID3','ID4','ID5','ID6','ID7','ID8','ID9'])
print('序列中的值:\n{0}'.format(data.values))
print('序列中的索引:\n{0}'.format(data.index))
print('访问序列的第1和第3上的值:\n{0}'.format(data[[0,2]]))
print('访问序列索引为ID1和ID3上的值:\n{0}'.format(data[['ID1','ID3']]))
print('判断ID1索引是否存在:%s;判断ID10索引是否存在:%s'%('ID1' in data,'ID10' in data))import pandas as pd
from pandas import Series,DataFrame
data=pd.read_excel('北京市空气质量数据.xlsx')
print('date的类型:{0}'.format(type(data)))
print('数据框的行索引:{0}'.format(data.index))
print('数据框的列名:{0}'.format(data.columns))
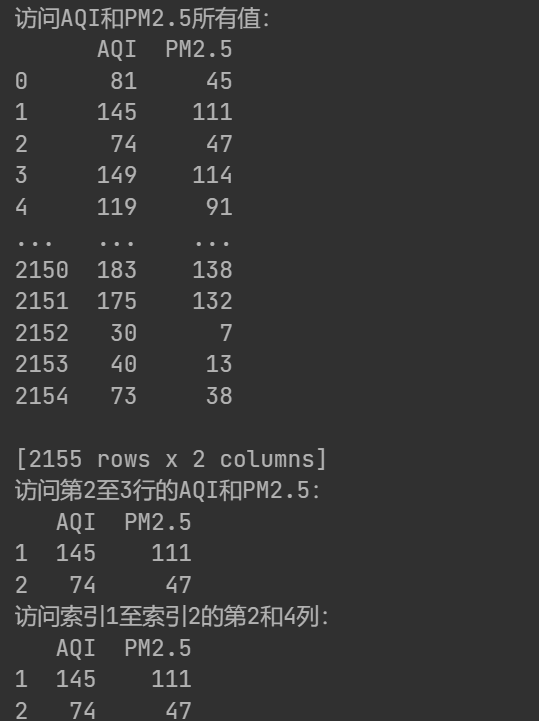
print('访问AQI和PM2.5所有值:\n{0}'.format(data[['AQI','PM2.5']]))
print('访问第2至3行的AQI和PM2.5:\n{0}'.format(data.loc[1:2,['AQI','PM2.5']]))
print('访问索引1至索引2的第2和4列:\n{0}'.format(data.iloc[1:3,[1,3]]))
data.info()
注:
loc是基于标签的索引,data.loc[1:2,]包含起始标签和结束标签,且是闭区间。表示选取标签为1,2的行
iloc是基于位置的索引,data.iloc[1:3,]是左闭右开的,表示索引2,3
两者打印结果相同:
数据框(DataFrame):
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df1=DataFrame({'key':['a','d','c','a','b','d','c'],'var1':range(7)})
df2=DataFrame({'key':['a','b','c','c'],'var2':[0,1,2,2]})
df=pd.merge(df1,df2,on='key',how='outer')
df.iloc[0,2]=np.NaN
df.iloc[5,1]=np.NaN
print('合并后的数据:\n{0}'.format(df))
df=df.drop_duplicates()
print('删除重复数据行后的数据:\n{0}'.format(df))
print('判断是否为缺失值:\n{0}'.format(df.isnull()))
print('判断是否不为缺失值:\n{0}'.format(df.notnull()))
print('删除缺失值后的数据:\n{0}'.format(df.dropna()))
#计算每列的均值
fill_value=df[['var1','var2']].apply(lambda x:x.mean())
#用均值填充
print('以均值替换缺失值:\n{0}'.format(df.fillna(fill_value)))3.实例
import numpy as np
import pandas as pd
from pandas import Series,DataFramedata=pd.read_excel('北京市空气质量数据.xlsx')
data=data.replace(0,np.NaN)
data['年']=data['日期'].apply(lambda x:x.year)
month=data['日期'].apply(lambda x:x.month)
quarter_month={'1':'一季度','2':'一季度','3':'一季度','4':'二季度','5':'二季度','6':'二季度','7':'三季度','8':'三季度','9':'三季度','10':'四季度','11':'四季度','12':'四季度'}
data['季度']=month.map(lambda x:quarter_month[str(x)])
bins=[0,50,100,150,200,300,1000]
data['等级']=pd.cut(data['AQI'],bins,labels=['一级优','二级良','三级轻度污染','四级中度污染','五级重度污染','六级严重污染'])
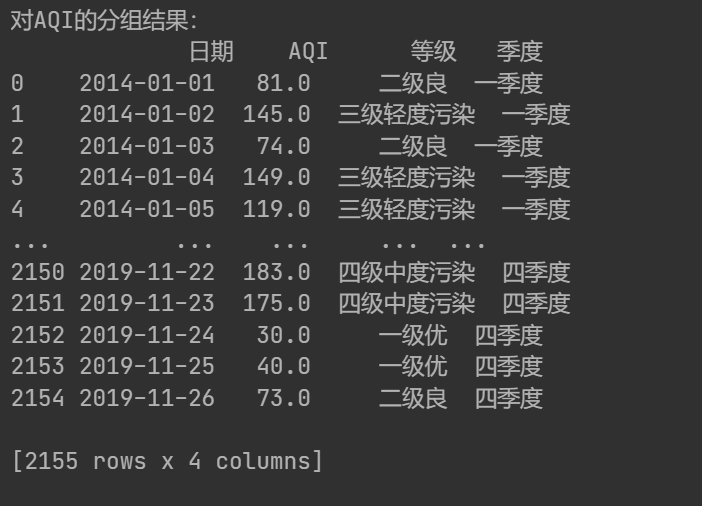
print('对AQI的分组结果:\n{0}'.format(data[['日期','AQI','等级','季度']]))输出:
print('各季度AQI和PM2.5的均值:\n{0}'.format(data.loc[:,['AQI','PM2.5']].groupby(data['季度']).mean()))
print('各季度AQI和PM2.5的描述统计量:\n',data.groupby(data['季度'])['AQI','PM2.5'].apply(lambda x:x.describe()))def top(df,n=10,column='AQI'):return df.sort_values(by=column,ascending=False)[:n]
print('空气质量最差的5天:\n',top(data,n=5)[['日期','AQI','PM2.5','等级']])
print('各季度空气质量最差的3天:\n',data.groupby(data['季度']).apply(lambda x:top(x,n=3)[['日期','AQI','PM2.5','等级']]))
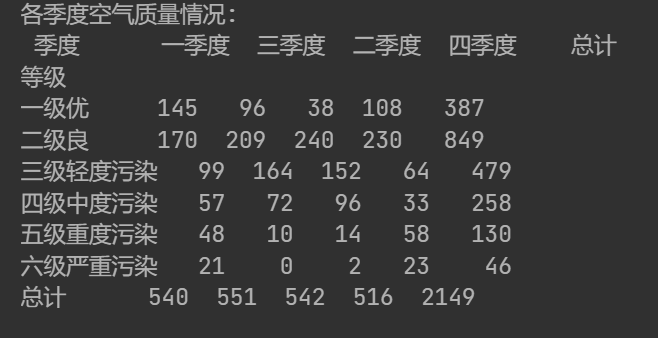
#crosstab可用于生成交叉表,行按等级分组,列按季度分组
print('各季度空气质量情况:\n',pd.crosstab(data['等级'],data['季度'],margins=True,margins_name='总计',normalize=False))最后一行代码输出结果:
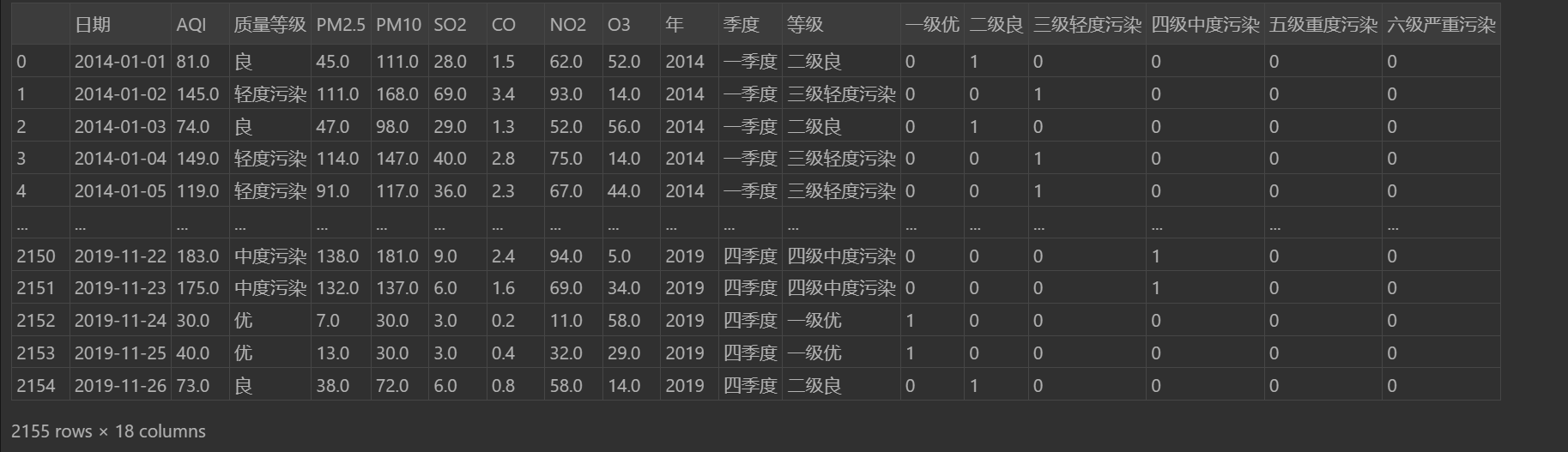
#用"0","1"表示改行是否属于该等级
pd.get_dummies(data['等级'])
#并且合并到data中一起显示
data.join(pd.get_dummies(data['等级']))输出:
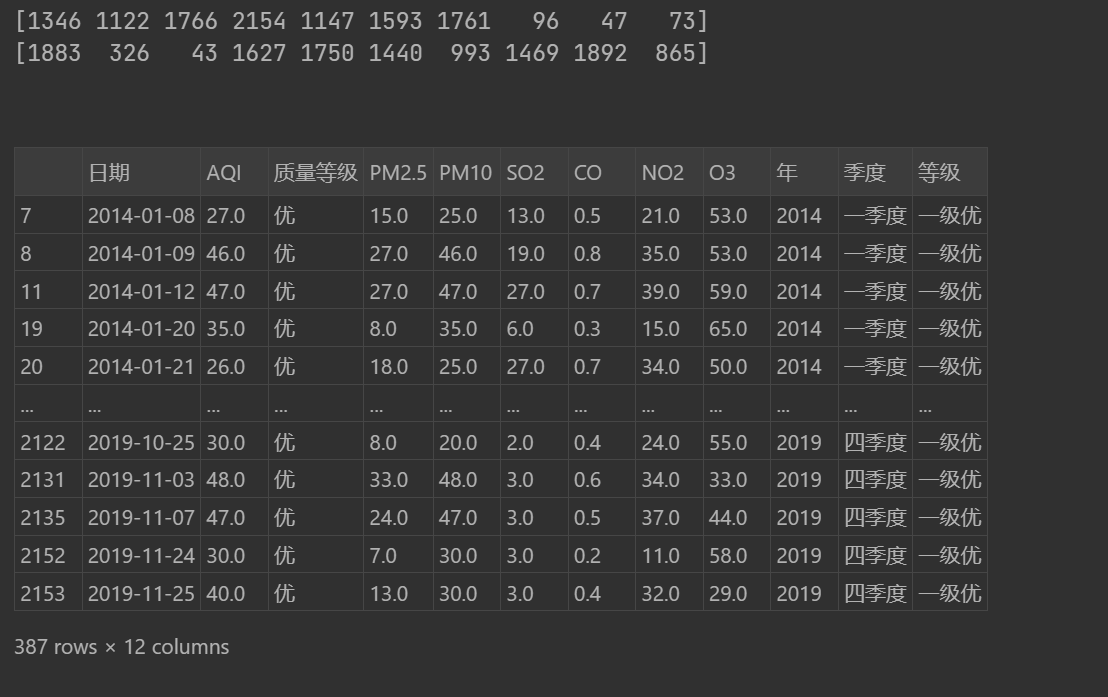
np.random.seed(123)
#np.random.randint(low, high, size),下限为low,上限为hign-1,打印个数为size
sampler=np.random.randint(0,len(data),10)
print(sampler)
#获取data的总行数,截取前10个
sampler=np.random.permutation(len(data))[:10]
print(sampler)#基于随机数获取数据集
data.take(sampler)
#获取"质量等级"为优的数据集
data.loc[data['质量等级']=='优',:]输出:
4.Matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=Falsedata=pd.read_excel('北京市空气质量数据.xlsx')
data=data.replace(0,np.NaN)plt.figure(figsize=(10,5))
plt.plot(data['AQI'],color='black',linestyle='-',linewidth=0.5)
plt.axhline(y=data['AQI'].mean(),color='red', linestyle='-',linewidth=0.5,label='AQI总平均值')
data['年']=data['日期'].apply(lambda x:x.year)
AQI_mean=data['AQI'].groupby(data['年']).mean().values
year=['2014年','2015年','2016年','2017年','2018年','2019年']
col=['red','blue','green','yellow','purple','brown']
for i in range(6):plt.axhline(y=AQI_mean[i],color=col[i], linestyle='--',linewidth=0.5,label=year[i])
plt.title('2014年至2019年AQI时间序列折线图')
plt.xlabel('年份')
plt.ylabel('AQI')
plt.xlim(xmax=len(data), xmin=1)
plt.ylim(ymax=data['AQI'].max(),ymin=1)
plt.yticks([data['AQI'].mean()],['AQI平均值'])
plt.xticks([1,365,365*2,365*3,365*4,365*5],['2014','2015','2016','2017','2018','2019'])
plt.legend(loc='best')
plt.text(x=list(data['AQI']).index(data['AQI'].max()),y=data['AQI'].max()-20,s='空气质量最差日',color='red')
plt.show()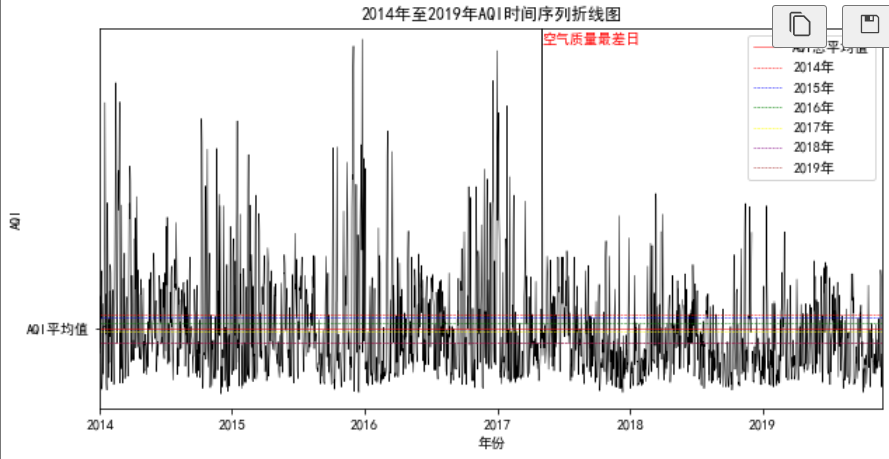
import warnings
warnings.filterwarnings(action = 'ignore')
plt.figure(figsize=(10,5))
#图表分为2行2列,选取第1个位置
plt.subplot(2,2,1)
plt.plot(AQI_mean,color='black',linestyle='-',linewidth=0.5)
plt.title('各年AQI均值折线图')
#[0,1,2,3,4..]是实际刻度,['2014','2015'..]是对应标签
plt.xticks([0,1,2,3,4,5,6],['2014','2015','2016','2017','2018','2019'])
plt.subplot(2,2,2)
plt.hist(data['AQI'],bins=20)
plt.title('AQI直方图')
plt.subplot(2,2,3)
#行为PM2.5,列为AQI
plt.scatter(data['PM2.5'],data['AQI'],s=0.5,c='green',marker='.')
plt.title('PM2.5与AQI散点图')
plt.xlabel('PM2.5')
plt.ylabel('AQI')
plt.subplot(2,2,4)
tmp=pd.value_counts(data['质量等级'],sort=False) #等同:tmp=data['质量等级'].value_counts(),统计各等级出现的次数
share=tmp/sum(tmp)
labels=tmp.index
explode = [0, 0.2, 0, 0, 0,0.2,0]
plt.pie(share, explode = explode,labels = labels, autopct = '%3.1f%%',startangle = 180, shadow = True)
plt.title('空气质量整体情况的饼图')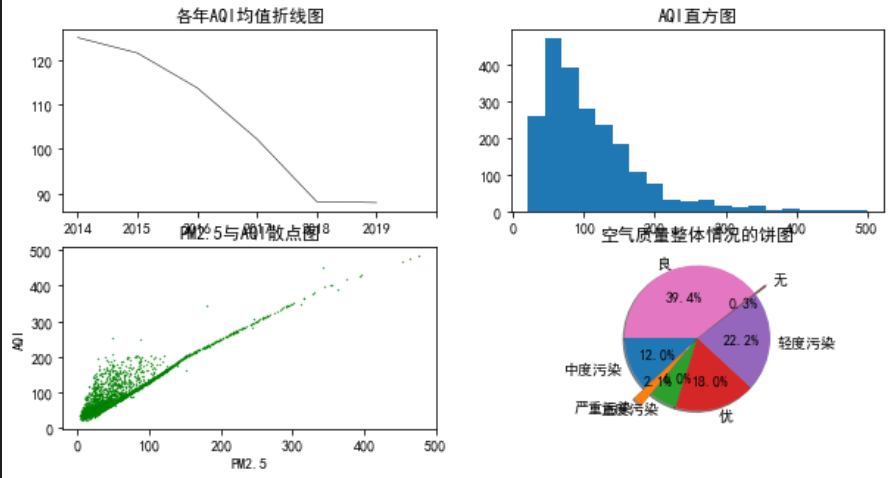
以下代码通过axes[0,0]直接定位子图,比plt.subplot容易维护,例如,如果删除第2个子图,则(2,2,3)--->(2,2,2),(2,2,4)--->(2,2,3)。
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(10,5))
axes[0,0].plot(AQI_mean,color='black',linestyle='-',linewidth=0.5)
axes[0,0].set_title('各年AQI均值折线图')
axes[0,0].set_xticks([0,1,2,3,4,5,6])
axes[0,0].set_xticklabels(['2014','2015','2016','2017','2018','2019'])
axes[0,1].hist(data['AQI'],bins=20)
axes[0,1].set_title('AQI直方图')
axes[1,0].scatter(data['PM2.5'],data['AQI'],s=0.5,c='green',marker='.')
axes[1,0].set_title('PM2.5与AQI散点图')
axes[1,0].set_xlabel('PM2.5')
axes[1,0].set_ylabel('AQI')
axes[1,1].pie(share, explode = explode,labels = labels, autopct = '%3.1f%%',startangle = 180, shadow = True)
axes[1,1].set_title('空气质量整体情况的饼图')
fig.subplots_adjust(hspace=0.5)#调整垂直间距
fig.subplots_adjust(wspace=0.5)#调整水平间距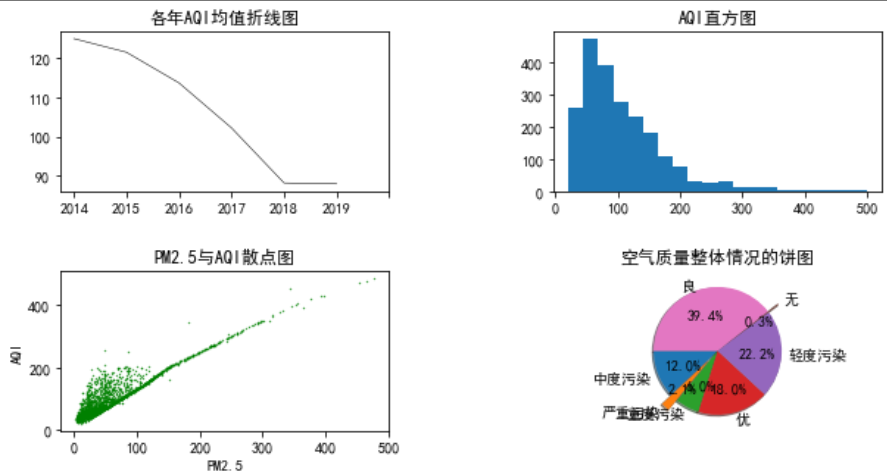



![[硬件电路-148]:数字电路 - 什么是CMOS电平、TTL电平?还有哪些其他电平标准?发展历史?](http://pic.xiahunao.cn/[硬件电路-148]:数字电路 - 什么是CMOS电平、TTL电平?还有哪些其他电平标准?发展历史?)
 --(前端篇 2)--)



)









常用管理SQL命令(3))
