最近在看吴恩达深度学习系列课程,简单做一个基本框架笔记。
如感兴趣或了解更多内容,推荐看原课程
以前也做过一些与机器学习和深度学习有关的笔记,过分重复的就一笔带过了。
01 第一门课 神经网络和深度学习
1.1 第一周:深度学习引言
略
1.2 第二周:神经网络的编程基础
需要基本了解:
- 二分类
- 逻辑回归
- 逻辑函数的代价函数(理解为什么要有代价函数)
- 梯度下降法(参数如何更新)
- 导数(理解微积分即可)
- 计算图(关于这个,“鱼书”将很好很详细,推荐,用来理解反向传播很方便)
- 利用计算图求导数(本质上就是求导的链式法则)
- 逻辑回归中的梯度下降
- m个样本的梯度下降
- 向量化(是为了解决若采用for循环的慢速,向量化更高效,但要注意维度对应上)
- python中的广播(broadcasting)
1.3 第三周:浅层神经网络
以两层神经网络为例,基本逻辑:
- 结构(包括输入层,隐藏层,输出层)
- 单个神经元的计算
- 多样本的向量化
- 激活函数(常用种类,为什么要用非线性激活函数,激活函数的导数)
- 神经逻辑的梯度下降(与前面逻辑回归的梯度下降的基本思路,基本一致)
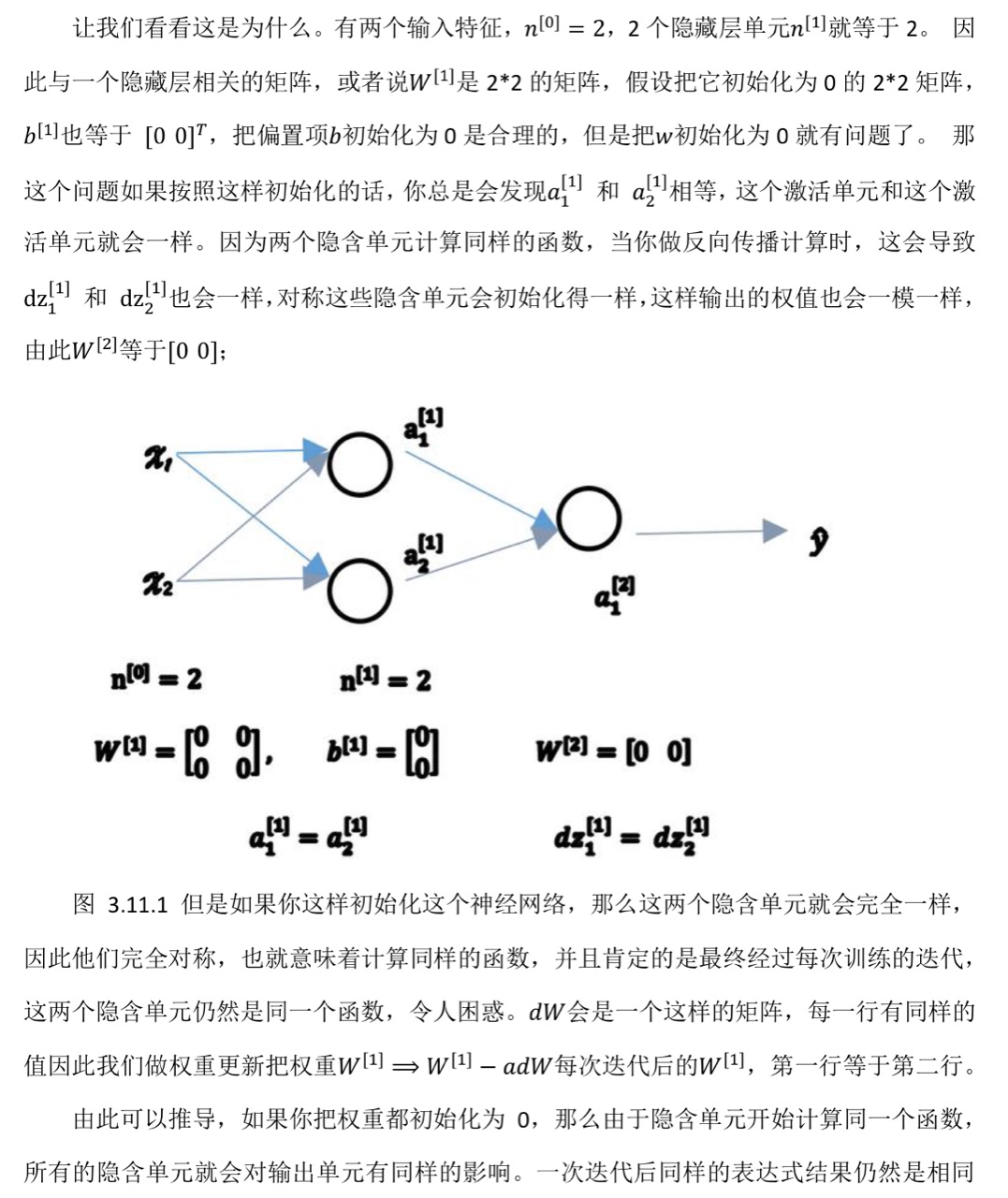
- 随机初始化(对于一个神经网络,把权重等参数都初始化为0,梯度下降将不会再起作用)
关于第六点的详细解释:
1.4 第四周:深层神经网络
隐藏层的数量可看作一个可自由选择大小的超参数
如果有比较多的隐藏层(网络比较深),总体上能够学更复杂的函数
前向传播和后向传播的基本逻辑,和浅层神经网络一致
02 第二门课 改善深层神经网络:超参数调试,正则化以及优化
2.1 第一周:深度学习的实践层面
2.1.1 训练,验证,测试集
先利用训练集,执行算法进行训练,通过验证集或简单交叉验证集选择最好的模型(比如超参数等的选择)。
经过充分验证,选定了最终模型,在测试集上进行评估。
在小数据量时代,常见做法是将所有数据三七分,即70%验证集+30%测试集,如果没有明确设置验证集,也可以按照 60%训练,20%验证和 20%测试集来划分。
在现在大数据阶段,验证集和测试集占数据总量的比例会趋向于变得更小。
2.1.2 偏差,方差
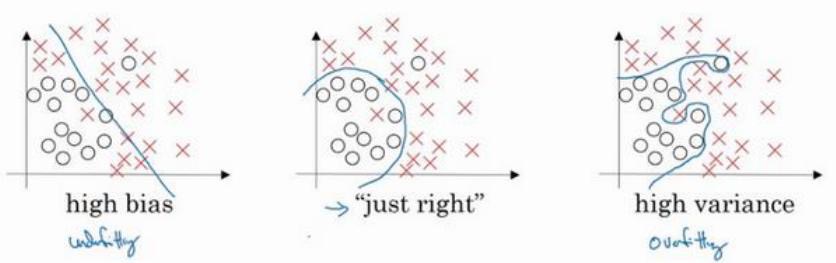
最左边的图片,用逻辑回归进行拟合,并不能很好地拟合该数据,这是高偏差(high bias)的情况,称为“欠拟合”(underfitting)。
最右边的图片,拟合方式分类器方差较高(high variance),数据过度拟合(overfitting)。
理解偏差和方差的两个关键数据是训练集误差(Train set error)和验证集误差(Dev set error)
- 假定训练集误差是 1%,验证集误差是 11%,可以看出训练集结果非常好,而验证集结果相对较差。我们可能过度拟合了训练集,泛化能力(适用于没训练的数据的结果较差)在某种程度上,验证集并没有充分利用交叉验证集的作用,像这种情况称为“高方差”。
- 假设训练集误差是 15%,验证集误差是 16%。且假设该案例中人的错误率几乎为 0%。可得知,算法并没有在训练集中得到很好训练,如果训练数据的拟合度不高,就是数据欠拟合,就可以说这种算法偏差比较高。
- 假设训练集误差是 15%,验证集的错误率达到 30%。在这种情况下,会认为这是方差偏差都很糟糕的情况。
- 如果训练集误差是 0.5%,验证集误差是 1%,则是很好的情况,偏差和方差都很低。
最优误差也被称为贝叶斯误差。
如果最优误差或贝叶斯误差非常高,比如 15%。此时训练误差 15%,验证误差 16%,15%的错误率对训练集来说也是非常合理的,偏差不高,方差也非常低。
需要根据实际情况(高偏差,还是高方差),采取不同的措施。
2.1.3 L2 正则化
前面提到了过拟合的问题—高方差。有两个解决方法,一个是正则化,一个是准备更多的数据。
对w用L2正则化:
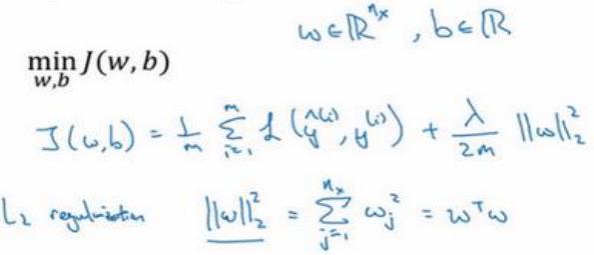
为什么一般对w用2范数?
因为w通常是一个高维参数向量,几乎可以涵盖所有参数。是否对b使用2范数的正则化,并不太影响最终结果。
L2正则化是最常见的正则化函数。
提问,为什么正则化有利于预防过拟合?
当处于过拟合状态时,若正则化𝜆设置得足够大,权重矩阵𝑊被设置为接近于 0 的值,直观理解就是把多隐藏单元的权重设为 0,于是基本上消除了这些隐藏单元的许多影响。(0这里算时比较极端的假设)
𝜆会存在一个中间值,于是会有一个接近“Just Right”的中间状态。
2.1.4 dropout 正则化
除了𝐿2正则化,还有一个非常实用的正则化方法——“Dropout(随机失活)”.
假设我们需要训练的神经网络图如下,存在过拟合现象:
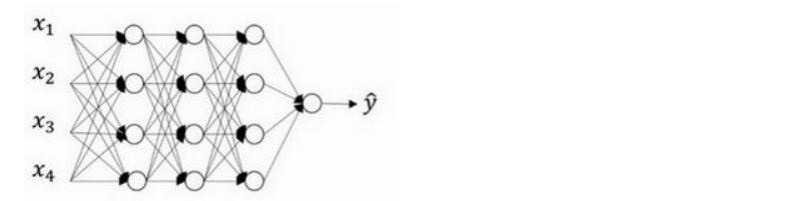
dropout 会遍历网络的每一层,并设置消除神经网络中节点的概率
假设网络中的每一层,设置每个节点得以保留和消除的概率都是 0.5。
设置完节点概率,我们会消除一些节点,然后删除掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络。
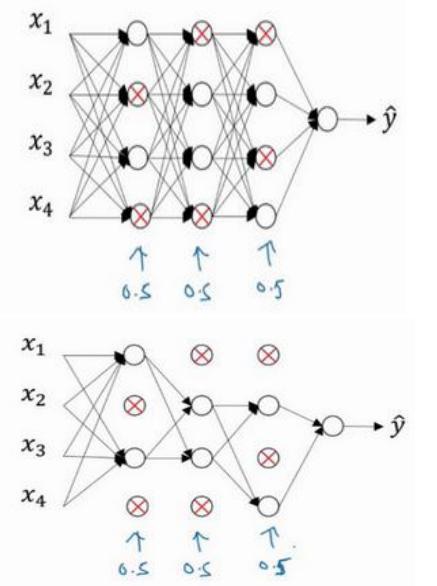
对于其他样本,我们同样这样设置概率,保留一类节点集合,删除其它类型的节点集合。
对于每个训练样本,我们都将采用一个精简后神经网络来训练它。
如何实施 dropout 呢?
下面主要讲inverted dropout(反向随机失活)。
出于完整性考虑,用一个三层(𝑙 = 3)网络来举例说明。
- 首先要定义向量𝑑,𝑑[3]表示一个三层的 dropout 向量:
d3 = np.random.rand(a3.shape[0],a3.shape[1]) - 然后看它是否小于某数,我们称之为 keep-prob,keep-prob 是一个具体数字。例如前面我们就设置的0.5。
- 接下来,从第三层中获取激活函数,叫做𝑎[3]。使用 a3=np.multiply(a3,d3),就可以利用乘法运算,得到相应元素的输出。
- 最后,进行调整,使用a3/=keep-prob。
解释原因:
50 个神经元,在一维上𝑎[3]是 50,我们通过因子分解将它拆分成50 × 𝑚维的。
假设保留和删除它们的概率分别为 80%和 20%,这意味着最后被删除或归零的单元平均有 10(50×20%=10)个。
看𝑧[4],𝑧[4] = 𝑤[4]𝑎[3] + 𝑏[4],我们的预期是,𝑎[3]减少 20%,也就是说𝑎[3]中有 20%的元素被归零,为了不影响𝑧[4]的期望值,我们需要用𝑤[4]𝑎[3]/0.8,它将会修正或弥补所需要的那20%,a[3]的期望不会变。
显然在测试阶段,我们并未使用 dropout。
因为在测试阶段进行预测时,我们不期望输出结果是随机的,如果测试阶段应用 dropout 函数,预测会受到干扰。
2.1.5 理解dropout
一种理解是:
不依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重。
dropout将产生收缩权重的平方范数的效果,和之前讲的𝐿2正则化类似;实施 dropout 的结果实它会压缩权重,并完成一些预防过拟合的外层正则化;𝐿2对不同权重的衰减是不同的,它取决于激活函数倍增的大小。
(可粗略理解为:dropout特征都有可能被随机清除,或者说该单元的输入也都可能被随机清除。机器不愿意把所有赌注都放在一个节点上,不愿意给任何一个输入加上太多权重,因为它可能会被删除,因此该单元将通过这种方式积极地传播开,并为单元的四个输入增加一点权重,通过传播所有权重)
不担心过拟合问题的,keep-prob 可以为 1。
过拟合问题比较严重的,keep-prob会需要小一点。
dropout的缺点是,代价函数J不再被明确定义,每次迭代,都会随机移除一些节点。如果要再三检查梯度下降的性能,很难进行复查。
2.1.6 其他正则化方法
除了𝐿2正则化和随机失活(dropout)正则化,还有几种方法可以减少神经网络中的过拟合:
- 数据扩增
通过随意翻转和裁剪图片等方式,我们可以增大数据集,额外生成假训练数据。
和全新的,独立的猫咪图片数据相比,这些额外的假的数据无法包含像全新数据那么多的信息,但我们这么做基本没有花费,代价几乎为零,除了一些对抗性代价。 - early stopping
术语early stopping表示提早停止训练神经网络(如验证集误差开始上升的位置)
2.1.7 归一化输入
训练神经网络,其中一个加速训练的方法就是归一化输入。假设一个训练集有两个特征,输入特征为 2 维。
归一化需要两个步骤:
- 零均值
- 归一化方差;
使用归一化输入,是为了让各特征能够从输入同等考虑。
2.1.8 梯度消失/梯度爆炸
训练神经网络的时候,导数或坡度有时会变得非常大,或者非常小,甚至于以指数方式变小,这加大了训练的难度。
假设深度为150层,在这样一个深度神经网络中,如果激活函数或梯度函数以与𝐿相关的指数增长或递减,它们的值将会变得极大或极小,从而导致训练难度上升,尤其是梯度指数小于𝐿时,梯度下降算法的步长会非常非常小,梯度下降算法将花费很长时间来学习。
2.1.9 神经网络权重的初始化
03后记
🥲关于吴恩达《深度学习》的笔记就到这了,应该暂时就当这了。
个人觉得吴恩达的课程,较李宏毅的课和“鱼书的讲解,还是有点冗长了。
目前打算看看别的书,或者更有针对性一点的论文/期刊之类的。
其实很早之前就学过一些deep learning的东西,目前读研换方向,算是“文艺复兴”了,不过就这么几年,人工智能发展也真的很快了。
粘贴一下以前在coursera学习上获得的证书,以前还申请了学生免费上课,🥹全当是纪念了

)



—— Mybatis,分页,数据源的配置及使用)



内容)


)
----配置RTC时钟及显示时间)






)