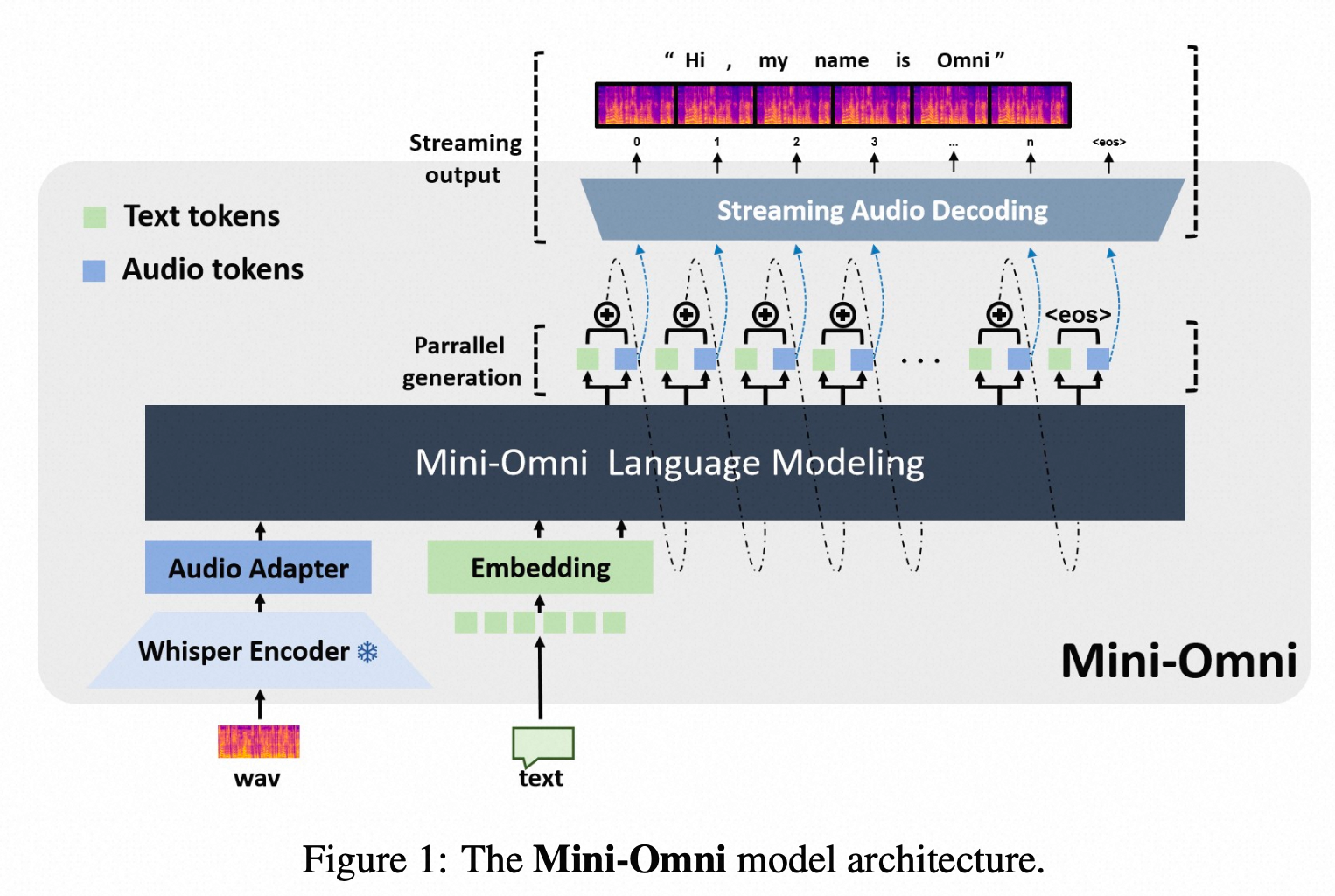
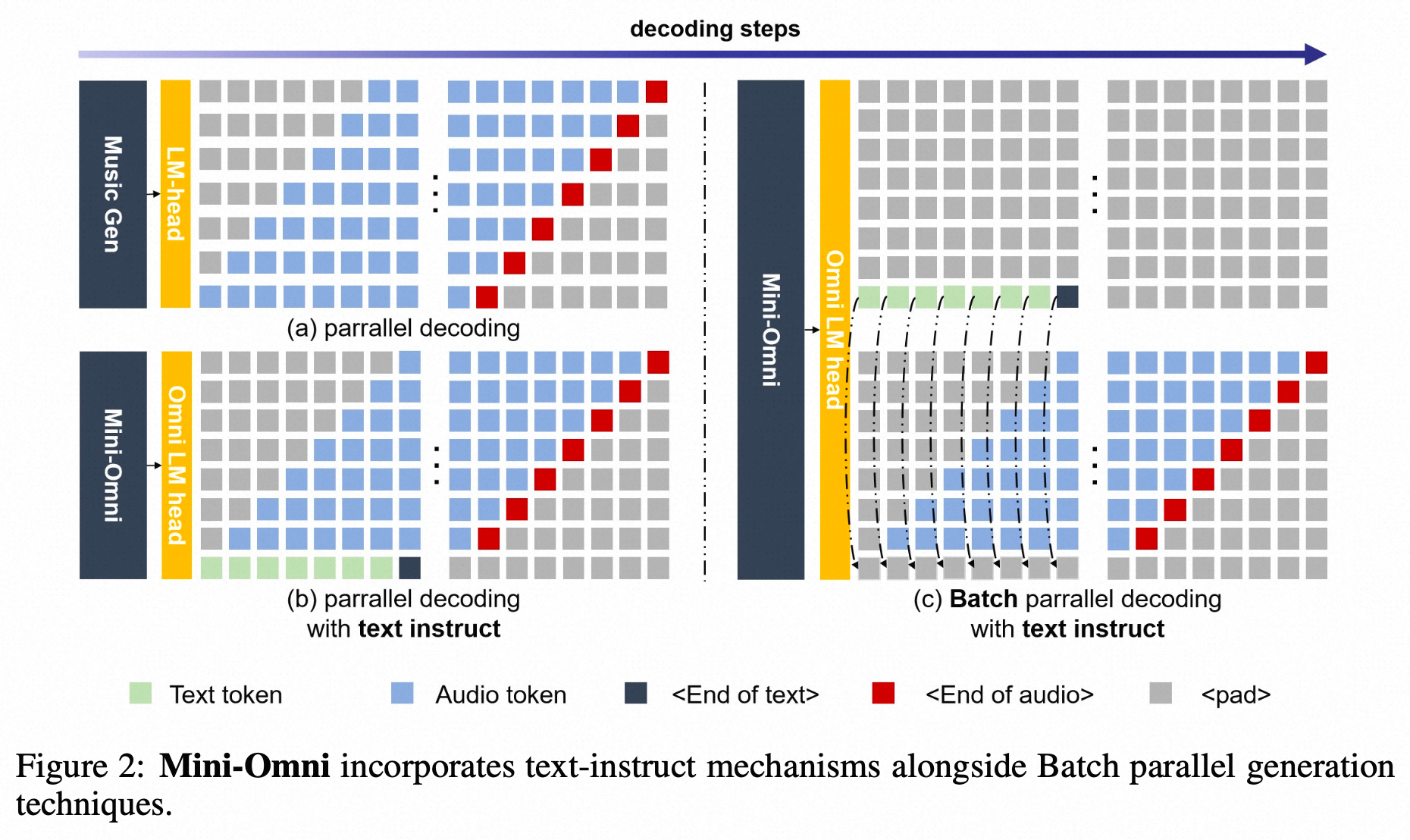
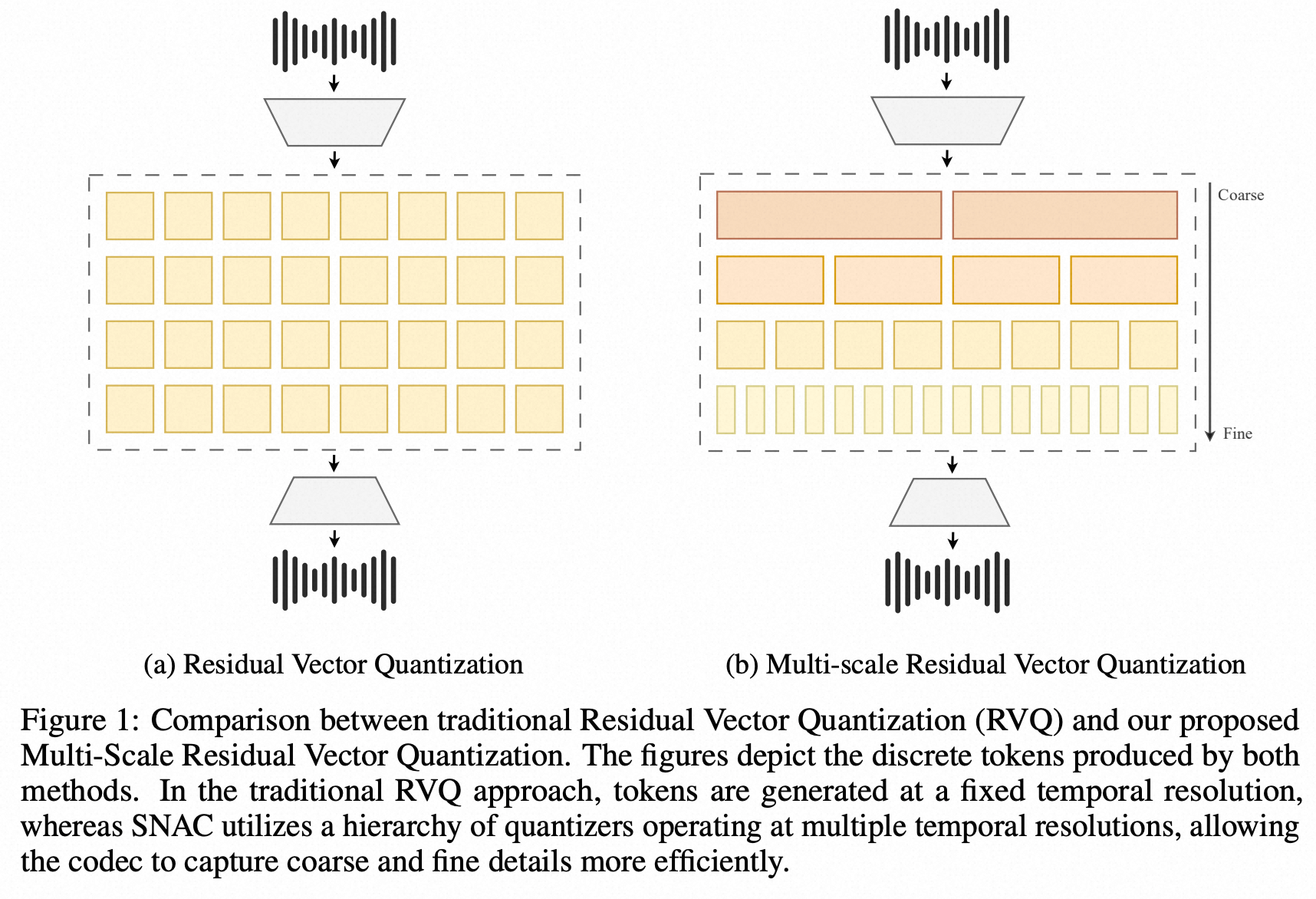
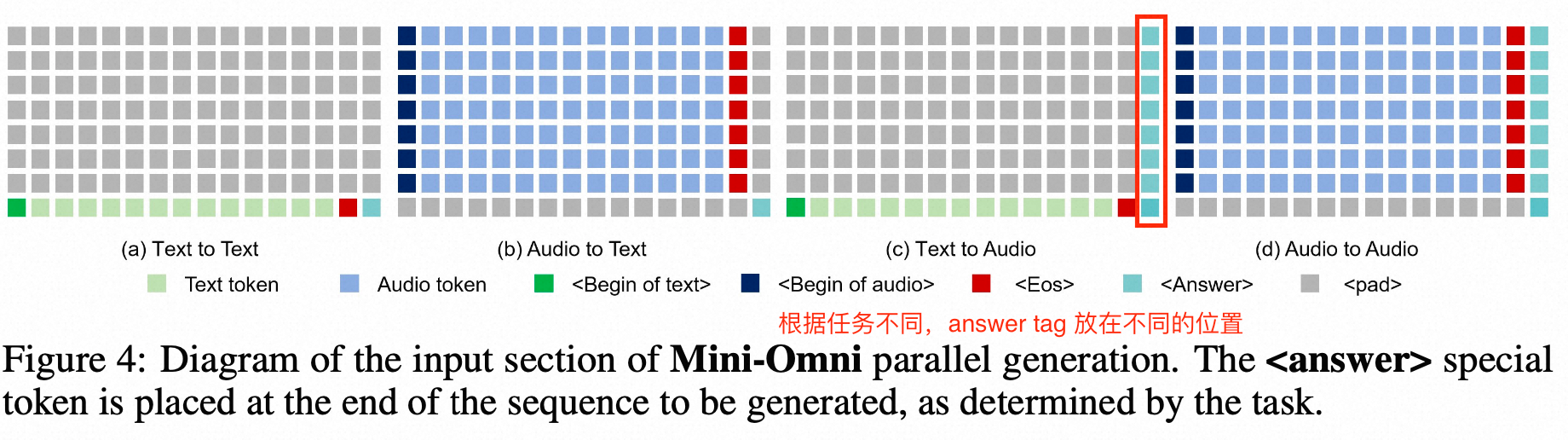
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.pswp.cn/diannao/95166.shtml 繁体地址,请注明出处:http://hk.pswp.cn/diannao/95166.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
和CT(协调转弯)双模型,二维环境下的轨迹定位。附代码下载链接)
【MATLAB例程】基于UKF的IMM例程,模型使用CA(匀加速)和CT(协调转弯)双模型,二维环境下的轨迹定位。附代码下载链接
本文介绍的MATLAB程序可以实现:基于交互式多模型(IMM)的无迹卡尔曼滤波(UKF)方法,用于二维平面中目标的运动状态估计。该算法结合了两个运动模型:匀速直线模型(CV)和匀速…

工厂智慧设备检测:多模态算法提升工业安全阈值
工厂智慧设备检测:从技术突破到场景化落地在工业4.0与智能制造的双重驱动下,工厂设备检测正经历从人工巡检到智能化监控的颠覆性变革。传统检测方式受限于人力成本、环境干扰及响应延迟,难以满足现代工厂对安全性、效率与可持续性的要求。而基…

复现论文《地形遮挡对GNSS干扰范围影响的高效仿真算法》
地形遮挡对GNSS干扰范围影响的高效仿真算法
1. 论文标题
论文标题为《地形遮挡对GNSS干扰范围影响的高效仿真算法》
2. 内容概括
该论文提出了一种高效计算地形遮挡对全球导航卫星系统(GNSS)干扰源干扰范围影响的新算法。传统基于视线可视域分析的方法存在大量冗余计算,本…
算法之拓扑排序介绍)
图论(2)算法之拓扑排序介绍
目录 一、什么是拓扑排序?
二、拓扑排序的算法实现
1 BFS算法实现
(1)算法思路
(2) 代码实现(Java)
2 DFS算法实现
(1)算法思路
(2) 代码实…

GoBy 工具联动 | GoBy AWVS 自动化漏扫工作流
GoBy 系统笔记导航 🚀:[网安工具] Web 漏洞扫描工具 —— GoBy 使用手册 AWVS 系统笔记导航 🚀:[网安工具] Web 漏洞扫描工具 —— AWVS 使用手册 0x01:GoBy AWVS —— 联动扫描简介
AWVS 是一款由 Acunetix 公司开…
)
《汇编语言:基于X86处理器》第13章 高级语言接口(1)
与C、c,Java等高级语言相比,汇编开发的效率偏低和维护成本偏高。大型的项目已经很少用汇编语言了,但并不是说汇编语言就完全没有用处了,在某些特定的领域,汇编语言还是很有用处的,比如配置硬件驱动器&#…

JVM基础【Java】
JVM基础
JVM:Java Virtual Machine(Java虚拟机)
1.Java文件的执行流程
首先认识Java文件的运行规则对字节码文件进行解释成机器码,让计算机执行内存管理
自动为对象、方法等分配内存自动垃圾回收机制,回收不再使用的对象
即时编译…

ISL9V3040D3ST-F085C一款安森美 ON生产的汽车点火IGBT模块,绝缘栅双极型晶体管ISL9V3040D3ST汽车点火电路中的线圈驱动器
ISL9V3040D3ST-F085C 是一款 安森美 (ON)生产的汽车点火 IGBT模块(绝缘栅双极型晶体管),主要用于汽车点火电路中的线圈驱动器,具有内部二极管电压箝位功能,可减少外部组件需求。
核心用途
该…

用Python实现Excel转PDF并去除Spire.XLS水印
最近业务需要,成功用Python原生代码实现了原本需要付费的Spire.XLS库的Excel转PDF功能,并彻底去除了转换后PDF中的评估水印"Evaluation Warning: The document was created with Spire.XLS for Python"。该解决方案完全开源免费,不…

论文学习22:UNETR: Transformers for 3D Medical Image Segmentation
代码来源
unetr
模块作用
具有收缩和扩展路径的全卷积神经网络 (FCNN) 在大多数医学图像分割应用中表现出色,但卷积层的局部性限制了其学习长距离空间依赖性的能力。受 Transformer 在自然语言处理 (NLP) 领域近期在长距离序列学习方面取得的成功的启发ÿ…
)
Jmeter使用第一节-认识面板(Mac版)
常用的基础元件(10个)1、测试计划:总体项目容器,其他元件需要建立在这个目录下面2、线程组:可以设置线程数、循环次数等参数来模拟用户行为。一个用户可用于接口测试,多个用户则可用于性能压测。“线程数”…

微软披露Exchange Server漏洞:攻击者可静默获取混合部署环境云访问权限
微软近日发布安全公告,披露一个影响本地版Exchange Server的高危漏洞(编号CVE-2025-53786,CVSS评分为8.0)。该漏洞在特定条件下可能允许攻击者提升权限,Outsider Security公司的Dirk-jan Mollema因报告此漏洞获得致谢。…

大模型中的反向传播是什么
反向传播(Backpropagation)是大模型(如GPT、BERT等)训练过程中的核心算法,用于高效计算损失函数对神经网络中所有参数的梯度。这些梯度随后被用于优化器(如Adam)更新参数,使模型逐渐…

数集相等定义凸显解析几何几百年重大错误:将无穷多各异点集误为同一集
数集相等定义凸显解析几何几百年重大错误:将无穷多各异点集误为同一集
黄小宁
本文据中学生就应熟悉的数集相等概念推翻了直线公理和平面公理表明“举世公认”不能是检验真理的唯一标准。“真理往往在少数人手里”。
请看图片举世公认:因数学是严密精确的…

container_of函数使用
用于根据结构体成员的地址反推整个结构体地址的宏定义。其核心作用是通过成员变量地址定位到其所属的结构体实例。struct panel_tm145{struct drm_panel base;}static inline struct panel_tm145 * to_panel_tm145(struct drm_panel *panel){return container_of(panel, struct…

【MySQL基础篇】:MySQL索引——提升数据库查询性能的关键
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:MySQL篇–CSDN博客 文章目录索引一.MySQL与存储二.索引的理解1.Page页模式理解单个Page理解…

TD-IDF的一些应用
TF-IDF(词频 - 逆文档频率)作为经典的文本特征提取算法,在自然语言处理(NLP)领域应用广泛。它能将文本转化为可量化的数值特征,为后续的数据分析和建模提供基础。本文结合实际场景,介绍如何用 P…

Redis 缓存问题详解及解决方案
一、缓存击穿 (Cache Breakdown)
原理:
某个热点 Key 突然过期,同时大量并发请求该 Key,导致请求直接穿透缓存击穿到数据库。
解决方案:
互斥锁 (Mutex Lock)
当缓存失效时,仅允许一个线程重建缓存,其他线程…
)
一周一个数据结构 第一周 --- 顺序表(下)
文章目录一、ArrayList的构造二、ArrayList常见操作三、ArrayList的遍历四、ArrayList练习1.【小练习】2.杨辉三角3.简单的洗牌算法五、ArrayList小结在上一章节中,我们通过代码示例以及画图的方式详细了解了顺序表,并模拟实现了它。那么,是不…

OpenCV的关于图片的一些运用
一、读取图片通过cv2库中的imread()方法读取图片代码:import cv2
a cv2.imread(1.png)
cv2.imshow(tu,a)
b cv2.waitKey(4000) # 图片执行时间
cv2.destroyAllWindows() # 关闭所有端口
print("图像形状(shape):",a.shape)
print…