1.基本介绍
1.1 什么是分布式日志
在分布式应用中,日志被分散在储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。所以我们使用集中化的日志管理,分布式日志就是对大规模日志数据进行采集、追踪、处理。
1.2 为什么要使用分布式日志
一般我们需要进行日志分析场景:直接在日志文件中grep、awk就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
1.3 ELK 分布式日志
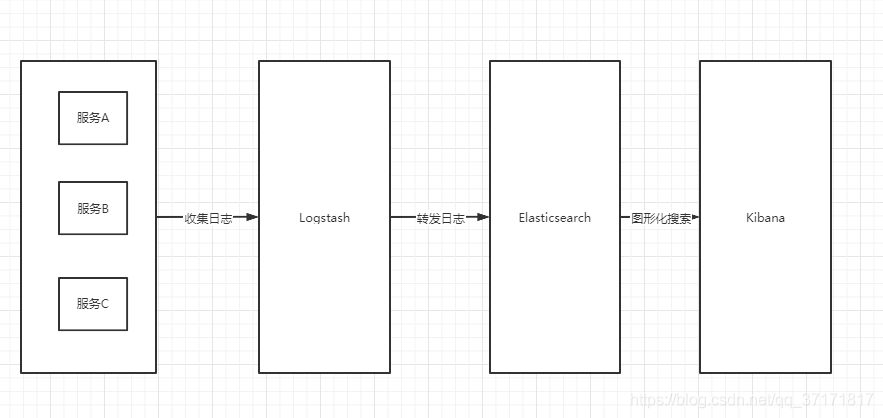
- 实际上ELK是三款软件的简称,分别是Elasticsearch、 Logstash、Kibana组成。
- Elasticsearch 基于java,是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
- Kibana 基于nodejs,也是一个开源和免费的工具,Kibana可以为Logstash和ElasticSearch提供的日志分析友好的Web 界面,可以汇总、分析和搜索重要数据日志。
- Logstash 基于java,是一个开源的用于收集,分析和存储日志的工具。
- 下面是ELK的工作原理:
2.实战
2.1 搭建elk环境
本环境用于接收各logstash发送的日志数据。
具体,参考:https://core815.blog.csdn.net/article/details/149837061
2.2 准备日志文件
日志文件,可以指向应用系统具体文件目录,本文准备了测试文件,可在文末“相关资源”章节获取。
2.3 安装logstash
安装文件,放到“/home”路径下:
tar -zxvf logstash-9.1.2-linux-x86_64.tar.gz
编写配置文件:
cd /home/logstash-9.1.2/bin
vim logstash-elasticsearch.conf
logstash-elasticsearch.conf:
# INPUT 模块:定义日志来源
input {file {# 监听 /home/logs/ 目录下所有 .log 文件path => "/home/logs/*.log"# 首次启动时从文件开头读取(历史日志全量导入)start_position => "beginning"# 禁用 sincedb 记录(每次重启均重新读取文件,适用于测试环境)sincedb_path => "/dev/null"# 多行合并编解码器(用于处理跨行日志,如 Java 异常堆栈)codec => multiline {# 匹配以时间戳开头的行(格式示例:2025-08-13 10:00:00)pattern => "^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}"# true 表示不匹配 pattern 的行合并到上一事件negate => true# 将当前行合并到上一事件的末尾what => "previous"# 强制未完成的多行事件每 3 秒输出一次auto_flush_interval => 3}}
}# FILTER 模块:数据处理逻辑
filter {# 若文件路径包含 "info"(如 /home/logs/app_info.log)if [path] =~ "info" {# 标记日志类型为 "info"mutate { replace => { type => "info" } }# 使用 GROK 解析 Apache 组合日志格式(提取 IP、方法、状态码等字段)grok {match => { "message" => "%{COMBINEDAPACHELOG}" }}# 解析日志中的时间戳,覆盖默认的 @timestampdate {match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ] # 格式示例:13/Aug/2025:14:00:00 +0800}}# 若文件路径包含 "error"(如 /home/logs/error.log)else if [path] =~ "error" {# 标记日志类型为 "error"mutate { replace => { type => "error" } }}# 其他日志文件else {# 标记日志类型为 "random_logs"mutate { replace => { type => "random_logs" } }}
}# OUTPUT 模块:定义数据输出目标
output {# 输出到 Elasticsearchelasticsearch {hosts => "10.86.97.210:9200" # ES 服务器地址(生产环境建议改为数组格式:["ip:port"])user => "elastic" # 用户名(正确字段应为 username)password => "test@123456" # 密码(特殊符号需用双引号包裹)# 缺失参数建议添加:# ssl => true # 若 ES 启用 HTTPS 需开启# index => "logs-%{type}-%{+YYYY.MM.dd}" # 按类型和日期分隔索引}# 同时输出到控制台(调试用,生产环境可移除)stdout {codec => rubydebug # 以易读格式打印结构化事件}
}
创建logstash专用用户:
sudo groupadd -r logstash
sudo useradd -r -s /bin/bash -g logstash -d /home/logstash-9.1.2 -m logstash
调整logstash目录权限:
# 将 Logstash 安装目录所有权赋予新用户
sudo chown -R logstash:logstash /home/logstash-9.1.2/
# 确保日志目录可写入
sudo mkdir /var/log/logstash
sudo chown logstash:logstash /var/log/logstash
使用测试命令检查语法:
sudo -u logstash /home/logstash-9.1.2/bin/logstash -f /home/logstash-9.1.2/bin/logstash-elasticsearch.conf --config.test_and_exit
以专用用户身份启动:
sudo -u logstash /home/logstash-9.1.2/bin/logstash -f /home/logstash-9.1.2/bin/logstash-elasticsearch.conf
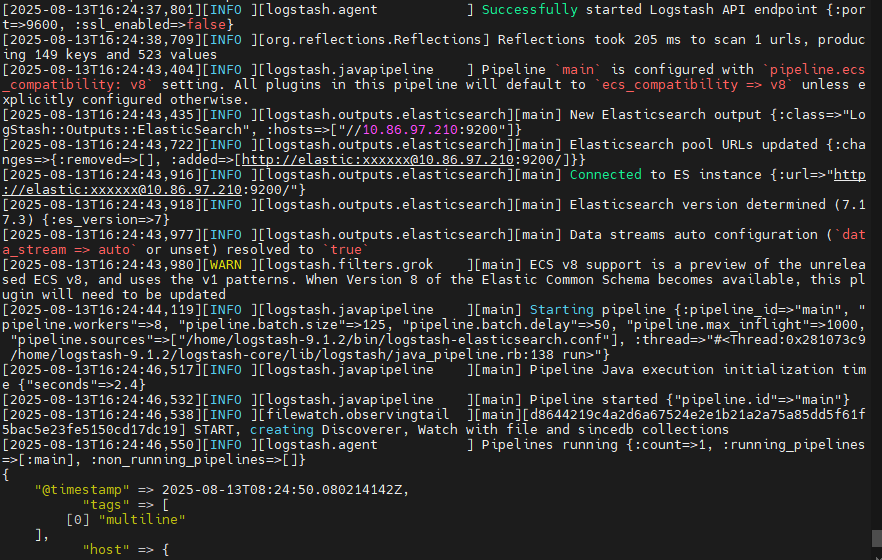
启动效果:
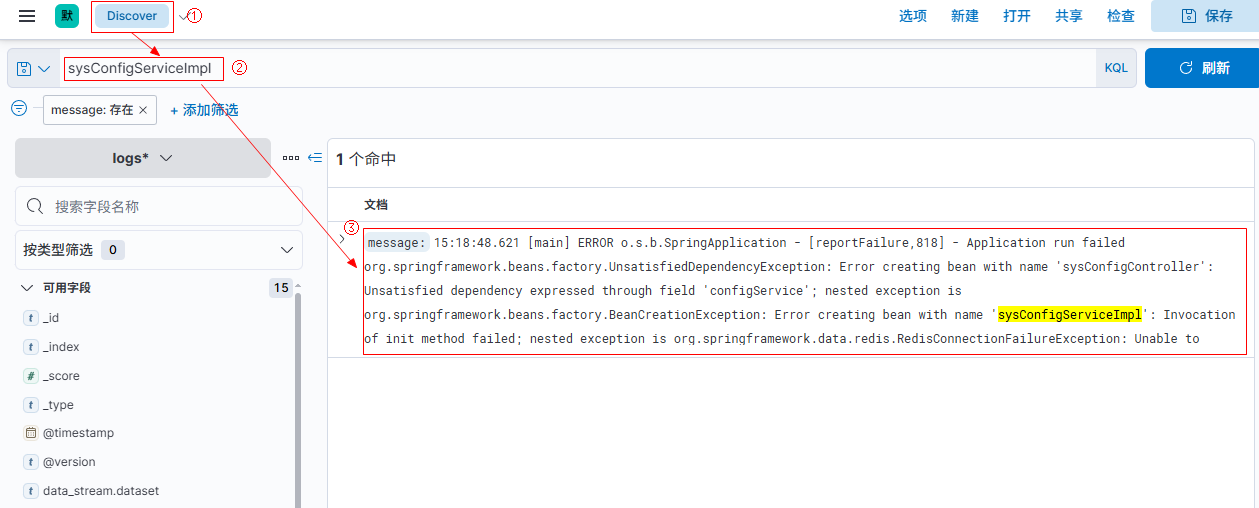
2.4 kibana查看
kibana访问地址:
http://10.86.97.210:5601/
账号:elastic
密码:test@123456
3.相关资源
百度网盘:https://pan.baidu.com/s/1DFlQim7xPwx7uEKOGTd85A?pwd=4i76






![[GESP202309 六级] 2023年9月GESP C++六级上机题题解,附带讲解视频!](http://pic.xiahunao.cn/[GESP202309 六级] 2023年9月GESP C++六级上机题题解,附带讲解视频!)


-Hello World)


![[前端算法]排序算法](http://pic.xiahunao.cn/[前端算法]排序算法)



:Dify 的日志分析与监控)


