使用 Jieba 库进行 TF-IDF 关键词提取(以《红楼梦》为例)
在中文文本分析中,TF-IDF(Term Frequency - Inverse Document Frequency) 是最常用的关键词提取方法之一。它通过评估词在单个文档中的出现频率和在所有文档中的稀有程度,来衡量该词的重要性。
本文将以《红楼梦》分卷文本为例,演示如何使用 jieba 库完成分词、停用词过滤,并最终进行 TF-IDF 关键词提取。
一、TF-IDF 的定义
TF-IDF(Term Frequency-Inverse Document Frequency,词频 - 逆文档频率)是文本挖掘领域中一种常用技术,其核心作用是评估某个词语在特定文档中的重要程度。该指标由两部分构成:
- 词频(TF):指一个词语在当前文档中出现的频率。
- 逆文档频率(IDF):用于衡量该词语在整个文档集合中的普遍重要性(即该词是否在多数文档中都频繁出现)。
通常来说,一个词语的 TF-IDF 值越高,就意味着它在当前文档中的重要性越高。
二、选择 jieba 库的原因
jieba 是一款优秀的中文分词工具库,其突出特点使其成为众多场景下的优选,包括:
- 支持三种不同的分词模式,可适应多样化的分词需求。
- 允许用户导入自定义词典,提升对特定领域词汇的分词准确性。
- 具备高效的词性标注功能,能快速为词语标注所属词性。
- 内置 TF-IDF 关键词提取功能,方便直接从文本中提取关键信息。
- 整体设计轻量,且操作简单易懂,易于上手使用。
代码一:准备数据
我们将准备 ./红楼梦 文件夹,其中:
红楼梦正文:
红楼梦.txt用户自定义词典:
红楼梦词库.txt(保证人名、地名等专业词汇的分词准确性)中文停用词表:
StopwordsCN.txt(去除“的”“了”等无意义的高频词)空文件夹
./红楼梦/分卷:用于存放代码产生分卷
《红楼梦》按卷分割文本代码详解
import os# 打开整本红楼梦文本
file = open('.\\红楼梦\\红楼梦.txt', encoding='utf-8')flag = 0 # 标记是否已打开分卷文件# 遍历整本小说每一行
for line in file:# 如果该行包含“卷 第”,表示这是卷的开头if '卷 第' in line:juan_name = line.strip() + '.txt' # 用该行作为分卷文件名path = os.path.join('.\\红楼梦\\分卷', juan_name)print(path)if flag == 0:# 第一次遇到卷标题,打开分卷文件准备写入juan_file = open(path, 'w', encoding='utf-8')flag = 1else:# 遇到新的卷标题时,先关闭之前的分卷文件,再打开新的juan_file.close()juan_file = open(path, 'w', encoding='utf-8')continue# 过滤空行和广告信息(如“手机电子书·大学生小说网”)if line.strip() != "" and "手机电子书·大学生小说网" not in line:juan_file.write(line) # 写入当前分卷文件# 最后关闭最后一个分卷文件及整本书文件
juan_file.close()
file.close()
代码流程说明
打开整本《红楼梦》文本文件
使用
open以 utf-8 编码打开.\\红楼梦\\红楼梦.txt文件,准备逐行读取。
初始化标记变量
flagflag = 0表示还没有打开分卷文件。
逐行读取整本小说内容
使用
for line in file:依次处理每一行文本。
判断是否遇到新分卷开头
通过判断字符串
'卷 第'是否在当前行中,识别分卷标题行。例如“卷 第1卷”,代表这是一个新的分卷开始。
新卷文件的创建与切换
如果是第一次遇到分卷标题(
flag == 0),则新建一个对应的分卷文件,准备写入。如果之前已经打开了分卷文件,先关闭旧文件,再打开新分卷文件。
文件名以当前行内容加
.txt后缀命名,并保存在.\\红楼梦\\分卷目录下。
非分卷标题行内容处理
过滤空行(
line.strip() != "")和广告信息(不包含"手机电子书·大学生小说网")。合格的行写入当前打开的分卷文件中。
结束时关闭所有文件
循环结束后,关闭当前分卷文件和整本小说文件。
运行效果
将
红楼梦.txt按照“卷 第X卷”的行作为分界点,生成多个如“卷 第1卷.txt”、“卷 第2卷.txt”等文件,分别保存在红楼梦\分卷文件夹中。每个分卷文件包含对应的章节内容,便于后续的分词和关键词分析。
代码二:对每个分卷提取词典
1. 导入必要库
import pandas as pd
import os
import jieba
pandas用于创建和操作结构化数据(DataFrame),方便后续处理。os用于遍历文件夹,获取分卷文件路径。jieba是一个常用的中文分词库,用于将连续文本切分成词语。
2. 读取分卷文本
filePaths = []
fileContents = []
for root, dirs, files in os.walk(r"./红楼梦/分卷"):for name in files:filePath = os.path.join(root, name) # 获取每个分卷的完整路径print(filePath)filePaths.append(filePath) # 记录该路径到filePaths列表f = open(filePath, 'r', encoding='utf-8')fileContent = f.read() # 读取整个文件内容为字符串f.close()fileContents.append(fileContent) # 把内容加入列表
使用
os.walk递归遍历./红楼梦/分卷文件夹,获取所有分卷文本文件路径和名称。将每个分卷文件的路径和对应的文本内容分别存储到
filePaths和fileContents两个列表中。读取文件时用 UTF-8 编码,保证中文字符正确读取。
3. 构建 pandas DataFrame
corpos = pd.DataFrame({'filePath': filePaths,'fileContent': fileContents
})
将分卷的路径和内容以字典形式传入,生成一个二维表格结构的 DataFrame。
每一行对应一个分卷文件,包含:
filePath:该分卷的文件路径fileContent:该分卷对应的文本内容(字符串)
这样方便后续批量处理。
4. 加载用户自定义词典和停用词表
jieba.load_userdict(r"./红楼梦/红楼梦词库.txt")
stopwords = pd.read_csv(r"./红楼梦/StopwordsCN.txt",encoding='utf-8', engine='python', index_col=False)
jieba.load_userdict()用来加载用户定义的词典,解决默认词库中可能没有的专有名词、人名地名、书中特殊词汇的分词准确度问题。stopwords读取停用词文件,一般是高频无实际含义的词(如“的”、“了”、“在”等),需要过滤掉,避免影响后续分析。
stopwords是一个 DataFrame,其中一列(假设列名为stopword)包含所有停用词。
5. 创建分词输出文件
file_to_jieba = open(r"./红楼梦/分词后汇总.txt", 'w', encoding='utf-8')
打开一个新的文本文件,用来存储所有分卷的分词结果。
使用写入模式,每个分卷分词结果写入一行,方便后续分析。
6. 对每个分卷逐条处理
for index, row in corpos.iterrows():juan_ci = ''filePath = row['filePath']fileContent = row['fileContent']segs = jieba.cut(fileContent) # 对该卷内容进行分词,返回一个生成器for seg in segs:# 如果分词结果不是停用词且不是空字符串if seg not in stopwords.stopword.values and len(seg.strip()) > 0:juan_ci += seg + ' ' # 词语之间用空格分开file_to_jieba.write(juan_ci + '\n') # 写入该卷分词结果,换行区分不同卷
corpos.iterrows()按行遍历 DataFrame,每行对应一个分卷。取出文本内容后,用
jieba.cut()对文本分词,得到一个可迭代的词语序列。对每个词:
判断它是否为停用词(通过停用词列表过滤)
判断是否为空白(防止多余空格或特殊符号)
过滤后的词汇拼接成字符串,用空格分隔,形成分词后的“句子”。
每个分卷的分词结果写入一行,方便后续按行读取、TF-IDF等分析。
7. 关闭文件
file_to_jieba.close()
关闭分词结果文件,保证写入完整。
运行结果:
代码三:计算 TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd1. 读取分词后的汇总文本
File = open(r".\红楼梦\分词后汇总.txt", 'r', encoding='utf-8')
corpus = File.readlines() # 每行作为一个文档内容
每行对应一卷(或一回)的分词结果。
corpus 是一个列表,
corpus[i]表示第 i 卷的文本。
2. 初始化并计算 TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(corpus)
wordlist = vectorizer.get_feature_names()
TfidfVectorizer()自动执行:统计每个词的词频(TF)
计算逆文档频率(IDF)
得到每个词在每个文档中的 TF-IDF 值
wordlist是词汇表(所有出现的词)。
3. 构建 DataFrame 存储结果
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
tfidf是稀疏矩阵(需要.todense()转成稠密矩阵才能放进 DataFrame)。转置
.T后:行(index)是词汇
列是文档(每卷)
可以打印出部分数据直观理解:
print(wordlist) print(tfidf) # print(tfidf.todense()) print(df.head(20))wordlist:词汇表
tfidf:
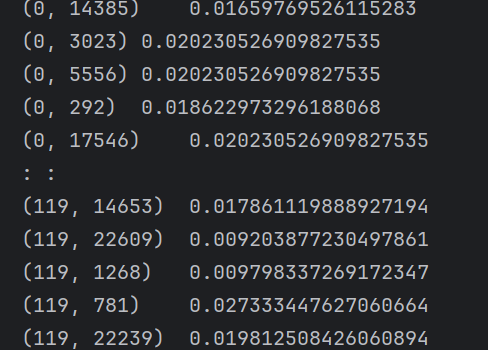
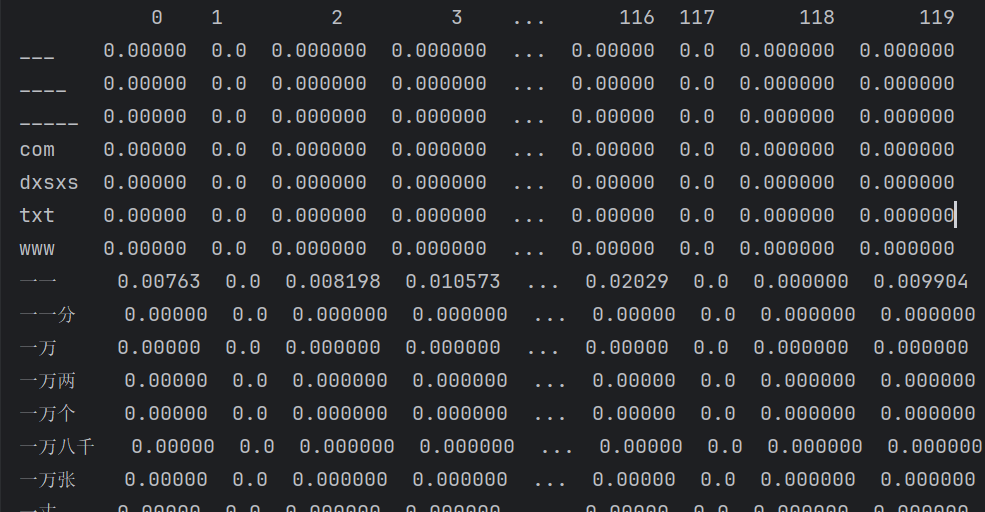
(0,14385)即表示一个二维坐标
0/119→ 这是文档编号(row index),表示这是第 1 篇文档(编号从 0 开始)。14385→ 这是词在词汇表(vocabulary)中的编号(column index),对应某个特定的单词,比如可能是
"machine"或"learning"(具体要看vectorizer.get_feature_names_out()对应表)。
0.01659769526115283→ 这是这个单词在该文档中的 TF-IDF 权重,数值越大,说明这个单词在这篇文章中越重要(出现频率高,但在其他文档中不常见)。df:
行索引(index):
___、____、txt、一一等是分词后的词语。列索引(0, 1, 2, ...):表示第几卷(文档),从
0列到119列,说明总共有 120 卷/文档。单元格的数值:该词在该卷里的 TF-IDF 权重(越大表示该词在这卷中越重要)。

4. 提取每卷的 Top 10 关键词
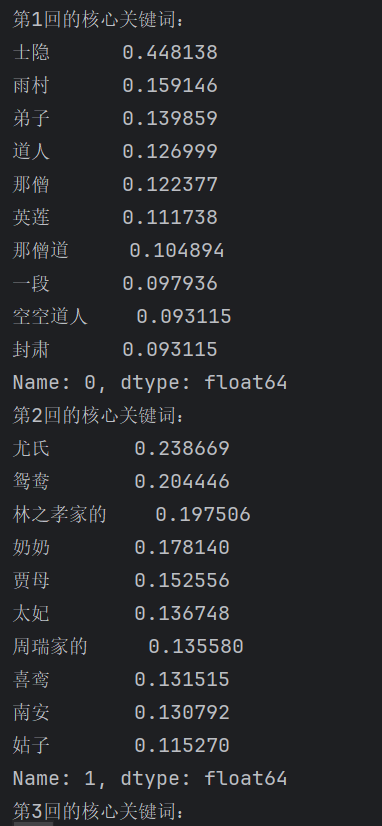
for i in range(len(corpus)):top_keywords = df.iloc[:, i].sort_values(ascending=False).head(10)print(f'第{i+1}回的核心关键词:\n{top_keywords}')
取第
i列(即第 i 卷的所有词的 TF-IDF 值)sort_values(ascending=False)降序排列head(10)取权重最高的 10 个关键词
结果:
扩展:可视化每卷 Top 10 关键词
以第 1 卷为例,绘制柱状图:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# [:, 0]取第1回,[:, 119]取第120回
top_keywords = df.iloc[:, 0].sort_values(ascending=False).head(10)plt.figure(figsize=(8,5))
plt.barh(top_keywords.index, top_keywords.values, color='skyblue')
plt.gca().invert_yaxis() # 倒序
plt.title("第1回的TF-IDF关键词")
plt.xlabel("TF-IDF权重")
plt.show()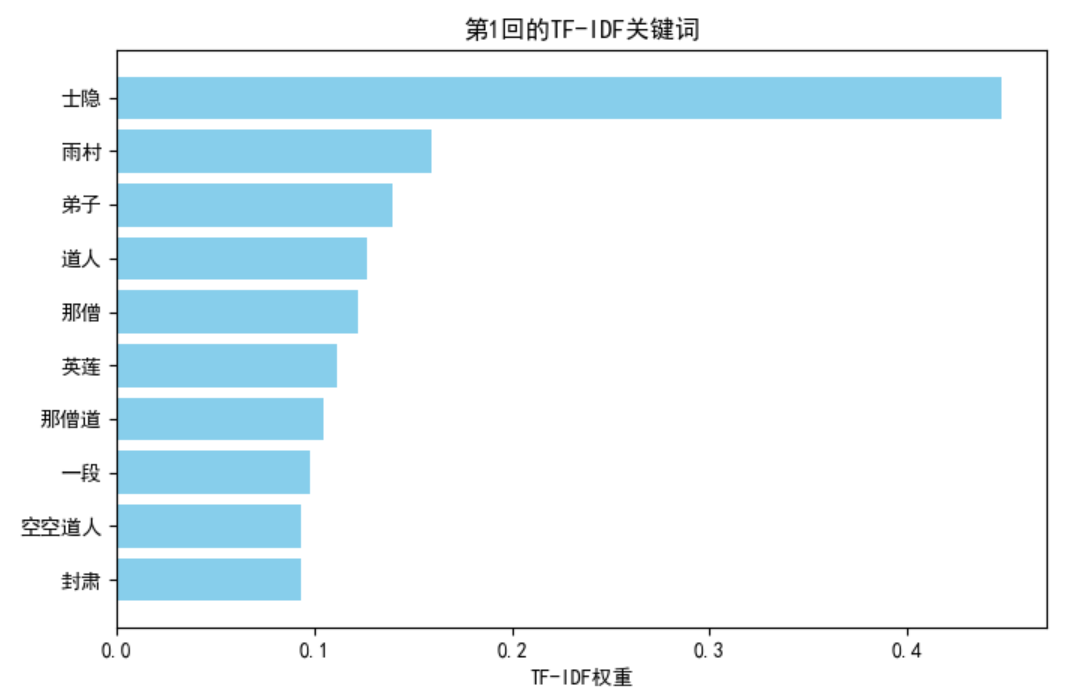
改进建议
自动去掉空行
corpus = [line.strip() for line in corpus if line.strip()]避免空文档导致向量化器报错。
指定分隔符
因为你的分词结果是用空格分隔的,可以告诉TfidfVectorizer:vectorizer = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b")保存结果
直接把每卷关键词存到 CSV,便于后续分析:all_keywords = {} for i in range(len(corpus)):all_keywords[f"第{i+1}回"] = df.iloc[:, i].sort_values(ascending=False).head(10).index.tolist() pd.DataFrame.from_dict(all_keywords, orient='index').to_csv("红楼梦_TF-IDF关键词.csv", encoding="utf-8-sig")
总结
本文实现了从原始《红楼梦》文本到关键词提取的完整流程:
对正文进行分卷
读取分卷内容
自定义词典 + 停用词过滤
分词并保存
使用
jieba.analyse.extract_tags进行 TF-IDF 关键词提取TfidfVectorizer计算 TF-IDF
扩展:可视化权重排序
通过这种方式,我们不仅能提取整本书的主题关键词,还能按卷分析主题变化,为文本挖掘、主题建模、人物关系分析等工作打下基础。








)



——枚举类)




)
:高效的优先级队列实现)
 --------python中的os库全指南)