文章目录
- 自然语言处理(NLP)
- 一、什么是自然语言处理(NLP)?
- 二、NLP 的核心目标
- 三、NLP 的主要应用方向(应用场景)
- 四、NLP 的基本概念
- 五、NLP 的基本处理流程
- 1. 文本预处理
- 2. 特征表示
- 3. 模型选择与训练
- 4. 模型评估
- 5. 部署与应用
- 六、NLP 的关键技术演进
- NLP 特征工程详解
- 一、传统 NLP 中的特征工程
- 1. 独热编码(One-Hot Encoding)
- 2. TF-IDF
- 3. N-Grams 特征
- 二、词向量
- 三、深度学习中的 NLP 特征输入
- 1. 词嵌入与分布式表示
- 1.1 传统编码的局限性
- 1.2 分布式表示
- 2. 稠密编码(特征嵌入)
- 3. 词嵌入算法
- 3.1 EmbeddingLayer
- 实现步骤
- 3.2 word2vec
- CBOW 连续词袋模型
- Skip-gram
- Gensim 中 Word2Vec 使用
自然语言处理(NLP)
一、什么是自然语言处理(NLP)?
自然语言处理(Natural Language Processing,简称 NLP)是人工智能(AI)的一个分支,致力于让计算机能够理解、生成、分析和处理人类语言(如中文、英文等)。
简单说:让机器“听懂”和“会说”人话。
二、NLP 的核心目标
| 目标 | 说明 |
|---|---|
| 理解语言 | 从文本中提取语义、情感、意图等信息 |
| 生成语言 | 让机器写出通顺、有逻辑的句子或文章 |
| 语言转换 | 如机器翻译、语音识别与合成 |
| 交互能力 | 实现人机对话,如智能客服、语音助手 |
三、NLP 的主要应用方向(应用场景)
| 应用 | 说明 | 实例 |
|---|---|---|
| 文本分类 | 判断文本属于哪一类 | 垃圾邮件识别、新闻分类 |
| 情感分析 | 分析文本的情感倾向 | 商品评论是好评还是差评 |
| 命名实体识别(NER) | 识别文本中的人名、地名、组织等 | “马云在杭州创立阿里巴巴” → 马云(人名)、杭州(地名)、阿里巴巴(组织) |
| 机器翻译 | 将一种语言自动翻译成另一种 | 谷歌翻译、DeepL |
| 问答系统 | 根据问题给出答案 | 智能客服、Siri、ChatGPT |
| 文本生成 | 自动生成文章、摘要、对话 | 写作助手、AI写诗、新闻摘要 |
| 语音识别与合成 | 语音转文字 / 文字转语音 | 语音输入法、智能音箱 |
| 信息抽取 | 从文本中提取结构化信息 | 从简历中提取姓名、学历、工作经验 |
| 文本摘要 | 将长文本压缩为短摘要 | 新闻摘要、论文摘要 |
| 对话系统 | 实现人机对话 | 智能客服、聊天机器人 |
四、NLP 的基本概念
| 概念 | 解释 |
|---|---|
| 分词(Tokenization) | 将句子切分成词语或子词(中文需分词,英文按空格) |
| 词性标注(POS) | 标注每个词的词性(名词、动词、形容词等) |
| 句法分析 | 分析句子的语法结构(主谓宾) |
| 语义分析 | 理解词语和句子的含义 |
| 停用词(Stop Words) | 无实际意义的词(如“的”、“了”、“is”、“the”),常被过滤 |
| 词向量(Word Embedding) | 将词语表示为向量,使语义相近的词向量也相近(如 Word2Vec、GloVe) |
| 上下文表示 | 考虑词语在句子中的上下文(如 BERT、Transformer) |
| 预训练模型 | 先在大规模语料上训练,再在具体任务上微调(如 BERT、RoBERTa、ChatGLM) |
五、NLP 的基本处理流程
一个典型的 NLP 任务处理流程如下:
1. 文本预处理
- 分词(中文用 jieba、英文用 split/spaCy)
- 去除标点、停用词、数字等
- 转小写(英文)
- 词干提取 / 词形还原(英文)
2. 特征表示
- One-Hot 编码:简单但稀疏
- 词袋模型(Bag of Words, BoW)
- TF-IDF:衡量词的重要性
- 词向量(Word2Vec、FastText)
- 上下文向量(BERT、Transformer)
3. 模型选择与训练
- 传统方法:朴素贝叶斯、SVM、CRF
- 深度学习:RNN、LSTM、GRU、Transformer、BERT
- 预训练 + 微调(主流范式)
4. 模型评估
- 分类任务:准确率、精确率、召回率、F1
- 生成任务:BLEU、ROUGE、METEOR
- 语义任务:相似度、人工评估
5. 部署与应用
- 导出模型(ONNX、TorchScript)
- 集成到 Web、App、API 服务中
六、NLP 的关键技术演进
| 阶段 | 技术 | 特点 |
|---|---|---|
| 1990s | 规则 + 统计方法 | 依赖人工规则和特征工程 |
| 2000s | 机器学习(SVM、CRF) | 使用 TF-IDF 等特征 |
| 2013~2018 | 深度学习(RNN、CNN) | 自动学习特征,但难处理长依赖 |
| 2018~至今 | 预训练模型(BERT、GPT) | 基于 Transformer,上下文理解强,效果卓越 |
🔥 当前主流:Transformer + 预训练 + 微调
NLP 特征工程详解
特征工程是指将原始文本转换为机器学习模型可理解的数值型输入的过程。在 NLP 中,特征工程是模型性能的关键。
一、传统 NLP 中的特征工程
1. 独热编码(One-Hot Encoding)
每个词被映射为一个二进制向量,向量长度等于类别总数,仅有一个位置为1(对应词的索引),其余为0。
示例
词表:["我", "爱", "学习", "AI"] → 大小为 4
- “我” →
[1, 0, 0, 0] - “爱” →
[0, 1, 0, 0]
优点:
- 消除顺序偏差:避免整数编码(如 0、1、2)引入的虚假顺序关系。
- 简单直观:易于实现,适用于线性模型、树模型等。
缺点:
- 维度爆炸:类别多时会导致高维稀疏向量(如词汇表有10万词时,向量长度为10万)。
- 稀疏性:大部分位置为0,计算和存储效率低。
- 忽略语义:无法捕捉词与词之间的关联(如“北京”和“天安门”可能相关)。
2. TF-IDF
改进版词袋模型,衡量一个词对文档的重要性。
-
TF:词在文档中出现的频率
TF(t,d)=词 t在文档 d中出现的次数文档 d的总词数\text{TF}(t, d) = \frac{\text{词 } t \text{ 在文档 } d \text{ 中出现的次数}}{\text{文档 } d \text{ 的总词数}} TF(t,d)=文档 d 的总词数词 t 在文档 d 中出现的次数
-
IDF:log(总文档数 / 包含该词的文档数),越少见的词,IDF 越高
IDF(t,D)=log(N1+包含词 t的文档数)\text{IDF}(t, D) = \log \left( \frac{N}{1 + \text{包含词 } t \text{ 的文档数}} \right) IDF(t,D)=log(1+包含词 t 的文档数N)
-
权重 = TF × IDF
【示例】
假设我们有一个小型语料库,包含 3 个文档(比如 3 篇新闻):
- D1:
the cat sat on the mat - D2:
the dog ran on the road - D3:
the cat and the dog are friends
我们的目标是:计算每个词在每篇文档中的 TF-IDF 值,以衡量其重要性。
第一步:构建词表
将所有文档中的词提取出来,去重后得到词表:
{the, cat, sat, on, mat, dog, ran, road, and, are, friends}
共 11 个词。
第二步:计算 TF(词频)
公式:
TF(t,d)=词 t在文档 d中出现的次数文档 d的总词数\text{TF}(t, d) = \frac{\text{词 } t \text{ 在文档 } d \text{ 中出现的次数}}{\text{文档 } d \text{ 的总词数}} TF(t,d)=文档 d 的总词数词 t 在文档 d 中出现的次数
我们先统计每个文档的总词数:
- D1: 6 个词
- D2: 6 个词
- D3: 7 个词
计算部分词的 TF(只展示关键词)
| 词 | D1 | D2 | D3 |
|---|---|---|---|
| the | 2/6 = 0.333 | 2/6 = 0.333 | 2/7 = 0.286 |
| cat | 1/6 = 0.167 | 0 | 1/7 = 0.143 |
| dog | 0 | 1/6 = 0.167 | 1/7 = 0.143 |
| mat | 1/6 = 0.167 | 0 | 0 |
| road | 0 | 1/6 = 0.167 | 0 |
其他词类似计算(如 sat, ran 等)
第三步:计算 IDF(逆文档频率)
公式:
IDF(t,D)=log(N1+包含词 t的文档数)\text{IDF}(t, D) = \log \left( \frac{N}{1 + \text{包含词 } t \text{ 的文档数}} \right) IDF(t,D)=log(1+包含词 t 的文档数N)
- N=3(总文档数)
- 加 1 是为了防止分母为 0(拉普拉斯平滑)
我们计算每个词的 IDF:
| 词 | 包含该词的文档数 | IDF 计算 | IDF 值(保留3位) |
|---|---|---|---|
| the | 3 | log(3/(1+3))=log(0.75)log(3/(1+3))=log(0.75) | -0.288 |
| cat | 2 | log(3/(1+2))=log(1.0)log(3/(1+2))=log(1.0) | 0.000 |
| dog | 2 | log(3/3)=log(1.0)log(3/3)=log(1.0) | 0.000 |
| sat | 1 | log(3/2)=log(1.5)log(3/2)=log(1.5) | 0.405 |
| mat | 1 | log(3/2)=log(1.5)log(3/2)=log(1.5) | 0.405 |
| ran | 1 | log(3/2)log(3/2) | 0.405 |
| road | 1 | log(3/2)log(3/2) | 0.405 |
| and | 1 | log(3/2)log(3/2) | 0.405 |
| are | 1 | log(3/2)log(3/2) | 0.405 |
| friends | 1 | log(3/2)log(3/2) | 0.405 |
| on | 2 | log(3/3)=log(1.0)log(3/3)=log(1.0) | 0.000 |
注意:
the出现在所有文档中,IDF 为负,说明它不具区分性,反而可能应被降权。简单说:
- 一个词出现的文档越多 → 越常见 → 越不重要 → IDF 值越低
- 一个词出现的文档越少 → 越稀有 → 越可能具有区分性 → IDF 值越高
第四步:计算 TF-IDF
公式:
TF-IDF(t,d)=TF(t,d)×IDF(t)
我们以 D1 为例,计算其中几个词的 TF-IDF:
文档 D1: the cat sat on the mat
| 词 | TF (D1) | IDF | TF-IDF (D1) |
|---|---|---|---|
| the | 0.333 | -0.288 | 0.333 × (-0.288) ≈ -0.096 |
| cat | 0.167 | 0.000 | 0.167 × 0.000 = 0.000 |
| sat | 0.167 | 0.405 | 0.167 × 0.405 ≈ 0.068 |
| on | 0.167 | 0.000 | 0.167 × 0.000 = 0.000 |
| mat | 0.167 | 0.405 | 0.167 × 0.405 ≈ 0.068 |
解读:
the虽然出现频繁,但 IDF 为负,整体贡献为负,说明它不重要。cat出现一次,但出现在 2 篇文档中,IDF=0,重要性被中和。sat和mat只在 D1 中出现,IDF > 0,因此 TF-IDF 值较高,说明它们是 D1 的“关键词”。
结论:
- 文档频率和样本语义贡献程度呈反相关
- 文档频率和逆文档频率呈反相关
- 逆文档频率和样本语义贡献度呈正相关
3. N-Grams 特征
N-Grams 是指文本中连续出现的 N 个词(或字符)的组合,是自然语言处理(NLP)中一种重要的特征表示方法。
简单理解:将句子切分为长度为 N 的“滑动窗口”片段。
【示例】
句子:“我爱机器学习”
根据 N 的取值不同,N-Grams 可分为:
| 类型 | 名称 | 示例(句子:“我爱机器学习”) |
|---|---|---|
| 1-Gram | Unigram(一元语法) | 我,爱,机器,学习 |
| 2-Gram | Bigram(二元语法) | 我爱,爱机器,机器学习 |
| 3-Gram | Trigram(三元语法) | 我爱机器,爱机器学习 |
| 4-Gram | Four-gram | (更长的组合,依此类推) |
通常 N 不会太大(一般 ≤ 5),否则特征数量爆炸。
N-Grams 的作用:
- 捕捉局部词序信息
- 传统词袋模型(Bag of Words)完全忽略词序。
- N-Grams 保留了词语的相邻关系,能区分:“猫怕狗” vs “狗怕猫”
- 提升模型对语言结构的理解
- Bigram 可以学习“通常哪些词会连在一起”
- 例如:“深度学习”比“学习深度”更常见
- 用于语言模型(Language Model)
- 预测下一个词的概率
- 广泛应用于拼写纠错、语音识别、机器翻译等。
通常情况下,可以将n-grams 与 TF-IDF 相结合,在保留词语搭配和词序信息的同时,通过 TF-IDF 权重突出关键短语、抑制常见无意义组合。结合的过程基本上是先生成 n-grams,然后对这些 n-grams 计算 TF-IDF 权重。
- n-grams:提供结构信息(词序、搭配)
- TF-IDF:提供重要性权重(突出关键词,抑制常见组合)
【示例】
文档1(正面):这部电影真的很棒
文档2(负面):这部电影并不棒
仅用 unigram + TF-IDF 的问题:
- 两篇都包含:“这”、“部”、“电影”、“很”、“棒”
- “并不” vs “真的” 差异被忽略 → 模型难区分情感
加入 bigram 后:
| 文档 | Bigrams |
|---|---|
| 正面 | 这部, 部电, 电影, 影真, 真的, 的很, 很棒 |
| 负面 | 这部, 部电, 电影, 影并, 并不, 不棒 |
→ “真的很棒” vs “并不棒” 被区分开!
再用 TF-IDF 加权后,“很棒”可能在语料中少见 → IDF 高 → 权重高,“的”等常见组合权重低。
传统特征工程手工成本高、语义表达弱、泛化能力差,难以应对复杂的语言理解任务。
因此现代 NLP 转向 词向量 和 深度学习(如 BERT)
二、词向量
词向量(Word Embedding)是将自然语言中的词语映射为一个低维、稠密的实数向量的技术。
它使得语义相近的词在向量空间中距离也相近。
在自然语言处理(NLP)中,计算机无法直接理解文字。为了让机器能处理“猫”、“喜欢”、“跑步”这样的词,我们需要把它们转换成数字形式。这就是词向量)的作用。
简单说:
词向量就是把一个词变成一串数字(向量),让计算机能进行数学计算,同时保留词语的语义信息。
单个词在预定义的向量空间中被表示为实数向量,每个单词都映射到一个向量。举个例子,比如在一个文本中包含“猫”“狗”“爱情”等若干单词,而这若干单词映射到向量空间中,“猫”对应的向量为(0.1 0.2 0.3),“狗”对应的向量为(0.2 0.2 0.4),“爱情”对应的映射为(-0.4 -0.5 -0.2)(本数据仅为示意)。像这种将文本X{x1,x2,x3,x4,x5……xn}映射到多维向量空间Y{y1,y2,y3,y4,y5……yn },这个映射的过程就叫做词嵌入。
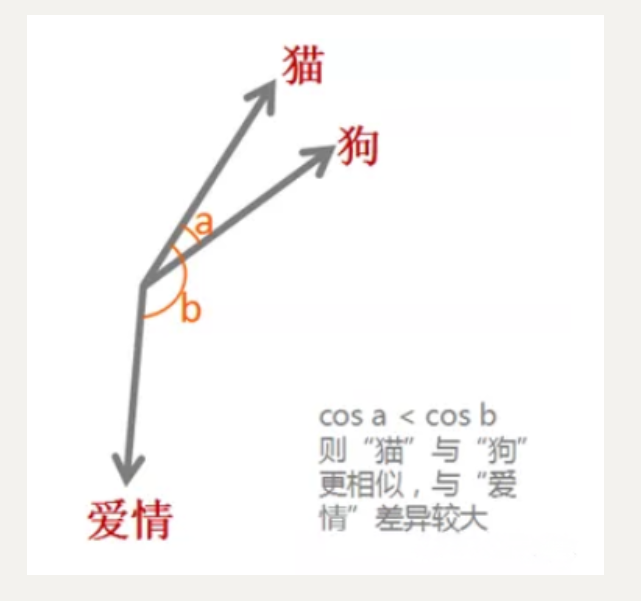
我们计算“猫”和“狗”的余弦相似度,发现它们很接近;而“猫”和“爱情”距离较远。
此外,词嵌入还可以做类比,比如:
vec("国王") - vec("男人") + vec("女人") ≈ vec("女王")
这说明词向量不仅能表示词义,还能捕捉语法和语义关系!
再比如:
- “北京” - “中国” + “法国” ≈ “巴黎”
- “跑步” - “走” + “飞” ≈ “飞行”
三、深度学习中的 NLP 特征输入
1. 词嵌入与分布式表示
1.1 传统编码的局限性
- 独热编码(One-Hot)
每个词表示为高维稀疏向量(如10000维词表中,每个词仅一个维度为1,其余为0)。
缺陷:- 维度灾难:10000词表需10000维向量,计算成本高。
- 无法捕捉语义关系(如"king"和"queen"的距离与其他词无区别)。
- N-gram与TF-IDF
通过统计局部共现词或词频构建特征,但无法解决语义相似性和动态上下文感知问题。
1.2 分布式表示
- 核心思想:
将离散词映射到低维连续向量空间(如300维),通过上下文学习词的语义关系。
优势:- 低维度(如300维 vs 10000维独热编码)。
- 语义相似性(如"king - man + woman ≈ queen")。
- 可微学习(通过反向传播优化向量表示)。
- 典型应用:
- Word2Vec(CBOW/Skip-gram)捕捉类比关系。
- GloVe 利用全局共现矩阵生成词向量。
2. 稠密编码(特征嵌入)
将离散特征(词、标签、位置等)映射到低维稠密向量,通过神经网络参数化学习。
特点:
- 低维度:将高维稀疏表示(如 10,000 维)压缩到低维(如 100 维)。
- 语义相似性:向量距离反映对象间的语义关系(如 “king” 和 “queen” 的距离较近)。
- 可微学习:通过神经网络参数化学习,支持反向传播优化。

3. 词嵌入算法
计算机无法直接处理文字,比如:
句子:"我 爱 学习"
如果我们用 One-Hot 编码:
- “我” →
[1, 0, 0] - “爱” →
[0, 1, 0] - “学习” →
[0, 0, 1]
问题来了:
- 向量维度等于词表大小,高维稀疏
- 所有词之间“距离相等”,没有语义信息
- “我” 和 “学习” 完全无关,但模型不知道它们常一起出现
所以我们需要更聪明的方式 —— Embedding Layer。
3.1 EmbeddingLayer
Embedding Layer 是一个可训练的神经网络层,它将词的索引(ID) 映射为一个固定维度的稠密向量。
本质是一个可训练的矩阵 E∈RV×d,其中 V 是词表大小,d是嵌入维度。
怎么得到词向量?
比如我们的目标是希望神经网络发现如下这样的规律:已知一句话的前几个字,预测下一个字是什么,于是有了NNLM 语言模型搭建的网络结构图:

具体怎么实施呢?先用最简单的方法来表示每个词,one-hot 表示为︰
dog=(0,0,0,0,1,0,0,0,0,…);
cat=(0,0,0,0,0,0,0,1,0,…) ;
eat=(0,1,0,0,0,0,0,0,0,…)

可是 one-hot 表示法有诸多的缺陷,还是稠密的向量表示更好一些,那么怎么转换呢?加一个矩阵映射一下就好!

映射之后的向量层如果单独拿出来看,还有办法找到原本的词是什么吗?
One-hot表示法这时候就作为一个索引字典了,可以通过映射矩阵对应到具体的词向量。

这个层内部维护一个矩阵:E∈RV×d
一、词表(V)
-
词表就是你模型认识的所有词的集合。
-
比如你的语料中只出现过这些词:
["我", "爱", "学习", "AI", "今天", "天气", "好"]那么词表大小 V = 7 。
-
每个词会被分配一个唯一的编号(索引):
我 → 0 爱 → 1 学习 → 2 AI → 3 今天 → 4 天气 → 5 好 → 6
二、嵌入维度(d)
-
嵌入维度 d 是指每个词要用多少个数字(即向量的长度)来表示。
-
比如 d = 4 ,那么每个词会被表示成一个 4 维的向量,像这样:
"我" → [0.2, -0.5, 0.8, 0.1] "爱" → [0.6, 0.3, 0.4, -0.2] ...
三、嵌入矩阵 E
- 为了高效存储和计算,我们把所有词的向量堆在一起,形成一个大矩阵,叫做 嵌入矩阵 E。它的形状是 V×d:
- 有 V 行(每行对应一个词)
- 有 d 列(每列对应向量的一个维度)
【示例】
V = 3 (词表:[“猫”, “狗”, “牛奶”])
d = 4 (每个词用 4 个数字表示)
嵌入矩阵 E 长这样:
E=[0.1−0.30.80.5←“猫”的向量0.20.40.70.6←“狗”的向量−0.10.90.20.3←“牛奶”的向量]∈R3×4E = \begin{bmatrix} 0.1 & -0.3 & 0.8 & 0.5 \\ \leftarrow \text{“猫”的向量} \\ 0.2 & 0.4 & 0.7 & 0.6 \\ \leftarrow \text{“狗”的向量} \\ -0.1 & 0.9 & 0.2 & 0.3 \\ \leftarrow \text{“牛奶”的向量} \end{bmatrix} \in \mathbb{R}^{3 \times 4} E=0.1←“猫”的向量0.2←“狗”的向量−0.1←“牛奶”的向量−0.30.40.90.80.70.20.50.60.3∈R3×4
所以:
- 第 0 行:是 “猫” 的词向量
- 第 1 行:是 “狗” 的词向量
- 第 2 行:是 “牛奶” 的词向量
当你输入一个词,比如 “狗”,它的编号是 1,模型就会去嵌入矩阵 E 中查找第 1 行,取出对应的向量 [0.2, 0.4, 0.7, 0.6],作为这个词的表示。
这个过程叫做 查表(lookup),也叫 嵌入查找(embedding lookup)。
# 伪代码
E = [[0.1, -0.3, 0.8, 0.5], # 猫[0.2, 0.4, 0.7, 0.6], # 狗[-0.1, 0.9, 0.2, 0.3]] # 牛奶word_id = 1 # “狗”
word_vector = E[word_id] # 取出第二行 → [0.2, 0.4, 0.7, 0.6]
实现步骤
在 PyTorch 中,我们可以使用 nn.Embedding 词嵌入层来实现输入词的向量化。接下来,我们将会学习如何将词转换为词向量,其步骤如下:
- 先将语料进行分词,构建词与索引的映射,我们可以把这个映射叫做词表,词表中每个词都对应了一个唯一的索引;
- 然后使用 nn.Embedding 构建词嵌入矩阵,词索引对应的向量即为该词对应的数值化后的向量表示。
【示例】文本数据为: “北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。”
- 首先,将文本进行分词;
- 然后,根据词构建词表;
- 最后,使用嵌入层将文本转换为向量表示。
步骤 1:首先使用 jieba 对文本进行分词操作,将连续的文本切分为词语列表。
import jiebatext = '北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
words = jieba.lcut(text) # 使用精确模式分词
print("分词结果:", words)
输出示例:
分词结果: ['北京', '冬奥', '的', '进度', '条', '已经', '过半', ',', '不少', '外国', '运动员', '在', '完成', '自己', '的', '比赛', '后', '踏上', '归途', '。']
步骤 2: 将分词后的词语去重,并为每个词分配唯一的索引(ID),构建词表(vocabulary)。
# 去重并保留顺序
unique_words = list(set(words))
word_to_index = {word: idx for idx, word in enumerate(unique_words)}
index_to_word = {idx: word for idx, word in enumerate(unique_words)}print("词表大小:", len(unique_words))
print("词到索引的映射示例:", {k: v for k, v in list(word_to_index.items())[:5]})
输出示例:
词表大小: 20
词到索引的映射示例: {'北京': 0, '冬奥': 1, '的': 2, '进度': 3, '条': 4...}
步骤 3:使用 nn.Embedding 构建词嵌入矩阵。
需要指定两个关键参数:
num_embeddings: 词表大小(即len(unique_words))embedding_dim: 每个词的向量维度(例如 128)
import torch
import torch.nn as nn# 设置嵌入维度
embedding_dim = 128# 初始化嵌入层
embedding_layer = nn.Embedding(num_embeddings=len(unique_words), embedding_dim=embedding_dim)
步骤 4: 将文本转换为索引序列
将分词后的词语转换为对应的索引,并封装为 PyTorch 张量作为输入。
# 将分词后的词语转换为索引序列
input_indices = [word_to_index[word] for word in words]
input_tensor = torch.tensor(input_indices)print("输入索引序列:", input_indices)
print("输入张量形状:", input_tensor.shape)
输出示例:
输入索引序列: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 2, 14, 15, 16, 17, 18]
输入张量形状: torch.Size([20])
步骤 5: 获取词向量
将索引序列输入嵌入层,得到对应的词向量表示。
# 获取词向量
embedded_vectors = embedding_layer(input_tensor)print("词向量形状:", embedded_vectors.shape)
print("第一个词的向量示例:", embedded_vectors[0].detach().numpy()[:5]) # 显示前5个维度
输出示例:
词向量形状: torch.Size([20, 128])
第一个词的向量示例: [ 0.012 -0.034 0.045 -0.067 0.023]
完整代码整合
import jieba
import torch
import torch.nn as nn# 1. 分词
text = '北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
words = jieba.lcut(text)# 2. 构建词表
unique_words = list(set(words))
word_to_index = {word: idx for idx, word in enumerate(unique_words)}
index_to_word = {idx: word for idx, word in enumerate(unique_words)}# 3. 初始化嵌入层
embedding_dim = 128
embedding_layer = nn.Embedding(num_embeddings=len(unique_words), embedding_dim=embedding_dim)# 4. 转换为索引序列
input_indices = [word_to_index[word] for word in words]
input_tensor = torch.tensor(input_indices)# 5. 获取词向量
embedded_vectors = embedding_layer(input_tensor)# 6. 输出结果
print("分词结果:", words)
print("词表大小:", len(unique_words))
print("词向量形状:", embedded_vectors.shape)
print("第一个词的向量示例:", embedded_vectors[0].detach().numpy()[:5])
3.2 word2vec
Word2Vec 是一种高效学习词向量(Word Embedding)的神经网络模型,由 Google 的 Tomas Mikolov 团队于 2013 年提出。它通过捕捉词语的上下文关系,将词语映射到低维连续向量空间中,使得语义相似的词在向量空间中距离更近。Word2Vec 的提出标志着自然语言处理(NLP)从传统基于规则和统计的方法转向基于深度学习的分布式表示方法。
Word2Vec 的核心思想:
1. 分布式表示
- 传统方法:将词语表示为独热编码(One-Hot),例如词汇表大小为 V 时,每个词的向量维度为 V × 1,且只有一个位置为 1,其余为 0。这种表示方式稀疏且无法捕捉语义关系。
- Word2Vec:通过神经网络将词语映射到低维稠密向量(例如 100 维、300 维),这些向量能够捕捉语义和句法关系。例如:
- 语义相似性:
king - man + woman ≈ queen - 句法关系:
Paris - France + Italy ≈ Rome
- 语义相似性:
2. Word2Vec 的两种模型架构
左边CBOW,右边skip-gram

CBOW 连续词袋模型
目标:根据上下文词预测中心词。
-
输入:多个上下文词的 One-Hot 向量(平均后作为隐藏层输入)。
-
输出:中心词的概率分布。
P(wt∣wt−1,wt−2,…,wt+n)P(w_t \mid w_{t-1}, w_{t-2}, \dots, w_{t+n}) P(wt∣wt−1,wt−2,…,wt+n)
模型结构:
- 输入层:上下文词的 One-Hot 向量(维度 C×V,其中 C 是窗口大小)。
- 投影层:
- 通过嵌入矩阵 W*(维度 V×N*),将每个上下文词的 One-Hot 向量转换为嵌入向量(维度 N×1)。
- 对所有上下文词的嵌入向量求平均,得到隐藏层向量 h(维度 N×1)。
- 输出层:
- 通过嵌入矩阵 W′(维度 N×V),将隐藏层向量 hh 转换为输出层的得分(维度 1×V)。
- 使用 Softmax 将得分转换为概率分布


import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim# 设置张量数据类型为 32 位浮点数
dtype = torch.FloatTensor# 1. 准备语料库
sentences = ["i like dog","i like cat","i like animal","dog cat animal","apple cat dog like","cat like fish","dog like meat","i like apple","i hate apple","i like movie book music apple","dog like bark","dog friend cat"
]# 2. 构建词汇表及词典
# 将所有句子合并为一个词列表,并去重
word_list = list(set(" ".join(sentences).split()))
print("词汇表:", word_list)# 构建词 → ID 和 ID → 词 的双向映射
word2id = {word: i for i, word in enumerate(word_list)}
id2word = {i: word for i, word in enumerate(word_list)}
print("词 → ID 映射:", word2id)# 3. 构建 CBOW 训练数据
# 目标:根据上下文词预测中心词
cbow_data = []
for sentence in sentences:words = sentence.split()for i in range(1, len(words) - 1): # 跳过首尾词,只处理中间词context = [word2id[words[i - 1]], word2id[words[i + 1]]] # 上下文词(前后各1个)target = word2id[words[i]] # 中心词cbow_data.append([context, target])print("示例训练数据 (上下文词索引, 中心词索引):")
print(cbow_data[:5]) # 打印前5个样本# 4. 随机批次生成函数
def random_batch(data, batch_size=3):"""从训练数据中随机抽取 batch_size 个样本参数:data: 训练数据,格式为 [[上下文词索引], 中心词索引]batch_size: 批次大小返回:input_batch: 上下文词索引组成的张量 [batch_size, 2]label_batch: 中心词索引组成的张量 [batch_size]"""random_inputs = []random_labels = []# 随机选择 batch_size 个样本的索引random_index = np.random.choice(range(len(data)), batch_size, replace=False)for i in random_index:random_inputs.append(data[i][0]) # 上下文词random_labels.append(data[i][1]) # 中心词return torch.LongTensor(random_inputs), torch.LongTensor(random_labels)# 5. 模型参数
vocab_size = len(word_list) # 词汇表大小
embedding_size = 2 # 词向量维度(可调,此处设为2便于可视化)# 6. 定义 CBOW 模型
class CBOW(nn.Module):def __init__(self):super(CBOW, self).__init__()# 嵌入层:将词索引转换为低维稠密向量self.embed = nn.Embedding(vocab_size, embedding_size)# 输出层:将上下文词向量的平均值映射到词汇表大小self.output = nn.Linear(embedding_size, vocab_size)def forward(self, input_batch):"""前向传播逻辑参数:input_batch: [batch_size, 2],每个样本包含两个上下文词的索引返回:output: [batch_size, vocab_size],每个词的概率分布"""# 1. 嵌入层:将上下文词索引转换为嵌入向量 [batch_size, 2, embedding_size]x = self.embed(input_batch)# 2. 取上下文词向量的平均值 [batch_size, embedding_size]x = torch.mean(x, dim=1)# 3. 输出层:线性变换到词汇表大小 [batch_size, vocab_size]x = self.output(x)return x# 7. 实例化模型、损失函数和优化器
model = CBOW()
criterion = nn.CrossEntropyLoss() # 分类损失
optimizer = optim.Adam(model.parameters(), lr=0.001) # 优化器# 8. 训练循环
for epoch in range(5000):# 1. 生成随机批次数据input_batch, label_batch = random_batch(cbow_data)# 2. 前向传播output = model(input_batch) # [batch_size, vocab_size]# 3. 计算损失loss = criterion(output, label_batch)# 4. 反向传播optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 5. 打印训练进度if (epoch + 1) % 1000 == 0:print(f"Epoch: {epoch + 1}/5000, Loss: {loss.item():.4f}")# 9. 查看训练后的词向量
with torch.no_grad():weights = model.embed.weight.data.numpy() # 获取嵌入层权重for i, word in enumerate(word_list):print(f"{word} 的词向量: {weights[i]}")
Skip-gram
给定一个中心词,预测其上下文词(即周围的词)
- 输入:一个中心词的 One-Hot 向量。
- 输出:上下文词的概率分布(通过 Softmax 计算)
模型结构:
- 输入层:中心词的 One-Hot 向量(维度为V×1)。
- 投影层:
- 通过嵌入矩阵 WW(维度 V×N,其中 N 是嵌入维度),将 One-Hot 向量转换为嵌入向量(维度 N×1)。
- 公式:h=WTx,其中x 是输入的 One-Hot 向量。
- 输出层:
- 通过另一个嵌入矩阵 W′(维度 N×V),将嵌入向量转换为输出层的得分(维度 1×V)。
- 公式:u=h⋅W′。
- 使用 Softmax 将得分转换为概率分布

import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import math# 定义数据类型为浮点数
dtype = torch.FloatTensor# 语料库,包含训练模型的句子
sentences = ["i like dog", "i like cat", "i like animal","dog cat animal", "apple cat dog like", "cat like fish","dog like meat", "i like apple", "i hate apple","i like movie book music apple", "dog like bark", "dog friend cat"
]# 将所有句子拼接为一个字符串并按空格分词
word_sequence = ' '.join(sentences).split()
# 获取词汇表中的所有唯一词
word_list = list(set(word_sequence))
print("词汇表(word_list):", word_list)# 创建词典,词汇表中的每个词都分配一个唯一的索引
word2id = {w: i for i, w in enumerate(word_list)}
id2word = {i: w for w, i in word2id.items()} # 用于根据索引还原词
print("词典(word2id):", word2id)# 词汇表大小
voc_size = len(word_list)
# 定义嵌入维度(嵌入向量的大小)为2
embedding_size = 2
# 每次训练的批量大小
batch_size = 5# 创建 Skip-gram 模型的训练数据
skip_grams = [] # 训练数据:[中心词ID, 上下文词ID]
for i in range(len(word_sequence)):# 当前词作为中心词target = word2id[word_sequence[i]]# 获取上下文词(窗口大小为1)left_context = word2id[word_sequence[i - 1]] if i > 0 else Noneright_context = word2id[word_sequence[i + 1]] if i < len(word_sequence) - 1 else None# 将目标词与上下文词配对if left_context:skip_grams.append([target, left_context]) # [中心词ID, 左侧词ID]if right_context:skip_grams.append([target, right_context]) # [中心词ID, 右侧词ID]# 打印生成的 Skip-gram 数据示例
print("生成的 Skip-gram 数据示例(前5条):")
for i in range(5):center_word = id2word[skip_grams[i][0]]context_word = id2word[skip_grams[i][1]]print(f"[中心词: {center_word}, 上下文词: {context_word}]")# 定义随机批量生成函数
def random_batch(data, size):"""从 skip_grams 数据中随机选择 size 个样本,生成 one-hot 编码的输入和标签"""random_inputs = [] # 输入批次(one-hot 编码)random_labels = [] # 标签批次(上下文词ID)# 从数据中随机选择 size 个索引random_index = np.random.choice(range(len(data)), size, replace=False)# 根据随机索引生成输入和标签批次for i in random_index:# 目标词 one-hot 编码# np.eye(voc_size) 创建 voc_size x voc_size 的单位矩阵random_inputs.append(np.eye(voc_size)[data[i][0]])# 上下文词的索引作为标签random_labels.append(data[i][1])return random_inputs, random_labels# 定义 Word2Vec 模型
class Word2Vec(nn.Module):def __init__(self):super(Word2Vec, self).__init__()# 定义词嵌入矩阵 W,大小为 (voc_size, embedding_size)self.W = nn.Parameter(torch.rand(voc_size, embedding_size)).type(dtype)# 定义上下文矩阵 WT,大小为 (embedding_size, voc_size)self.WT = nn.Parameter(torch.rand(embedding_size, voc_size)).type(dtype)# 前向传播def forward(self, x):# 通过嵌入矩阵 W 得到词向量weight_layer = torch.matmul(x, self.W) # [batch_size, embedding_size]# 通过上下文矩阵 WT 得到输出output_layer = torch.matmul(weight_layer, self.WT) # [batch_size, voc_size]return output_layer# 创建模型实例
model = Word2Vec()# 定义损失函数为交叉熵损失
criterion = nn.CrossEntropyLoss()
# 使用 Adam 优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(10000):# 获取随机的输入和目标inputs, labels = random_batch(skip_grams, batch_size)# 转为张量input_batch = torch.Tensor(inputs)label_batch = torch.LongTensor(labels)optimizer.zero_grad() # 梯度清零output = model(input_batch) # 前向传播# 计算损失函数loss = criterion(output, label_batch)# 每 1000 轮打印一次损失if (epoch + 1) % 1000 == 0:print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))loss.backward() # 反向传播optimizer.step() # 参数更新# 训练完成后,打印学习到的词向量
print("\n学习到的词向量(嵌入矩阵 W):")
for i in range(voc_size):print(f"{id2word[i]}: {model.W.data[i].numpy()}")# 计算词向量之间的余弦相似度
def cosine_similarity(vec1, vec2):return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))print("\n词向量的余弦相似度示例:")
print(f"i 和 like 的相似度: {cosine_similarity(model.W.data[word2id['i']].numpy(), model.W.data[word2id['like']].numpy())}")
print(f"like 和 dog 的相似度: {cosine_similarity(model.W.data[word2id['like']].numpy(), model.W.data[word2id['dog']].numpy())}")
print(f"dog 和 cat 的相似度: {cosine_similarity(model.W.data[word2id['dog']].numpy(), model.W.data[word2id['cat']].numpy())}")
Gensim 中 Word2Vec 使用
1. 安装 Gensim
pip install gensim
2. 常用参数
| 参数名 | 默认值 | 说明 |
|---|---|---|
sentences | 无(必需) | 输入语料,应为分词后的句子列表,如 [["word1"], ["word2"]]。大语料建议使用 LineSentence 流式读取。 |
vector_size | 100 | 词向量的维度,常用 100、200、300。维度越高表达能力越强,但需要更多数据和计算资源。 |
window | 5 | 上下文窗口大小,即目标词前后最多考虑的词数。一般设置为 3~10。 |
min_count | 5 | 忽略出现次数少于该值的词语。用于过滤低频词,小语料可设为 1 或 2。 |
sg | 0 | 训练算法:0 表示使用 CBOW,1 表示使用 Skip-gram。Skip-gram 更适合小语料和低频词。 |
workers | 3 | 训练时使用的 CPU 线程数,建议根据 CPU 核心数设置以提升训练速度。 |
alpha | 0.025 | 初始学习率,训练过程中会线性衰减。一般无需调整。 |
sample | 1e-3 | 高频词的下采样阈值,用于减少常见词(如“的”、“是”)的训练样本,提升效果和速度。 |
hs | 0 | 是否使用层次 Softmax:1 表示使用,0 表示不使用。通常与负采样互斥。 |
negative | 5 | 负采样数量,0 表示不使用负采样。推荐值为 5~20,适合大规模语料。 |
seed | 1 | 随机数种子,设置后可保证训练结果可重现。 |
model.wv 的常用且重的方法
-
model.wv.most_similar(positive, negative, topn)
查找与给定词语最相似的词,支持类比推理。model.wv.most_similar('apple') # 找与 apple 相似的词 model.wv.most_similar(positive=['king', 'woman'], negative=['man']) # king - man + woman ≈ queen -
model.wv.similarity(word1, word2)
计算两个词之间的语义相似度(余弦相似度),返回值在 -1 到 1 之间。model.wv.similarity('man', 'woman') # 返回如 0.78 -
model.wv.doesnt_match(list_of_words)
找出列表中语义上“最不合群”的词。model.wv.doesnt_match(['cat', 'dog', 'mouse', 'table']) # 返回 'table' -
model.wv[word]或model.wv.get_vector(word)
获取某个词的词向量(numpy 数组)。vec = model.wv['hello'] # 获取 'hello' 的向量 -
model.wv.key_to_index
获取词到索引的映射字典,可用于查看词在词汇表中的位置。index = model.wv.key_to_index['python'] -
model.wv.index_to_key
获取索引到词的映射列表,与key_to_index对应。word = model.wv.index_to_key[100] # 获取索引为 100 的词 -
model.wv.save()和model.wv.load()
保存或加载训练好的词向量,便于后续使用或共享。model.wv.save("vectors.kv") from gensim.models import KeyedVectors wv = KeyedVectors.load("vectors.kv")
| 概念 | 定义 | 示例 |
|---|---|---|
| 词向量(Word Vector) | 将一个词语表示为一个低维稠密向量,捕捉其语义信息 | “猫” → [0.8, -0.3, 0.5] |
| 句向量(Sentence Vector) | 将一个完整句子表示为一个向量,反映整个句子的语义 | “我爱学习” → [0.6, 0.1, -0.4, ...] |
【示例】
sentence = "Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers."需要把这句话通过api的方法,转成句向量
from gensim.models import Word2Vec
import numpy as np
import resentence = "Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers."# 1.文本处理
def preprocess(text):text = re.sub(r'[^a-zA-Z0-9\s]', '', text)text = text.lower()text = text.split()return textwords = preprocess(sentence)
print('分词后:', words)# 2.训练模型
model = Word2Vec(sentences=[words],vector_size=100,window=5,min_count=1, # 所有词都保留workers=1
)
# 3.获得句向量
def sentence2vec(sentence,model,vector_size=100):words = preprocess(sentence)word_vectors = []for word in words:if word in model.wv:# 确保词在词汇表中word_vectors.append(model.wv[word])if len(word_vectors) == 0:return np.zeros(vector_size)sentence_vector = np.mean(word_vectors, axis=0)return sentence_vectorvec = sentence2vec(sentence, model,vector_size=100)
print('句向量形状:', vec.shape)
print('句向量:', vec)
)





系统架构:如何构建一个能查资料的大语言模型系统)




)




)


