目录
理解负载均衡
负载均衡的实现方式
服务端负载均衡
客户端负载均衡
Spring Cloud LoadBalancer快速上手
常见的负载均衡策略
自定义负载均衡策略
LoadBalancer 原理
理解负载均衡
在 Spring Cloud 微服务架构中,负载均衡(Load Balance)是实现服务高可用、提高系统吞吐量的核心机制之一。它通过将请求合理分发到多个服务实例,避免单个实例过载,同时实现故障自动隔离,是服务调用链路中的关键环节。
在微服务中,一个服务通常会部署多个实例(如产品信息服务可能有product-service:9090、product-service:9091、product-service:9092等)。负载均衡的核心目标是:
请求分发:将服务消费者的请求均匀分配到多个服务提供者实例,避免单点压力过大。
故障隔离:自动排除不可用的实例(如宕机、健康检查失败),确保请求只发送到可用实例。
弹性伸缩支持:当服务实例扩缩容时,能自动感知并调整分发策略,无需人工干预。
负载均衡的实现方式
负载均衡分为服务端负载均衡和客户端负载均衡
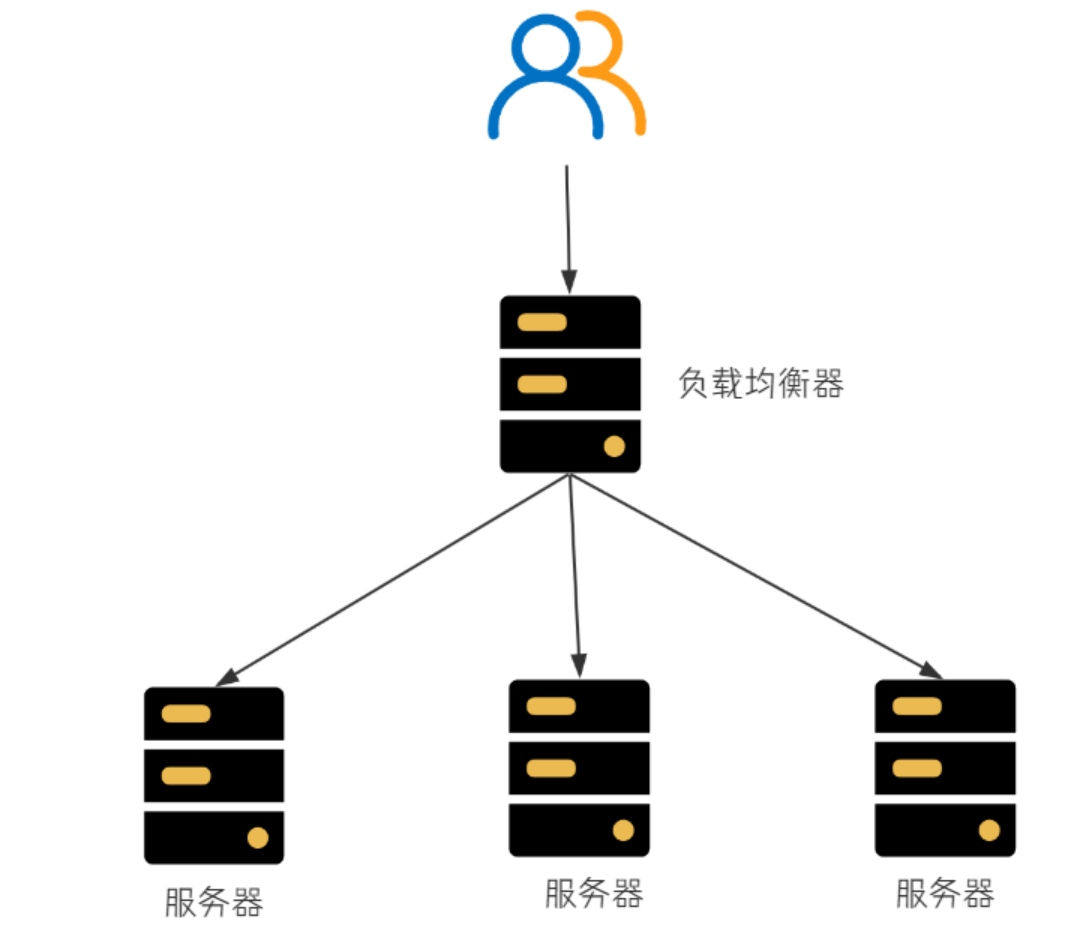
服务端负载均衡
比较有名的服务端负载均衡器是Nginx,请求先到达Nginx负载均衡器,然后通过负载均衡算法,在多个服务器之间选择⼀个进行访问。
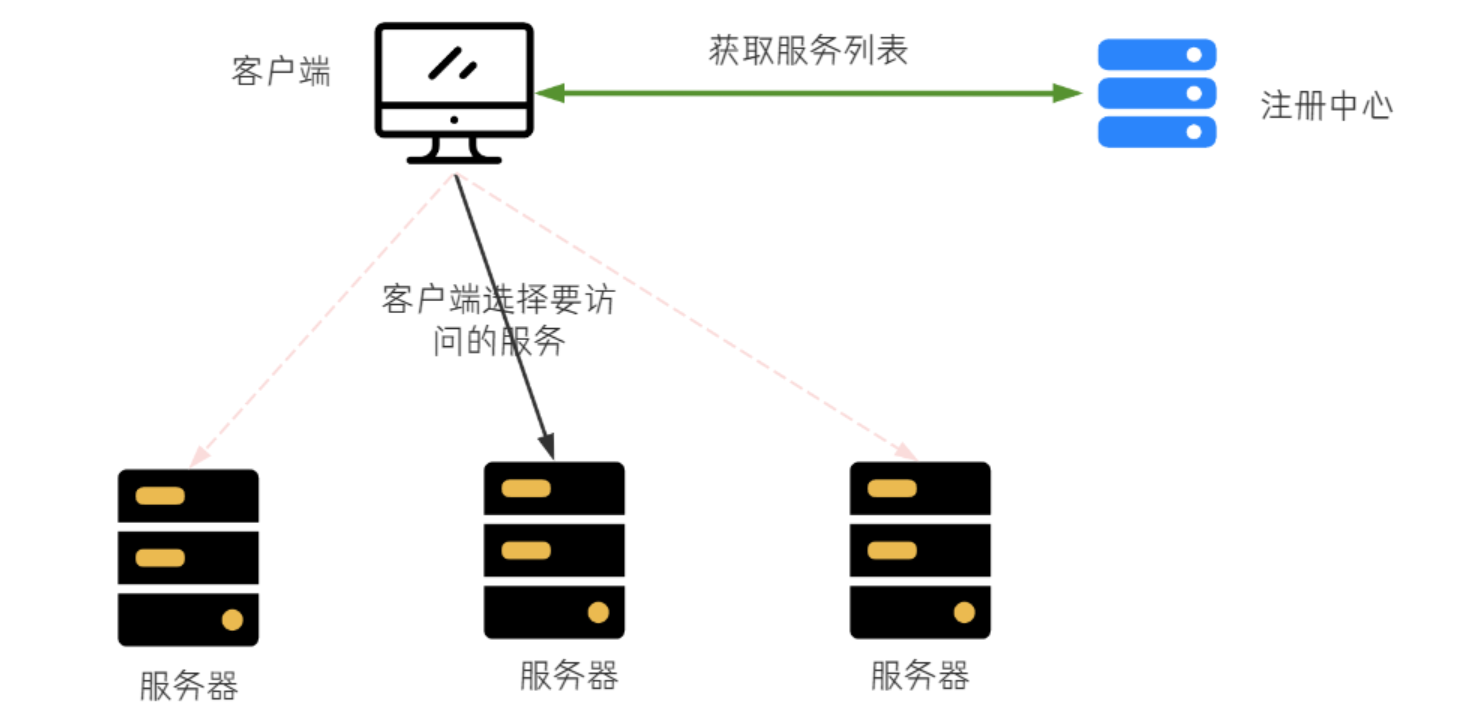
客户端负载均衡
把负载均衡的功能以库的方式集成到客户端,而不再是由⼀台指定的负载均衡设备集中提供。
比如Spring Cloud的Ribbon,请求发送到客户端,客户端从注册中心(比如Eureka)获取服务列表,在发送请求前通过负载均衡算法选择⼀个服务器,然后进行访问。
Ribbon是Spring Cloud早期的默认实现,由于不维护了,所以最新版本的Spring Cloud负载均衡集成的是Spring Cloud LoadBalancer(Spring Cloud官方维护)
Spring Cloud LoadBalancer快速上手
Spring Cloud LoadBalancer 并不是一个独立服务,而是一个 客户端负载均衡库。
调用流程大致是:
获取服务名(例如调用
http://inventory-service/api/stock/1,这里的inventory-service就是服务名)。去服务注册中心查找(Nacos、Eureka、Consul…)获取该服务的所有实例地址(IP:Port)。
负载均衡策略选择:比如轮询、随机、权重优先、本地优先。
发起请求到选定的实例
使用方式
给 RestTemplate 加上 @LoadBalanced 注解:
@Configuration
public class RestTemplateConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}
}使用时直接写服务名:
@Autowired
private RestTemplate restTemplate;
public OrderDO selectOrderById(Integer id) {OrderDO orderDO = orderMapper.selectOrderById(id);//这里的 product-service 不再是域名,而是注册中心里的 服务名。String url = "http://product-service/product/"+orderDO.getProductId();//远程调用获取数据ProductDO productDO = restTemplate.getForObject(url, ProductDO.class);orderDO.setProductDO(productDO);return orderDO;
}启动服务进行测试
前置环境配置可参考Spring Cloud——服务注册与服务发现原理与实现-CSDN博客

测试负载均衡
连续多次发起请求: http://127.0.0.1:8080/order/1
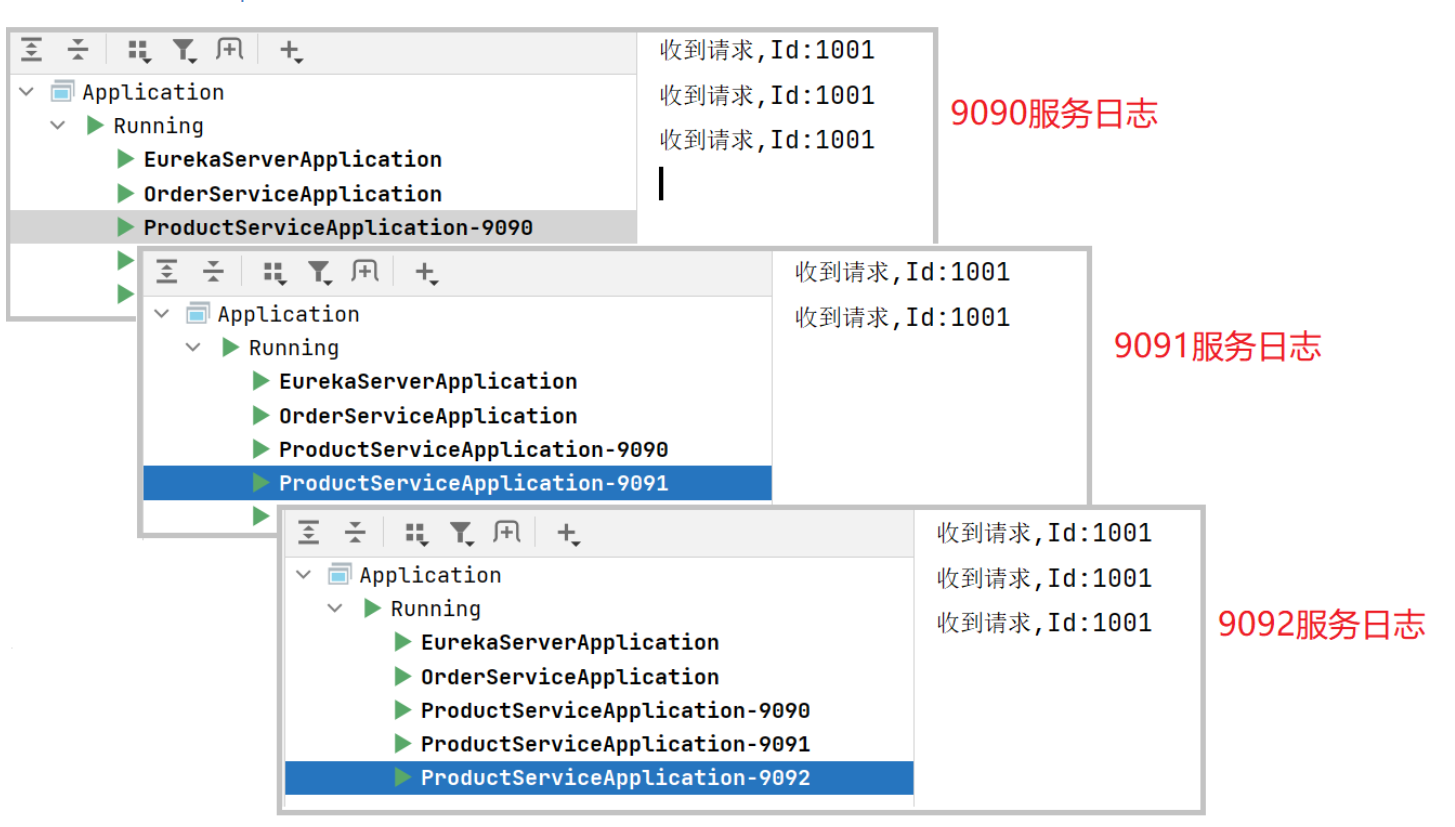
观察product-service的日志, 会发现请求被分配到这3个实例上了
常见的负载均衡策略
Spring Cloud LoadBalancer 默认策略是 RoundRobin(轮询)。 常见策略包括:
RoundRobin(轮询):依次选择服务实例,分配均匀。
Random(随机):随机选一个实例,适合流量比较小的场景。
Weighted(权重):根据权重选择(Nacos 支持,可以按版本或机房区分)。
ZonePreference(区域优先):优先选择同机房的实例,跨机房兜底。
可以通过自定义配置扩展策略。
自定义负载均衡策略
@Configuration
public class LoadBalancerConfig {@BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name,ServiceInstanceListSupplier.class), name);}
}注意: 该类需要满足:
不用 @Configuration 注释
在组件扫描范围内
@LoadBalancerClient(name = "product-service", configuration = LoadBalancerConfig.class)
@Configuration
public class BeanConfig {@LoadBalanced@Beanpublic RestTemplate getRestTemplate(){return new RestTemplate();}
}在 RestTemplate 配置类上方, 使用 @LoadBalancerClient 或 @LoadBalancerClients 注解, 可以对不同的服务提供方配置不同的客户端负载均衡算法策略,这样就把默认的 轮询策略替换成了 随机策略
@LoadBalancerClient 注解说明
name: 该负载均衡策略对哪个服务生效(服务提供方)。
configuration : 该负载均衡策略用哪个负载均衡策略实现。
LoadBalancer 原理
LoadBalancer 的实现,主要是 LoadBalancerInterceptor ,这个类会对 RestTemplate 的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。
我们来看看源码实现:
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {// ...@Overridepublic ClientHttpResponse intercept(final HttpRequest request,final byte[] body,final ClientHttpRequestExecution execution) throws IOException {URI originalUri = request.getURI();String serviceName = originalUri.getHost();
Assert.state(serviceName != null,"Request URI does not contain a valid hostname: " + originalUri);
return (ClientHttpResponse) this.loadBalancer.execute(serviceName,this.requestFactory.createRequest(request, body, execution));}
}可以看到这里的intercept方法, 拦截了用户的HttpRequest请求,然后做了几件事:
request.getURI() 从请求中获取uri,也就是 http://product-service/product/1001
originalUri.getHost() 从uri中获取路径的主机名,也就是服务id,product-service
loadBalancer.execute 根据服务id,进行负载均衡,并处理请求。
public class BlockingLoadBalancerClient implements LoadBalancerClient {
@Overridepublic <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {String hint = this.getHint(serviceId);
LoadBalancerRequestAdapter<T, TimedRequestContext> lbRequest =new LoadBalancerRequestAdapter<>(request, this.buildRequestContext(request, hint));
Set<LoadBalancerLifecycle> supportedLifecycleProcessors =this.getSupportedLifecycleProcessors(serviceId);
supportedLifecycleProcessors.forEach(lifecycle -> lifecycle.onStart(lbRequest));
// 根据 serviceId 和负载均衡策略选择处理的服务ServiceInstance serviceInstance = this.choose(serviceId, lbRequest);
if (serviceInstance == null) {supportedLifecycleProcessors.forEach(lifecycle -> {lifecycle.onComplete(new CompletionContext(Status.DISCARD, lbRequest, new EmptyResponse()));});throw new IllegalStateException("No instances available for " + serviceId);} else {return this.execute(serviceId, serviceInstance, lbRequest);}}
/*** 根据 serviceId 和负载均衡策略选择一个服务实例*/@Overridepublic <T> ServiceInstance choose(String serviceId, Request<T> request) {// 获取负载均衡器ReactiveLoadBalancer<ServiceInstance> loadBalancer =this.loadBalancerClientFactory.getInstance(serviceId);
if (loadBalancer == null) {return null;} else {// 根据负载均衡算法,在列表中选择一个服务实例Response<ServiceInstance> loadBalancerResponse =(Response<ServiceInstance>) Mono.from(loadBalancer.choose(request)).block();
return loadBalancerResponse == null ? null : loadBalancerResponse.getServer();}}
}

lossbase_v2)



)
快速入门完全指南:从零开始构建你的第二大脑(免费好用的笔记软件的知识管理系统)、黑曜石笔记)
)




![Dism++备份系统时报错[句柄无效]的解决方法](http://pic.xiahunao.cn/Dism++备份系统时报错[句柄无效]的解决方法)





