主键表(Table with PK)
PK 是 Primary Key(主键)的缩写。在数据库中,主键是一个或多个列的组合,其值在表中是唯一的,并且不能为 NULL。主键的作用是确保每一行记录的唯一性,便于数据的查找、管理和维护,还可用于建立表与表之间的关系。
概述
如果定义了一个带有主键的表,就可以在表中插入、更新或删除记录。
主键由一组列组成,这些列中的值对于每条记录都是唯一的。Paimon通过在每个桶内对主键进行排序来强制数据有序,这样用户通过在主键上应用过滤条件就能实现高性能操作。详见“创建表(CREATE TABLE)”。
桶(Bucket)
未分区的表,或者分区表中的各个分区,会进一步细分为桶,为数据提供额外的结构,以便更高效地进行查询。
每个桶目录包含一个日志结构合并树(LSM tree)及其变更日志文件。
桶的范围由记录中一个或多个列的哈希值决定。用户可以通过提供 bucket-key 选项来指定分桶列。如果未指定 bucket-key 选项,则主键(如果已定义)或完整记录将用作桶键。
桶是读写的最小存储单元,因此桶的数量限制了最大处理并行度。不过,这个数量也不宜过大,否则会导致产生大量小文件,降低读取性能。一般来说,建议每个桶中的数据大小约为200MB-1GB。
另外,如果在表创建后想要调整桶的数量,可以参考“重新调整桶(rescale bucket)”。
日志结构合并树(LSM Trees)
Paimon采用日志结构合并树(log-structured merge-tree,简称LSM树)作为文件存储的数据结构。本文档简要介绍有关LSM树的概念。
有序段(Sorted Runs)
LSM树将文件组织成几个有序段。一个有序段由一个或多个数据文件组成,并且每个数据文件恰好属于一个有序段。
数据文件内的记录按其主键排序。在一个有序段内,各个数据文件的主键范围从不重叠。
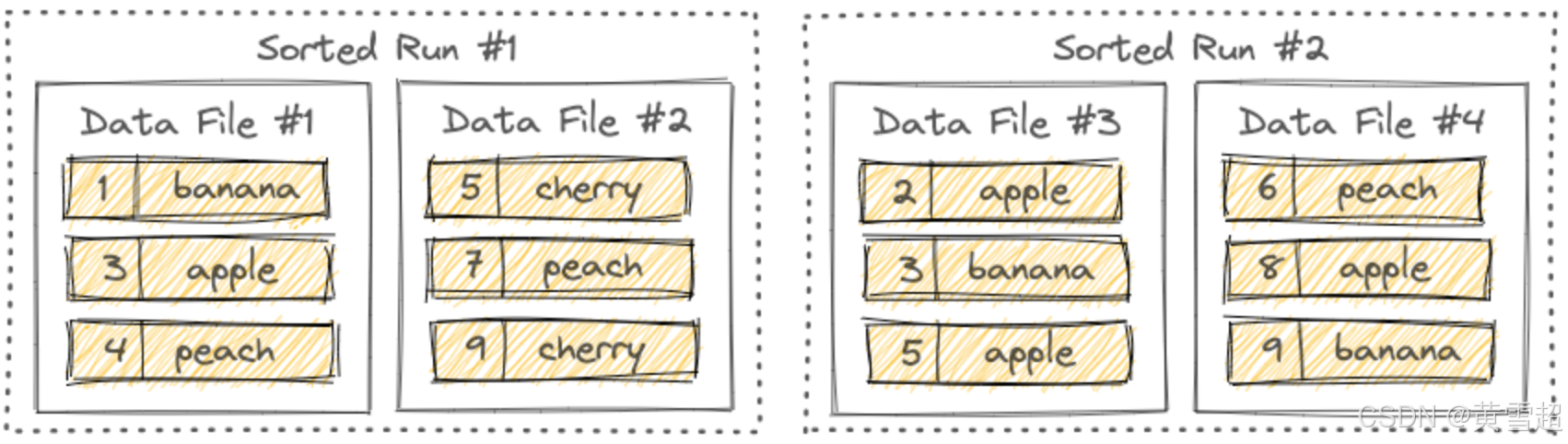
如你所见,不同的有序段可能有重叠的主键范围,甚至可能包含相同的主键。在查询LSM树时,必须合并所有有序段,并且所有具有相同主键的记录必须根据用户指定的合并引擎和每条记录的时间戳进行合并。
写入LSM树的新记录首先会在内存中缓冲。当内存缓冲区已满时,内存中的所有记录将被排序并刷新到磁盘。此时会创建一个新的有序段。
拓展:
主键(Primary Key):在数据库设计中,主键是用于唯一标识表中每一行记录的一个或多个字段的集合。主键的主要特点是唯一性和非空性,它确保了表中数据的完整性和准确性,便于数据的索引、关联和操作。例如,在用户信息表中,可以将“用户ID”设置为主键,这样就可以通过该主键快速定位和管理每个用户的记录。在Paimon中,主键不仅用于保证数据的唯一性,还通过在桶内排序来优化查询性能。
日志结构合并树(Log-Structured Merge-Tree, LSM Tree):这是一种广泛应用于数据库系统的数据结构,特别适用于处理高写入负载的场景。LSM树的基本原理是将写入操作先记录在日志中,然后定期将日志合并到更大的有序结构中。这种设计减少了随机I/O操作,提高了写入性能。在Paimon中,LSM树用于文件存储,将数据文件组织成有序段,使得数据的写入和查询能够更高效地进行。例如,在处理大量实时数据写入时,LSM树能够快速响应写入请求,并在后续的合并过程中优化数据存储结构,以提升查询效率。
分桶(Bucketing):在数据存储和查询优化中,分桶是一种将数据按照特定规则划分到不同桶中的技术。通过分桶,可以将数据分布到多个较小的单元中,从而提高查询并行度和效率。在Paimon中,分桶不仅可以基于主键,还可以通过用户指定的桶键进行。合理的分桶策略能够平衡数据存储和查询性能,避免因桶数量过多导致小文件过多影响读取性能,或者桶数量过少无法充分利用并行处理能力。例如,在处理大规模销售数据时,可以按照销售地区或时间等维度进行分桶,以便在查询特定地区或时间段的数据时能够快速定位和处理。
数据分布(Data Distribution)
桶是读写的最小存储单元,每个桶目录包含一个日志结构合并树(LSM树)。
固定桶(Fixed Bucket)
配置一个大于0的桶数,使用固定桶模式,根据 Math.abs(key_hashcode % numBuckets) 来计算记录所属的桶。
只能通过离线流程重新调整桶的数量,详见“重新调整桶(Rescale Bucket)”。桶的数量过多会导致产生过多小文件,而桶的数量过少则会导致写入性能不佳。
动态桶(Dynamic Bucket)
主键表的默认模式,或者配置 'bucket' = '-1'。
先到达的键会落入旧桶,新的键会落入新桶,桶与键的分布取决于数据到达的顺序。Paimon维护一个索引来确定哪个键对应哪个桶。
Paimon会自动扩展桶的数量。
选项1:
'dynamic-bucket.target-row-num':控制一个桶的目标行数。选项2:
'dynamic-bucket.initial-buckets':控制初始化的桶数量。
动态桶仅支持单个写入作业。请勿启动多个作业写入相同的分区(这可能会导致数据重复)。即使启用 'write-only' 并启动一个专门的合并作业,也无法避免。
普通动态桶模式(Normal Dynamic Bucket Mode)
当你的更新不跨分区(无分区,或者主键包含所有分区字段)时,动态桶模式使用哈希(HASH)索引来维护键到桶的映射,相比固定桶模式,它需要更多内存。
性能:
一般来说,不会有性能损失,但会有一些额外的内存消耗,一个分区中有1亿条记录会多占用1GB内存,不再活跃的分区不占用内存。
对于更新率较低的表,建议使用此模式以显著提高性能。
普通动态桶模式支持排序合并(Sort Compact)以加速查询。详见“排序合并(Sort Compact)”。
跨分区插入更新动态桶模式(Cross Partitions Upsert Dynamic Bucket Mode)
当你需要跨分区插入更新(主键不包含所有分区字段)时,动态桶模式直接维护键到分区和桶的映射,使用本地磁盘,并在启动流写入作业时通过读取表中所有现有键来初始化索引。
不同的合并引擎有不同的行为:
去重(Deduplicate):从旧分区删除数据,并将新数据插入到新分区。
部分更新(PartialUpdate)和聚合(Aggregation):将新数据插入到旧分区。
首行(FirstRow):如果存在旧值,则忽略新数据。
性能:对于数据量较大的表,性能会有显著损失。此外,初始化需要很长时间。
如果你的插入更新操作不依赖太旧的数据,可以考虑配置索引生存时间(TTL)来减少索引和初始化时间:
cross-partition-upsert.index-ttl:RocksDB索引和初始化中的生存时间(TTL),这可以避免维护过多索引导致性能越来越差。
但请注意,这也可能会导致数据重复。
选择分区字段(Pick Partition Fields)
在数据仓库中,以下三种类型的字段可定义为分区字段:
创建时间(推荐):创建时间通常是不可变的,因此你可以放心地将其作为分区字段并添加到主键中。
事件时间:事件时间是原始表中的一个字段。对于变更数据捕获(CDC)数据,例如从MySQL CDC同步的表或由Paimon生成的变更日志,它们都是完整的CDC数据,包括
UPDATE_BEFORE记录,即使你声明主键包含分区字段,也能实现唯一性效果(需要'changelog-producer'='input')。CDC操作时间戳(CDC op_ts):它不能定义为分区字段,因为无法得知先前记录的时间戳。所以你需要使用跨分区插入更新,这会消耗更多资源。
拓展:
哈希索引(HASH Index):一种通过哈希函数将键值映射到特定存储位置(如桶)的索引结构。在普通动态桶模式中,哈希索引用于快速定位键所属的桶,提高数据存储和查询效率。哈希函数的选择很关键,理想情况下应尽量减少哈希冲突,确保数据均匀分布。例如,在处理大量用户数据时,通过用户ID的哈希值将用户记录分配到不同桶中,使得查询特定用户记录时能快速定位到对应的桶。
生存时间(TTL, Time-To-Live):在计算机系统中,TTL常用于指定数据或资源的有效期限。在跨分区插入更新动态桶模式下,通过配置索引TTL,可以控制索引数据的保留时间,避免因长期积累过多索引数据而导致性能下降。例如,对于一些时效性较强的数据,设置较短的索引TTL,过期后索引数据被清理,可减少内存占用和索引维护成本,但可能会因索引数据丢失而导致部分数据查询不准确或重复。
变更数据捕获(CDC, Change Data Capture):一种用于捕获数据库中数据变化的技术,它能实时监测数据库表的插入、更新和删除操作,并将这些变化的数据捕获下来。在Paimon中,涉及CDC数据处理时,理解如何利用CDC数据的特性(如事件时间、
UPDATE_BEFORE记录等)来设计分区和主键,对于确保数据的一致性和高效处理非常重要。例如,从MySQL数据库同步数据到Paimon时,通过CDC技术捕获MySQL表的变更,然后在Paimon中根据这些变更进行相应的数据更新和管理。
表模式(Table Mode)
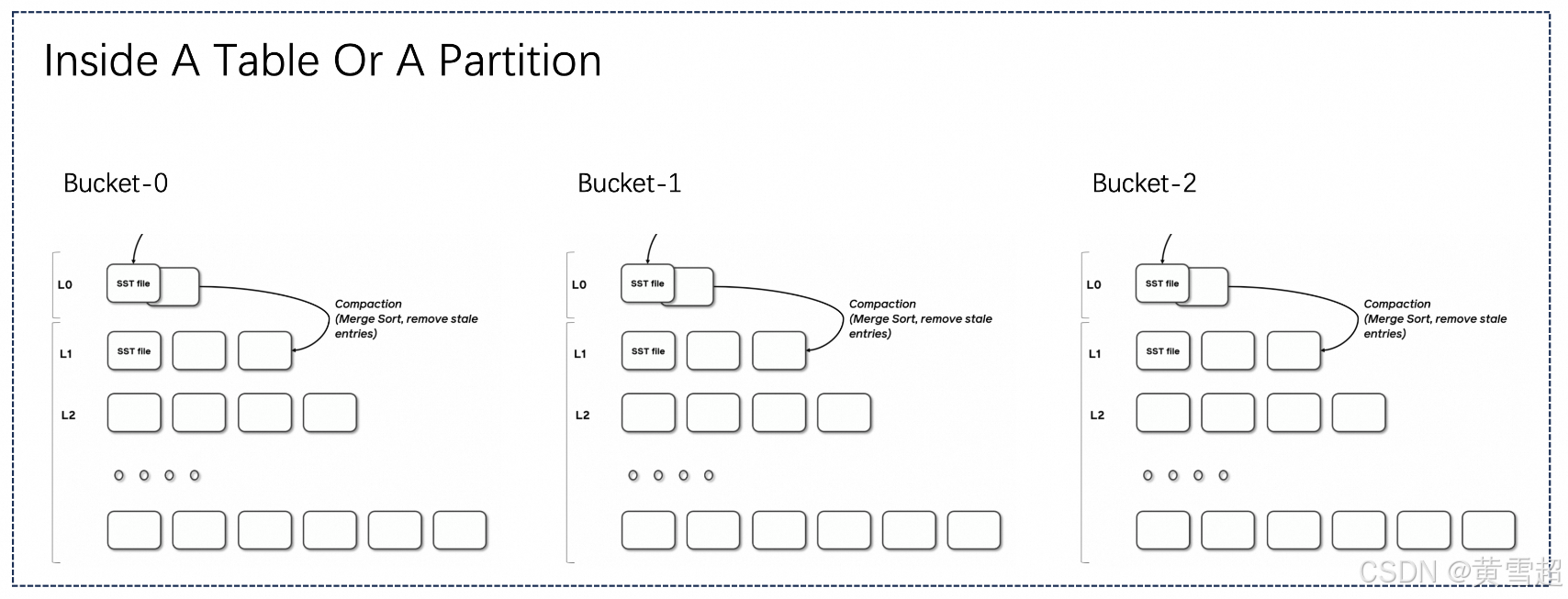
主键表的文件结构大致如上图所示。表或分区包含多个桶,每个桶是一个单独的日志结构合并树(LSM)结构,包含多个文件。
LSM的写入过程大致如下:Flink检查点刷新L0文件,并根据需要触发合并以合并数据。根据写入时的不同处理方式,有三种模式:
读时合并(Merge On Read, MOR):默认模式,仅执行小范围合并,读取时需要进行合并。
写时复制(Copy On Write, COW):使用
'full-compaction.delta-commits' = '1',将同步进行完全合并,这意味着写入时就完成合并。写时合并(Merge On Write, MOW):使用
'deletion-vectors.enabled' = 'true',在写入阶段,LSM将被查询以生成数据文件的删除向量文件,读取时可直接过滤掉不必要的行。
对于一般的主键表,推荐使用写时合并模式(合并引擎默认为去重)。
读时合并(Merge On Read)
MOR是主键表的默认模式。
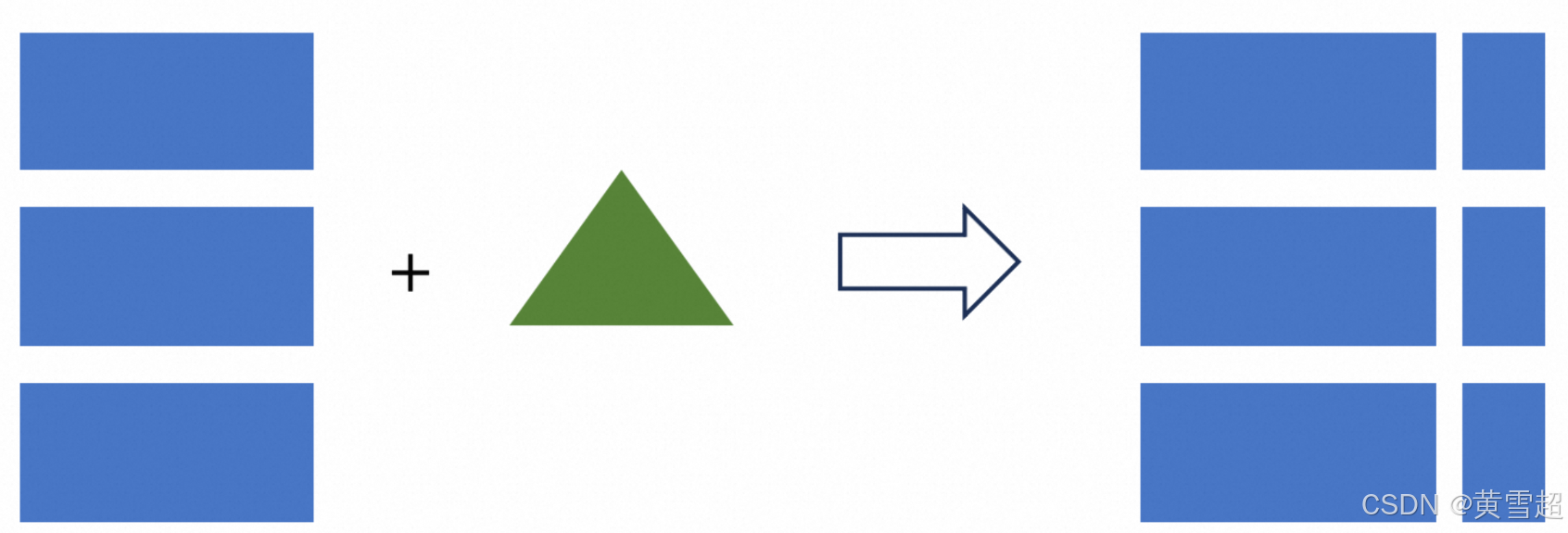
当模式为MOR时,读取时需要合并所有文件,因为所有文件都是有序的,要进行多路合并,其中包括主键的比较计算。
这里存在一个明显的问题,单个LSM树一次只能由一个线程读取,因此读取并行度受限。如果桶中的数据量过大,会导致读取性能不佳。所以为了保证读取性能,建议分析查询需求表,并将桶中的数据量设置在200MB到1GB之间。但如果桶过小,会有大量小文件的读写操作,给文件系统带来压力。
此外,由于合并过程的存在,不能对非主键列执行基于过滤(Filter)的数据跳过操作,否则新数据会被过滤掉,导致旧数据不正确。
写入性能:非常好。
读取性能:不太好。
写时复制(Copy On Write)
ALTER TABLE orders SET ('full-compaction.delta-commits' = '1');将full-compaction.delta-commits设置为1,意味着每次写入都会进行完全合并,所有数据都会合并到最高层。此时读取时无需合并,读取性能最高。但每次写入都需要完全合并,写放大非常严重。
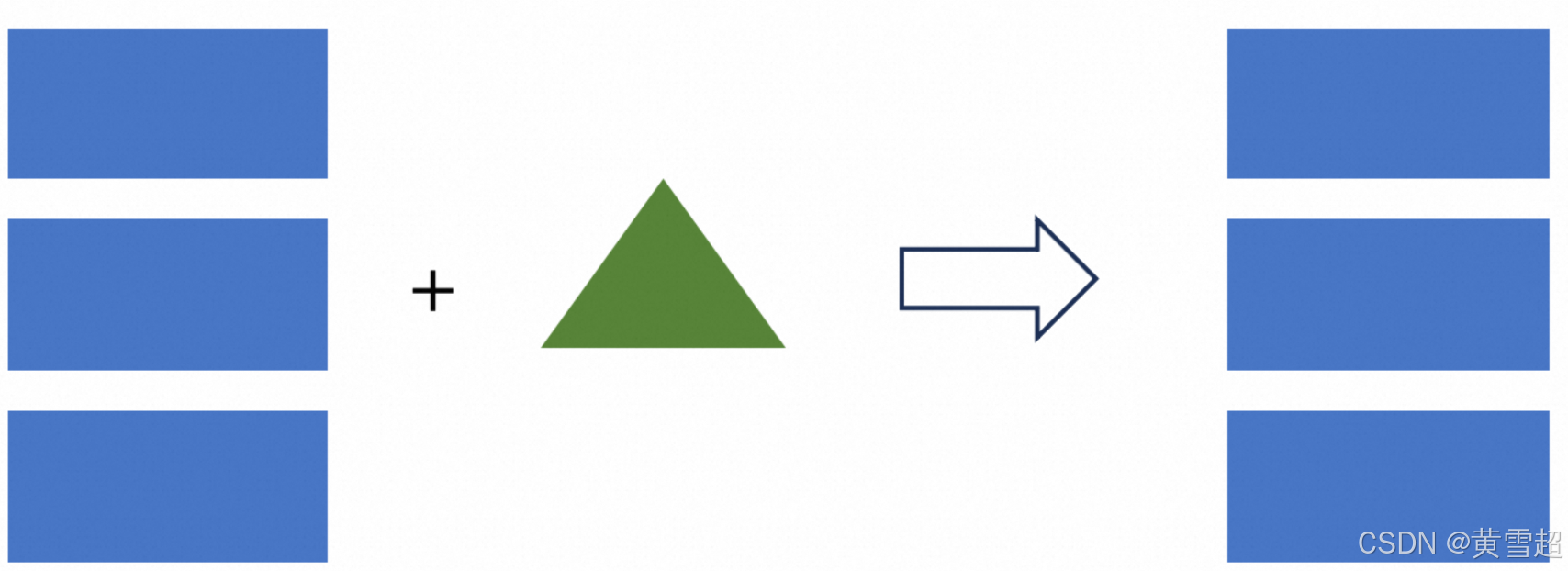
写入性能:非常差。
读取性能:非常好。
写时合并(Merge On Write)
ALTER TABLE orders SET ('deletion-vectors.enabled' = 'true');得益于Paimon的LSM结构,它具备按主键查询的能力。我们可以在写入时生成删除向量文件,表明文件中的哪些数据已被删除。读取时这能直接过滤掉不必要的行,相当于进行了合并且不影响读取性能。
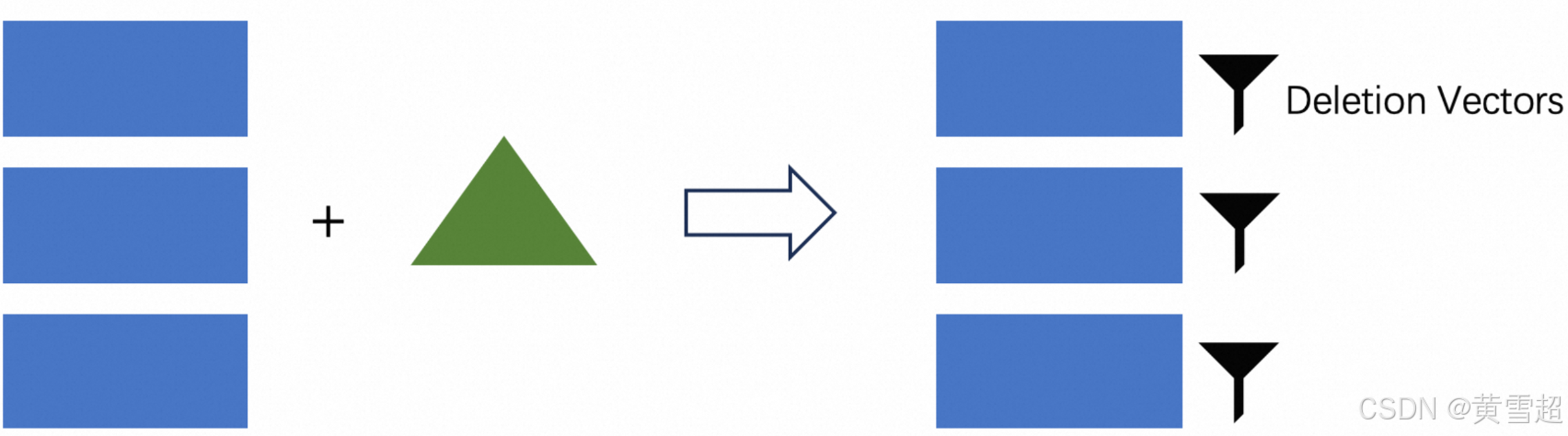
一个简单的例子:
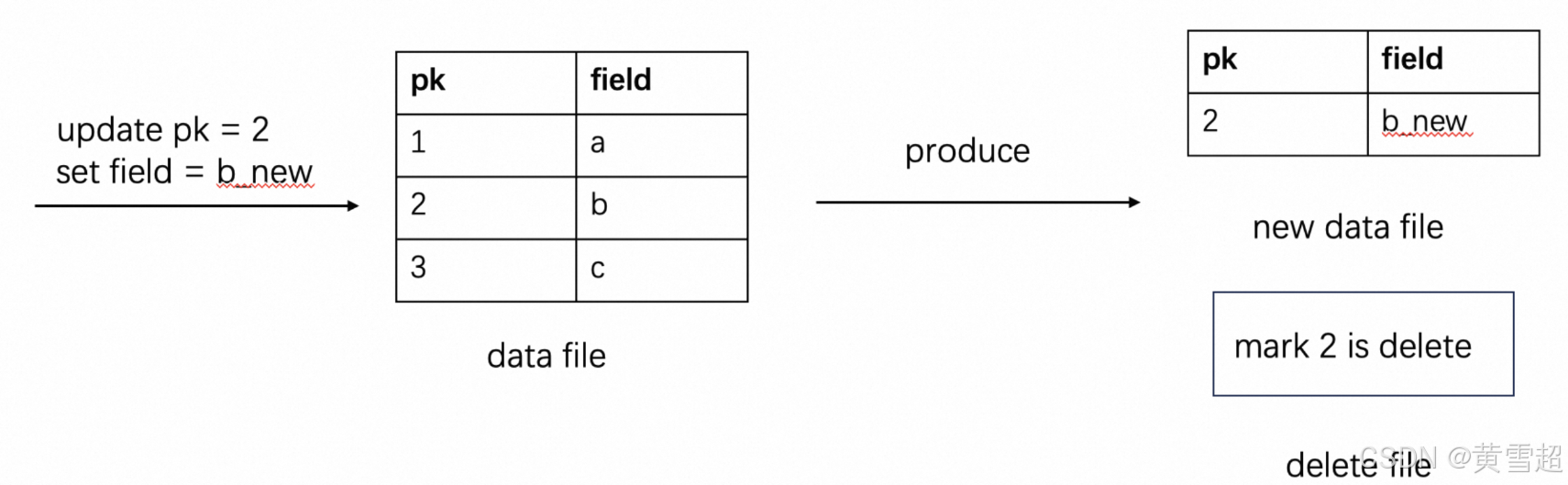
通过先删除旧记录再添加新记录来更新数据。
写入性能:好。
读取性能:好。
可见性保证:在删除向量模式下的表,L0级别的文件只有在合并后才会可见。所以默认情况下,合并是同步的,如果开启异步,数据可能会有延迟。
MOR读优化(MOR Read Optimized)
如果你不想使用删除向量模式,又希望在MOR模式下查询足够快,但只能查询到较旧的数据,你还可以:
在写入数据时配置
‘compaction.optimization-interval’。从读优化的系统表中查询。从优化后的文件结果中读取可避免合并具有相同键的记录,从而提高读取性能。
你可以在读取时灵活平衡查询性能和数据延迟。
拓展:
读时合并(Merge On Read, MOR):在这种模式下,数据写入时不立即进行大规模合并,而是在读取时才将多个有序文件合并。这使得写入操作相对快速,因为不需要等待合并完成。然而,读取性能会受到影响,尤其是数据量较大时,由于单线程读取和合并操作,可能导致读取速度慢。在一些大数据存储场景中,如果数据写入频繁但读取不那么频繁,MOR模式可以在一定程度上提高整体系统性能。例如,在日志数据的存储中,日志数据不断写入,而查询频率相对较低,MOR模式可减少写入时的开销。
写时复制(Copy On Write, COW):此模式下,每次写入操作都会触发数据的完全合并,将所有数据合并到最高层。虽然这极大地提高了读取性能,因为读取时无需再进行合并操作,但严重的写放大问题会导致写入性能急剧下降。写放大意味着为了完成一次写入,需要进行大量额外的I/O操作(如多次读取和写入数据块)。这种模式适用于对读取性能要求极高且写入频率较低的场景,例如某些数据仓库,主要用于数据分析查询,写入操作相对较少。
写时合并(Merge On Write, MOW):通过在写入时生成删除向量文件,记录哪些数据已被删除,读取时可直接过滤掉这些不必要的数据行,从而在保证写入性能的同时,也能维持较好的读取性能。删除向量文件作为一种优化手段,利用了LSM树按主键查询的特性,有效提升了整体性能。在实际应用中,对于频繁更新且对读写性能都有要求的主键表数据,MOW模式是一种较为理想的选择。例如,在电商系统的订单表中,订单数据会不断更新,采用MOW模式可在不影响写入速度的前提下,快速读取最新的订单状态。
合并优化间隔(compaction.optimization-interval):在MOR读优化中,配置该参数可以控制合并优化的时间间隔。通过合理设置这个间隔,可以在写入时对数据进行适当的预处理,使得后续读取时能够更快地获取数据,同时也能在一定程度上平衡查询性能和数据延迟。较短的优化间隔可能会提高查询性能,但可能会增加写入时的开销;较长的间隔则相反。这需要根据具体的业务需求和数据特点来调整。
合并引擎(Merge Engine)
概述
当Paimon接收器接收到两条或更多具有相同主键的记录时,它会将它们合并为一条记录,以保持主键的唯一性。通过指定 merge-engine 表属性,用户可以选择记录的合并方式。
在Flink SQL表配置中,始终将 table.exec.sink.upsert-materialize 设置为 NONE,sink upsert-materialize 可能会导致奇怪的行为。当输入无序时,建议使用序列字段来纠正无序问题。
去重(Deduplicate)
去重合并引擎是默认的合并引擎。Paimon将只保留最新的记录,并丢弃其他具有相同主键的记录。
具体来说,如果最新的记录是一条DELETE记录,则所有具有相同主键的记录都将被删除。你可以配置 ignore-delete 来忽略它。
拓展:
Paimon接收器(Paimon sink):在数据处理流程中,负责将数据写入Paimon存储系统的组件。当它接收到数据时,需要按照特定规则处理重复主键的情况,以维护数据的一致性和完整性。例如,在一个实时数据处理任务中,数据从各种数据源流入,通过Flink等流处理框架处理后,由Paimon接收器写入Paimon表中。
table.exec.sink.upsert-materialize:这是Flink SQL表配置中的一个属性,用于控制upsert操作(插入或更新操作)的数据物化方式。设置为NONE可以避免一些异常行为,确保数据按照预期的方式写入Paimon。在Flink与Paimon结合使用时,正确配置这个属性对于保证数据处理的正确性非常重要。例如,如果设置不当,可能会导致数据重复写入或更新异常。序列字段(Sequence Field):当数据输入无序时,序列字段可以作为一种标记,用于确定数据的先后顺序。在Paimon中,结合去重合并引擎,序列字段可以帮助系统准确判断哪条记录是最新的,从而正确执行去重操作。比如在一个电商订单系统中,订单数据可能由于网络延迟等原因无序到达,通过为每条订单记录添加一个递增的序列字段,系统可以根据序列字段的值来确定订单的实际发生顺序,进而在去重时保留最新的订单状态。
部分更新(Partial Update)
通过指定'merge-engine' = 'partial-update',用户能够通过多次更新来更新记录的列,直至记录完整。这是通过逐个更新值字段来实现的,使用相同主键下的最新数据。不过,在此过程中,空值不会被覆盖。
例如,假设Paimon接收到三条记录:
<1, 23.0, 10, NULL>-
<1, NULL, NULL, 'This is a book'>
<1, 25.2, NULL, NULL>假设第一列是主键,最终结果将是<1, 25.2, 10, '这是一本书'>。
对于流查询,部分更新合并引擎必须与查找(lookup)或完全合并变更日志生成器一起使用。(也支持‘input’变更日志生成器,但仅返回输入记录。)
默认情况下,部分更新不接受删除记录,你可以选择以下解决方案之一:
配置‘ignore-delete’以忽略删除记录。
配置‘partial-update.remove-record-on-delete’,在接收到删除记录时删除整行。
配置‘sequence-group’以撤回部分列。
序列组(Sequence Group)
序列字段可能无法解决具有多个流更新的部分更新表的无序问题,因为在多流更新期间,序列字段可能会被另一个流的最新数据覆盖。
因此,我们为部分更新表引入序列组机制。它可以解决:
多流更新期间的无序问题。每个流定义自己的序列组。
实现真正的部分更新,而不仅仅是非空更新。
看示例:
CREATE TABLE t
(k INT,a INT,b INT,g_1 INT,c INT,d INT,g_2 INT,PRIMARY KEY (k) NOT ENFORCED
) WITH ('merge - engine' = 'partial - update','fields.g_1.sequence - group' = 'a,b','fields.g_2.sequence - group' = 'c,d');INSERT INTO t
VALUES (1, 1, 1, 1, 1, 1, 1);-- g_2为空,c、d不应更新
INSERT INTO t
VALUES (1, 2, 2, 2, 2, 2, CAST(NULL AS INT));SELECT *
FROM t;
-- 输出1, 2, 2, 2, 1, 1, 1-- g_1较小,a、b不应更新
INSERT INTO t
VALUES (1, 3, 3, 1, 3, 3, 3);SELECT *
FROM t; -- 输出1, 2, 2, 2, 3, 3, 3对于fields.<field-name>.sequence-group,有效的可比较数据类型包括:DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP和TIMESTAMP_LTZ。
你还可以在一个序列组中配置多个排序字段,如fields.<field-name1>,<field-name2>.sequence-group,多个字段将按顺序进行比较。
看示例:
CREATE TABLE SG
(k INT,a INT,b INT,g_1 INT,c INT,d INT,g_2 INT,g_3 INT,PRIMARY KEY (k) NOT ENFORCED
) WITH ('merge-engine' = 'partial-update','fields.g_1.sequence-group' = 'a,b','fields.g_2,g_3.sequence-group' = 'c,d');INSERT INTO SG
VALUES (1, 1, 1, 1, 1, 1, 1, 1);-- g_2、g_3不应更新
INSERT INTO SG
VALUES (1, 2, 2, 2, 2, 2, 1, CAST(NULL AS INT));SELECT *
FROM SG;
-- 输出1, 2, 2, 2, 1, 1, 1, 1-- g_1不应更新
INSERT INTO SG
VALUES (1, 3, 3, 1, 3, 3, 3, 1);SELECT *
FROM SG;
-- 输出1, 2, 2, 2, 3, 3, 3, 1部分更新的聚合(Aggregation For Partial Update)
你可以为输入字段指定聚合函数,支持聚合中的所有函数。
看示例:
CREATE TABLE t
(k INT,a INT,b INT,c INT,d INT,PRIMARY KEY (k) NOT ENFORCED
) WITH ('merge-engine' = 'partial-update','fields.a.sequence-group' = 'b','fields.b.aggregate-function' = 'first_value','fields.c.sequence-group' = 'd','fields.d.aggregate-function' ='sum');
INSERT INTO t
VALUES (1, 1, 1, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO t
VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 1, 1);
INSERT INTO t
VALUES (1, 2, 2, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO t
VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 2, 2);SELECT *
FROM t; -- 输出1, 2, 1, 2, 3你还可以为多个排序字段内的序列组配置聚合函数。
看示例:
CREATE TABLE AGG
(k INT,a INT,b INT,g_1 INT,c VARCHAR,g_2 INT,g_3 INT,PRIMARY KEY (k) NOT ENFORCED
) WITH ('merge-engine' = 'partial-update','fields.a.aggregate-function' ='sum','fields.g_1,g_3.sequence-group' = 'a','fields.g_2.sequence-group' = 'c');
-- a在序列组g_1、g_3中,使用sum聚合
-- b不在序列组中
-- c在序列组g_2中,无聚合INSERT INTO AGG
VALUES (1, 1, 1, 1, '1', 1, 1);-- g_2不应更新
INSERT INTO AGG
VALUES (1, 2, 2, 2, '2', CAST(NULL AS INT), 2);SELECT *
FROM AGG;
-- 输出1, 3, 2, 2, "1", 1, 2-- g_1、g_3不应更新
INSERT INTO AGG
VALUES (1, 3, 3, 2, '3', 3, 1);SELECT *
FROM AGG;
-- 输出1, 6, 3, 2, "3", 3, 2你可以使用fields.default-aggregate-function为所有输入字段指定默认聚合函数,看示例:
CREATE TABLE t
(k INT,a INT,b INT,c INT,d INT,PRIMARY KEY (k) NOT ENFORCED
) WITH ('merge-engine' = 'partial-update','fields.a.sequence-group' = 'b','fields.c.sequence-group' = 'd','fields.default-aggregate-function' = 'last_non_null_value','fields.d.aggregate-function' ='sum');INSERT INTO t
VALUES (1, 1, 1, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO t
VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 1, 1);
INSERT INTO t
VALUES (1, 2, 2, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO t
VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 2, 2);SELECT *
FROM t; -- 输出1, 2, 2, 2, 3拓展:
部分更新合并引擎(Partial Update Merge Engine):在数据库操作中,部分更新合并引擎允许用户对记录的特定列进行逐步更新,而不是一次性更新整个记录。这种机制在处理需要多次累积更新的场景时非常有用,比如在一个用户信息表中,用户可能分多次更新自己的不同信息字段,使用部分更新合并引擎可以确保每次更新都能正确累积,同时避免覆盖空值。
序列组(Sequence Group):这是为解决多流更新场景下部分更新表的无序问题而引入的机制。通过为不同的字段组定义序列组,每个序列组内的数据可以按照特定规则进行更新,保证更新的准确性和顺序性。例如在一个包含多个属性的设备状态表中,不同的属性可能来自不同的数据流,通过序列组可以确保每个数据流对应的属性更新按照正确顺序进行,避免数据混乱。
聚合函数(Aggregation Function):在部分更新的场景下,聚合函数用于对具有相同主键的不同记录中的字段值进行聚合操作。如示例中展示的
sum(求和)、first_value(取第一个值)等函数,通过这些函数可以根据业务需求对数据进行合并处理。在销售数据统计中,可以使用sum函数对具有相同产品ID的不同销售记录的销售额进行求和,从而得到该产品的总销售额。默认聚合函数(Default Aggregation Function):通过
fields.default-aggregate-function设置的默认聚合函数,为所有未单独指定聚合函数的输入字段提供统一的聚合规则。这在批量处理具有相似聚合需求的字段时非常方便,减少了配置的复杂性。例如在一个包含多个数值字段的统计表格中,如果大部分字段都需要使用last_non_null_value函数进行聚合,设置默认聚合函数可以避免为每个字段单独配置。
聚合(Aggregation)
注意:在Flink SQL表配置中,始终将 table.exec.sink.upsert-materialize 设置为 NONE。
有时用户只关心聚合结果。聚合合并引擎会根据聚合函数,对相同主键下的每个值字段逐个与最新数据进行聚合。
每个非主键字段都可以指定一个聚合函数,通过 fields.<field-name>.aggregate-function 表属性指定,否则将默认使用 last_non_null_value 聚合。例如,考虑以下表定义:
Flink:
CREATE TABLE my_table (product_id BIGINT,price DOUBLE,sales BIGINT,PRIMARY KEY (product_id) NOT ENFORCED
) WITH ('merge-engine' = 'aggregation','fields.price.aggregate-function' ='max','fields.sales.aggregate-function' ='sum'
);price 字段将通过 max 函数进行聚合,sales 字段将通过 sum 函数进行聚合。给定两条输入记录 <1, 23.0, 15> 和 <1, 30.2, 20>,最终结果将是 <1, 30.2, 35>。
聚合函数(Aggregation Functions)
目前支持的聚合函数和数据类型如下:
sum
sum 函数对多行的值进行求和。它支持 DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT 和 DOUBLE 数据类型。
product
product 函数可以计算多行的乘积值。它支持 DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT 和 DOUBLE 数据类型。
count
在需要统计满足特定条件的行数的场景中,可以使用 SUM 函数来实现。通过将条件表示为布尔值(TRUE 或 FALSE)并将其转换为数值,就可以有效地统计行数。在这种方法中,TRUE 转换为 1,FALSE 转换为 0。
例如,如果有一个 orders 表,想要统计满足特定条件的行数,可以使用以下查询:
SELECT SUM(CASE WHEN condition THEN 1 ELSE 0 END) AS count
FROM orders;max
max 函数识别并保留最大值。它支持 CHAR、VARCHAR、DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP 和 TIMESTAMP_LTZ 数据类型。
min
min 函数识别并保留最小值。它支持 CHAR、VARCHAR、DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP 和 TIMESTAMP_LTZ 数据类型。
last_value
last_value 函数用最近导入的值替换先前的值。它支持所有数据类型。
last_non_null_value
last_non_null_value 函数用最新的非空值替换先前的值。它支持所有数据类型。
listagg
listagg 函数将多个字符串值连接成一个字符串。它支持 STRING 数据类型。每个非主键字段都可以指定一个列表聚合分隔符,通过 fields.<field-name>.list-agg-delimiter 表属性指定,否则将默认使用 “,”。
bool_and
bool_and 函数评估布尔集合中的所有值是否都为 true。它支持 BOOLEAN 数据类型。
bool_or
bool_or 函数检查布尔集合中是否至少有一个值为 true。它支持 BOOLEAN 数据类型。
first_value
first_value 函数从数据集中检索第一个空值。它支持所有数据类型。
first_non_null_value
first_non_null_value 函数选择数据集中的第一个非空值。它支持所有数据类型。
rbm32
rbm32 函数将多个序列化的 32 位 RoaringBitmap 聚合为一个 RoaringBitmap。它支持 VARBINARY 数据类型。
rbm64
rbm64 函数将多个序列化的 64 位 Roaring64Bitmap 聚合为一个 Roaring64Bitmap。它支持 VARBINARY 数据类型。
nested_update
nested_update 函数将多行收集到一个数组中(即所谓的 “嵌套表”)。它支持 ARRAY 数据类型。
使用 fields.<field-name>.nested-key = pk0,pk1,... 来指定嵌套表的主键。如果没有指定键,行将追加到数组中。
collect
collect 函数将元素收集到一个数组中。可以设置 fields.<field-name>.distinct = true 来对元素进行去重。它仅支持 ARRAY 类型。
merge_map
merge_map 函数合并输入的映射。它仅支持 MAP 类型。
基数草图类型(Types of cardinality sketches)
Paimon 使用 Apache DataSketches 随机流算法库来实现草图模块。DataSketches 库包含各种类型的草图,每种草图都旨在解决不同类型的问题。Paimon 支持 HyperLogLog(HLL)和 Theta 基数草图。
HyperLogLog
HyperLogLog(HLL)草图聚合器是一种非常紧凑的草图算法,用于近似基数统计(计算不同值的数量)。你还可以使用 HLL 聚合器来计算 HLL 草图的并集。
Theta
Theta 草图是一种用于带有集合操作的近似基数统计的草图算法。Theta 草图允许你计算集合之间的重叠部分,以便你可以计算草图对象之间的并集、交集或差集。
选择草图类型
HLL 和 Theta 草图都支持近似基数统计;然而,HLL 草图产生的结果更准确,并且消耗的存储空间更少。Theta 草图更灵活,但需要显著更多的内存。
在为你的用例选择近似算法时,请考虑以下几点:
如果你的用例需要基数统计和合并草图对象,请使用 HLL 草图。
如果你需要评估并集、交集或差集操作,请使用 Theta 草图。
你不能将 HLL 草图与 Theta 草图合并。
hll_sketch
hll_sketch 函数将多个序列化的 Sketch 对象聚合为一个 Sketch。它支持 VARBINARY 数据类型。
theta_sketch
theta_sketch 函数将多个序列化的 Sketch 对象聚合为一个 Sketch。它支持 VARBINARY 数据类型。
例如:
Flink:
-- 源表
CREATE TABLE VISITS (id INT PRIMARY KEY NOT ENFORCED,user_id STRING
);-- 聚合表
CREATE TABLE UV_AGG (id INT PRIMARY KEY NOT ENFORCED,uv VARBINARY
) WITH ('merge-engine' = 'aggregation','fields.f0.aggregate-function' = 'theta_sketch'
);-- 将以下类注册为名为 "THETA_SKETCH" 的 Flink 函数,
-- 该函数用于将输入转换为草图字节数组:
--
-- public static class ThetaSketchFunction extends ScalarFunction {
-- public byte[] eval(String user_id) {
-- UpdateSketch updateSketch = UpdateSketch.builder().build();
-- updateSketch.update(user_id);
-- return updateSketch.compact().toByteArray();
-- }
-- }
--
INSERT INTO UV_AGG SELECT id, THETA_SKETCH(user_id) FROM VISITS;-- 将以下类注册为名为 "THETA_SKETCH_COUNT" 的 Flink 函数,
-- 该函数用于从草图字节数组中获取基数:
--
-- public static class ThetaSketchCountFunction extends ScalarFunction {
-- public Double eval(byte[] sketchBytes) {
-- if (sketchBytes == null) {
-- return 0d;
-- }
-- return Sketches.wrapCompactSketch(Memory.wrap(sketchBytes)).getEstimate();
-- }
-- }
--
-- 然后我们可以根据聚合字段获取用户基数。
SELECT id, THETA_SKETCH_COUNT(UV) as uv FROM UV_AGG;对于流查询,聚合合并引擎必须与查找(lookup)或完全合并变更日志生成器一起使用。(也支持 ‘input’ 变更日志生成器,但仅返回输入记录。)
回撤(Retraction)
只有 sum、product、collect、merge_map、nested_update、last_value 和 last_non_null_value 支持回撤(UPDATE_BEFORE 和 DELETE),其他聚合函数不支持回撤。如果你允许某些函数忽略回撤消息,可以配置:'fields.${field_name}.ignore-retract' = 'true'。
last_value 和 last_non_null_value 在接收到回撤消息时仅将字段设置为 null。
collect 和 merge_map 尽力尝试处理回撤消息,但不能保证结果准确。在处理回撤消息时可能会出现以下行为:
如果记录无序,可能无法处理回撤消息。例如,表使用 collect,上游分别发送 +I['A', 'B'] 和 -U['A']。如果表先接收到 -U['A'],则无法处理;然后接收到 +I['A', 'B'],合并结果将是 +I['A', 'B'] 而不是 +I['B']。
来自一个上游的回撤消息将回撤从多个上游合并的结果。例如,表使用 merge_map,一个上游发送 +I[1 -> A],另一个上游发送 +I[1 -> B],随后发送 -D[1 -> B]。表将首先将两个插入值合并为 +I[1 -> B],然后 -D[1 -> B] 将回撤整个结果,因此最终结果是一个空映射而不是 +I[1 -> A]。
拓展:
聚合合并引擎(Aggregation Merge Engine):在数据处理中,聚合合并引擎负责按照指定的聚合函数对具有相同主键的数据进行聚合操作,以生成最终的聚合结果。这在数据分析和统计场景中广泛应用,例如在销售数据分析中,通过聚合合并引擎可以按产品ID统计不同产品的总销售额、最高价格等信息。
Flink SQL 配置:在使用Flink与Paimon结合进行数据处理时,正确配置Flink SQL的相关属性(如
table.exec.sink.upsert-materialize设置为NONE)对于确保数据处理的准确性和一致性至关重要。这些配置会影响数据的写入方式和聚合操作的执行逻辑。Apache DataSketches 库:这是一个用于概率算法和数据草图的开源库,提供了高效的近似计算方法,如基数统计等。在Paimon中使用该库实现的HLL和Theta草图,能够在处理大规模数据时,以较小的空间开销和计算成本获得近似的统计结果。例如,在统计网站的独立访客数量(基数统计)时,使用HLL草图可以在不存储所有访客ID的情况下,快速得到较为准确的访客数量估计。
回撤(Retraction):在流数据处理中,回撤表示对之前发送的消息进行撤销或修正。例如,由于数据更新或删除操作,需要撤回之前插入或更新的数据。不同的聚合函数对回撤的支持情况不同,了解这些差异对于正确处理流数据中的变更非常重要。在实时数据分析场景中,如果不妥善处理回撤消息,可能会导致数据的不一致或错误的统计结果。
首行(First Row)
通过指定'merge-engine' = 'first-row',用户可以保留具有相同主键的首行记录。它与去重合并引擎的不同之处在于,首行合并引擎只会生成仅插入的变更日志。
不能指定序列字段(sequence.field)。
不接受 DELETE 和 UPDATE_BEFORE 消息。你可以配置
ignore-delete来忽略这两种记录。可见性保证:使用首行合并引擎的表,L0 级别的文件只有在合并后才会可见。所以默认情况下,合并是同步的,如果开启异步,数据可能会有延迟。
这在流计算中替代日志去重方面有很大帮助。
拓展:
首行合并引擎(First Row Merge Engine):在数据处理场景中,该引擎为处理具有相同主键的数据提供了一种特定的合并策略,即保留首条记录。这种策略在某些特定业务场景下很有用,比如在记录事件的先后顺序且只关心最早发生的事件记录时,首行合并引擎能确保保留所需数据。与去重合并引擎相比,它生成的变更日志只有插入操作,简化了数据变更的记录方式。
序列字段(sequence.field):在数据处理过程中,序列字段常用于标识数据的顺序或版本等信息。在首行合并引擎中不允许指定序列字段,这是因为该引擎的设计初衷就是简单地保留首条记录,序列字段可能会引入额外的复杂性,与引擎的简洁设计原则不符。
可见性保证(Visibility Guarantee):在数据存储和处理系统中,可见性保证定义了数据何时对查询操作可见。对于使用首行合并引擎的表,L0 级文件在合并后才可见,这是为了确保数据的一致性和完整性。同步合并可以即时保证数据的可见性,但可能会影响写入性能;而异步合并虽然能提高写入性能,但会导致数据可见延迟,用户需要根据实际业务需求权衡选择。在实时性要求较高的业务场景中,可能更倾向于同步合并;而在对写入性能要求较高、对数据可见延迟有一定容忍度的场景中,异步合并可能是更好的选择。
变更日志生产者(Changelog Producer)
流写入能够持续为流读取生成最新的变更。
在创建表时通过指定 changelog-producer 表属性,用户可以选择从表文件中生成变更的模式。
changelog-producer 可能会显著降低合并性能,除非必要,请勿启用它。
无(None)
默认情况下,不会对表的写入器应用额外的变更日志生成器。Paimon 源只能看到跨快照的合并变更,比如哪些键被移除以及某些键的新值是什么。
然而,这些合并变更无法形成完整的变更日志,因为我们无法直接从它们当中读取键的旧值。合并变更要求消费者 “记住” 每个键的值,并且在看不到旧值的情况下重写值。然而,一些消费者需要旧值来确保正确性或提高效率。
考虑一个消费者,它对某些分组键(可能与主键不相等)计算总和。如果消费者只看到新值 5,它无法确定应该将什么值加到求和结果中。例如,如果旧值是 4,它应该将 1 加到结果中。但如果旧值是 6,它反而应该从结果中减去 1。对于这类消费者,旧值很重要。
总而言之,无变更日志生成器最适合像数据库系统这样的消费者。Flink 也有一个内置的 “规范化(normalize)” 算子,它会在状态中持久化每个键的值。可以很容易看出,这个算子成本很高,应该避免使用。(你可以通过 'scan.remove-normalize' 强制移除 “规范化” 算子。)
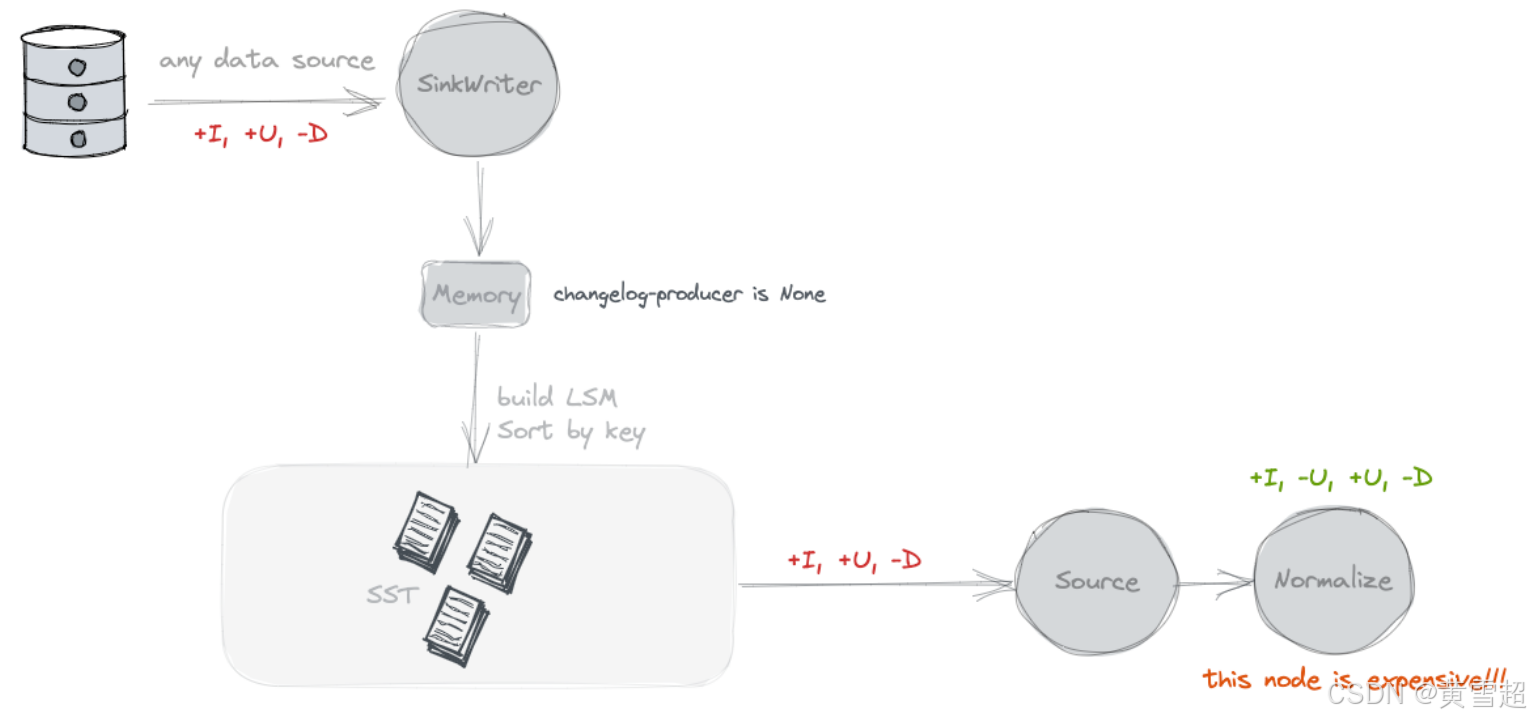
输入(Input)
通过指定 'changelog-producer' = 'input',Paimon 写入器依赖其输入作为完整变更日志的来源。所有输入记录都将保存在单独的变更日志文件中,并由 Paimon 源提供给消费者。
当 Paimon 写入器的输入是完整的变更日志时,可以使用输入变更日志生成器,例如来自数据库变更数据捕获(CDC),或者由 Flink 有状态计算生成的情况。
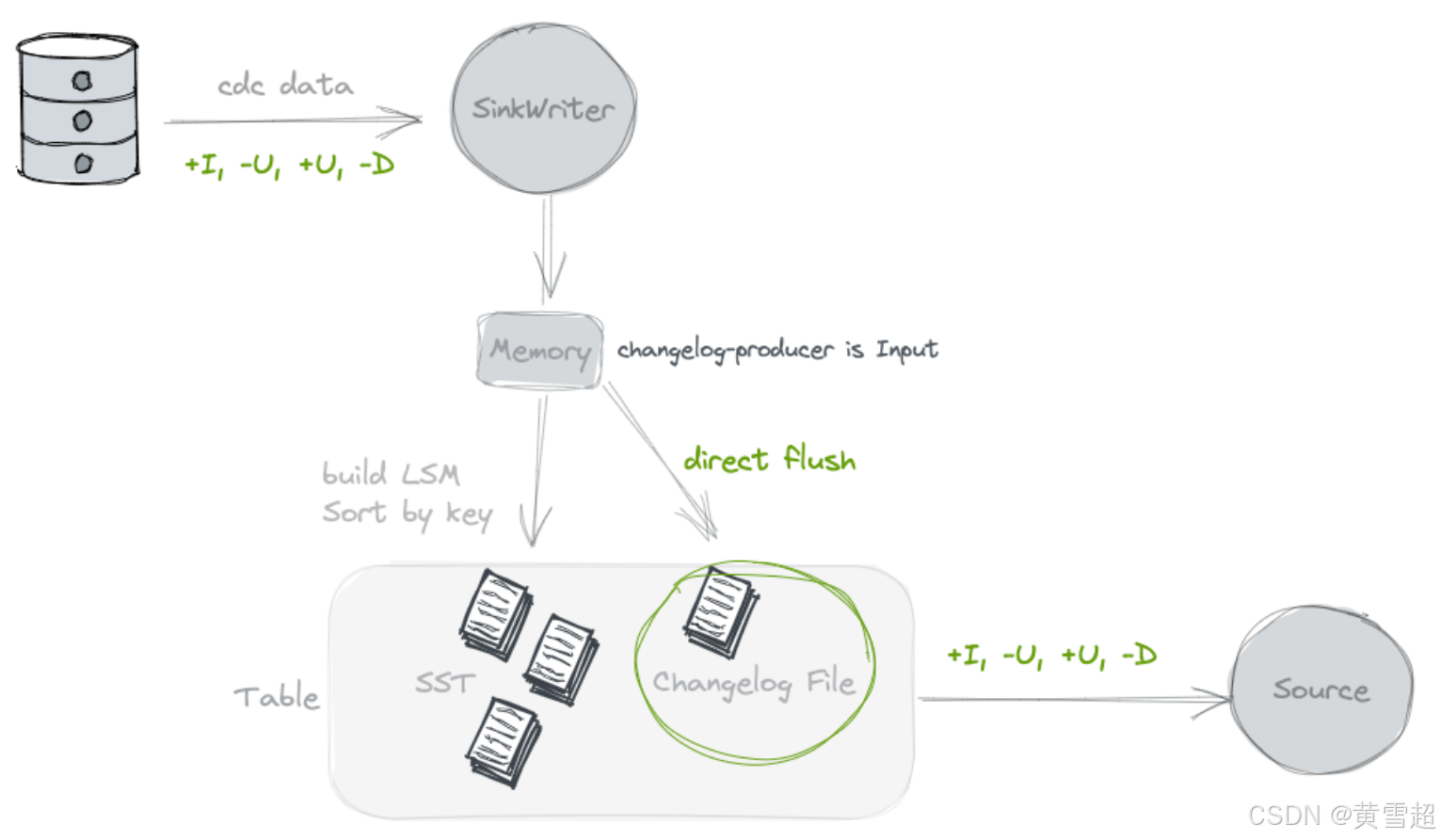
查找(Lookup)
如果你的输入无法生成完整的变更日志,但你仍然希望摆脱成本高昂的规范化算子,你可以考虑使用 lookup 变更日志生成器。
通过指定 'changelog-producer' = 'lookup',Paimon 将在提交数据写入之前通过 “查找” 生成变更日志。
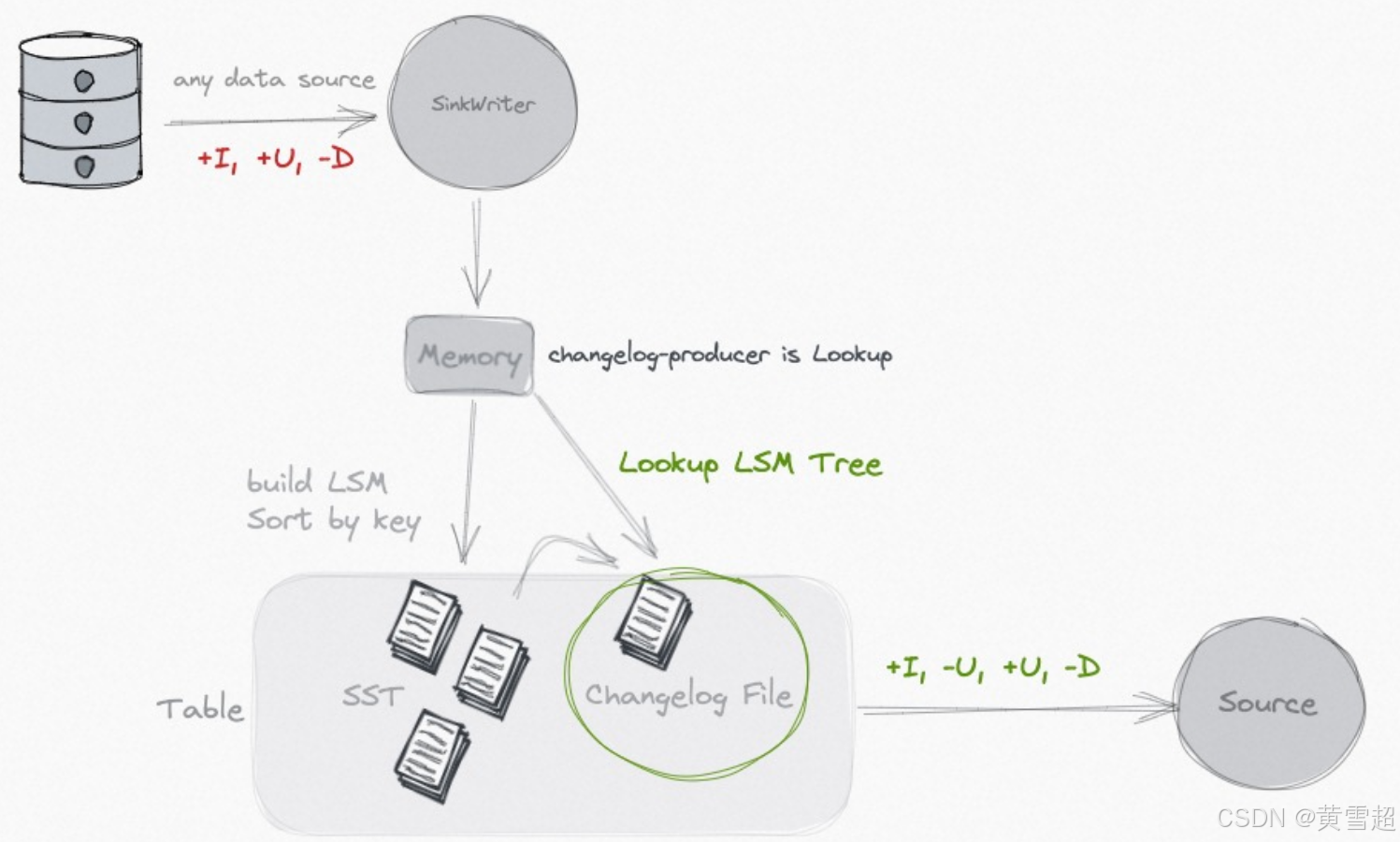
Lookup 会在内存和本地磁盘上缓存数据,你可以使用以下选项来优化性能:
选项 | 默认值 | 类型 | 描述 |
|---|---|---|---|
lookup.cache-file-retention | 1 小时 | 持续时间 | 查找缓存文件的保留时间。文件过期后,如果需要访问,将从分布式文件系统(DFS)重新读取以在本地磁盘上构建索引。 |
lookup.cache-max-disk-size | 无限制 | 内存大小 | 查找缓存的最大磁盘大小,你可以使用此选项限制本地磁盘的使用。 |
lookup.cache-max-memory-size | 256 mb | 内存大小 | 查找缓存的最大内存大小。 |
查找变更日志生成器支持 changelog-producer.row-deduplicate 以避免为相同记录生成 -U,+U 变更日志。
(注意:请增加 Flink 配置 'execution.checkpointing.max-concurrent-checkpoints',这对性能非常重要。)
完全合并(Full Compaction)
如果你认为 lookup 的资源消耗过大,可以考虑使用 full-compaction 变更日志生成器,它可以解耦数据写入和变更日志生成,更适合高延迟的场景(例如,10 分钟)。
通过指定 'changelog-producer' = 'full-compaction',Paimon 将比较完全合并之间的结果,并将差异作为变更日志生成。变更日志的延迟受完全合并频率的影响。
通过指定 full-compaction.delta-commits 表属性,在增量提交(检查点)后将不断触发完全合并。默认设置为 1,所以每个检查点都会进行一次完全合并并生成一个变更日志。
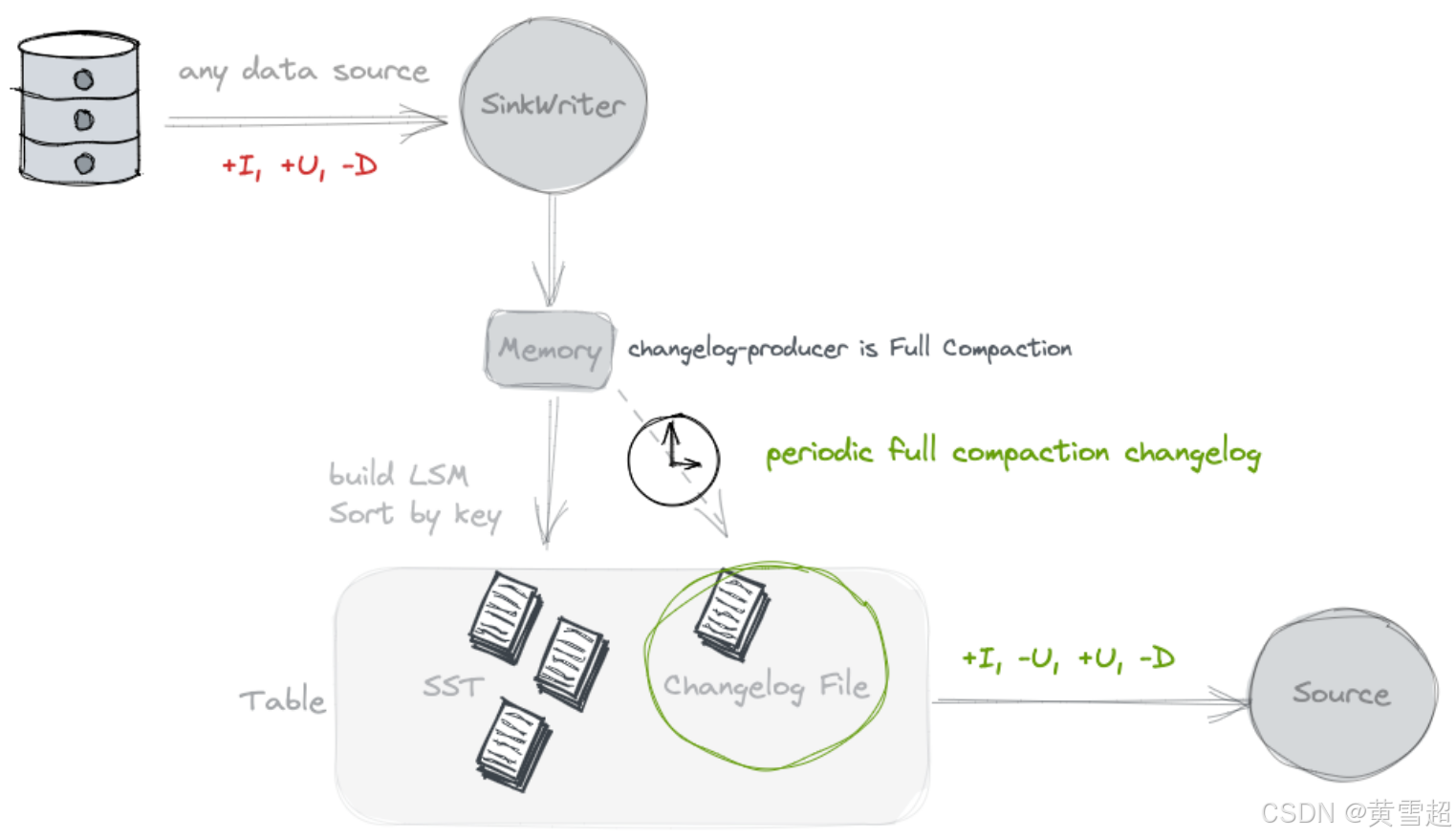
完全合并变更日志生成器可以为任何类型的源生成完整的变更日志。然而,它不像输入变更日志生成器那样高效,并且生成变更日志的延迟可能较高。
完全合并变更日志生成器支持 changelog-producer.row-deduplicate 以避免为相同记录生成 -U,+U 变更日志。
(注意:请增加 Flink 配置 'execution.checkpointing.max-concurrent-checkpoints',这对性能非常重要。)
拓展:
变更日志生成器(Changelog Producer):在数据处理流程中,变更日志生成器负责生成记录数据变更的日志,这些日志对于流读取获取最新数据状态至关重要。不同的生成模式(None、Input、Lookup、Full Compaction)适用于不同的业务场景和数据来源,开发者需要根据实际情况选择,以平衡数据处理的效率、准确性和资源消耗。
规范化算子(Normalize Operator):在Flink中,规范化算子用于在没有完整变更日志旧值的情况下,通过在状态中持久化每个键的值来处理合并变更。然而,这种方式资源消耗较大,在使用
None变更日志生成器模式时,为了避免其高成本,可以通过'scan.remove-normalize'强制移除。这体现了在数据处理中需要根据具体需求权衡不同组件的使用。Lookup:
Lookup变更日志生成器通过在内存和本地磁盘缓存数据,在写入前通过查找生成完整变更日志。合理配置其相关缓存参数(如lookup.cache-file-retention、lookup.cache-max-disk-size、lookup.cache-max-memory-size)对于优化性能很关键,同时注意配合调整Flink的'execution.checkpointing.max-concurrent-checkpoints'配置。完全合并(Full Compaction):适用于对延迟有一定容忍度且希望解耦数据写入和变更日志生成的场景。通过比较完全合并结果生成变更日志,虽然能为各种数据源生成完整日志,但效率相对较低且延迟较高。同样,使用时需关注相关配置及对Flink配置的调整以提升性能。
序列与行类型(Sequence and Rowkind)
创建表时,你可以通过指定字段来指定'sequence.field'以确定更新顺序,或者指定'rowkind.field'来确定记录的变更日志类型。
序列字段(Sequence Field)
默认情况下,主键表根据输入顺序确定合并顺序(最后输入的记录将最后合并)。然而,在分布式计算中,会出现一些导致数据无序的情况。此时,你可以使用一个时间字段作为序列字段,例如:
Flink:
CREATE TABLE my_table (pk BIGINT PRIMARY KEY NOT ENFORCED,v1 DOUBLE,v2 BIGINT,update_time TIMESTAMP
) WITH ('sequence.field' = 'update_time'
);序列字段值最大的记录将最后合并,如果值相同,则使用输入顺序来确定哪条记录最后合并。序列字段支持所有数据类型的字段。
你可以为序列字段定义多个字段,例如'update_time,flag',多个字段将按顺序进行比较。
用户定义的序列字段与诸如first_row和first_value等特性冲突,这可能会导致意外结果。
行类型字段(Row Kind Field)
默认情况下,主键表根据输入行确定行类型。你也可以定义'rowkind.field',使用一个字段来提取行类型。
有效的行类型字符串应为'+I'、'-U'、'+U'或'-D'。
拓展:
序列字段(Sequence Field):在分布式数据处理场景中,由于网络延迟、并行计算等因素,数据到达的顺序可能与实际期望的处理顺序不一致。通过指定序列字段,可以明确数据的合并顺序,确保数据处理结果的准确性。例如在一个实时订单处理系统中,订单数据可能会因为网络波动而无序到达,使用订单的更新时间作为序列字段,就可以保证按照时间先后顺序处理订单数据,避免数据更新错误。
行类型字段(Row Kind Field):在数据变更日志中,不同的行类型(
+I表示插入,-U表示删除更新前数据,+U表示更新,'-D'表示删除)用于准确记录数据的变化情况。通过定义行类型字段,可以从数据记录中提取这些变更类型信息,方便下游数据处理逻辑根据不同的变更类型进行相应操作。例如在数据同步过程中,接收方可以根据行类型字段确定是进行插入、更新还是删除操作,保证数据的一致性。特性冲突(Feature Conflict):用户定义的序列字段与
first_row、first_value等特性冲突,这是因为first_row、first_value等特性已经有其固定的逻辑来确定数据的处理方式,而序列字段的引入改变了数据的默认处理顺序,可能导致这些特性无法按预期工作。在实际应用中,开发者需要注意这些特性之间的相互影响,根据业务需求合理选择和配置相关参数,以避免出现意外结果。
合并(Compaction)
当越来越多的记录写入日志结构合并树(LSM tree)时,有序段(sorted runs)的数量会增加。由于查询LSM树需要合并所有的有序段,过多的有序段会导致查询性能变差,甚至出现内存溢出。
为了限制有序段的数量,我们需要时不时地将几个有序段合并成一个大的有序段。这个过程就称为合并。
然而,合并是一个资源密集型的过程,会消耗一定的CPU时间和磁盘I/O,所以过于频繁的合并反而可能导致写入速度变慢。这是查询性能和写入性能之间的一种权衡。Paimon目前采用了类似于Rocksdb通用合并的策略。
合并解决的问题
减少L0层文件数量,避免查询性能下降。
通过变更日志生成器(changelog-producer)生成变更日志。
为写时合并(MOW)模式生成删除向量。
快照过期、标签过期、分区过期。
限制
同一分区的合并只能有一个作业进行,否则会导致冲突,一方会抛出异常失败。
写入性能几乎总是会受到合并的影响,因此对其进行调优至关重要。
异步合并(Asynchronous Compaction)
合并本质上是异步的,但如果你希望它完全异步且不阻塞写入,期望一种能获得最大写入吞吐量的模式,合并可以缓慢且不急于完成。你可以为你的表使用以下策略:
num-sorted-run.stop-trigger = 2147483647
sort-spill-threshold = 10
lookup-wait = false
这种配置会在写入高峰期生成更多文件,并在写入低谷期逐渐合并以达到最佳读取性能。
专用合并作业(Dedicated compaction job)
一般来说,如果你期望多个作业写入同一个表,就需要分离合并操作。你可以使用专用合并作业。
记录级过期(Record-Level expire)
在合并过程中,你可以配置记录级过期时间来使记录过期,你应该配置:
'record-level.expire-time':记录保留的时间。'record-level.time-field':记录级过期的时间字段。'record-level.time-field-type':记录级过期的时间字段类型,可以是seconds-int(秒为单位的整数)或millis-long(毫秒为单位的长整型)。
过期操作在合并时发生,并不能强有力地保证记录及时过期。
完全合并(Full Compaction)
Paimon合并使用通用合并(Universal-Compaction)。默认情况下,当增量数据过多时,会自动执行完全合并。通常你不必为此担心。
Paimon还提供了一些配置,允许定期执行完全合并:
‘compaction.optimization-interval’:表示每隔多久执行一次优化型完全合并,此配置用于确保读优化系统表的查询及时性。‘full-compaction.delta-commits’:增量提交(delta commits)后会不断触发完全合并。其缺点是只能同步执行合并,这会影响写入效率。
合并选项(Compaction Options)
暂停写入的有序段数量(Number of Sorted Runs to Pause Writing)
当有序段数量较少时,Paimon写入器会在单独的线程中异步执行合并,这样记录可以持续写入表中。然而,为了避免有序段无限制增长,当有序段数量达到阈值时,写入器会暂停写入。以下表属性决定这个阈值:
选项 | 是否必需 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
num-sorted-run.stop-trigger | 否 | (none) | Integer | 触发停止写入的有序段数量,默认值是 |
num-sorted-run.stop-trigger的值越大,写入暂停的频率就越低,从而提高写入性能。但是,如果这个值太大,查询表时将需要更多的内存和CPU时间。如果你担心内存溢出(OOM)问题,请配置以下选项。其值取决于你的内存大小。
选项 | 是否必需 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
sort-spill-threshold | 否 | (none) | Integer | 如果排序读取器的最大数量超过此值,将尝试进行溢出操作。这可以防止过多的读取器消耗过多内存导致OOM。 |
触发合并的有序段数量(Number of Sorted Runs to Trigger Compaction)
Paimon使用的LSM树支持大量更新操作。LSM将文件组织成多个有序段。从LSM树查询记录时,必须合并所有有序段才能生成所有记录的完整视图。
很容易看出,过多的有序段会导致查询性能不佳。为了将有序段数量保持在合理范围内,Paimon写入器会自动执行合并。以下表属性决定触发合并的最小有序段数量:
选项 | 是否必需 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
num-sorted-run.compaction-trigger | 否 | 5 | Integer | 触发合并的有序段数量。包括L0层文件(一个文件一个有序段)和高层有序段(一层一个有序段)。 |
num-sorted-run.compaction-trigger的值越大,合并频率就越低,从而提高写入性能。但是,如果这个值太大,查询表时将需要更多的内存和CPU时间。这是写入性能和查询性能之间的一种权衡。
拓展:
日志结构合并树(LSM Tree)与合并(Compaction):LSM树是一种适合高写入负载的存储结构,通过将写入操作先记录在日志中,然后定期合并成更大的有序段来优化存储。合并在这个过程中起着关键作用,它不仅能控制有序段数量以提升查询性能,还负责处理数据过期、生成变更日志等重要任务。例如,在一个大规模的日志数据存储系统中,随着日志数据不断写入LSM树,合并操作可以定期清理过期的日志记录,同时合并小的有序段,使得查询特定时间段的日志数据时能更高效地进行。
异步合并(Asynchronous Compaction)策略:采用异步合并策略可以在不阻塞写入操作的前提下,逐渐优化数据存储结构以提升读取性能。通过调整
num-sorted-run.stop-trigger、sort-spill-threshold和lookup-wait等参数,系统可以根据业务场景的读写特点进行灵活配置。例如,在一个实时数据写入频繁但对读取实时性要求相对较低的物联网数据采集系统中,适当增大num-sorted-run.stop-trigger的值可以减少写入暂停次数,提高写入吞吐量,而在写入低谷期再进行有序段的合并优化读取性能。专用合并作业(Dedicated Compaction Job):当多个作业同时写入同一个表时,使用专用合并作业可以避免合并操作之间的冲突,确保数据的一致性和系统的稳定性。这在多用户或多模块同时对同一数据集进行操作的复杂应用场景中尤为重要。比如在一个企业级的数据仓库中,不同部门的数据分析任务可能同时向同一个表写入数据,专用合并作业可以保证每个部门的写入操作不受其他部门合并操作的干扰。
记录级过期(Record-Level Expire):在合并过程中配置记录级过期,使得系统可以根据业务需求自动清理过期数据,节省存储空间。通过设置
'record-level.expire-time'、'record-level.time-field'和'record-level.time-field-type'等参数,用户可以灵活控制哪些记录在什么时间过期。例如,在一个存储用户会话信息的系统中,可以设置会话记录在一定时间(如24小时)后过期,以保护用户隐私并减少无用数据的存储。合并选项调优(Compaction Options Tuning):
num-sorted-run.stop-trigger和num-sorted-run.compaction-trigger等合并选项的调整涉及到写入性能和查询性能的平衡。在实际应用中,需要根据系统的硬件资源(如内存大小)和业务需求(如读写频率、数据量等)来合理设置这些参数。例如,对于内存有限且写入操作频繁的系统,适当降低num-sorted-run.stop-trigger的值可以避免因过多有序段导致的内存溢出问题,同时合理调整num-sorted-run.compaction-trigger的值以确保查询性能不会受到太大影响。


突破性FPGA仿真算法技术助力Grover搜索,显著提升量子计算仿真效率)



公式解析—仙盟创梦IDE)

,想用别的环境就是用anaconda命令行往anaconda里创建虚拟环境)
)









