25年8月来自武汉大学、阿里达摩院、湖畔研究中心、浙大和清华的论文“Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors”。
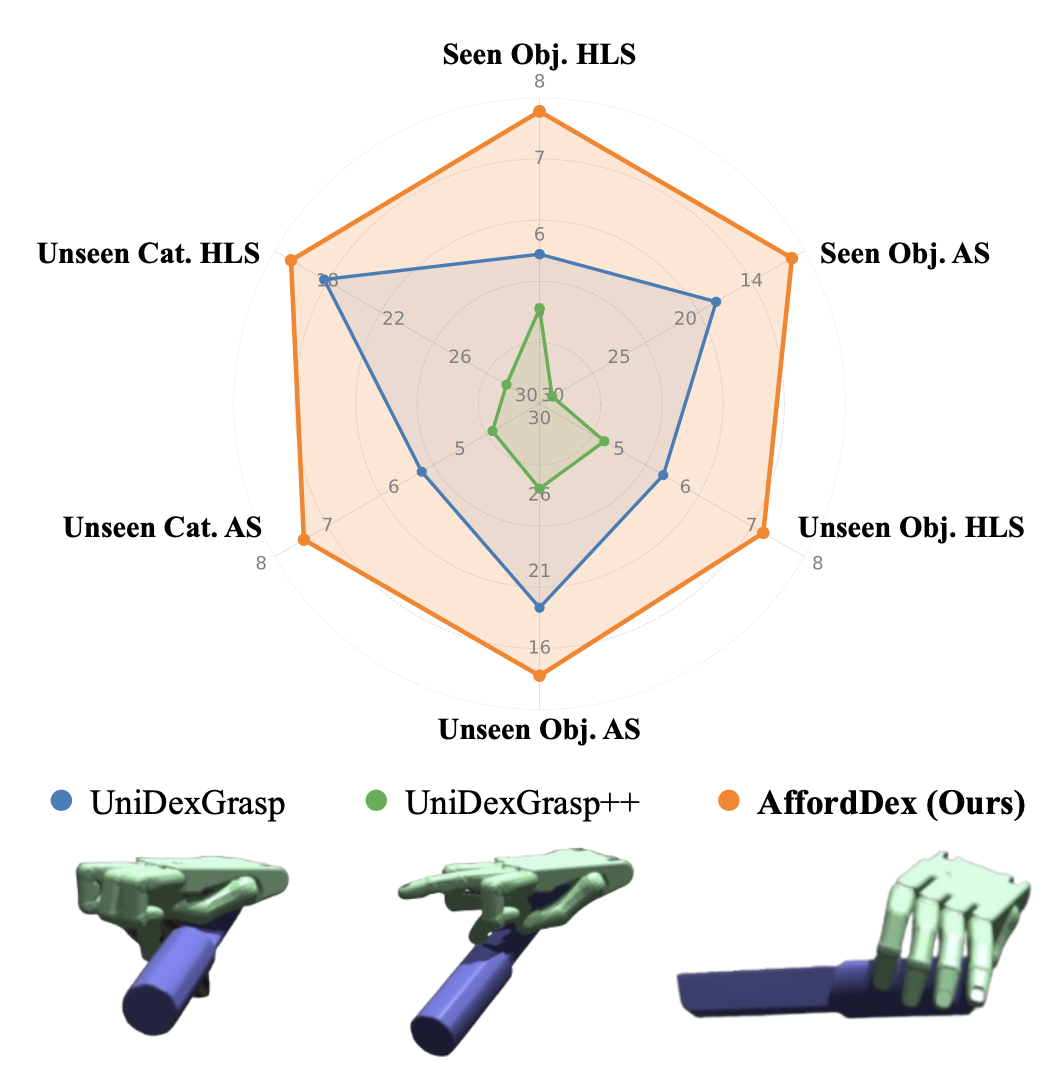
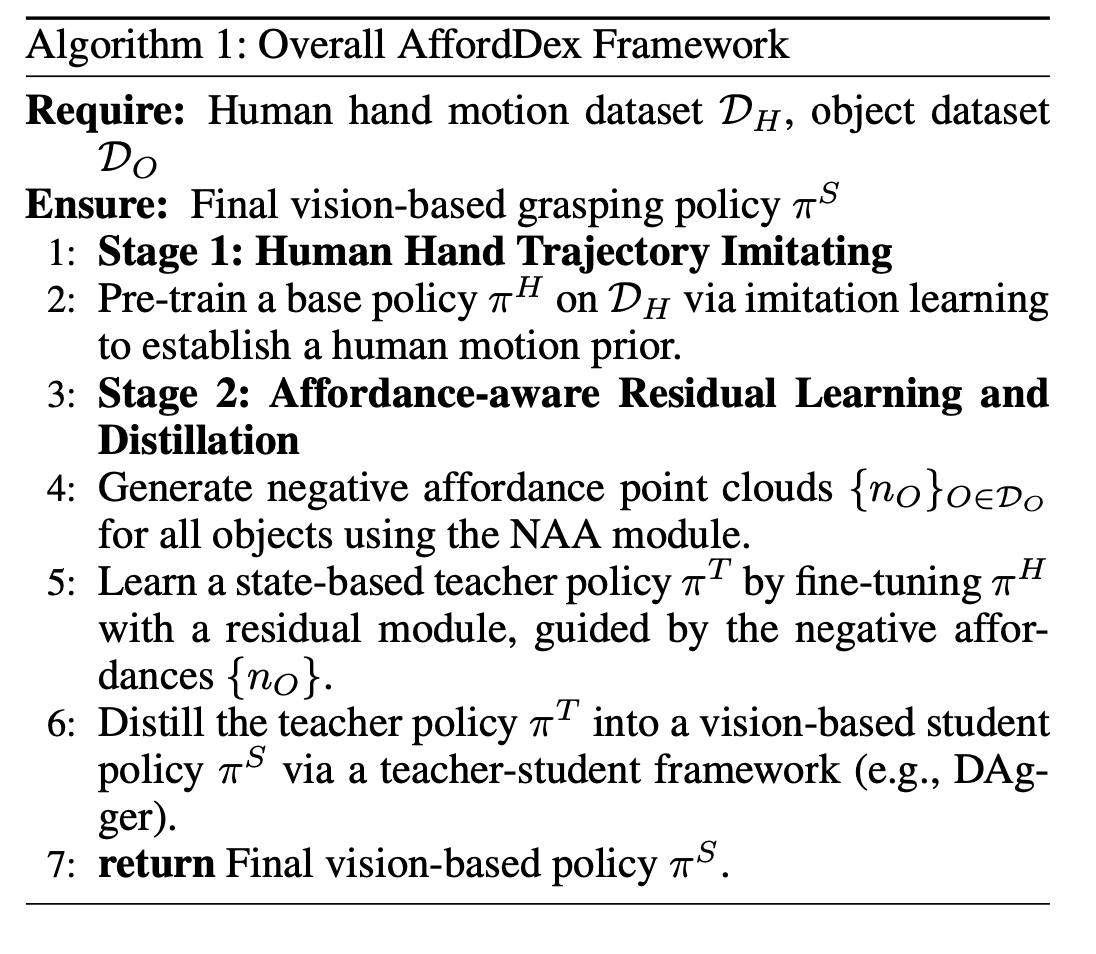
能够泛化抓取目标的灵巧手是开发通用具身人工智能的基础。然而,之前的方法仅仅关注低级抓取稳定性指标,而忽略了affordance-觉察的定位和拟人姿态,而这些对于下游操作至关重要。为了突破这些限制,AffordDex,一个采用两阶段训练的框架,可以学习通用的抓取策略,并固有地理解运动先验和目标 affordance。在第一阶段,轨迹模仿器在大量人类手部动作语料库上进行预训练,以灌输自然运动的强大先验。在第二阶段,训练残差模块,使这些一般的拟人动作适应特定的目标实例。这一改进的关键在于两个组件:负 affordance-觉察分割 (NAA) 模块,用于识别功能上不合适的接触区域;以及一个特别的师-生蒸馏过程,用于确保最终基于视觉的策略高度成功。大量实验表明,AffordDex 不仅实现通用的灵巧抓取,而且在姿势上保持与人类高度相似的抓取姿势,并在接触位置上保持功能上的恰当性。因此,AffordDex 在见过的、未知实例乃至全新类别上的表现均显著超越最先进的基线模型。
灵巧抓取作为机器人操作的基础能力,已引起学术界和工业界的广泛关注 (Zhao et al. 2024b)。与较为简单的末端执行器(例如平行爪、真空夹持器)相比,五指灵巧手的结构与人手结构更加相似,从而显著提高了灵活性、精确度和任务适应性 (Zhong et al. 2025)。此外,拟人机器人通过远程操作加速了丰富的人类演示数据的收集 (Li et al. 2025a)。因此,这种协同效应推动了该领域的快速发展,近期的算法在将抓取泛化至新物体方面取得了很高的成功率 (Fang et al. 2022, 2020; Gou et al. 2021; Wang et al. 2021; Xu et al. 2023; Wan et al. 2023)。
由于灵巧手具有较高的自由度 (DOF),传统的基于运动规划的方法 (Andrews & Kry 2013;Bai & Liu 2014) 难以处理如此复杂的手部关节运动。强化学习 (RL) 的最新进展 (Wan et al. 2023;Mandikal and Grauman 2022;Christen et al. 2022;Nagabandi et al. 2020;Mandikal and Grauman 2021) 已在复杂的灵巧操作中展现出良好的效果。然而,抓取的目标不仅仅是举起一个物体。它涉及与人类意图的一致性,并为后续的操作任务做好准备,例如避开刀刃或准备打开瓶盖。现有方法虽然侧重于低级抓握稳定性指标,但在很大程度上忽略了 affordance-觉察定位与类人运动学之间的关键结合,从而限制了它们在现实世界多步骤操作场景中的实用性。
本文通过建模负 affordance(需要避开的区域)来关注安全性和功能正确性这一关键方面,这些区域提供了清晰明确的负约束,从而简化学习问题。 AffordDex,可以学习一种通用的抓握策略,该策略既具有类人运动能力,又能够感知物体 affordance。其通过一个结构化的两阶段训练范式来实现这一点。在第一阶段,基于大量人类手部动作对基础策略进行预训练,以灌输自然运动的强大先验知识。在第二阶段,训练一个残差模块,使预训练策略中的类人运动适应特定物体。如图所示,AffordDex 生成的抓取动作不仅成功,而且非常类似于人类,功能正确,例如安全地握住刀柄。
为了生成具有 affordance-觉察定位和类人运动的抓取动作(这对于促进下游操作至关重要),提出一个两阶段框架。第一阶段通过在大规模人体运动数据集 (Zhan et al. 2024) 上通过模仿学习预训练基本策略 πH 来建立强大的人体运动先验。这将策略限制为一系列自然的类人运动。在第二阶段,冻结 πH 的权重并通过强化学习 (RL) 训练轻量级残差模块,使这些一般运动适应特定的物体交互。这个 RL 细化阶段主要由两个组件引导:负 affordance-觉察分割 (NAA) 模块,它对物体不能接触的位置提供明确的约束;以及一个师-生蒸馏框架,它利用特别状态信息来显著提升最终策略的性能。如图展示该方法的概述:
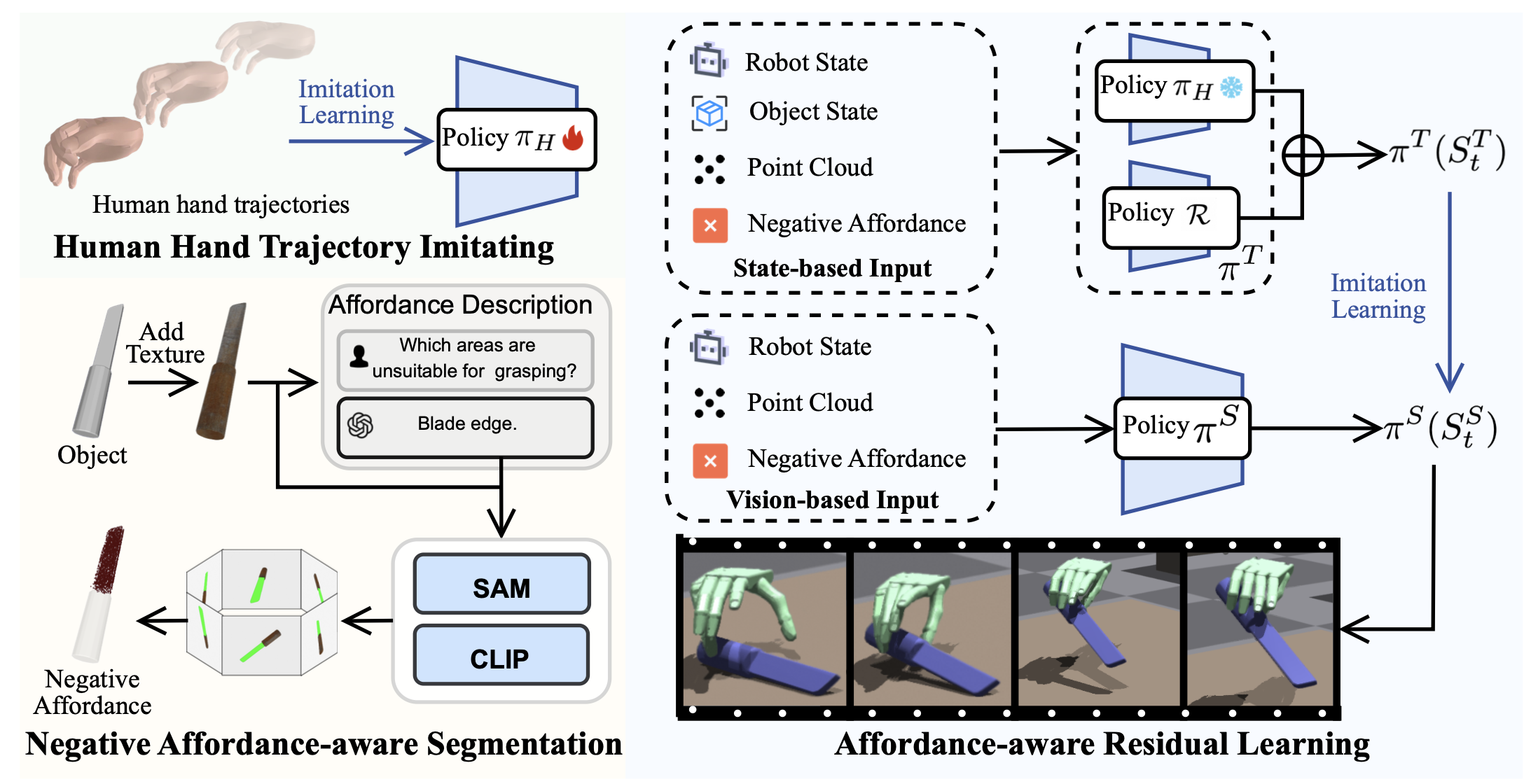
人手轨迹模仿
在此阶段,目标是学习一个基础策略πH,该策略能够捕捉自然人手运动的运动学先验。将此任务表述为一个强化学习 (RL) 问题,其中策略 πH (a_t|SH_t) 学习基于时刻 t 的当前状态 SH_t 生成灵巧的手部动作。为了便于后续的微调阶段,状态由机器人状态 R_t、物体状态 O_t 和物体的点云表示 P_t组成,即SH_t = {R_t, O_t, P_t}。
奖励函数。设计一个奖励函数rH,以促进对人手轨迹的精确模仿和运动稳定性。它由两个项组成:手指模仿奖励 rH_finger 和平滑度奖励 rH_smooth。
手指模仿奖励 rH_finger 鼓励灵巧手紧密跟踪人手数据集中的参考手指姿势。根据 (Li et al. 2025b) 的研究,根据机器人灵巧手和 MANO 手上对应关键点 F 之间的距离来定义此奖励。
平滑度奖励 rH_smooth 通过惩罚过度功耗来鼓励节能运动。它通过关节速度和施加扭矩的元素乘积来计算。
负 affordance-觉察分割
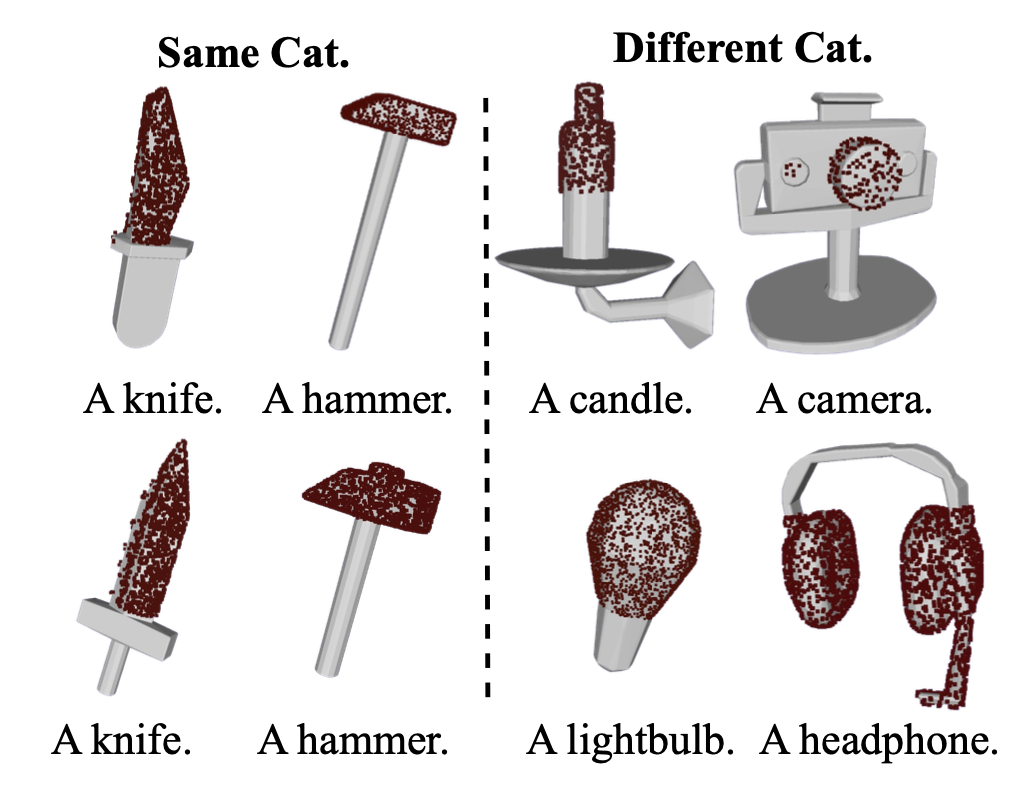
先前研究在抓握合成方面存在一个显著的局限性 (Xu et al. 2023; Wan et al. 2023; Zhong et al. 2025),即忽略了交互的语义和功能背景。一个典型的例子是刀:虽然刀刃在几何上对于抓握来说是稳定的,但任何这样的抓握在功能上都是不正确且不安全的。为了解决这一局限性,引入负 affordance-觉察分割 (NAA) 模块,以融入负 affordance——推理物体的哪些部分不应该被触碰。提出的 NAA 能够利用视觉-语言模型 (VLM) 中丰富的世界知识 (Radford et al. 2021; Achiam et al. 2023),以开放词汇的方式进行操作,并自动受益于未来基础模型的进展。这确保了生成的抓取不仅在几何上稳定,而且在语义上连贯且具有任务感知能力。
VLM 难以解释无纹理的 3D 网格,因为这些模型主要依赖于从图像中学习的丰富视觉线索。为了弥补这一缺陷,首先对原始网格应用程序化纹理 (Zhang et al. 2024c),该方法基于几何分析生成语义上合理的纹理,确保在不同物体形状上的鲁棒性。接下来,从六个基本方向渲染带纹理的物体,以创建多视图图像集 I 作为整体视觉表示。虽然这可能无法捕捉高度复杂物体的所有凹面,但它为基准数据集中物体的 affordance 预测提供了充分的基础,体现了覆盖范围和计算成本之间的实际权衡。然后,本文查询 GPT-4V (Achiam et al. 2023) 以引出物体 affordance 的详细描述。
视觉-语言模型 (VLM) (Radford,2021) 和多模态大语言模型 (MLLM) (Achiam,2023) 在图像级理解方面表现出色,但在分割所需的细粒度空间定位方面却举步维艰。为了解决这个问题,不再要求 CLIP (Radford,2021) 从图像中找出“叶片部件”,而是将分割任务转变为一个简单得多的分类任务。生成一组精确的物体-部件掩码 M_i,并将它们用作视觉提示,让 CLIP 识别 M_i 中哪个掩码与文本描述“叶片部件”的语义相似度最高。具体来说,对于每幅图像 I_i ∈ I,提示“SAM”(Kirillov,2023),在 I_i 上叠加一个密集的点网格 G,这会提示 SAM 执行详尽的分割,识别所有潜在的物体和部件。然后使用非最大抑制 (NMS) 对得到的掩码集合进行细化,以消除重复,从而产生一个干净的候选掩码集 M_i。对于每个掩码 M_ij ∈ M_i,用高斯滤波器模糊掩码外部的区域来生成视觉提示图像 I_ij (Yang et al. 2023)。然后,将提示图像集 {I_ij} 与文本查询一起传递给 CLIP,以计算每个图像-文本对的相似度得分。选择相似度得分最高的掩码作为最终的分割掩码。然后,将掩码投影到 3D 空间中,以分割目标点云的相应区域,从而获得负 affordance N_t,如图所示。
affordance-觉察的残差学习
基于提出的NAA预测负 affordance,用残差模块 R 来改进预训练策略πH。由于视觉姿态估计本质上不如使用特别状态信息精确,直接训练有效的基于视觉的策略可能具有挑战性。因此,首先训练一个基于状态的教师策略πT,它可以访问环境的真实状态(例如物体状态),以学习残差动作来改进πH预测的初始动作。教师策略πT完成训练后,用模仿学习算法DAgger(Ross、Gordon和Bagnell,2011)将 πT 蒸馏为基于视觉的学生策略 πS,该策略可以访问预言机信息,并让策略辅助和简化基于视觉的策略学习。
基于状态的教师策略。在此阶段,输入为机器人状态 R_t、物体状态 O_t、场景点云 P_t 和预测的负 affordance N_t。场景点云由多视角深度摄像头融合。目标是学习残差动作 ∆_a_t = πT (S_tT),并结合 PPO (Schulman et al. 2017) 预测的负affordance。最终,动作通过逐元素加法计算得出。
奖励函数。奖励函数 rT 定义为:rT =−rT_d −rT_g +rT_s −r_n,其中抓握奖励 r_dT 惩罚灵巧手与物体之间的距离,鼓励手保持与物体表面的接触,以实现稳固的抓握。目标奖励 r_gT 惩罚物体与目标之间的距离,成功奖励 rT 在物体成功到达目标时给予奖励。此外,负 affordance 奖励 r_nT 惩罚灵巧手接近预测的负affordance。
基于视觉的学生策略。对于基于视觉的策略,仅允许其访问现实世界中可用的信息,包括机器人状态 R_t、场景点云 P_t 和预测的负 affordance N_t。然后,用 DAgger (Ross, Gordon, and Bagnell 2011) 将教师策略 πT 蒸馏为基于视觉的学生策略 πS。
实验情况如下。
数据集
UniDexGrasp (Xu et al. 2023)。该数据集包含 3165 个不同的物体实例,涵盖 133 个类别。评估基于这 3,200 个可见物体,以及来自见过类别的 140 个未见过物体和来自未见过的 100 个未可见物体。每个环境都随机初始化一个物体及其初始姿态,该环境由固定摄像头捕捉的全景 3D 点云 P_t 组成,用于基于视觉的策略学习。
OakInk2 (Zhan et al. 2024)。该数据集记录人体上半身和物体的姿态和形状的操作过程。用其中约 2,200 个右手操作序列对 πT 进行预训练。还使用 OakInk2 中的物体来评估其在抓取方面的泛化能力。
指标
参照前人的研究(Xu et al. 2023; Wan et al. 2023; Wang et al. 2025),每个物体被随机旋转并落到桌面上,以增强其初始姿势的多样性。结果报告所有物体和抓取尝试的抓取成功率 Succ、人像评分 HLS 和 affordance 评分 AS。如果物体在模拟器中 200 步内达到目标,则认为抓取成功。人像评分 HLS 评估抓取的拟人化质量,该质量是通过提示 Gemini 2.5 Pro(Comanici et al. 2025)分析抓取执行的视觉序列获得的。该指标专门用于评估灵巧手运动与典型人类运动的相似性,从而定量衡量自然度。相比之下,affordance 评分 (AS) 通过惩罚与不适当物体部位的接触来评估抓握的功能正确性。该指标使用从 NAA 中采样的 100 个“负 affordance”点云计算得出。具体来说,每指尖与负 affordance 点集中的任何点保持 2 厘米以上的距离,分数就会加 1,从而奖励功能良好的抓握。
实施细节
在 Issac Gym (Makoviychuk,2021) 模拟器中进行实验。训练期间,在 NVIDIA RTX 4090 GPU 上并行模拟 4096 个环境。对于网络架构,在基于状态的设置中使用具有 4 个隐藏层(1024,1024,512,512)的多层感知器 (MLP) 作为策略网络和价值网络;在基于视觉的设置中,用一个额外的 PointNet+Transformer(Mu,2021)来编码 3D 场景点云输入。
灵巧手配置。用 Shadow Hand,它具有 24 个主动自由度 (DOF)。手腕具有 6 个由力和扭矩控制的自由度,而手指具有 18 个由关节角度控制的主动自由度。具体来说,拇指有 5 个 DOF,小指有 4 个,其余三个手指各有 3 个。此外,除拇指外,每个手指都包括一个被动的、不受控制的 DOF。
最后,AffordDex 算法总结如下:

![[光学原理与应用-338]:ZEMAX - Documents\Zemax\Samples](http://pic.xiahunao.cn/[光学原理与应用-338]:ZEMAX - Documents\Zemax\Samples)


:Android安全架构深度剖析 - 从内核到应用的全栈防护)

】系统工程与信息系统基础上:系统工程基础概念)
![[p2p-Magnet] 队列与处理器 | DHT路由表](http://pic.xiahunao.cn/[p2p-Magnet] 队列与处理器 | DHT路由表)











