目录
测试前的准备
驱动
安装驱动管理
selenium库
使用selenium编写代码
自动化测试常用函数
元素的定位
cssSelector
xpath
查找元素
点击/提交对象
模拟按键输入
清除文本内容
获取文本信息
获取当前页面标题和URL
窗口
切换窗口
窗口设置大小
屏幕截图
关闭窗口
弹窗
警告弹窗+确认弹窗
提示弹窗
等待
强制等待
隐式等待
显示等待
浏览器导航
文件上传
浏览器参数设置
自动化的测试的目标是:通过自动化测试有效减少人力的消耗的同时也提高了测试的质量和效 率。
测试前的准备
驱动
web系统的测试前提是需要打开浏览器,通过访问web服务器来对服务器界面进行一系列的操作。对于手工测试来说,这一系列的操作都需要测试人员手动的,一步一步的来执行测试。那么对于自动化程序来说,程序如何才能打开浏览器并执行我们预期的操作流程呢?
驱动一词应用广泛,同学们都不会陌生。车有了驱动才能够让车跑起来。

计算机有了驱动程序就可以与设备(耳机,摄像头,麦克风,键盘,显示器等等设备)进行通信。

程序想要打开web浏览器就需要安装web驱动(即WebDriver),WebDriver 以本地化方式驱动浏览器。
安装驱动管理
若通过安装驱动的方法来启动浏览器,每次浏览器更新后对应的驱动也需要更新,为了解决这个问题,selenium中提供了驱动管理工具webdriver-manager,有了webdriver-manager无需手动安装浏览器驱动,即使浏览器更新也不会影响自动化的执行。
pip install webdriver-manager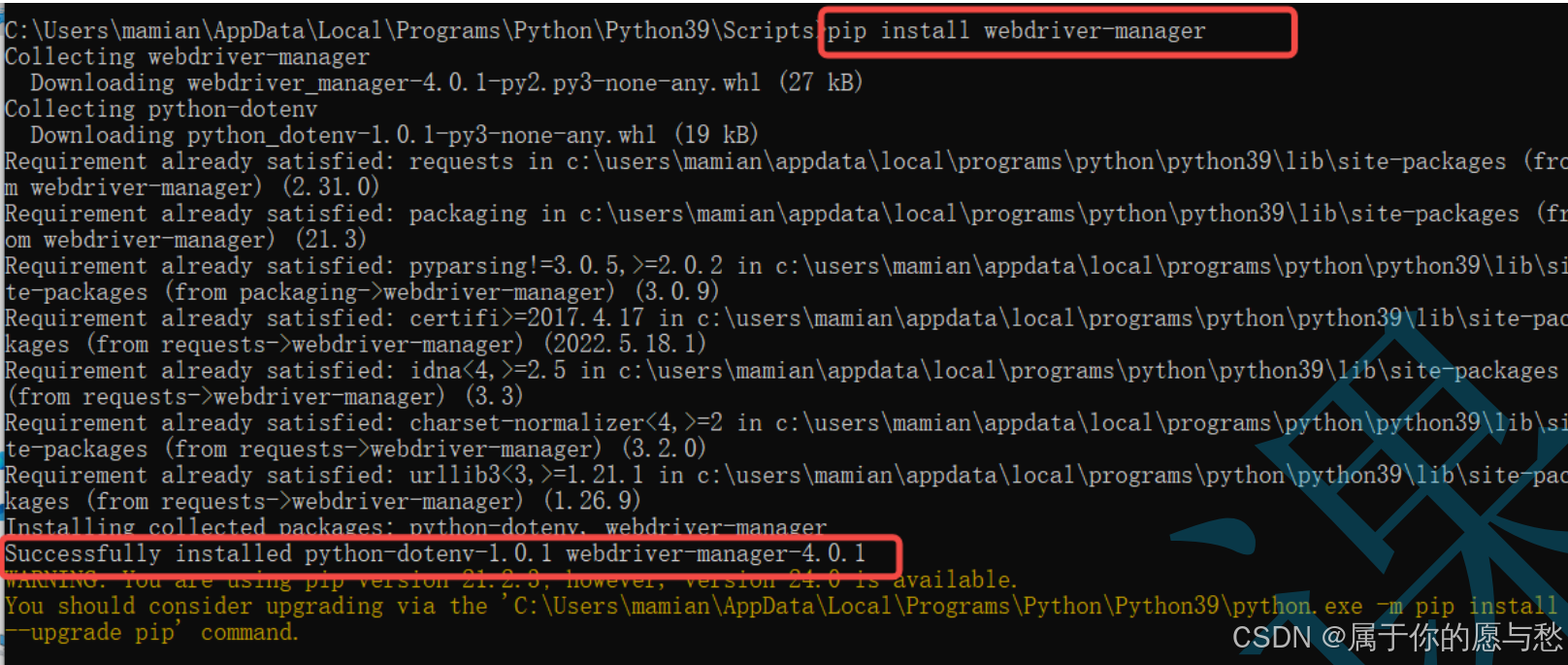
驱动管理:
webdriver-manager支持的python版本为:3.7~3.11
WebDriver Manager是⼀个开源的命令行⼯具,它可以自动下载和安装适用于不同浏览器的
WebDriver。通过使用WebDriver Manager,我们可以确保浏览器驱动版本始终与浏览器版本保持⼀致,从而避免因版本不匹配而导致的各种问题。
selenium库
安装selenium库
selenium版本很多,统⼀使用selenium4.0.0版本
pip install selenium==4.0.0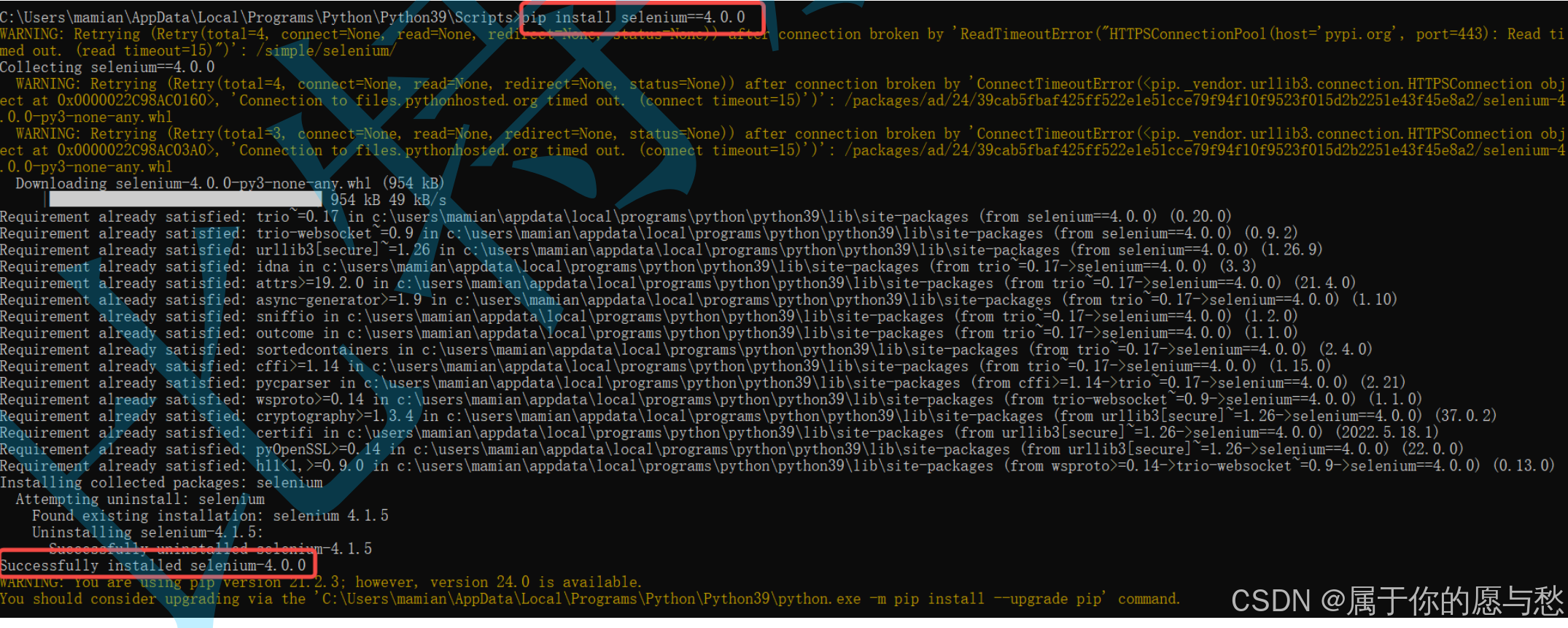
但是我前面说的都是在本地上部署的,也就是在 ctrl+r --> cmd 中输入的内容。但是我们写脚本是在PyCharm中,所以我们还是要把selenium和webdriver-manager安装到PyCharm中。
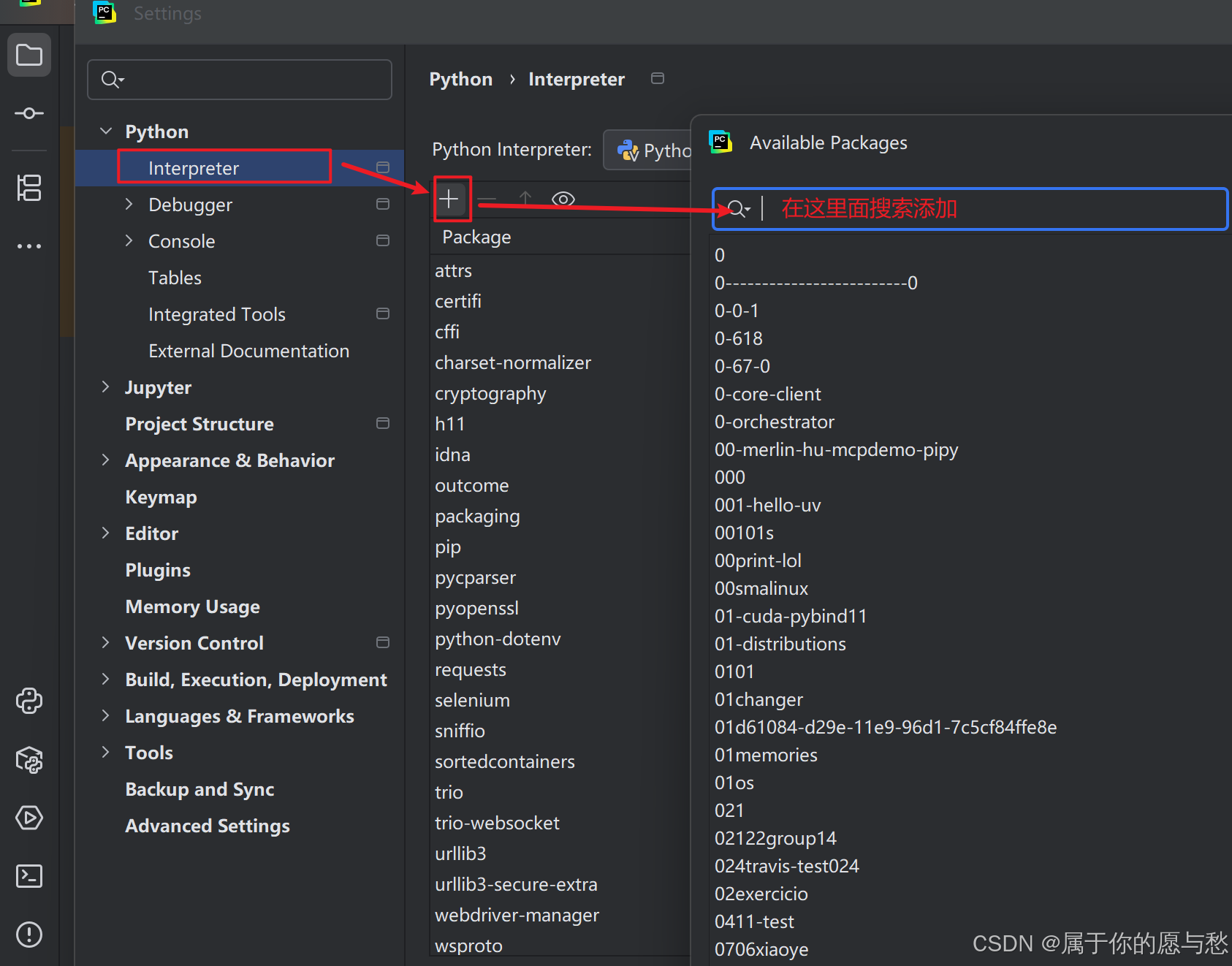
最终需要下面2个内容(版本要一样,这样后面说的自动化测试常见函数在使用过程中才不会有偏差)
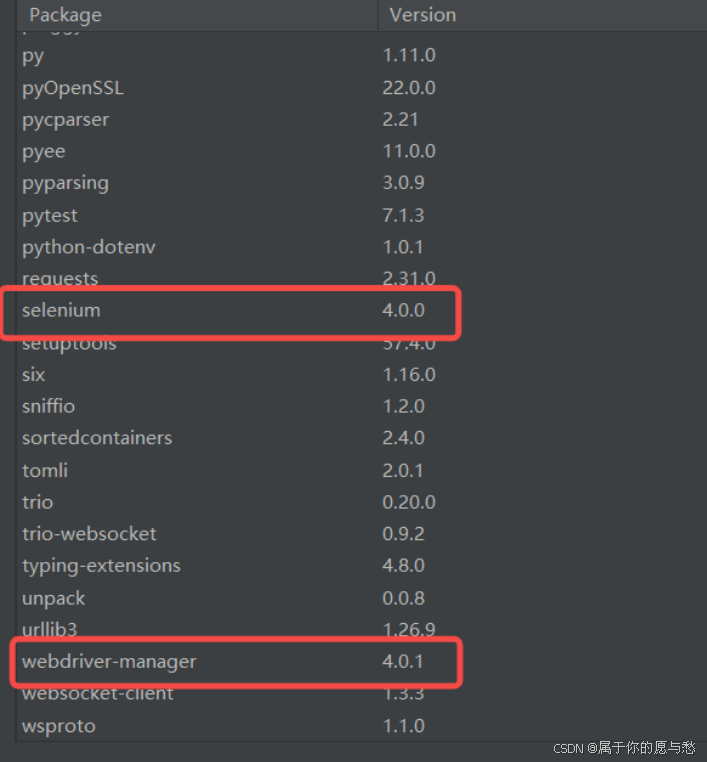
使用selenium编写代码
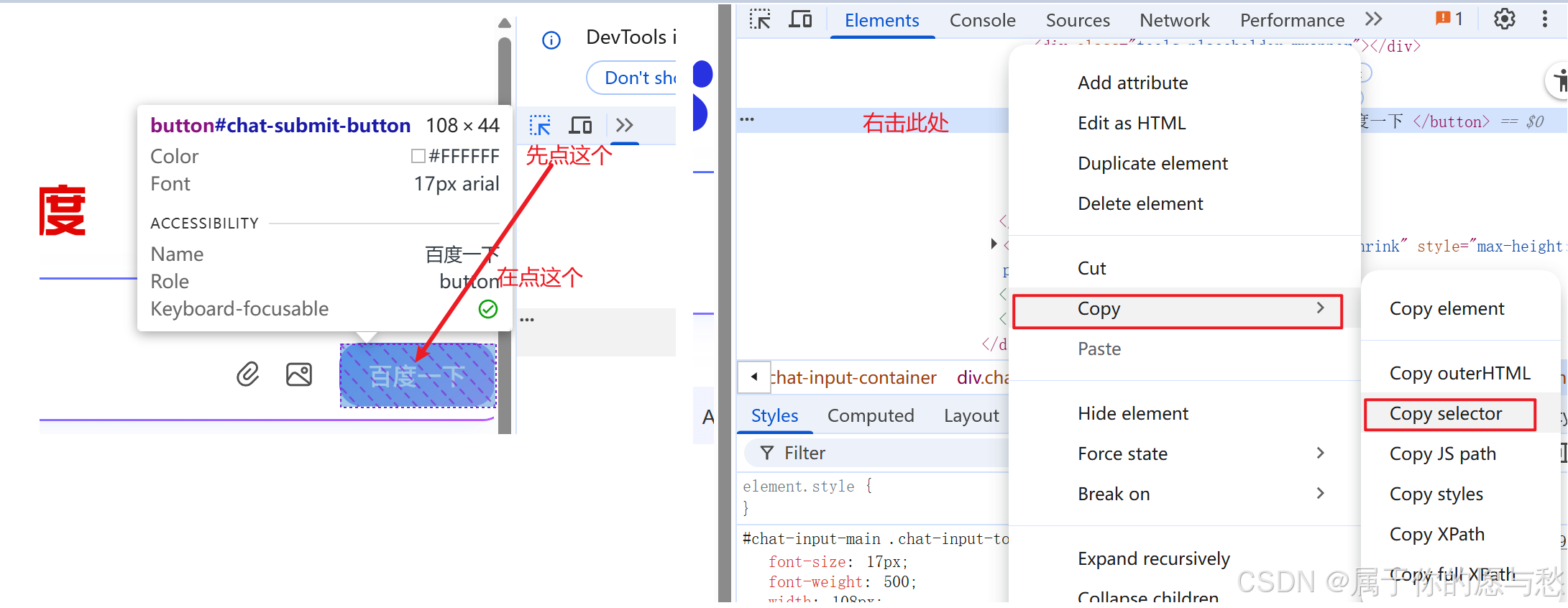
在谷歌浏览器中使用自动化的方式来搜索迪丽热巴
复制方式:选择器
import timefrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager#创建谷歌浏览器驱动
ChormIns=ChromeDriverManager().install()
#创建浏览器对象来调用驱动
driver=webdriver.Chrome(service=Service(ChormIns))
time.sleep(2)
#输入 https://www.baidu.com
driver.get("https://www.baidu.com/")
time.sleep(2)
#在百度输入框中,输入关键词"迪丽热巴" #chat-textarea
driver.find_element(By.CSS_SELECTOR,"#chat-textarea").send_keys("迪丽热巴")
time.sleep(5)
#点击百度一下按钮
element=driver.find_elements(By.CSS_SELECTOR,"#chat-submit-button")
element[1].click()time.sleep(2)
#关闭浏览器
driver.quit()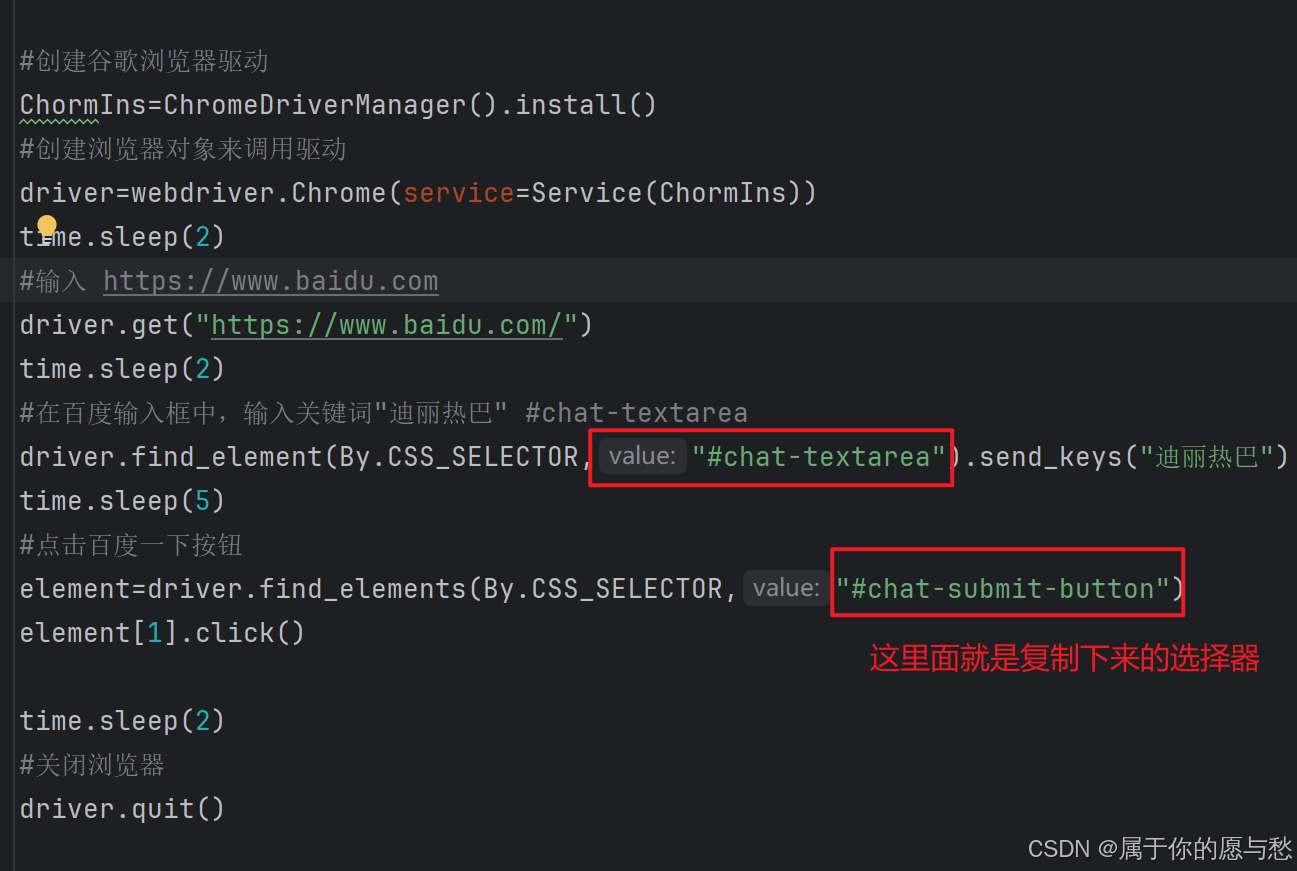
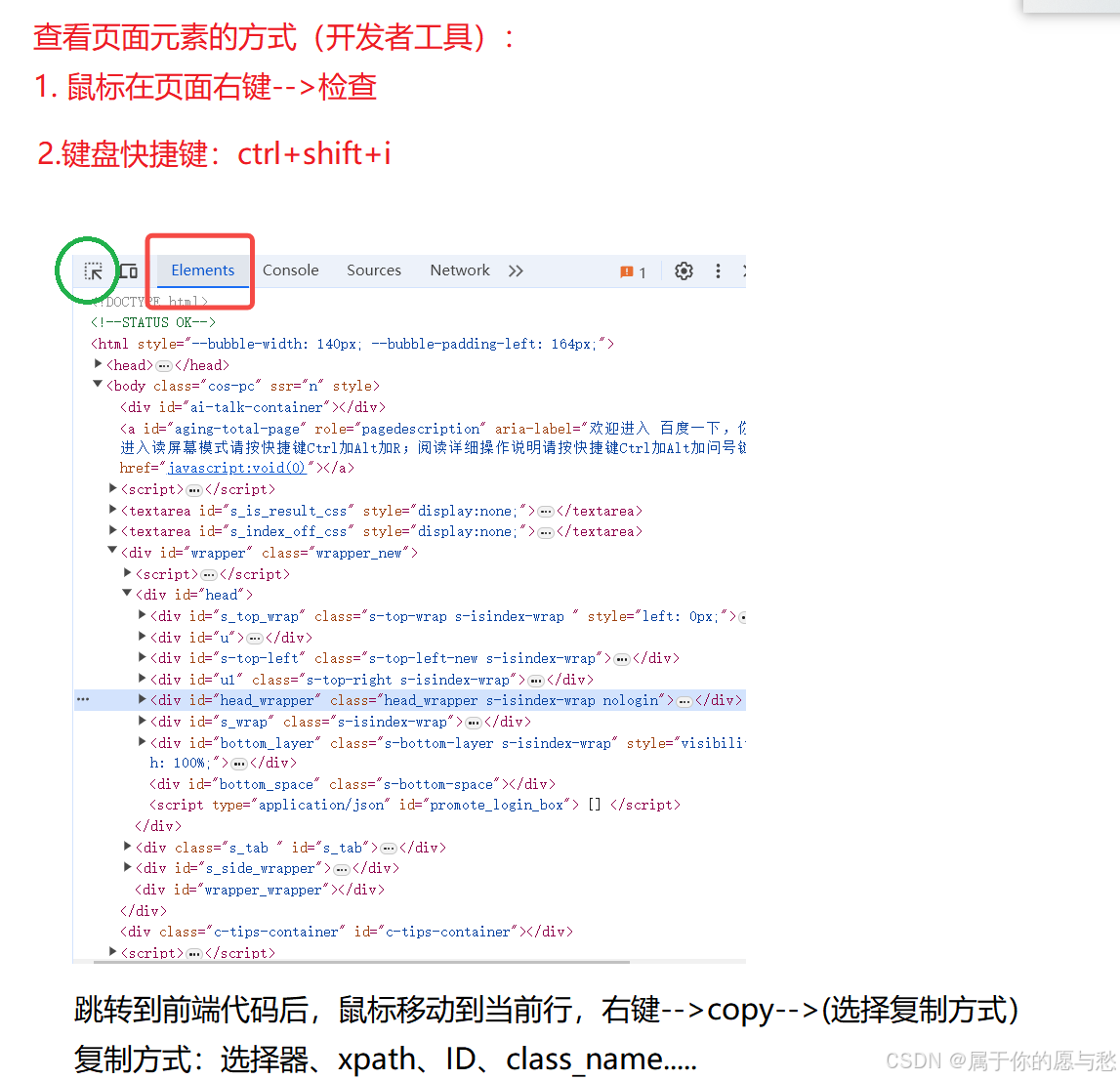
图中的 "#chat-textarea" 是以Copy selector复制下来的元素, selector表达式属于选择器的一种
自动化测试常用函数
元素的定位
web自动化测试的操作核心是能够找到页面对应的元素,然后才能对元素进行具体的操作。常见的元素定位⽅式非常多,如id,classname,tagname,xpath,cssSelector
常用的主要由cssSelector和xpath
cssSelector
选择器的功能:选中页面中指定的标签元素
选择器的种类分为基础选择器和复合选择器,常见的元素定位方式可以通过id选择器和子类选择器来进行定位。
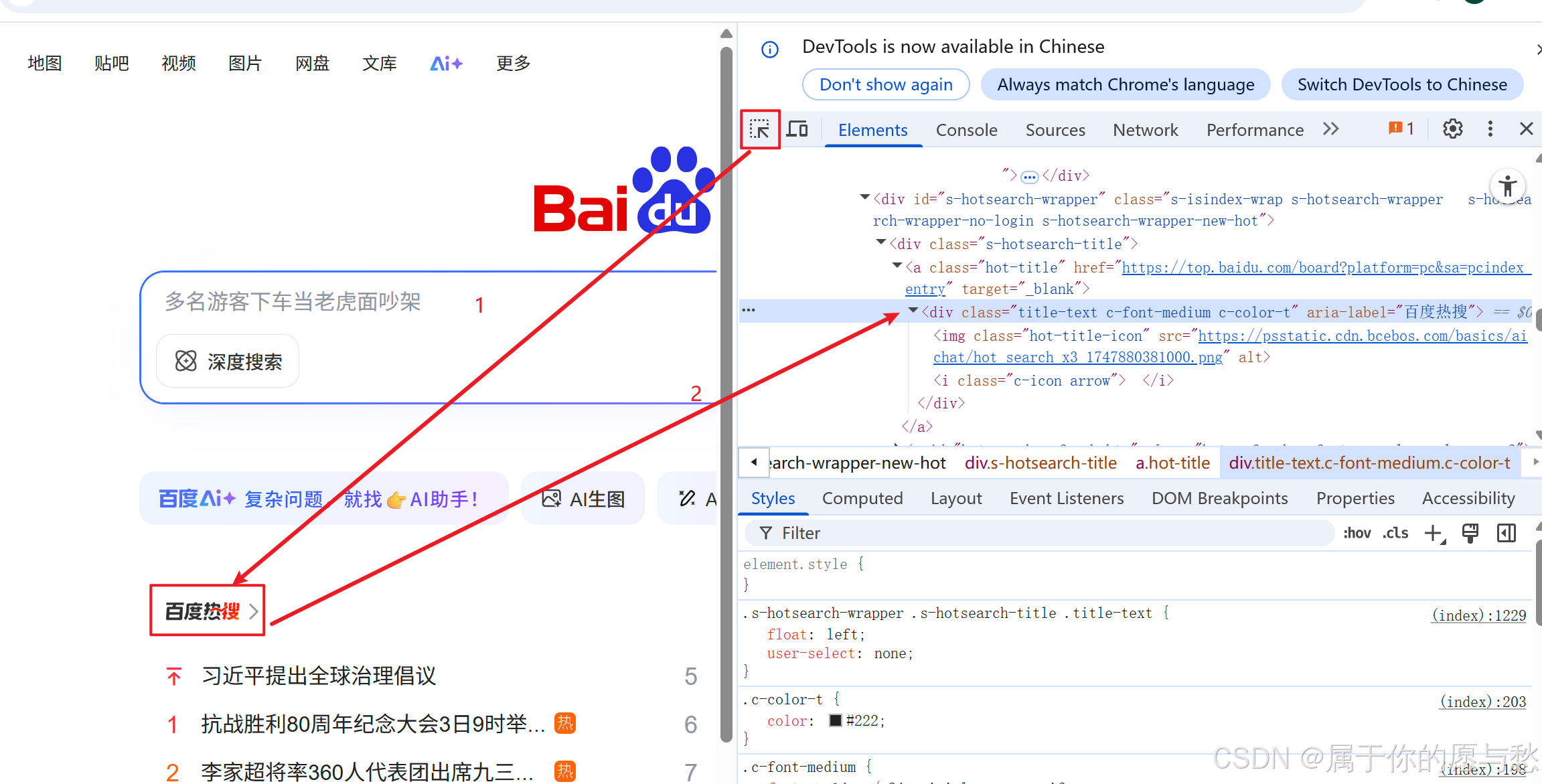
定位百度首页的“百度热搜”元素,可以使用通过id选择器和子类选择器进行定位:
#s-hotsearch-wrapper > div > a.hot-title > div
“搜索输入框元素”
#chat-textarea
“百度一下按钮”:
#chat-submit-button
xpath
XML路径语言,不仅可以在XML文件中查找信息,还可以在HTML中选取节点。
xpath使用路径表达式来选择xml文档中的节点
xpath语法中:
获取HTML页面所有的节点
//*
获取HTML页面指定的节点
//[指定节点]
获取一个节点中的直接子节点
/
例子://span/input
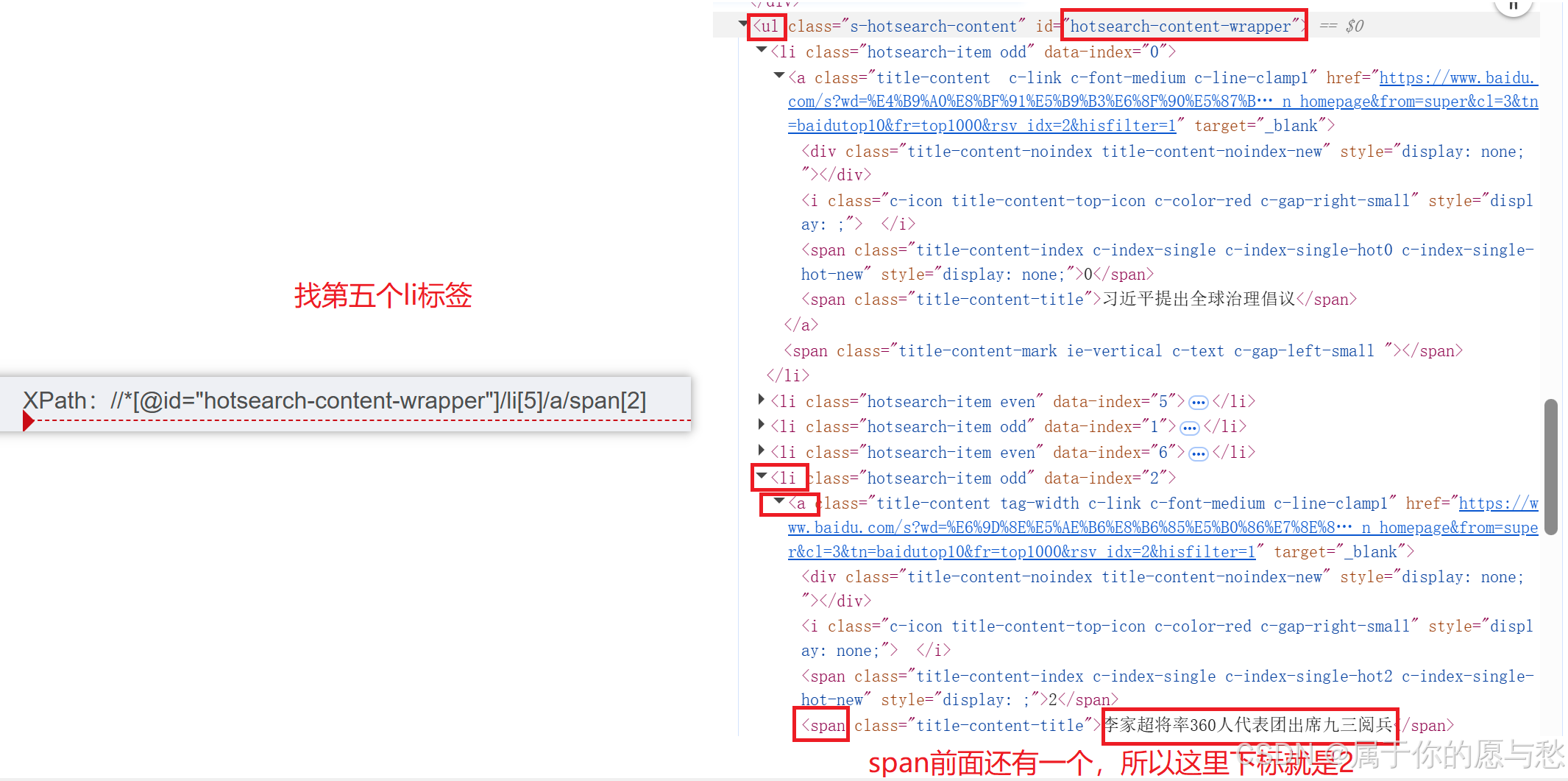
使用指定索引的方式获取对应的节点内容
注意:xpath的索引是从1开始的。
便捷的生成selector/xpath的方式:右键选择复制"Copy selector/xpath"
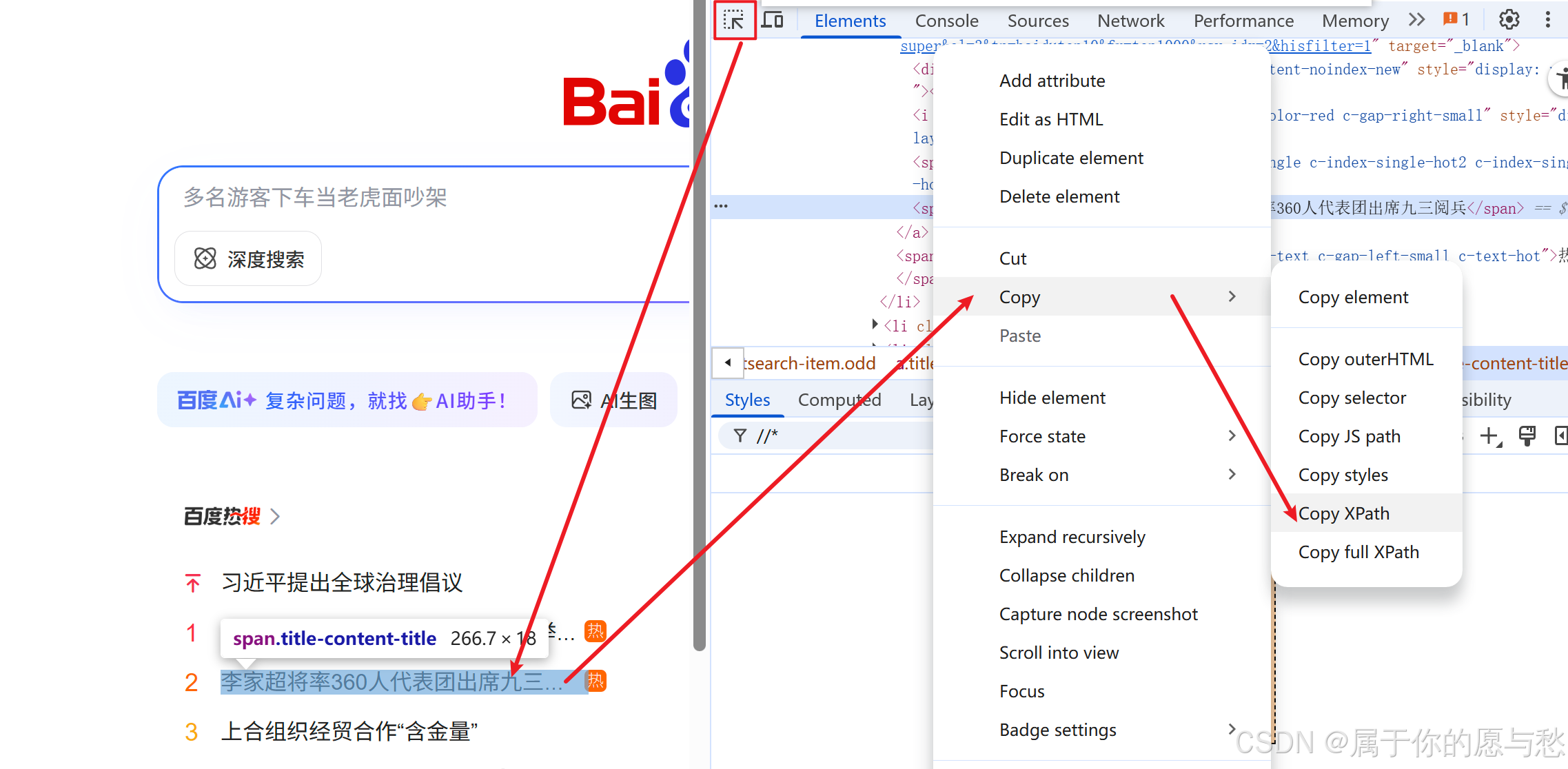
XPath://*[@id="hotsearch-content-wrapper"]/li[5]/a/span[2]
查找元素
find_element
find_element(方式"元素") 这里只能查找一个元素
driver.find_element(By.CSS_SELECTOR,"#chat-textarea").send_keys("迪丽热巴")
这里方式 --> 选择器 查找元素是搜索框(以Copy selector的方式)
find_elements
find_elements(方式"元素") 这里只能查找多个元素

点击/提交对象
click()
# 找到百度一下
element=driver.find_elements(By.CSS_SELECTOR,"#chat-submit-button")
# 点击按钮
element[1].click()模拟按键输入
send_keys("")
模拟键盘输入,因此键盘上可以输入的内容都可以填写上去
# 在百度输入框中,输入关键词"迪丽热巴" #chat-textarea
driver.find_element(By.CSS_SELECTOR,"#chat-textarea").send_keys("迪丽热巴")清除文本内容
连续的send_keys会将多次输入的内容拼接连接在一起,若想重新输入,需要使用清除方法。
所以输入文本后又想换一个新的关键词,这里就需要用到 clear()
#在百度输入框中,输入关键词"迪丽热巴" #chat-textarea
driver.find_element(By.CSS_SELECTOR,"#chat-textarea").send_keys("迪丽热巴")
time.sleep(2)
#首先要先查找到搜索框并清除搜索框中的内容
element=driver.find_elements(By.CSS_SELECTOR,"#chat-textarea")
element[1].clear()
time.sleep(2)
#在在搜索框中输入关键词古力娜扎
driver.find_element(By.CSS_SELECTOR,"#chat-textarea").send_keys("古力娜扎")获取文本信息
如果判断获取到的元素对应的⽂本是否符合预期呢?获取元素对应的文本并打印一下~~
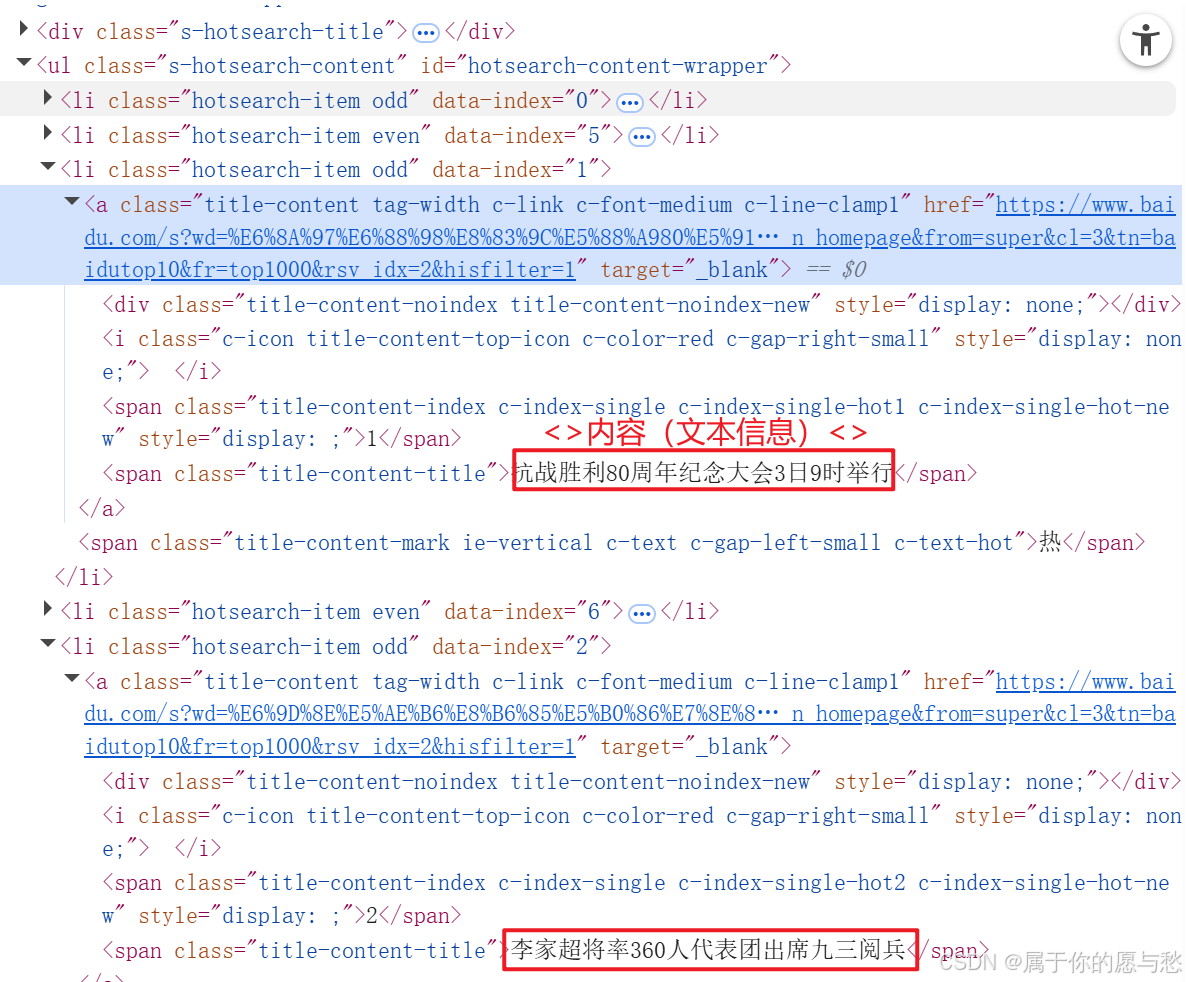
获取文本信息: text
text=driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(5) > a > span.title-content-title").text
print(text)
问题:是否可以通过 text 获取到“百度一下按钮”上的文字“百度一下”呢?尝试一下
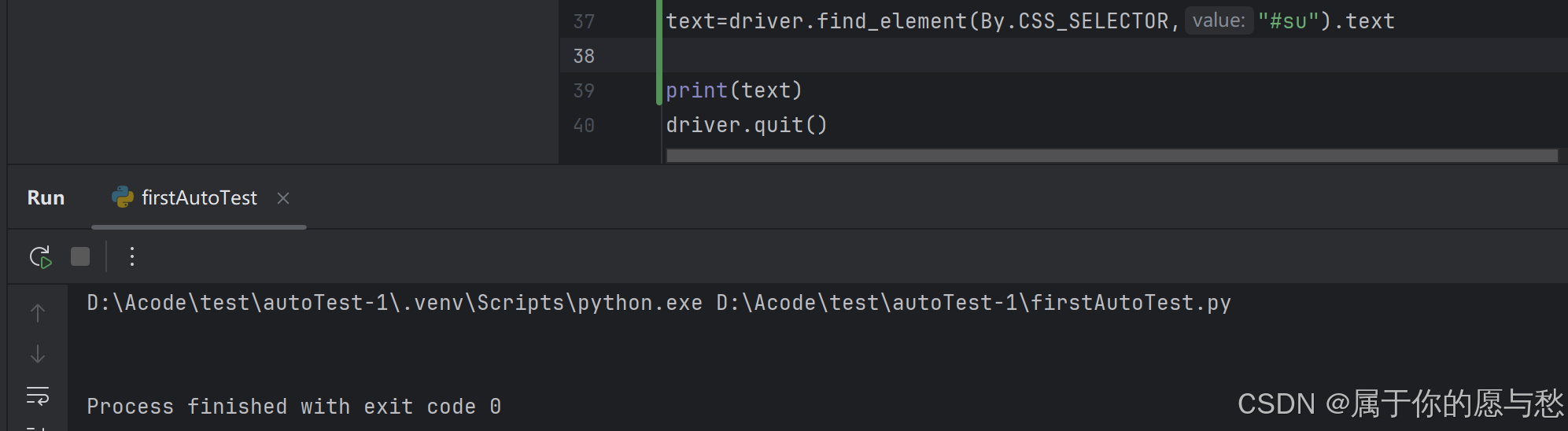
可以看到,这里并没有输出任何内容出来,原因如下

解决方案:get_attribute("属性名称")
text=driver.find_element(By.CSS_SELECTOR,"#su").get_attribute("value")
assert text=="百度一下"
print(text)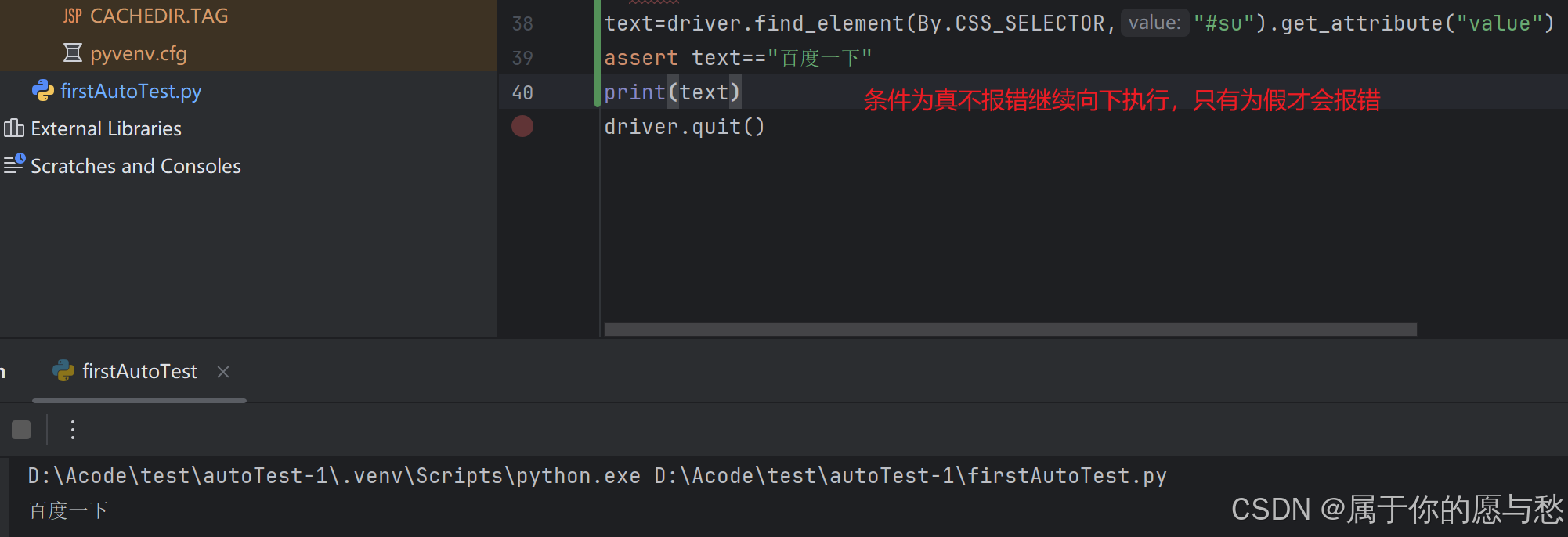
获取当前页面标题和URL
获取当前页面标题:title
获取当前页面URL:current_url
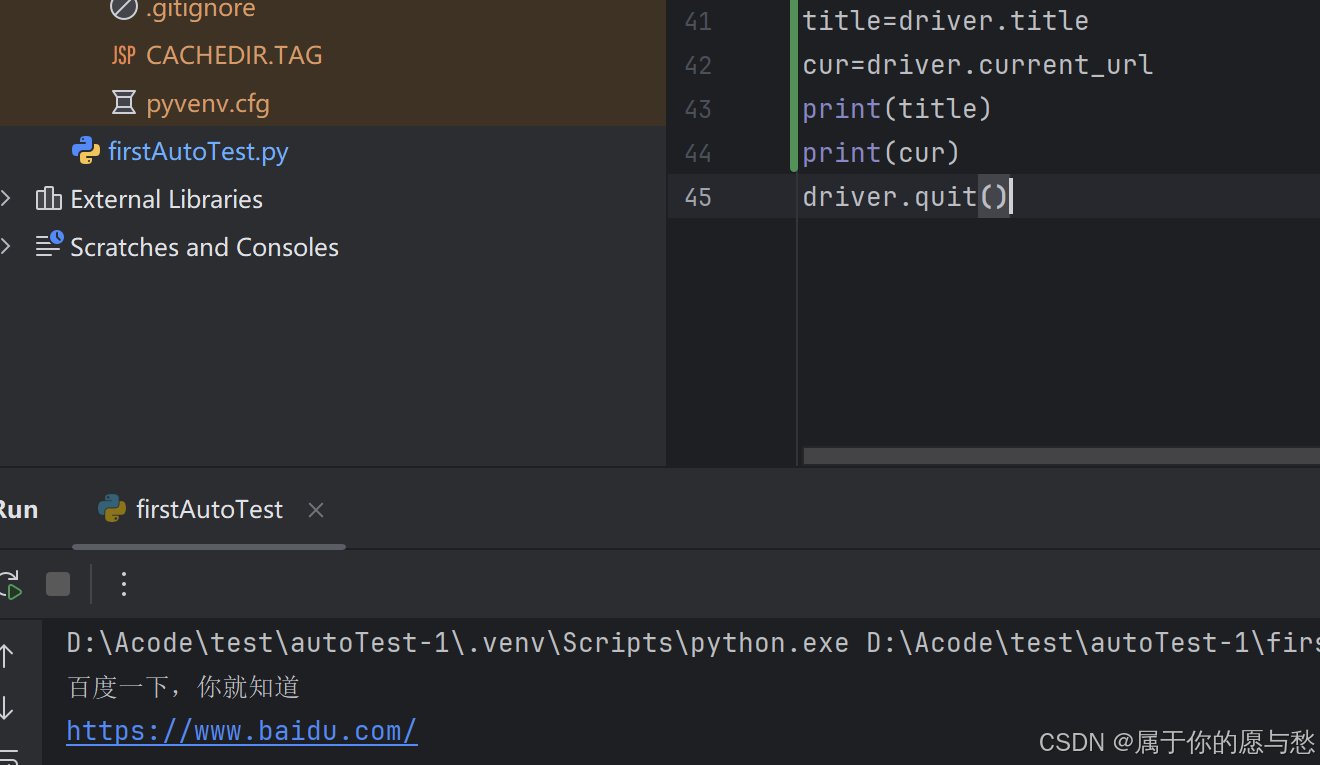
窗口
打开一个新的页面之后获取到的title和URL仍然还是前一个页面的?
当我们手工测试的时候,我们可以通过眼睛来判断当前的窗口是什么,但对于程序来说它是不知道当前最新的窗口应该是哪一个。对于程序来说它怎么来识别每一个窗口呢?每个浏览器窗口都有⼀个唯一的属性句柄(handle)来表示,我们就可以通过句柄来切换
切换窗口
在百度首页点击图片,跳转界面后,我们打印出跳转后的标题和URL观察情况

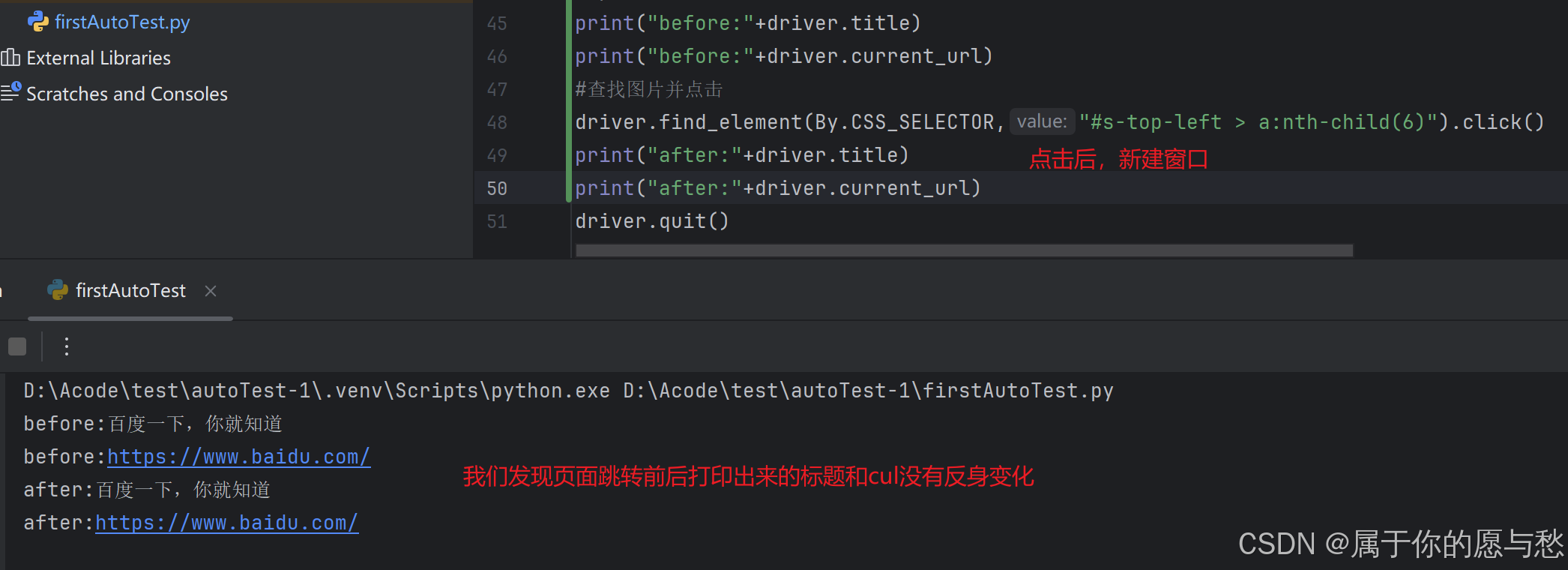
解决方法如下:
预备知识
获取当前页面句柄:driver.current_window_handle
获取所有页面句柄:driver.window_handles
print("before:"+driver.title)
print("before:"+driver.current_url)
#查找图片并点击
driver.find_element(By.CSS_SELECTOR,"#s-top-left > a:nth-child(6)").click()
#获取当前页面的句柄---第一个标签页
curWindow = driver.current_window_handle
#获取所有句柄
allWindows = driver.window_handles
#遍历所有的句柄,切换到新页面
for handle in allWindows:if handle!=curWindow:#切换句柄driver.switch_to.window(handle)
print("after:"+driver.title)
print("after:"+driver.current_url)
driver.quit()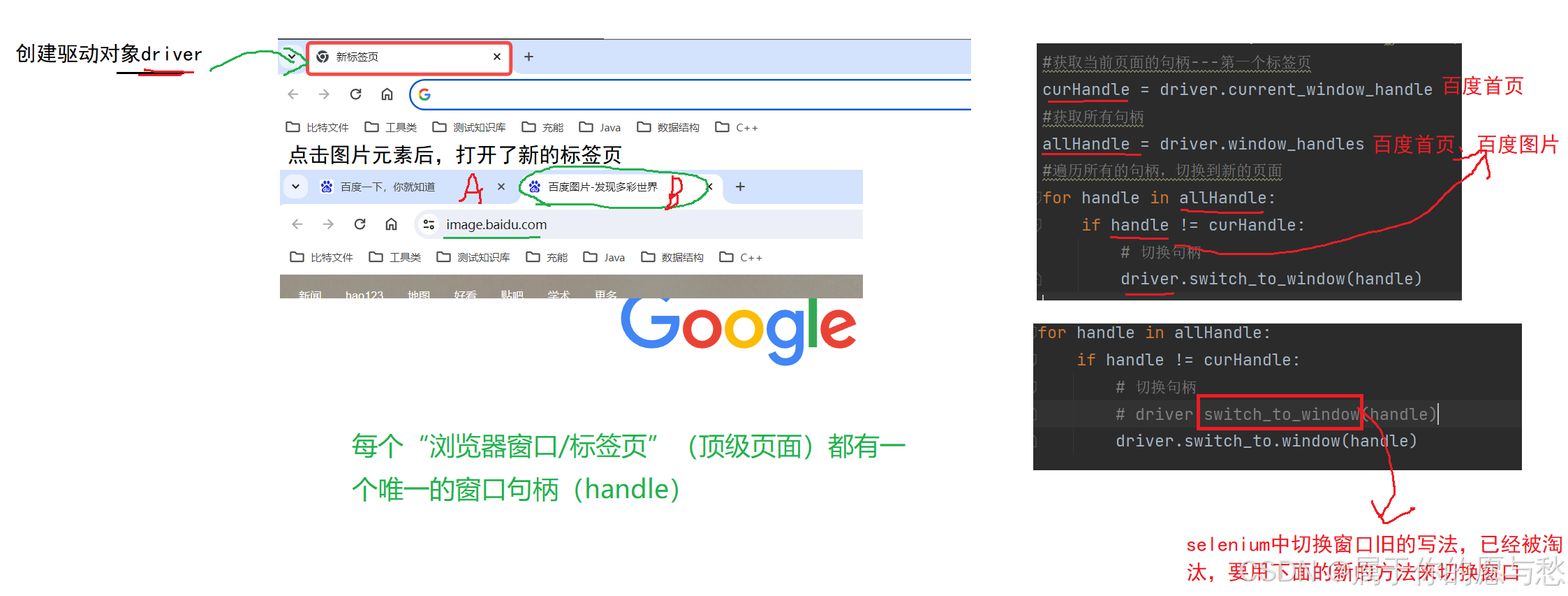
窗口设置大小
#窗⼝最⼤化
driver.maximize_window()
time.sleep(1)
#窗⼝最⼩化
driver.minimize_window()
time.sleep(1)
#窗⼝全屏
driver.fullscreen_window()
time.sleep(1)
#⼿动设置窗⼝⼤⼩
driver.set_window_size(1024,768)
time.sleep(1)屏幕截图
我们的自动化脚本一般部署在机器上自动的去运行,如果出现了报错,我们是不知道的,可以通过抓拍来记录当时的错误场景

driver.save_screenshot('./baidu.png')由于图片给定的名称是固定的,当我们多次运行自动化脚本时,历史的图片将被覆盖
如何将历史的图片文件保存下来:每次生成的图片文件名称都不一样(带时间)
filename="autotest-"+datetime.datetime.now().strftime("%Y-%m-%d-%H%M%S")+'.png'
print(filename)
driver.save_screenshot("./images/"+filename)
关闭窗口
driver.close()
注意:窗口关闭后driver要重新定义
# #查找图片并点击
driver.find_element(By.CSS_SELECTOR,"#s-top-left > a:nth-child(6)").click()
# #获取当前页面的句柄---第一个标签页
curWindow = driver.current_window_handle
# #获取所有句柄
allWindows = driver.window_handles
# #遍历所有的句柄,切换到新页面
for handle in allWindows:if handle!=curWindow:#切换句柄driver.switch_to.window(handle)
print("after:"+driver.title)
print("after:"+driver.current_url)
driver.close()
# 获取所有窗口句柄
handles = driver.window_handles
# 切换到第一个窗口
driver.switch_to.window(handles[0])
text=driver.find_element(By.CSS_SELECTOR,"#su").get_attribute("value")
assert text=="百度一下"# 获取所有窗口句柄
handles = driver.window_handles
# 切换到第一个窗口
driver.switch_to.window(handles[0])类似这种切换窗口才能继续关闭
弹窗
弹窗是在页面是找不到任何元素的,这种情况怎么处理?使用selenium提供的Alert接口
警告弹窗+确认弹窗
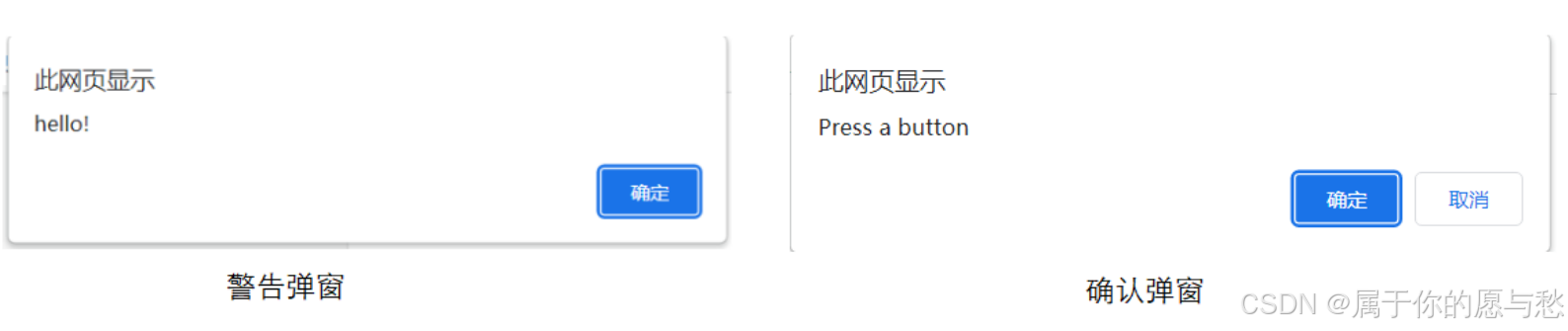
alert = driver.switchTo.alert //确认
alert.accept() //取消
alert.dismiss()
driver.get("file:///D:/Acode/c-recording-test-course--2024/selenium-html/alert.html#")
time.sleep(2)
#点击调起弹窗
driver.find_element(By.CSS_SELECTOR,"#tooltip").click()
alert = driver.switch_to.alert
time.sleep(1)
#确认
#alert.accept()
#取消
alert.dismiss()
# 弹窗关闭之后才能执行下面的代码
driver.find_element(By.CSS_SELECTOR,"#tooltip").click()
time.sleep(1)提示弹窗
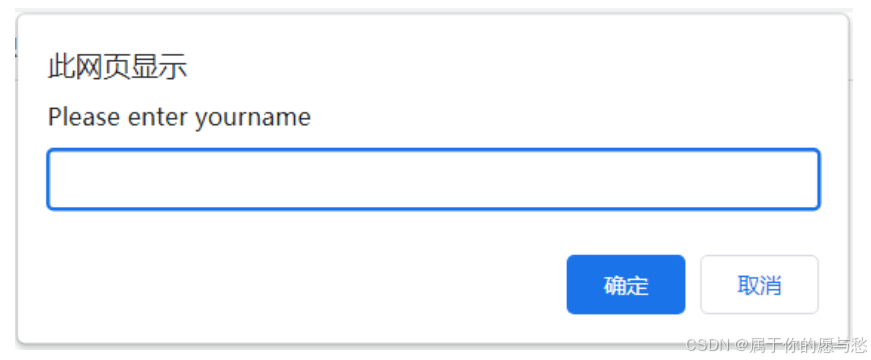
alert = driver.switch_to.alert
alert.send_keys("hello")
alert.accept()
alert.dismiss()
driver.get("file:///D:/Acode/c-recording-test-course--2024/selenium-html/Prompt.html")
time.sleep(2)
#点击调起弹窗driver.find_element(By.CSS_SELECTOR,"body > input[type=button]").click()
alert = driver.switch_to.alert
time.sleep(1)
#在弹窗中的输入框中输入内容
alert.send_keys("测试课")
time.sleep(1)
#确认
alert.accept()
time.sleep(1)
#取消
#alert.dismiss()注意:弹窗中输入的内容是看不到的!
等待
通常代码执行的速度比页面渲染的速度要快,如果避免因为渲染过慢出现的自动化误报的问题呢?可以使用selenium中提供的三种等待方法:
强制等待
time.sleep()单位:秒
调用该方法时,程序会直接阻塞,等待指定秒数后继续执行后面的代码
优点:使用简单,调试的时候比较有效
缺点:影响运行效率,浪费大量的时间
隐式等待
隐式等待是一种智能等待,他可以规定在查找元素时,在指定时间内不断查找元素。如果找到则代码继续执行,直到超时没找到元素才会报错。
- 它会在指定的时间范围内,持续尝试查找元素。
- 如果在超时前找到了元素,就会立即停止等待,继续执行后续代码;
- 只有直到超时都没找到元素,才会抛出 “元素未找到” 的异常
implicitly_wait() 参数:秒
#隐式等待5秒
driver.implicitly_wait(5)
隐式等待作用域是整个脚本的所有元素。即只要driver对象没有被释放掉( driver.quit() ),隐 式等待就一直生效。
优点:智能等待,作用于全局
显示等待
显式等待的工作机制就是在预先设定的超时时间范围之内进行等待,只要满足操作的条件就会继续执行后续代码
WebDriverWait(driver,sec).until(functions)
functions :涉及到selenium.support.ui.ExpectedConditions包下的 ExpectedConditions类
式例:
from selenium.webdriver.support import expected_conditions as EC
#expected_conditions as EC 这里是对expected_conditions起来别名
wait = WebDriverWait(driver,2)
wait.until(EC.invisibility_of_element((By.XPATH,'//*
[@id="2"]/div/div/div[3]/div[1]/div[1]/div')))
WebDriverWait(driver, 2)
第一个参数:指定要绑定的浏览器驱动实例,显式等待会基于此驱动监听页面状态。
第二个参数:设置最长超时时间(单位:秒),表示最多等待多久。这里的2表示最长等待2秒。

#显示等待
wait=WebDriverWait(driver, 3)wait.until(EC.invisibility_of_element((By.XPATH,'/html/body/input')))
driver.get("file:///D:/Acode/c-recording-test-course--2024/selenium-html/Prompt.html")driver.find_element(By.CSS_SELECTOR,"body > input[type=button]").click()
#等待弹窗是否出现
wait.until(EC.alert_is_present())
#弹窗出现向下执行
alert = driver.switch_to.alert
alert.send_keys("hello")
alert.accept()
优点:显示等待是智能等待,可以自定义显示等待的条件,操作灵活
缺点:写法复杂
隐式等待和显示等待⼀起使用效果如何呢?
#隐式等待设置为10s,显⽰等待设置为15s,那么结果会是5+10=15s吗?
driver.implicitly_wait(10)
wait = WebDriverWait(driver,15)
start = time.time()try:res = wait.until(EC.presence_of_element_located((By.XPATH,'//*
[@id="2"]/div/div/div[3]/div[1]/div[1]/div/div/div')))except:end = time.time()print("no such element")
driver.quit()print(end-start)
运行结果: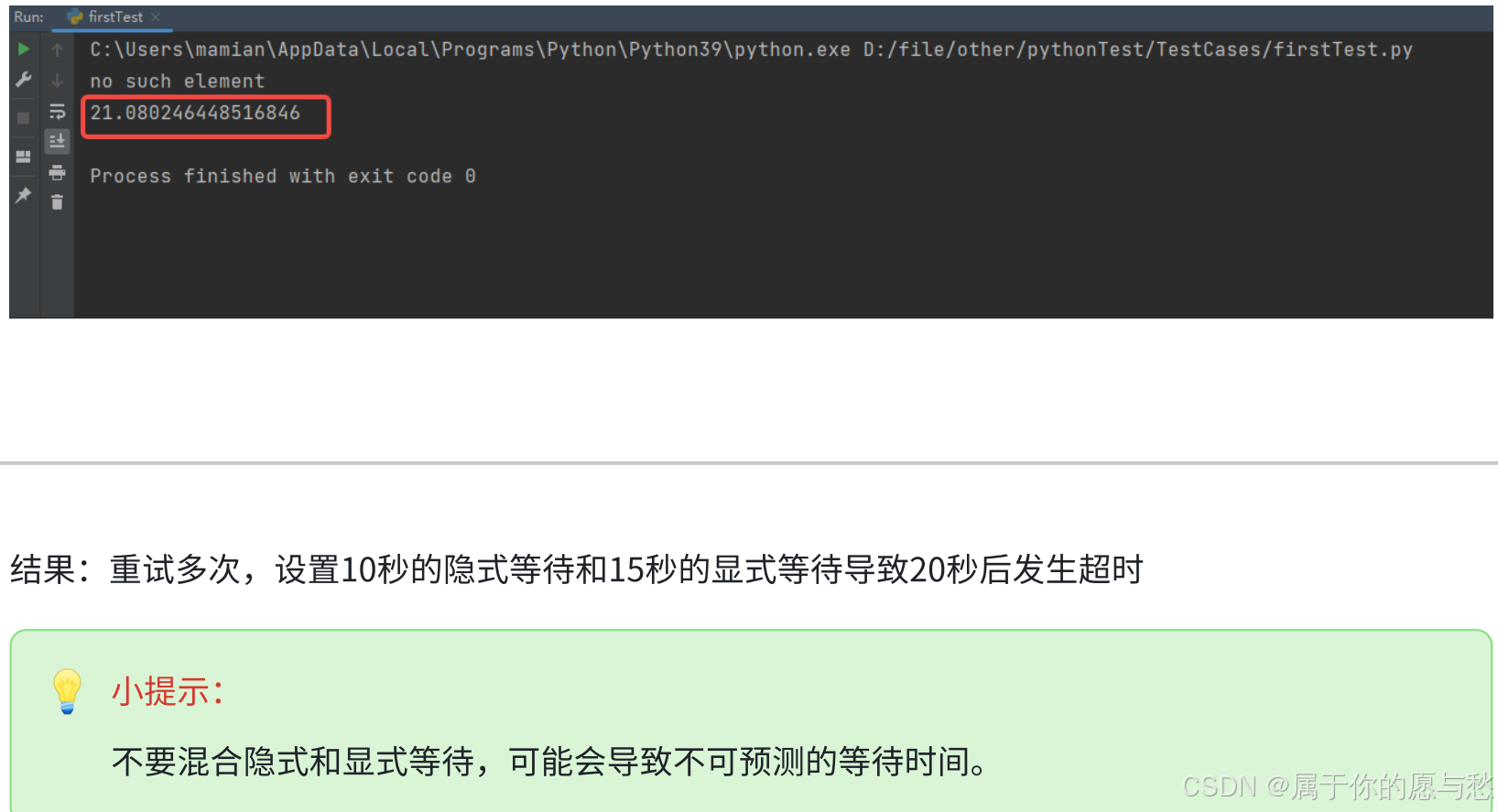
浏览器导航
常见操作:
1)打开网站
driver.get("https://tool.lu/")
2)浏览器的前进、后退、刷新
driver.back()
driver.forward()
driver.refresh()
文件上传
点击文件上传的场景下会弹窗系统窗口,进行文件的选择。 selenium无法识别非web的控件,上传文件窗口为系统自带,无法识别窗口元素 但是可以使用sendkeys来上传指定路径的文件,达到的效果是一样的
driver.get("file:///D:/Acode/c-recording-test-course--2024/selenium-html/upload.html")
#找到选择文件按钮后发送要上传的文件
driver.find_element(By.CSS_SELECTOR,"body > div > div > input[type=file]").send_keys("D:\\1\\1.txt")
time.sleep(3)这里不需要click的,这个是前端的逻辑,这个地方只需要直接输入文件就行,点击之后,是打开弹窗选择文件
浏览器参数设置
无头模式:程序在后端运行,界面看不到页面的表现
自动化打开浏览器默认情况下为有头模式
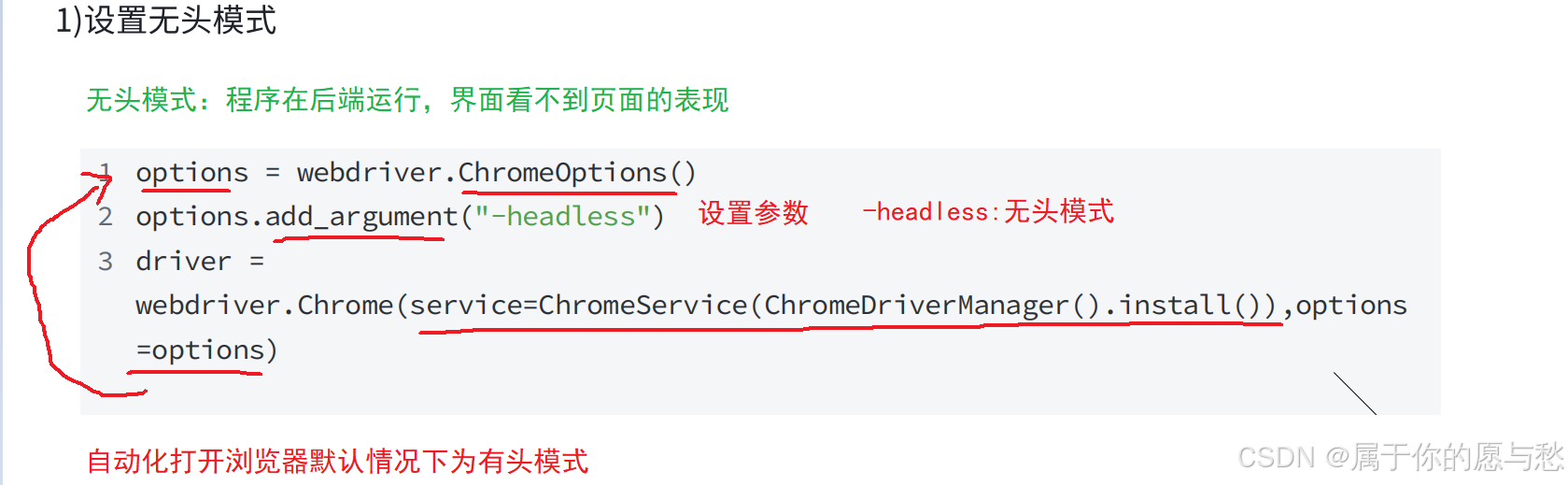
#创建谷歌浏览器驱动
ChromIns=ChromeDriverManager().install()
#浏览器参数配置
options=webdriver.ChromeOptions()
#添加无头模式
options.add_argument("--headless")
#创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromIns),options=options)
driver.quit()运行结果: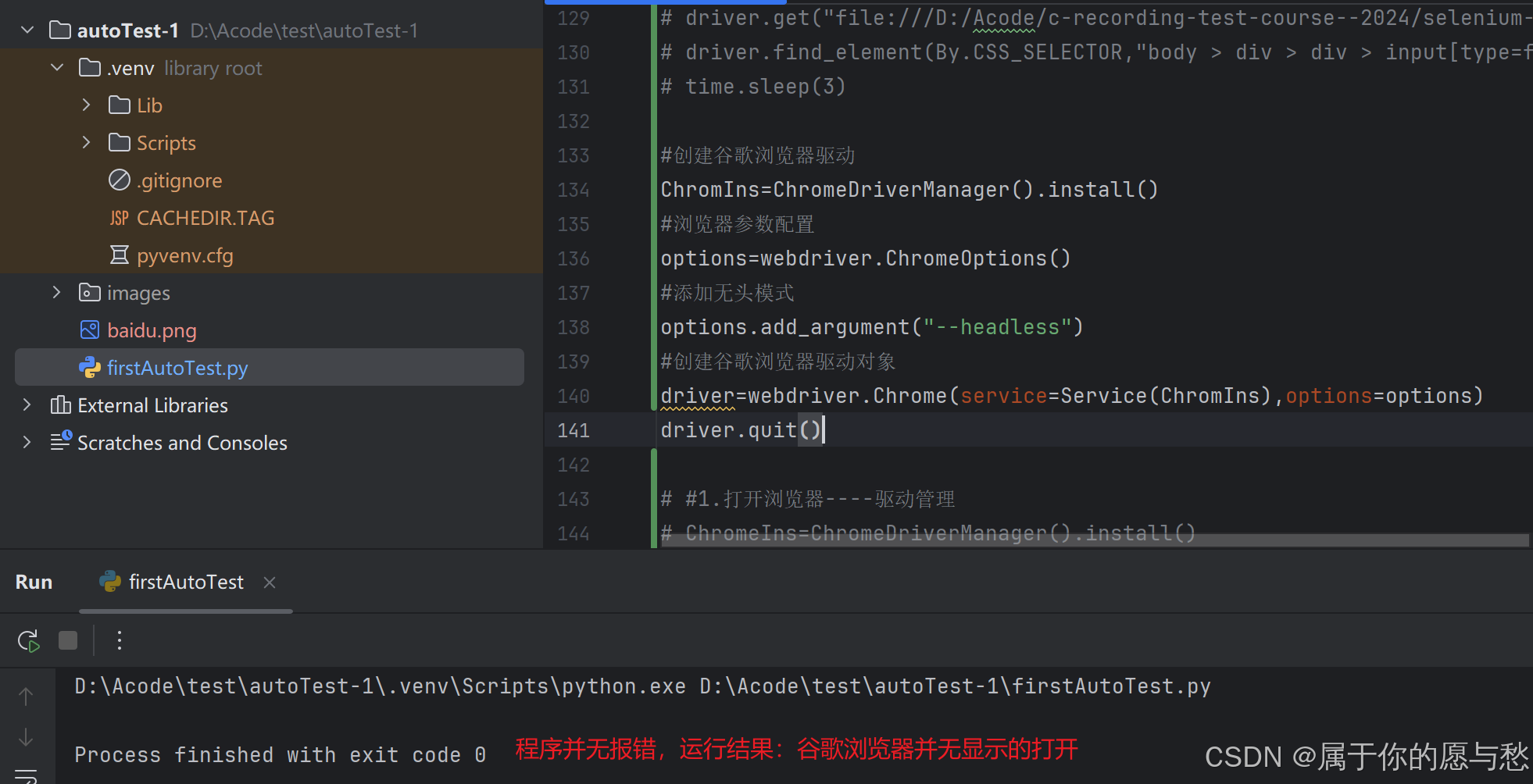
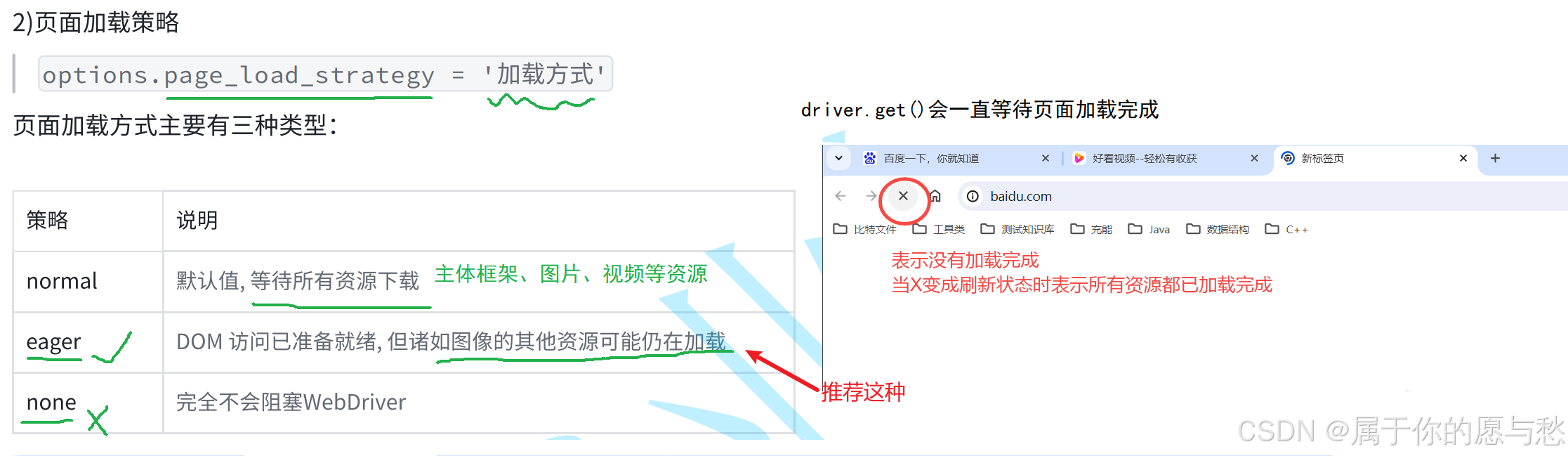
页面加载策略
options.page_load_strategy = '加载方式'
页面加载发式主要有三种类型:
| 策略 | 说明 |
| normal | 默认值,等待所有资源下载 |
| eager | DOM访问已准备就绪,但诸如图像的其他资源可能仍在加载 |
| none | 完全不会阻塞WebDriver |

#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
#浏览器参数配置
options = webdriver.ChromeOptions()#添加页面加载策略
# options.page_load_strategy = 'normal' #等待所有的资源加载完成
options.page_load_strategy = 'eager' #DOM访问就绪
#options.page_load_strategy = 'none' #完全不阻塞,直接继续往下执行脚本###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns),options=options)
driver.get("https://haokan.baidu.com/")
print(driver.title)
driver.quit()


















