概述与设计思路
利用Python的Scrapy框架进行大规模页面抓取和结构化数据提取,配合aiohttp实现高并发请求,从而高效获取Amazon平台上的商品列表、详情、评论等公开信息。通过对这些数据进行清洗与分析,可以识别出有潜力的商品,评估市场竞争程度,并跟踪竞争对手的动态,为跨境电商选品提供数据支撑。
核心思路是通过爬虫程序模拟浏览器行为,绕过Amazon的反爬虫机制,持续抓取商品标题、价格、评分、评论数、类目、上架时间、卖家信息等关键字段,进而利用数据分析方法评估商品的市场潜力。
以下是本方案主要组件及其关系的架构图: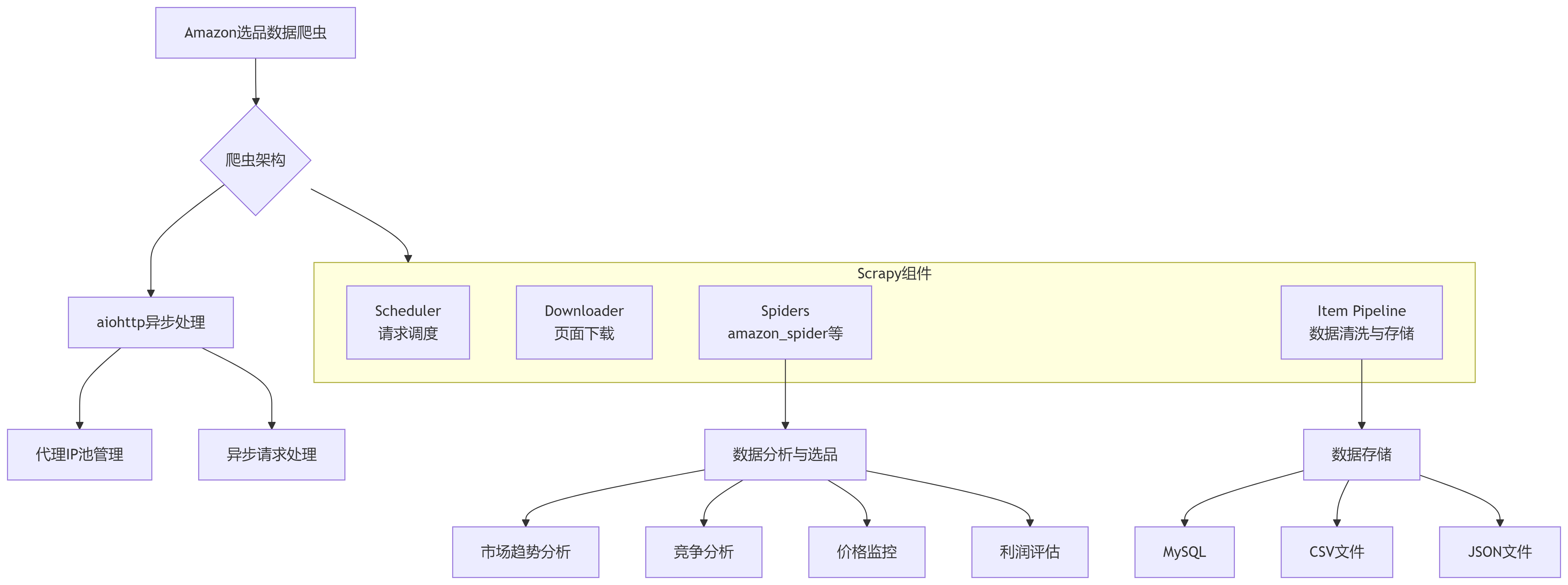
核心代码实现
1. 环境配置与依赖安装
首先,确保你的Python环境(建议3.8及以上)已安装必要的库:
pip install scrapy aiohttp aiohttp-socks scrapy-user-agents pandas numpy matplotlib2. Scrapy爬虫项目搭建
使用Scrapy框架创建爬虫项目,这是爬取Amazon产品数据的主力47。
(1) 创建Scrapy项目
在命令行中执行:


详解)
、CD(持续交付/部署)、CT(持续测试)、CICD、CICT)



之一(变更预检查部分规则))


)

文件管理-基础命令-pwd命令的使用)
)





)