一个朴实无华的目录
- 题型
- 226.翻转二叉树
- 思路:把每一个节点的左右孩子交换一下
- 101. 对称二叉树
- 思路:使用队列来比较两个树(根节点的左右子树)是否相互翻转
- 222.完全二叉树的节点个数
- 思路:本题直接就是求有多少个节点,无脑存进结果变量就行了。
- 110.平衡二叉树
- 思路:比较高度,必然是要后序遍历。
- 257. 二叉树的所有路径
- 思路:把路径记录下来,需要回溯来回退一个路径再进入另一个路径。
- 递归三部曲
- 1.递归函数参数以及返回值
- 2.确定递归终止条件
- 3.确定单层递归逻辑
- 404.左叶子之和
- 思路:如果该节点的左节点不为空,该节点的左节点的左节点为空,该节点的左节点的右节点为空,则找到了一个左叶子
- 513.找树左下角的值
- 思路:
- 112. 路径总和
- 思路:
- 106.从中序与后序遍历序列构造二叉树
- 思路:
- 654.最大二叉树
- 思路:构造树一般采用的是前序遍历,因为先构造中间节点,然后递归构造左子树和右子树。
题型
226.翻转二叉树
思路:把每一个节点的左右孩子交换一下
class Solution {
public:TreeNode* invertTree(TreeNode* root) {if (root == NULL) return root;swap(root->left, root->right); // 中invertTree(root->left); // 左invertTree(root->right); // 右return root;}
};
101. 对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
思路:使用队列来比较两个树(根节点的左右子树)是否相互翻转
class Solution {
public:bool isSymmetric(TreeNode* root) {if (root == NULL) return true;queue<TreeNode*> que;que.push(root->left); // 将左子树头结点加入队列que.push(root->right); // 将右子树头结点加入队列while (!que.empty()) { // 接下来就要判断这两个树是否相互翻转TreeNode* leftNode = que.front(); que.pop();TreeNode* rightNode = que.front(); que.pop();if (!leftNode && !rightNode) { // 左节点为空、右节点为空,此时说明是对称的continue;}// 左右一个节点不为空,或者都不为空但数值不相同,返回falseif ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {return false;}que.push(leftNode->left); // 加入左节点左孩子que.push(rightNode->right); // 加入右节点右孩子que.push(leftNode->right); // 加入左节点右孩子que.push(rightNode->left); // 加入右节点左孩子}return true;}
};
222.完全二叉树的节点个数
给出一个完全二叉树,求出该树的节点个数。
在这里插入代码片
示例 1:
输入:root = [1,2,3,4,5,6]
输出:6
示例 2:
输入:root = []
输出:0
示例 3:
输入:root = [1]
输出:1
思路:本题直接就是求有多少个节点,无脑存进结果变量就行了。
class Solution {
public:int countNodes(TreeNode* root) {if (root == nullptr) return 0;TreeNode* left = root->left;TreeNode* right = root->right;int leftDepth = 0, rightDepth = 0; // 这里初始为0是有目的的,为了下面求指数方便while (left) { // 求左子树深度left = left->left;leftDepth++;}while (right) { // 求右子树深度right = right->right;rightDepth++;}if (leftDepth == rightDepth) {return (2 << leftDepth) - 1; // 注意(2<<1) 相当于2^2,所以leftDepth初始为0}return countNodes(root->left) + countNodes(root->right) + 1;}
};
110.平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
思路:比较高度,必然是要后序遍历。
递归三步曲分析:
1.明确递归函数的参数和返回值
参数:当前传入节点。 返回值:以当前传入节点为根节点的树的高度。
2.明确终止条件
递归的过程中依然是遇到空节点了为终止,返回0,表示当前节点为根节点的树高度为0
3.明确单层递归的逻辑
如何判断以当前传入节点为根节点的二叉树是否是平衡二叉树呢?当然是其左子树高度和其右子树高度的差值。
分别求出其左右子树的高度,然后如果差值小于等于1,则返回当前二叉树的高度,否则返回-1,表示已经不是二叉平衡树了。
class Solution {
public:// 返回以该节点为根节点的二叉树的高度,如果不是平衡二叉树了则返回-1int getHeight(TreeNode* node) {if (node == NULL) {return 0;}int leftHeight = getHeight(node->left);if (leftHeight == -1) return -1;int rightHeight = getHeight(node->right);if (rightHeight == -1) return -1;return abs(leftHeight - rightHeight) > 1 ? -1 : 1 + max(leftHeight, rightHeight);}bool isBalanced(TreeNode* root) {return getHeight(root) == -1 ? false : true;}
};int getHeight(TreeNode* node) {if (node == NULL) {return 0;}int leftHeight = getHeight(node->left);if (leftHeight == -1) return -1;int rightHeight = getHeight(node->right);if (rightHeight == -1) return -1;return abs(leftHeight - rightHeight) > 1 ? -1 : 1 + max(leftHeight, rightHeight);
}
257. 二叉树的所有路径
给定一个二叉树,返回所有从根节点到叶子节点的路径。
说明: 叶子节点是指没有子节点的节点。
思路:把路径记录下来,需要回溯来回退一个路径再进入另一个路径。
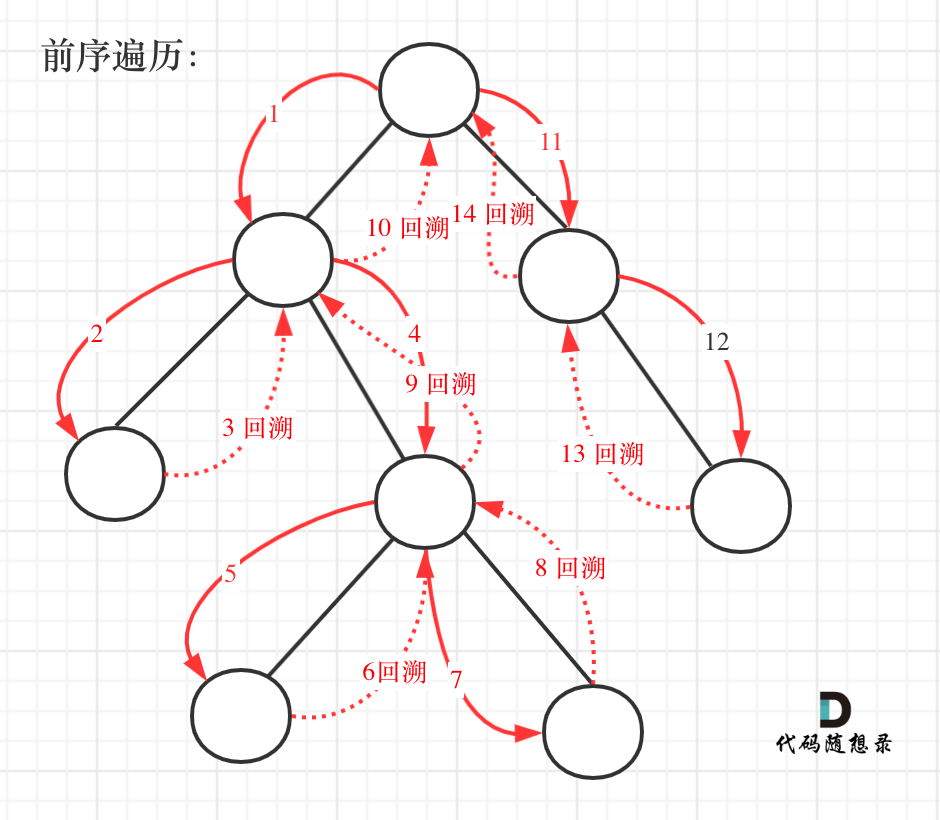
递归三部曲
1.递归函数参数以及返回值
传入根节点,记录每一条路径的path,和存放结果集的result
2.确定递归终止条件
当 cur不为空,其左右孩子都为空的时候,就找到叶子节点。
3.确定单层递归逻辑
回溯要和递归永远在一起
class Solution {
private:void traversal(TreeNode* cur, vector<int>& path, vector<string>& result) {path.push_back(cur->val); // 中,中为什么写在这里,因为最后一个节点也要加入到path中 // 这才到了叶子节点if (cur->left == NULL && cur->right == NULL) {string sPath;for (int i = 0; i < path.size() - 1; i++) {sPath += to_string(path[i]);sPath += "->";}sPath += to_string(path[path.size() - 1]);result.push_back(sPath);return;}if (cur->left) { // 左 traversal(cur->left, path, result);path.pop_back(); // 回溯}if (cur->right) { // 右traversal(cur->right, path, result);path.pop_back(); // 回溯}}public:vector<string> binaryTreePaths(TreeNode* root) {vector<string> result;vector<int> path;if (root == NULL) return result;traversal(root, path, result);return result;}
};
404.左叶子之和
计算给定二叉树的所有左叶子之和。
思路:如果该节点的左节点不为空,该节点的左节点的左节点为空,该节点的左节点的右节点为空,则找到了一个左叶子
class Solution {
public:int sumOfLeftLeaves(TreeNode* root) {if (root == NULL) return 0;if (root->left == NULL && root->right== NULL) return 0;int leftValue = sumOfLeftLeaves(root->left); // 左if (root->left && !root->left->left && !root->left->right) { // 左子树就是一个左叶子的情况leftValue = root->left->val;}int rightValue = sumOfLeftLeaves(root->right); // 右int sum = leftValue + rightValue; // 中return sum;}
};
513.找树左下角的值
给定一个二叉树,在树的最后一行找到最左边的值。
思路:
class Solution {
public:int findBottomLeftValue(TreeNode* root) {queue<TreeNode*> que;if (root != NULL) que.push(root);int result = 0;while (!que.empty()) {int size = que.size();for (int i = 0; i < size; i++) {TreeNode* node = que.front();que.pop();if (i == 0) result = node->val; // 记录最后一行第一个元素if (node->left) que.push(node->left);if (node->right) que.push(node->right);}}return result;}
};
112. 路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
思路:
参数:需要二叉树的根节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。
让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。
如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。
回溯隐藏在traversal(cur->left, count - cur->left->val)这里, 因为把count - cur->left->val 直接作为参数传进去,函数结束,count的数值没有改变。
class Solution {
private:bool traversal(TreeNode* cur, int count) {if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0if (!cur->left && !cur->right) return false; // 遇到叶子节点直接返回if (cur->left) { // 左count -= cur->left->val; // 递归,处理节点;if (traversal(cur->left, count)) return true;count += cur->left->val; // 回溯,撤销处理结果}if (cur->right) { // 右count -= cur->right->val; // 递归,处理节点;if (traversal(cur->right, count)) return true;count += cur->right->val; // 回溯,撤销处理结果}return false;}public:bool hasPathSum(TreeNode* root, int sum) {if (root == NULL) return false;return traversal(root, sum - root->val);}
};
106.从中序与后序遍历序列构造二叉树
根据一棵树的中序遍历与后序遍历构造二叉树。
注意: 你可以假设树中没有重复的元素。
思路:
第一步:如果数组大小为零的话,说明是空节点了。
第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
第五步:切割后序数组,切成后序左数组和后序右数组
第六步:递归处理左区间和右区间
class Solution {
private:// 中序区间:[inorderBegin, inorderEnd),后序区间[postorderBegin, postorderEnd)TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& postorder, int postorderBegin, int postorderEnd) {if (postorderBegin == postorderEnd) return NULL;int rootValue = postorder[postorderEnd - 1];TreeNode* root = new TreeNode(rootValue);if (postorderEnd - postorderBegin == 1) return root;int delimiterIndex;for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {if (inorder[delimiterIndex] == rootValue) break;}// 切割中序数组// 左中序区间,左闭右开[leftInorderBegin, leftInorderEnd)int leftInorderBegin = inorderBegin;int leftInorderEnd = delimiterIndex;// 右中序区间,左闭右开[rightInorderBegin, rightInorderEnd)int rightInorderBegin = delimiterIndex + 1;int rightInorderEnd = inorderEnd;// 切割后序数组// 左后序区间,左闭右开[leftPostorderBegin, leftPostorderEnd)int leftPostorderBegin = postorderBegin;int leftPostorderEnd = postorderBegin + delimiterIndex - inorderBegin; // 终止位置是 需要加上 中序区间的大小size// 右后序区间,左闭右开[rightPostorderBegin, rightPostorderEnd)int rightPostorderBegin = postorderBegin + (delimiterIndex - inorderBegin);int rightPostorderEnd = postorderEnd - 1; // 排除最后一个元素,已经作为节点了root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, postorder, leftPostorderBegin, leftPostorderEnd);root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, postorder, rightPostorderBegin, rightPostorderEnd);return root;}
public:TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {if (inorder.size() == 0 || postorder.size() == 0) return NULL;// 左闭右开的原则return traversal(inorder, 0, inorder.size(), postorder, 0, postorder.size());}
};
654.最大二叉树
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
二叉树的根是数组中的最大元素。
左子树是通过数组中最大值左边部分构造出的最大二叉树。
右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
思路:构造树一般采用的是前序遍历,因为先构造中间节点,然后递归构造左子树和右子树。
class Solution {
private:// 在左闭右开区间[left, right),构造二叉树TreeNode* traversal(vector<int>& nums, int left, int right) {if (left >= right) return nullptr;// 分割点下标:maxValueIndexint maxValueIndex = left;for (int i = left + 1; i < right; ++i) {if (nums[i] > nums[maxValueIndex]) maxValueIndex = i;}TreeNode* root = new TreeNode(nums[maxValueIndex]);// 左闭右开:[left, maxValueIndex)root->left = traversal(nums, left, maxValueIndex);// 左闭右开:[maxValueIndex + 1, right)root->right = traversal(nums, maxValueIndex + 1, right);return root;}
public:TreeNode* constructMaximumBinaryTree(vector<int>& nums) {return traversal(nums, 0, nums.size());}
};


 详细指南)











 egui (0.32.1) 学习笔记(逐行注释)(二十六)windows平台运行时隐藏控制台)


 如何搭建Redis哨兵?)

