1.前言
在 Java 中,树(Tree)是一种非线性数据结构,由节点(Node)组成,常见的线性表则是我们之前学过的顺序表、链表、栈、队列等等。每个节点包含数据和指向子节点的引用。树的常见实现方式包括二叉树、二叉搜索树、平衡树(如 AVL 树、红黑树)等。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
数据部分和指向子节点的引用。以二叉树为例,每个节点最多有两个子节点(左子节点和右子节点)。树的构建通常通过手动创建节点并连接子节点来实现。
2.节点与树的关系
下面是一些关于树中节点与树之间的关系的概念,建议花三到五分钟来看一下:
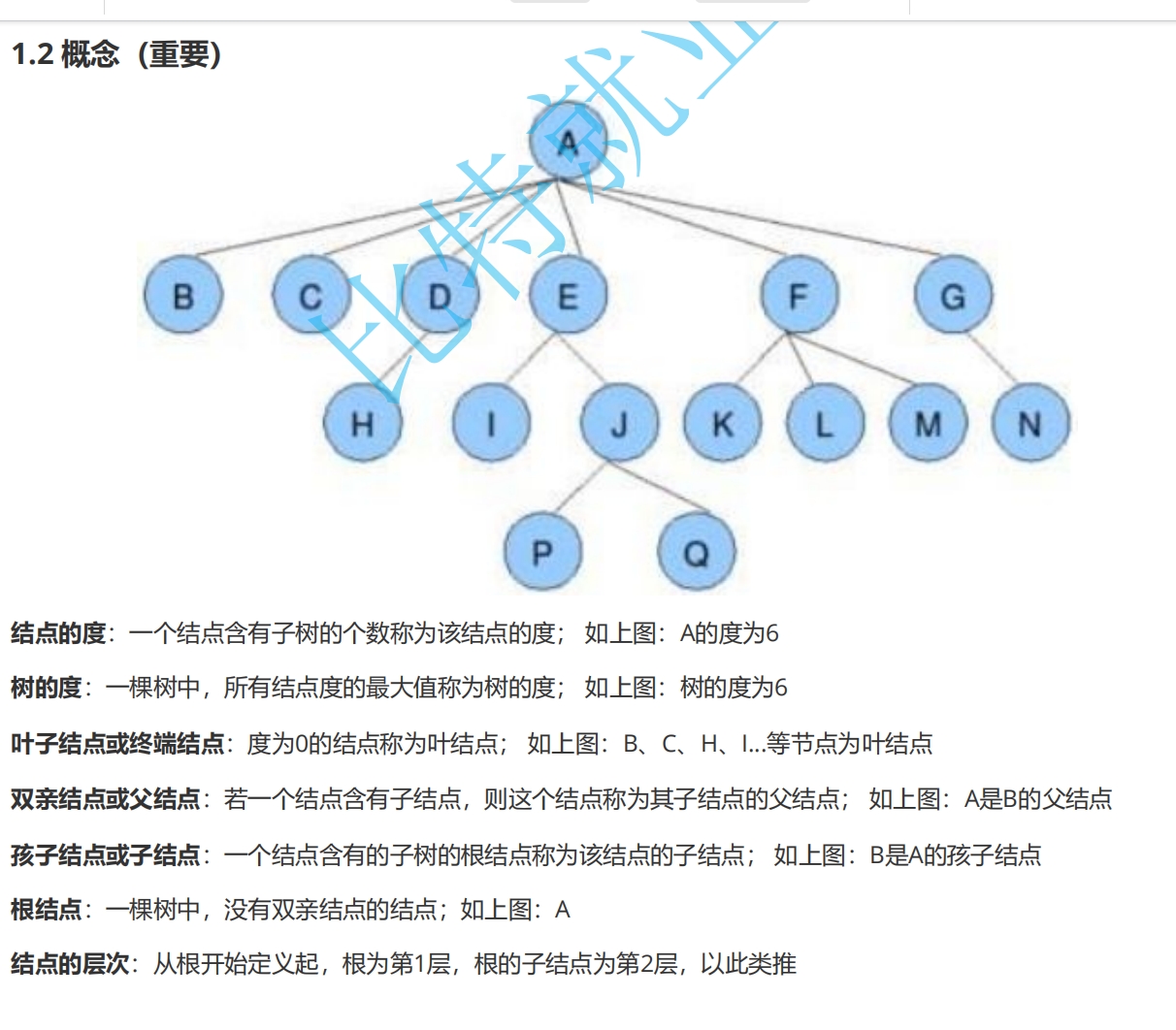
![]()
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,实际中树有很多种表示方式,如:双亲表示法孩子表示法、孩子双亲表示法、孩子兄弟表示法等等。我们这里就简单的了解其中最常用的孩子兄弟表示法。这部分我们只做了解,我给出部分代码如下:
class Node f
int value; // 树中存储的数据
Node firstchild; // 第一个孩子引用
Node nextBrother; //下一个兄弟引用
那么,树在我们计算机中可以起到什么样的作用呢?如下图所示:
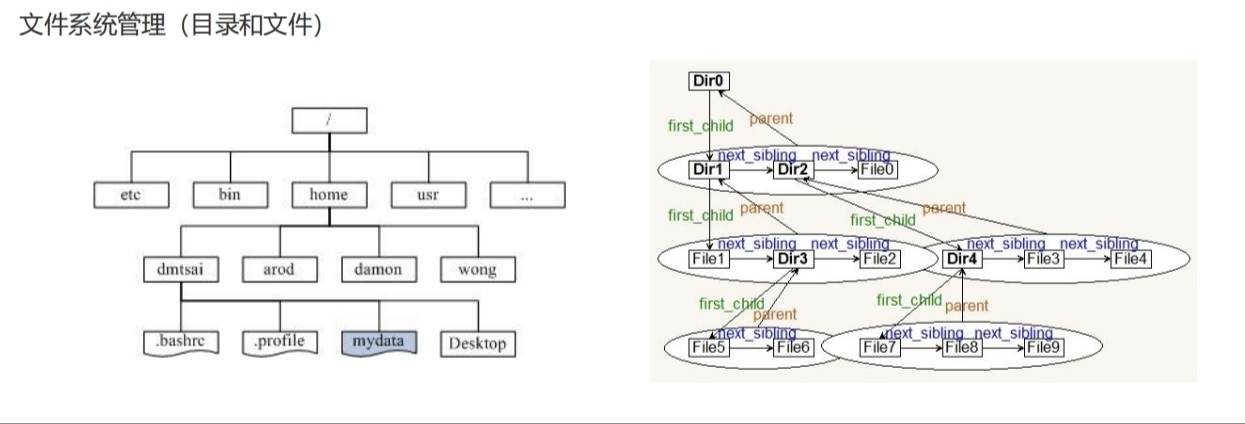
3.二叉树(重点)
一棵二叉树是结点的一个有限集合,该集合:
1.要么为空;
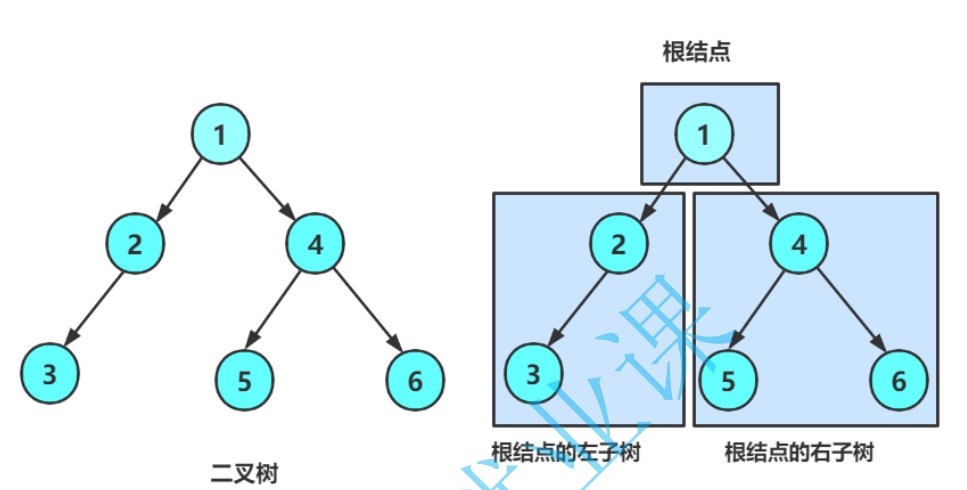
从上图可以看出:
1. 二叉树不存在度大于2的结点;
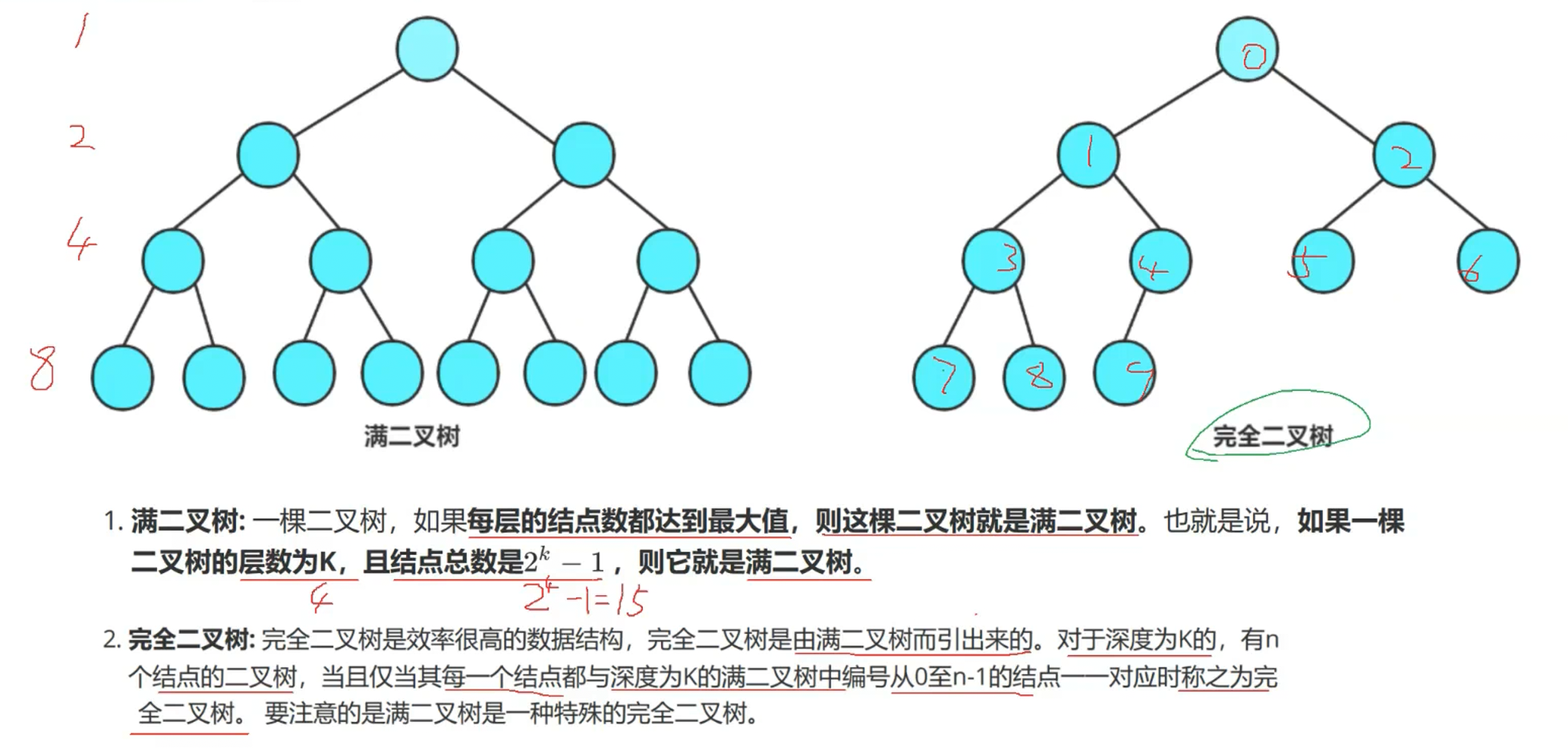
然后是二叉树的性质,这两大知识点理解后,能有效利于我们对于二叉树各个点的了解与计算。

看完之后,我们来做几道例题巩固一下:
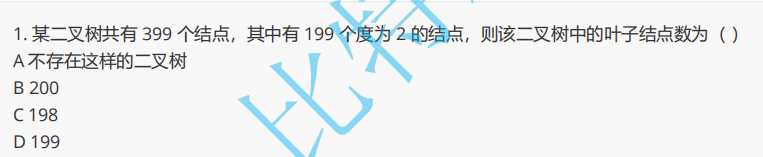
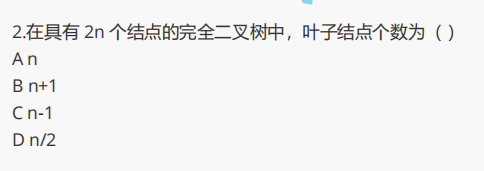
解析:第一题这里运用了 n0 = n2 + 1 的公式,就可以直接得出。第二题则需要一些公式推导,如下图所示:
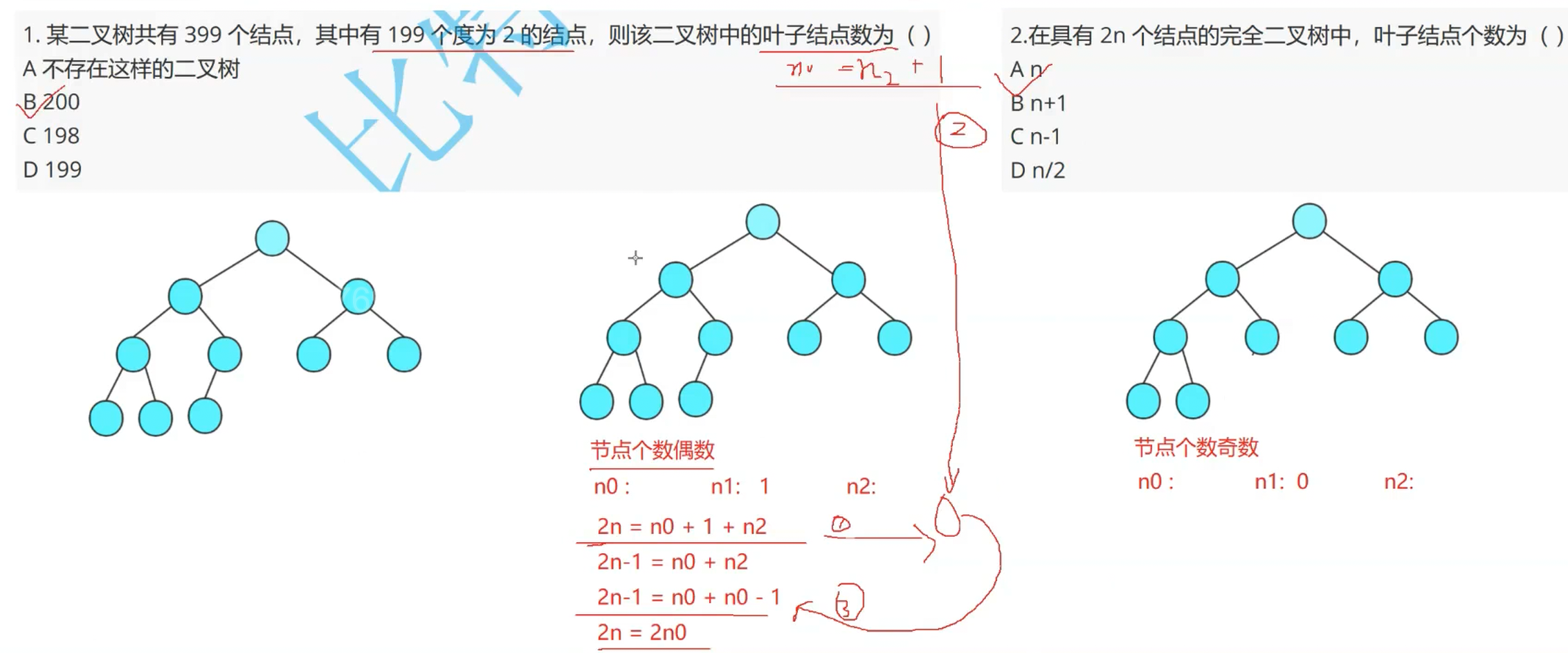


解析:具体解法与第一第二无太大区别;第四题我们就得用二叉树性质第四点:具有n个结点的完全二叉树的深度k为log2(n + 1)向上取整,就可得到正确答案。

3.1 二叉树的遍历方式
二叉树有以下四种遍历方式:前序遍历、中序遍历、后序遍历和层序遍历。前三个我们用的最频繁,现在我们来一个个以图的形式来分别看它们是如何实现的:
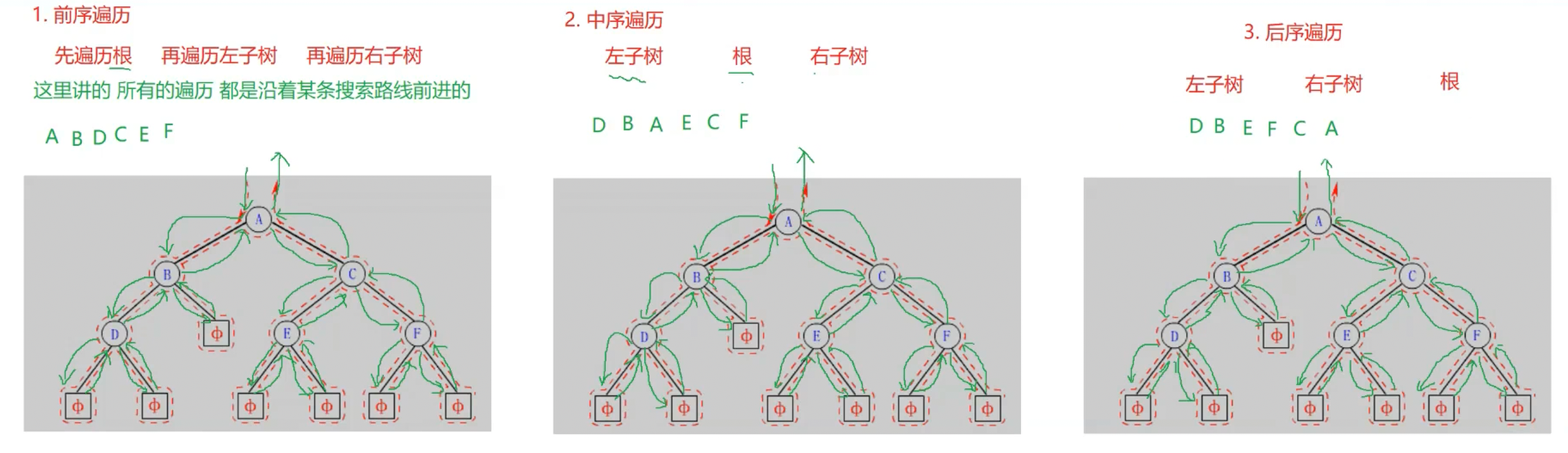
所以,前序遍历可总结成 根 左 右 的形式来遍历,中序遍历则是 左 根 右 的形式,后序遍历则是 左 右 根 的形式。层序遍历的实现与上面三种都不相同,因此单独来进行说明。
设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。具体可看下图:
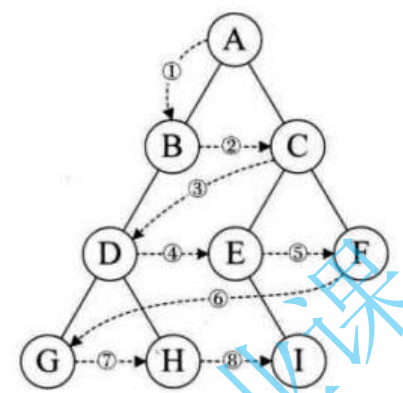
然后同样,我们来做一些例题。

方法和经验提示【重要】:先通过先序(前序)遍历或后序遍历来确定根,再从中序遍历中找到根所在的位置,则可以得出根左边是左树,根右边是右树。


解析如下:

思考:如果有一道题给出了前序和后序遍历,那我们是否可以得到中序遍历呢?
答:不能!!因为前序和后序遍历都确定的是二叉树的根,无法确定左树是哪些,右树是哪些。
3.2 二叉树的基本操作
学完了二叉树的一些实现方式及相关概念后,就该来看看二叉树的几种基本操作了。
二叉树的基本操作及要求有以下几种:
1. 创建一棵二叉树,并返回根节点;
2. 前序、中序、后序、层序遍历(两种思路:递归和非递归);
3. 获取树中节点的个数(两种思路:遍历思路与子问题思路);
4. 获取树中叶子节点的个数(两种思路:遍历思路与子问题思路);
5. 获取第K层节点的个数;
6. 获取二叉树的高度;
7. 检测值为value的元素是否存在;
8. 判断一棵树是不是完全二叉树;
所以可以看到二叉树的操作还是比较多的,而且都是用递归去实现,所以会复杂一些。我认为这其实就是二叉树难的原因。但是大家也不要灰心,坚持下去;学完本节,数据结构可以说基本就完成了一大半了。下来我们就来分别看一看各个操作的实现:
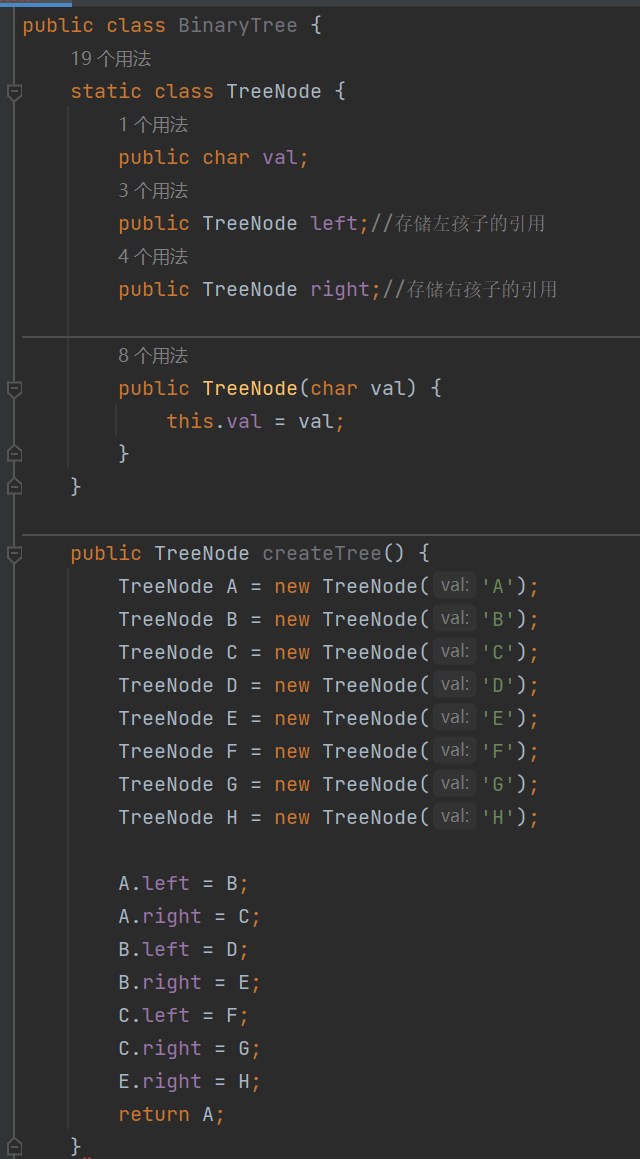
1. 创建一棵二叉树,并返回根节点
对于一棵二叉树,我们肯定是有值、左树和右树存在的。所以我们新定义一个类叫做BinaryTree,由于在创建后就是固定的了,因此创建出静态方法 static class TreeNode 把值、左树和右树创建出来,再对值用构造方法进行初始化,为什么这里不对左树和右树进行初始化呢?因为左树、右树的指向由于递归,它们是一直在不断变化的,这个时候显然用构造方法来初始化不太合理。
然后接下来,我们就要创建节点了,这里就可以用实例化的方式把ABCDEFG......给创建出来,然后再定义A左树、A右树;B左树、B右树;C左树、C右树......具体如何创建就看个人了。
图解代码如下:
2. 前序、中序、后序、层序遍历(两种思路:递归和非递归)
2.1 前序遍历(preOrder)【递归思路】
在此之前,先来复习一下递归的条件是:开始条件即是程序终止条件、运行时会自己调用自己。
前序遍历顺序是 根 左 右 ,我们首先先来判断一下该树是否为空,为空则直接返回(这里由于是void,所以没有返回值,直接写个return即可);然后由于是前序遍历,我们应该首先打印出根节点的值,然后再调用自己把左树打印出来、再把右树打印出来,就可以完成遍历。它会将所有的根先打印完后(说明它会一直向下、然后打印根 向下、然后打印根,直到没有根可以被打印时),就会去打印左树、再去打印右树。

2.2 前序遍历(preOrder)【非递归思路】
非递归思路这里使用的是栈来完成的,条件仍然是判断一下该树是否为空,为空则直接返回。然后我们需要创建一个栈,才能完成操作,具体可以写成 Stack<TreeNode> stack = new Stack<>();
由于这里是采用非递归的方式进行遍历,因为递归的整体流程与循环比较类似,所以我们可以使用循环来取代递归。那么就要先想到循环的条件应该是什么,这里我们可以定义一个指针cur等于根节点 (根节点是root) ,让cur来执行 根 左 右 的顺序并打印,那么循环条件其实就应该是cur != null ,因为如果为空就证明没有 根节点/左树/右树 了。
具体就是:每往下走一个,就把cur放到栈里面,并进行打印,然后让 cur = cur.left ,直到为空的时候是不是就不进入循环了,这里我们就要想如何从左树转到右树。这里我们就用到栈中的方法stack.pop() 进行弹出(这里可以定义一个top,用于接收pop()的值),然后再令 cur = top.right 就能过渡到右树来了,但是此时有一个问题,过渡到右树来我们是不是也是为了去遍历?那我们刚才这样写只执行了一次(没有写成循环的形式),那该怎么办呢?
答:再来一个循环,形成嵌套循环。
我们可以写成嵌套循环的形式,在原来的 while (cur != null) { 之上再来一个循环,那么同样的,我们要思考循环条件是什么。大家想想。既然每次是需要放栈才打印,出栈到右树,右树为空时又会出栈。那么是不是总有一次栈就会一直出出出,最后变为空了呢。所以我们的条件应该是会反其道而行之,即 !stack.isEmpty(),然后由于 根 左 顺序时循环条件是 cur != null,则到右树时也不应该去掉。然后如果两个条件中我们应该使用的是或者(||),只要满足一个就终止程序。即完整的循环条件是 while (cur != null || !stack.isEmpty() 。
具体代码实现如下:

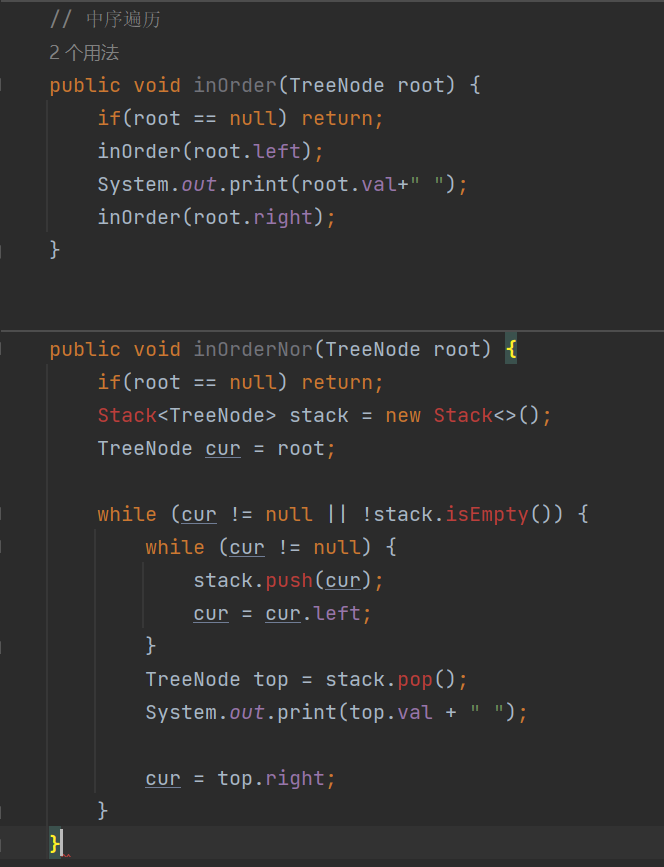
2.3 中序遍历(inOrder)【递归思路和非递归思路】
中序和后序遍历它们与前序思路基本相同,所以这里就不再赘述,大家可以自己尝试一下,看能不能写出来,数据结构重要的就是多画图、多写、多想。
我把递归思路和非递归思路的代码放在一起了,实现如下:
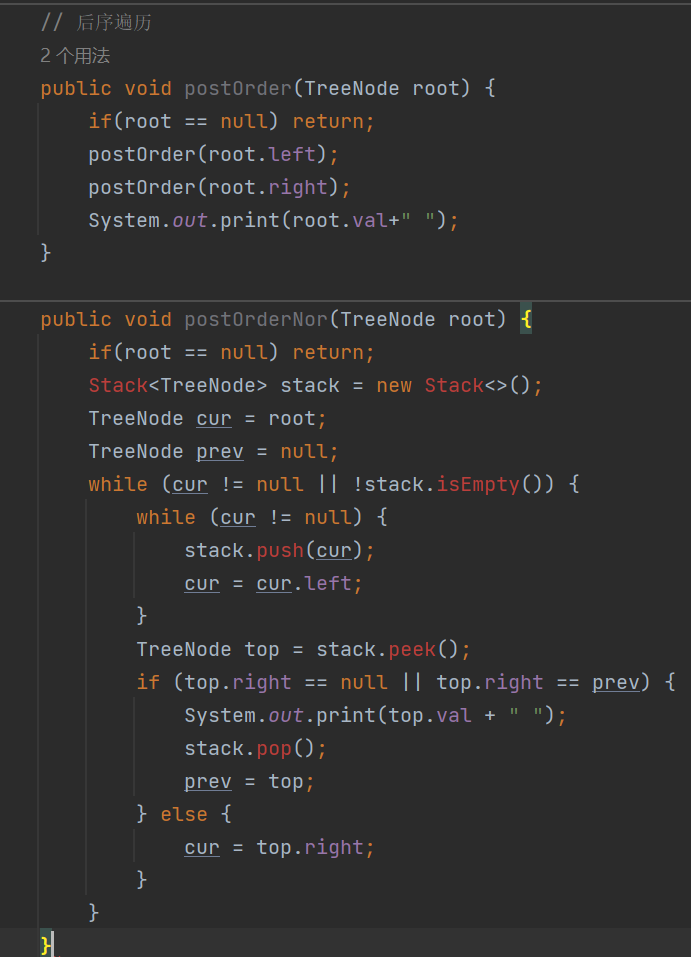
2.4 后序遍历(postOrder)【递归思路和非递归思路】
同样放在一起,如下:
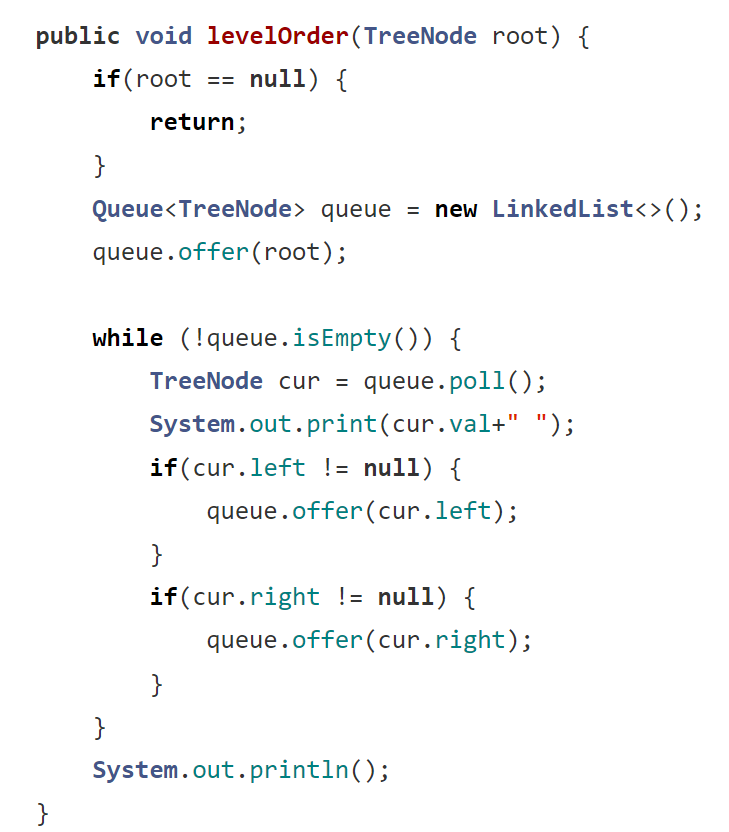
2.5 层序遍历
层序遍历我们是使用队列的方式进行实现,队列的特点是“先入先出”,如果用栈的话,由于特点是“先入后出”,所以就不可能先打印出A(假如一棵树是ABCDEFG)。所以必须要使用队列才能完成。
在此之前,我们也是要判断一下树本身是否为空的情况。判断好了之后,因为我们使用队列来实现,所以我们要先创建队列。队列创建好了之后,我们应该先把根节点手动放到队列里面。由于这种也是属于非递归实现的,所以要使用循环;我们的思路是这样的:因为已经放了根节点,所以先把根节点弹出并打印值,然后再判断 左/右 树是否是非空,是非空我们就放到队列中一直循环。所以这里的循环条件应该是队列不为空。
那么思路已经告诉你了,接下来就自己试一试,参考代码如下:
3. 获取树中节点的个数(两种思路:遍历思路与子问题思路)
3.1 获取树中节点的个数(遍历思路)
遍历的思路比较简单(这里默认以前序遍历为例,下同),我们可以设置一个指针,每遍历了一个节点就 ++ 一下,直到以 根 左 右 的顺序遍历完成,就停止程序,条件与前序遍历条件一致。需要注意的是,指针不能在递归方法中创建,不然的话每次递归就都会创建一个新的指针,就无法达到预期要求。因此我们应该创建在外部,并用 static int 修饰。大家可以自己尝试一下,并不是很难。
具体代码如下:

3.2 获取树中节点的个数(子问题思路)
子问题思路就是把一个大问题转化成几个小问题,然后再根据代码思想进行实现,这样有时候问题执行效率会快一些。
本题的子问题思路就是以 根 左 右 的方式把一棵二叉树分成三份,条件是root = null(该树为空树的情况) ,由于根节点只有一个,所以获取树中节点数可以理解成 左树数量 + 右树数量 + 1 。而左树和右树计算有多少个这里我们还是使用递归的方式,但是这里我们是直接 return size2(root.left) + size2(root.right)+1 来得到,如图所示:

所以可以看到,这里我们是以递归执行次数来判断节点数的,每次递归一次,节点数就多一个,以此类推。所以比较巧妙。
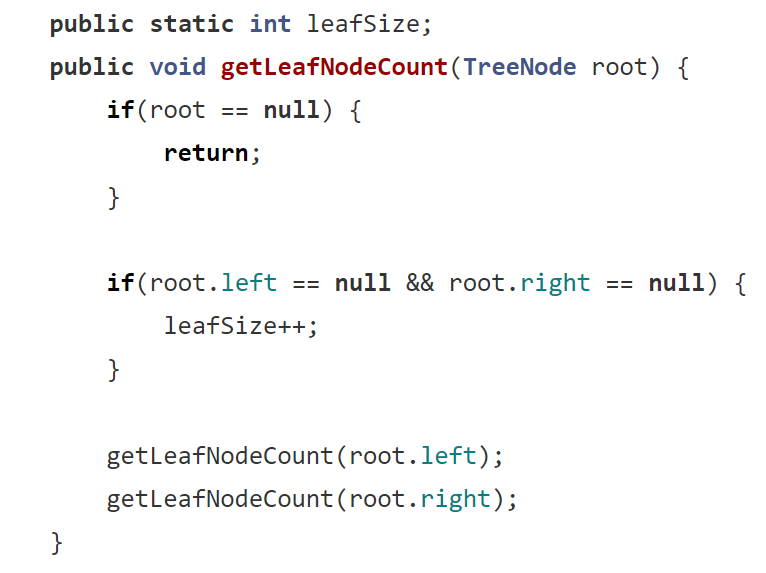
4. 获取树中叶子节点的个数(遍历思路与子问题思路)
4.1 获取树中叶子节点的个数(遍历思路)
与获取树中节点的个数思路有点类似,同样也是要设置一个指针(用 static int 修饰),遇到叶子节点就 ++ 一下。那么指针什么时候遇到的节点才是叶子节点呢?我们就得想想叶子结点的含义。(这里忘记了可以往前面翻一下,有目录,我这里由于篇幅,就不再阐述)
所以由叶子结点定义可知,左右树都没有节点的节点就是叶子节点,因此我们递归时它 ++ 的条件就应该是if(root.left == null && root.right == null) ,然后在这之前还是一样if(root == null) 判断树为空树的情况,最后再把递归方法写上就可以了。如图:
4.2 获取树中叶子节点的个数(子问题思路)
同样与获取树中节点的个数思路相差不大,需要注意的是由于没有指针的帮助,那我们就应该把方法写成有返回值的,最后再直接返回叶子结点个数就行了。

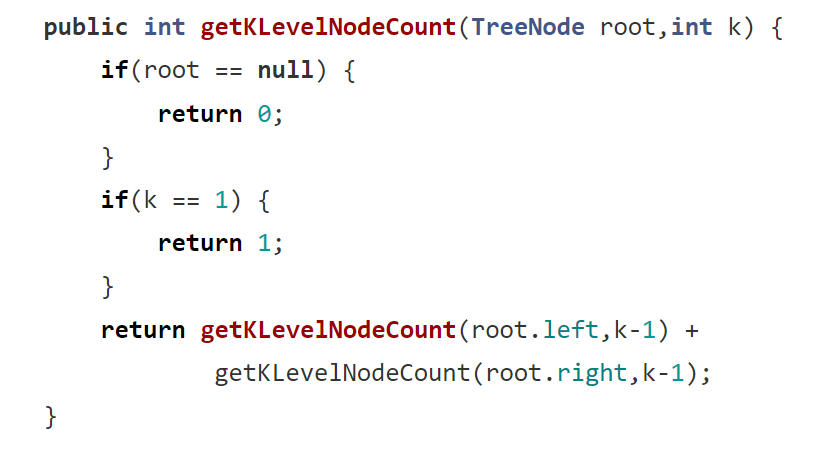
5. 获取第K层节点的个数
这里也是可以用子问题来解答,但没有使用指针,所以我们就用返回值来弄。顺带一提,不要考虑你怎么调用到第K层,这个是方法里已经实现了的。你只需要专注于如何获取第K层节点的个数就可以了。
6. 获取二叉树的高度
这里我们的思路是,把左树高度和右树高度各自都用一个变量来接受,最后比较就可以得到预期结果。

7. 检测值为value的元素是否存在
既然是要找值是否存在,那么根节点就是该值的情况和树为空的情况我们需要注意去判断一下,该方法findVal(TreeNode root,char val) 它的方法内部就可以直接查找值,我们要做的就是预防或处理各种情况的发生。顺带一提,使用该方法的时候就构成了递归。
我们可以将找到了该值的节点用变量来接收,因为已经判断了根节点就是该值的情况,那么在递归的时候,不断往下走就会变成判断下面的节点是否是我们需要寻找的值;所以我们只需要判断有找到和没有找到的情况即可。

8. 判断一棵树是不是完全二叉树
这里仅给出参考代码,不做思路说明,大家可以自己尝试一下。
至此。二叉树的所有基本操作我们都完成了,下面就要开始练题了。练题的时候某些题目不要死磕,实在不会就看一下参考答案。还有就是要多画图,这样能更方便的去理解。
3.3 二叉树的相关题型
这里给出的题目都是力扣或牛客网里的,在大家学完数据结构的时候就可以在这里刷题了。
由于篇幅原因,思路和代码都以图的形式来呈现。
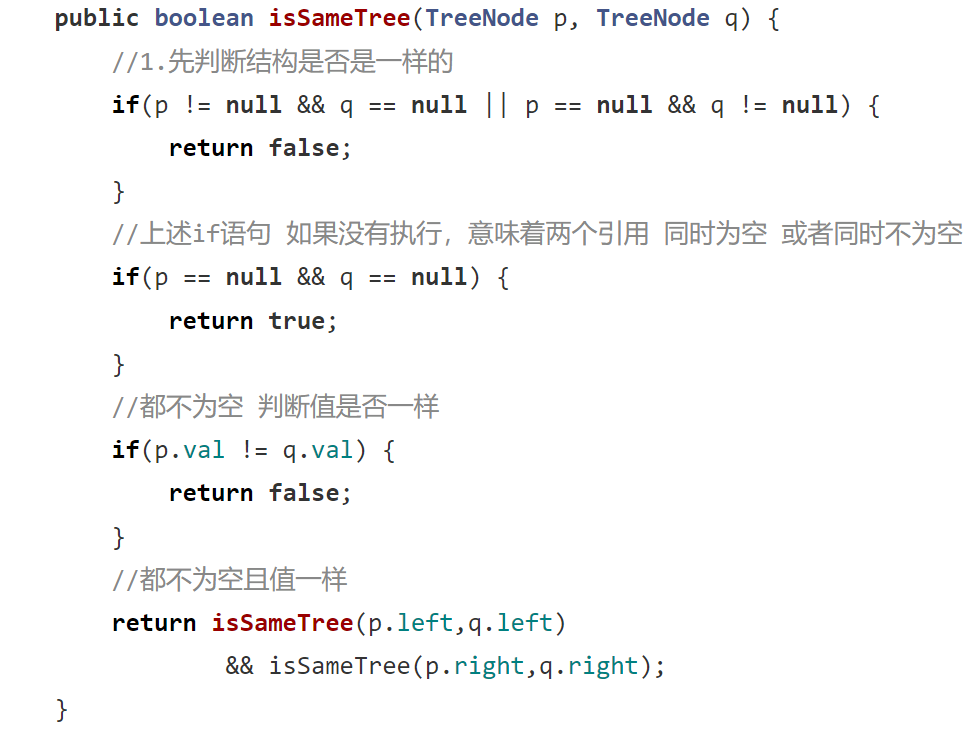
1. 572. 另一棵树的子树 - 力扣(LeetCode)
提示:这里用到了 8. 判断一棵树是不是完全二叉树 的相关代码。
思路(先自己去想,不会再来看一下思路,看完思路还不会就看答案吧):
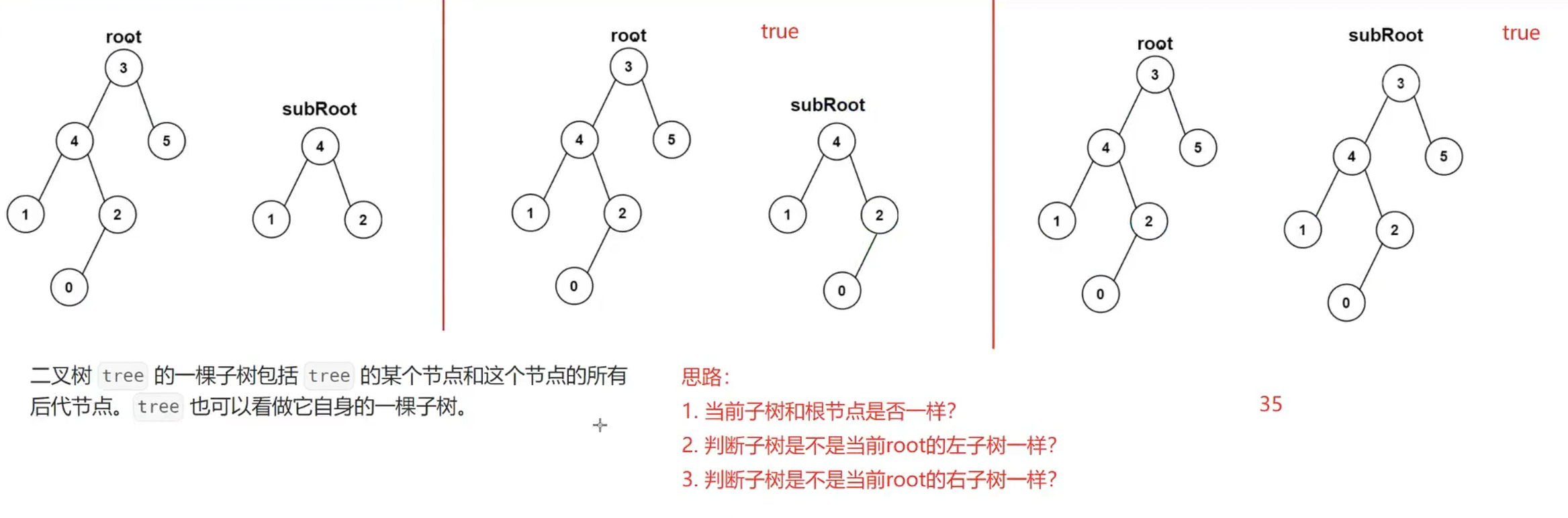
答案:在 boolean isSameTree(TreeNode p, TreeNode q) 之下的都是 8. 判断一棵树是不是完全二叉树 的代码。
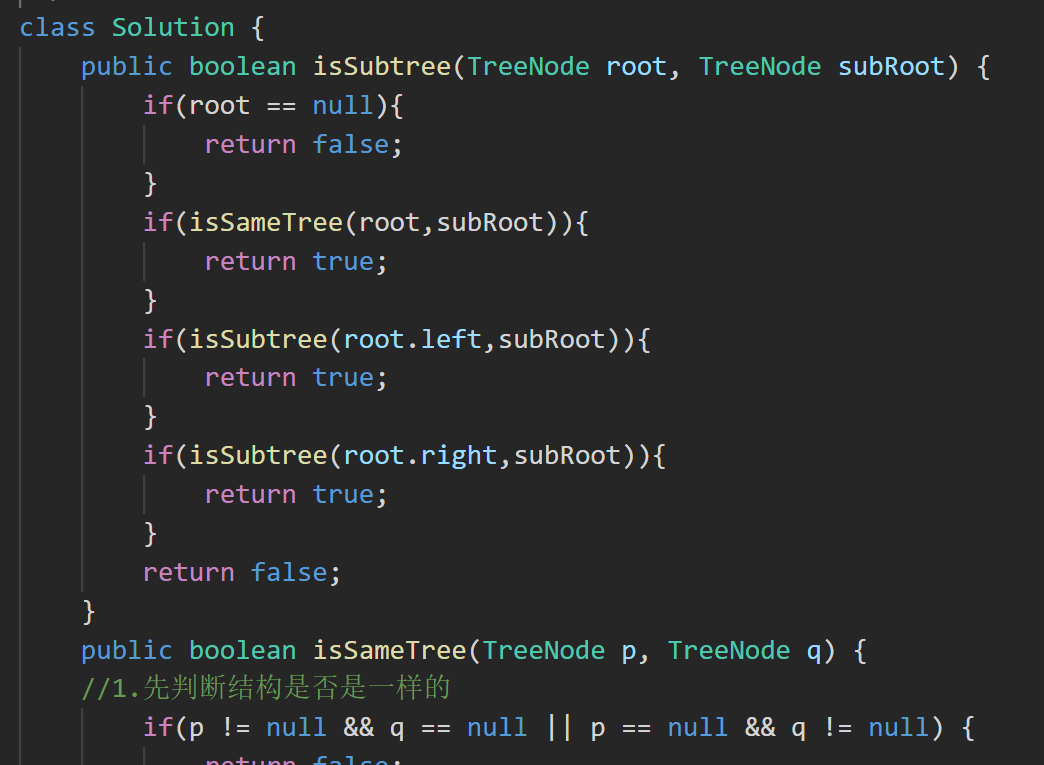
2. 101. 对称二叉树 - 力扣(LeetCode)
思路:
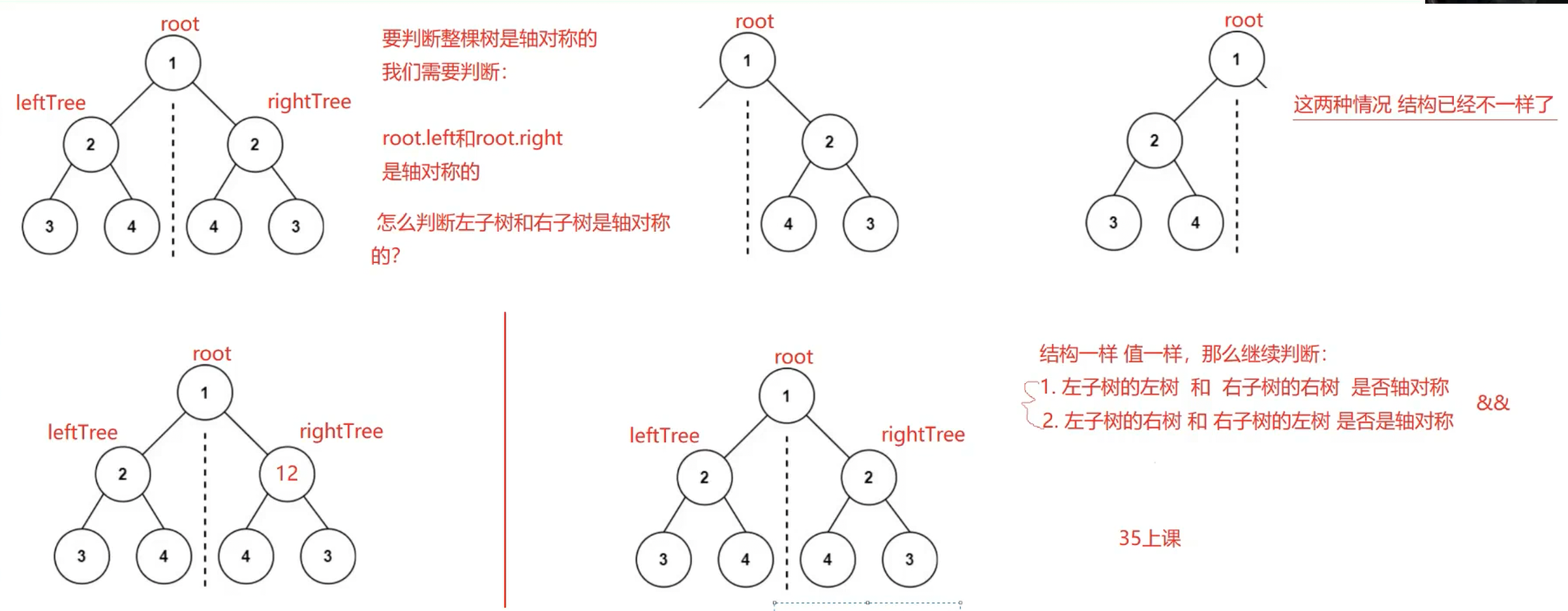
答案:
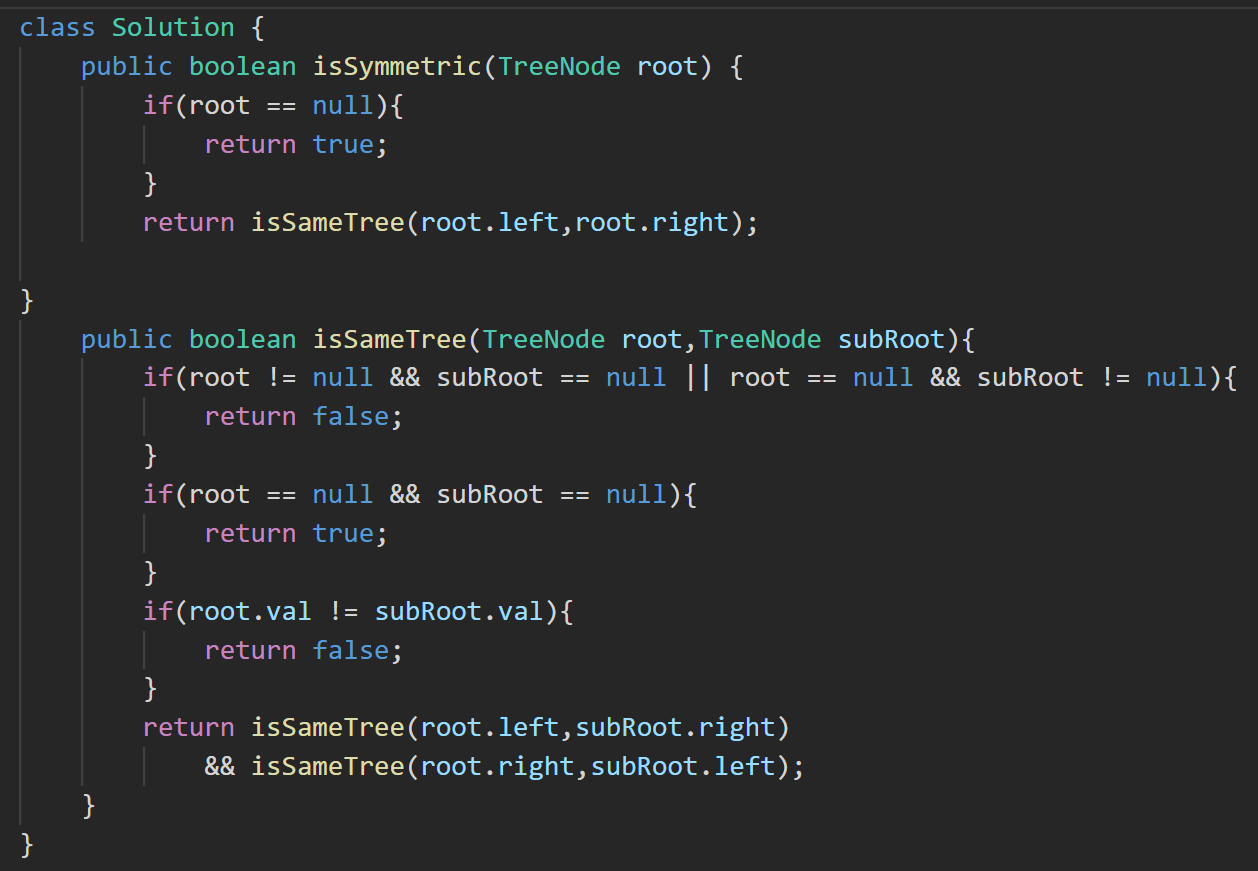
3. 100. 相同的树 - 力扣(LeetCode)
思路:
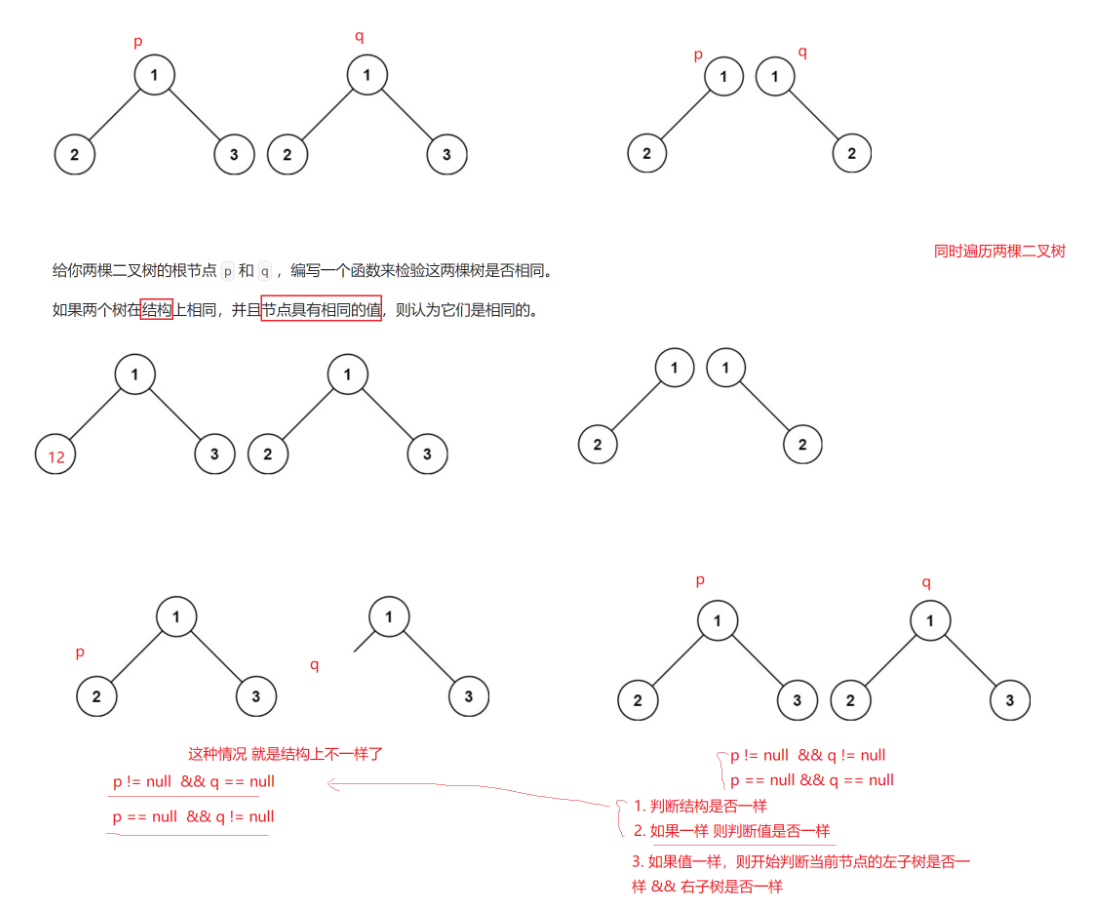
答案:
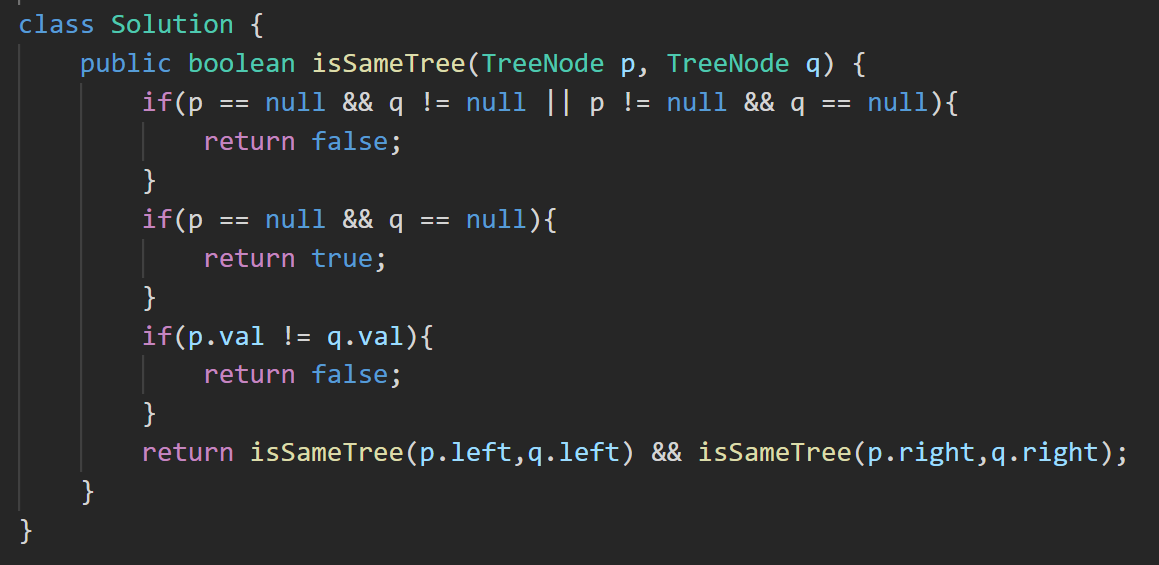
ps:虽然思路看上去很长,但写成代码却没有几行就搞定了。
4. 226. 翻转二叉树 - 力扣(LeetCode)
思路:
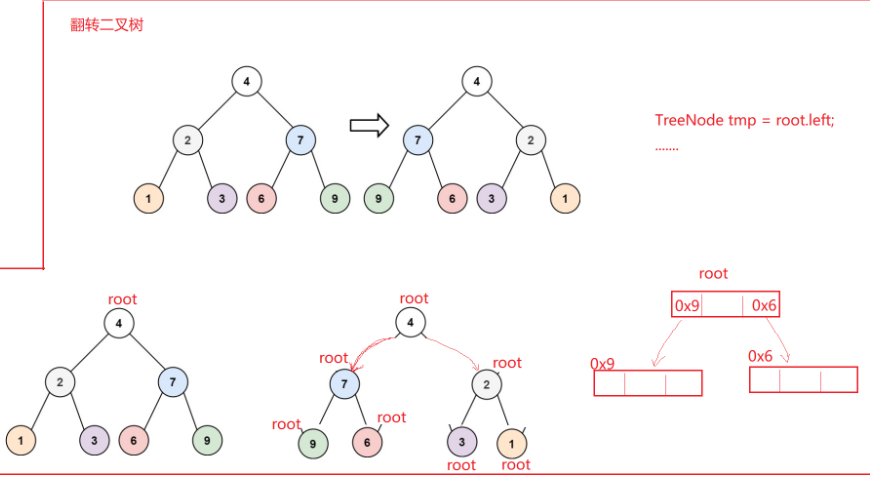
答案:
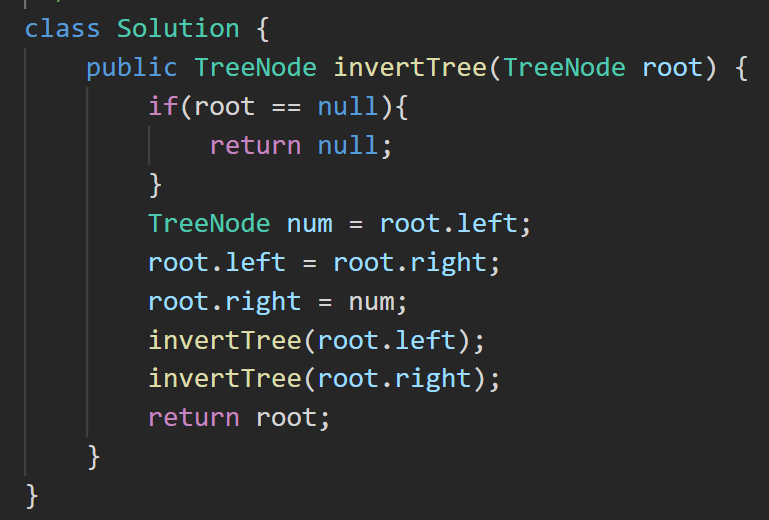
5. 110. 平衡二叉树 - 力扣(LeetCode)
思路:
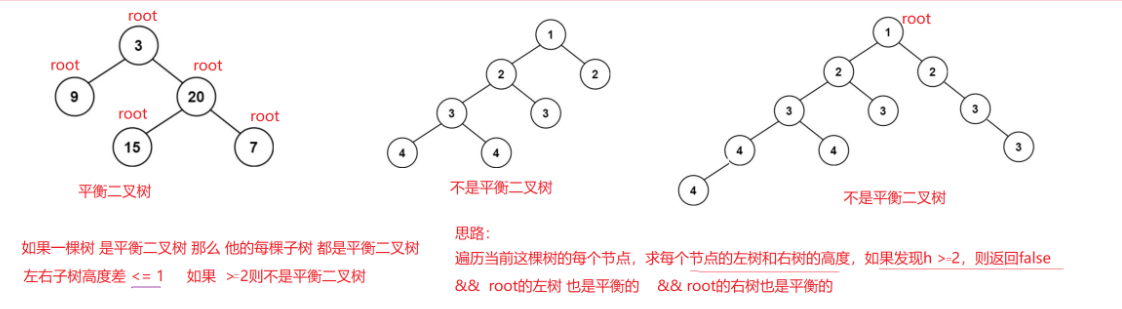
答案:
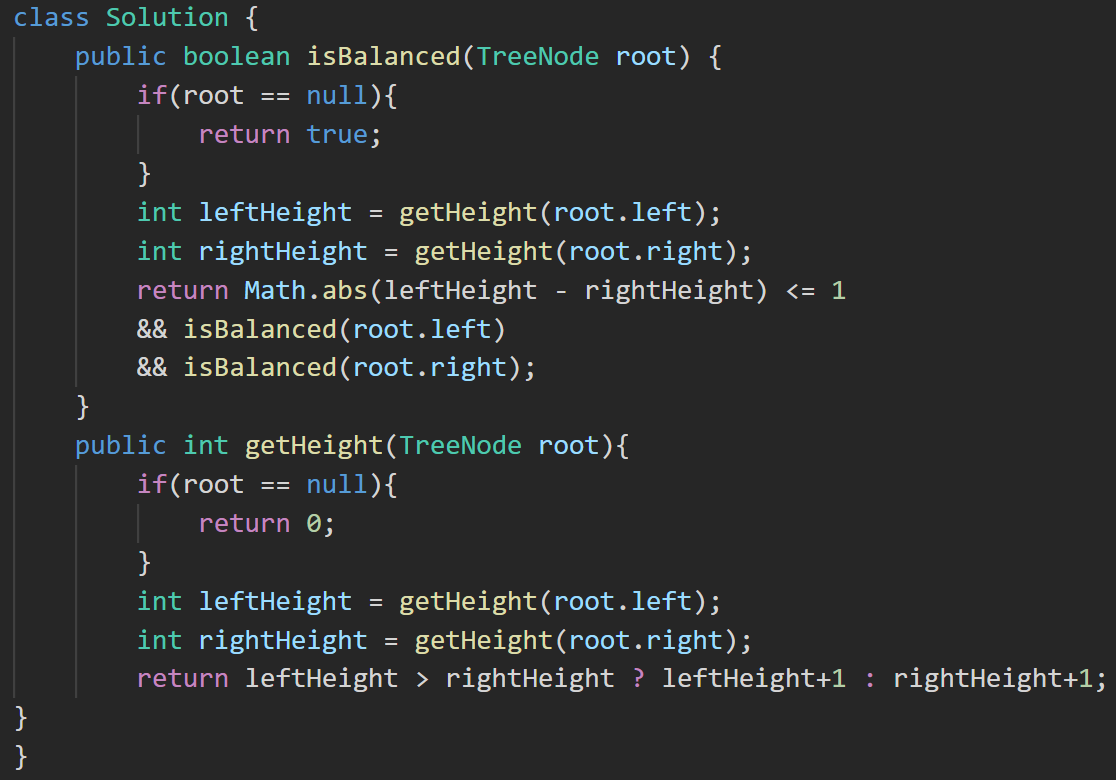
6. 94. 二叉树的中序遍历 - 力扣(LeetCode)
提示:本题是使用非递归方法实现的。
答案:
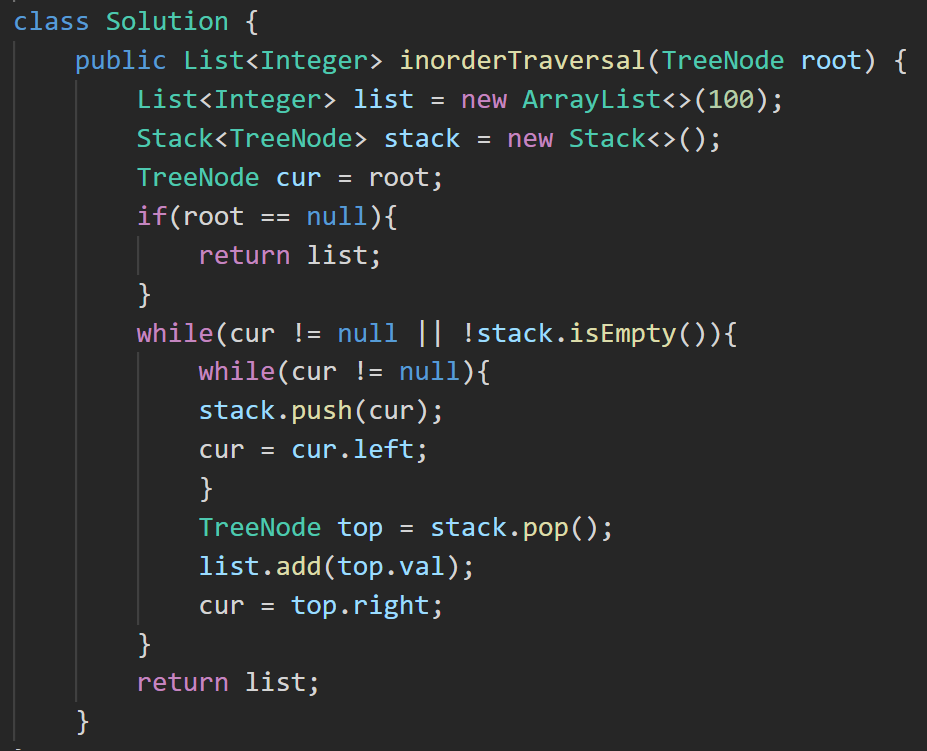
6. 102. 二叉树的层序遍历 - 力扣(LeetCode)【本题开始会需要一些脑回路】
思路:
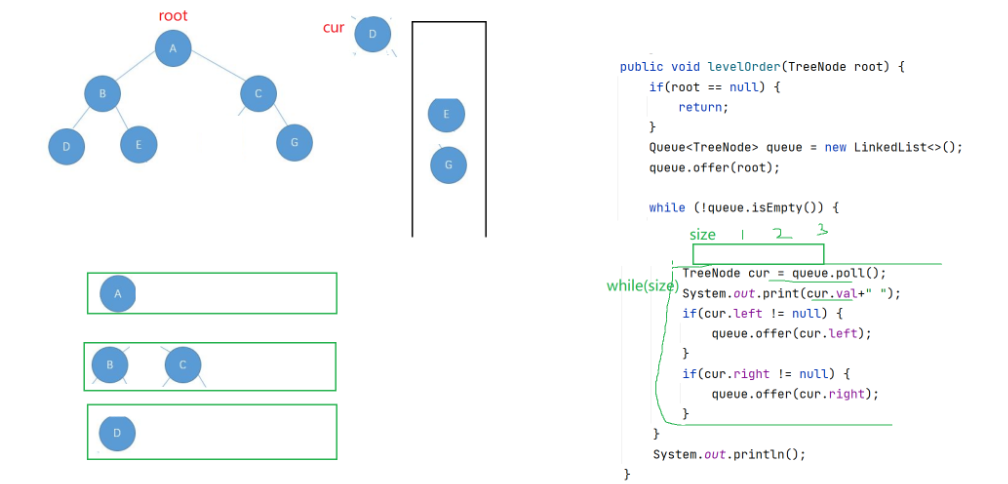
答案:
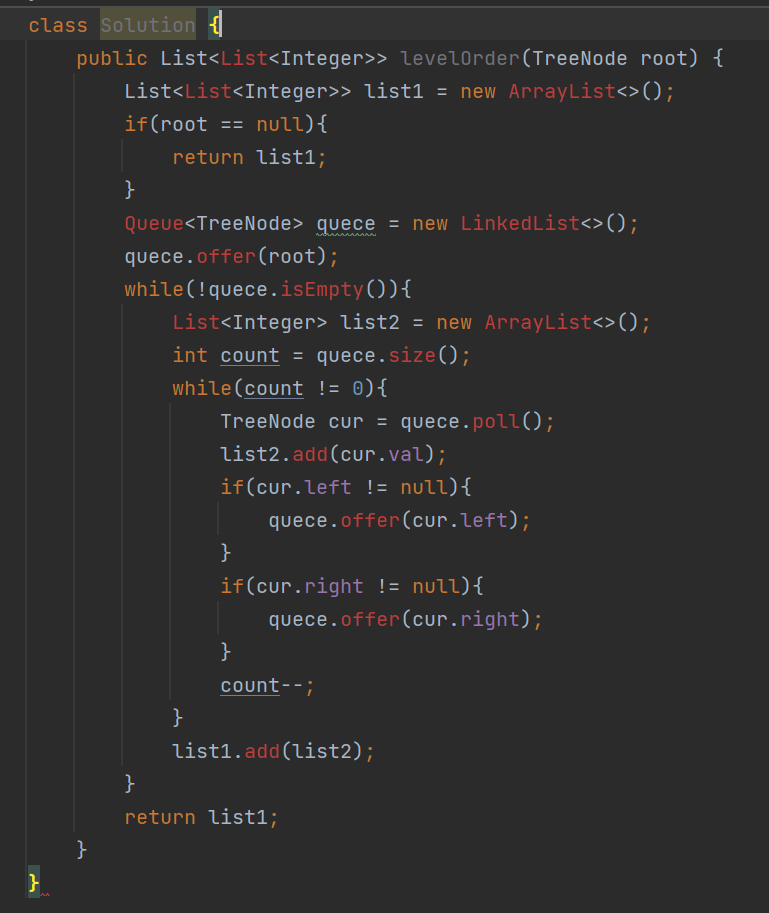
那么,本篇文章到此结束!
本篇文章的截图部分摘自于比特科技 。希望能对你有帮助。



![[iOS] ViewController 的生命周期](http://pic.xiahunao.cn/[iOS] ViewController 的生命周期)





![[数据结构] 栈 · Stack](http://pic.xiahunao.cn/[数据结构] 栈 · Stack)









