从 PDF 中提取文本一直是很多人的需求。市面上的工具虽然能处理大部分数字 PDF,但遇到扫描件 PDF 时往往无能为力,想要直接复制或获取其中的文字并不容易。其实这个问题并不是没有解法 —— 本文将带你了解如何借助 Python + OCR 技术,从扫描 PDF 中提取可编辑文本。
为什么提取扫描件 PDF 需要用到 OCR 技术
在探讨如何从扫描件 PDF 中提取文本之前,我们先来了解一下 OCR 技术 及其重要性。
OCR(Optical Character Recognition,光学字符识别),是一种将图像或视频中的文字内容转化为可编辑文本的技术。它不仅能识别字符,还能保留一定的排版信息,因此被广泛应用在文档数字化、档案管理以及数据提取等场景中。
为什么提取扫描件 PDF 的文本离不开 OCR?原因在于 PDF 文件主要分为两类:
- 标准 PDF(数字 PDF):文档中的文字是以字符形式存储的,可以直接复制、搜索和提取。
- 扫描件 PDF:内容本质上是图片,不包含可识别的文本信息,传统的提取方法无法处理。
因此,当面对扫描件 PDF 时,OCR 技术就显得尤为必要,它能帮助我们将图片中的文字识别出来,转换为真正可操作的文本。
安装必要的 Python 库
在了解了基础知识之后,我们进入到 工具准备环节。本文将主要使用两款库:Spire.PDF for Python 和 Spire.OCR for Python。有了它们,处理扫描件 PDF 并提取文本会变得高效而简单。
- Spire.PDF:负责将扫描件 PDF 转换为适合 OCR 处理的图片。
- Spire.OCR:对这些图片进行文字识别,并输出可编辑的文本内容。
它们的安装方式十分便捷,只需在命令行中运行以下命令:
pip install spire.pdf
pip install spire.ocr
除了使用 pip 安装外,你也可以前往 E-iceblue 官网 下载相应的安装包并手动安装。
通过 Python 将 PDF 转换为图像
正如前面提到的,OCR 无法直接处理 PDF 文件,尤其是扫描件 PDF。因此,第一步我们需要先将其转换为图片。借助 Spire.PDF,这个过程十分简便:只需加载 PDF 文档,遍历页面,然后调用 PdfDocument.SaveAsImage() 方法,就能将每一页保存为图像文件。
在保存时,你还可以根据需求选择 PNG、JPG 或 BMP 等常见格式。下面的示例代码演示了如何使用 Python 将扫描件 PDF 转换为 PNG 图片:
from spire.pdf import *# 加载 PDF 文件
pdf = PdfDocument()
pdf.LoadFromFile("E:/Administrator/Python1/input/AI绘画的利与弊.pdf")# 遍历 PDF 页面
for i in range(pdf.Pages.Count):# 将每一页转换为图像with pdf.SaveAsImage(i) as image:# 保存图像image.Save(f"E:/Administrator/Python1/output/pdftoimage/ToImage_{i}.png")# image.Save(f"Output/ToImage_{i}.jpg")# image.Save(f"Output/ToImage_{i}.bmp")pdf.Close()
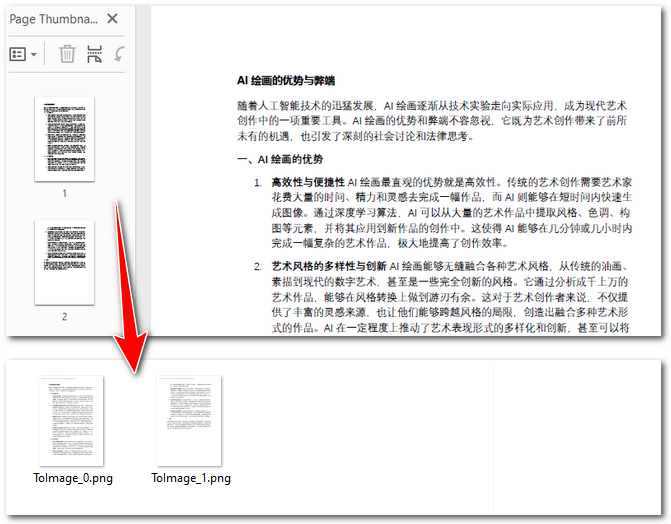
OCR 识别并提取扫描件 PDF 中的文本
完成 PDF 转图片 的步骤后,我们就可以进入核心环节——使用 OCR 扫描图片并提取文字。借助 OcrScanner.Scan() 方法,这个过程非常简单。它不仅能够从图片中获取文本,还支持包括 中文、英文、法语 在内的多种语言识别,可以做到“一字不落”。
下面的示例演示了如何在 Python 中调用 OCR,对前一步生成的 PDF 图片进行文字识别,并将结果保存为 .txt 文档:
from spire.ocr import *# 创建 OCR 扫描器实例
scanner = OcrScanner()# 配置 OCR 模型路径和语言
configureOptions = ConfigureOptions()
configureOptions.ModelPath = r'E:/DownloadsNew/win-x64/'
configureOptions.Language = 'Chinese'
scanner.ConfigureDependencies(configureOptions)# 使用 OCR 扫描图片
scanner.Scan(r'E:/Administrator/Python1/output/pdftoimage/ToImage_0.png')# 将提取的文本保存为文本文件
text = scanner.Text.ToString()
with open('E:/Administrator/Python1/output/扫描件PDF文本提取.txt', 'a', encoding='utf-8') as file:file.write(text + '\n')

结论
通过本文的示例,我们完成了从扫描件 PDF 转换为图片,再利用 OCR 技术识别并提取文本的全过程。借助 Spire.PDF for Python 和 Spire.OCR for Python,这一流程不仅简单高效,而且对多语言的支持也非常友好。如果你也在寻找快速处理扫描件 PDF 的方法,不妨尝试一下这两个库。









)
完全指南及电商销售数据TreeMap绘制实战)








