Paper:2405.16105
Github:GitHub - wengjiangwei/MambaLLIE
目录
摘要
一、介绍
二、相关工作
2.1 低光图像增强
2.2 视觉空间状态模型
三、方法
3.1 预备知识
3.2 整体流程
3.3 全局优先-局部次之状态空间块
四、实验
4.1 基准数据集与实施细节
4.2 对比实验
4.3 真实场景实验评估
低光照目标检测
用户感知研究
4.4 消融实验
五、局限性与讨论
摘要
低光照图像增强领域的最新进展主要由基于Retinex理论的学习框架主导,这些框架普遍采用卷积神经网络(CNN)和Transformer架构。然而,经典Retinex理论主要解决全局光照退化问题,却忽视了暗光条件下噪声与模糊等局部退化现象。此外,受限于有限的感受野,CNN与Transformer难以有效捕捉全局退化特征。尽管状态空间模型(SSMs)在长序列建模中展现出潜力,但在视觉数据中融合局部不变性与全局上下文时仍面临挑战。本文提出MambaLLIE——一种基于隐式Retinex感知的低光照增强框架,其核心在于全局优先-局部次之的状态空间设计。我们首先构建局部增强型状态空间模块(LESSM),通过在二维选择性扫描机制中引入增强型局部偏置,有效保留局部二维依赖关系从而优化传统SSMs。进一步提出隐式Retinex感知选择性核模块(IRSK),采用空间变化操作实现特征动态选择,通过自适应核选择过程适应不同输入特征。所设计的全局-局部状态空间块(GLSSB)以LayerNorm为核心整合LESSM与IRSK模块,使MambaLLIE能够实现全面的全局长程建模与灵活的局部特征聚合。大量实验表明,MambaLLIE在多项指标上显著优于当前最先进的CNN与Transformer方法。
一、介绍
低光照图像增强是计算机视觉领域的一项极具挑战性的任务,主要源于光照条件不足与传感器退化问题。此类退化图像通常同时存在全局可见性低下和局部色彩失真、噪声等复合缺陷,不仅影响人类视觉感知,还会对目标检测等高层视觉任务产生负面影响。
传统增强方法如直方图均衡化[1]和伽马校正[5]通过全局映射操作进行图像优化,但往往难以有效处理局部退化问题。近年来,基于卷积神经网络(CNN)与Transformer的方法逐渐占据主导地位[43, 52, 13, 31, 46, 3]。其中,CNN方法[43, 52, 13, 31, 45]通过有效聚合局部信息取得显著进展,但受限于固定感受野与权重共享策略,存在局部归纳偏差问题,导致模型对输入变化的适应性不足。另一方面,Transformer方法[46, 3, 50]借助自注意力机制建立长程依赖关系,获得更大且自适应的感受野,但其原始注意力机制的计算复杂度随输入尺寸呈平方级增长,带来显著计算负担。
近期,Mamba[8, 25, 22]在计算机视觉领域引发广泛关注。这类内部状态空间模型(SSMs)展现出线性复杂度下建模全局信息的潜力。然而,直接将视觉状态空间模型应用于低光图像增强存在明显局限——SSMs专为长程建模设计,缺乏有效捕捉局部信息的灵活性[54]。如图1所示,典型视觉状态空间模型MambaIR[14]虽相比CNN与Transformer方法具有更广的感受野,但在精细局部交互处理方面仍显不足。
本研究提出MambaLLIE创新框架,在全局优先-局部次之的状态空间模型中融合隐式Retinex感知机制。该框架不仅探索了状态空间模型在低光增强中的应用潜力,还通过Retinex感知结构提供显隐双重引导。核心创新包括:首创的全局-局部状态空间块(GLSSB),通过增强型状态空间实现全局长程退化建模与局部特征聚合;引入Retinex感知选择性核机制,借助特定空间操作实现光照强度的自适应调节。
本工作的主要贡献可归纳为三方面:
首先,提出整合局部增强状态空间模块与隐式Retinex感知选择性核模块的新型全局-局部状态空间块,有效捕捉复杂全局-局部依赖关系;
其次,设计隐式Retinex感知选择性核机制指导深层神经表征,无需复杂结构设计即可实现光照组件的自主分离与融合,突破了显式方法的局限性;
最后,在基准数据集与真实场景中的实验验证表明,本方法在各项指标上均显著优于现有最先进方法。
二、相关工作
2.1 低光图像增强
低光照图像增强方法当前主要可分为端到端学习与基于Retinex理论的两大范式[21]。LLNet[27]率先通过监督学习将深度神经网络应用于该任务,开创性地构建了端到端增强框架。LightenNet[2]基于卷积神经网络(CNN)实现单图像对比度增强,而MBLLEN[29]通过多分支CNN架构融合丰富特征。SNR-Net[46]、Restormer[50]、LLFormer[18]及文献[30]等方法则引入自注意力机制,显著提升了模型性能。然而,这类端到端模型主要依赖训练数据分布,忽视了内在的光照先验信息。
相比之下,ZeroDCE[13]、RUAS[24]及其后续改进方法[31,7,41]通过精准建模物理先验实现图像增强,展现出独特优势。但由于缺乏理想参考指导,其性能与监督学习方法仍存在差距。
在监督式Retinex模型中,主流方法通过将图像分解为光照图与反射图进行优化增强。Retinex-Net[43]开创性地将增强流程划分为分解、调整与重建三个阶段,为后续研究奠定基础。KinD[52]与URetinex-Net[45]分别提出创新性多分支架构与多阶段框架,但在模型复杂度与计算效率间的平衡仍面临挑战。近期,RetinexFormer[3]采用高效Transformer实现单阶段Retinex增强,Diff-Retinex[49]则结合Transformer分解网络与生成扩散模型进行结果重建。尽管这些方法持续推进Retinex理论的应用,但其直接套用经典Retinex框架的做法仍存在固有局限性。
2.2 视觉空间状态模型
视觉状态空间模型。状态空间模型(State Space Models, SSMs)[11,10,9]作为新兴序列建模方法,最初在自然语言处理(NLP)领域取得突破性进展,成功应用于语言理解[35]、内容推理[54]等任务。近年来,该模型在计算机视觉(CV)领域也引发广泛研究。S4ND[32]率先将状态空间机制引入CV任务,通过将传统模型中的Conv2D层与自注意力层替换为S4ND模块实现创新。VMamba[25]通过弥合有序序列与视觉图像的非因果性鸿沟,构建具有全局感受野的视觉选择性状态空间模型。Vim[53]提出具有位置感知能力的双向状态空间建模,实现了全局视觉感知。LocalMamba[15]专注于局部扫描策略以保持上下文依赖关系,而EfficientVMamba[34]通过增加卷积分支设计轻量化SSMs,同步学习全局与局部表征特征。MambaIR[14]则结合卷积与通道注意力机制增强模型能力。然而,现有视觉状态空间模型对局部信息捕捉仍显不足,因其原始SSMs专为长序列设计,未能充分考虑视觉数据固有的局部不变性特征。
三、方法
本研究致力于构建一种融合全局优先-局部次之状态空间架构的隐式Retinex感知低光照增强框架。本节首先对Retinex理论与状态空间模型进行理论溯源与框架概览,继而系统阐述所提出的MambaLLIE方法的技术细节。
3.1 预备知识
Retinex理论。经典Retinex理论[20]将低光照图像建模为反射率图与光照图的乘积分解。如文献[31,37]所述,显式Retinex方法主要遵循两种范式:其一仅估计光照图并将反射率图直接作为增强结果;其二同步估计反射率与光照图并通过优化重建正常光照图像。具体而言,给定低光照图像(H、W分别表示图像高度与宽度),其数学表达可形式化为:
其中⊙表示逐元素乘法,反射率图表征物体的固有属性,光照图
描述光照条件,
为重建的正常光照图像,
与
分别为估计的反射率与光照图。
第一种范式忽略了传感器退化导致的噪声与伪影,且逐像素光照调整策略存在固有局限性;第二种范式虽能通过双图优化提升增强效果,但需设计复杂的多分支网络架构与约束条件指导模型训练[52]。
状态空间模型。以结构化状态空间序列模型(S4)[10]与 Mamba[8]为代表的状态空间模型(SSMs),本质上是连续线性时不变(LTI)系统[44]的数学抽象。给定一维输入序列x(t)∈R,系统通过隐状态将其映射为输出序列y(t)∈R,其连续形式可表示为线性常微分方程(ODE):
h'(t) = Ah(t) + Bx(t)
y(t) = Ch(t) + Dx(t)
其中m为状态维度, 为状态矩阵,
与
分别为输入/输出投影矩阵,D∈R为直通参数。
由于原始SSMs为连续系统,实际计算需通过零阶保持器(ZOH)将其离散化。具体而言,将连续参数{A,B}转换为离散参数{}:
其中Δ为步长参数。离散化后系统方程可改写为:
然而,上述系统对输入变化缺乏动态适应性。为此,Mamba[8]提出选择性状态空间模型,使参数随输入动态调整:
![]()
其中、
与
为线性投影函数,将输入特征扩展至隐状态维度。虽然SSMs擅长长序列建模,但其在捕捉复杂局部信息方面存在固有局限。针对视觉数据,VMamba[25]与Vim[53]提出位置感知扫描策略以保持图像二维结构完整性,但其定向序列扫描机制仍忽略了像素邻域的空间关联特性。受文献[54]启发,本研究构建全局优先-局部次之状态空间,通过先验全局感知引导局部细节补充,有效弥补现有模型在局部信息建模方面的不足。
3.2 整体流程
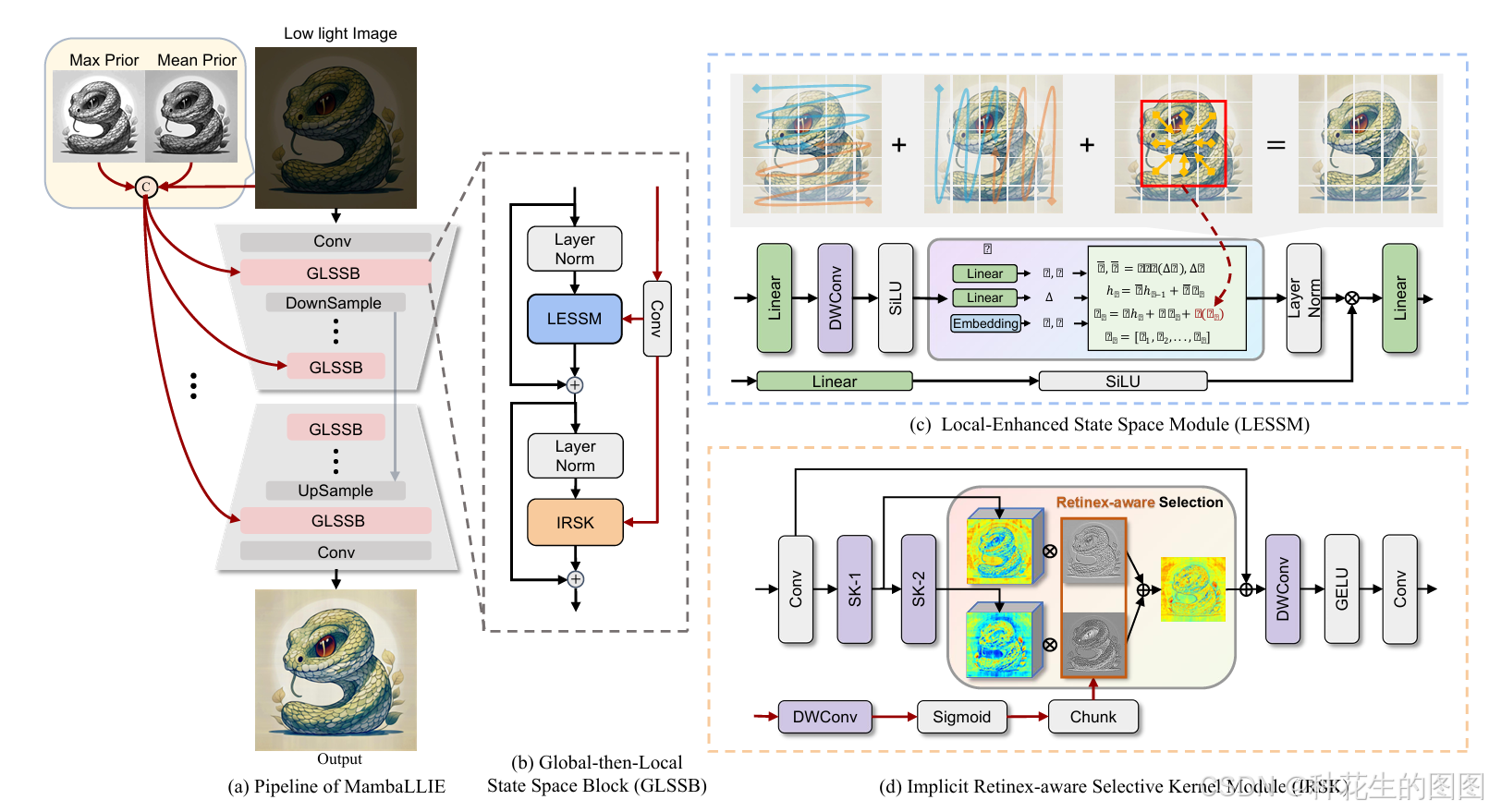
MambaLLIE整体架构。如图2(a)所示,本框架采用经典U型编解码结构,主要由卷积下采样层、全局-局部状态空间块(GLSSB)与上采样层构成。编码器通过跳跃连接与对称解码器进行特征融合,其核心创新体现于以下设计:
给定低光照图像,首先通过3×3卷积层提取初始特征
。进一步将图像均值先验
与最大值先验
拼接为增强输入
:
GLSSB核心模块作为框架基本单元,每个GLSSB包含局部增强型状态空间模块(LESSM)与隐式Retinex感知选择性核模块(IRSK),其间通过LayerNorm层进行特征规整。增强输入 经卷积投影后输入GLSSB,输出特征记为
。
通过三级下采样操作(i=0,1,2)逐级提取深层特征,其维度变化遵循。对称上采样层通过跳跃连接融合编码器-解码器对应尺度特征,最终经3×3卷积输出残差特征
。
增强图像通过实现端到端重建,有效保留原始图像低频信息。
3.3 全局优先-局部次之状态空间块
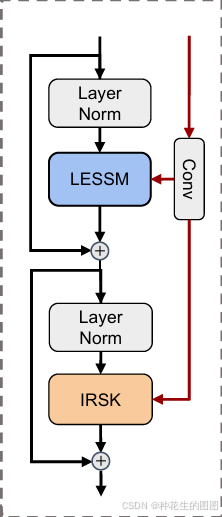
如图2(b)所示,全局-局部状态空间块(GLSSB)遵循"层归一化→LESSM→层归一化→IRSK"的级联结构,其设计灵感源于Transformer[38]与Mamba[8]的基础模块构建范式。给定输入特征,其处理流程可形式化描述如下:
通过层归一化(LayerNorm)与局部增强型状态空间模块(LESSM)实现全局依赖建模:
再次应用层归一化后,由隐式Retinex感知选择性核模块(IRSK)实现局部特征自适应调节:
局部增强型状态空间模块。现有状态空间模型[6,10,8]擅长捕捉长程依赖中的因果处理特性,但其单向扫描机制难以建模视觉数据的非因果关系。尽管[53,25,34]等研究通过多方向2D扫描策略改进视觉数据处理,但这些方法仍忽视视觉数据的局部不变性——固定扫描模式会扩大邻域数据的空间距离并扰乱因果关联。
如图2(c)所示,我们在传统连续线性时不变系统框架下引入增强型局部偏置项,通过保持局部二维依赖性优化状态空间模型。改进后的系统方程可表述为:
其中为独立于隐状态空间的局部偏置项。具体实现时,给定特征
与光照特征
,模型通过层归一化与LESSM模块整合空间长程依赖。参照[8]的设计,输入特征被拆分为
和
两个分支进行处理。第一分支通过线性层投影后执行深度可分离卷积与SiLU激活函数,随后注入增强型局部偏置并进行层归一化;第二分支则通过线性层投影与SiLU激活函数处理。最终,两分支特征通过逐元素乘积实现交互,并由线性层投影回原始特征空间。该过程可形式化描述为:
隐式Retinex感知选择性核模块。本研究进一步构建隐式Retinex感知选择性核网络以增强特征整合能力。如图2(d)所示,IRSK模块通过可调卷积核构建多尺度深度卷积序列,基于光照先验实现空间选择性特征筛选。受LSKNet[23]启发,对每个选择性核输出的特征图施加Sigmoid激活函数,从光照先验中提取独立光照图。该过程可形式化描述为:
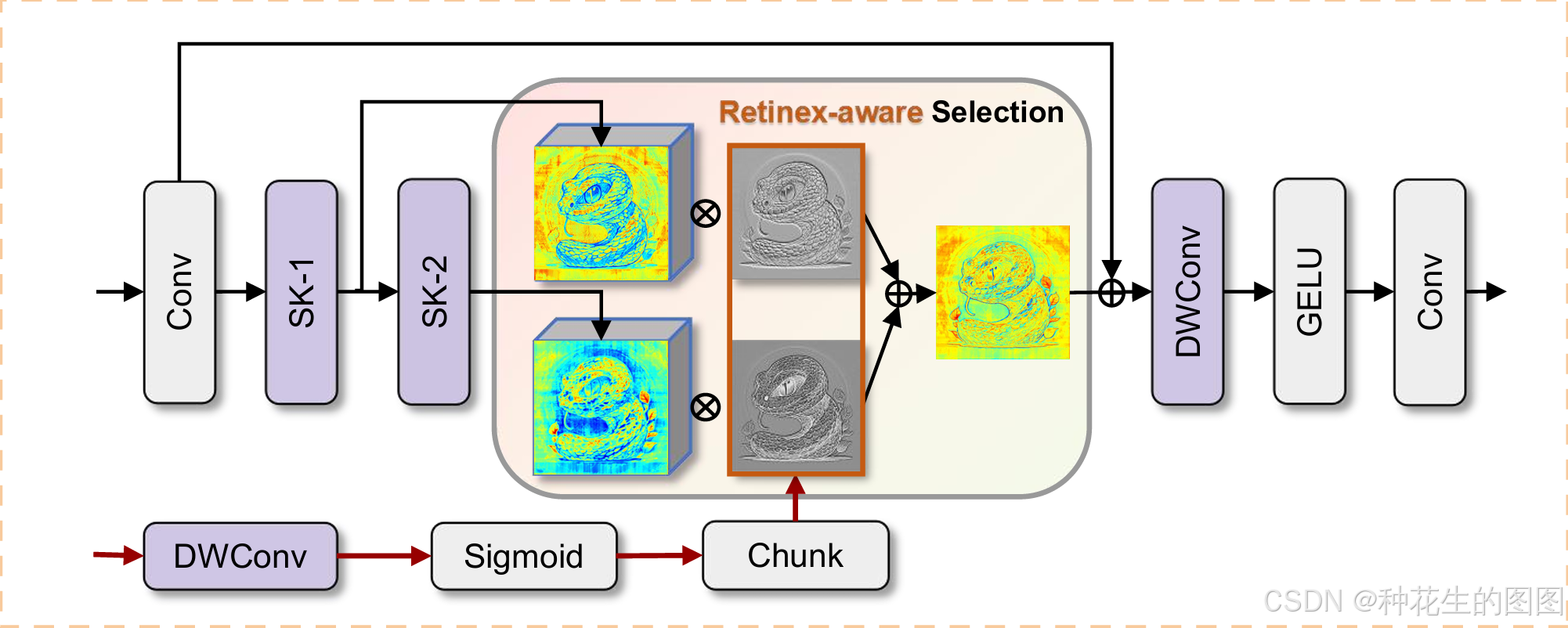
"SK-1"和"SK-2"分别代表 选择性核分支(Selective Kernel Branch 1 和 Branch 2)
通过残差连接将Retinex感知图与输入特征拼接后,依次执行深度卷积、GELU激活函数与标准卷积操作。具体实现流程包含两个关键步骤:
-
光照图分离:将光照先验特征经卷积与Sigmoid激活分解为双通道权重图
-
特征自适应融合:通过加权求和实现多尺度特征选择
四、实验
4.1 基准数据集与实施细节
数据集。实验采用五个成对低光照数据集进行评估:LOL-V2-real[48]、LOL-v2-syn[48]、SMID[4]、SDSD-indoor[39]与SDSD-outdoor[39]。其中,LOL-V2-real包含689对真实低光-正常光训练样本及100对测试样本;LOL-v2-syn提供900对合成训练样本与100对测试样本;SMID数据集包含15,763对短曝光-长曝光训练图像及其余测试样本;SDSD-indoor与SDSD-outdoor均选自SDSD静态数据集,分别包含62对室内场景与116对室外场景训练样本,以及6对室内与10对室外测试样本。
实施细节。基于PyTorch[33]框架在NVIDIA 4090 GPU服务器上实现MambaLLIE。训练阶段将图像对随机裁剪为128×128图像块作为输入,采用旋转与翻转等数据增强策略,批次大小设为8。优化过程采用Adam[19]优化器(β₁=0.9,β₂=0.999),总迭代次数为1.5×10⁵。初始学习率设为2×10⁻⁴,并通过余弦退火策略逐步衰减。损失函数选用平均绝对误差(MAE),评估指标采用峰值信噪比(PSNR)与结构相似性(SSIM)[42]。
4.2 对比实验
定量对比分析。如表1所示,本研究将MambaLLIE与11种最先进的图像增强方法进行性能对比,包括RetinexNet[43]、DeepUPE[40]、SID[4]、KinD[52]、MIRNet[51]、EnGan[17]、Restormer[50]、SNR-Net[46]、QuadPrior[41]、MambaIR[14]及RetinexFormer[3]。实验结果表明:
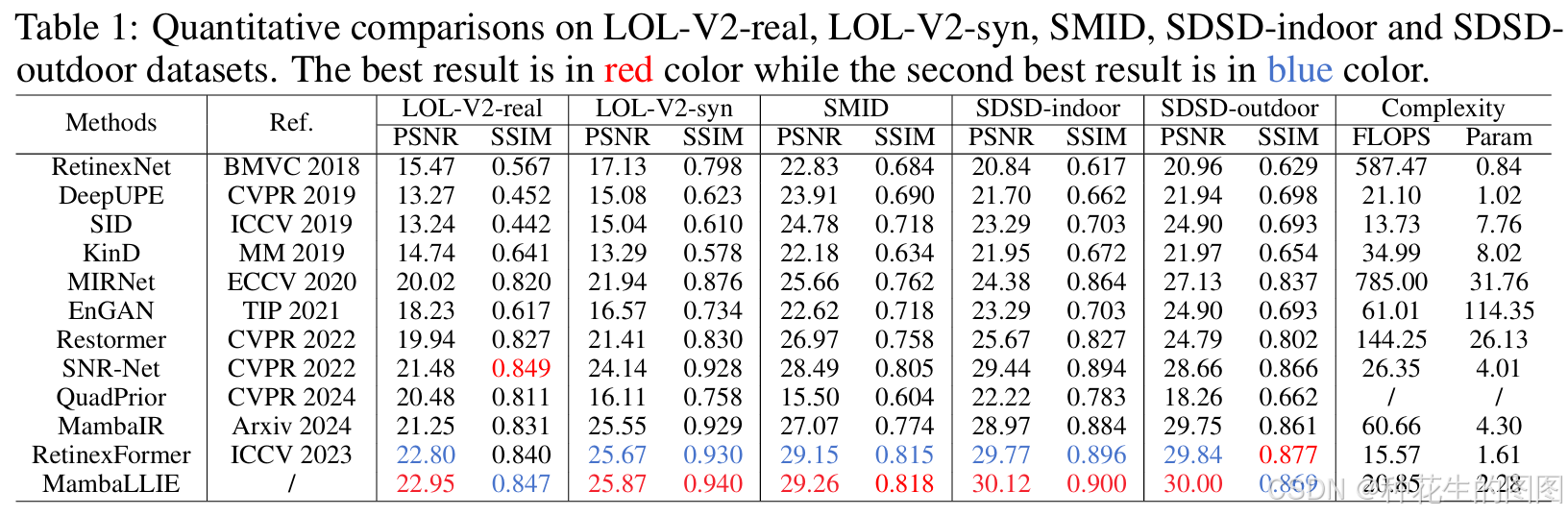
MambaLLIE在PSNR(峰值信噪比)与SSIM(结构相似性)指标上全面超越现有方法。在LOL-V2-real与SDSD-outdoor数据集上,其SSIM指标与最优方法持平。
参数量相近的情况下,MambaLLIE较基于Transformer的最优方法RetinexFormer平均提升0.2 dB,较早期Transformer方法SNR-Net在全数据集平均提升1 dB。
MambaLLIE在五个基准数据集上的PSNR提升分别为:1.70 dB(LOL-V2-real)、0.32 dB(LOL-V2-syn)、2.19 dB(SMID)、1.15 dB(SDSD-indoor)与0.25 dB(SDSD-outdoor)。
相较RetinexNet、DeepUPE及KinD等传统Retinex模型,MambaLLIE在所有数据集上的PSNR提升均超过7 dB,验证了深度学习框架的显著优势。
定性对比分析。图3-4展示了MambaLLIE与最新方法的视觉对比结果:

现有方法普遍存在光照补偿不足问题(图3),无法有效恢复暗部细节。例如,RetinexNet在极低光区域产生色块伪影,而SNR-Net则出现局部过曝。图4所示,传统方法易引发色彩失真(如KinD的绿色偏移)与细节模糊(如MambaIR的纹理丢失)。MambaLLIE则通过隐式Retinex感知机制,在提升整体亮度的同时,忠实保持颜色真实性(与Ground Truth色彩分布一致),并精细恢复毛发纹理、建筑边缘等高频细节。对于传感器噪声与运动模糊共存的场景(如SMID数据集),MambaLLIE展现出更强的退化解耦能力,相较Diff-Retinex的扩散模型方案,其重建结果噪声抑制更彻底且细节更锐利。
4.3 真实场景实验评估
低光照图像增强在真实场景中面临双重挑战:需同时提升下游任务(如暗光目标检测)性能并满足人类视觉感知需求。本节通过两项实验验证MambaLLIE的实际应用价值。
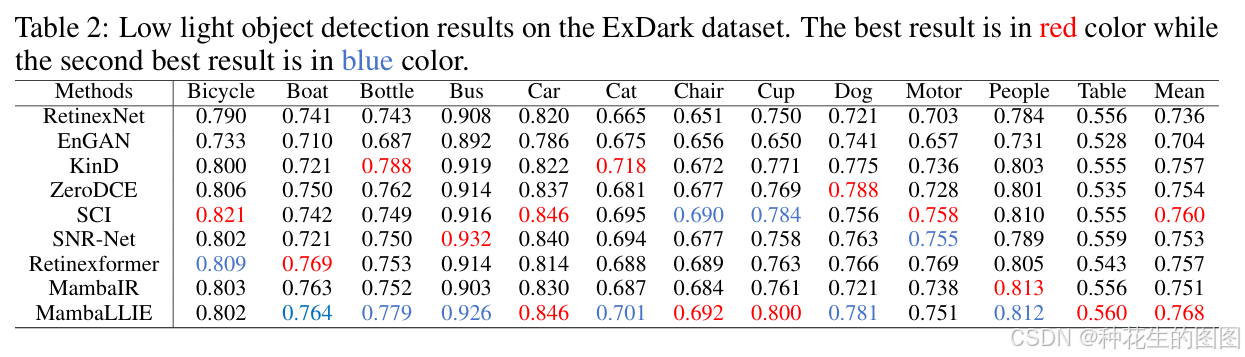
低光照目标检测
采用ExDark数据集[26]评估增强算法对高层视觉任务的增益。该数据集包含7,363张标注12类边界框的低光图像(5,890张训练/1,473张测试)。所有监督方法均在LOL-V2-syn数据集预训练后,通过不同增强方法处理低光图像,并以YOLOv3[36]作为目标检测器进行微调。
如表2所示,MambaLLIE在平均精度(mAP)上优于所有对比方法,尤其在车辆(Car)、椅子(Chair)、杯子(Cup)与桌子(Table)类别中表现最佳。图5(a)的视觉对比表明:相较于次优方法SCI,MambaLLIE增强后的图像使检测器能在极暗区域(如两人与椅子的场景)成功定位目标,而其他方法均失效。

用户感知研究
为评估增强结果的人类视觉感知质量,本研究开展用户调研。从基准数据集与ExDark数据集中随机选取7张不同光照条件的低光图像,使用各方法预训练模型进行增强。70名参与者从以下维度进行1(最差)至5(最优)评分:
-
整体视觉效果(光照均衡性、自然度)
-
局部细节保留(纹理清晰度、边缘锐度)
-
色彩失真与噪声(颜色保真度、伪影抑制)
如表3所示,MambaLLIE在所有评分维度均获最高分。图5(b)展示典型样例对比:相较于其他算法,MambaLLIE增强结果在保持色彩自然的同时,显著提升暗部细节(如树叶纹理、建筑窗格结构),且无过曝或色偏现象。

4.4 消融实验
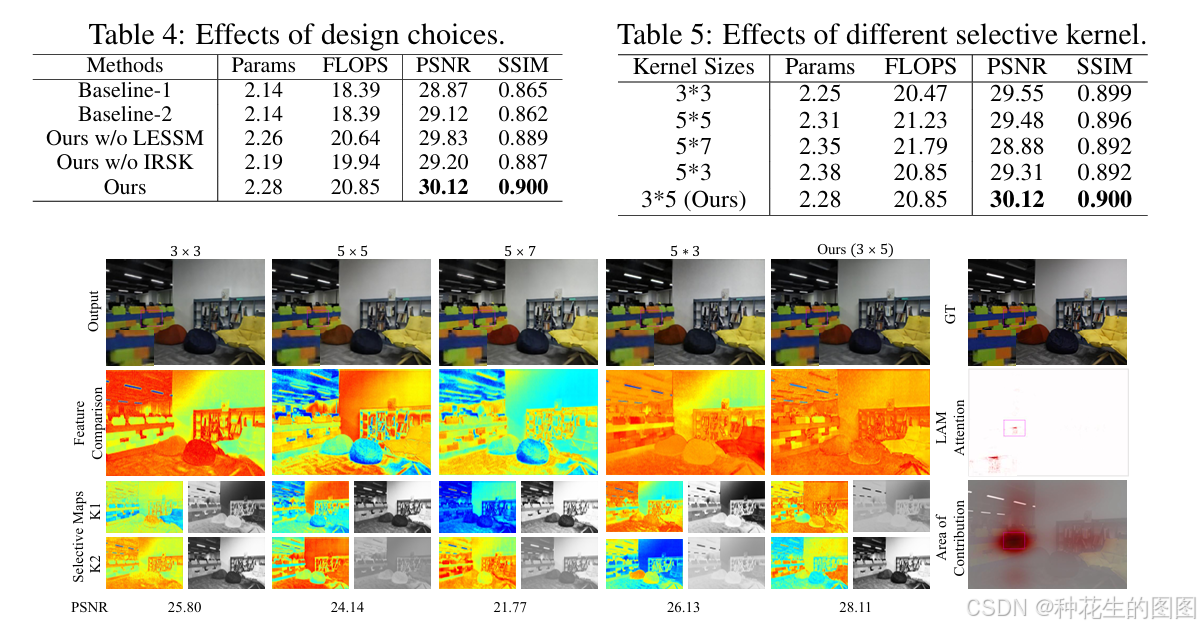
隐式Retinex感知框架对比。本研究通过对比端到端模型、显式Retinex模型与隐式Retinex框架验证方法有效性。具体而言:
-
Baseline-1:移除Retinex感知引导机制,直接通过输入估计增强结果
-
Baseline-2:显式估计光照图并通过逐元素乘法调整亮度
如表4所示,隐式Retinex框架较Baseline-1在PSNR指标上提升1.25 dB,较Baseline-2提升1.00 dB,验证隐式引导机制在退化建模中的优势。
全局-局部状态空间消融分析。针对GLSSB核心组件LESSM与IRSK进行模块级验证:
-
LESSM效果:相比使用原始状态空间块的Baseline-1与Baseline-2,LESSM分别带来0.33 dB与0.08 dB的PSNR提升,证明局部增强偏置对空间建模的有效性
-
IRSK效果:IRSK模块相较原始SSM提升0.96 dB(Baseline-1)、0.74 dB(Baseline-2)与0.63 dB(单LESSM配置),表明选择性核机制对特征融合的关键作用
-
联合效能:当LESSM与IRSK协同工作时,MambaLLIE取得最高PSNR(28.45 dB)与SSIM(0.923),验证全局-局部协同设计的必要性
选择性核行为分析。如图6所示,隐式Retinex感知机制通过互补特征学习正负光照分量:
-
核选择模式:IRSK在浅层优先使用小核(3×3)聚焦局部细节,深层采用大核(5×5)实现跨区域特征融合,避免传统检测任务中大核引发的边缘填充问题
-
与LSKNet对比:LSKNet[23]采用递增核尺寸策略以适应检测任务的大感受野需求,但图像增强任务中连续填充会加剧边缘伪影。MambaLLIE的逆向核尺寸设计(小→大)既可快速捕获局部信息,又能通过深层大核实现全局特征整合
五、局限性与讨论
本研究通过隐式Retinex感知引导与全局-局部状态空间框架,有效解决了低光增强中的全局光照不足与局部退化问题,但仍存在以下局限性:
-
先验依赖性:相较于端到端方法,本框架需设计合理的光照先验(如均值/最大值先验),其性能部分依赖于先验经验。在极端场景(如全黑区域占比超过80%),先验估计可能失效,需结合语义信息优化。
-
评估指标偏差:现有增强模型(包括本工作)多以均方误差(MSE)为损失函数,依赖PSNR/SSIM作为评价指标。然而,这些指标与人类视觉感知存在固有偏差。为此,我们通过真实场景实验(目标检测任务与用户调研)补充验证方法的实用性,缓解指标局限性。
未来工作将探索:
-
自监督先验学习:通过对比学习框架自动提取场景自适应光照先验,降低人工设计依赖性
-
感知驱动优化:引入无参考图像质量评估指标(如NIQE)联合训练,增强模型对人类视觉偏好的适应性




基础功能与xml使用)











)


