DataX 是一个异构数据源离线同步(ETL)工具,实现了包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。它也是阿里云 DataWorks 数据集成功能的开源版本。
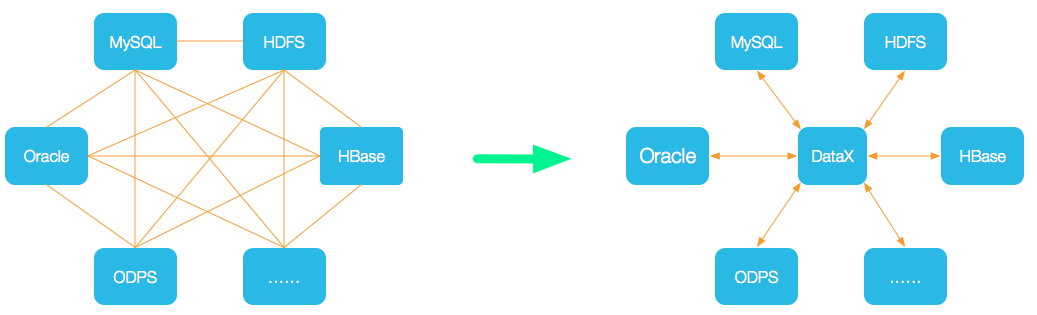
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,便能跟已有的数据源做到无缝数据同步。
体系原理
DataX 本身作为离线数据同步框架,采用 Framework + Plugin 架构构建。将数据源读取和写入抽象成为 Reader/Writer 插件,纳入到整个同步框架中,如下图所示:

其中,
- Reader:Reader 为数据采集模块,负责采集数据源的数据,将数据发送给 Framework 模块。
- Framework:Framework 用于连接 Reader 和 Writer,作为两者的数据传输通道,并处理缓冲、流控、并发、数据转换等核心技术问题。
- Writer: Writer 为数据写入模块,负责不断地向 Framework 获取数据,并将数据写入到目的端。
DataX 开源版本支持单机多线程模式完成同步作业运行,以下是一个 DataX 作业生命周期的时序图:
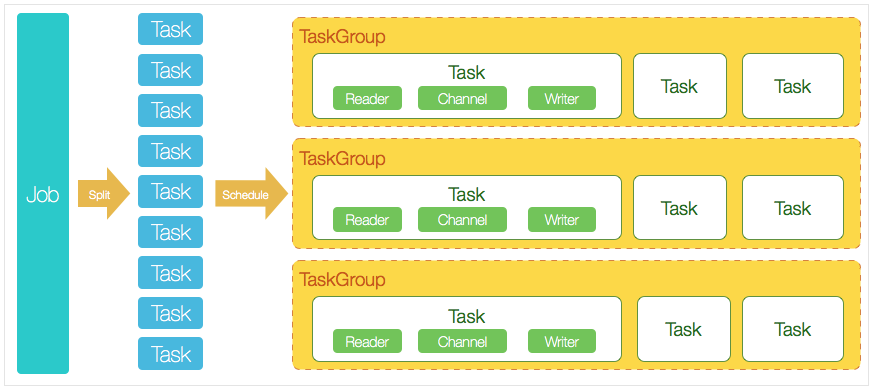
其中涉及的核心模块和流程如下:
- DataX 完成单个数据同步的作业称之为 Job,DataX 接受到一个 Job 之后,将启动一个进程来完成整个作业同步过程。DataX
Job 模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子 Task)、TaskGroup 管理等功能。 - DataX Job启动后,会根据不同的源端切分策略,将 Job 切分成多个小的 Task(子任务),以便于并发执行。Task 是作业的最小单元,每一个 Task 都会负责一部分数据的同步工作。
- 切分多个 Task 之后,DataX Job会调用 Scheduler 模块,根据配置的并发数据量,将拆分成的 Task 重新组合,组装成 TaskGroup(任务组)。每一个 TaskGroup 负责以一定的并发运行完毕分配好的所有 Task,默认单个任务组的并发数量为 5。
- 每一个 Task 都由 TaskGroup 负责启动,Task 启动后,会固定启动 Reader—>Channel—>Writer 的线程来完成任务同步工作。
- DataX 作业运行起来之后,Job 监控并等待多个 TaskGroup 模块任务完成,等待所有 TaskGroup 任务完成后 Job 成功退出。否则,异常退出,进程退出值为非零。
举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100 张分表的 MySQL 数据同步到 MaxCompute 里面。 DataX 的调度决策思路是:DataX Job 根据分库分表切分成了 100 个子任务;根据 20 个并发,DataX 计算共需要分配 4 个 TaskGroup;4个任务组平分切分好的 100 个子任务,每一个任务组负责以 5 个并发共计运行 25 个子任务。
数据源
经过多年的积累,DataX 目前已经有了比较全面的插件体系,主流的 RDBMS 数据库、NOSQL、大数据计算系统都已经接入。DataX 目前支持数据如下:
- 关系型数据库:包括 MySQL、Oracle、OceanBase、SQL Server、PostgreSQL、DRDS、金仓、高斯以及通用的 RDBMS 等;
- 阿里云数仓数据存储:包括 MaxCompute、AnalyticDB for MySQL、ADS、OSS、OCS、Hologres、AnalyticDB for PostgreSQL 等;
- 阿里云中间件:数据总线 DataHub、日志服务 SLS;
- 图数据库:阿里云 Graph Database、Neo4j;
- NoSQL:阿里云 OTS、Hbase、Phoenix、MongoDB、Cassandra 等;
- 数仓数据存储:StarRocks、Apache Doris、ClickHouse、Databend、Hive、SelectDB 等;
- 无结构化数据存储:TxtFile、FTP、HDFS、Elasticsearch;
- 时序数据库:OpenTSDB、TSDB、TDengine。
DataX 框架提供了简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。插件开发可以参考以下文章:
https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md
快速体验
通过 GitHub 或者直接输入以下网址下载 DataX 工具包:
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
解压之后进入 bin 目录即可运行作业,作业通过配置文件进行设置,可以通过以下命令查看配置模板:
$ cd {YOUR_DATAX_HOME}/bin$ python datax.py -r streamreader -w streamwriter
DataX (UNKNOWN_DATAX_VERSION), From Alibaba !
Copyright (C) 2010-2015, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document:https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "streamreader", "parameter": {"column": [], "sliceRecordCount": ""}}, "writer": {"name": "streamwriter", "parameter": {"encoding": "", "print": true}}}], "setting": {"speed": {"channel": ""}}}
}
其中,-r 用于指定 Reader,-w用于指定 Writer,示例中两个都是 streamreader。安装目录下的 plugin 子目录包含了所有的 Reader 和 Writer。
job 目录提供了一个默认的作业配置 job.json,使用以下命令运行示例作业:
$ python datax.py ../job/job.json2025-05-17 15:00:02.135 [job-0] INFO JobContainer -
任务启动时刻 : 2025-05-17 15:00:02
任务结束时刻 : 2025-05-17 15:00:22
任务总计耗时 : 20s
任务平均流量 : 545/s
记录写入速度 : 5000rec/s
读出记录总数 : 100000
读写失败总数 : 0
其他类型的数据源也可以按照相同的方式进行配置。
除了使用命令行和配置文件的方式运行作业之外,还可以通过图形化的调度工具(例如 DataX-Web、Apache DolphinScheduler)进行管理。

)








线性表-链表-单链表)

)
)





流编辑器系统)