需求
实现一个HA mysql,包括1个master,2个slave。在K8S上已statefulset部署。
mysql HA原理
略
K8S环境需要解决的问题
1、由于使用同一个statefulset配置,因此需要考虑master和slave使用不同的cnf文件。
2、不同pod之间文件的传输
3、容器重启之后,有些状态不能改变。
K8S部署
configmap
apiVersion: v1
kind: ConfigMap
metadata:name: mysqllabels:app: mysql
data:master.cnf: |# Apply this config only on the master.[mysqld]log-binslave.cnf: |# Apply this config only on slaves.[mysqld]super-read-only
master.cnf用于master节点,slave.cnf用于slave节点。
service
#写要通过mysql-0来写
apiVersion: v1
kind: Service
metadata:name: mysqllabels:app: mysql
spec:ports:- name: mysqlport: 3306clusterIP: None #与service不同selector:app: mysql
---
#用于读
apiVersion: v1
kind: Service
metadata:name: mysql-readlabels:app: mysql
spec:ports:- name: mysqlport: 3306selector:app: mysql
statefulset
apiVersion: apps/v1
kind: StatefulSet
metadata:name: mysql
spec:selector:matchLabels:app: mysqlserviceName: mysqlreplicas: 3template:metadata:labels:app: mysqlspec:
#----------------初始化容器部分----------------- initContainers: //pod初始化阶段,第一个初始化容器#=============== 初始化mysql- name: init-mysqlimage: reg.westos.org/k8s/mysql:5.7command:- bash- "-c"- |set -ex# 通过hostname创建 mysql server-id 。[[ `hostname` =~ -([0-9]+)$ ]] || exit 1ordinal=${BASH_REMATCH[1]}echo [mysqld] > /mnt/conf.d/server-id.cnf# Add an offset to avoid reserved server-id=0 value.echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf# 根据pod序号从configmap拷贝不同cnfif [[ $ordinal -eq 0 ]]; thencp /mnt/config-map/master.cnf /mnt/conf.d/elsecp /mnt/config-map/slave.cnf /mnt/conf.d/fivolumeMounts:- name: conf #emptyDir保证每次启动pod都会重新生成,这样每次configmap都会生效。mountPath: /mnt/conf.d- name: config-mapmountPath: /mnt/config-map#==========拷贝数据文件 - name: clone-mysql //第二个初始化容器,主从复制image: reg.westos.org/k8s/xtrabackup:1.0command:- bash- "-c"- |set -ex# 数据已存在则退出.[[ -d /var/lib/mysql/mysql ]] && exit 0# master节点 直接退出 (ordinal index 0).[[ `hostname` =~ -([0-9]+)$ ]] || exit 1ordinal=${BASH_REMATCH[1]}[[ $ordinal -eq 0 ]] && exit 0# 从其他节点(前一个节点)拷贝数据文件. 仅接收数据,接收完数据就退出。ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql# 准备备份为后面的节点服务.xtrabackup --prepare --target-dir=/var/lib/mysqlvolumeMounts:- name: datamountPath: /var/lib/mysqlsubPath: mysql- name: confmountPath: /etc/mysql/conf.d
#--------------容器定义部分-------------------- containers:#===========mysql容器- name: mysql image: reg.westos.org/k8s/mysql:5.7env:- name: MYSQL_ALLOW_EMPTY_PASSWORDvalue: "1"ports:- name: mysqlcontainerPort: 3306volumeMounts:- name: datamountPath: /var/lib/mysqlsubPath: mysql- name: confmountPath: /etc/mysql/conf.dresources:requests:cpu: 500mmemory: 1GilivenessProbe:exec:command: ["mysqladmin", "ping"]initialDelaySeconds: 30periodSeconds: 10timeoutSeconds: 5readinessProbe:exec:# Check we can execute queries over TCP (skip-networking is off).command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]initialDelaySeconds: 5periodSeconds: 2timeoutSeconds: 1#========= 备份容器 - name: xtrabackup image: reg.westos.org/k8s/xtrabackup:1.0ports:- name: xtrabackupcontainerPort: 3307command:- bash- "-c"- |set -excd /var/lib/mysql# 从备份信息文件里读取MASTER_LOG_FILEM和MASTER_LOG_POS这两个字段的值,用来拼装集群初始化SQLif [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then# 如果xtrabackup_slave_info文件存在,说明这个备份数据来自于另一个Slave节点。#这种情况下,XtraBackup工具在备份的时候,就已经在这个文件里自动生成了"CHANGE MASTER TO" SQL语句。#所以,我们只需要把这个文件重命名为change_master_to.sql.in,后面直接使用即可# 由于从slave节点拷贝,因此把最后一个分号去掉。cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in# 就用不着xtrabackup_binlog_info了,删除rm -f xtrabackup_slave_info xtrabackup_binlog_infoelif [[ -f xtrabackup_binlog_info ]]; then#如果只存在xtrabackup_binlog_inf文件,那说明备份来自于Master节点,#我们就需要解析这个备份信息文件,读取MASTER_LOG_FILEM和MASTER_LOG_POS这两个字段的值[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1#删除不用了rm -f xtrabackup_binlog_info xtrabackup_slave_infoecho "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.infi# 如果change_master_to.sql.in存在,就意味着需要做集群初始化工作if [[ -f change_master_to.sql.in ]]; then#一定要先等MySQL容器启动之后才能进行下一步连接MySQL的操作echo "Waiting for mysqld to be ready (accepting connections)"until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; doneecho "Initializing replication from clone position"# 使用change_master_to.sql.in的内容,拼装SQL,组成一个完整的初始化和启动Slave的SQL语句mysql -h 127.0.0.1 \-e "$(<change_master_to.sql.in), \MASTER_HOST='mysql-0.mysql', \MASTER_USER='root', \MASTER_PASSWORD='', \MASTER_CONNECT_RETRY=10; \START SLAVE;" || exit 1# 将文件change_master_to.sql.in改个名字,防止这个Container重启的时候,因为又找到了change_master_to.sql.in,从而重复执行一遍这个初始化流程mv change_master_to.sql.in change_master_to.sql.origfi#使用ncat监听3307端口。它的作用是,在收到传输请求的时候,直接执行"xtrabackup --backup"命令,备份MySQL的数据并发送给请求者exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"volumeMounts:- name: datamountPath: /var/lib/mysqlsubPath: mysql- name: confmountPath: /etc/mysql/conf.dresources:requests:cpu: 100mmemory: 100Mivolumes:- name: confemptyDir: {}- name: config-mapconfigMap:name: mysql
#---------------数据持久化部分----------------- volumeClaimTemplates:- metadata:name: dataspec:accessModes: ["ReadWriteOnce"]resources:requests:storage: 10Gi
原理
部署结构
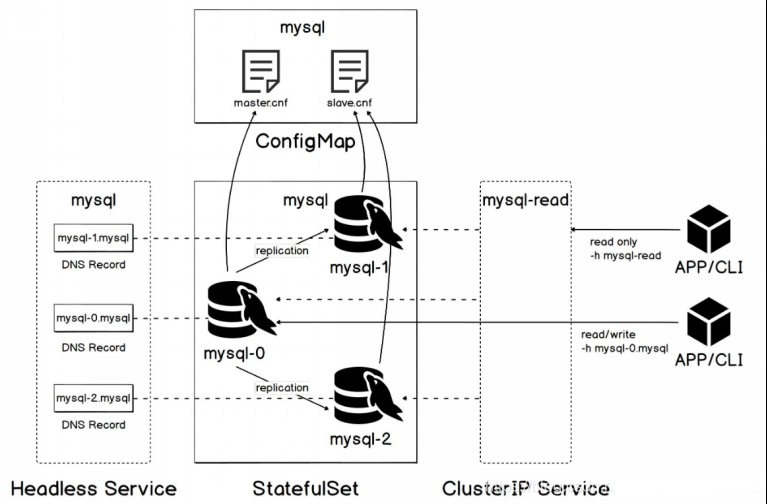
使用statefulset部署pod,headless service 访问服务。service 访问read节点。
init-mysql容器
init-mysql容器主要用于根据节点的类型不同生成server-id和拷贝cnf文件。
容器使用的目录是容器内部的目录,因此每次启动pod,容器都会重新创建。server-id不会变。
clone-mysql容器
容器主要用于从其他节点拷贝数据文件到 slave节点。
mysql容器
mysql运行容器。
xtrabackup容器
备份还原工具
共享目录
conf 目录 挂载在init-mysql容器的/mnt/conf.d目录,clone-mysql容器的/etc/mysql/conf.d目录,,mysql容器的/etc/mysql/conf.d目录。通过此方式实现数据文件共用。
ncat
说起ncat我们不得不说一下Netcat。Netcat用于从TCP/UDP连接中读取或发送网络数据。cat是Linux中查看或连接文件的命令,所以netcat本意为从网络上查看文件内容。
镜像说明
-
reg.westos.org/k8s/mysql:5.7
-
reg.westos.org/k8s/xtrabackup:1.0
备份还原镜像
探针
mysql容器探针
livenessProbe:mysqladmin ping
readinessProbe:mysql -h 127.0.0.1 -e "SELECT 1 "
附录
参考
mysql主从搭建:https://blog.csdn.net/demon7552003/article/details/124728616
xtrabackup原理:https://blog.csdn.net/ChenVast/article/details/72594055,https://blog.csdn.net/yu891203/article/details/106758822
ncat详细介绍:https://blog.csdn.net/demon7552003/article/details/117162103
解决K8S/openshift等限制以root账户运行问题
Dockerfile
)


)


:)
基础自定义分区器)






![[250521] DBeaver 25.0.5 发布:SQL 编辑器、导航器全面升级,新增 Kingbase 支持!](http://pic.xiahunao.cn/[250521] DBeaver 25.0.5 发布:SQL 编辑器、导航器全面升级,新增 Kingbase 支持!)




