Langchain系列文章目录
01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南
02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖
03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南
04-玩转 LangChain:从文档加载到高效问答系统构建的全程实战
05-玩转 LangChain:深度评估问答系统的三种高效方法(示例生成、手动评估与LLM辅助评估)
06-从 0 到 1 掌握 LangChain Agents:自定义工具 + LLM 打造智能工作流!
07-【深度解析】从GPT-1到GPT-4:ChatGPT背后的核心原理全揭秘
08-【万字长文】MCP深度解析:打通AI与世界的“USB-C”,模型上下文协议原理、实践与未来
Python系列文章目录
PyTorch系列文章目录
机器学习系列文章目录
深度学习系列文章目录
Java系列文章目录
JavaScript系列文章目录
深度学习系列文章目录
01-【深度学习-Day 1】为什么深度学习是未来?一探究竟AI、ML、DL关系与应用
02-【深度学习-Day 2】图解线性代数:从标量到张量,理解深度学习的数据表示与运算
03-【深度学习-Day 3】搞懂微积分关键:导数、偏导数、链式法则与梯度详解
04-【深度学习-Day 4】掌握深度学习的“概率”视角:基础概念与应用解析
05-【深度学习-Day 5】Python 快速入门:深度学习的“瑞士军刀”实战指南
06-【深度学习-Day 6】掌握 NumPy:ndarray 创建、索引、运算与性能优化指南
07-【深度学习-Day 7】精通Pandas:从Series、DataFrame入门到数据清洗实战
08-【深度学习-Day 8】让数据说话:Python 可视化双雄 Matplotlib 与 Seaborn 教程
09-【深度学习-Day 9】机器学习核心概念入门:监督、无监督与强化学习全解析
10-【深度学习-Day 10】机器学习基石:从零入门线性回归与逻辑回归
11-【深度学习-Day 11】Scikit-learn实战:手把手教你完成鸢尾花分类项目
12-【深度学习-Day 12】从零认识神经网络:感知器原理、实现与局限性深度剖析
13-【深度学习-Day 13】激活函数选型指南:一文搞懂Sigmoid、Tanh、ReLU、Softmax的核心原理与应用场景
14-【深度学习-Day 14】从零搭建你的第一个神经网络:多层感知器(MLP)详解
15-【深度学习-Day 15】告别“盲猜”:一文读懂深度学习损失函数
16-【深度学习-Day 16】梯度下降法 - 如何让模型自动变聪明?
17-【深度学习-Day 17】神经网络的心脏:反向传播算法全解析
文章目录
- Langchain系列文章目录
- Python系列文章目录
- PyTorch系列文章目录
- 机器学习系列文章目录
- 深度学习系列文章目录
- Java系列文章目录
- JavaScript系列文章目录
- 深度学习系列文章目录
- 前言
- 一、为什么需要反向传播?
- 1.1 梯度下降的回顾
- 1.2 简单模型的梯度计算
- 1.3 深度网络的挑战
- 1.4 反向传播的诞生
- 二、反向传播的核心:链式法则
- 2.1 单变量链式法则
- 2.2 多变量链式法则
- 2.3 链式法则在神经网络中的体现
- 2.3.1 关键思想:计算图
- 三、前向传播与反向传播的流程
- 3.1 前向传播 (Forward Propagation)
- (1) 流程步骤:
- (2) 目标:
- 3.2 反向传播 (Backward Propagation)
- (1) 流程步骤:
- (2) 目标:
- 3.3 训练循环
- 四、直观理解:误差如何逐层传递
- 4.1 误差的源头
- 4.2 责任的逐层分配
- 4.3 权重梯度的意义
- 五、常见问题与注意事项
- 5.1 梯度消失与梯度爆炸
- 5.2 自动求导的便利
- 5.3 理解原理的重要性
- 六、总结
前言
在上一篇文章【深度学习-Day 16】中,我们了解了梯度下降法——这个引领我们寻找损失函数最小值的强大工具。我们知道了,只要能计算出损失函数关于模型参数(权重 w w w 和偏置 b b b)的梯度,我们就能通过不断迭代来更新参数,让模型变得越来越好。但是,对于一个拥有成千上万甚至数百万参数的深度神经网络来说,如何高效地计算这些梯度呢?手动推导显然是不现实的。这时,神经网络的“心脏”——反向传播算法(Backpropagation, BP)——就登场了。它是一种能够高效计算梯度的“魔法”,是绝大多数神经网络训练的基础。本文将带你深入探索反向传播的奥秘。
一、为什么需要反向传播?
1.1 梯度下降的回顾
我们知道,梯度下降的核心是更新规则:
θ = θ − η ∇ θ J ( θ ) \theta = \theta - \eta \nabla_\theta J(\theta) θ=θ−η∇θJ(θ)
其中, θ \theta θ 代表模型的所有参数, J ( θ ) J(\theta) J(θ) 是损失函数, η \eta η 是学习率,而 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ) 就是损失函数对参数的梯度。关键就在于计算这个梯度 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ)。
1.2 简单模型的梯度计算
对于像线性回归或逻辑回归这样的简单模型,损失函数相对直接,参数数量也不多,我们甚至可以手动推导出梯度的解析表达式。例如,对于单个样本的均方误差损失 J = 1 2 ( y p r e d − y t r u e ) 2 J = \frac{1}{2}(y_{pred} - y_{true})^2 J=21(ypred−ytrue)2,如果 y p r e d = w x + b y_{pred} = wx + b ypred=wx+b,计算 ∂ J ∂ w \frac{\partial J}{\partial w} ∂w∂J 和 ∂ J ∂ b \frac{\partial J}{\partial b} ∂b∂J 并不复杂。
1.3 深度网络的挑战
然而,当面对深度神经网络时,情况变得复杂起来。
- 层级结构: 神经网络通常包含多个隐藏层,输出层的误差是由前面所有层的计算共同决定的。
- 参数众多: 一个典型的深度网络可能有数百万个参数。
- 计算依赖: 某一层的梯度计算,会依赖于其后一层的梯度信息。
如果对每个参数都独立地去推导梯度表达式,计算量会极其庞大,且难以实现。想象一下,一个微小的参数变动,会像涟漪一样扩散,影响到最终的输出和损失。我们需要一种系统性的方法,能够高效地计算出每个参数对最终损失的“贡献度”,也就是梯度。
1.4 反向传播的诞生
反向传播算法应运而生。它并非一个全新的优化算法(优化算法是梯度下降等),而是一种计算梯度的高效方法。它巧妙地利用了微积分中的链式法则(Chain Rule),将最终的损失误差从输出层开始,逐层地“反向”传播回输入层,并在传播过程中计算出每一层参数的梯度。
二、反向传播的核心:链式法则
链式法则是理解反向传播的关键。它告诉我们如何计算复合函数的导数。
2.1 单变量链式法则
如果 y = f ( u ) y = f(u) y=f(u) 且 u = g ( x ) u = g(x) u=g(x),那么 y y y 对 x x x 的导数可以表示为:
d y d x = d y d u ⋅ d u d x \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy=dudy⋅dxdu
这就像一个传递过程: x x x 的微小变化 Δ x \Delta x Δx 导致 u u u 的变化 Δ u \Delta u Δu,进而导致 y y y 的变化 Δ y \Delta y Δy。总的变化率是两个阶段变化率的乘积。
2.2 多变量链式法则
在神经网络中,情况更复杂,因为一个节点的输出可能影响多个后续节点,或者一个节点的输入可能来自多个前序节点。这时就需要用到多变量链式法则。
假设 z = f ( x , y ) z = f(x, y) z=f(x,y),而 x = g ( t ) x = g(t) x=g(t), y = h ( t ) y = h(t) y=h(t),那么 z z z 对 t t t 的导数是:
d z d t = ∂ z ∂ x ⋅ d x d t + ∂ z ∂ y ⋅ d y d t \frac{dz}{dt} = \frac{\partial z}{\partial x} \cdot \frac{dx}{dt} + \frac{\partial z}{\partial y} \cdot \frac{dy}{dt} dtdz=∂x∂z⋅dtdx+∂y∂z⋅dtdy
这个公式告诉我们,要计算 z z z 对 t t t 的总影响,需要将 t t t 通过所有可能的路径(这里是 t → x → z t \to x \to z t→x→z 和 t → y → z t \to y \to z t→y→z)对 z z z 产生的影响加起来。
2.3 链式法则在神经网络中的体现
想象一个简单的神经网络,输入 x x x,经过第一层计算得到 a ( 1 ) a^{(1)} a(1),再经过激活函数得到 h ( 1 ) h^{(1)} h(1),然后进入第二层计算得到 a ( 2 ) a^{(2)} a(2),最后得到输出 y p r e d y_{pred} ypred,并计算损失 J J J。
- J J J 是 y p r e d y_{pred} ypred 的函数。
- y p r e d y_{pred} ypred (可能是 a ( 2 ) a^{(2)} a(2) 或其激活) 是 a ( 2 ) a^{(2)} a(2) 的函数。
- a ( 2 ) a^{(2)} a(2) 是 h ( 1 ) h^{(1)} h(1) 和第二层权重 w ( 2 ) w^{(2)} w(2)、偏置 b ( 2 ) b^{(2)} b(2) 的函数。
- h ( 1 ) h^{(1)} h(1) 是 a ( 1 ) a^{(1)} a(1) 的函数(激活函数)。
- a ( 1 ) a^{(1)} a(1) 是 x x x 和第一层权重 w ( 1 ) w^{(1)} w(1)、偏置 b ( 1 ) b^{(1)} b(1) 的函数。
如果我们想计算损失 J J J 对第一层某个权重 w i j ( 1 ) w_{ij}^{(1)} wij(1) 的梯度 ∂ J ∂ w i j ( 1 ) \frac{\partial J}{\partial w_{ij}^{(1)}} ∂wij(1)∂J,就需要沿着这条计算链,从 J J J 开始,一层一层地往回应用链式法则,直到 w i j ( 1 ) w_{ij}^{(1)} wij(1)。
2.3.1 关键思想:计算图
将神经网络的计算过程表示为一个**计算图(Computation Graph)**会非常有帮助。在这个图中,节点代表变量(输入、参数、中间结果、损失),边代表操作(加法、乘法、激活函数等)。
在计算图中,反向传播就是从最终节点 J J J 开始,沿着边的反方向,利用链式法则计算每个节点相对于 J J J 的梯度。
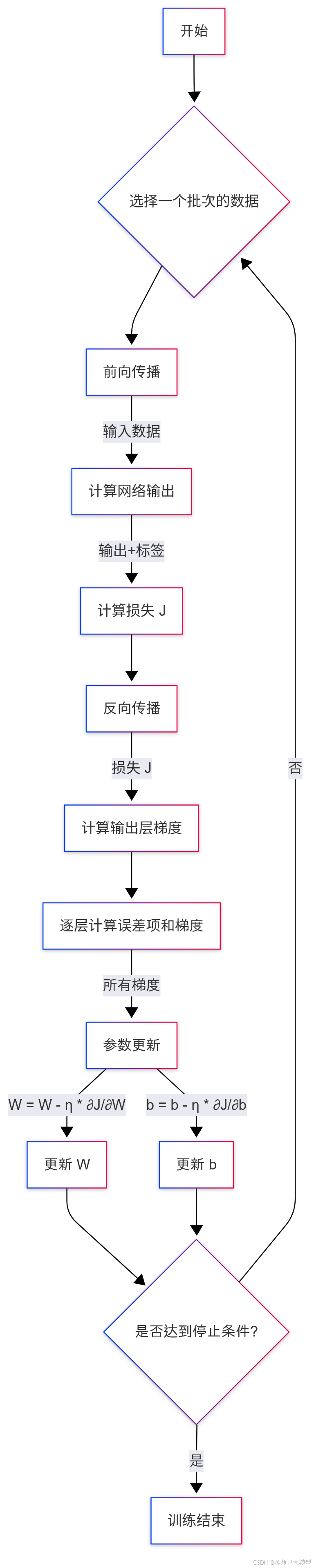
三、前向传播与反向传播的流程
神经网络的训练过程主要包含两个阶段:前向传播和反向传播。
3.1 前向传播 (Forward Propagation)
这个过程我们已经比较熟悉了,它指的是数据从输入层开始,逐层通过网络,计算每一层的输出,直到最终得到预测结果并计算损失。
(1) 流程步骤:
- 输入数据: 将训练样本 X X X 输入到网络的第一层。
- 逐层计算:
- 对于第 l l l 层:
- 计算加权和: a ( l ) = W ( l ) h ( l − 1 ) + b ( l ) a^{(l)} = W^{(l)}h^{(l-1)} + b^{(l)} a(l)=W(l)h(l−1)+b(l) (其中 h ( 0 ) = X h^{(0)} = X h(0)=X)
- 应用激活函数: h ( l ) = f ( l ) ( a ( l ) ) h^{(l)} = f^{(l)}(a^{(l)}) h(l)=f(l)(a(l))
- 对于第 l l l 层:
- 输出结果: 最后一层(假设为 L L L 层)的输出 h ( L ) h^{(L)} h(L) 就是模型的预测值 Y p r e d Y_{pred} Ypred。
- 计算损失: 根据 Y p r e d Y_{pred} Ypred 和真实标签 Y t r u e Y_{true} Ytrue,使用预定义的损失函数(如交叉熵或均方误差)计算损失值 J J J。
(2) 目标:
前向传播的目标是得到预测结果并计算出当前的损失值。这个损失值衡量了当前模型的好坏程度。
3.2 反向传播 (Backward Propagation)
这是训练的核心,目标是计算损失函数 J J J 对网络中每一个参数( W W W 和 b b b)的梯度。
(1) 流程步骤:
-
计算输出层梯度: 首先计算损失 J J J 对输出层激活值 h ( L ) h^{(L)} h(L) 的梯度 ∂ J ∂ h ( L ) \frac{\partial J}{\partial h^{(L)}} ∂h(L)∂J,以及对输出层加权和 a ( L ) a^{(L)} a(L) 的梯度 ∂ J ∂ a ( L ) \frac{\partial J}{\partial a^{(L)}} ∂a(L)∂J。这通常比较直接,因为 J J J 是 h ( L ) h^{(L)} h(L) (或 a ( L ) a^{(L)} a(L)) 的直接函数。
δ ( L ) = ∂ J ∂ a ( L ) = ∂ J ∂ h ( L ) ⋅ ∂ h ( L ) ∂ a ( L ) = ∂ J ∂ h ( L ) ⋅ f ′ ( L ) ( a ( L ) ) \delta^{(L)} = \frac{\partial J}{\partial a^{(L)}} = \frac{\partial J}{\partial h^{(L)}} \cdot \frac{\partial h^{(L)}}{\partial a^{(L)}} = \frac{\partial J}{\partial h^{(L)}} \cdot f'^{(L)}(a^{(L)}) δ(L)=∂a(L)∂J=∂h(L)∂J⋅∂a(L)∂h(L)=∂h(L)∂J⋅f′(L)(a(L))
我们通常定义 δ ( l ) = ∂ J ∂ a ( l ) \delta^{(l)} = \frac{\partial J}{\partial a^{(l)}} δ(l)=∂a(l)∂J 为第 l l l 层的误差项。 -
反向逐层计算梯度: 从第 L − 1 L-1 L−1 层开始,一直到第一层 ( l = L − 1 , L − 2 , . . . , 1 l = L-1, L-2, ..., 1 l=L−1,L−2,...,1):
- 计算当前层的误差项 δ ( l ) \delta^{(l)} δ(l): 利用后一层 ( l + 1 l+1 l+1) 的误差项 δ ( l + 1 ) \delta^{(l+1)} δ(l+1) 来计算当前层的误差项。根据链式法则:
δ ( l ) = ∂ J ∂ a ( l ) = ∂ J ∂ a ( l + 1 ) ⋅ ∂ a ( l + 1 ) ∂ h ( l ) ⋅ ∂ h ( l ) ∂ a ( l ) = ( δ ( l + 1 ) W ( l + 1 ) ) ⊙ f ′ ( l ) ( a ( l ) ) \delta^{(l)} = \frac{\partial J}{\partial a^{(l)}} = \frac{\partial J}{\partial a^{(l+1)}} \cdot \frac{\partial a^{(l+1)}}{\partial h^{(l)}} \cdot \frac{\partial h^{(l)}}{\partial a^{(l)}} = (\delta^{(l+1)} W^{(l+1)}) \odot f'^{(l)}(a^{(l)}) δ(l)=∂a(l)∂J=∂a(l+1)∂J⋅∂h(l)∂a(l+1)⋅∂a(l)∂h(l)=(δ(l+1)W(l+1))⊙f′(l)(a(l))
其中 ⊙ \odot ⊙ 表示哈达玛积(Hadamard product,即元素对应相乘)。这一步体现了误差是如何从后一层传播到前一层的。 - 计算当前层参数的梯度: 一旦有了当前层的误差项 δ ( l ) \delta^{(l)} δ(l),就可以计算 W ( l ) W^{(l)} W(l) 和 b ( l ) b^{(l)} b(l) 的梯度了:
∂ J ∂ W ( l ) = δ ( l ) ( h ( l − 1 ) ) T \frac{\partial J}{\partial W^{(l)}} = \delta^{(l)} (h^{(l-1)})^T ∂W(l)∂J=δ(l)(h(l−1))T ∂ J ∂ b ( l ) = δ ( l ) \frac{\partial J}{\partial b^{(l)}} = \delta^{(l)} ∂b(l)∂J=δ(l)
(注意:这里为了简洁,省略了对批次求和或求平均的过程,实际实现中需要考虑)。
- 计算当前层的误差项 δ ( l ) \delta^{(l)} δ(l): 利用后一层 ( l + 1 l+1 l+1) 的误差项 δ ( l + 1 ) \delta^{(l+1)} δ(l+1) 来计算当前层的误差项。根据链式法则:
-
梯度汇总: 收集所有层的梯度 ∂ J ∂ W ( l ) \frac{\partial J}{\partial W^{(l)}} ∂W(l)∂J 和 ∂ J ∂ b ( l ) \frac{\partial J}{\partial b^{(l)}} ∂b(l)∂J。
(2) 目标:
反向传播的目标是高效地计算出所有参数的梯度,为梯度下降法的参数更新提供依据。
3.3 训练循环
一个完整的训练迭代(或一个批次的训练)包括:
- 前向传播: 计算预测值和损失。
- 反向传播: 计算所有参数的梯度。
- 参数更新: 使用梯度下降法(或其变种)更新 W W W 和 b b b。
这个循环会重复进行,直到模型收敛或达到预设的训练轮数。
四、直观理解:误差如何逐层传递
反向传播不仅仅是一个数学技巧,它背后有着深刻的直观含义。我们可以将其理解为一个责任分配的过程。
4.1 误差的源头
最终的损失 J J J 是衡量模型预测错误程度的指标。这个误差是整个网络共同作用的结果。反向传播就是要弄清楚,网络中的每一个神经元、每一个权重,对这个最终的误差负有多大的责任。
4.2 责任的逐层分配
- 输出层: 输出层的神经元直接影响最终的损失,它们的责任(梯度)最容易计算。如果一个输出神经元的激活值与真实值差距越大,它对损失的责任就越大。
- 倒数第二层: 这一层的神经元不直接影响损失,但它们通过影响输出层来间接影响损失。一个倒数第二层的神经元 A A A 对最终损失的责任,取决于:
- 它对所有它连接到的输出层神经元 B 1 , B 2 , . . . B_1, B_2, ... B1,B2,... 产生了多大的影响(即连接权重 W A B i W_{AB_i} WABi)。
- 输出层神经元 B 1 , B 2 , . . . B_1, B_2, ... B1,B2,... 各自对最终损失负有多大的责任(即 δ ( L ) \delta^{(L)} δ(L))。
- 神经元 A A A 本身的激活程度(通过激活函数的导数 f ′ f' f′ 体现,如果 f ′ f' f′ 很大,说明微小的输入变化会导致较大的输出变化,责任可能更大)。
- 因此, A A A 的责任是它对所有 B i B_i Bi 的影响与其责任的加权和。这正是反向传播公式 δ ( l ) = ( δ ( l + 1 ) W ( l + 1 ) ) ⊙ f ′ ( l ) ( a ( l ) ) \delta^{(l)} = (\delta^{(l+1)} W^{(l+1)}) \odot f'^{(l)}(a^{(l)}) δ(l)=(δ(l+1)W(l+1))⊙f′(l)(a(l)) 所表达的含义。
- 以此类推: 这个责任分配过程从输出层开始,一层一层地向后传递,直到输入层。每一层的神经元都将它所“承担”的误差责任,根据连接权重分配给它的前一层神经元。
4.3 权重梯度的意义
最终计算出的 ∂ J ∂ W i j ( l ) \frac{\partial J}{\partial W_{ij}^{(l)}} ∂Wij(l)∂J,其直观意义是:如果我将权重 W i j ( l ) W_{ij}^{(l)} Wij(l) 增加一个微小的量,最终的损失 J J J 会发生多大的变化?
- 如果梯度为正,说明增加权重会增加损失,我们应该减小这个权重。
- 如果梯度为负,说明增加权重会减小损失,我们应该增大这个权重。
- 如果梯度接近零,说明这个权重对当前损失影响不大。
这正是梯度下降法更新参数的依据。反向传播通过高效计算这些梯度,使得神经网络能够有效地从错误中学习,并调整自身,以做出更准确的预测。
五、常见问题与注意事项
5.1 梯度消失与梯度爆炸
正如我们在【Day 16】中提到的,在深层网络中,反向传播过程中梯度的连乘效应可能导致梯度变得极小(梯度消失)或极大(梯度爆炸),使得训练困难。这与激活函数的选择(如 Sigmoid 在两端梯度接近0)和权重初始化有关。后续我们将学习 LSTM、GRU、ResNet 等结构以及 ReLU 等激活函数来缓解这些问题。
5.2 自动求导的便利
现代深度学习框架(如 TensorFlow 和 PyTorch)都内置了**自动求导(Automatic Differentiation)**功能。我们只需要定义好网络结构(计算图)和损失函数,框架就能自动地执行反向传播并计算梯度,极大地简化了开发过程。我们无需手动实现复杂的反向传播代码。
5.3 理解原理的重要性
尽管框架为我们做了很多工作,但深入理解反向传播的原理仍然至关重要。它能帮助我们:
- 更好地设计网络结构。
- 理解各种优化算法和正则化技巧的原理。
- 在模型训练出现问题时进行诊断和调试。
- 跟进和理解最新的研究进展。
六、总结
反向传播算法是深度学习领域一座重要的里程碑,它为训练复杂而深层的神经网络提供了可能。
- 核心目标: 高效计算损失函数关于网络中所有参数的梯度。
- 核心原理: 基于微积分中的链式法则。
- 核心流程: 包括前向传播(计算输出和损失)和反向传播(从输出层开始,逐层计算并传递误差项,进而计算梯度)。
- 直观理解: 是一个将最终误差责任逐层分配回网络中每个参数的过程。
- 关键作用: 为梯度下降及其变种提供必要的梯度信息,驱动神经网络的学习过程。
虽然现代框架隐藏了反向传播的实现细节,但理解其工作机制,是我们深入掌握深度学习、成为一名优秀从业者的必经之路。在接下来的文章中,我们将学习更多优化算法,并开始接触强大的深度学习框架,将这些理论知识付诸实践。













)


——第一个小程序(进度条))


