牛羊检测数据集 3700张 平视视角牛羊检测 带标注 voc yolo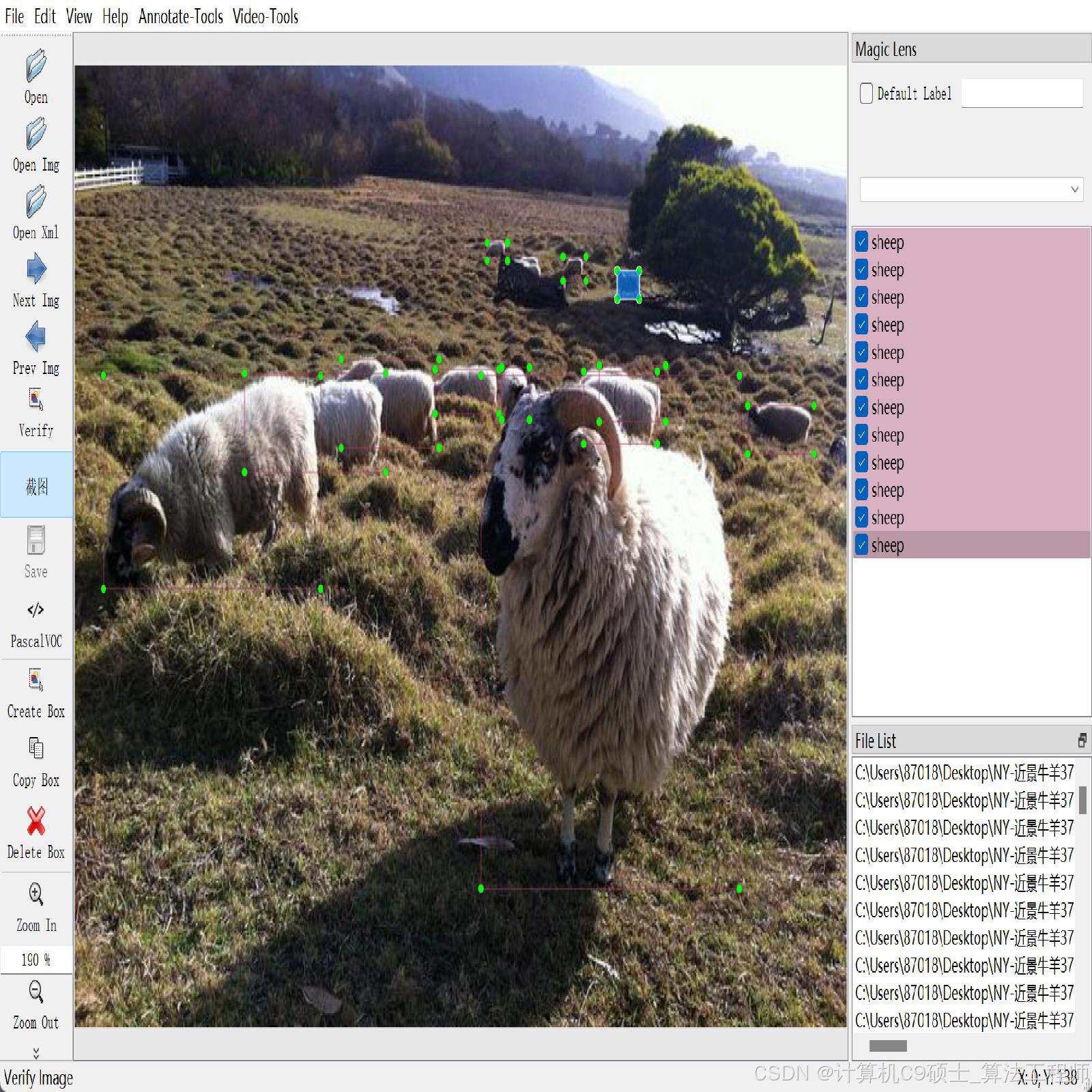
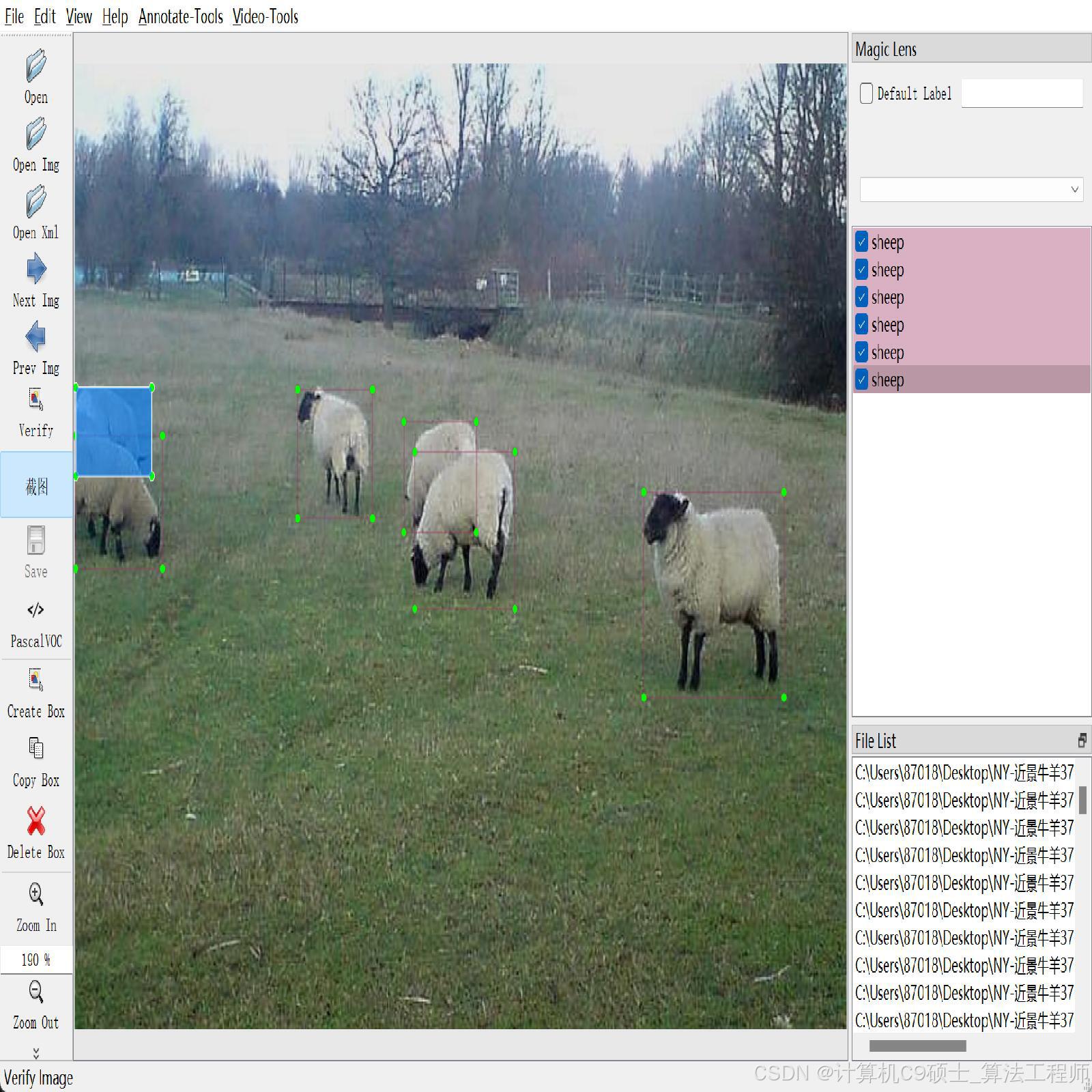
牛羊检测数据集 3700张 牛羊检测平视 带标注 voc yolo
分类名: (图片张数,标注个数)
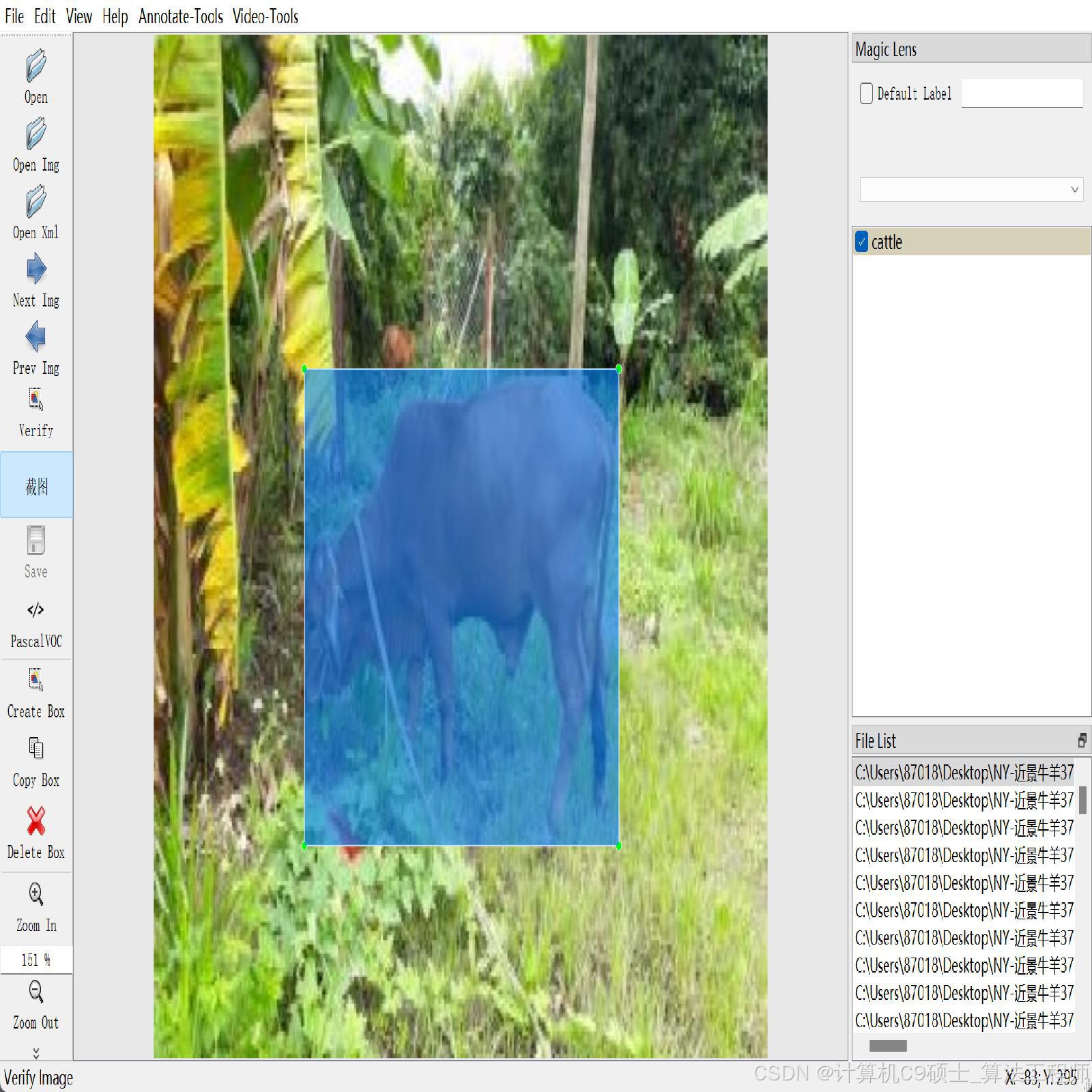
cattle:
(1395,4309)
sheep:
(2393,1 1205)
总数:
(3791, 15514)
总类(nc):
2类
以下是详细的步骤和完整的代码示例:
完整训练脚本
1. 安装依赖
首先确保你已经安装了必要的库,特别是ultralytics库,它是YOLOv8的核心库。
pip install ultralytics
2. 准备数据集
假设你的数据集格式符合YOLO的要求,即图像文件夹和对应的标注文件夹。数据集结构应如下所示:
datasets/
├── images/
│ ├── train/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └── ...
│ └── val/
│ ├── img1.jpg
│ ├── img2.jpg
│ └── ...
└── labels/├── train/│ ├── img1.txt│ ├── img2.txt│ └── ...└── val/├── img1.txt├── img2.txt└── ...
每个.txt文件对应一张图片,内容格式为:
<class_id> <x_center> <y_center> <width> <height>
其中,坐标值都是归一化的(范围在0到1之间)。
3. 配置YOLOv8
创建一个YAML文件来配置数据集路径和类别信息。例如,创建一个名为cattle_sheep.yaml的文件:
train: ../datasets/images/train
val: ../datasets/images/valnc: 2
names: ['cattle', 'sheep']
4. 训练模型
编写训练脚本,使用YOLOv8进行训练。以下是完整的训练脚本:
[<title="Cattle and Sheep Detection using YOLOv8">]
from ultralytics import YOLO# Load a pre-trained YOLOv8n model
model = YOLO('yolov8n.pt')# Train the model on your dataset
results = model.train(data='cattle_sheep.yaml',epochs=50,imgsz=640,batch=8,workers=4,device='0' # Use GPU if available
)# Evaluate the model performance on the validation set
metrics = model.val()# Export the trained model to ONNX format for deployment
success = model.export(format='onnx')
解释
- 加载预训练模型:我们从预训练的YOLOv8n模型开始。
- 训练模型:使用
train方法进行训练。参数包括数据集配置文件路径、训练轮数、图像大小、批量大小、工作线程数和设备。 - 评估模型:使用
val方法对模型进行评估。 - 导出模型:将训练好的模型导出为ONNX格式以便部署。
运行脚本
保存上述脚本到一个Python文件中,例如train_cattle_sheep.py,然后运行该脚本:
python train_cattle_sheep.py
这样,你就可以在一个连续的文档中看到所有的步骤和代码,并且可以直接复制和运行整个脚本。

:语音识别输入功能)

)

软件及安装教程)

)






)



ChatGPT Plus充值教程与实用指南:附国内外使用案例与模型排行)
