Python中的变量、赋值及函数的参数传递概要
python中的变量、赋值
python中的变量不是盒子。
python中的变量无法用“变量是盒子”做解释。图说明了在 Python 中为什么不能使用盒子比喻,而便利贴则指出了变量的正确工作方式。

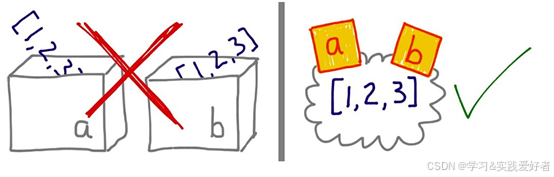
如果把变量想象为盒子,那么无法解释 Python 中的赋值;应该把变量视作便利贴,这样示例中的行为就好解释了
注意:
对引用式变量来说,说把变量分配给对象更合理,反过来说就有问题。毕竟,对象在赋值之前就创建了。
上面这一段是《流畅的Python》说法。
在 Python 中,一切皆为对象。对象分为不可变对象和可变对象。每个对象都有各自的 id、type 和 value。
Id:当一个对象被创建后,在对象生命周期内它的 id 就不会在改变,在 CPython 实现中,id 通常等于对象的内存地址,可以使用 id() 去查看对象在内存中地址。不可对象(如元组)可能包含可变子对象,子对象的修改不会影响容器的 id。
Type:对象类型(如 int, str, list),决定了支持的操作,通过 type() 获取。
Value:对象存储的具体数据。
可变性的本质
可变性取决于对象是否允许 原地修改(即不改变 id 的情况下修改 value)。
不可变对象看似“修改”时,实际上是创建新对象并重新赋值给变量。(不可变对象的“不可变”是指 value 不可原地修改,而非完全不可变。任何对不可变对象的“修改”都会生成新对象。)
# 不可变对象示例(整数)
a = 10
print(id(a)) # 输出初始 id
a += 5
print(id(a)) # id 改变,因为创建了新对象# 可变对象示例(列表)
b = [1, 2]
print(id(b)) # 输出初始 id
b.append(3)
print(id(b)) # id 不变,原地修改
学过C/C++可知,python与C/C++不一样,它的变量使用有自己的特点。下面,就进行必要的展开介绍。
在Python中,变量赋值的机制涉及到对象的引用和对象的可变性。变量名只是对象的引用,而不是直接存储数据。因此,变量a和b赋值后的行为差异,取决于两个因素:
在Python中,数据对象被明确划分为两大阵营:可变(Mutable)与不可变(Immutable)。
不可变数据类型
数字类型(int/float/complex)
字符串(str)
元组(tuple)
不可变集合/冻结集合(frozenset)
布尔值(bool)
不可变数据类型的核心特性
1.内存机制:当尝试修改不可变对象时,Python不会改变原对象,而是创建一个新对象。例如:
a = 10
b = a
a += 5 # a指向新对象15,不可变对象的重新赋值,无法原地修改,必须生成新对象
print(id(a), id(b)) # 输出不同内存地址
print(id(a) == id(b)) # 输出 False
2. 内存效率优化
对象复用:Python对部分不可变对象(如小整数范围-5到256、部分短字符串)会进行缓存优化,相同值的对象可能复用同一内存地址。
垃圾回收:不可变对象更易被识别为垃圾,提升回收效率。
3. 哈希性能提升
快速查找:不可变对象的哈希值在创建时确定且不可变,适合作为字典键。字典查找时间复杂度O(1)。
安全保障:哈希值稳定性防止字典键冲突导致的逻辑错误。
4. 线程安全保证
不可变对象天然线程安全,因为无法被修改;可变对象在多线程环境中需使用锁(如 threading.Lock)来保证数据一致性。
不可变 vs 可变
| 特性 | 不可变类型 | 可变类型 |
| 内存占用 | 低(注:不可变类型的低内存占用仅适用于可复用的对象如小整数,大对象可能仍会独立存储) | 高(独立副本) |
| 修改成本 | 高(需创建新对象) | 低(原地修改) |
| 线程安全 | 是 | 否(需加锁) |
| 哈希支持 | 是 | 否 |
| 适用场景 | 字典键、线程共享数据 | 频繁修改的数据集合 |
☆不可变对象的值一旦创建,就不能修改其内容
1) 修改变量的新赋值
a = 5 # a指向整数对象5
b = a # b也指向同一个整数对象5
a = 6 # 此时a指向新的整数对象6,但b仍指向5
print(b) # 输出5
解释原因:
赋值操作 b = a 时,仅复制引用,使得 a 和 b 都指向同一个对象(初始是5)。
当 a = 6 时,a 的引用被更新为指向新对象6,而 b 仍然指向原对象
2)不可变对象无法被修改内容,只能重新创建新对象,尝试直接修改对象内容(无效)
a = "hello" # a指向字符串"hello"
b = a # b也指向相同的字符串对象
# 尝试修改字符串内容(但不可变对象不允许此操作)
a[0] = "H" # 报错:'str' object does not support item assignment
☆可变对象的值可以在创建后被修改
1) 直接修改对象内容
a = [1, 2] # a指向列表[1, 2]
b = a # b指向同一个列表对象
a.append(3) # 修改列表内容,原列表变为[1, 2, 3]
print(b) # 输出[1, 2, 3]
解释原因:
a 和 b 指向同一个列表对象。
append() 方法直接修改了该对象的内部内容,因此两个变量看到的都是同一个被修改后的对象。
可变对象(如列表)在修改时可能触发动态扩容,导致内存地址变化(如 a = a + [3] 会创建新列表,内存地址改变,而 a.append(3) 是原地修改,内存地址不变)
2) 修改变量的引用(不影响对方)
a = [1, 2]
b = a
a = [3, 4] # a的引用被更新为新列表[3,4],但b仍指向原列表[1,2]
print(b) # 输出[1, 2]
解释原因:
a = [3,4] 是一个新的赋值操作,直接改变了a的引用,使其指向新对象,而b未被修改,依然指向原列表。
python函数的参数传递
python函数的参数传递,也有自己的特点。当传过来的是可变类型(list、dict)时,我们在函数内部修改就会影响函数外部的变量。而传入的是不可变类型时在函数内部修改改变量并不会影响函数外部的变量,因为修改的时候会先复制一份再修改。
Python的参数传递,有人建议表述为:Python的参数传递是按对象引用传递(pass by object reference),即函数接收的是对象的引用副本,而非对象本身的副本。
官方术语,参数传递使用按值调用(call by value)的方式(其中的值始终是对象的引用,而不是对象的值)。实际上,Python函数参数传递的始终对象的引用,而不是对象的值。这方面的内容,因一些人和资料介绍的比较混乱,特地附注。
【附注(有关官方文档节选——同时给出python官方的英文和中文两种说法节选和链接——供参考):
The actual parameters (arguments) to a function call are introduced in the local symbol table of the called function when it is called; thus, arguments are passed using call by value (where the value is always an object reference, not the value of the object). [1] When a function calls another function, or calls itself recursively, a new local symbol table is created for that call.
https://docs.python.org/3/tutorial/controlflow.html#defining-functions
在调用函数时会将实际参数(实参)引入到被调用函数的局部符号表中;因此,实参是使用 按值调用 来传递的(其中的 值 始终是对象的 引用 而不是对象的值)。 [1] 当一个函数调用另外一个函数时,会为该调用创建一个新的局部符号表。
https://docs.python.org/zh-cn/3/tutorial/controlflow.html#defining-functions
Remember that arguments are passed by assignment in Python. Since assignment just creates references to objects, there’s no alias between an argument name in the caller and callee, and so no call-by-reference per se.
https://docs.python.org/3/faq/programming.html#how-do-i-write-a-function-with-output-parameters-call-by-reference
请记住,Python 中的实参是通过赋值传递的。由于赋值只是创建了对象的引用,所以调用方和被调用方的参数名都不存在别名,本质上也就不存在按引用调用的方式。
https://docs.python.org/zh-cn/3/faq/programming.html#how-do-i-write-a-function-with-output-parameters-call-by-reference 】
这种机制,也有人称为按对象引用调用(call by object reference),但机制本质不变。
对于不可变对象(如整数、字符串、元组),因为其不可变性,函数内对参数的任何修改不会影响到外部变量。对于可变对象(如列表、字典、集合),函数内对参数的修改会影响到外部变量。
如果传入的参数是不可变类型(如数字、字符串、元组),那么在函数体内修改参数的值,并不会影响到原来的变量。因为不可变类型的变量实际上是值的引用,当试图改变变量的值时,相当于是在创建新的对象。例如:
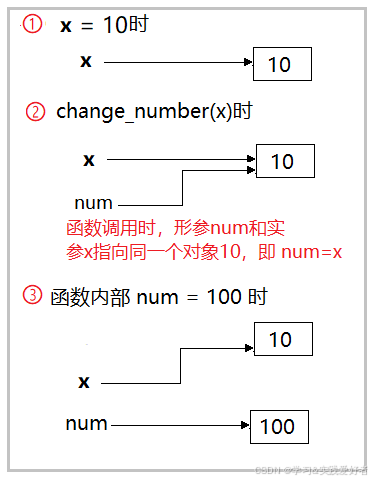
def change_number(num):num = 100x = 10
change_number(x)
print(x) # 输出:10
在上面的例子中,尽管在函数内部num的值被改变了,但是原变量x的值并没有改变。参见下图:
如果传入的参数是可变类型(如列表、字典),那么在函数体内修改参数的值,会影响到原来的变量。因为可变类型的变量存储的是一个地址,当试图改变变量的值时,实际上是在改变这个地址所指向的内容。例如:
def change_list(lst):lst.append(100)x = [1, 2, 3]
change_list(x)
print(x) # 输出:[1, 2, 3, 100]
在上面的例子中,函数内部对参数lst的修改影响到了原变量x的值。参见下图:

浅拷贝与深拷贝在函数参数传递中的作用
函数参数传递使用可变对象时,可能涉及浅拷贝问题(如传入列表时,函数内修改会影响原对象),并建议使用 copy.deepcopy() 避免副作用。
- 浅拷贝:copy.copy()或切片操作(如lst[:]),仅复制顶层对象,嵌套对象仍共享引用。
- 深拷贝:copy.deepcopy(),递归复制所有嵌套对象,生成完全独立的副本。
- 选择依据:根据数据结构复杂度和是否需要隔离修改来决定。在涉及嵌套可变对象时,优先使用深拷贝。
通过合理使用copy.deepcopy(),可以确保函数对参数的修改不会意外影响外部数据。
假设有一个函数接收一个列表参数,并在内部修改该列表。由于Python的参数传递是对象引用传递,直接修改会影响原对象:
def modify_list(lst):lst.append(4) # 原地修改列表print("函数内列表:", lst)original_list = [1, 2, 3]
modify_list(original_list)
print("函数外列表:", original_list)
输出:
函数内列表: [1, 2, 3, 4]
函数外列表: [1, 2, 3, 4] # 原列表被修改
如果希望避免修改原列表,可以使用浅拷贝(copy.copy()或切片操作),但对于嵌套的可变对象,浅拷贝可能不够:
import copydef modify_list_shallow(lst):lst_copy = copy.copy(lst) # 浅拷贝lst_copy.append(4)print("函数内列表:", lst_copy)original_list = [1, 2, 3]
modify_list_shallow(original_list)
print("函数外列表:", original_list)
输出:
函数内列表: [1, 2, 3, 4]
函数外列表: [1, 2, 3] # 原列表未被修改
但当列表包含其他可变对象时,浅拷贝仍可能影响原对象:
def modify_nested_list_shallow(lst):lst_copy = copy.copy(lst) # 浅拷贝lst_copy[0].append(100) # 修改嵌套列表print("函数内列表:", lst_copy)original_list = [[1, 2], [3, 4]]
modify_nested_list_shallow(original_list)
print("函数外列表:", original_list)
输出:
函数内列表: [[1, 2, 100], [3, 4]]
函数外列表: [[1, 2, 100], [3, 4]] # 原嵌套列表被修改
使用深拷贝copy.deepcopy()创建完全独立的副本,即使对象包含嵌套的可变对象:
import copydef modify_list_deep(lst):lst_copy = copy.deepcopy(lst) # 深拷贝lst_copy[0].append(100) # 修改嵌套列表print("函数内列表:", lst_copy)original_list = [[1, 2], [3, 4]]
modify_list_deep(original_list)
print("函数外列表:", original_list)
输出:
函数内列表: [[1, 2, 100], [3, 4]]
函数外列表: [[1, 2], [3, 4]] # 原列表未被修改
何时使用深拷贝
- 需要完全独立的副本:当函数需要修改传入的可变对象,但又不希望影响外部变量时。
- 嵌套可变对象:当对象包含多层嵌套的可变结构(如列表的列表、字典的字典)时,必须使用深拷贝。
- 避免副作用:在并发编程或需要保持数据隔离的场景中,深拷贝能有效防止意外修改。
OK!

)

















)