文章目录
- 5. RAG的架构
- 5.1 Naive RAG
- 5.2 Advanced RAG
- 5.2.1 检索前处理和数据索引技术
- 5.2.2 知识分片技术
- 5.2.3 分层索引
- 5.2.4 检索技术
- 5.2.4.1 优化用户查询
- 5.2.4.2 通过假想文档嵌入修复查询和文档不对称
- 5.2.4.3 Routing
- 5.2.4.5 自查询检索
- 5.2.4.6 混合搜索
- 5.2.4.7 图检索
- 5.2.4.8 微调嵌入模型
- 5.2.5 检索后技术
- 5.2.5.1 通过重新排名确定搜索的优先级
- 5.2.5.2 使用上下文提示压缩优化搜索结果
- 5.2.5.3 Corrective RAG
- 5.2.5.4 扩展查询
- 5.2.6 生成技术
- 5.2.6.1 思维链
- 5.2.6.2 通过 Self-RAG 使系统具备自我反思能力
- 5.2.6.3 微调LLM
- 5.3 模块化RAG
- 5.3.1 模块化RAG系统组成
- 5.3.2 模块化RAG的工作流程
- 5.3.3 模块化RAG的优势
- 5.3.4 模块化RAG的挑战
本篇是 【RAG】RAG综述|一文了解RAG|从零开始(下)的后续,重点讲解RAG的结构与重点技术。
5. RAG的架构
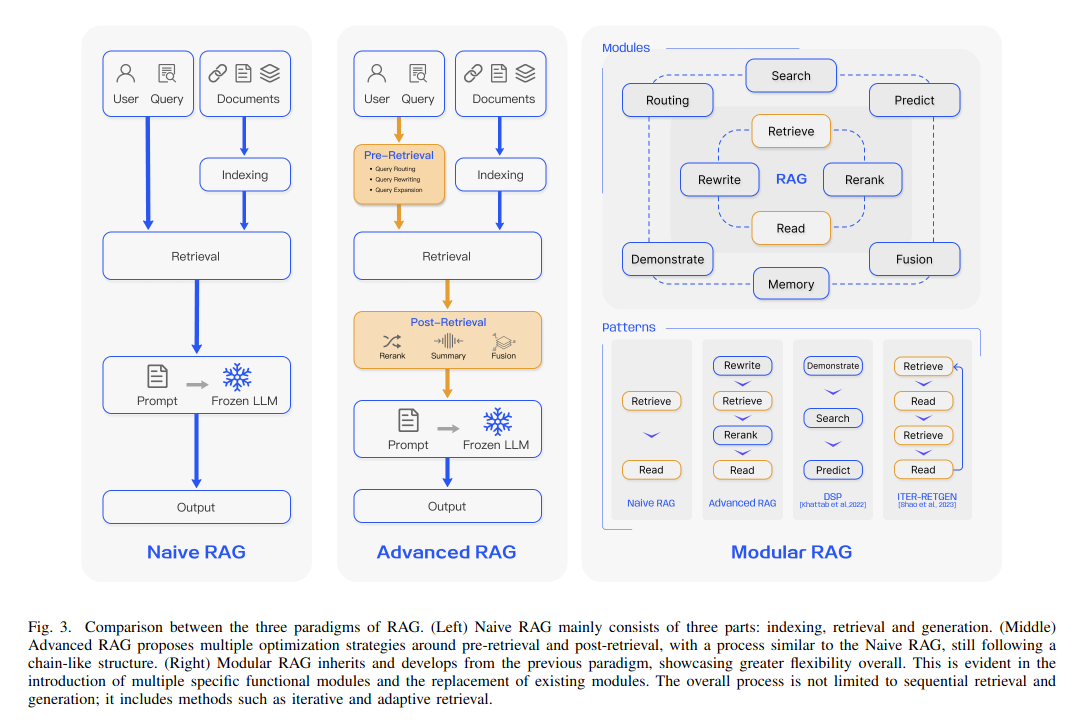
5.1 Naive RAG
这是最简单的RAG架构,其工作流程为:
- 用户查询
- 检索信息
- 利用prompt技术增强
- 将prompt输入到LLM生成结果
5.2 Advanced RAG
相比于朴素RAG,高级RAG主要优化了索引步骤和生成步骤。高级RAG技术提高了信息检索和后续内容生成的效率、准确性和相关性。
高级RAG涉及的主要技术:检索前处理和数据索引技术、知识分片技术、检索技术、后检索技术和生成技术。
5.2.1 检索前处理和数据索引技术
检索前处理侧重在数据进入向量库或知识图谱之前提高数据的质量。干净、格式良好的数据可以提高检索数据的质量,而嘈杂的数据会显著降低检索结果,从而更容易导致LLM幻觉的产生。
预处理数据的常见方法:
- 增加信息密度:可以通过LLM对查询进行改写,总结、提取或清理后查询信息密度更高。
- 删除数据中的重复信息:同样能用LLM对查询进行去重,输出LLM更容易理解、更简洁的查询语句。
- 使用假设问题索引提高索引对称性
- 使用语言模型为数据库中每个数据块生成一个或多个问题,并将它们与文档块一起存储。这些问题可用于索引。
- 在检索的时候,用户查询在语义上与模型生成的所有问题匹配。然后索引与用户查询类似的问题,然后将与检索问题关联的文档块传递给LLM以生成响应。
5.2.2 知识分片技术
知识分片就是将大文档分解成较小的文本块,以便更高效的进行检索和生成。这些较小的文本块,称为chunk,它可以是段落,句子,子句或短语,具体取决于实际应用需求。
常见的分片技术有:
- 基于文本长度的切块:例如固定300个词或500个字符对文本进行切分。
- 滑动窗口技术:这种方法通过在连续的文本块之间使用重叠区域来进行切块,确保每个块都可以包含部分上下文信息。这在需要上下文连贯性的应用中非常有用,比如生成模型需要更大的上下文信息来生成准确的内容。
- 基于句子的切块:按句子对文本进行切分,适用于短且结构简单的文档。
- 基于语义的切块:可以根据章节、段落、主题或关键字进行切分。这种切分出来的块更具有语义一致性。
- 自然语言处理技术:通过分句、分词、主题建模等NLP技术对文本进行切分。好处就是能用NLP技术识别到文本中的语义边界,使得切出来的块更具语义。
关于chunk优化的代码实践:https://blog.csdn.net/2401_85325557/article/details/143359056
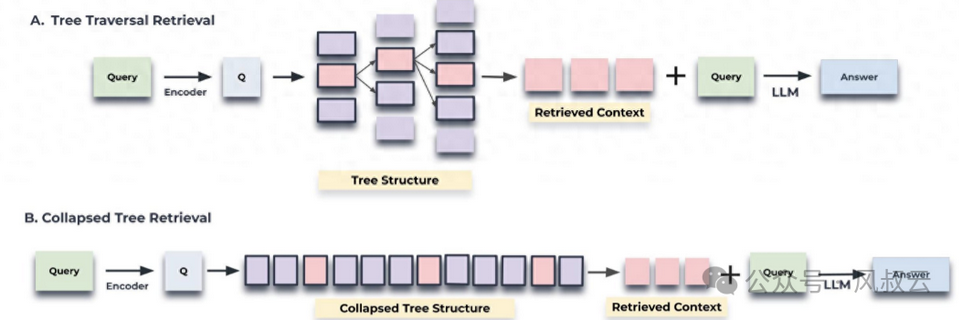
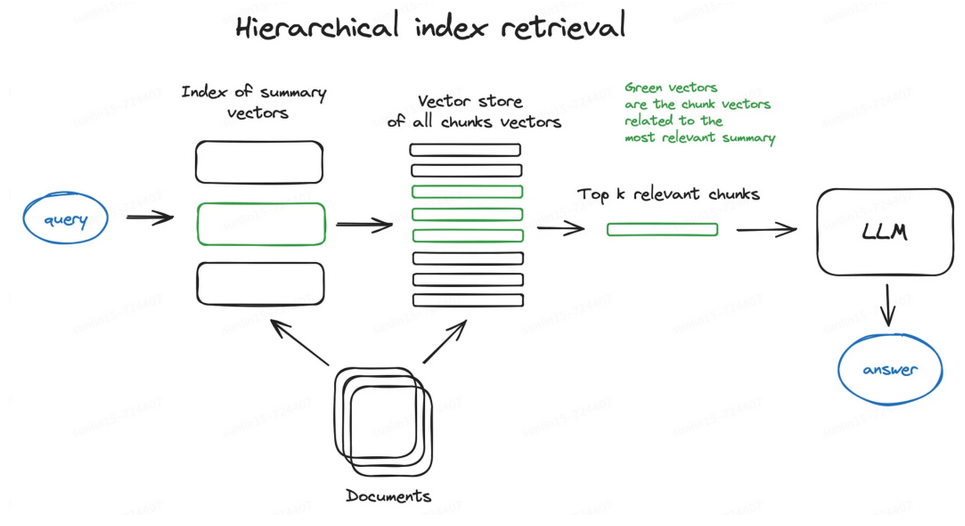
5.2.3 分层索引
使用分层索引来提高RAG应用程序的精度。在这种方法中,数据被组织成一个分层结构,信息根据相关性和关系进行分类和子分类。
检索过程从较宽的数据块或父节点开始,然后再链接到所选父节点的较小数据块或子节点中进行更集中的搜索。分层索引不仅可以提高检索效率,还可以最大限度减少最终输出中包含不相关的数据。
5.2.4 检索技术
5.2.4.1 优化用户查询
该技术将用户的查询重构为LLM更容易理解且检索器更容易使用的格式。技术实现上可通过微调的语言模型处理用户查询,以优化和构建它。此过程会删除任何不相关的上下文并添加必要的元数据,从而确保查询针对底层数据存储进行定制。
例子:
原始:who was the director of the Godfather?
LLM处理后:(Movice: “The Godfather” …)
5.2.4.2 通过假想文档嵌入修复查询和文档不对称
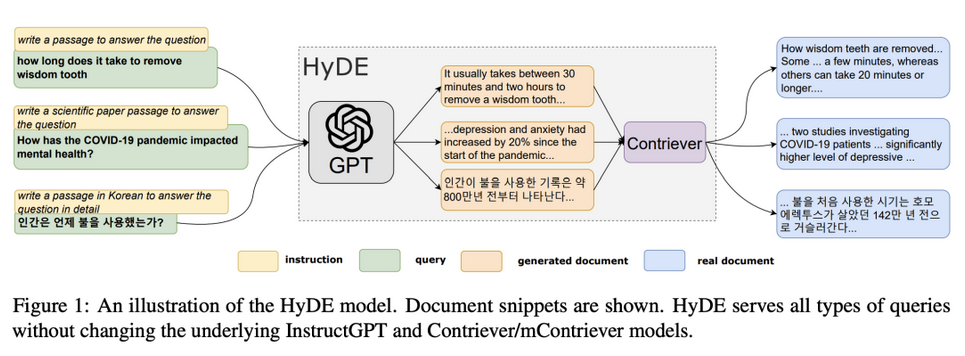
假想文档嵌入(HyDE)技术是一个新颖且强大的方法。它通过生成一个假想的文档来增强查询的检索效果,再通过嵌入向量查找与假想文档相似的实际文档,从而实现更高效的检索。
在传统的检索增强生成(RAG)架构中,用户的查询直接用于查找文档。然而,这种方式可能会受到语义偏差的影响,导致检索效果不佳。
)






)

:STUN服务和TURN服务的作用)


)






