目录
引言
一、环境准备
二、利用虚拟机搭建
三、镜像集群配置
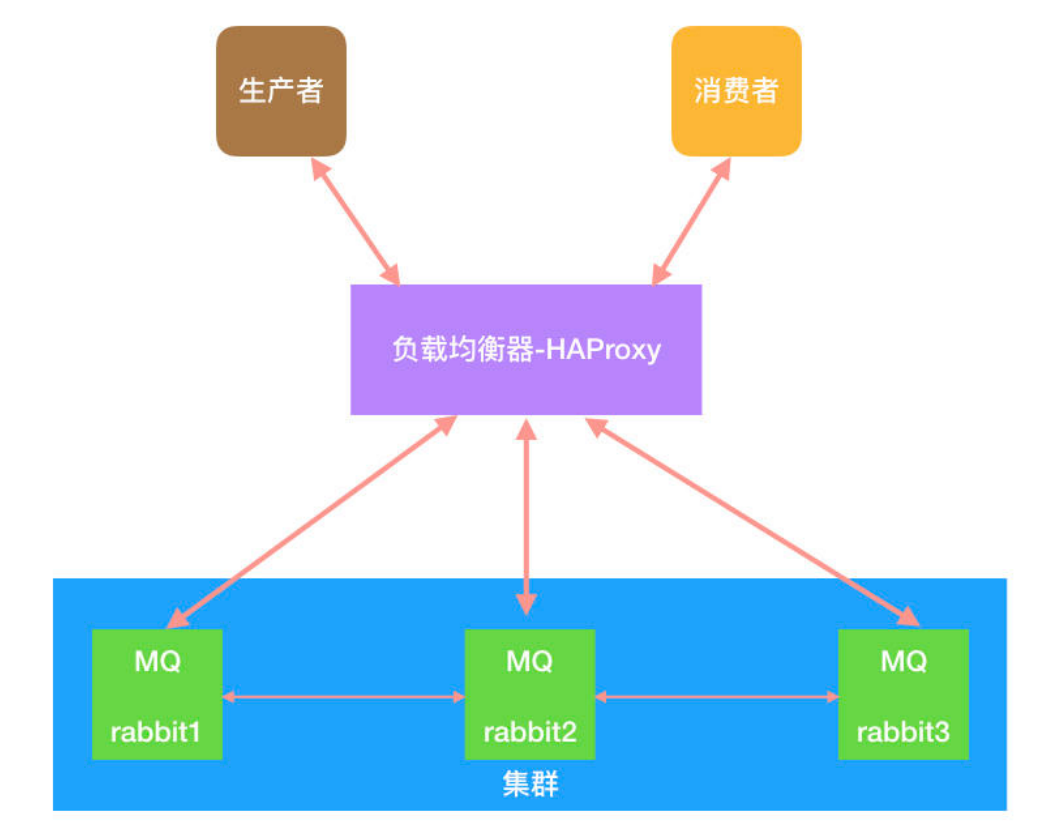
四、HAProxy实现负载均衡(主用虚拟机操作)
五、测试RabbitMQ集群搭建情况
引言
一、环境准备
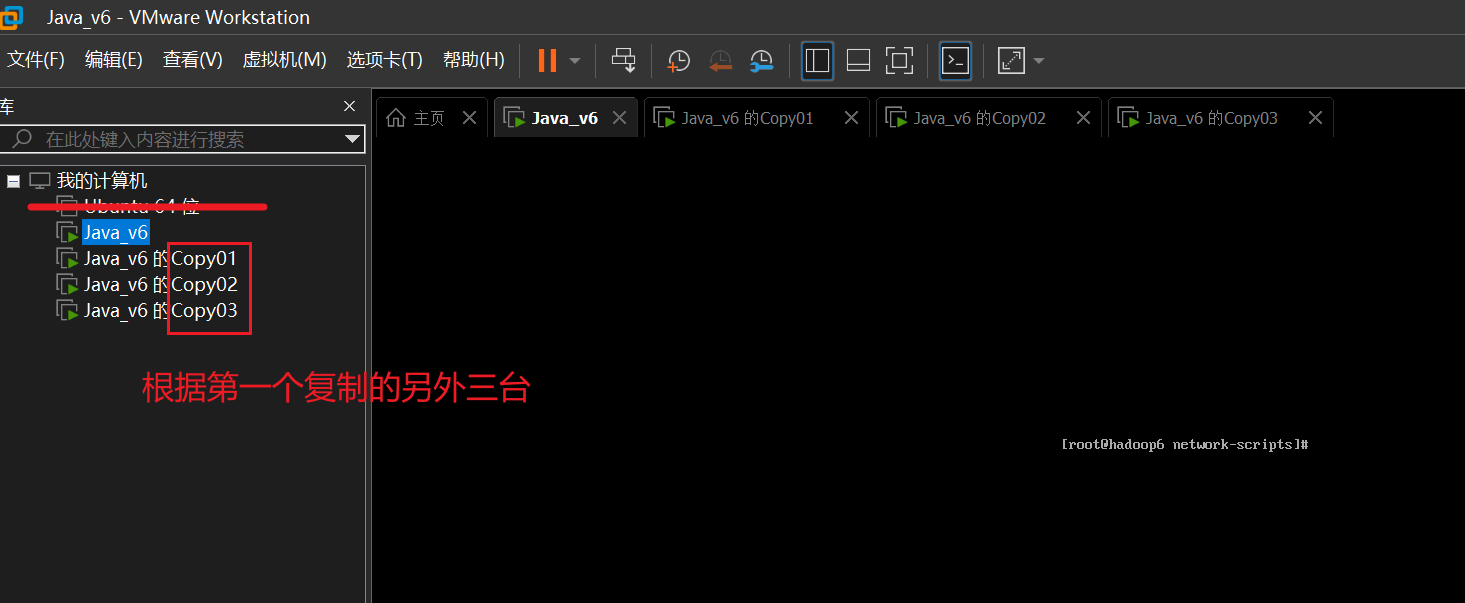
二、利用虚拟机搭建
这里利用我本地的虚拟机模拟三台真实的机器
服务器信息表:
| IP地址 | 主机名 | 操作系统 |
|---|---|---|
| 192.168.93.135 | rabbitmq01 | CentOS7(64位) |
| 192.168.93.136 | rabbitmq02 | CentOS7(64位) |
| 192.168.93.137 | rabbitmq03 | CentOS7(64位) |
进行下一步前可以在本地windows的cmd中测试ping一下上面的三个虚拟机的IP地址。如果都能ping通,那可以进行下一步。
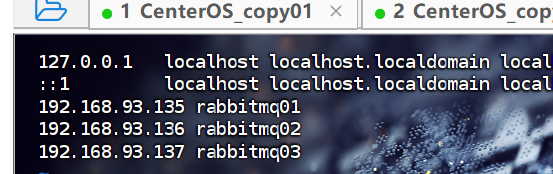
(1)下面修改三台机器的hosts配置文件,为了方便机器间的相互访问,三台centos都执行 vim /etc/hosts , 添加下边的配置,依次执行:
#将三台机器上hosts都修改内容如下
vim /etc/hosts192.168.93.135 rabbitmq01
192.168.93.136 rabbitmq02
192.168.93.137 rabbitmq03#通过ping命令看主机名是否生效
ping rabbitmq02#修改三台主机的主机名 vim /etc/hostname
#修改主机名会导致这台主机上RabbitMQ的数据丢失,可以只改后两台主机名,或者修改前备份
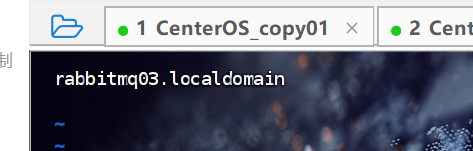
#rabbitmq01 修改为 rabbitmq01.localdomain
#rabbitmq02 修改为 rabbitmq02.localdomain
vim /etc/hostname#然后重启每台机器
reboot对应修改如下:
(2)如果上述都已准确完成,进行下一步:
#查看rabbitmq01的.erlang.cookie
cat erlang.cookie#修改rabbitmq02和rabbitmq03的.erlang.cookie
vim /var/lib/rabbitmq/.erlang.cookie#该文件是只读的,加上写权限
chmod u+w /var/lib/rabbitmq/.erlang.cookie
vim /var/lib/rabbitmq/.erlang.cookie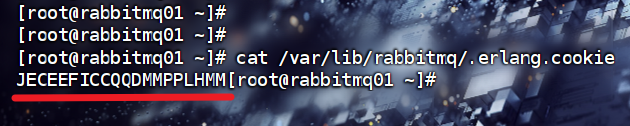
将另外两台都改成与这一样的即可。
最后启动三台机器上的rabbitMQ服务
#每台机器的RabbitMQ服务的访问地址和控制台的访问地址分别是
#192.168.93.135:5672 192.168.93.135:15672
#192.168.93.136:5672 192.168.93.136:15672
#192.168.93.137:5672 192.168.93.137:15672#启动RabbitMQ服务
service rabbitmq-server start(3)将rabbitmq02,rabbitmq03作为内存节点加入rabbitmq01节点集群中

开放端口:
#这里需要开放25672和4369
firewall-cmd --zone=public --add-port=25672/tcp --permanent
systemctl restart firewalld.service
firewall-cmd --reloadfirewall-cmd --zone=public --add-port=4369/tcp --permanent
systemctl restart firewalld.service
firewall-cmd --reload在进行操作:
#在rabbitmq02机器下执行
#停掉rabbit应用
rabbitmqctl stop_app #加入rabbitmq01
rabbitmqctl join_cluster --ram rabbit@rabbitmq01#启动rabbit应用
rabbitmqctl start_app#查看所有节点状态
rabbitmqctl cluster_status最后查看所有节点状态时:
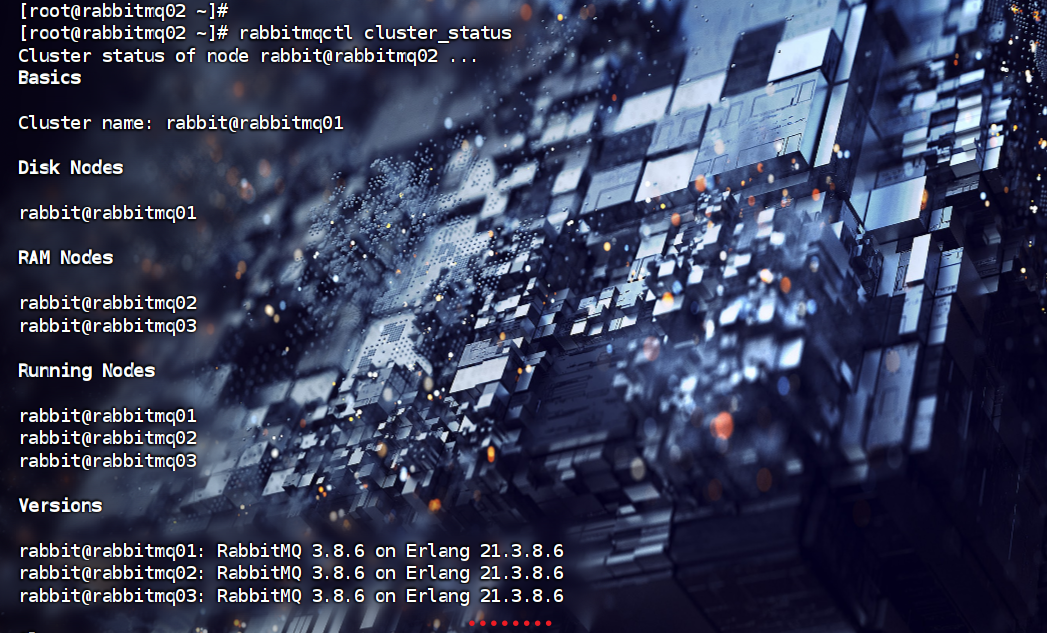
到此:
 三、镜像集群配置
三、镜像集群配置
在网页上打开三个虚拟机的任意一个RabbitMQ的控制台,按照以下添加策略:
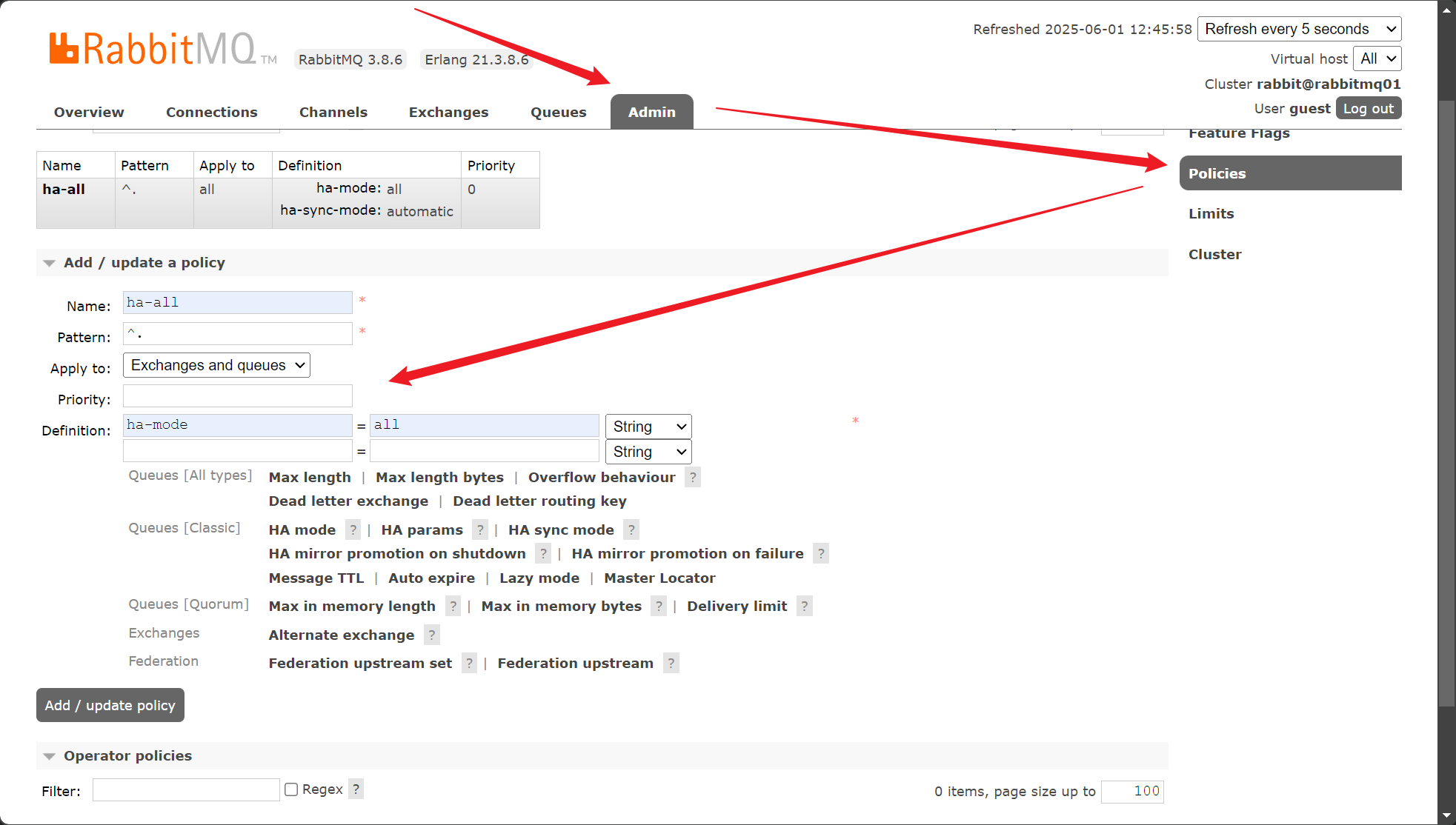
当然如果不想用上面的方式,可以执行下面一行命令来完成操作(任意虚拟机即可):
策略参数解读:# ha-all:为策略名称;
# ^my:为匹配符,只有一个^代表匹配所有,^abc为匹配名称以abc开头的queue或exchange,^.则
匹配所有
# ha-mode:为同步模式,一共3种模式:
# all-所有(所有的节点都同步消息),
# exctly-指定节点的数目(需配置ha-params参数,此参数为int类型比如2,在集群中随机
抽取2个节点同步消息)
# nodes-指定具体节点(需配置ha-params参数,此参数为数组类型比如
["rabbit@rabbitmq01","rabbit@rabbitmq02"],明确#指定在这两个节点上同步消息)。
# ha-sync-mode
#ha-sync-mode=manual(默认),镜像队列中的消息不会主动同步到新节点,除非显式调用同步命令,
调用同步命令后,队列开始阻塞,无法对其进行操作,直到同步完毕
#ha-sync-mode=automatic 新加入节点时会默认同步已知的镜像队列#执行该命令等效于上面的页面添加策略操作
rabbitmqctl set_policy ha-all "^." '{"ha-mode":"all","ha-sync-mode":"automatic"}'测试:
#关闭rabbitmq01
rabbitmqctl stop_app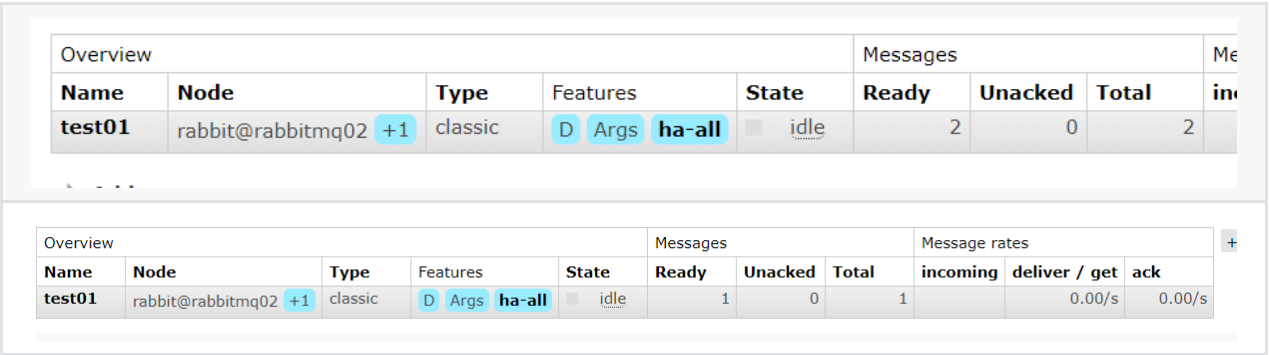
四、HAProxy实现负载均衡(主用虚拟机操作)
yum install -y haproxyhaproxy -v看到下面则安装成功:
### haproxy 监控页面地址是:http://192.168.93.134:9188/haproxy_statuslisten admin_statsbind *:9188mode httplog 127.0.0.1 local3 errstats refresh 60sstats uri /haproxy_statusstats realm welcome login\ Haproxystats auth admin:123456 ##记得改成自己的账号和密码stats hide-versionstats admin if TRUE### rabbitmq 集群配置,转发到listen rabbitmq_clusterbind *:5672mode tcpbalance roundrobinserver rabbitnode1 192.168.93.135:5672 check inter 2000 rise 2 fall 3 weight 1server rabbitnode2 192.168.93.136:5672 check inter 2000 rise 2 fall 3 weight 1server rabbitnode3 192.168.93.137:5672 check inter 2000 rise 2 fall 3 weight 1添加后:
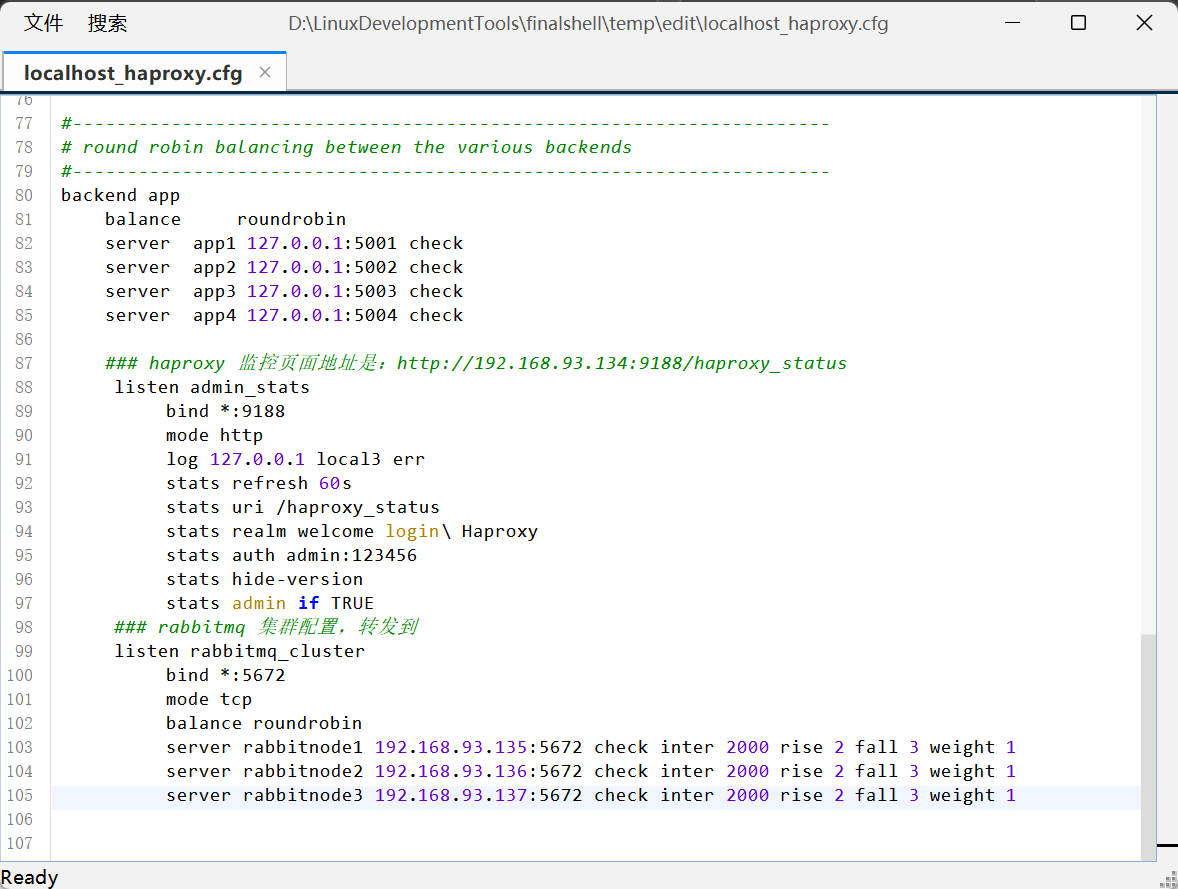
完成上述的修改和配置后,启动
haproxy -f /etc/haproxy/haproxy.cfg在网页上访问:http://192.168.93.134:9188/haproxy_status
看到下图,说明已经配置成功:
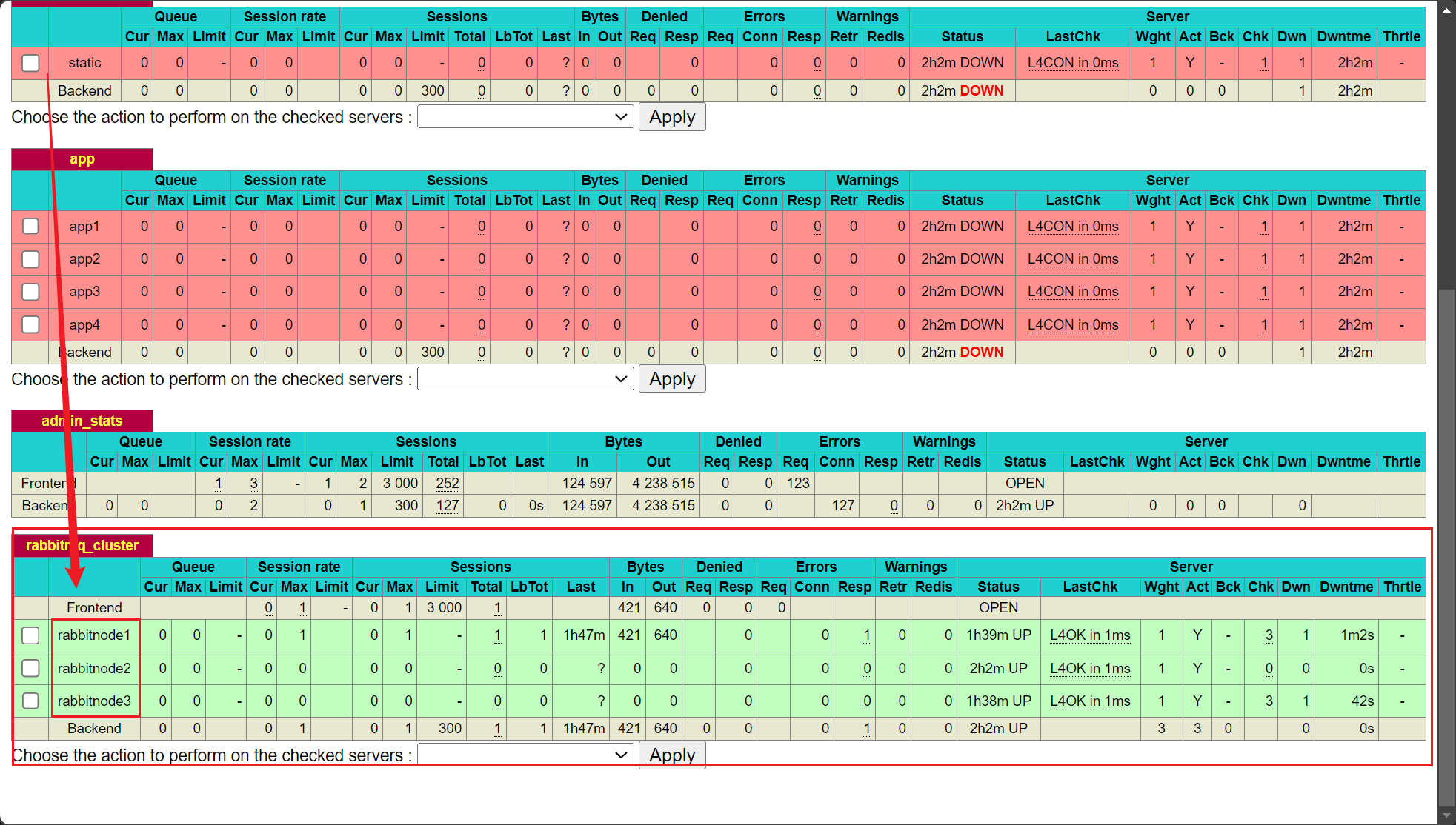
可以看到三个虚拟机已经和HAProxy实现了负载均衡,当有信息发送到三台主机中的任意一个rabbitMQ时,尽管两外一台或两台出现宕机的情况,仍然不妨碍我们使用。
五、测试RabbitMQ集群搭建情况
完成上面的所有配置后,下面使用IDEA来连接RabbitMQ测试搭建情况:
连接三台中任意一台虚拟机即可:
public class SimpleProducer {public static void main(String[] args) throws IOException, TimeoutException {//1.创建连接工厂,并且设置RabbitMQ相关的连接参数ConnectionFactory connectionFactory = new ConnectionFactory();connectionFactory.setHost("192.168.93.135");connectionFactory.setPort(5672); //设置rabbitMq的默认端口 不修改可以不设置//connectionFactory.setUsername("admin");//connectionFactory.setPassword("123456");//connectionFactory.setVirtualHost("myVH");//2.根据连接工厂创建一个连接,根据这个连接创建一个channelConnection connection = connectionFactory.newConnection();Channel channel = connection.createChannel();//3.创建一个队列(Queue)//设置队列名、是否持久化、是否独占、是否被消费后自动删除、队列参数等等channel.queueDeclare("hello",true,false,false,null);//4.发布一条消息//设置交换机名称、routingKey、信息属性、消息内容channel.basicPublish("","hello",null,"Hello,World".getBytes());//5.释放资源channel.close();connection.close();}
}发送信息后,查看任意页面:
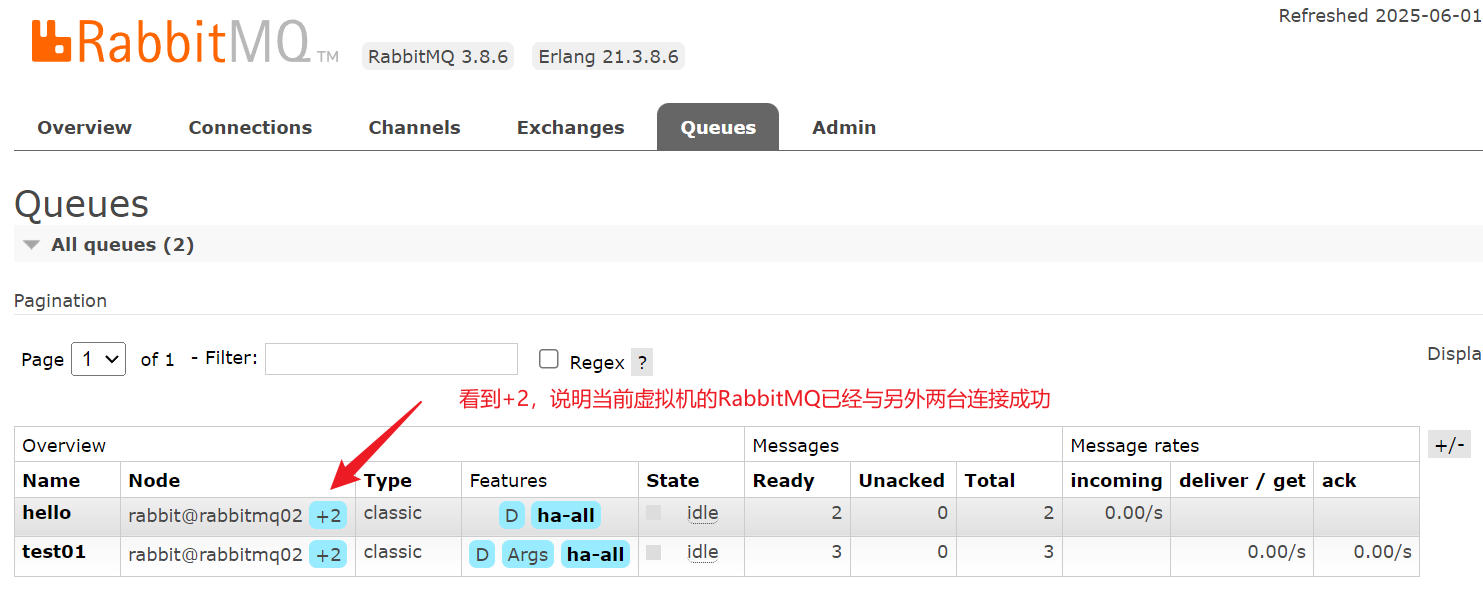
当故意关闭三台中的任意一台或两台虚拟机(模拟宕机)时,仍可以继续发送信息,再次启动“宕机”的虚拟机,会自动同步消息,应为三台机器已经构成一个集群,可以实现信息互相同步,当出问题时,信息会立刻同步到正常的机器上去,宕机修复后又可以同步,这里不再演示此过程。
)


)
,VSCODE+Claude3.5+deepseek开发edge扩展插件V2)





:Proxy-Wasm Go SDK)



)

)

)
)