DAY 44 预训练模型
知识点回顾:
1. 预训练的概念
2. 常见的分类预训练模型
3. 图像预训练模型的发展史
4. 预训练的策略
5. 预训练代码实战:resnet18
作业:
1. 尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同
2. 尝试通过ctrl进入resnet的内部,观察残差究竟是什么
一、预训练的概念
我们之前在训练中发现,准确率最开始随着epoch的增加而增加。随着循环的更新,参数在不断发生更新。
所以参数的初始值对训练结果有很大的影响:
1. 如果最开始的初始值比较好,后续训练轮数就会少很多
2. 很有可能陷入局部最优值,不同的初始值可能导致陷入不同的局部最优值
所以很自然的想到,如果最开始能有比较好的参数,即可能导致未来训练次数少,也可能导致未来训练避免陷入局部最优解的问题。这就引入了一个概念,即预训练模型。
如果别人在某些和我们目标数据类似的大规模数据集上做过训练,我们可以用他的训练参数来初始化我们的模型,这样我们的模型就比较容易收敛。
Q&A:
1. 那为什么要选择类似任务的数据集预训练的模型参数呢?
因为任务差不多,他提取特征的能力才有用,如果任务相差太大,他的特征提取能力就没那么好。
所以本质预训练就是拿别人已经具备的通用特征提取能力来接着强化能力使之更加适应我们的数据集和任务。
2. 为什么要求预训练模型是在大规模数据集上训练的,小规模不行么?
因为提取的是通用特征,所以如果数据集数据少、尺寸小,就很难支撑复杂任务学习通用的数据特征。比如你是一个物理的博士,让你去做小学数学题,很快就能上手;但是你是一个小学数学速算高手,让你做物理博士的课题,就很困难。所以预训练模型一般就挺强的。
我们把用预训练模型的参数,然后接着在自己数据集上训练来调整该参数的过程叫做微调,这种思想叫做迁移学习。把预训练的过程叫做上游任务,把微调的过程叫做下游任务。
二、经典的预训练模型
2.1 CNN 架构预训练模型
| 模型 | 预训练数据集 | 核心特点 | 在 CIFAR10 上的适配要点 |
|---|---|---|---|
| AlexNet | ImageNet | 首次引入 ReLU / 局部响应归一化,参数量 6000 万 + | 需修改首层卷积核大小(原 11x11→适配 32x32) |
| VGG16 | ImageNet | 纯卷积堆叠,结构统一,参数量 1.38 亿 | 冻结前 10 层卷积,仅微调全连接层 |
| ResNet18 | ImageNet | 残差连接解决梯度消失,参数量 1100 万 | 直接适配 32x32 输入,需调整池化层步长 |
| MobileNetV2 | ImageNet | 深度可分离卷积,参数量 350 万 + | 轻量级设计,适合计算资源有限的场景 |
2.2 Transformer 类预训练模型
适用于较大尺寸图像(如 224×224),在 CIFAR10 上需上采样图像尺寸或调整 Patch 大小。
| 模型 | 预训练数据集 | 核心特点 | 在 CIFAR10 上的适配要点 |
|---|---|---|---|
| ViT-Base | ImageNet-21K | 纯 Transformer 架构,参数量 8600 万 | 图像 Resize 至 224×224,Patch 大小设为 4×4 |
| Swin Transformer | ImageNet-22K | 分层窗口注意力,参数量 8000 万 + | 需调整窗口大小适配小图像 |
| DeiT | ImageNet | 结合 CNN 归纳偏置,参数量 2200 万 | 轻量级 Transformer,适合中小尺寸图像 |
2.3 自监督预训练模型
无需人工标注,通过 pretext task(如掩码图像重建)学习特征,适合数据稀缺场景。
| 模型 | 预训练方式 | 典型数据集 | 在 CIFAR10 上的优势 |
|---|---|---|---|
| MoCo v3 | 对比学习 | ImageNet | 无需标签即可迁移,适合无标注数据 |
| BEiT | 掩码图像建模 | ImageNet-22K | 特征语义丰富,微调时收敛更快 |
三、常见的分类预训练模型介绍
3.1 预训练模型的发展史
模型对比表
| 模型 | 年份 | 提出团队 | 关键创新点 | 层数 | 参数量 | ImageNet Top-5 错误率 | 典型应用场景 | 预训练权重可用性 |
|---|---|---|---|---|---|---|---|---|
| LeNet-5 | 1998 | Yann LeCun 等 | 首个 CNN 架构,卷积层 + 池化层 + 全连接层,Sigmoid 激活函数 | 7 | ~60K | N/A | 手写数字识别(MNIST) | 无(历史模型) |
| AlexNet | 2012 | Alex Krizhevsky 等 | ReLU 激活函数、Dropout、数据增强、GPU 训练 | 8 | 60M | 15.3% | 大规模图像分类 | PyTorch/TensorFlow 官方支持 |
| VGGNet | 2014 | Oxford VGG 团队 | 统一 3×3 卷积核、多尺度特征提取、结构简洁 | 16/19 | 138M/144M | 7.3%/7.0% | 图像分类、目标检测基础骨干网络 | PyTorch/TensorFlow 官方支持 |
| GoogLeNet | 2014 | Inception 模块(多分支并行卷积)、1×1 卷积降维、全局平均池化 | 22 | 5M | 6.7% | 大规模图像分类 | PyTorch/TensorFlow 官方支持 | |
| ResNet | 2015 | 何恺明等 | 残差连接(解决梯度消失)、Batch Normalization | 18/50/152 | 11M/25M/60M | 3.57%/3.63%/3.58% | 图像 / 视频分类、检测、分割 | PyTorch/TensorFlow 官方支持 |
| DenseNet | 2017 | Gao Huang 等 | 密集连接(每层与后续所有层相连)、特征复用、参数效率高 | 121/169 | 8M/14M | 2.80% | 小数据集、医学图像处理 | PyTorch/TensorFlow 官方支持 |
| MobileNet | 2017 | 深度可分离卷积(减少 75% 计算量)、轻量级设计 | 28 | 4.2M | 7.4% | 移动端图像分类 / 检测 | PyTorch/TensorFlow 官方支持 | |
| EfficientNet | 2019 | 复合缩放(同时优化深度、宽度、分辨率)、NAS 搜索最佳配置 | B0-B7 | 5.3M-66M | 2.6% (B7) | 高精度图像分类(资源受限场景) | PyTorch/TensorFlow 官方支持 |
补充说明:
- 层数含义:代表模型不同版本,如 ResNet 有 18/50/152 层,EfficientNet 有 B0-B7 等变体。
- ImageNet Top-5 准确率:模型预测概率前五的类别中包含正确类别的比例,是图像分类任务的重要评估指标(共 1000 类)。
模型架构演进关键点总结
- 深度突破:从 LeNet 的 7 层到 ResNet152 的 152 层,残差连接解决了深度网络的训练难题。
(没上过复试班 CV 部分的自行了解残差连接,非常重要!) - 计算效率:GoogLeNet(Inception)和 MobileNet 通过结构优化,在保持精度的同时大幅降低参数量。
- 特征复用:DenseNet 的密集连接设计使模型能更好地利用浅层特征,适合小数据集。
- 自动化设计:EfficientNet 使用神经架构搜索(NAS)自动寻找最优网络配置,开创了 AutoML 在 CNN 中的应用。
预训练模型使用建议
| 任务需求 | 推荐模型 | 理由 |
|---|---|---|
| 快速原型开发 | ResNet50/18 | 结构平衡,预训练权重稳定,社区支持完善 |
| 移动端部署 | MobileNetV3 | 参数量小,计算高效,专为移动设备优化 |
| 高精度分类(资源充足) | EfficientNet-B7 | 目前 ImageNet 准确率领先,适合 GPU/TPU 环境 |
| 小数据集或特征复用需求 | DenseNet | 密集连接设计减少过拟合,特征复用能力强 |
| 多尺度特征提取 | Inception-ResNet | 结合 Inception 多分支和 ResNet 残差连接,适合复杂场景 |
说明:
模型预训练权重均可通过主流框架(如 PyTorch 的torchvision.models、Keras 的applications模块)直接加载,便于快速迁移到新任务。
总结:CNN 架构发展脉络
1. 早期探索(1990s-2010s):LeNet 验证 CNN 可行性,但受限于计算和数据。
2. 深度学习复兴(2012-2015):AlexNet、VGGNet、GoogLeNet 通过加深网络和结构创新突破性能。
3. 超深网络时代(2015 年后):ResNet 解决退化问题,开启残差连接范式,后续模型围绕效率(MobileNet)、特征复用(DenseNet)、多分支结构(Inception)等方向优化。
3.2预训练模型的训练策略
那么什么模型会被选为预训练模型呢?比如一些调参后表现很好的cnn神经网络(固定的神经元个数+固定的层数等)。
所以调用预训练模型做微调,本质就是 用这些固定的结构+之前训练好的参数 接着训练
所以需要找到预训练的模型结构并且加载模型参数
相较于之前用自己定义的模型有以下几个注意点
1. 需要调用预训练模型和加载权重
2. 需要resize 图片让其可以适配模型
3. 需要修改最后的全连接层以适应数据集
其中,训练过程中,为了不破坏最开始的特征提取器的参数,最开始往往先冻结住特征提取器的参数,然后训练全连接层,大约在5-10个epoch后解冻训练。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器(可调整batch_size)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 训练函数(支持学习率调度器)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []for epoch in range(epochs):running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录Iteration损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计训练指标running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印进度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 单Batch损失: {iter_loss:.4f}")# 计算 epoch 级指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 测试阶段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录历史数据train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新学习率调度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 结果print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 5. 绘制Iteration损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('训练过程中的Iteration损失变化')plt.grid(True)plt.show()# 6. 绘制Epoch级指标曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('准确率随Epoch变化')plt.legend()plt.grid(True)# 损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('损失值随Epoch变化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()
# 导入ResNet模型
from torchvision.models import resnet18# 定义ResNet18模型(支持预训练权重加载)
def create_resnet18(pretrained=True, num_classes=10):# 加载预训练模型(ImageNet权重)model = resnet18(pretrained=pretrained)# 修改最后一层全连接层,适配CIFAR-10的10分类任务in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes)# 将模型转移到指定设备(CPU/GPU)model = model.to(device)return model# 创建ResNet18模型(加载ImageNet预训练权重,不进行微调)
model = create_resnet18(pretrained=True, num_classes=10)
model.eval() # 设置为推理模式# 测试单张图片(示例)
from torchvision import utils# 从测试数据集中获取一张图片
dataiter = iter(test_loader)
images, labels = next(dataiter)
images = images[:1].to(device) # 取第1张图片# 前向传播
with torch.no_grad():outputs = model(images)_, predicted = torch.max(outputs.data, 1)# 显示图片和预测结果
plt.imshow(utils.make_grid(images.cpu(), normalize=True).permute(1, 2, 0))
plt.title(f"预测类别: {predicted.item()}")
plt.axis('off')
plt.show()
在 CIFAR-10 数据集中,类别标签是固定的 10 个,分别对应:
| 标签(数字) | 类别名称 | 说明 |
|---|---|---|
| 0 | airplane | 飞机 |
| 1 | automobile | 汽车(含轿车、卡车等) |
| 2 | bird | 鸟类 |
| 3 | cat | 猫 |
| 4 | deer | 鹿 |
| 5 | dog | 狗 |
| 6 | frog | 青蛙 |
| 7 | horse | 马 |
| 8 | ship | 船 |
| 9 | truck | 卡车(重型货车等) |
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义ResNet18模型
def create_resnet18(pretrained=True, num_classes=10):model = models.resnet18(pretrained=pretrained)# 修改最后一层全连接层in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes)return model.to(device)# 5. 冻结/解冻模型层的函数
def freeze_model(model, freeze=True):"""冻结或解冻模型的卷积层参数"""# 冻结/解冻除fc层外的所有参数for name, param in model.named_parameters():if 'fc' not in name:param.requires_grad = not freeze# 打印冻结状态frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)total_params = sum(p.numel() for p in model.parameters())if freeze:print(f"已冻结模型卷积层参数 ({frozen_params}/{total_params} 参数)")else:print(f"已解冻模型所有参数 ({total_params}/{total_params} 参数可训练)")return model# 6. 训练函数(支持阶段式训练)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5):"""前freeze_epochs轮冻结卷积层,之后解冻所有层进行训练"""train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []# 初始冻结卷积层if freeze_epochs > 0:model = freeze_model(model, freeze=True)for epoch in range(epochs):# 解冻控制:在指定轮次后解冻所有层if epoch == freeze_epochs:model = freeze_model(model, freeze=False)# 解冻后调整优化器(可选)optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合model.train() # 设置为训练模式running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录Iteration损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计训练指标running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印进度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 单Batch损失: {iter_loss:.4f}")# 计算 epoch 级指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 测试阶段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录历史数据train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新学习率调度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 结果print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 7. 绘制Iteration损失曲线
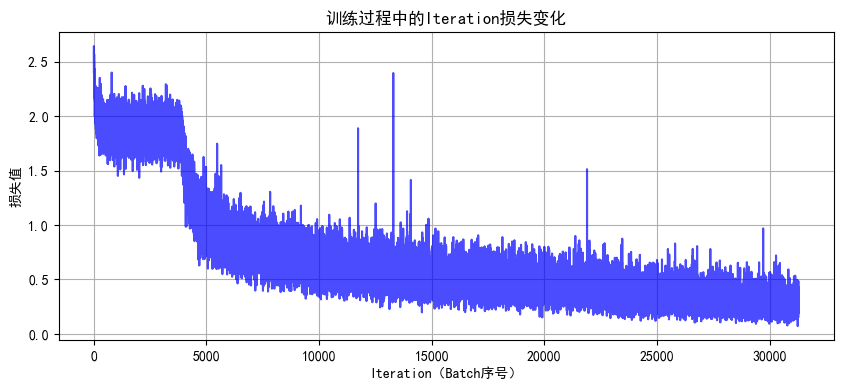
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('训练过程中的Iteration损失变化')plt.grid(True)plt.show()# 8. 绘制Epoch级指标曲线
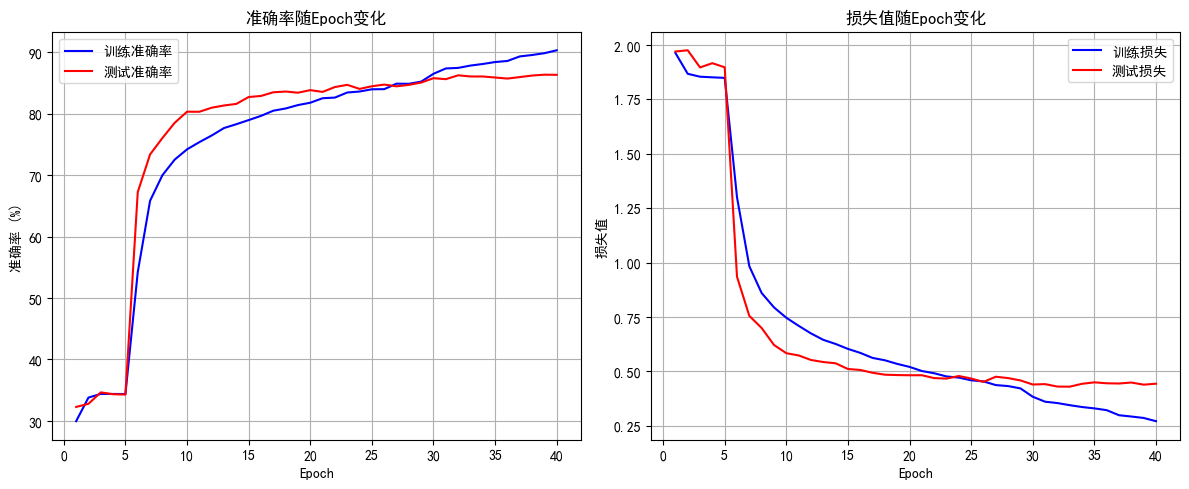
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('准确率随Epoch变化')plt.legend()plt.grid(True)# 损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('损失值随Epoch变化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 主函数:训练模型
def main():# 参数设置epochs = 40 # 总训练轮次freeze_epochs = 5 # 冻结卷积层的轮次learning_rate = 1e-3 # 初始学习率weight_decay = 1e-4 # 权重衰减# 创建ResNet18模型(加载预训练权重)model = create_resnet18(pretrained=True, num_classes=10)# 定义优化器和损失函数optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)criterion = nn.CrossEntropyLoss()# 定义学习率调度器scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2, verbose=True)# 开始训练(前5轮冻结卷积层,之后解冻)final_accuracy = train_with_freeze_schedule(model=model,train_loader=train_loader,test_loader=test_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,device=device,epochs=epochs,freeze_epochs=freeze_epochs)print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型# torch.save(model.state_dict(), 'resnet18_cifar10_finetuned.pth')# print("模型已保存至: resnet18_cifar10_finetuned.pth")if __name__ == "__main__":main()

几个明显的现象
1. 解冻后几个epoch即可达到之前cnn训练20轮的效果,这是预训练的优势
2. 由于训练集用了 RandomCrop(随机裁剪)、RandomHorizontalFlip(随机水平翻转)、ColorJitter(颜色抖动)等数据增强操作,这会让训练时模型看到的图片有更多 “干扰” 或变形。比如一张汽车图片,训练时可能被裁剪成只显示局部、颜色也有变化,模型学习难度更高;而测试集是标准的、没增强的图片,模型预测相对轻松,就可能出现训练集准确率暂时低于测试集的情况,尤其在训练前期增强对模型影响更明显。随着训练推进,模型适应增强后会缓解。
3. 最后收敛后的效果超过非预训练模型的80%,大幅提升
作业
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 数据预处理
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 加载数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)def create_resnet50(pretrained=True, num_classes=10):model = models.resnet50(pretrained=pretrained) in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes) return model.to(device)# 训练函数
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5):"""前freeze_epochs轮冻结卷积层,之后解冻所有层进行训练"""train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []# 初始冻结卷积层if freeze_epochs > 0:model = freeze_model(model, freeze=True)for epoch in range(epochs):# 解冻控制:在指定轮次后解冻所有层if epoch == freeze_epochs:model = freeze_model(model, freeze=False)# 解冻后调整优化器(可选)optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合model.train() # 设置为训练模式running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录Iteration损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计训练指标running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印进度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 单Batch损失: {iter_loss:.4f}")# 计算 epoch 级指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 测试阶段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录历史数据train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新学习率调度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 结果print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 绘图函数
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('训练过程中的Iteration损失变化')plt.grid(True)plt.show()def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('准确率随Epoch变化')plt.legend()plt.grid(True)# 损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('损失值随Epoch变化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()def main():epochs = 40freeze_epochs = 5learning_rate = 5e-4 weight_decay = 1e-4# 创建ResNet50模型model = create_resnet50(pretrained=True)# 定义优化器optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=weight_decay, momentum=0.9 # 添加动量加速收敛)criterion = nn.CrossEntropyLoss()scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2, verbose=True)# 训练流程final_accuracy = train_with_freeze_schedule(model=model,train_loader=train_loader,test_loader=test_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,device=device,epochs=epochs,freeze_epochs=freeze_epochs)print(f"\nResNet50在CIFAR-10上的最终测试准确率: {final_accuracy:.2f}%")# 保存模型(可选)# torch.save(model.state_dict(), 'resnet50_cifar10_finetuned.pth')if __name__ == "__main__":main()@浙大疏锦行

)




)












