
文章目录
- Abstract
- Introduction
- Related Work
- Vector Graphics Recognition
- Panoptic Symbol Spotting
- Point Cloud Segmentation
- Method
- From Symbol to Points
- Primitive position
- Primitive feature
- Panoptic Symbol Spotting via Point-based Representation
- Backbone
- Symbol Spotting Head
- Attention with Connection Module
- Contrastive Connection Learning
- KNN Interpolation
- Training and Inference
- Experiments
- Experimental Setting
- Dataset and Metrics
- Implementation Details
- Benchmark Results
- Semantic symbol spotting
- Instance Symbol Spotting
- Panoptic Symbol Spotting
- Ablation Studies
- Effects of Techniques
- KNN Interpolation
- Architecture Design
- Conclusion and Future Work
paper
code
Abstract
本文研究的是全光学符号识别问题,即从计算机辅助设计(CAD)图纸中识别和解析可计数物体实例(窗户、门、桌子等)和不可计数物体(墙壁、栏杆等)。现有的方法通常包括将矢量图形光栅化成图像并使用基于图像的方法进行符号识别,或者直接构建图形并使用图形神经网络进行符号识别。在本文中,我们采用了一种不同的方法,将图形原语视为一组局部连接的2D点,并使用点云分割方法来处理它。具体来说,我们利用一个点转换器来提取原始特征,并附加一个类似于mask2former的点阵头来预测最终输出。为了更好地利用原语的局部连接信息,增强原语的可分辨性,我们进一步提出了连接模块关注(ACM)和对比连接学习方案(CCL)。最后,我们提出了一种KNN插值机制,用于点状头的mask注意模块,以更好地处理原始mask下采样,这与图像的像素级相比是原始级的。我们的方法名为SymPoint,简单而有效,在FloorPlanCAD数据集上,其PQ和RQ的绝对增幅分别为9.6%和10.4%,优于最近最先进的GAT-CADNet方法。
Introduction
矢量图形(VG)以其任意缩放的能力而闻名,而不会屈服于诸如模糊或细节混叠之类的问题,已成为工业设计中的主要内容。这包括它们在平面设计(Reddy et al., 2021)、2D界面(Carlier et al., 2020)和计算机辅助设计(CAD)(Fan et al., 2021)中的普遍使用。具体地说,CAD绘图,由几何原语(例如:(如弧、圆、折线等),已成为室内设计、室内建筑和房地产开发领域的首选数据表示方法,推动了这些领域更高的精度和创新标准。
符号识别(Rezvanifar et al., 2019;2020年;Fan等,2021;2022年;Zheng et al., 2022)是指从CAD图纸中发现和识别符号,这是检查设计图纸和3D建筑信息建模(BIM)错误的基础任务。由于存在诸如遮挡、聚类、外观变化以及不同类别分布的显着不平衡等障碍,在CAD绘图中发现每个符号(一组图形原语)是一项重大挑战。传统的符号识别通常处理代表可数事物的实例符号(Rezvanifar等人,2019),如桌子、沙发和床。Fan等人(2021)进一步将其扩展到全视符号识别,既可以识别可数实例(例如,一扇门、一扇窗、一张桌子等),也可以识别不可数物体(例如,墙、栏杆等)。
典型方法(Fan et al., 2021;2022)解决全光符号识别任务涉及首先将CAD图纸转换为光栅图形(RG),然后使用强大的基于图像的检测或分割方法对其进行处理(Ren et al., 2015;Sun等人,2019)。另一行先前的作品(Jiang et al., 2021;郑等,2022;Yang等人,2023)放弃栅格过程,直接处理矢量图形,使用图卷积网络进行识别。代替将CAD绘图光栅化到图像或用GCN/GAT对图形原语建模,这在计算上可能是昂贵的,特别是对于大型CAD图形,我们提出了一个新的范例,它有可能产生新的见解,而不仅仅是在性能上提供增量进步。
通过对CAD图纸数据特征的分析,我们可以发现CAD图纸有三个主要特性:1)不规则性和无序性。与光栅图形/图像中的常规像素数组不同,CAD绘图由几何原语(例如:(圆弧、圆、折线等),没有特定的顺序。2).图形基元之间的局部交互。每个图形原语不是孤立的,而是与邻近的原语局部相连,形成一个符号。3)变换下的不变性。每个符号对于某些变换都是不变的。例如,旋转和翻译符号不会改变符号的类别。这些属性几乎与点云相同。因此,我们将CAD绘图视为点集(图形原语),并利用点云分析的方法(Qi等人,2017a;b;Zhao et al., 2021)用于符号识别。
在这项工作中,我们首先将每个图形原语视为具有位置和原语属性(类型,长度等)信息的8维数据点。然后,我们利用点云分析的方法进行图形原语表示学习。与点云不同,这些图形原语是局部连接的。因此,我们提出了对比连接学习机制来利用这些局部连接。最后,我们借用了Mask2Former(Cheng et al., 2021;2022),并构建一个mask注意转换器解码器来执行全光符号识别任务。此外,不像(Cheng et al., 2022)那样使用双线性插值进行mask注意力降采样,由于图形基元的稀疏性可能导致信息丢失,我们提出了KNN插值,它融合了最近的相邻基元,用于mask注意力降采样。我们在FloorPlanCAD数据集上进行了广泛的实验,我们的SymPoint在全光符号识别设置下实现了83.3%的PQ和91.1%的RQ,大大优于最近最先进的GAT-CADNet方法(Zheng et al., 2022)。
Related Work
Vector Graphics Recognition
矢量图形广泛应用于二维CAD设计、城市设计、平面设计、电路设计等领域,便于实现无分辨率的高精度几何建模。考虑到矢量图的广泛应用和重要性,许多工作致力于矢量图的识别任务。Jiang等人(2021)探索了矢量化目标检测,并取得了优于检测方法的精度(Bochkovskiy等人,2020;Lin等人,2017)在栅格图形上工作,同时享受更快的推理时间和更少的训练参数。Shi等人(2022)提出了一个统一的矢量图形识别框架,该框架利用了矢量图形和光栅图形的优点。
Panoptic Symbol Spotting
传统的符号识别通常处理代表可数事物的实例符号(Rezvanifar等人,2019),如桌子、沙发和床。遵循(Kirillov et al., 2019)的思想,Fan et al.(2021)通过识别不可数事物的语义扩展了定义,并将其命名为panoptic symbol spotting。因此,CAD绘图中的所有组件都包含在一个任务中。例如,由一组平行线表示的墙被(Fan et al., 2021)处理得很好,但被(Jiang et al., 2021)作为背景处理;Shi et al., 2022;Nguyen et al., 2009)中的矢量图形识别。同时,(Fan et al., 2021)以矢量图形的形式发布了第一个大规模的真实世界floorplanad数据集。Fan等人(2022)提出了CADTransformer,它修改了现有的视觉transformer(ViT)主干,用于全光符号识别任务。Zheng等人(2022)提出了GAT-CADNet,它将实例符号识别任务表述为子图检测问题,并通过预测邻接矩阵来解决。
Point Cloud Segmentation
点云分割的目的是将点映射到多个同质组中。点云与二维图像不同,二维图像的特征是有序排列的密集像素,而点云是由无序和不规则的点集组成的。这使得直接将图像处理方法应用于点云分割成为一种不切实际的方法。然而,近年来,神经网络的集成显著增强了点云分割在一系列应用中的有效性,包括语义分割(Qi等人,2017a;a;Zhao et al., 2021),实例分割(Ngo et al., 2023;Schult et al., 2023)和全视分割(Zhou et al., 2021;Li et al., 2022;Hong et al., 2021;Xiao et al., 2023)等。
Method
我们的方法放弃了光栅图像或GCN,而支持图形原语的基于点的表示。与基于图像的表示相比,由于原始CAD图纸的稀疏性,它降低了模型的复杂性。在本节中,我们首先描述如何使用CAD图纸的图形原语形成基于点的表示。然后,我们说明了一个基线框架的全光符号定位。最后,我们详细解释了三种关键技术,即关注局部连接、对比连接学习和KNN插值,以使该基线框架更好地处理CAD数据。
From Symbol to Points
给定由一组图形基元{pk}表示的矢量图形,我们将其视为点{pk | (xk , fk)}的集合,每个点都包含基元位置{xk}和基元特征{fk}信息;因此,点集可能是无序和无组织的。
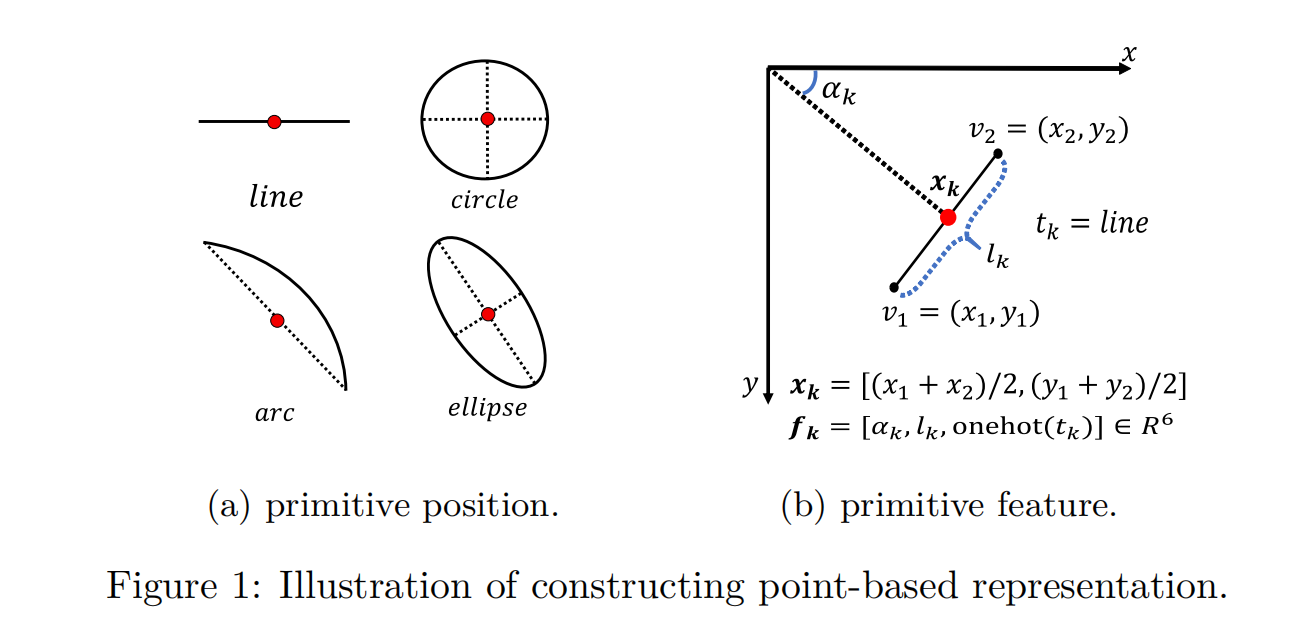
Primitive position
给定一个图形原语,起点和终点的坐标分别为(x1, y1)和(x1, y2)。原始位置xk∈R2定义为:
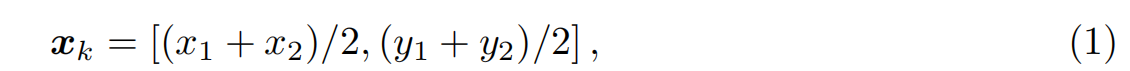
我们把它的中心作为封闭图形原语(圆、椭圆)的原语位置。如图1a所示。
Primitive feature
我们定义基元特征fk∈R6为:

其中αk为x正轴到xk的顺时针角度,lk为v1到v2的长度,如图1b所示。我们将原语类型tk(直线、圆弧、圆或椭圆)编码为一个单热向量,以弥补段近似的缺失信息。
Panoptic Symbol Spotting via Point-based Representation
基线框架主要由两个部分组成:主干和符号定位头。主干将原始点转换为点特征,而符号识别头通过可学习查询预测符号掩码(Cheng et al., 2021;2022)。图2展示了整个框架。
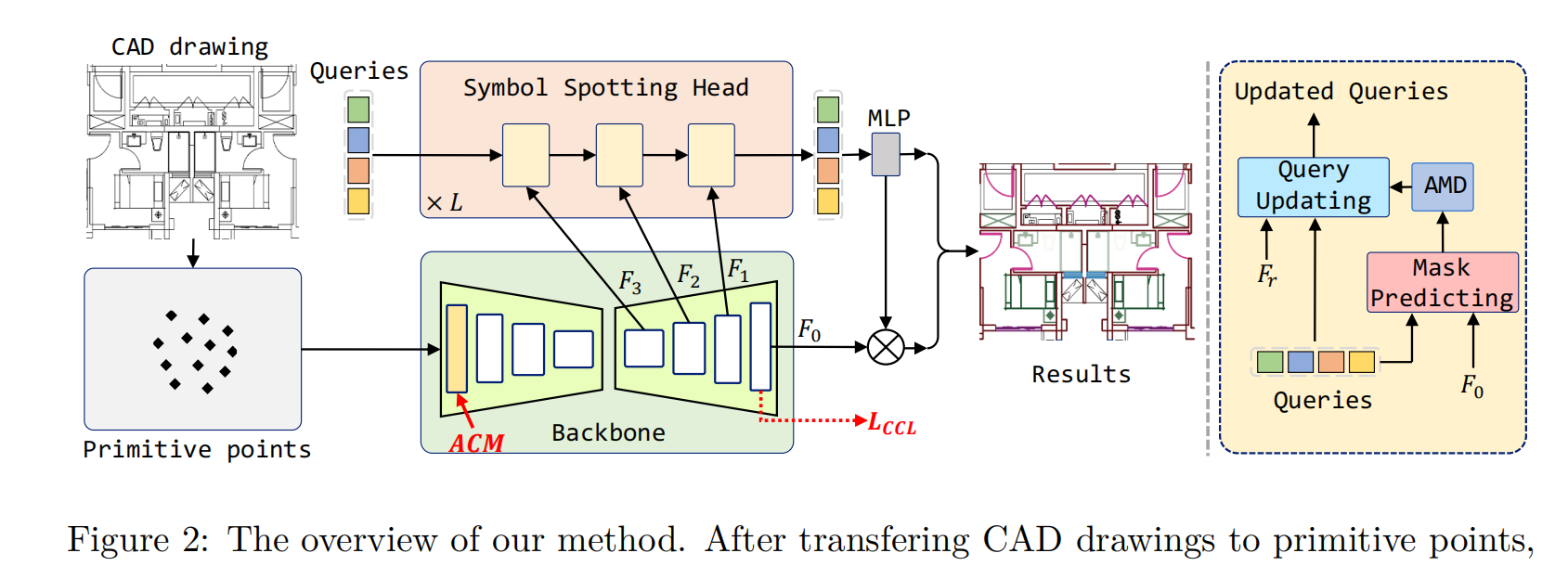
在将CAD图形转换为原始点后,我们使用主干提取多分辨率特征Fr,并附加符号识别头来识别和识别符号。在此过程中,我们提出了连接模块(ACM)的注意,该模块在backone的第一阶段进行自我注意时利用原始连接信息。随后,我们提出了对比连接学习(CCL)来增强连接原语特征之间的区分能力。最后,我们提出了KNN插值的注意遮罩下采样(AMD),以有效地下采样高分辨率的注意遮罩。
Backbone
我们选择具有对称编码器和解码器的点transformer(Zhao et al., 2021)作为特征提取的骨干,因为它在全光符号识别方面具有良好的泛化能力。主干以原始点为输入,在每个点与相邻点之间进行向量关注,探索局部关系。给定一个点pi和它的邻点M(pi),我们将它们投影到查询特征qi、关键特征kj和值特征vj中,得到向量关注如下:
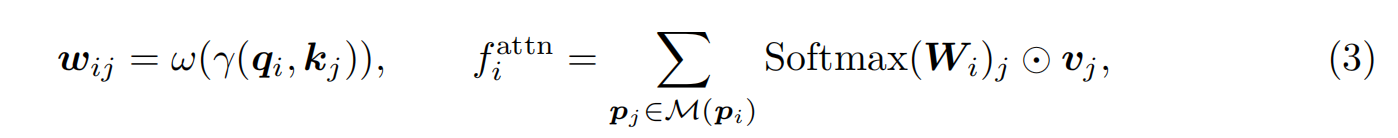
其中γ作为关系函数,例如减法。ω是一种可学习的权重编码,用于计算注意力向量。⊙是Hadamard积。
Symbol Spotting Head
我们遵循Mask2Former (Cheng et al., 2022),使用来自骨干解码器的分层多分辨率原语特征Fr∈RNr×D作为符号定位预测头部的输入,其中Nr为分辨率r中的特征令牌数,D为特征维数。该头部由L层被屏蔽的注意力模块组成,这些模块逐步从主干中提升低分辨率特征,以产生用于掩码预测的高分辨率逐像素嵌入。掩码关注模块有两个关键组成部分:查询更新和掩码预测。对于每一层1,查询更新涉及到与不同分辨率原语特征Fr交互以更新查询特征。这个过程可以表示为:
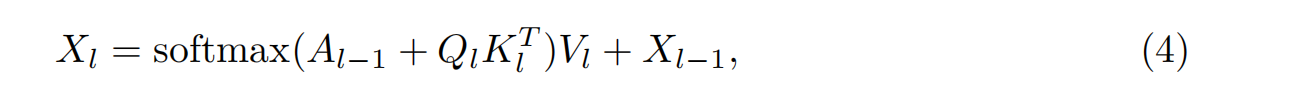
其中Xl∈RO×D为查询特征。O是查询特征的数量。Ql = fQ(Xl−1),Kl = fK(Fr)和Vl = fV(Fr)是MLP层投影的查询、键和值特征。Al−1为注意掩码,计算公式为:
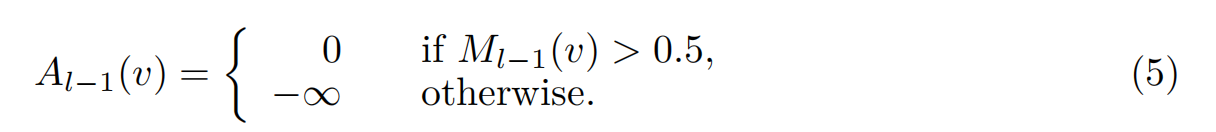
式中,v为特征点位置,Ml−1为掩码预测部分预测的掩码。
注意,我们需要对高分辨率的注意力掩码进行下采样,以采用对低分辨率特征的查询更新。在实际应用中,我们利用了主干网解码器的四个粗级原语特征,并进行了从粗到精的查询更新。
在掩码预测过程中,我们使用两个MLP层fY和fM对查询特征进行投影,得到对象掩码Ml∈RO×N0及其对应的类别Yl∈RO×C;其中C为类别编号,N0为点数。流程如下:
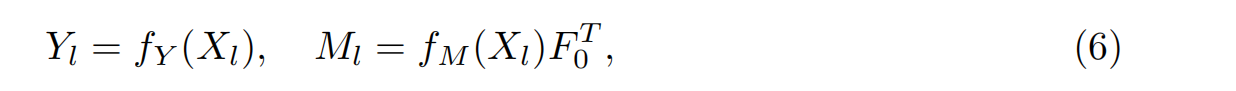
最后一层的输出YL和ML是预测结果。
Attention with Connection Module
简单而统一的框架通过提供CAD绘图的新视角(一组点)来奖励出色的泛化能力。与以往的方法相比,可以获得较好的结果。然而,它忽略了CAD图纸中普遍存在的原始连接。正是由于这些联系,分散的、不相关的图形元素才聚集在一起,形成具有特殊语义的符号。为了利用每个原语之间的这些连接,我们提出了注意连接模块(ACM),详细信息如下所示。
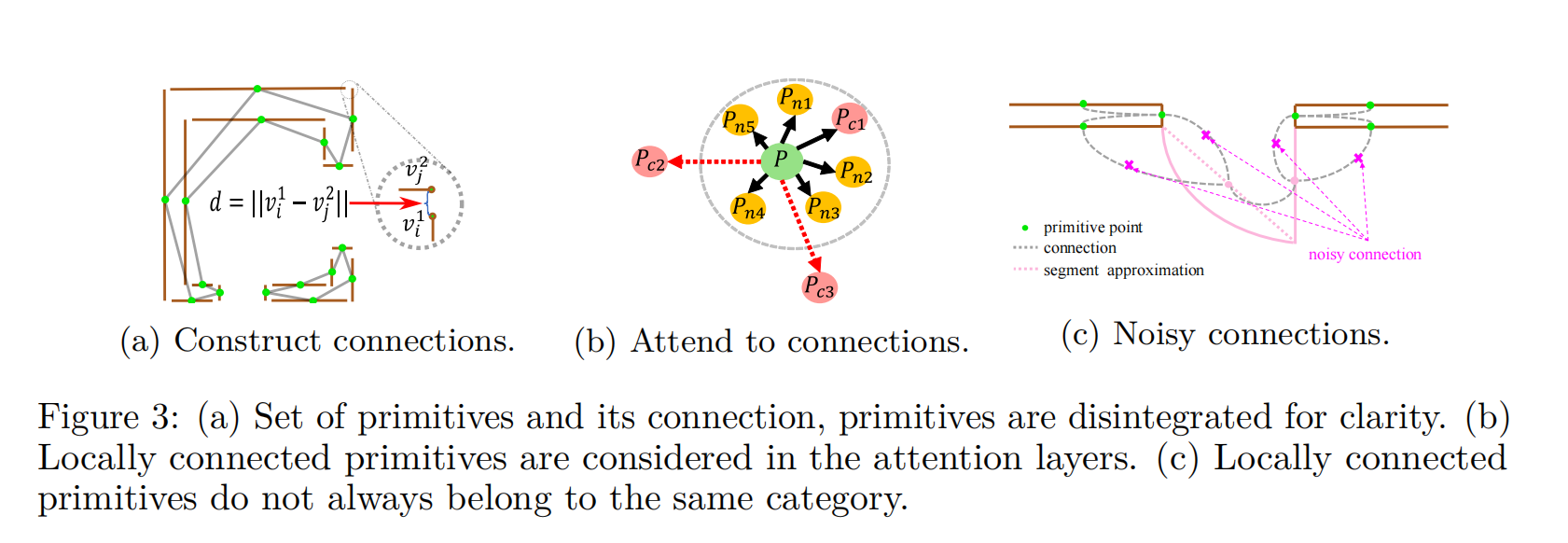
如果两个图基元(pi, pj)的端点(vi, vj)之间的最小距离dij低于某一阈值λ,则认为这两个图基元(pi, pj)是相互连接的,其中:
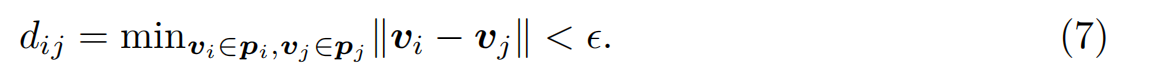
为了保持较低的复杂性,通过随机删除,每个图形原语最多允许K个连接。图3a展示了围绕墙符号的连接构造,灰线是两个原语之间的连接。在实践中,我们设置为1.0px。(Zhao et al., 2021)中的注意机制直接在每个点与其相邻点之间进行局部注意,以探索两者之间的关系。原始注意机制仅与球面区域内相邻点相互作用,如图3b所示。我们的ACM还在注意力期间引入了与局部连接的原始点(粉色点)的相互作用,从本质上扩大了球面区域的半径。请注意,我们通过实验发现,在不考虑原始点的局部连接的情况下,粗略地增加球面区域的半径并不能提高性能。这可能是由于感受野的扩大同时也引入了额外的噪音。具体地说,我们将Eq.(3)中的邻点集M(pi)扩展为A(pi) = M(pi)∪C(pi),其中C(pi) = {pj |dij < λ},得到:
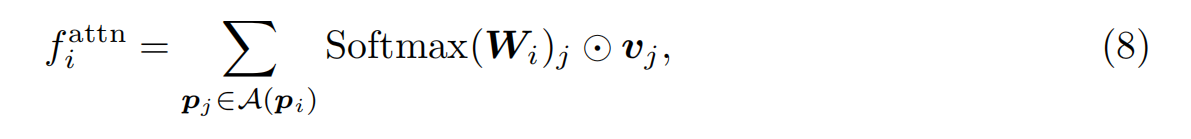
在实际应用中,由于我们无法直接获得主干网中间层各点的连接关系,所以我们将该模块集成到主干网的第一阶段,以取代原有的局部关注,如图2所示。
Contrastive Connection Learning
虽然在计算编码器transformer的注意力时考虑了原语连接的信息,但局部连接的原语可能不属于同一实例,即在考虑原语连接的同时可能引入噪声连接,如图3c所示因此,为了更有效地利用具有类别一致性的连接信息,我们遵循了广泛使用的InfoNCE损失(Oord等人,2018)及其泛化(frost等人,2019;Gutmann & Hyvärinen, 2010)定义对主干最终输出特征的对比学习目标。我们鼓励学习表征与来自同一类别的连接点更相似,与来自不同类别的其他连接点更不同。此外,我们还考虑了相邻点M(pi),得到:
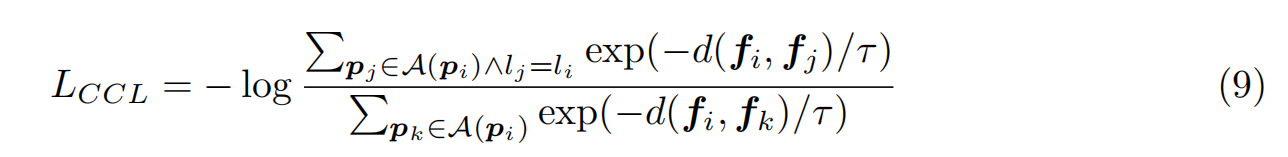
其中fi为pi的主干特征,d(·,·)为距离测量值,τ为对比学习中的温度。我们默认设置τ = 1。
KNN Interpolation
在符号识别头Eq.(4)和Eq.(5)的查询更新过程中,我们需要将高分辨率掩码预测转换为低分辨率,进行注意掩码计算,如图2所示(右图为AMD)。Mask2Former (Cheng et al., 2022)在像素级mask上采用双线性插值进行下采样。然而,CAD图纸的mask是原始级的,直接对其进行双线性插值是不可行的。为此,我们提出了KNN插值,通过融合最近邻点对注意力mask进行降采样。一个简单的操作是最大池化或平均池化。我们使用基于距离的插值。为了简单起见,我们省略了A中的层索引1,
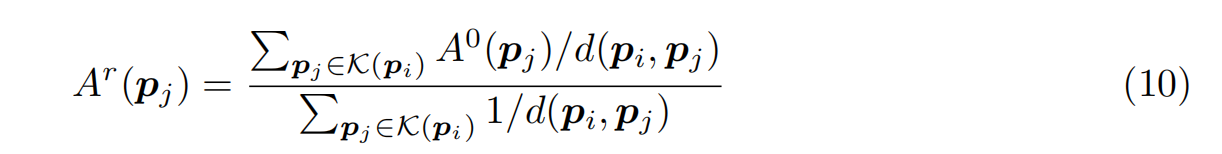
式中,A0和Ar分别为全分辨率注意掩码和r分辨率注意掩码。D(·,·)是距离度量。K(pi)是K个最近邻的集合,在实践中,我们在实验中设置K= 4r。
Training and Inference
在整个训练阶段,我们采用二部匹配和设置预测损失的方法,以最小的匹配代价为预测分配基础真值。全损失函数L可表示为L = λBCELBCE + λdiceLdice + λclsLcls + λCCLLCCL,其中LBCE为二值交叉熵损失(在该掩码的前景和背景上),lice为Dice损失(Deng et al., 2018), Lcls为默认的多类交叉熵损失来监督查询分类,LCCL为对比连接损失。在我们的实验中,我们经验地设置λBCE: λdice: λcls: λCCL = 5:5:2: 8。对于推断,我们简单地使用argmax来确定最终的全景结果。
Experiments
在本节中,我们介绍了在公共CAD绘图数据集FloorPlanCAD上的实验设置和基准测试结果(Fan et al., 2021)。继之前的作品(Fan et al., 2021;郑等,2022;Fan et al., 2022),我们还将我们的方法与典型的基于图像的实例检测进行了比较(Ren et al., 2015;Redmon & Farhadi, 2018;田等人,2019;Zhang等人,2022)。此外,我们还与点云语义分割方法进行了比较(Zhao et al., 2021),进行了广泛的消融研究以验证所提出技术的有效性。此外,我们还验证了我们的方法在floorplanCAD以外的其他数据集上的通用性,详细结果可在附录A中获得。
Experimental Setting
Dataset and Metrics
FloorPlanCAD数据集包含11,602张各种平面图的CAD图纸,带有分段粒度的全景注释,涵盖30个物体和5个物体类。以下(Fan et al., 2021;郑等,2022;Fan等人,2022),我们使用在矢量图形上定义的全光质量(PQ)作为评估全光符号识别性能的主要指标。通过用语义标签l和实例索引z表示图形实体e = (l, z),将PQ定义为分割质量(SQ)和识别质量(RQ)的乘积,表示为
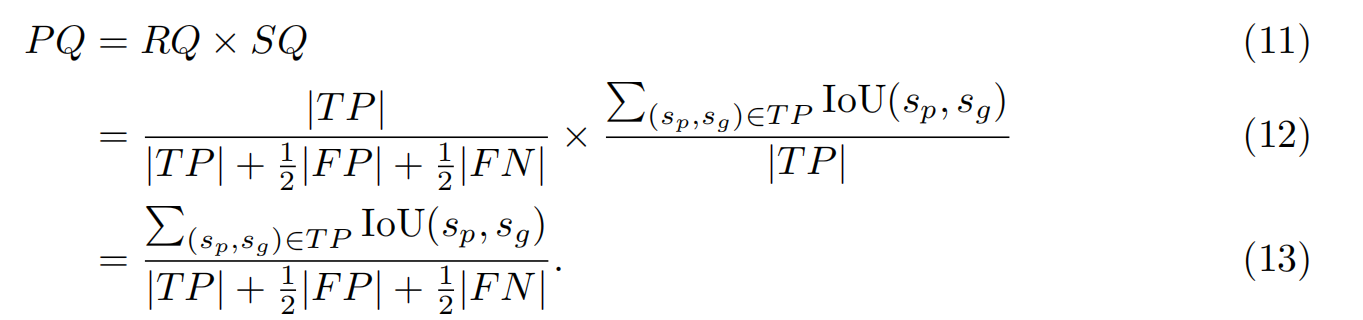
式中,sp = (lp, zp)为预测符号,sg = (lg, zg)为基础真值符号。|T P|、|F P|、|F N|分别为真阳性、假阳性、假阴性。如果某个预测符号找到了一个基础真值符号,则认为它匹配,其中lp = lg, IoU(sp, sg) > 0.5,其中IoU的计算方法为:
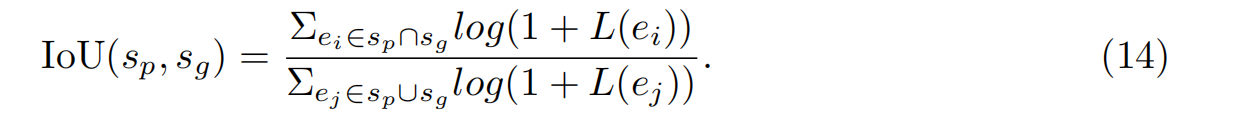
Implementation Details
我们用Pytorch实现SymPoint。我们使用双通道的PointT (Zhao et al., 2021)作为主干,并将L = 3层堆栈用于符号定位头。对于数据增强,我们采用旋转、翻转、缩放、移动和混合增强。我们选择AdamW (Loshchilov & Hutter, 2017)作为优化器,默认权重衰减为0.001,初始学习率为0.0001,我们在8个NVIDIA A100 GPU上训练模型1000次,批处理大小为每个GPU 2个。
Benchmark Results
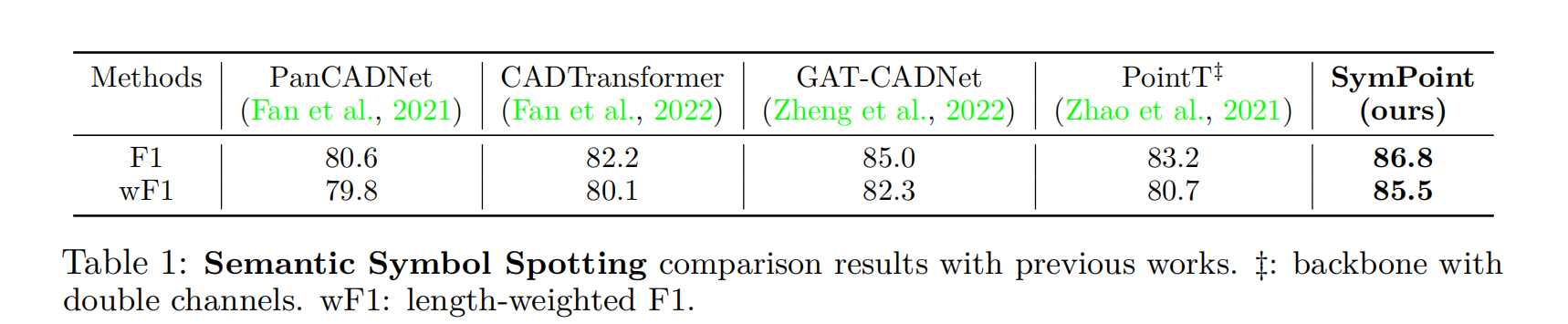
Semantic symbol spotting
我们将我们的方法与点云分割方法(Zhao et al., 2021)和符号识别方法(Fan et al., 2021;2022年;郑等人,2022)。主要测试结果如表1所示,我们的算法在语义符号识别任务上优于以往的所有方法。更重要的是,与GAT-CADNet相比(Zheng et al., 2022),我们实现了1.8% F1的绝对改进。和3.2% wF1。对于点,我们使用3.1节中提出的基于点的表示法将CAD绘图转换为作为输入的点集合。值得注意的是,PointT‡已经取得了与GAT-CADNet相当的结果(Zheng et al., 2022),这证明了所提出的基于点的表示用于CAD符号识别的有效性。
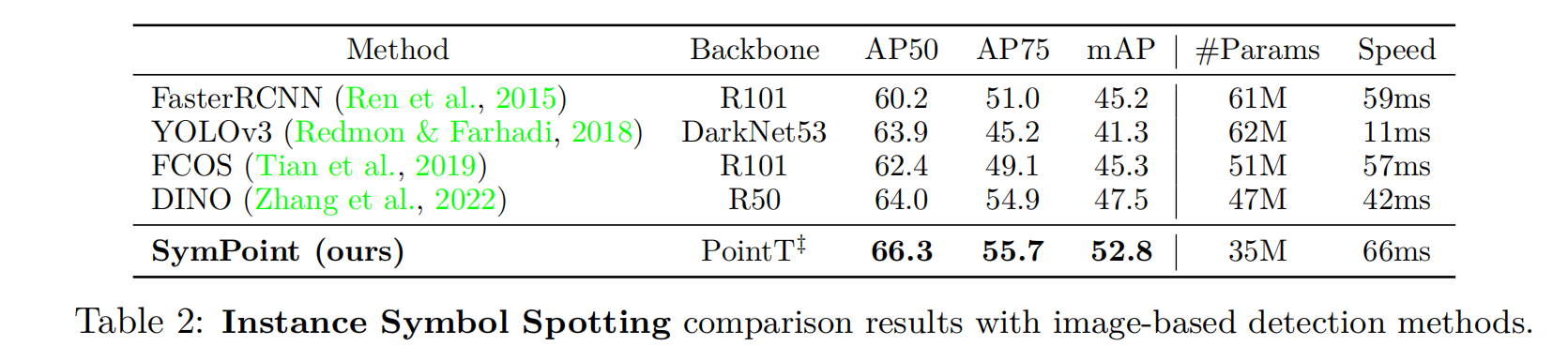
Instance Symbol Spotting
我们将我们的方法与各种图像检测方法进行了比较,包括fastrcnn (Ren et al., 2015)、YOLOv3 (Redmon & Farhadi, 2018)、FCOS和DINO。为了公平的比较,我们对预测的掩码进行后处理,以产生一个用于度量计算的边界框。主要对比结果如表2所示。虽然我们的框架没有被训练输出一个边界框,但它仍然达到了最好的结果。
Panoptic Symbol Spotting
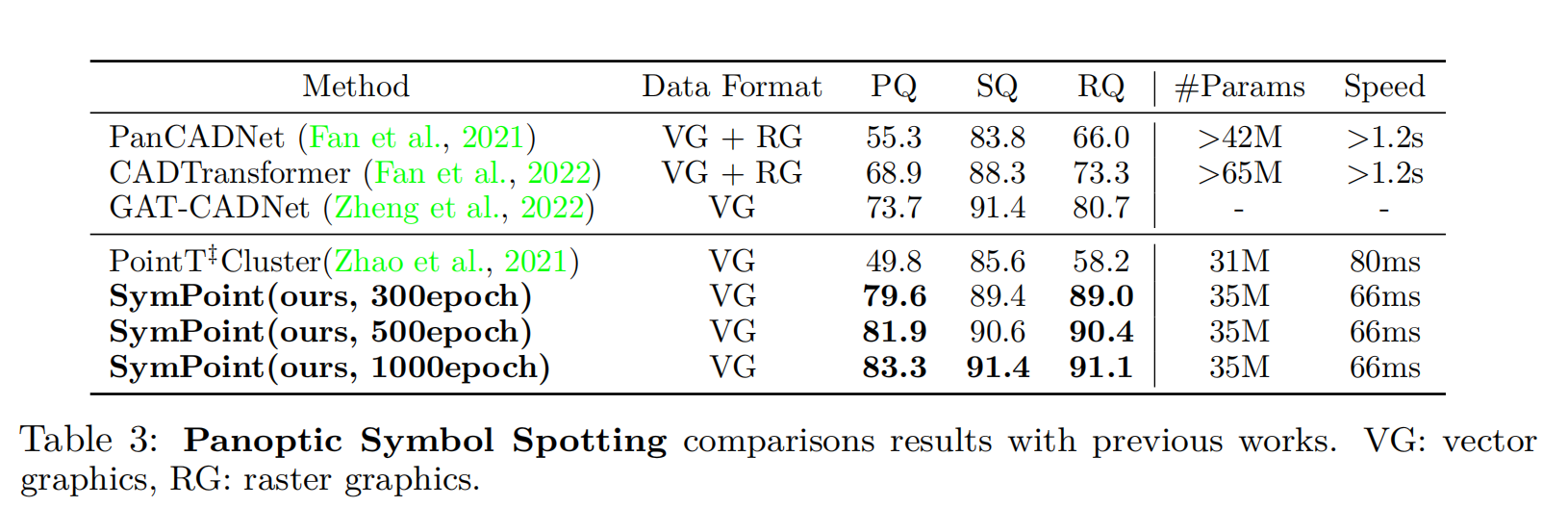
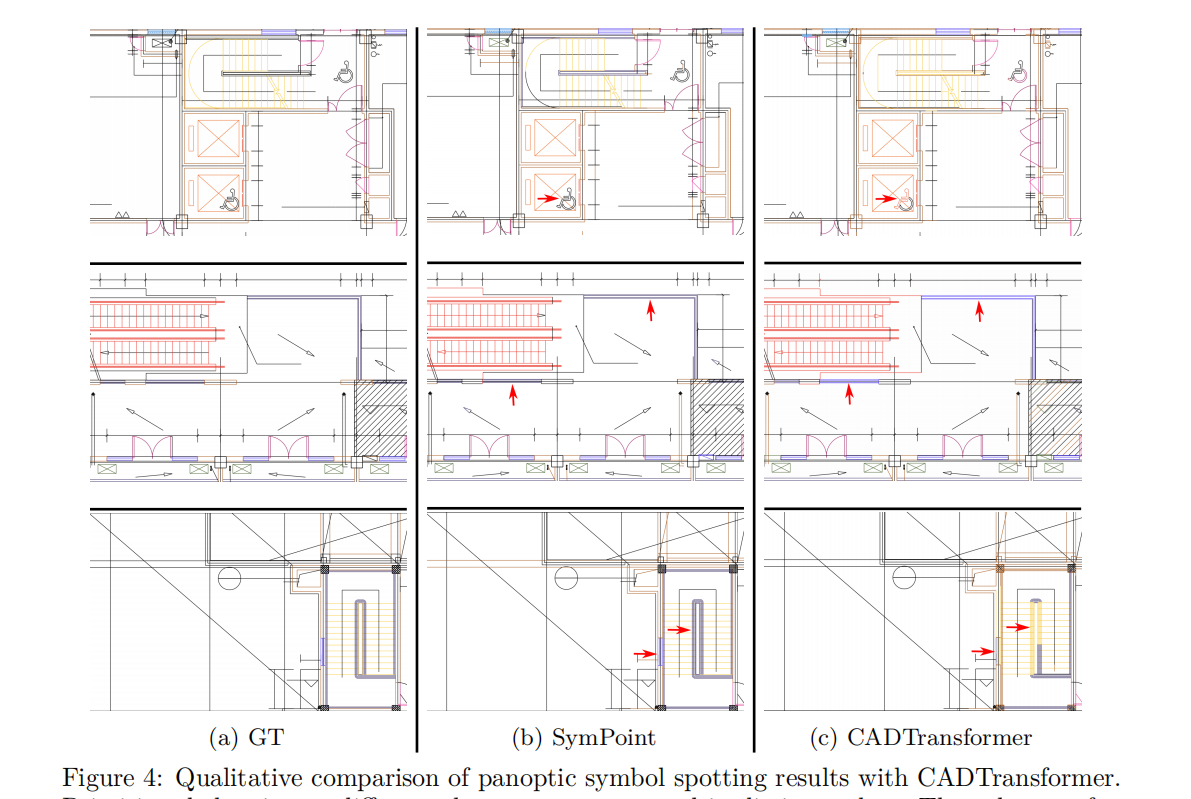
为了验证符号定位头的有效性,我们还设计了一种没有这个头的变体方法,名为PointT‡Cluster,它预测每个图形实体的偏移向量,以收集公共实例质心周围的实例实体,并执行类智能聚类(例如meanshift (Cheng, 1995)),以获得CADTransformer (Fan et al., 2022)中的实例标签。最终结果如表3所示。我们使用300epoch训练的SymPoint的性能大大优于point‡Cluster和最近的SOTA方法GAT-CADNet(Zheng et al., 2022),证明了所提出方法的有效性。我们的方法也受益于更长的训练时间,并实现进一步的性能提高。此外,我们的方法在推理阶段的运行速度比以前的方法快得多。对于基于图像的方法,将矢量图形渲染为图像大约需要1.2s,而我们的方法不需要这个过程。定性结果如图4所示。
Ablation Studies
所有的消融都是在300次训练下进行的
Effects of Techniques
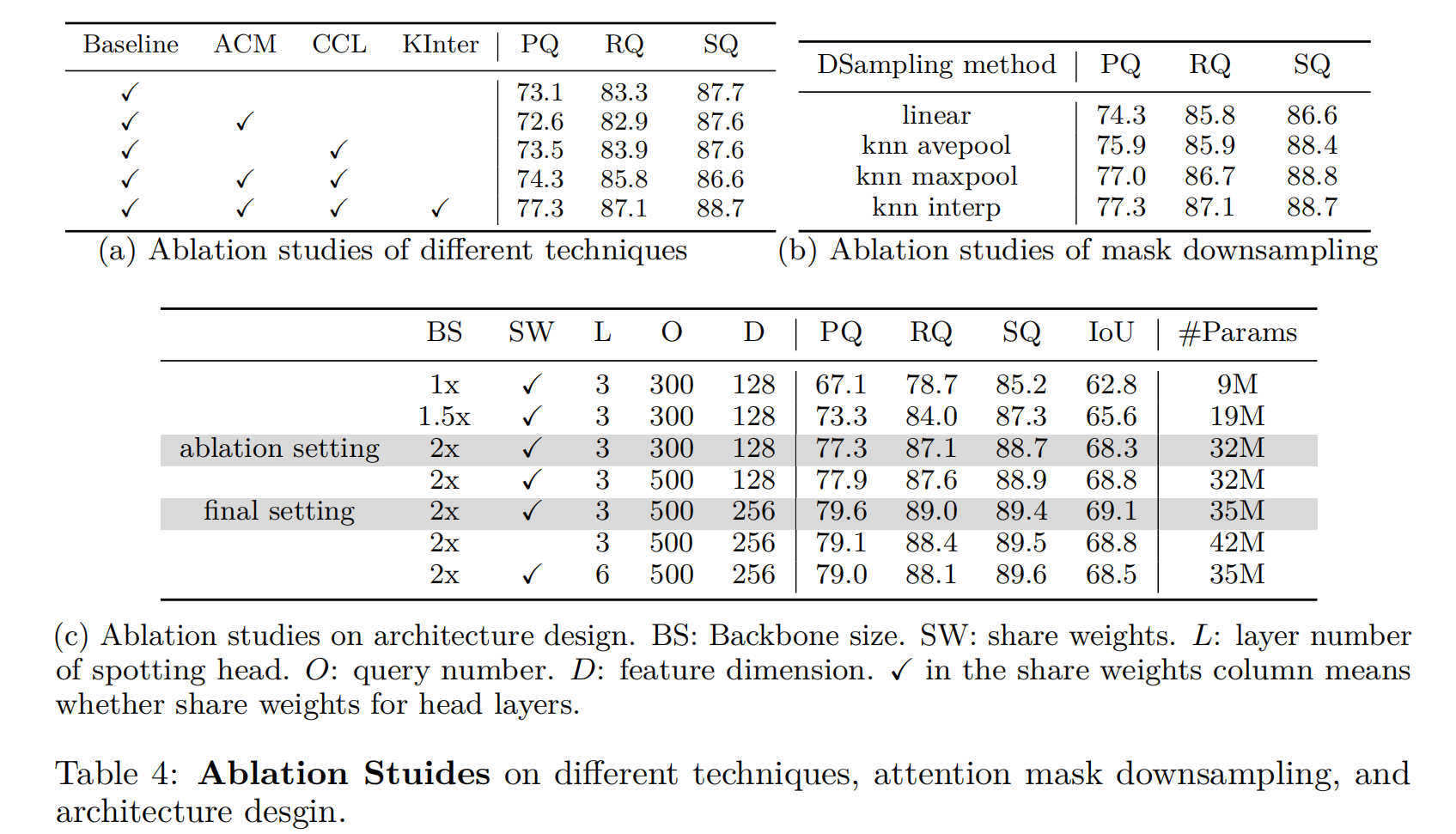
我们在表4a中进行了各种对照实验,以验证提高SymPoint性能的不同技术。这里的基线是指第3.2节中描述的方法。当我们只引入ACM (Attention with Connection Module)时,由于嘈杂的连接,性能会下降一点。但当我们将其与CCL(对比连接学习)相结合时,性能提高到PQ的74.3。注意,单独应用CCL只能略微提高性能。此外,KNN插值显著提高了性能,达到了PQ的77.3。
KNN Interpolation
在表4b中,我们列出了不同的下采样注意掩码方法:1)线性插值,2)KNN平均池化,3)KNN最大池化,4)KNN插值。KNN平均池化和KNN最大池化是指使用最近的K个相邻点的平均值或最大值作为输出,而不是使用Eq.(10)中定义的输出。我们可以看到,所提出的KNN插值达到了最好的性能。
Architecture Design
我们分析了不同的模型架构设计,如主干网通道数和符号识别头的L层是否共享权重的影响。从表4c可以看出,增大符号点头的主干、查询数和特征通道可以进一步提高性能。定位头权值共享不仅节省了模型参数,而且比不权值共享获得了更好的性能。
Conclusion and Future Work
本研究为全光学符号识别提供了一个新的视角。我们将CAD图纸视为点的集合,并利用点云分析的方法来识别符号。我们的方法SymPoint简单而有效,优于以往的工作。一个限制是我们的方法需要很长的训练时间来获得有希望的性能。因此,加速模型收敛是今后工作的重要方向。

![[闭源saas选项]Pinecone:为向量数据库而生的实时语义搜索引擎](http://pic.xiahunao.cn/[闭源saas选项]Pinecone:为向量数据库而生的实时语义搜索引擎)

)

)
——Chat Client API)


![[蓝桥杯]堆的计数](http://pic.xiahunao.cn/[蓝桥杯]堆的计数)


简易开发环境)






