文章目录
- 题目
- 思路
- 解题过程
- Python代码
- C代码
- 复杂度
题目
给出长度相同的两个字符串s1 和 s2 ,还有一个字符串 baseStr 。
其中 s1[i] 和 s2[i] 是一组等价字符。
举个例子,如果 s1 = “abc” 且 s2 = “cde”,那么就有 ‘a’ == ‘c’, ‘b’ == ‘d’, ‘c’ == ‘e’。
等价字符遵循任何等价关系的一般规则:
- 自反性 :‘a’ == ‘a’
- 对称性 :‘a’ == ‘b’ 则必定有 ‘b’ == ‘a’
- 传递性 :‘a’ == ‘b’ 且 ‘b’ == ‘c’ 就表明 ‘a’ == ‘c’
例如, s1 = “abc” 和 s2 = “cde” 的等价信息和之前的例子一样,那么 baseStr = “eed” , “acd” 或 “aab”,这三个字符串都是等价的,而 “aab” 是 baseStr 的按字典序最小的等价字符串
利用 s1 和 s2 的等价信息,找出并返回 baseStr 的按字典序排列最小的等价字符串。
示例 1:
输入:s1 = "parker", s2 = "morris", baseStr = "parser"
输出:"makkek"
解释:根据 A 和 B 中的等价信息,我们可以将这些字符分为 [m,p], [a,o], [k,r,s], [e,i] 共 4 组。每组中的字符都是等价的,并按字典序排列。所以答案是 "makkek"。示例 2:
输入:s1 = "hello", s2 = "world", baseStr = "hold"
输出:"hdld"
解释:根据 A 和 B 中的等价信息,我们可以将这些字符分为 [h,w], [d,e,o], [l,r] 共 3 组。所以只有 S 中的第二个字符 'o' 变成 'd',最后答案为 "hdld"。示例 3:
输入:s1 = "leetcode", s2 = "programs", baseStr = "sourcecode"
输出:"aauaaaaada"
解释:我们可以把 A 和 B 中的等价字符分为 [a,o,e,r,s,c], [l,p], [g,t] 和 [d,m] 共 4 组,因此 S 中除了 'u' 和 'd' 之外的所有字母都转化成了 'a',最后答案为 "aauaaaaada"。
提示:
- 1 <= s1.length, s2.length, baseStr <= 1000
- s1.length == s2.length
- 字符串s1, s2, and baseStr 仅由从 ‘a’ 到 ‘z’ 的小写英文字母组成。
思路
a == b,b == c,c == d,则a与d存在连通性,查找连通分量可以使用并查集。
注意:在合并s1[i]和s2[i]时,两个字母的祖先字典序排列较小的作为新的公共祖先
解题过程
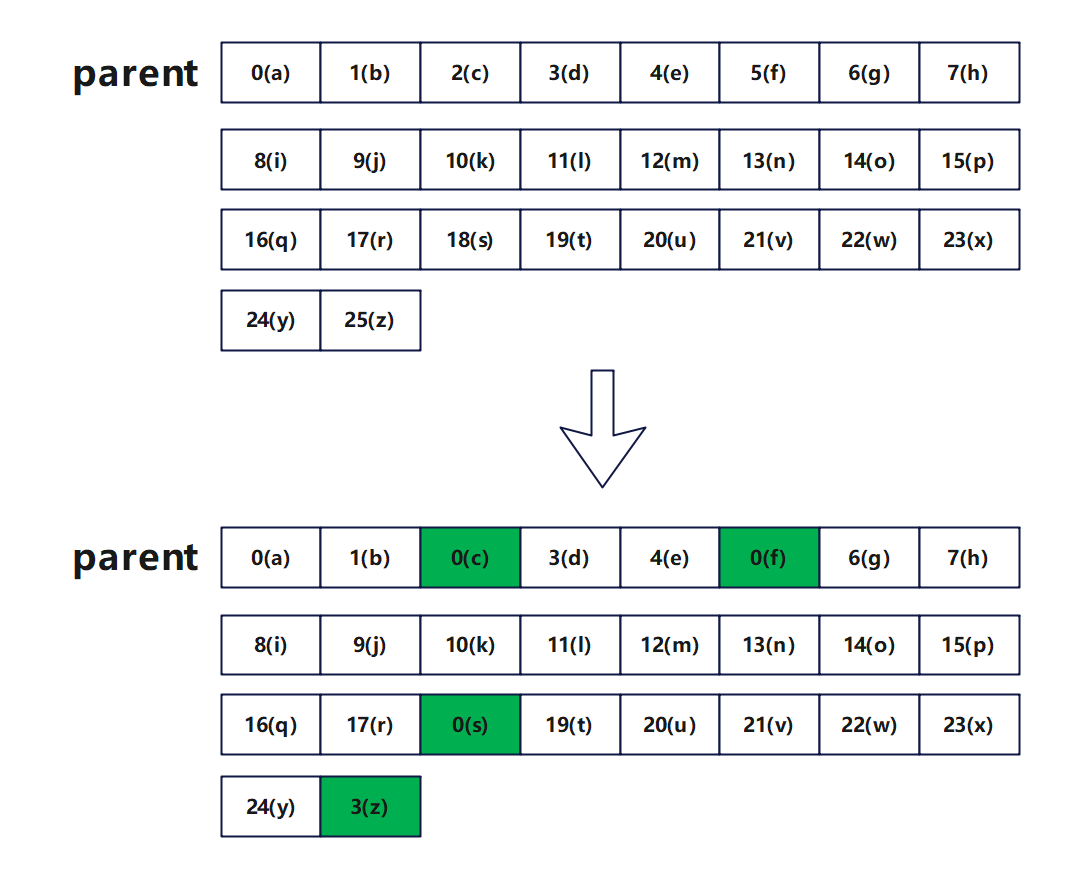
1、初始化并查集,因为总共只有26个小写字母,所以并查集长度为26,每个字母的祖先初始化为其本身。
2、关联s1与s2中的字母。
3、关联后再次更新并查集,确保每个字母的祖先最小。
4、遍历baseStr,生成结果。
Python代码
def search(node, parent):# 查找祖先节点if node == parent[node]:return nodeparent[node] = search(parent[node], parent)return parent[node]def union(node1, node2, parent):# 关联node1、node2ancestor1 = search(node1, parent)ancestor2 = search(node2, parent)if ancestor1 < ancestor2:parent[ancestor2] = ancestor1else:parent[ancestor1] = ancestor2class Solution:def smallestEquivalentString(self, s1: str, s2: str, baseStr: str) -> str:# 初始化并查集,所有字符(字母)的父节点都是本身parent = list(range(26))# 关联s1和s2中的每个字母n = len(s1)for i in range(n):a = ord(s1[i]) - ord("a")b = ord(s2[i]) - ord("a")union(a, b, parent)# 更新并查集for i in range(26):search(i, parent)# 生成结果ans = ""for c in baseStr:ans += chr(ord("a") + parent[ord(c) - ord("a")])return ans
C代码
typedef struct {int* parent;
} UnionFind;UnionFind* createUnionFind(int n) {// 初始化并查集UnionFind* uf = malloc(sizeof(UnionFind));uf->parent = malloc(n * sizeof(int));for (int i = 0; i < n; i++) {uf->parent[i] = i;}return uf;
}int find(int x, UnionFind* uf) {// 查找祖先节点if (uf->parent[x] != x) {uf->parent[x] = find(uf->parent[x], uf);}return uf->parent[x];
}void unite(int x, int y, UnionFind* uf) {x = find(x, uf);y = find(y, uf);if (x == y) return;if (x > y) {uf->parent[x] = y;} else {uf->parent[y] = x;}}char* smallestEquivalentString(char* s1, char* s2, char* baseStr) {// 初始化并查集UnionFind* uf = createUnionFind(26);for (int i = 0; s1[i]; i++) {unite(s1[i] - 'a', s2[i] - 'a', uf);}for (int i = 0; baseStr[i]; i++) {baseStr[i] = 'a' + find(baseStr[i] - 'a', uf);}free(uf->parent);free(uf);return baseStr;
}
复杂度
-
时间复杂度:O((n+m)logC)。其中n是s1和s2的长度,m是baseStr的长度,C是字符集大小,本题中为 26。由于并查集使用了路径压缩优化,合并和查找的平均时间复杂度为 O(α( C )),其中 α 是反阿克曼函数,最差时间复杂度为 O(logC)。
-
空间复杂度:O( C ),C 是字符集大小,本题中为 26,并查集所需的空间是 O( C )。















)



