Elasticsearch 核心技术(二):映射
- 1.什么是映射(Mapping)
- 1.1 元字段(Meta-Fields)
- 1.2 数据类型 vs 映射类型
- 1.2.1 数据类型
- 1.2.2 映射类型
- 2.实际运用案例
- 案例 1:电商产品索引映射
- 案例 2:动态模板设置
- 3.动态映射与静态映射详解
- 3.1 动态映射 (Dynamic Mapping)
- 3.1.1 动态映射的三种模式
- 3.1.2 动态映射示例
- 3.2 静态映射(Explicit Mapping)
- 静态映射示例
- 3.3 对比
- 3.4 最佳实践建议
- 4.映射修改详解
- 4.1 可以修改的内容
- 4.2 不可修改的内容
- 4.3 修改映射的解决方案
- 4.4 案例:将字符串字段从 text 改为 keyword
- 4.4.1 错误方式(直接修改会失败)
- 4.4.2 正确方式(通过重建索引)
- 4.5 注意事项
- 5.注意事项
1.什么是映射(Mapping)
映射是 Elasticsearch 中定义文档及其包含字段如何存储和索引的过程。它相当于关系型数据库中的表结构定义,决定了:
- 每个字段的数据类型
- 字段是否被索引
- 字段的索引方式
- 字段的分析器设置
- 字段的格式(如日期格式)
1.1 元字段(Meta-Fields)
元字段是 Elasticsearch 为每个文档自动创建的内部字段,用于管理文档的元数据。常见的元字段包括:
- 标识元字段
_index:文档所属的索引_id:文档的唯一 ID
- 文档源元字段
_source:存储原始 JSON 文档
- 索引元字段
_field_names:包含非空值的所有字段
- 路由元字段
_routing:用于将给定文档路由到指定的分片。
- 其他元字段
_meta:应用特定的元数据_version:文档版本号
例如 Kibana 中自带的 sample_data_ecommerce 示例数据。
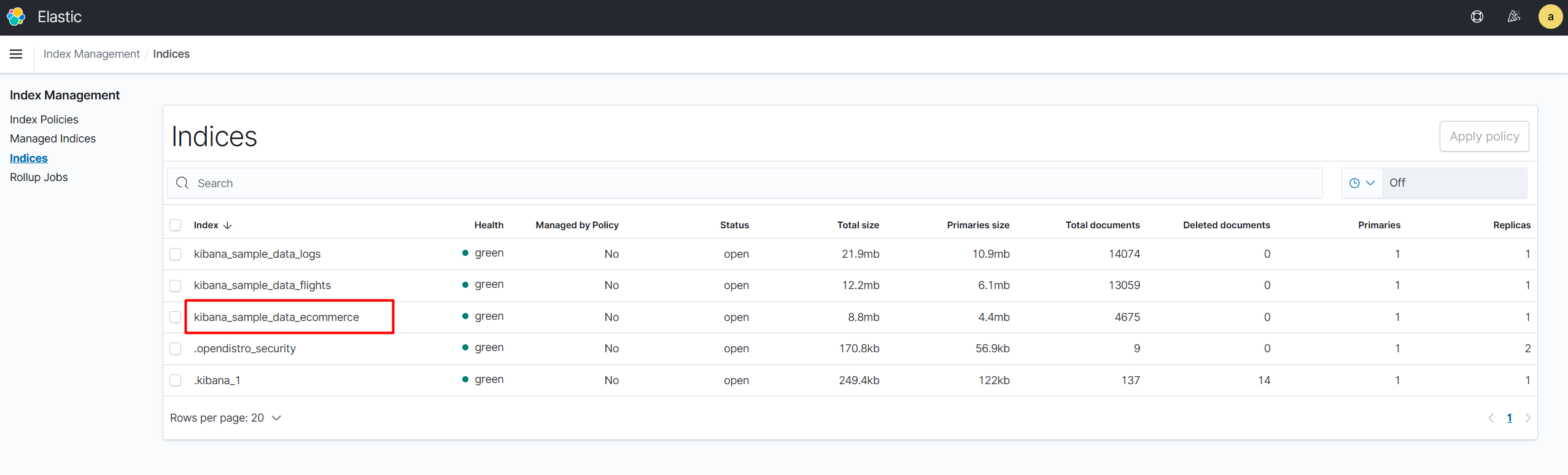
下面框出来的就是元字段信息。
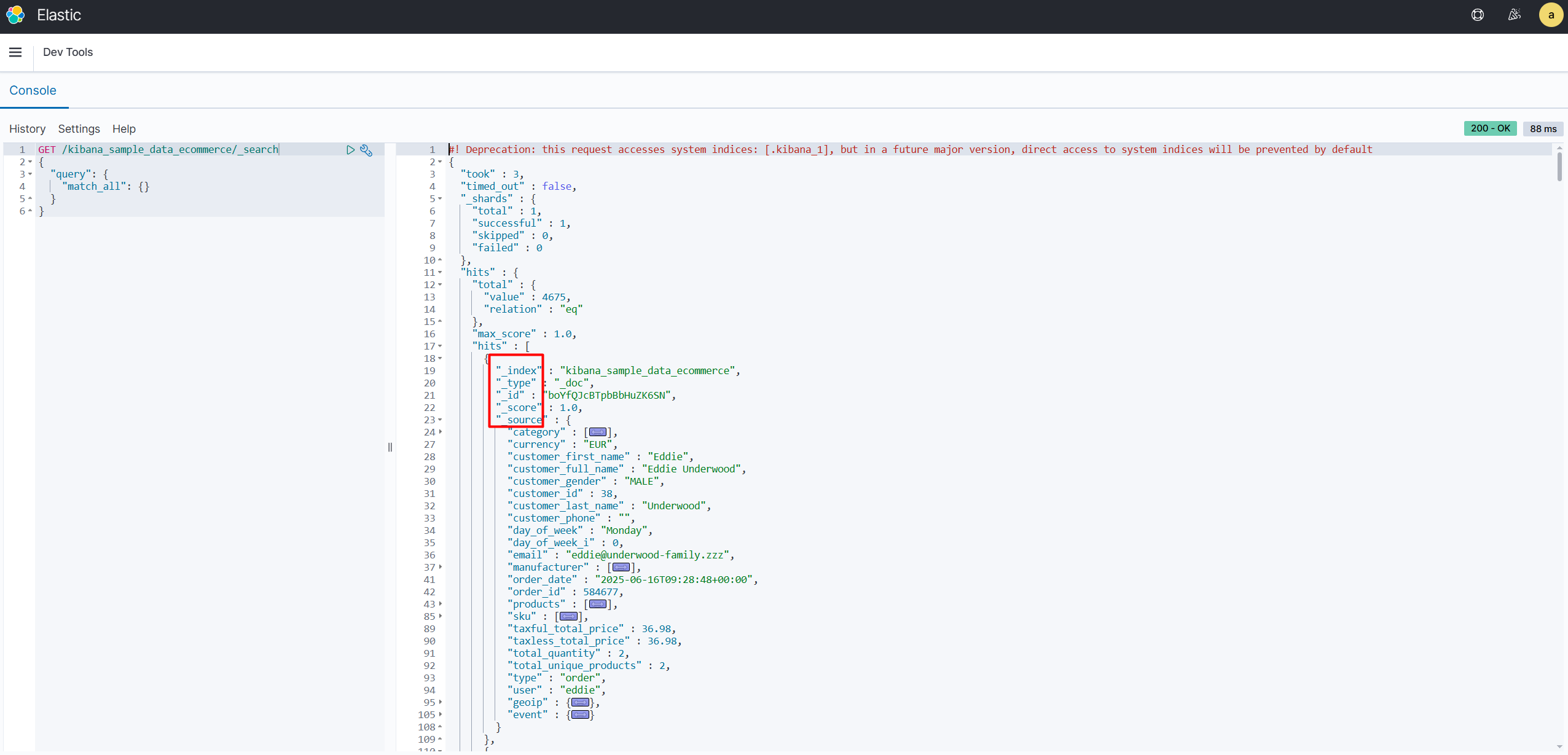
1.2 数据类型 vs 映射类型
1.2.1 数据类型
指字段值的具体类型,如:
- 核心类型:
text、keyword、long、integer、short、byte、double、float、boolean、date - 复杂类型:
object、nested - 地理类型:
geo_point、geo_shape - 特殊类型:
ip、completion、token_count
1.2.2 映射类型
在 Elasticsearch 7.0 之前,索引可以包含多个类型(类似于表),但 7.0 之后已弃用,每个索引现在只有一个隐式的 _doc 类型。
2.实际运用案例
案例 1:电商产品索引映射
PUT /products
{"mappings": {"properties": {"name": { "type": "text", "analyzer": "ik_max_word" },"price": { "type": "double" },"description": { "type": "text" },"category": { "type": "keyword" },"tags": { "type": "keyword" },"created_at": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" },"specs": { "type": "object" },"location": { "type": "geo_point" }}}
}
案例 2:动态模板设置
PUT /my_index
{"mappings": {"dynamic_templates": [{"strings_as_keywords": {"match_mapping_type": "string","mapping": {"type": "keyword"}}}]}
}
3.动态映射与静态映射详解
3.1 动态映射 (Dynamic Mapping)
动态映射是 Elasticsearch 自动检测和创建字段映射的能力。当索引一个新文档时,如果包含未定义的字段,Elasticsearch 会根据字段值自动推断数据类型并创建映射。
3.1.1 动态映射的三种模式
true(默认):自动添加新字段false:忽略新字段(不索引但会存储在_source中)strict:拒绝包含新字段的文档(抛出异常)
3.1.2 动态映射示例
# 创建索引时不定义映射(使用默认动态映射)
PUT /dynamic_index# 插入包含新字段的文档
POST /dynamic_index/_doc/1
{"name": "John Doe", # 自动识别为text字段"age": 30, # 自动识别为long"birth_date": "1990-01-01", # 自动识别为date"is_active": true, # 自动识别为boolean"salary": 5000.50, # 自动识别为float"tags": ["tech", "sports"], # 自动识别为text数组"address": { # 自动识别为object"street": "123 Main St","city": "New York"}
}
查看自动生成的映射
GET /dynamic_index/_mapping# 返回结果示例:
{"dynamic_index": {"mappings": {"properties": {"address": {"properties": {"city": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },"street": { "type": "text", "fields": { "keyword": { "type": "keyword" } } }}},"age": { "type": "long" },"birth_date": { "type": "date" },"is_active": { "type": "boolean" },"name": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },"salary": { "type": "float" },"tags": { "type": "text", "fields": { "keyword": { "type": "keyword" } } }}}}
}
3.2 静态映射(Explicit Mapping)
静态映射是手动预定义索引的字段结构和数据类型,在创建索引时明确指定每个字段的类型和属性。
静态映射示例
# 创建索引时明确定义映射
PUT /static_index
{"mappings": {"dynamic": "strict", # 严格模式,禁止未定义的字段"properties": {"name": {"type": "text","analyzer": "standard","fields": {"keyword": { "type": "keyword" }}},"age": { "type": "integer" },"birth_date": {"type": "date","format": "yyyy-MM-dd||epoch_millis"},"is_active": { "type": "boolean" },"salary": { "type": "scaled_float", "scaling_factor": 100 },"tags": {"type": "keyword"},"address": {"type": "object","properties": {"street": { "type": "keyword" },"city": { "type": "keyword" },"coordinates": { "type": "geo_point" }}},"comments": {"type": "nested","properties": {"user": { "type": "keyword" },"message": { "type": "text" },"rating": { "type": "byte" }}}}}
}
尝试插入未定义字段的文档
POST /static_index/_doc/1
{"name": "Jane Smith","age": 28,"new_field": "test" # 将抛出异常,因为dynamic=strict
}# 错误响应:
{"error": {"root_cause": [{"type": "strict_dynamic_mapping_exception","reason": "mapping set to strict, dynamic introduction of [new_field] within [_doc] is not allowed"}]},"status": 400
}
3.3 对比
| 特性 | 动态映射 | 静态映射 |
|---|---|---|
| 字段创建方式 | 自动推断 | 手动预定义 |
| 灵活性 | 高 | 低 |
| 可控性 | 低 | 高 |
| 适合场景 | 开发初期、数据结构不确定 | 生产环境、数据结构稳定 |
| 性能影响 | 可能产生不理想的映射 | 可优化映射提升性能 |
| 维护成本 | 低(初期)高(后期整理) | 高(前期)低(后期) |
| 数据一致性 | 可能不一致 | 高度一致 |
3.4 最佳实践建议
-
开发阶段:可以使用动态映射快速原型开发。
PUT /dev_index {"mappings": {"dynamic": true} } -
过渡阶段:使用动态模板(
dynamic templates)控制自动映射。PUT /transition_index {"mappings": {"dynamic_templates": [{"strings_as_keywords": {"match_mapping_type": "string","mapping": {"type": "keyword"}}}]} } -
生产环境:推荐使用静态映射。
PUT /prod_index {"mappings": {"dynamic": "strict","properties": {// 明确定义所有字段}} } -
混合使用:可以结合两者优势。
PUT /hybrid_index {"mappings": {"dynamic": "false", # 不自动索引新字段,但存储在_source"properties": {// 明确定义已知字段}} }
通过合理选择映射策略,可以在灵活性和可控性之间取得平衡,为不同阶段的业务需求提供最合适的解决方案。
4.映射修改详解
在 Elasticsearch 中,映射创建后是可以修改的,但有重要的限制和注意事项。
4.1 可以修改的内容
-
添加新字段:任何时候都可以向现有映射添加新字段。
PUT /my_index/_mapping {"properties": {"new_field": { "type": "text" }} } -
修改某些字段属性:
- 可以更新
fields多字段设置 - 可以修改
analyzer、search_analyzer等分析相关设置 - 可以修改
ignore_above(keyword 字段) - 可以修改
null_value设置
- 可以更新
-
动态映射规则:可以更新动态模板(dynamic templates)
4.2 不可修改的内容
- 字段数据类型:不能更改已有字段的数据类型。
- 例如:不能将
text改为keyword,不能将long改为integer。
- 例如:不能将
- 已索引的字段:不能更改已索引字段的基本结构。
- 例如:不能将单字段改为多字段。
- 字段名称:不能直接重命名字段。
4.3 修改映射的解决方案
当需要做不允许的修改时,可以考虑以下方案:
-
重建索引(Reindex)
- 创建新索引,定义新映射。
- 使用 Reindex API 将数据从旧索引复制到新索引。
- 示例:
POST _reindex {"source": { "index": "old_index" },"dest": { "index": "new_index" } }
-
使用别名(Alias)
- 创建指向新索引的别名。
- 无缝切换应用查询到新索引。
- 示例:
POST _aliases {"actions": [{ "remove": { "index": "old_index", "alias": "my_alias" } },{ "add": { "index": "new_index", "alias": "my_alias" } }] }
-
多字段(Multi-fields)
- 为字段添加不同数据类型的多字段版本。
- 示例:
PUT /my_index/_mapping {"properties": {"my_field": {"type": "text","fields": {"keyword": { "type": "keyword" }}}} }
4.4 案例:将字符串字段从 text 改为 keyword
4.4.1 错误方式(直接修改会失败)
PUT /my_index/_mapping
{"properties": {"category": { "type": "keyword" } // 如果原先是text,这会报错}
}
4.4.2 正确方式(通过重建索引)
// 1. 创建新索引
PUT /my_index_v2
{"mappings": {"properties": {"category": { "type": "keyword" }}}
}// 2. 重新索引数据
POST _reindex
{"source": { "index": "my_index" },"dest": { "index": "my_index_v2" }
}// 3. 切换别名
POST _aliases
{"actions": [{ "remove": { "index": "my_index", "alias": "products" } },{ "add": { "index": "my_index_v2", "alias": "products" } }]
}
4.5 注意事项
- 生产环境谨慎操作:映射更改可能影响现有查询和应用程序。
- 停机时间考虑:重建大索引可能需要时间,规划好维护窗口。
- 版本兼容性:Elasticsearch 不同版本对映射修改的支持可能不同。
- 监控影响:修改后监控集群性能和查询结果。
- 备份数据:重大映射修改前建议备份重要数据。
- 测试环境验证:先在测试环境验证映射修改的效果。
通过合理规划映射修改策略,可以在最小化影响的情况下实现索引结构的演进。
5.注意事项
- 提前规划映射:生产环境中应预先定义好映射,避免依赖动态映射
- 避免映射爆炸:
- 设置
index.mapping.total_fields.limit(默认 1000) - 使用
dynamic: false或dynamic: strict控制动态字段
- 设置
- 合理选择数据类型:
- 需要全文搜索用
text,需要精确匹配/聚合用keyword - 数值类型选择最合适的范围(如能用
integer就不用long)
- 需要全文搜索用
- 元字段使用:
- 不要修改
_source字段,它是文档的原始 JSON - 使用
_routing优化查询性能
- 不要修改
- 映射更新限制:
- 已有字段的映射类型不能更改
- 只能添加新字段或修改某些参数(如增加字段的
fields)
- 性能考虑:
- 避免过多的嵌套对象
- 对于不搜索的字段设置
"index": false
- 版本兼容性:
- Elasticsearch 7.x 及以后版本已移除映射类型概念
- 升级时要注意 API 变化
通过合理设计映射,可以显著提高 Elasticsearch 的查询性能和存储效率。



)





)

: 一刀斩断视频片头广告)







