全栈监控系统架构
可观测性从数据层面可分为三类:
- 指标度量(Metrics):记录系统的总体运行状态。
- 事件日志(Logs):记录系统运行期间发生的离散事件。
- 链路追踪(Tracing):记录一个请求接入到结束的处理过程,主要用于排查故障。
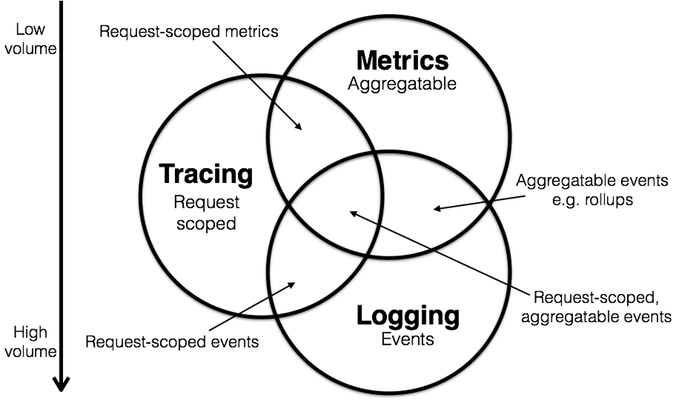
图片来自:Metrics, Tracing, and Logging
CNCF 的 Observability Whitepaper(可观测性白皮书) 将上述数据统称为 Signal(信号),除了以上三种,又提出来额外两种信号:
- 性能剖析(Profiling):记录代码级别的的详细视图,比如 CPU、内存的使用,帮助诊断环境中的性能瓶颈。
- 核心转储(Core Dumps):程序崩溃时的内存快照。
从系统架构层面可分为三层:
-
基础层:对底层主机资源的监控。比如 CPU、内存、磁盘用量、磁盘IO、网络IO 、系统日志等。
-
中间层:对中间件的监控。比如 MySQL、Redis、ElasticSearch、Nginx 等中间件的关键指标。
-
应用层 :监控应用的指标。比如 JVM 指标、JDBC 指标、HTTP 的吞吐、响应时间和返回码分布等。当然也包括客户端的监控,比如移动客户端的性能监控。
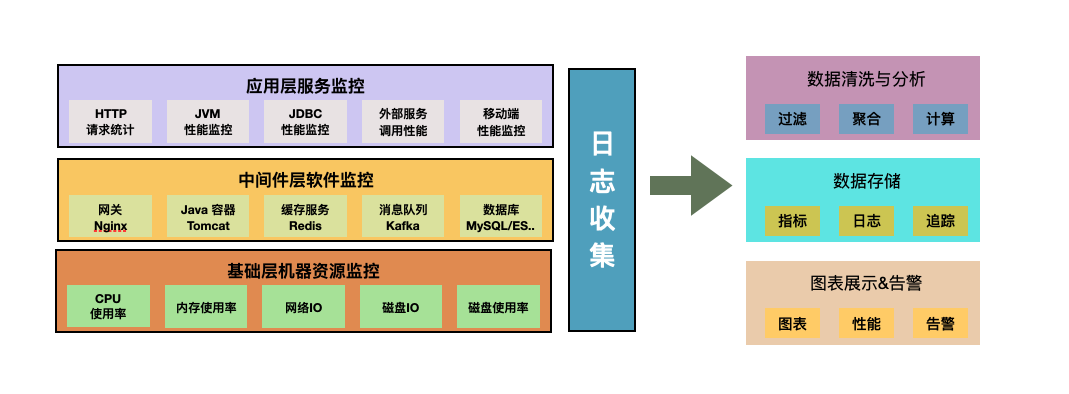
我们知道分布式系统的架构和运维极其复杂,只有实现一个全栈监控系统,将上述各层的指标、日志、追踪数据收集并关联保存好,让它成为分布式系统的眼睛,我们才能更好的了解系统运行状态,及时发现问题,进而解决问题。
一个分布式系统、一个自动化运维系统、或是一个Cloud Native的云化系统,最重要的事就是把监控系统做好,在把数据收集好的同时更重要的是把数据关联好。开发和运维才可能很快地定位故障,进而根据故障原因做出相应的(自动化)处置,将故障恢复或把故障控制在影响范围之内。 《左耳听风》
监控系统功能要求
一个好的监控系统,主要为两个场景服务:
-
体检
-
容量管理。提供一个全局的系统运行时数据监控大盘,可以让工程师团队知道是否需要增加机器或是其它资源。
-
性能管理。可以通过查看大盘,找到系统瓶颈,并有针对性的优化系统和相应代码。
-
-
急诊
-
定位问题。可以快速的暴露并找到问题的发生点,帮助技术人员诊断问题。
-
性能分析。当出现不预期的流量提升,可以快速的找到系统的瓶颈,并可以帮助开发人员深入代码。
-
具体需要有如下功能:
全栈监控
做到对基础、中间件和应用层的指标、日志、链路追踪的整体监控。
整体 SLA 分析
需要根据用户的 API 访问计算整体的 SLA。比如下面的一系列指标:
- 吞吐量:M1,M5,M15 的吞吐量,即最近 1、5、15 分钟的 QPS。
- 响应时间:P99 、P95 、P90、P75、P50 等延时时长,
- 错误率:2XX、3XX、4XX、5XX 的各自占比;最近 1、5、15 分钟的 400、500 错误请求数。
- Apdex(Application Performance Index) 指标
这是工业界用来衡量系统运行是否健康的指标。Apdex 有三种状态来描述用户的使用体验:
- 满意(Satisfied):请求服务响应时间小于某个阈值 T。
- 可容忍(Tolerating):请求服务响应时间高于 T,但低于一个可容忍值 F,通常 F = 4T。
- 失望(Frustrated):请求服务响应时间大于可容忍值 F。
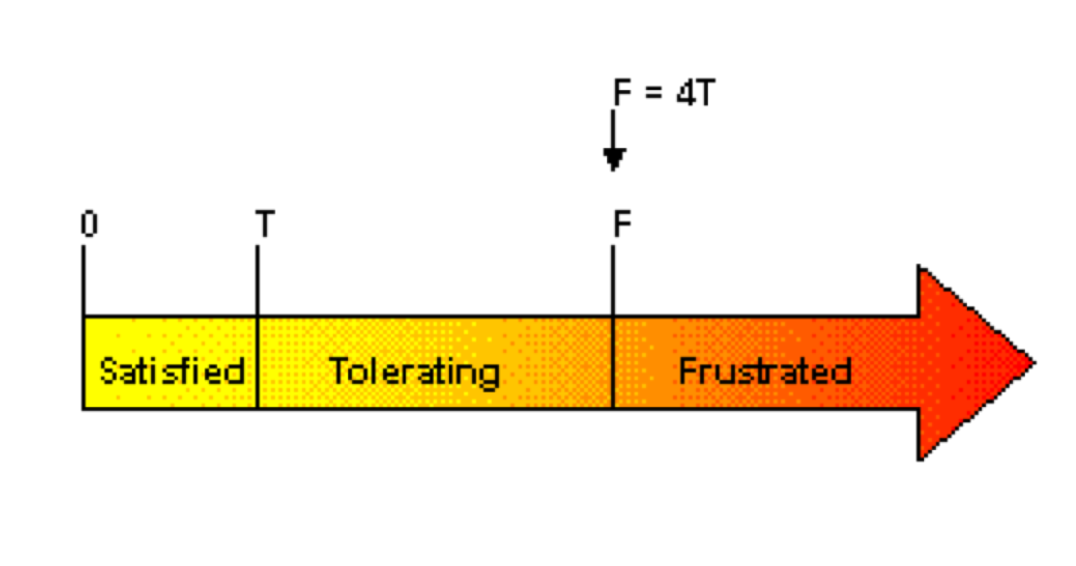
基于以上值,Apdex 的计算公式如下:
// 满意的请求数加上可容忍的请求数的一半,除以总的请求数。
Apdex = (Satisfied count + Tolerating count / 2) / Total count
假设我们系统有 100 个请求,满意响应时间为 200ms。这 100 个请求中:
- 80 个请求响应时间小于 200ms,即满意的请求数为 80。
- 15 个请求响应时间在 200ms 到 800ms(4 * 200) 之间,即可容忍的请求数为 15。
- 5 个请求响应时间大于 800ms,即失望的请求数为 5。
那么 Apdex 的值为:
Apdex = (80 + 15 / 2) / 100 = 0.875
一般来说,Apdex 的值大于 0.9 时系统可以认为运行正常,用户体验良好;低于 0.8 时需要告警,并进行优化;在 0.5 以下时可以认为系统运行不正常,需要将服务实例下线。
关联分析
监控系统需要对三层数据进行统一全面的关联、分析,并能够通过调用关系帮助我们定位故障的根因。
以一个报 500 的请求为例,我们能够通过链路追踪日志获取该请求的整个请求链路,链路中的所有服务、中间件以及对应的服务器信息都能关联查询出来。查询到链路中的每个 Span 时,对应的日志、指标都能关联展示出来。
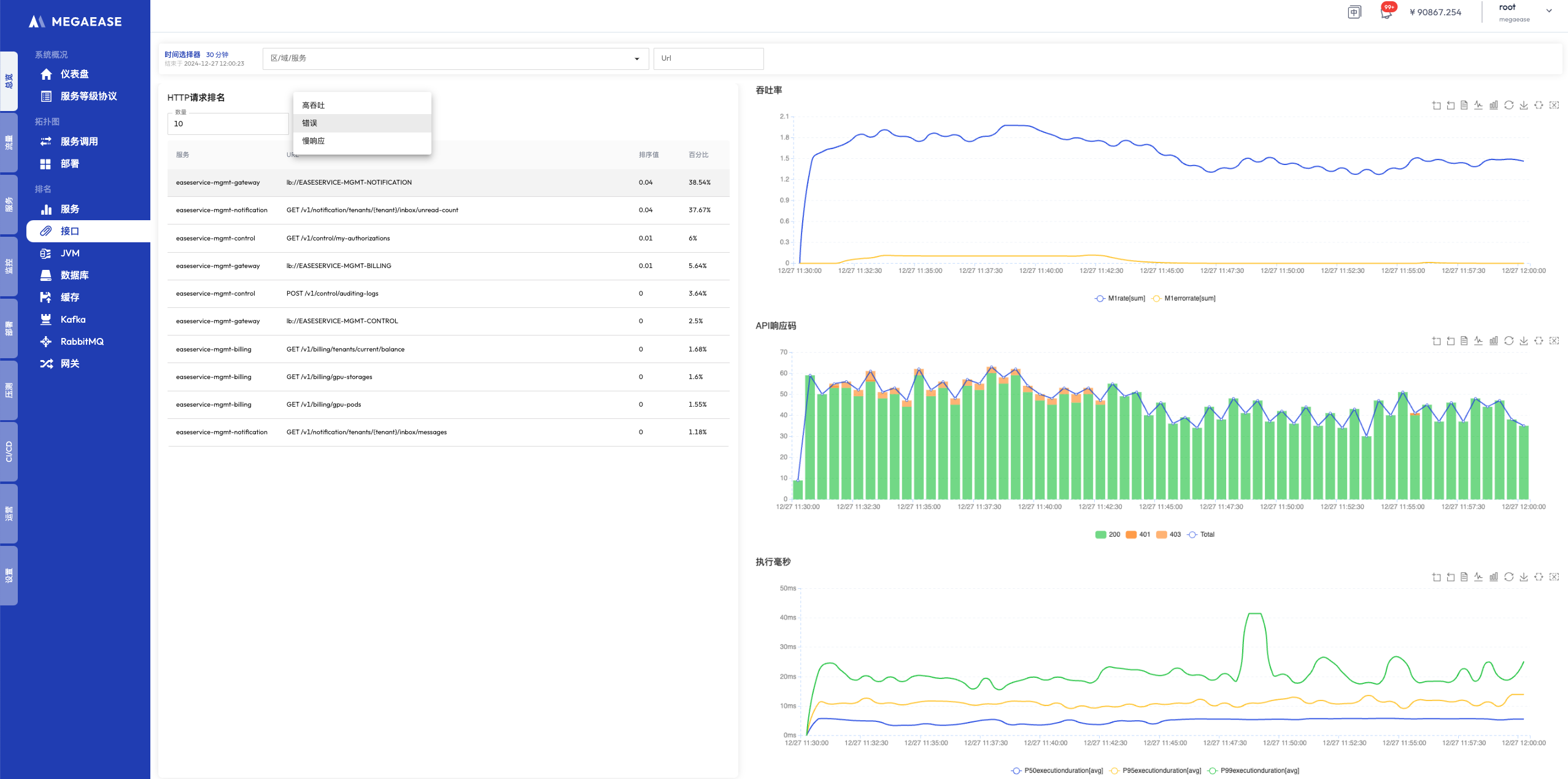
下图是使用 MegaEase Cloud 云平台监控的一个微服务系统的调用链追踪展示以及点击某个 Span 时所能关联查询的所有数据。整个调用链的拓扑图、日志、请求、JDBC 等信息全部能关联查询出来。
- 调用链拓扑图

- Span 信息

- Span 详情,包括日志、指标、请求、JDBC 等
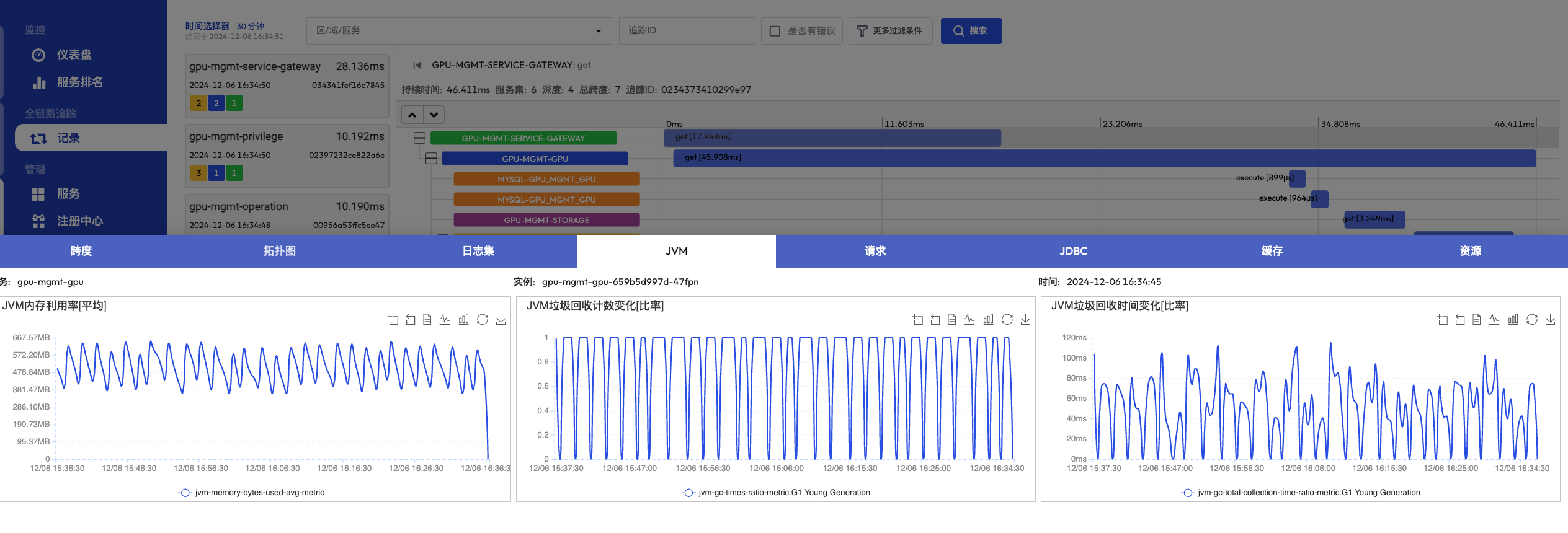
图片来自 MegaEase 官网
实时告警与自动处理
通过设置告警规则,当系统异常时能够及时的发出告警。在此基础上要有一定的自动故障处理能力,比如自动扩缩容、弹力处理等。
对于常见的指标,比如服务器的 CPU、内存、磁盘的用量,JVM 的 Memory、GC 等最好有默认的告警规则模版,每当有新的机器、服务上线时,能够自动生成告警规则。
系统容量与性能分析
通过对过去一段时段的监控数据分析,获取系统的 SLA、负载、容量使用等情况,为系统的容量规划提供参考依据。
监控系统技术架构
数据采集
数据采集通常会有一个客户端,与被采集的目标实例运行在一起,采集目标实例的运行指标、日志、追踪等信息,并将采集到的数据通过 API 进行暴露或者直接上报。
指标全局字段
为了后续的关联分析,采集的数据需要标明来源等信息,通常需要以下全局字段:
| 字段 | 说明 |
|---|---|
| category | 指标分类,通常可以分为 infrastructure、platform、application 三类,即对应基础设施层、中间件层、应用层 |
| host_name | 采集客户端所在的主机名称 |
| host_ipv4 | 采集客户端所在的主机 IP |
| system | 被监控服务的系统名称(一般是所属的业务系统) |
| service | 被监控服务的服务名,最重要的一个字段,大盘需要根据该字段确定要查询的目标数据以及关联分析 |
| instance | 被监控服务的实例名称,一个服务通常会有多个实例,该字段用来标识具体的实例信息, 方便关联分析和故障定位 |
| type | 指标类型分类,更加细化的指标分类,比如 mysql、jvm、cpu、memory 等,可以基于该 type 将数据存储在不同的索引库中 |
| timestamp | 指标和日志产生的时间戳 |
通过这些字段,我们能精确定位某个系统下的任意服务实例位于哪台机器上,从而去目标主机查看实例的状态;也可以在监控系统中通过这些字段关联查询到具体实例的日志、指标、追踪等信息。
基础层与中间件层采集
Linux 系统内核以及几乎所有的的中间件都有运行时的统计信息。比如 Linux 的 /proc 目录,MySQL 的 performance schema 等。
对于基础层和中间件层,有非常多的优秀成熟开源的监控组件可以使用:
-
Telegraf:一款开源的基于 Go 语言开发的指标采集软件,有众多的采集、处理和输出插件,基本能覆盖日常开发的指标采集需求。
-
Elastic Beats:ElasticSearch 公司开发的一系列采集客户端。比如用于采集日志的
Filebeat;用于采集指标的Metricbect;用于采集网络的:Packetbeat。 -
Prometheus Exporter:围绕 Prometheus 开发的一系列 Exporter,会暴露指标采集 API,供 Prometheus 定时拉取。
-
OpenTelemetry:由 CNCF 的 OpenTracing 和 Google/微软支持的 OpenCensus 合并而来,最初是为了实现链路追踪的标准化,后来逐渐演化为一套完整的可观测性解决方案。自 2019 年发布以来,逐渐成为了云原生领域可观测性数据收集的事实标准。

应用层指标采集
应用层的指标采集要相对更麻烦一些,因为不同的语言实现通常需要不同的方式采集。但总体来看有三种如下方式:
-
应用 API 暴露:比如 SpringBoot 应用就通过
/_actuatorAPI 对外暴露了一系列应用相关信息。我们也可以自行编写相应的 API 对外暴露指标。这里需要注意指标标记的合理性,避免表示不准确和数据量爆炸,对服务本身和监控系统造成影响。一般来说除了指标名、时间戳和指标值外,其他 lable 都是固定的,这样 Prometheus 等时序数据库在存储时会进行压缩,节省存储空间。可以参考这篇文章 程序的 Metrics 优化——Prometheus 文档缺失的一章。 -
SDK 采集上报:将采集上报功能以 SDK 的形式集成到服务中。好处是灵活性高,可以自行编写 SDK,最大程度满足自身的需求,但坏处是会对业务服务造成侵入。主流语言通常会有很多优秀开源库,即使是自己造轮子通常也是在其基础之上做进一步的封装。以笔者比较熟悉的 Java 生态为例,一些优秀的开源工具库:
- OSHI: Operating System and Hardware Information 用来收集操作系统和硬件信息的 Java 开源库。
- Dropwizard Metrics 用来测量 Java 应用的相关指标的开源库。
- opentelemetry-java:opentelemetry 提供的 Java SDK。
-
无侵入式采集:SDK 的方式一般需要应用添加依赖,修改配置等操作,通常会影响到线上的服务运行。更好的方式是使用无侵入技术,将采集功能无缝集成到应用中。一些常见的技术有:
-
Java Agent: Java 提供了字节码编程,可以动态的修改服务配置。MegaEase 就使用了该技术实现了 EaseAgent 无侵入式观测系统
-
ServiceMesh SideCar: 在 Service Mesh 架构下,可以将服务发现、流量调度、指标日志和分布式追踪收集等非业务性功能放到 SideCar 中,从而避免对应用造成影响。
在 MegaEase,我们结合 JavaAgent 和 SideCar 实现了 EaseMesh 服务网格, 可以在不改变一行源代码的情况下将 Spring Cloud 应用迁移到服务网格架构,整个架构已经被赋予了全功能的服务治理、弹性设计和完整的可观察性,而用户不需要修改一行代码。具体参考 与 Spring Cloud 完全兼容的服务网格可以干什么样的事。
-
采集端注意事项
-
监控系统属于控制面的功能,和业务逻辑没有直接关系。因此业务系统不应该感知到监控系统的存在,更重要的,监控系统的资源占用要尽可能小,不应该影响到业务系统的正常运行。
-
尽可能对应用开发透明,比如优先使用上述提到的无侵入的方式采集应用的监控数据。
-
如果做不到无侵入,比如要使用 SDK 的方式,也要做到技术收口,采用切面编程的范式来实现,避免对业务逻辑造成影响。
-
采集数据的传输应该采用标准的协议,比如 HTTP 协议。
-
采集数据的格式应该采用标准的格式,比如 JSON、ProtoBuf 等,尤其是数据量过大时,尽量使用高效率的二进制协议。
-
如果条件允许,应该使用物理上的专用网络来隔离业务网络,避免对业务服务的访问造成影响。
数据传输与清洗
当数据收集上来后,我们需要对数据进行清洗梳理,从而实现
- 日志数据的结构化
- 监控数据的标准化
这里需要两个组件的支持:
-
数据总线:通过数据总线来对接所有的收集组件,成为数据集散地;另外也作为数据缓存和扩展的中间 Broker。Kafka 可以很好的担任这样一个角色。
-
数据 ETL:ETL 工具用来对数据进行清洗,将客户端采集发送到数据总线的数据解析处理,最终生成结构化的数据写入到存储组件中。常用的开源组件有 LogStash,Fluentd 等,当然也可以自研,选择更合适的高性能语言并满足内部更加复杂的清洗需求。
数据清洗注意事项
-
清洗组件要做到高性能、高可用。一般来说,指标数据是周期性产生的,其数据量并不会跟随当前请求并发量的多少变化而变化。另外一些数据(比如日志)则是和系统接受的请求并发量有着直接的关系。因此数据处理管线需要能够支撑高并发、大数据量的写入,同时也起到削峰填谷的作用。Kafka 可以非常完美的符合这些要求。
-
清洗逻辑要尽量的简单,不应该在清洗组件做过多复杂的设计。
-
清洗组件必须是无状态的,能够支持水平扩展。
-
尽量提升数据处理的效率,比如使用 Golang 开发清洗组件;对 JVM 的语言做优化,如使用无锁队列、固定大小的 buffer 等提升效率。
数据存储
在存储方面,以 ElasticSearch 为代表的全文搜索引擎和以 Prometheus 为代表的时序数据库已经成为事实上的标准。一般来说可以将以日志为主的、需要全文检索的数据写入到 ES;将告警相关的数据写入到 Prometheus 中。
存储注意事项
-
根据需要对数据按天、小时或分钟等级别建立索引,避免单个索引数据量过大。
-
全局字段指标通常需要单独建立索引,以方便后续的关联分析。
-
尽量提升磁盘的 IO 性能,比如使用 SSD,使用文件系统 cache 机制。避免使用 NFS 等远程文件系统。
-
监控数据的特点一般是:数据量大,有效期短。因此可以考虑数据冷热分离。热数据存入 ES 和 Prometheus 中做检索和告警;冷数据以时间区间命名做归档存入其他的分布式文件系统做备份。
-
按照业务级别,需要对日志必须分级,高级别日志需要满足异地容灾、冗余。
-
根据业务敏感度,要考虑到数据的脱敏和归档安全
数据展示
以图表的形式展示相关的度量指标,方便我们查看系统的当前状态。可以使用 Grafana 实现该功能,作为一款非常流行的 dashboard 组件,已经有了众多现成的图表模版,对于大多数系统和中间件可以直接使用。当然对于应用层的监控,可能需要自行设计开发进行展示了。
总体而言,需要有以下功能的展示:
-
总体系统健康和容量情况,包括
- 关键服务的健康状态
- 系统的 SLA 指标,包括吞吐量、响应时间(P99、P95、P90、P75、P50)、错误率(2XX、3XX、4XX、5XX)。
- 各种中间件的关键指标,比如 MySQL 的连接数、Redis 的内存碎片等。
- 服务器基础资源的健康状态,比如 CPU、内存、磁盘、网络等。
-
TopN 视图:包括最慢请求、最热请求、错误最多请求等
数据告警
当系统容量、性能达到瓶颈,或者某个组件出现问题,需要告警组件及时的通知相关人员介入处理。对于告警,需要定义告警规则,一般需要处理如下一些情况:
-
基础探活:采用心跳机制,定期检查某个服务的连通性,让心跳检查失败时,触发告警。MegaEase 开源了 EaseProbe 可以作为众多服务的探活工具。
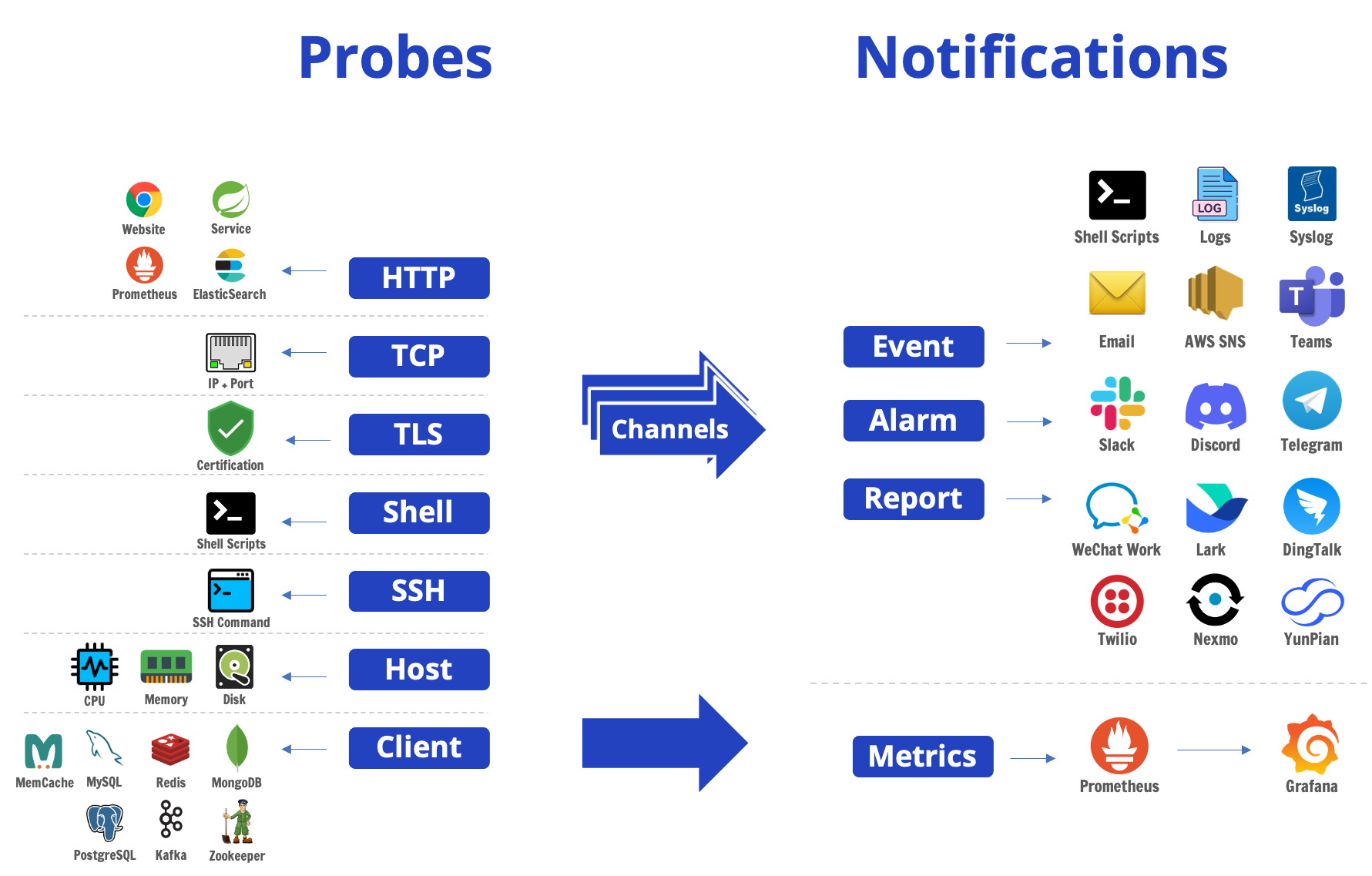 ,
, -
指标 - 持续时间 - 阈值: 当某个指标再一段时间内持续超过某个阈值时,触发告警。比如 两分钟内 CPU 使用率持续超过 90%。
-
指标 - 持续时间 - 百分比 - 阈值: 当某个指标再一段时间内持续超过某个百分比时,触发告警。比如两分钟内 P99 超过 300ms。
-
指标 - 持续时间 - 函数 - 阈值: 此时需要一些聚合计算,某些函数的计算在一段时间内超过阈值。比如两分钟内的 JVM GC 次数(sum 函数计算)超过阈值。
-
指标 - 持续时间 - 关键词 - 匹配次数: 日志中的某个关键词在一段时间内出现的次数超过阈值,关键词需要支持精确匹配和正则匹配。
设置告警规则时,首先需要梳理关键业务路径和非关键业务路径,并以此制定故障分级原则。对于关键业务异常要有事件告警,其次需要对如下关键指标设置告警:
- 各业务接口的失败率指标
- P99/P90/P50 指标
- 主机/服务实例的 CPU、内存、JVM 等基础资源指标
- 主机/服务实例的饱和度指标(磁盘容量、网络IO、磁盘IO)
- 各中间件关键指标
上述提到的组件都提供了告警工具,通常可以满足需求。比如:
- Prometheus Alert Manager
- Elastic Alerting
- Grafana Alerting
当然也可以自研,梳理出关键指标后形成告警规则模版,每当有新服务引入时自动创建告警规则,然后定时监测指标信息,及时告警
至此,如果全部采用开源组件实现一个全栈监控系统,技术栈如下:
- 数据采集端
- 基础层和中间件指标采集 - Telegraf
- 日志采集 - Filebeat 和 Fluentd
- Java Agent - EaseAgent
- OpenTelemetry - OpenTelemetry
- 数据处理管线
- 数据总线 - Apache Kafka
- 数据 ETL - Logstash,Fluentd
- 数据存储
- 日志数据存储 - ElasticSearch
- 指标数据存储 - Prometheus,InfluxDB
- 数据图表
- 数据展示:Grafana
- 异常告警:Prometheus Alert Manager,Elastic Alerting,Grafana Alerting
最终形成如下架构

图片来自MegaEase 官网







:重塑数据安全攻防边界)
![[python] 使用python设计滤波器](http://pic.xiahunao.cn/[python] 使用python设计滤波器)

)

 服务器: 工作原理)





)
