Java面试题029:一文深入了解MySQL(1)
Java面试题030:一文深入了解MySQL(2)
Java面试题031:一文深入了解MySQL(3)
Java面试题032:一文深入了解MySQL(4)
Java面试题033:一文深入了解MySQL(5)
1、分库分表简介
随着业务规模的扩大和系统复杂度的增长,数据量和访问量也同时增加,关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。单个服务的磁盘空间是有限制的,并发压力下,所有的请求都访问同一个节点,肯定会对磁盘IO造成非常大的影响。此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间。
分库:将一个库的数据按照一定规则拆分到多个库中
分表:把一个表的数据按照一定规则放到多个表中
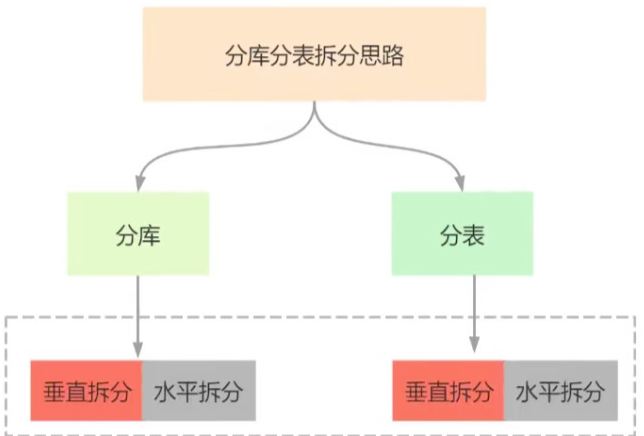
当单个库太大时,先要看一下是因为表太多还是数据量太大,如果是表太多,则应该将部分表进行迁移(可以按业务区分),这就是垂直切分。如果是数据量太大,则需要将表拆成更多的小表,来减少单表的数据量,这就是水平拆分。
2、四种实现形式
(1)垂直分库:是指在一个系统中的按照不同业务进行拆分,将不同的业务数据存放到不同的数据库中。典型的案例是微服务架构中不同的业务微服务可以将自己的业务数据存放到自己的数据源中,以服务的形式向系统提供数据查询。
(2)垂直分表:一般是表中的字段较多时,按照业务需要将列字段拆分为多个表。
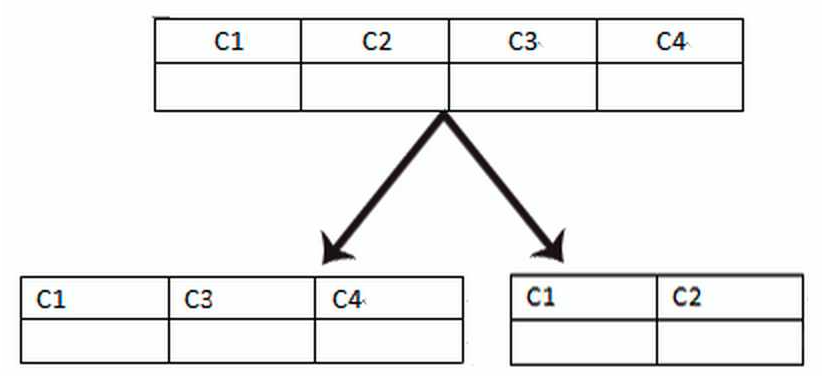
垂直分库(表)是将不同的数据进行分别存放,每个库或表存放的数据差别很大。
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了,可以理解为负载均衡。
(3)水平分库:每个库(表)的结构都一样,数据都不一样。它们的并集就是全量数据。
(4)水平分表:每个库(表)的结构都一样,数据都不一样。它们的并集就是全量数据。
3、分库分表规则
(1)根据数值范围range
按照时间区间或ID区间来切分。例如:按日期将不同月甚至是日的数据分散到不同的库中;将userId为1~9999的记录分到第一个库,10000~20000的分到第二个库。
优点:
- 单表大小可控
- 便于水平扩展,后期想对集群扩容时,只需添加节点即可,无需对其他分片的数据进行迁移
- 使用分片字段进行范围查找时,连续分片可快速定位分片,有效避免跨分片查询的问题。
缺点:
- 热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询。
某些系统中使用的“冷热数据分离“,将一些使用较少的历史数据迁移到其他库中,业务功能上只提供热点数据的查询,也是类似的实践。
(2)根据数值取模Hash
对字段值进行哈希运算后取余分区,适用于数据分布均匀的场景。
例如:将 Customer 表根据 cusno 字段切分到4个库中,余数为0的放到第一个库,余数为1的放到第二个库,以此类推。这样同一个用户的数据会分散到同一个库中,如果查询条件带有cusno字段,则可明确定位到相应库去查询。
优点:
- 数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈
缺点:
-
后期分片集群扩容时,需要迁移旧的数据(使用一致性hash算法能较好的避免这个问题),否则会导致历史数据失效。
-
容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带cusno时,将会导致无法定位数据库,从而需要同时向4个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
4、实现方式
分库分表的开源框架中常用的就是sharding-sphere和Mycat。
sharding-sphere和Mycat后续会有专门单独的章节进行梳理。
一般分库分表步骤分为:根据容量(当前容量和增长量)评估分库或分表个数 -> 选key(均匀)-> 分表规则(hash或range等)-> 执行(一般双写)-> 扩容问题(尽量减少数据的移动)。
(1)Mycat
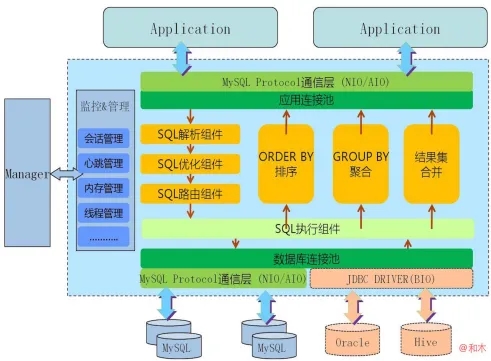
Mycat是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分表分库、容灾备份,而且可以用于多租户应用开发、云平台基础设施、让你的架构具备很强的适应性和灵活性,借助于即将发布的Mycat智能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表映射到不同存储引擎上,而整个应用的代码一行也不用改变。
Mycat的原理中最重要的一个动词是“拦截”,它拦截用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
Mycat典型的应用场景:
-
单纯的读写分离,此时配置最为简单,支持读写分离,主从切换;
-
分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片;
-
多租户应用,每个应用一个库,应用程序只连接Mycat,不改造程序本身,实现多租户化;
-
报表系统,借助Mycat的分表能力,处理大规模报表的统计;
-
替代Hbase,分析大数据;
-
作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时Mycat可能是最简单有效的选择。
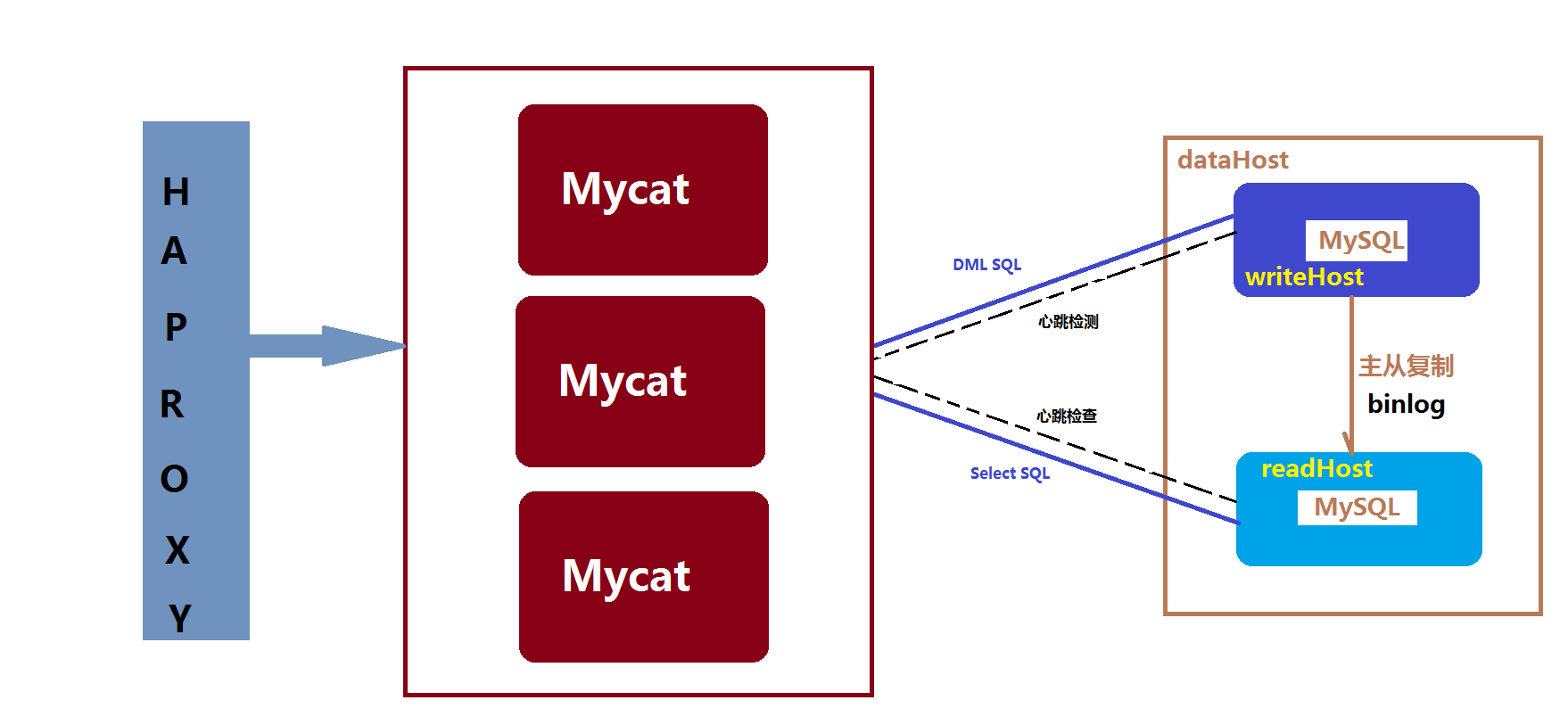
Mycat高可用方案
Mycat系统的高可用涉及到Mycat本身的高可用以及后端MySQL的高可用,大多数情况下,建议采用标准的MySQL主从复制高可用性配置。
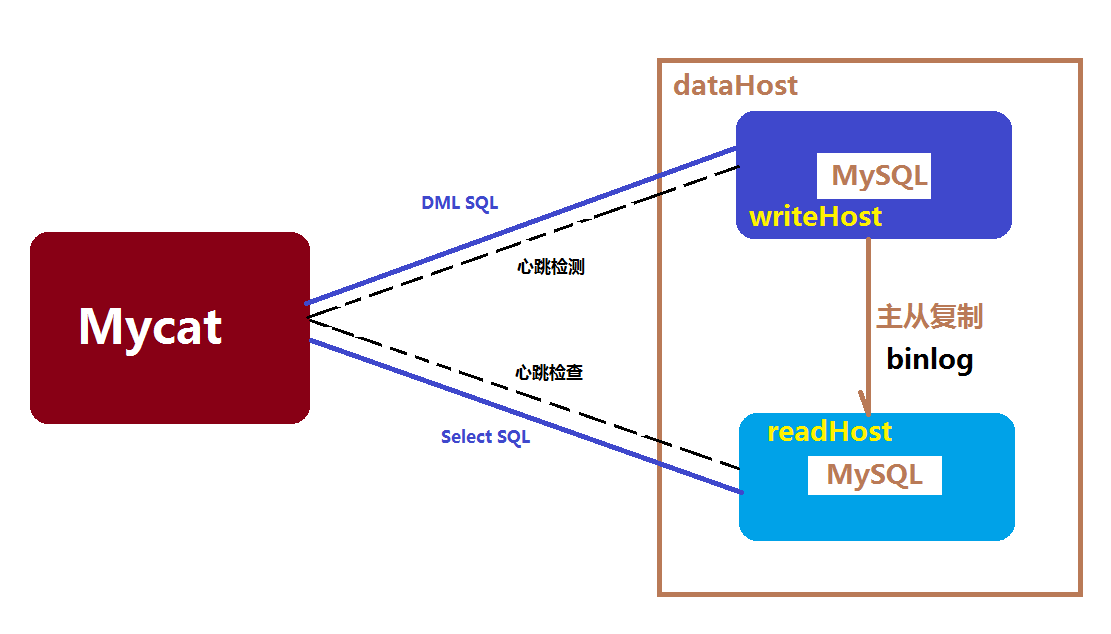
MySQL节点开启主从复制的配置方案,并将主节点配置为Mycat的dataHost里的writeNode,从节点配置为readNode,同时Mycat内部定期对一个dataHost里的所有writeHost与readHost节点发起心跳检测,正常情况下,Mycat会将第一个writeHost作为写节点,所有的DML SQL会发送给此节点,若Mycat开启了读写分离,则查询节点会根据读写分离的策略发往readHost(+writeHost)执行,当一个dataHost里面配置了两个或多个writeHost的情况下,如果第一个writeHost宕机,则Mycat会在默认的3次心跳检查失败后,自动切换到下一个可用的writeHost执行DML SQL语句。
Mycat自身的高可用性,官方建议是采用基于硬件的负载均衡器或者软件方式的HAproxy,HAProxy相比LVS的使用要简单很多,功能方面也很丰富,免费开源。(HAproxy+Mycat集群+MySQL主从所组成的高可用性方案)
(2)sharding-sphere
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
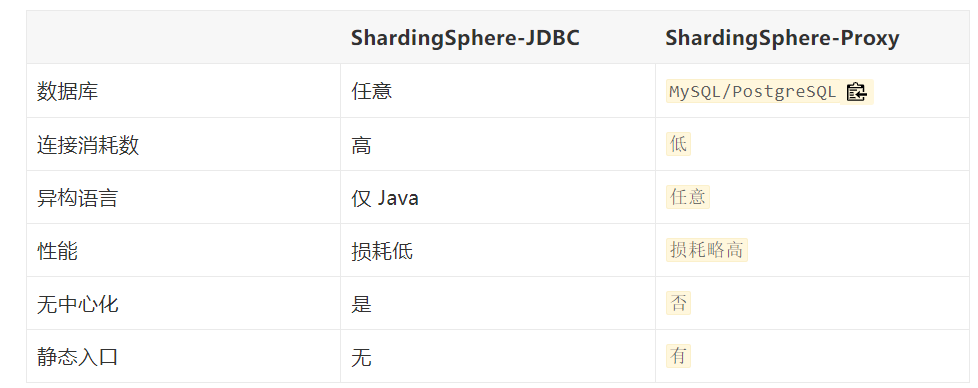
通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统。
数据分片
指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。ShardingSphere 基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储。
ShardingSphere通过YAML 配置方式,实现数据分片,在 YAML 文件中配置数据分片规则,包含数据源、分片规则、全局属性等配置项,然后调用 YamlShardingSphereDataSourceFactory 对象的 createDataSource 方法,根据配置信息自动完成ShardingSphereDataSource 对象的创建。
rules:
- !SHARDINGtables: # 数据分片规则配置<logic_table_name> (+): # 逻辑表名称actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一standard: # 用于单分片键的标准分片场景shardingColumn: # 分片列名称shardingAlgorithmName: # 分片算法名称complex: # 用于多分片键的复合分片场景shardingColumns: # 分片列名称,多个列以逗号分隔shardingAlgorithmName: # 分片算法名称hint: # Hint 分片策略shardingAlgorithmName: # 分片算法名称none: # 不分片tableStrategy: # 分表策略,同分库策略keyGenerateStrategy: # 分布式序列策略column: # 自增列名称,缺省表示不使用自增主键生成器keyGeneratorName: # 分布式序列算法名称auditStrategy: # 分片审计策略auditorNames: # 分片审计算法名称- <auditor_name>- <auditor_name>allowHintDisable: true # 是否禁用分片审计hintautoTables: # 自动分片表规则配置t_order_auto: # 逻辑表名称actualDataSources (?): # 数据源名称shardingStrategy: # 切分策略standard: # 用于单分片键的标准分片场景shardingColumn: # 分片列名称shardingAlgorithmName: # 自动分片算法名称bindingTables (+): # 绑定表规则列表- <logic_table_name_1, logic_table_name_2, ...> - <logic_table_name_1, logic_table_name_2, ...> defaultDatabaseStrategy: # 默认数据库分片策略defaultTableStrategy: # 默认表分片策略defaultKeyGenerateStrategy: # 默认的分布式序列策略defaultShardingColumn: # 默认分片列名称# 分片算法配置shardingAlgorithms:<sharding_algorithm_name> (+): # 分片算法名称type: # 分片算法类型props: # 分片算法属性配置# ...# 分布式序列算法配置keyGenerators:<key_generate_algorithm_name> (+): # 分布式序列算法名称type: # 分布式序列算法类型props: # 分布式序列算法属性配置# ...# 分片审计算法配置auditors:<sharding_audit_algorithm_name> (+): # 分片审计算法名称type: # 分片审计算法类型props: # 分片审计算法属性配置# ...- !BROADCASTtables: # 广播表规则列表- <table_name>- <table_name>
配置示例:
dataSources:ds_0:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.jdbc.DriverjdbcUrl: jdbc:mysql://localhost:3306/demo_ds_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8username: rootpassword:ds_1:dataSourceClassName: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.jdbc.DriverjdbcUrl: jdbc:mysql://localhost:3306/demo_ds_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8username: rootpassword:rules:
- !SHARDINGtables: # 数据分片规则配置t_order: # 逻辑表名称actualDataNodes: ds_${0..1}.t_order_${0..1} # 由数据源名 + 表名组成(参考 Inline 语法规则)tableStrategy: # 分表策略,缺省表示使用默认分表策略,以下的分片策略只能选其一standard:shardingColumn: order_idshardingAlgorithmName: t_order_inlinekeyGenerateStrategy:column: order_idkeyGeneratorName: snowflakeauditStrategy:auditorNames:- sharding_key_required_auditorallowHintDisable: truet_order_item:actualDataNodes: ds_${0..1}.t_order_item_${0..1}tableStrategy:standard:shardingColumn: order_idshardingAlgorithmName: t_order_item_inlinekeyGenerateStrategy:column: order_item_idkeyGeneratorName: snowflaket_account:actualDataNodes: ds_${0..1}.t_account_${0..1}tableStrategy:standard:shardingAlgorithmName: t_account_inlinekeyGenerateStrategy:column: account_idkeyGeneratorName: snowflakedefaultShardingColumn: account_idbindingTables:- t_order,t_order_itemdefaultDatabaseStrategy:standard:shardingColumn: user_idshardingAlgorithmName: database_inlinedefaultTableStrategy:none:shardingAlgorithms:database_inline:type: INLINEprops:algorithm-expression: ds_${user_id % 2}t_order_inline:type: INLINEprops:algorithm-expression: t_order_${order_id % 2}t_order_item_inline:type: INLINEprops:algorithm-expression: t_order_item_${order_id % 2}t_account_inline:type: INLINEprops:algorithm-expression: t_account_${account_id % 2}keyGenerators:snowflake:type: SNOWFLAKEauditors:sharding_key_required_auditor:type: DML_SHARDING_CONDITIONS- !BROADCASTtables:- t_addressprops:sql-show: false
YamlShardingSphereDataSourceFactory.createDataSource(getFile("/META-INF/sharding-databases-tables.yaml"));
分片键
用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
分片算法
ShardingSphere 内置提供了多种分片算法,按照类型可以划分为自动分片算法、标准分片算法、复合分片算法和 Hint 分片算法,能够满足用户绝大多数业务场景的需要。此外,考虑到业务场景的复杂性,内置算法也提供了自定义分片算法的方式,用户可以通过编写 Java 代码来完成复杂的分片逻辑。
(1)自动分片算法
自动分片算法的分片逻辑由 ShardingSphere 自动管理,需要通过配置 autoTables 分片规则进行使用。
- 取模分片算法:MOD

- 哈希取模分片算法:HASH_MOD

- 基于分片容量的范围分片算法:VOLUME_RANGE
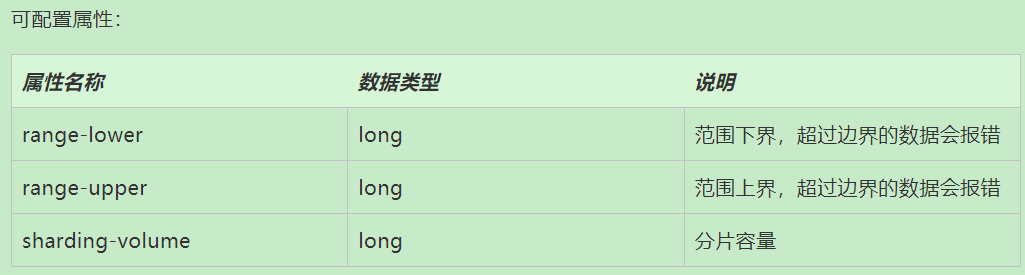
- 基于分片边界的范围分片算法:BOUNDARY_RANGE

-
自动时间段分片算法:AUTO_INTERVAL
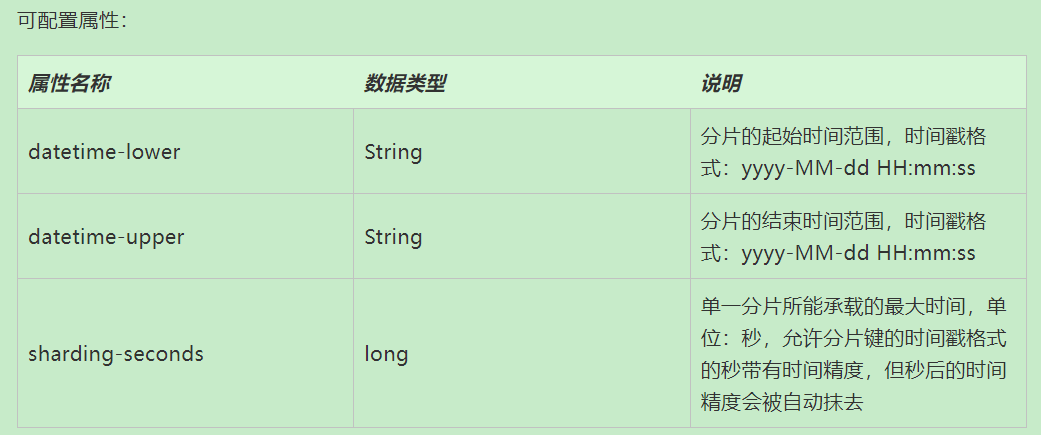
(2)标准分片算法
用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。
Apache ShardingSphere 内置的标准分片算法实现类包括:
- 行表达式分片算法:提供对 SQL 语句中的
=和IN的分片操作支持,只支持单分片键。 - 时间范围分片算法
(3)复合分片算法
用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
行表达式:简化数据节点配置工作量
由两部分组成,分别是字符串开头的对应 SPI 实现的 Type Name 部分和表达式部分。
${['online', 'offline']}_table${1..3}
最终会解析为:
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3
(4)Hint 分片算法
用于处理使用 Hint 行分片的场景。
:面向对象中的构造方法)












)




-day23)
