文章目录
- 一、有关概念
- 原子性
- 错误认知澄清
- 加锁
- 二、锁的相关函数
- 全局锁
- 局部锁
- 初始化
- 销毁
- 加锁
- 解锁
- 三、锁相关
- 如何看待锁
- 一个线程在执行临界区的代码时,可以被切换吗?
- 锁是本身也是临界资源,它如何做到保护自己?(锁的实现)
- 软件层面的互斥锁的实现
- 硬件层面的互斥锁的实现
- 锁是不允许拷贝构造或者赋值拷贝的
- 锁的饥饿问题
一、有关概念
共享资源:多执行流运行时都能使用的资源临界资源:多线程执行流被保护的共享的资源就叫做临界资源- 临界区:每个线程内部,访问临界资源的代码,就叫做临界区
互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用原子性:不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成- 保护的方式常见:
互斥与同步 - 多个执行流,访问临界资源的时候,具有一定的顺序性,叫做
同步 - 在进程中涉及到互斥资源的程序段叫临界区。你写的代码=访问临界资源的代码(临界区)+不访问临界资源的代码(非临界区)
- 所谓的对共享资源进行保护,本质是对访问共享资源的代码进行保护
原子性
原子性是指一个操作在执行过程中不会被其他线程或者中断所干扰
即这个操作要么完全执行,要么完全不执行,不会出现只执行了一部分的情况。
注意:
在计算机系统中,原子性指令的设计目标就是确保其执行过程不可分割,即使在多核并行环境下,同一原子指令也不可能被两个CPU核心真正“同时”执行
原因:
-
总线锁定
原理:当CPU核心执行原子指令时,会通过总线信号锁定内存区域,阻止其他核心访问对应变量物理内存地址,防止变量被修改被读取
代价:锁定总线会导致其他核心的访存操作被阻塞,影响整体性能 -
缓存锁定
原理:利用缓存一致性协议,在缓存行级别锁定内存区域,无需全局总线锁定。
优势:更高效,仅阻塞对特定缓存行的访问 -
硬件指令原子性
某些指令(如x86的LOCK前缀指令)直接在硬件层面保证原子性,例如:
LOCK ADD [mem], 1 ; 原子递增内存值
错误认知澄清
误区:原子操作等同于“互斥”?
错误观点:原子操作让其他线程完全无法访问变量
现实:原子操作仅保证特定操作的原子性,其他线程仍可自由访问变量(例如,通过非原子方式读取,或执行其他原子操作)
例
std::atomic<int> x(0);
int y = 0;线程A(原子写)
x.store(42, std::memory_order_relaxed);线程B(非原子读!)
int local_x = x.load(std::memory_order_relaxed); 正确:原子读
int local_y = y; 错误:非原子读,可能读到未同步的值
原子操作和互斥锁虽然都能实现线程安全,但它们的核心机制和适用场景不同:
- 原子操作:针对单个变量的特定操作,通过硬件指令实现高效无锁同步
- 互斥锁:保护代码块内的任意操作(无论涉及多少变量),通过阻塞实现强一致性
所以:
原子性和互斥锁都能保证对共享资源的进行某一操作时,多执行流必须串行执行,但是互斥锁保护的范围比原子性更大
多执行流时,共享资源如果不加保护会怎么样?
多执行流时,共享资源不互斥(没有原子性)可能会怎样?
很可能产生数据不一致问题
例
下面是4个线程同时进行抢票的操作,票数就是全局变量ticket
#include <iostream>
#include <unistd.h>
#include <pthread.h>int ticket = 100;void* Route(void* args)
{char* buf = (char*)args;while(true){if(ticket > 0){sleep(1);std::cout << buf << "sell ticket: " << ticket << std::endl;ticket--;}else{break;}}return nullptr;
}int main()
{pthread_t t1, t2, t3, t4;pthread_create(&t1, nullptr, Route, (void*)"thread 1");pthread_create(&t2, nullptr, Route, (void*)"thread 2");pthread_create(&t3, nullptr, Route, (void*)"thread 3");pthread_create(&t4, nullptr, Route, (void*)"thread 4");pthread_join(t1, nullptr);pthread_join(t2, nullptr);pthread_join(t3, nullptr);pthread_join(t4, nullptr);return 0;
}
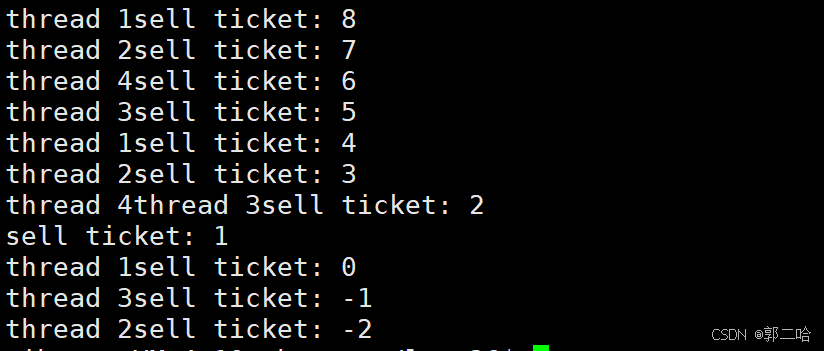
为什么最后抢票会抢出负数?
if(ticket>0)不是原子的
因为它会变成3条汇编指令,一条汇编指令虽然是原子的,但是3条汇编指令和在一起的操作就不是原子的了
所以在CPU在执行这3条汇编指令期间,都有可能进行线程切换。
比如:
ticket=1了,线程a把1读取到寄存器之后,线程a就切换了,还没去–ticket
线程b也来读取了,也把ticket=1读到寄存器里了
这个时候,线程a和线程b就都会判断,ticket>0,就都进去抢了
而且
ticket–也不是原子的
线程/进程什么时候会发生切换?
- 线程时间片到了
- 来了一个(多个)优先级更高的进程/线程,此时CPU上的线程时间片没有耗尽也可能会被切换
- CPU上的线程执行阻塞了(比如执行了sleep暂停代码,scanf等待键盘等)线程进入等待队列,代码不执行了
CPU就不会让这个线程占着茅坑不拉屎,就会直接切换到其他线程
因为ticketnum–编译之后,会变成3条汇编指令
- 读取ticket到CPU的寄存器
- CPU执行–计算
- 把计算之后的ticket结果写回内存
所以ticket–不是原子的
所以上面的代码,在ticket=1时:
线程1执行if判断时,可以通过,然后执行sleep时,就会阻塞,就切换到线程2了
线程2执行if判断时,ticket还是1,所以线程2也能通过,然后执行sleep,阻塞,就切换到线程3
线程3…
所以最后if的{}里面同时进入了4个线程
4个线程依次从阻塞状态恢复,依次对ticket进行–
ticket就减到了-2
还是上面的4个线程抢票问题
因为ticket–编译之后,会变成3条汇编指令
- 读取ticket到CPU的寄存器
- CPU执行–计算
- 把计算之后的ticket结果写回内存
所以ticket–不是原子的
假设线程1要执行ticket–了,此时ticket的值为10000
CPU执行第一个汇编指令,把10000写进CPU寄存器
CPU执行第二个汇编指令,把10000减到了9999
CPU刚准备执行第3个汇编指令时,线程1的时间片到了
那么CPU就会把CPU中线程1相关的寄存器中的数据保存,即保存上下文数据(PC指针和9999等)
然后线程2被切换上来了,正好线程2也要执行ticket–
而线程2运气比较好,它一直循环执行了9999次ticket–
于是线程2从10000开始减[ 因为线程1的9999没有写回内存,而线程的上下文是线程私有的 ]把ticket减到了1
线程2准备再次执行ticket–时,也和线程1一样,刚执行到第二条汇编代码,把ticket减到0,时间片就到了
线程2就被切换成了线程1
线程1恢复上下文之后,根据PC指针中的下一条汇编代码继续执行
就把自己计算的结果:9999写回了内存中的ticket中
然后从循环从9999开始减…
所以线程2就白干了
加锁
如何给共享资源增加互斥性质?
多执行流时保护共享资源的本质其实是:
保护临界区的代码,因为共享资源是通过临界区的代码访问的
那么给共享资源增加互斥性质,本质就是给临界区代码添加互斥性质
让任意时刻最多同时有一个执行流执行该临界区的代码
如何给临界区添加互斥性质?
加锁
Linux上提供的这把锁叫互斥量。
加了锁之后:
每个线程(执行流)执行这个互斥性质的临界区的代码之前,都必须先申请锁,只有申请锁成功的那个线程才能执行临界区的代码
二、锁的相关函数
锁pthread_mutex_t类型的结构体
分为
全局锁
- 全局锁可以使用
pthread_mutex_init或者宏PTHREAD_MUTEX_INITIALIZER初始化 - 全局锁销不销毁无所谓,因为生命周期本来就和进程一样长
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER
局部锁
- 只能使用
pthread_mutex_init初始化 - 并且需要使用
pthread_mutex_destroy销毁局部锁 - 锁是局部的,所以要让所有线程都看到的话,就需要把锁的地址/引用传给所有线程
初始化
pthread_mutex_init
作用:初始化对应的锁
#include <pthread.h>int pthread_mutex_init(pthread_mutex_t * mutex,const pthread_mutexattr_t * attr);
- pthread_mutex_t* mutex:要初始化的锁的地址
- const pthread_mutexattr_t* attr:用户指定的锁的属性,一般不管,设置为nullptr
- 返回值
0 成功,互斥锁(mutex)初始化完成。
非 0 失败,返回的错误代码
销毁
pthread_mutex_destroy
作用:销毁对应的锁
int pthread_mutex_destroy(pthread_mutex_t *mutex);
- pthread_mutex_t*mutex:要销毁的锁的地址
- 返回值
0 成功
非 0 失败
加锁
pthread_mutex_lock
作用:对一个临界区上锁(申请一个访问对应临界区的"入场券")
- 申请成功:就获得对应的入场券
- 申请失败:就说明其他线程已经把入场券抢完了,此时线程的PCB就进入对应的等待队列
阻塞
int pthread_mutex_lock(pthread_mutex_t *mutex);
- pthread_mutex_t*mutex:锁对象的地址
- 返回值
0 成功
非 0 失败
pthread_mutex_trylock
作用:对一个临界区上锁(申请一个访问对应临界区的"入场券"):
- 申请成功:就获得对应的入场券
- 申请失败:就说明其他线程已经把入场券抢完了,此时线程
不阻塞,直接返回一个错误码
int pthread_mutex_trylock(pthread_mutex_t *mutex);
- pthread_mutex_t*mutex:锁对象的地址
- 返回值
0 成功
非 0 失败
解锁
pthread_mutex_unlock
作用:
解除对应的锁(把一个访问对应临界区的"入场券"还回去,让其他线程可以去抢"入场券")
int pthread_mutex_unlock(pthread_mutex_t *mutex);
- pthread_mutex_t*mutex:锁对象的地址
- 返回值
0 成功
非 0 失败
三、锁相关
如何看待锁
锁的本质就是一个二元信号量
而二元信号量本质是一个值只可能为1或0的计数器
这个计数器作为锁时:记的是访问对应临界区的"入场券"数量
即
- 没有线程申请访问对应临界区时,count为1
- 有一个线程成功申请到了使用对应临界区的资格时,count就变成0
- 解锁的话,count就从0变成1
所以锁本质是一个预定机制
一个线程在执行临界区的代码时,可以被切换吗?
可以被切换
而且这个线程切换了之后,其他线程依然不能进入临界区
因为这个线程还没有调用解锁的接口,所以这个线程把锁“拿走了”
所以一个线程执行临界区代码这个操作,对于其他线程来说就是具有原子性的!
因为对于其他线程而言:
这个临界区的代码要吗没有被这个线程执行,要吗就是这个线程执行完了
执行过程中不可能被任何其他线程干扰
锁是本身也是临界资源,它如何做到保护自己?(锁的实现)
每个线程(执行流)执行某个互斥性质的临界区的代码之前,都必须先申请锁,只有申请成功的那个线程才能执行临界区的代码
锁需要被所有线程共享访问,因此它本身是一种共享资源。
由于锁的实现必须保证自身操作的原子性(如通过硬件指令避免竞争),所以锁也是一种临界资源——它需要被自身的机制保护。
软件层面的互斥锁的实现
软件层面锁是如何自保的?
加锁和解锁的操作是原子的锁的本质是一个二元信号量,即一个只有0和1的计数器
我们知道++和–操作都不是原子的,所以锁不能通过++或者–来修改自己的值
为了实现互斥锁,体系结构[X86,X64等]提供了两个新的汇编指令,swap和xchange
它们的作用都是:交换一个寄存器和一个物理内存中的变量的值
因为swap和xchange都只是一条汇编指令,所以他们两个操作都是原子的
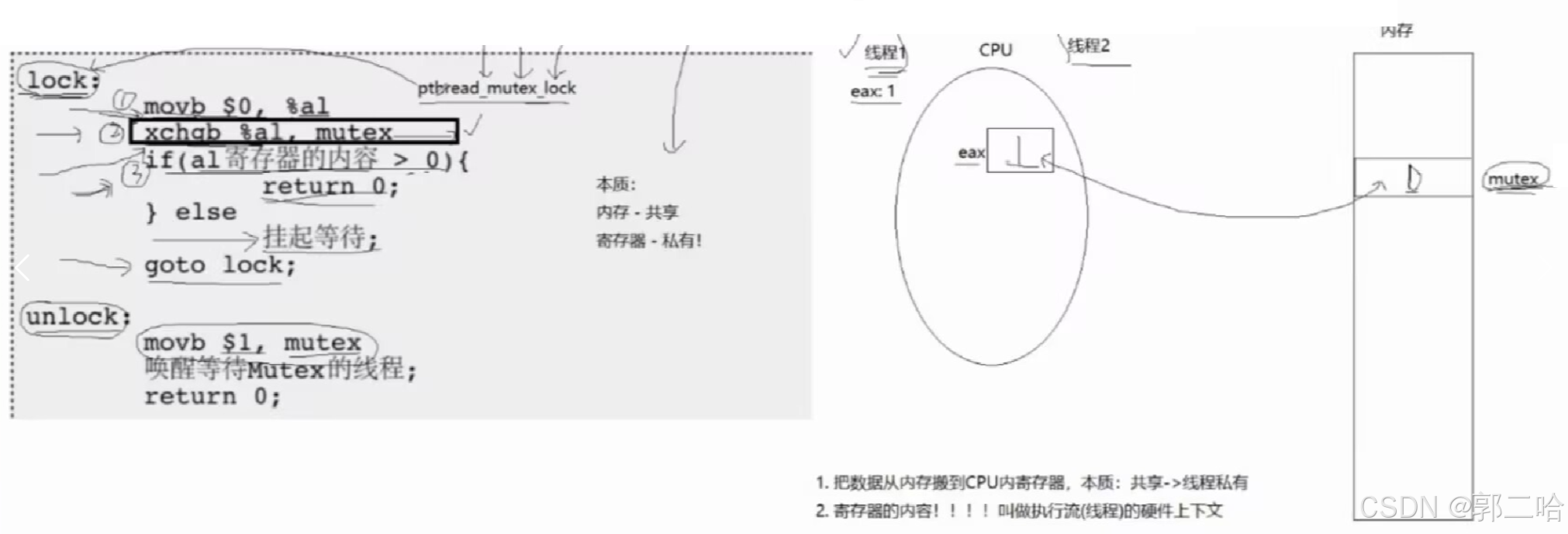
函数pthread_mutex_lock和unlock实现的伪代码如下图:
即
调用pthread_mutex_init或者使用宏初始化锁之后,物理内存中锁mutex里面的值为1
-
①movb $0,%al:就是把0放进一个寄存器中
-
②xchge %al,mutex:就是交换寄存器和mutex中的值
-
③
- 1.如果寄存器交换得到的值>0,这个线程就申请锁成功,获得进入临界区的资格
- 2.如果寄存器交换得到的值<0,这个线程就会被阻塞,等到获取到锁的线程解锁之后,才会继续运行
-
④最后执行goot lock,即回到pthread_mutex_lock函数的开头重新执行一遍,看能不能抢到锁
线程进入pthread_mutex_lock函数之后依然可以进行切换,并且不会影响锁的获取
为什么?
假设有两个线程
线程1先调用pthread_mutex_lock,当线程1执行完第②条汇编指令[xchge %al,mutex],把寄存器中的0与mutex中的1进行了交换
然后就被切换走了
切换之前,CPU会保护线程1的上下文数据,所以线程1就把mutex中的1放进上下文里带走了
线程2切换上来之后,也执行了lock方法想要获取锁
线程2执行汇编指令①:把0放进寄存器中,把线程1留下的1覆盖
执行汇编指令②,交换寄存器与mutex的值
但是此时线程2只能从mutex里面拿到被线程1换进去的0
拿不到1了,所以线程2获取锁失败,被阻塞
所以
- 线程1如果在执行汇编指令②之前被切换,本来就不影响锁的竞争
- 线程1如果在执行完汇编指令②并且成功获取了锁,之后被切换,即使线程1被切换了它也会把1(锁)带走
所以其实整个pthread_mutex_lock中,汇编指令②xchge %al,mutex就是申请锁
pthread_mutex_unlock中movb $1,mutex就是解锁
所以
线程们竞争的资源是什么?
是mutex这个变量空间吗?不是!
因为所有线程都可以与变量空间中的值进行交换
线程们竞争的是1,是mutex初始时(或者解锁操作执行后)mutex里面那唯一的一个1
mutex里面的值可能>1或者<0吗?
不可能!!!
因为锁只能使用pthread_mutex_init或者宏初始化,不支持其他任何初始化方法
解锁时也只会把1放进mutex中
硬件层面的互斥锁的实现
即
在某个线程要执行临界区代码之前,先关闭操作系统对与时钟中断和外部中断的响应
这个线程执行完临界区代码之后,再打开
即:这个线程执行临界区代码时,操作系统不会进行切换
这样就可以防止并发切换导致的线程安全问题
不过:一般用的是软件实现锁
锁是不允许拷贝构造或者赋值拷贝的
因为如果要使用锁对一个临界资源进行保护的话
那么就应该保证所有想访问这个临界资源线程看到的都是同一把锁
不然就不能起到保护的作用了
所以为了防止用户无意识地进行锁的拷贝构造/赋值导致出现线程安全问题
就直接禁止锁进行拷贝构造和赋值拷贝了
锁的饥饿问题
如果一个共享资源只加了锁,就有可能出现锁的饥饿问题
例:
一个死循环–计数器的代码
while(1)
{
//加锁
p–
//解锁
}
一个线程a抢到锁之后,其他线程想要锁的进程就只能阻塞等待线程a解锁
线程a使用完临界区之后,解锁之后,又进入下一次循环,又去抢锁了
因为其他想抢锁的线程还阻塞着,唤醒需要时间
但是线程a本来就醒着,所以线程a就比别的线程快,马上又把锁抢到了
其他想要锁的线程只能再次进入阻塞状态
就有可能一直是线程a拿着锁,访问临界区
怎么解决这个问题?
就要用到同步了
宣布开源两大核心项目——Coze Studio(扣子开发平台)和Coze Loop(扣子罗盘),附安装步骤)
)
)












)



