🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【机器学习案列-25】电信用户流失预测:从数据处理到模型评估
- 一、引言
- 二、数据集介绍
- 三、环境准备
- 四、数据清洗与探索
- 4.1 数据加载与预处理
- 4.2 数据探索
- 4.3 缺失值处理
- 4.4 数据分布
- 4.5 特征分布
- 五、特征工程
- 5.1 哑变量转换
- 5.2 特征选择
- 六、模型构建与训练
- 6.1 随机森林模型
- 6.2 模型评估
- 6.3 特征重要性
- 6.4 ROC 曲线与 AUC 值
- 七、分析总结与策略建议
- 7.1 关键发现
- 7.2 策略建议
一、引言
在电信行业,用户流失是一个关键问题,因为它直接影响到公司的收入和市场份额。通过分析用户流失的原因,我们可以制定有效的策略来减少流失率,提高用户满意度和忠诚度。本文将使用 Python 进行数据处理、可视化、特征工程和模型构建,最终实现用户流失的预测。

二、数据集介绍
数据集包含以下字段:
customerID:用户IDgender:性别SeniorCitizen:是否是老年人(1代表是)Partner:是否有配偶(Yes or No)Dependents:是否经济独立(Yes or No)tenure:用户入网时间PhoneService:是否开通电话业务(Yes or No)MultipleLines:是否开通多条电话业务(Yes、No or No phoneservice)InternetService:是否开通互联网服务(No、DSL数字网络或fiber optic光线网络)OnlineSecurity:是否开通网络安全服务(Yes、No or No internetservice)OnlineBackup:是否开通在线备份服务(Yes、No or No internetservice)DeviceProtection:是否开通设备保护服务(Yes、No or No internetservice)TechSupport:是否开通技术支持业务(Yes、No or No internetservice)StreamingTV:是否开通网络电视(Yes、No or No internetservice)StreamingMovies:是否开通网络电影(Yes、No or No internetservice)Contract:合同签订方式(按月、按年或者两年)PaperlessBilling:是否开通电子账单(Yes or No)PaymentMethod:付款方式(bank transfer、credit card、electronic check、mailed check)MonthlyCharges:月度费用TotalCharges:总费用Churn:是否流失(Yes or No)
三、环境准备
在开始之前,请确保安装了以下库:
pip install pandas numpy seaborn matplotlib scikit-learn
四、数据清洗与探索
4.1 数据加载与预处理
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_curve, auc# 加载数据
data = pd.read_csv("WA_Fn-UseC_-Telco-Customer-Churn.csv")# 将列名转换为中文
data.columns = ['用户ID', '性别', '是否老年人', '是否有配偶', '是否经济独立', '用户入网时间','是否开通电话业务', '是否开通多条电话业务', '是否开通互联网服务', '是否开通网络安全服务','是否开通在线备份服务', '是否开通设备保护服务', '是否开通技术支持业务', '是否开通网络电视','是否开通网络电影', '合同签订方式', '是否开通电子账单', '付款方式', '月度费用','总费用', '是否流失'
]# 将总费用列转换为浮点型
data['总费用'] = pd.to_numeric(data['总费用'], errors='coerce').fillna(0)# 将是否流失列转换为数值型
data['是否流失'] = data['是否流失'].map({'Yes': 1, 'No': 0})
4.2 数据探索
# 查看数据基本信息
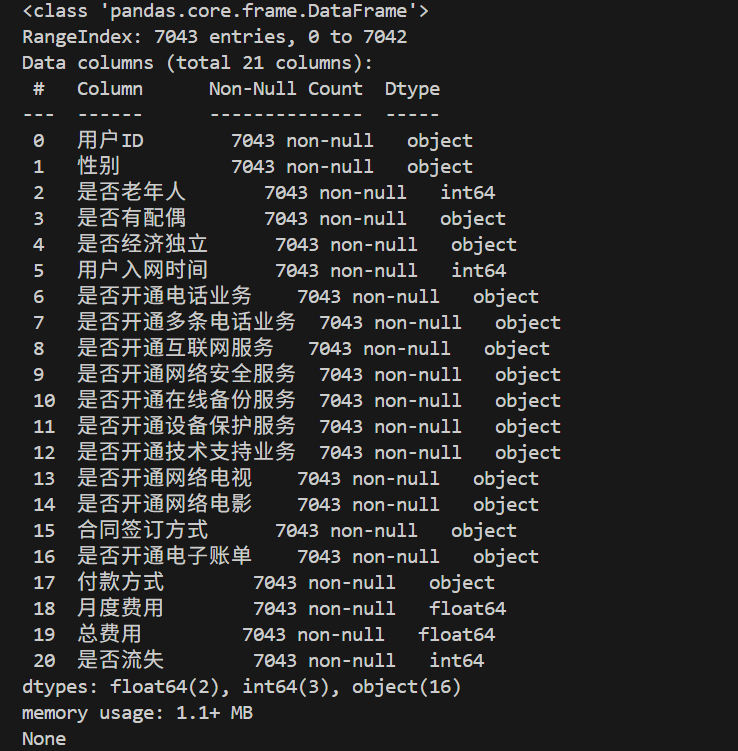
print(data.info())
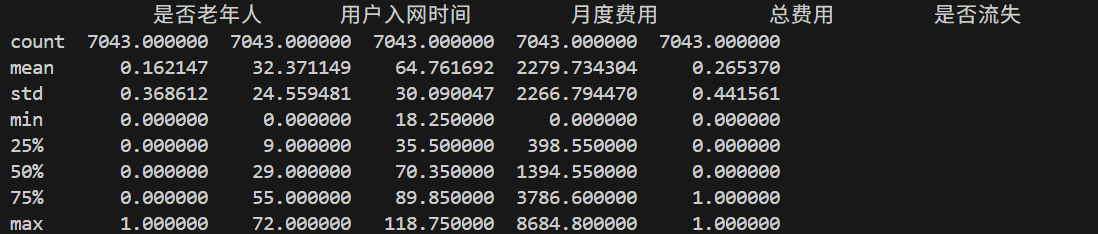
print(data.describe())# 查看数据样本
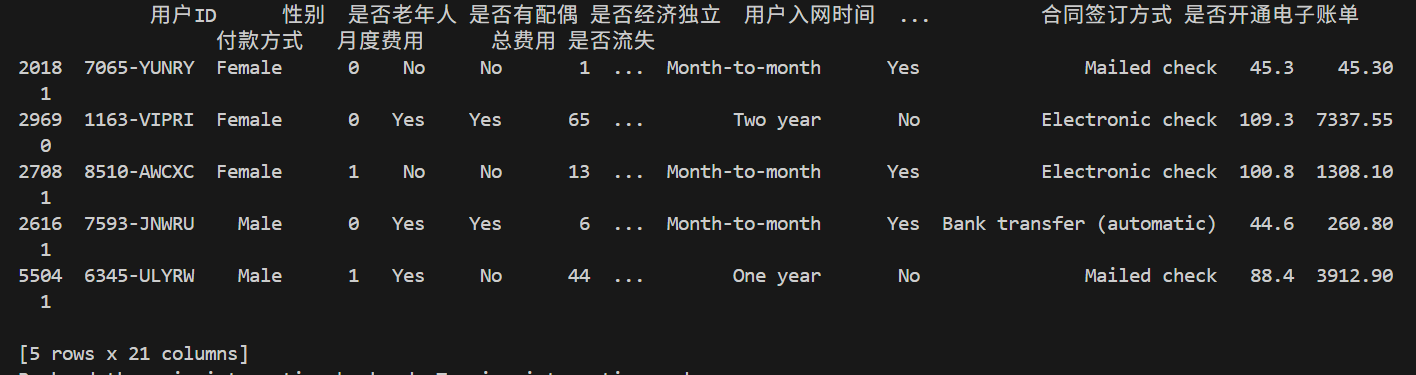
print(data.sample(5))
4.3 缺失值处理
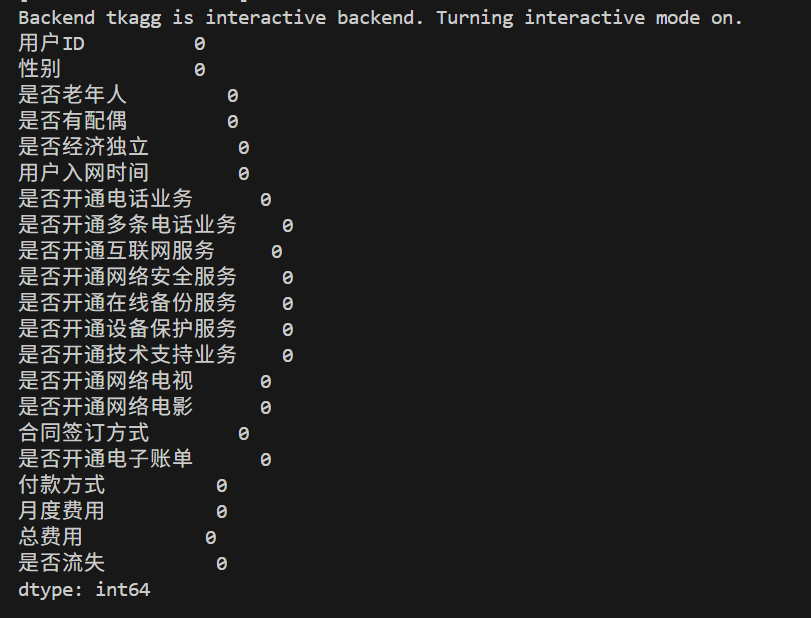
# 检查缺失值
print(data.isnull().sum())# 填充缺失值
data['总费用'] = data['总费用'].fillna(data['总费用'].median())
4.4 数据分布
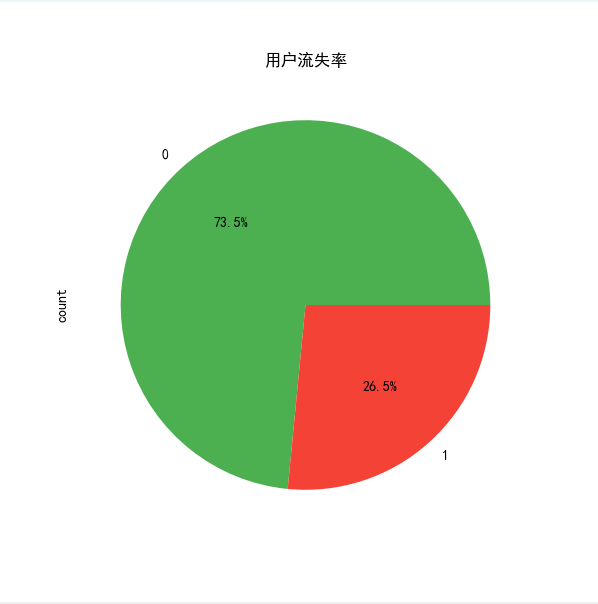
# 用户流失率
churn_rate = data['是否流失'].mean() * 100
print(f"用户流失率: {churn_rate:.2f}%")# 绘制用户流失率饼图
plt.figure(figsize=(6, 6))
data['是否流失'].value_counts().plot.pie(autopct='%1.1f%%', colors=['#4CAF50', '#F44336'])
plt.title("用户流失率")
plt.show()
4.5 特征分布
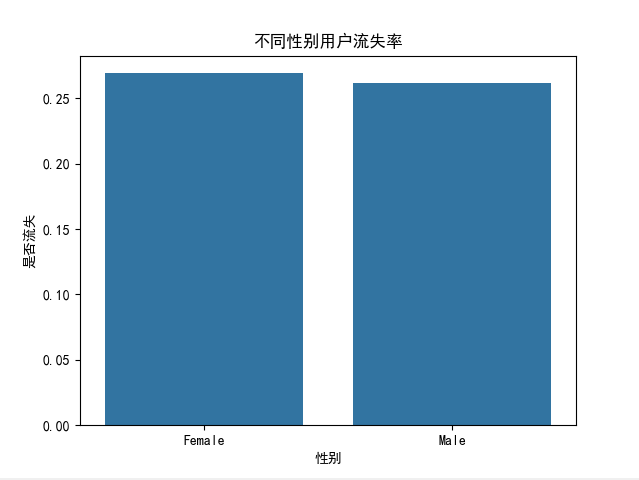
# 不同性别用户流失率
gender_churn = data.groupby('性别')['是否流失'].mean().reset_index()
sns.barplot(x='性别', y='是否流失', data=gender_churn)
plt.title("不同性别用户流失率")
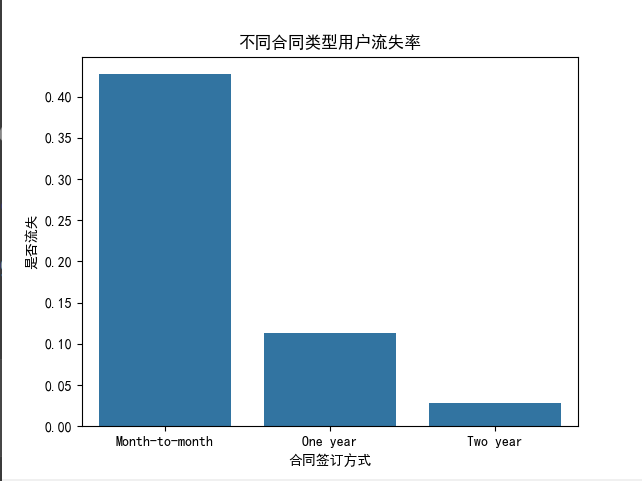
plt.show()# 不同合同类型用户流失率
contract_churn = data.groupby('合同签订方式')['是否流失'].mean().reset_index()
sns.barplot(x='合同签订方式', y='是否流失', data=contract_churn)
plt.title("不同合同类型用户流失率")
plt.show()
具体的数据特征分布,参考【数据可视化-74】电信用户流失数据可视化分析:Python + Pyecharts 炫酷大屏(含完整的数据,代码)文章即可;
五、特征工程
5.1 哑变量转换
# 将分类变量转换为哑变量
data = pd.get_dummies(data, columns=['性别', '是否有配偶', '是否经济独立', '是否开通电话业务', '是否开通多条电话业务','是否开通互联网服务', '是否开通网络安全服务', '是否开通在线备份服务','是否开通设备保护服务', '是否开通技术支持业务', '是否开通网络电视', '是否开通网络电影','合同签订方式', '是否开通电子账单', '付款方式'
])# 查看转换后的数据
print(data.head())
5.2 特征选择
# 选择特征和目标变量
X = data.drop(['用户ID', '是否流失'], axis=1)
y = data['是否流失']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
六、模型构建与训练
6.1 随机森林模型
# 创建随机森林分类器
rf = RandomForestClassifier(random_state=42)# 定义超参数范围
param_grid = {'n_estimators': [50, 100, 150],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}# 使用 GridSearchCV 进行超参数调优
grid_search = GridSearchCV(rf, param_grid, cv=5)
grid_search.fit(X_train, y_train)# 输出最佳超参数组合
print("最佳超参数组合为:", grid_search.best_params_)# 使用最佳超参数组合重新训练模型
best_rf = grid_search.best_estimator_
best_rf.fit(X_train, y_train)
6.2 模型评估
# 在测试集上进行预测
y_pred = best_rf.predict(X_test)# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f"准确率: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
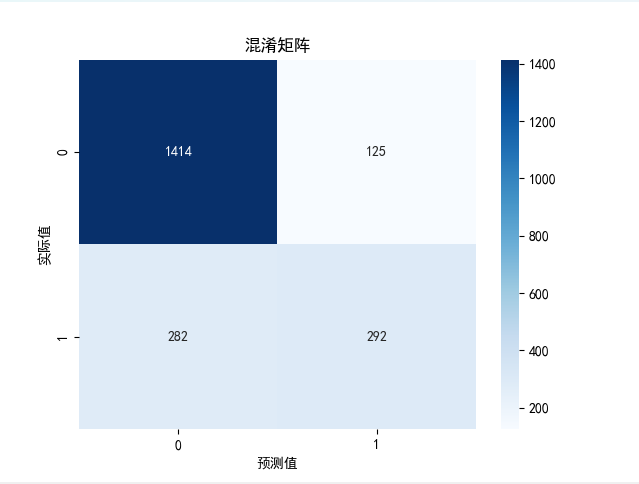
print(f"F1值: {f1:.4f}")# 绘制混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel("预测值")
plt.ylabel("实际值")
plt.title("混淆矩阵")
plt.show()

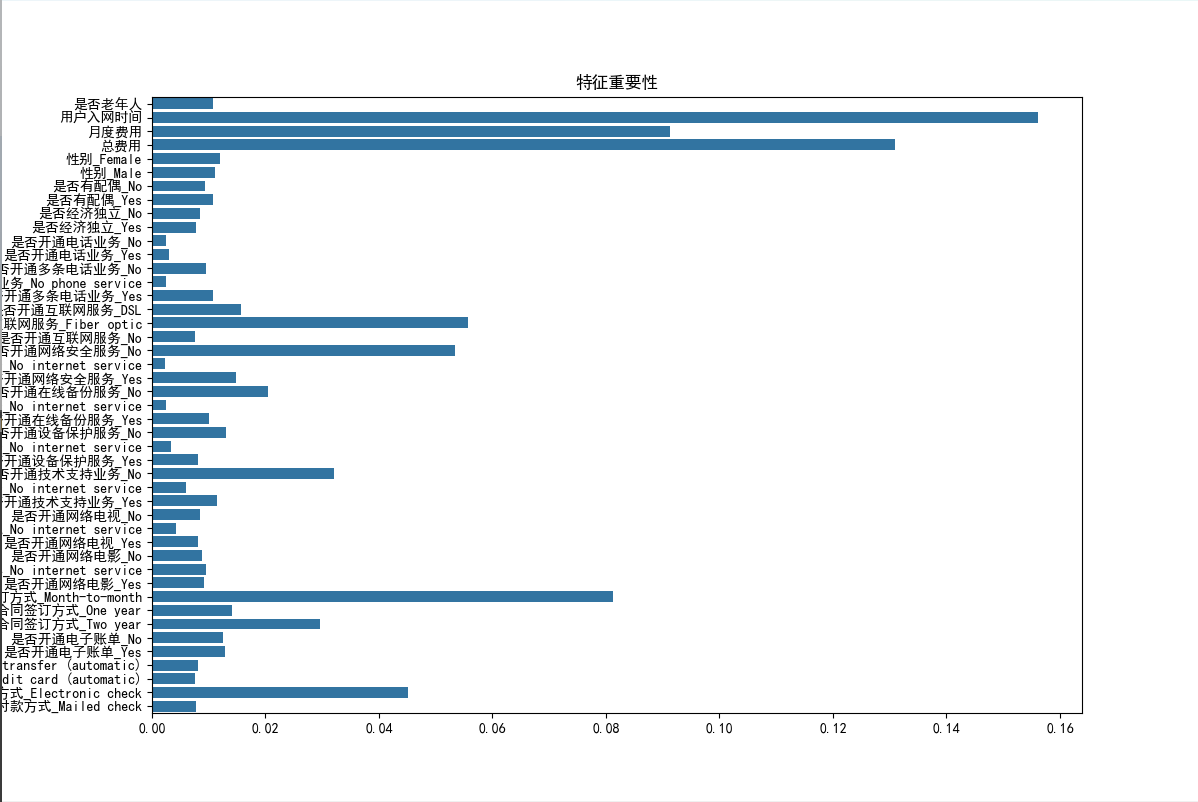
6.3 特征重要性
# 获取特征重要性
feature_importances = best_rf.feature_importances_
feature_names = X.columns# 绘制特征重要性柱状图
plt.figure(figsize=(12, 8))
sns.barplot(x=feature_importances, y=feature_names)
plt.title("特征重要性")
plt.show()
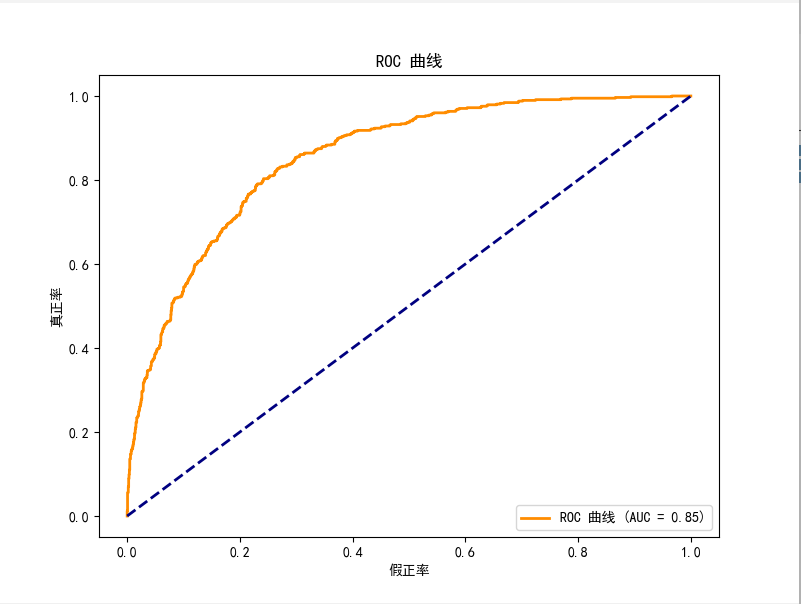
6.4 ROC 曲线与 AUC 值
# 计算 ROC 曲线和 AUC 值
y_prob = best_rf.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)# 绘制 ROC 曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC 曲线 (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel("假正率")
plt.ylabel("真正率")
plt.title("ROC 曲线")
plt.legend(loc="lower right")
plt.show()
七、分析总结与策略建议
7.1 关键发现
- 用户入网时间:入网时间越短,流失率越高。
- 月度费用:月度费用越高,流失率越高。
- 总费用:总费用较低的用户流失率较高。
- 合同类型:按月签约的用户流失率最高,而两年签约的用户流失率最低。
- 付款方式:使用电子支票付款的用户流失率最高,而使用银行转账付款的用户流失率最低。
- 互联网服务类型:未开通互联网服务的用户流失率最高,而开通光纤互联网服务的用户流失率最低。
7.2 策略建议
- 优化合同策略:鼓励用户签订长期合同,如两年合同,以降低流失率。
- 调整费用结构:对于新用户,提供优惠的月度费用和总费用套餐,以吸引他们入网并长期使用。
- 改善付款方式:提供更多的付款方式选择,特别是银行转账和信用卡支付,以提高用户满意度。
- 增强互联网服务:为用户提供高质量的互联网服务,特别是光纤互联网服务,以提高用户忠诚度。
希望这篇文章能帮助你更好地理解和分析电信用户流失数据。如果你有任何问题或建议,欢迎在评论区留言!🎉


)







—享元模式)
)






)
