第一部分:异常检测的核心概念
在深入算法细节之前,理解异常检测的“语境”至关重要。
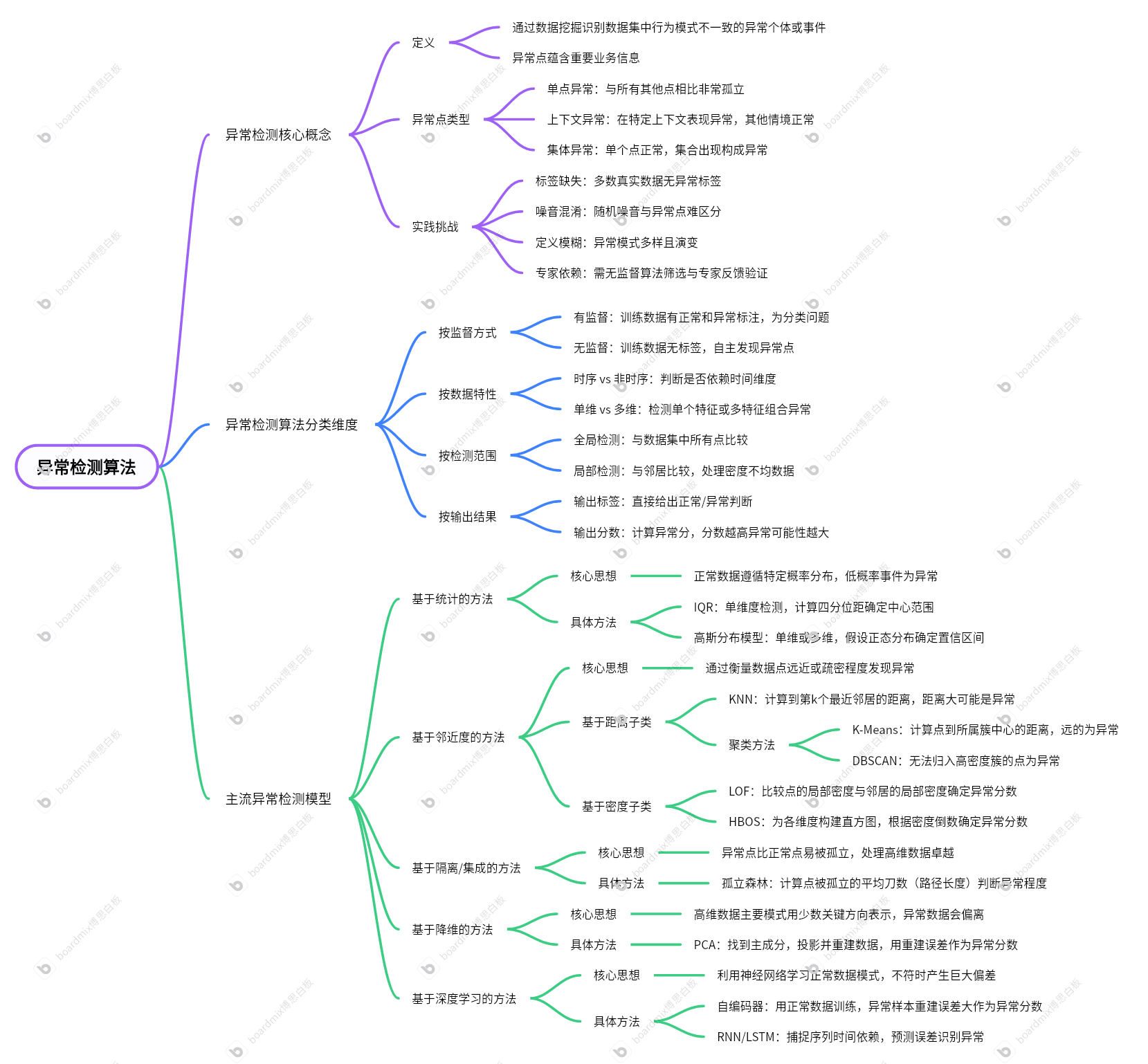
1. 什么是异常检测?
异常检测(Anomaly Detection 或 Outlier Detection)旨在通过数据挖掘技术,识别出数据集中与大多数数据在行为模式上不一致的“异常个体”或“异常事件”。这些异常点通常蕴含着重要的业务信息,如欺诈行为、设备故障或新的商业机会。
2. 异常点的类型
- 单点异常 (Global Outlier):一个数据点与数据集中所有其他点相比都显得非常孤立。例如,在一群小黄人中,突然出现一个海绵宝宝。
- 上下文异常 (Contextual Outlier):一个数据点在特定上下文中表现出异常,但在其他情境下可能完全正常。例如,夏季的某一天气温骤降到10℃,在“夏季”这个上下文中即为异常。
- 集体异常 (Collective Outlier):单个数据点本身不异常,但当一小组数据点集合在一起出现时,则构成了异常。例如,小区里有10户人家在同一天搬家,这个“集体行为”就是异常。
3. 实践中的挑战
- 标签缺失:绝大多数真实场景的数据没有“异常”标签,导致无法直接使用有监督学习。
- 噪音混淆:数据中的随机噪音与有价值的异常点很难区分。
- 定义模糊:异常模式多样且持续演变(如欺诈手段升级),难以给出精确定义。
- 专家依赖:通常需要“无监督算法初步筛选 + 领域专家反馈验证”的闭环模式来持续优化模型。
第二部分:异常检测算法的分类维度
我们可以从不同角度对算法进行归类,这有助于我们根据具体场景选择最合适的工具。
-
按监督方式 (Supervision)
- 有监督:训练数据已明确标注“正常”和“异常”。问题转化为一个(通常是类别不均衡的)分类问题。
- 无监督:训练数据完全没有标签,算法需要自主发现“与众不同”的数据点。这是最常见、也是挑战最大的场景。
-
按数据特性 (Data Characteristics)
- 时序 vs. 非时序:异常的判断是否依赖于时间维度。
- 单维 vs. 多维:是只检测单个特征的异常值,还是在多特征构成的空间中寻找异常组合。
-
按检测范围 (Detection Scope)
- 全局检测:将每个数据点与数据集中的所有其他点进行比较。
- 局部检测:仅将每个数据点与其“邻居”进行比较,更擅长处理密度不均的数据。
-
按输出结果 (Output Result)
- 输出标签:模型直接给出“正常/异常”的判断。
- 输出分数:模型为每个数据点计算一个“异常分”,分数越高代表异常可能性越大,决策更灵活。
第三部分:主流异常检测模型详解
几乎所有现代算法都源于一些经典的核心思想。下面我们按照模型的内在逻辑,对它们进行归类和详细解析。
1. 基于统计的方法 (Statistical-based Methods)
核心思想:正常数据遵循一个特定的概率分布,而低概率事件被视为异常。
-
IQR (Interquartile Range,四分位距)
- 适用场景:单维度异常检测。
- 工作原理:这是一种简单稳健的统计方法。它通过计算数据的上四分位数(Q3)和下四分位数(Q1)的差值(IQR = Q3 - Q1),来定义数据的“中心范围”。任何超出
[Q1 - 1.5*IQR, Q3 + 1.5*IQR]这个“围栏”的数据点都被视为异常。它不需要假设数据分布,非常实用。
-
高斯分布模型 (Gaussian Model)
- 适用场景:单维或多维数据。
- 工作原理:假设正常数据服从高斯(正态)分布。通过计算数据的均值和标准差,我们可以确定一个置信区间(如均值±3倍标准差)。落在该区间之外的数据点因其出现概率极低,被判定为异常。在多维场景下,则使用“多元高斯分布”模型。
2. 基于邻近度的方法 (Proximity-based Methods)
核心思想:通过衡量数据点之间的“远近”或“疏密”程度来发现异常。这类方法在处理低维数据时非常有效。
-
子类:基于距离 (Distance-based)
- KNN (K-Nearest Neighbors):其思想是“物以类聚,离群索居”。对每个点,计算它到其第K个最近邻居的距离。如果这个距离特别大,说明该点处于一个稀疏区域,远离任何种群,因此很可能是异常点。
- 聚类方法 (Clustering-based):
- K-Means:先将数据聚成k个簇,然后计算每个点到其所属簇中心的距离。距离中心非常遥远的点,可以被看作不属于任何一个簇的异常点。
- DBSCAN:这是一个基于密度的聚类算法。它能自动发现高密度区域作为簇。那些无法被归入任何一个高密度簇的点,会被算法直接标记为“噪声(Noise)”,这些噪声点就是我们寻找的异常点。
-
子类:基于密度 (Density-based)
- LOF (Local Outlier Factor, 局部异常因子):这是对纯距离方法的重大改进。它认为,异常的判断应该是“相对”的。LOF不仅看一个点到邻居的距离,更关键的是,它会比较这个点的局部密度与其邻居们的局部密度。如果一个点的密度远低于其周围邻居的密度,它就会被赋予一个很高的异常分数,即使它处于一个整体稀疏的区域。
- HBOS (Histogram-based Outlier Score):这是一种快速的密度估计方法。它为数据的每个维度(特征)单独构建直方图。一个数据点的异常分数由它在各个维度上所落入的直方图“箱子”的高度(即密度)的倒数决定。如果一个点在多个维度上都落在低密度区域,它的总分就会很高。
3. 基于隔离/集成的方法 (Isolation/Ensemble-based Methods)
核心思想:异常点因为“稀少且与众不同”,所以应该比正常点更容易被“孤立”出来。这类方法在处理高维数据时表现卓越。
- 孤立森林 (Isolation Forest)
- 工作原理:想象一下用随机的“刀”(超平面)去切割数据空间。异常点由于处于稀疏地带,往往用很少的几刀就能被完美地从群体中分离出来。而正常的、处于数据簇内部的点,则需要很多刀才能被“孤立”。孤立森林通过计算一个点被孤立所需的平均“刀数”(路径长度)来判断其异常程度。路径越短,异常分数越高。
4. 基于降维的方法 (Dimensionality Reduction-based Methods)
核心思想:高维数据的主要模式可以用少数几个关键方向来表示。正常数据能够很好地遵循这些模式,而异常数据则会偏离。
- PCA (主成分分析)
- 工作原理:PCA能够找到代表数据变化最主要方向的几个“主成分”。我们将所有数据点投影到这些主成分构成的低维空间,然后再将它们“重建”回原始的高维空间。对于正常点,这个过程中的信息损失很小,重建误差(原始点与重建点之间的距离)也很低。而异常点由于不符合数据的主流模式,在降维时会丢失大量个性信息,导致其重建误差非常大。这个重建误差就可以作为其异常分数。
5. 基于深度学习的方法 (Deep Learning-based Methods)
核心思想:利用神经网络强大的非线性拟合能力,学习正常数据的复杂模式。当模型遇到与该模式不符的数据时,会产生巨大偏差。
-
自编码器 (Autoencoder)
- 适用场景:复杂的非时序数据,如图像、用户向量等。
- 工作原理:这是一种自我监督的神经网络。它由一个编码器(压缩数据)和一个解码器(解压并重建数据)组成。我们只用正常数据来训练它,迫使它学会如何完美地重建正常样本。当一个异常样本(如一张它从未见过的图片)输入时,由于模型没有学过它的模式,解码器将无法很好地重建它,导致巨大的重建误差。这个误差值就是异常分数。
-
RNN/LSTM (循环神经网络)
- 适用场景:时序相关数据、序列数据。
- 工作原理:RNN及其变体(如LSTM)擅长捕捉序列中的时间依赖关系。通过在正常的时间序列上进行训练,模型能学习到“下一时刻应该发生什么”。当一个不符合历史规律的事件发生时,模型的预测会与真实值产生巨大差异,这个预测误差就可以用来识别上下文异常或集体异常。
)
![【[CSP-J 2022] 上升点列】](http://pic.xiahunao.cn/【[CSP-J 2022] 上升点列】)



)







动态内存分配与它的指针变量)


SmartWaterServer)


