1、介绍
微服务架构是一种架构模式,它提倡将原本独立的单体应用,拆分成多个小型服务。
这些小型服务各 自独立运行,服务与服务间的通信采用轻量级通信机制(一般基于HTTP协议的RESTful API) ,达到互相协调、互相配合的目的。
被拆分后的服务都围绕着具体的业务进行构建,每个服务都能独立地进 行开发、部署、扩展。
由于相互独立且采用轻量级通信机制,因此各个小型服务能够使用不同的语言开发,也可以使用不同的数据存储技术
2、对比SpringBoot
Spring Boot是用于构建单个Spring应用的框架,而Spring Cloud则是用于构建分布式系统中的微服务架构的工具,Spring Cloud提供了服务注册与发现、负载均衡、断路器、网关等功能。
3、初始架构:单机架构
在淘宝网站最初时,应用数量与用户数都较少,可以把Tomcat和数据库部署在同一台服务器上。 浏览器往www.taobao.com发起请求时,首先经过DNS服务器(域名系统)把域名转换为实际IP地址 10.102.4.1,浏览器转而访问该IP对应的Tomcat。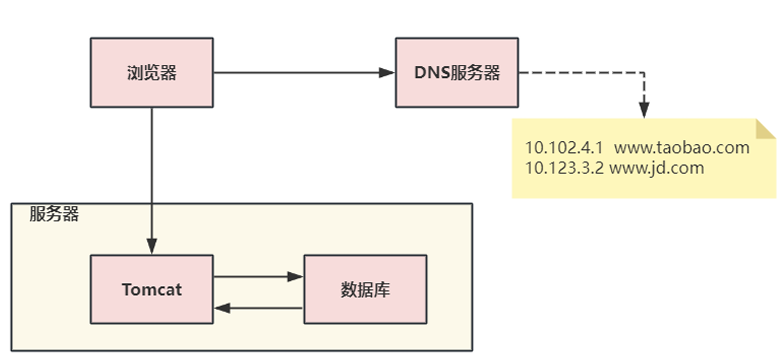
新的技术挑战: 随着用户数的增长,Tomcat和数据库之间竞争资源,单机性能不足以支撑业务,架构演 进势在必行。
4、演进
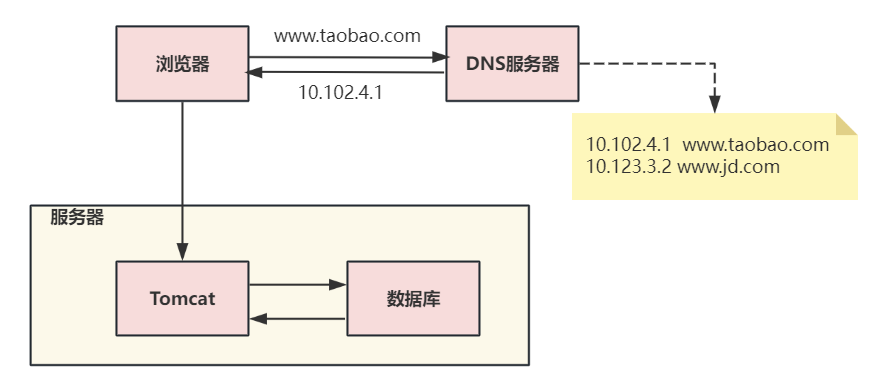
第一次演进:Tomcat与数据库分开部署
将 Tomcat 和数据库分别独占服务器资源,显著提高两者各自性能
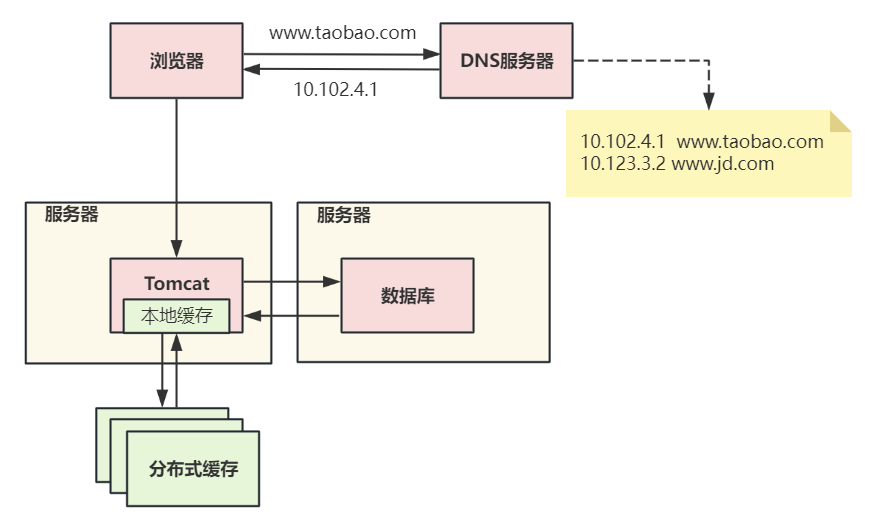
第二次演进:引入本地缓存和分布式缓存
第二次架构演进引入了缓存,在Tomcat服务器上增加本地缓存,并在外部增加分布式缓存,缓存热门商品信息或热门商品的html页面等。
通过缓存能把绝大多数请求在读写数据库前拦截掉,大大降低数据库压力。其中涉及的技术包括:使用memcached作为本地缓存,使用Redis作为分布式缓存,还会涉及缓存一致性、缓存穿透/击穿、缓存雪崩、热点数据集中失效等问题。
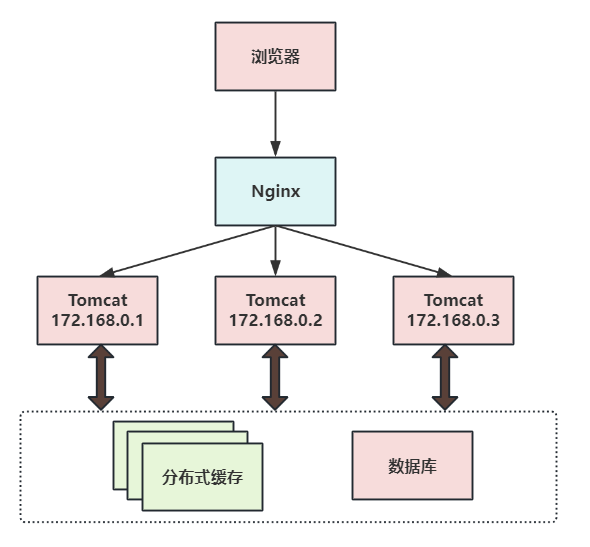
第三次演进:引入反向代理实现负载均衡
在多台服务器上分别部署Tomcat,使用反向代理软件(Nginx)把请求均匀分发到每个Tomcat中。此处假设Tomcat最多支持100个并发,Nginx最多支持50000个并发,那么理论上Nginx把请求分发到500个Tomcat上,就能抗住50000个并发。
在多台服务器上分别部署Tomcat,使用反向代理软件(Nginx)把请求均匀分发到每个Tomcat中。此处假设Tomcat最多支持100个并发,Nginx最多支持50000个并发,那么理论上Nginx把请求分发到500个Tomcat上,就能抗住50000个并发。
第四次演进:数据库读写分离
把数据库划分为读库和写库,读库可以有多个,通过同步机制把写库的数据同步到读库。对于需要查询最新写入数据场景,可通过在缓存中多写一份,通过缓存获得最新数据。
其中涉及的技术包括:Mycat,它是数据库中间件,可通过它来组织数据库的分离读写和分库分表,客户端通过它来访问下层数据库,还会涉及数据同步,数据一致性的问题。
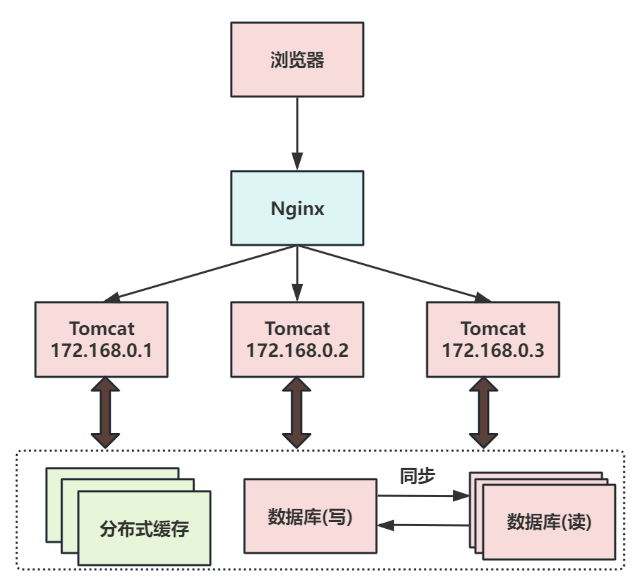
第五次演进:数据库按业务分库
数据库按业务分库,把不同业务的数据保存到不同的数据库中,使业务之间的资源竞争降低,对于访问量大的业务,可以部署更多的服务器来支撑。
这样同时会导致跨业务的表无法直接做关联分析,需要通过其他途径来解决。
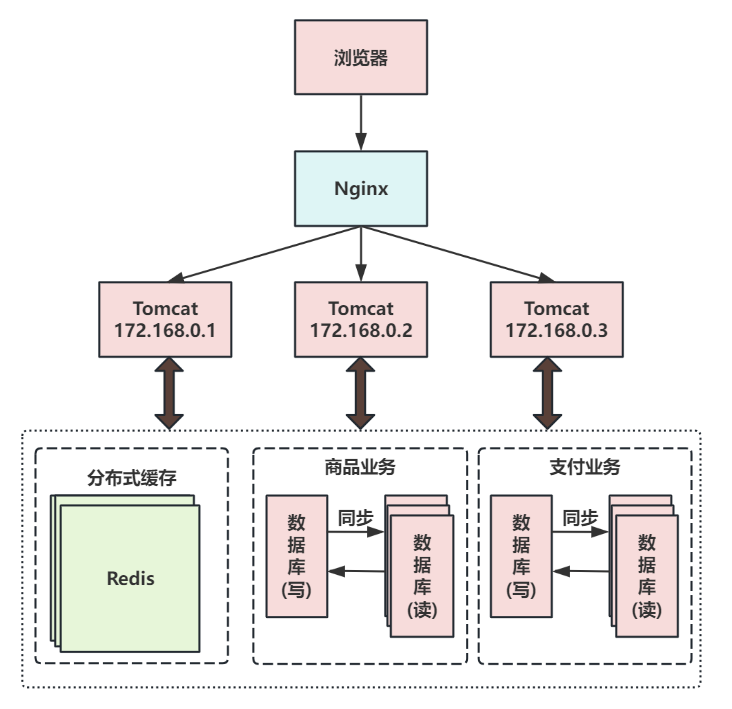
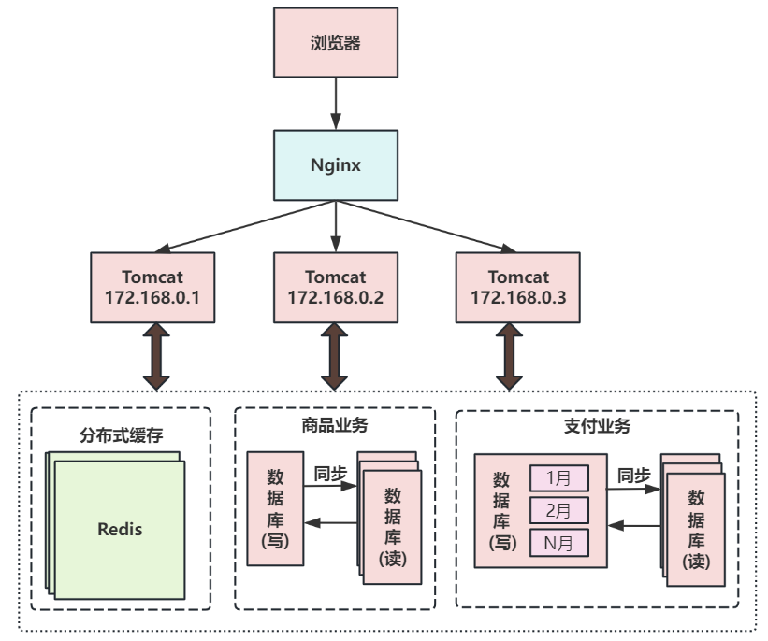
第六次演进:把大表拆分为小表
比如针对评论数据,可按照商品ID进行hash,路由到对应的表中存储。
针对支付记录,可按照小时创建表,每个小时表继续拆分为小表,使用用户ID或记录编号来路由数据。
只要实时操作的表数据量足够小,请求能够足够均匀的分发到多台服务器上的小表,那数据库就能通过水平扩展的方式来提高性能。其中前面提到的Mycat也支持在大表拆分为小表情况下的访问控制。
这种做法显著的增加了数据库运维的难度,对DBA的要求较高。数据库设计到这种结构时,已经可以称为分布式数据库。
第七次演进:使用LVS或F5来使多个Nginx负载均衡
由于瓶颈在Nginx,因此无法通过两层的Nginx来实现多个Nginx的负载均衡。LVS和F5是工作在网络第四层的负载均衡解决方案,其中LVS是软件,运行在操作系统内核态,可对TCP请求或更高层级的网络协议进行转发,因此支持的协议更丰富,并且性能也远高于Nginx,可假设单机的LVS可支持几十万个并发的请求转发。
F5是一种负载均衡硬件,与LVS提供的能力类似,性能比LVS更高,但价格昂贵。
由于LVS是单机版的软件,若LVS所在服务器宕机则会导致整个后端系统都无法访问,因此需要有备用节点。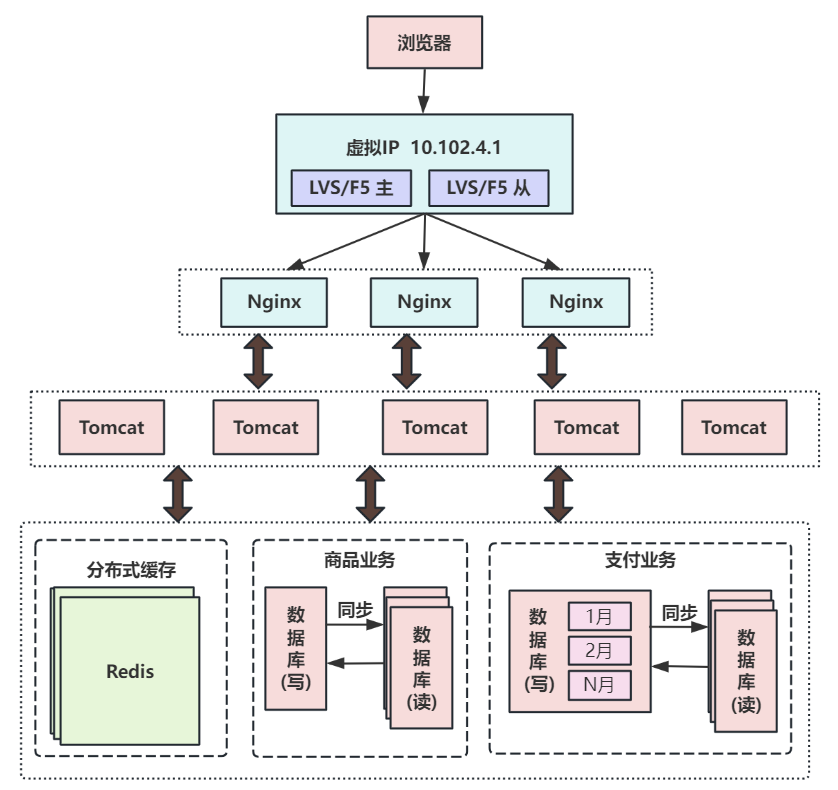
第八次演进:通过DNS轮询实现机房间的负载均衡
在DNS服务器中可配置一个域名对应多个IP地址,每个IP地址对应到不同的机房里的虚拟IP。
当用户访问www.taobao.com时,DNS服务器会使用轮询策略或其他策略,来选择某个IP供用户访问。此方式能实现机房间的负载均衡
至此,系统可做到机房级别的水平扩展,千万级到亿级的并发量都可通过增加机房来解决,系统入口处的请求并发量不再是问题。
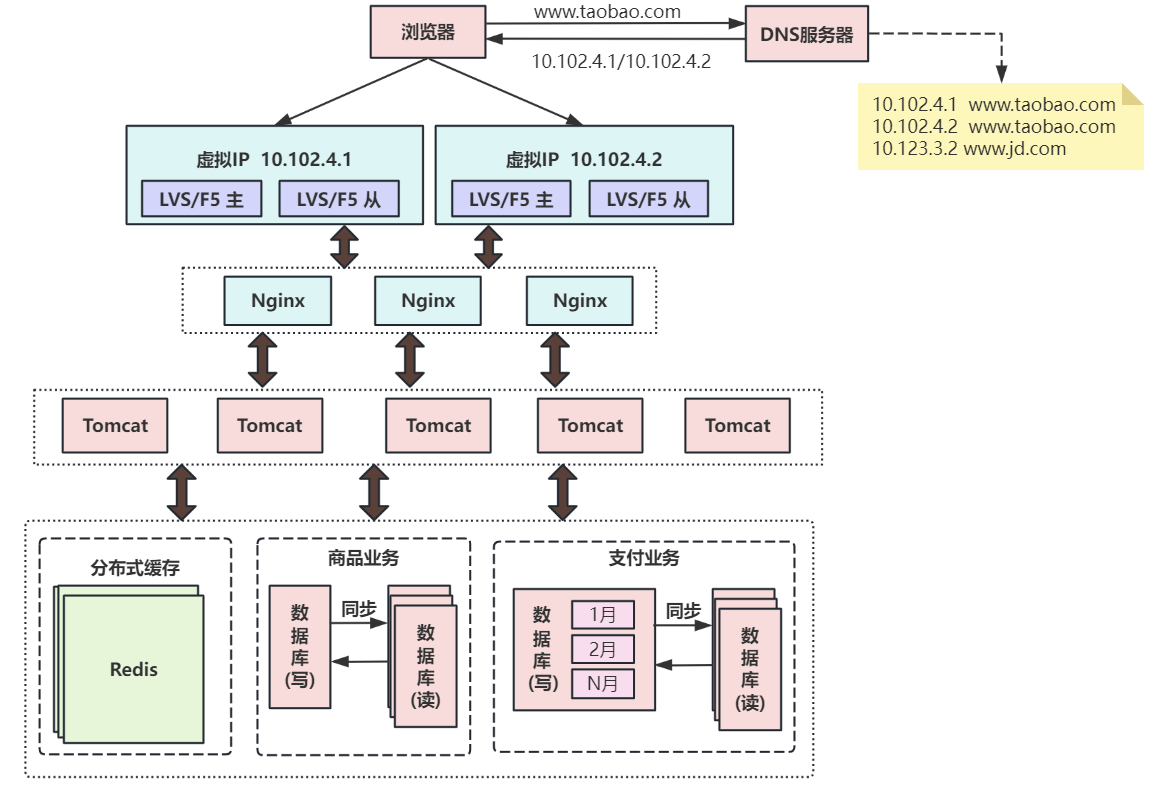
第九次演进:引入NoSQL数据库和搜索引擎等技术
当数据库中的数据多到一定规模时,数据库就不适用于复杂的查询了,往往只能满足普通查询的场景。
对于统计报表场景,在数据量大时不一定能跑出结果,而且在跑复杂查询时会导致其他查询变慢。
对于全文检索、可变数据结构等场景,数据库天生不适用。因此需要针对特定的场景,引入合适的解决方案。
如对于海量文件存储,可通过分布式文件系统HDFS解决,对于key value类型的数据,可通过Redis解决,对于全文检索场景,可通过搜索引擎如ElasticSearch解决,对于多维分析场景,可通过Kylin或Druid等方案解决。
当然,引入更多组件同时会提高系统的复杂度,不同的组件保存的数据需要同步,需要考虑一致性的问题,需要有更多的运维手段来管理这些组件等。
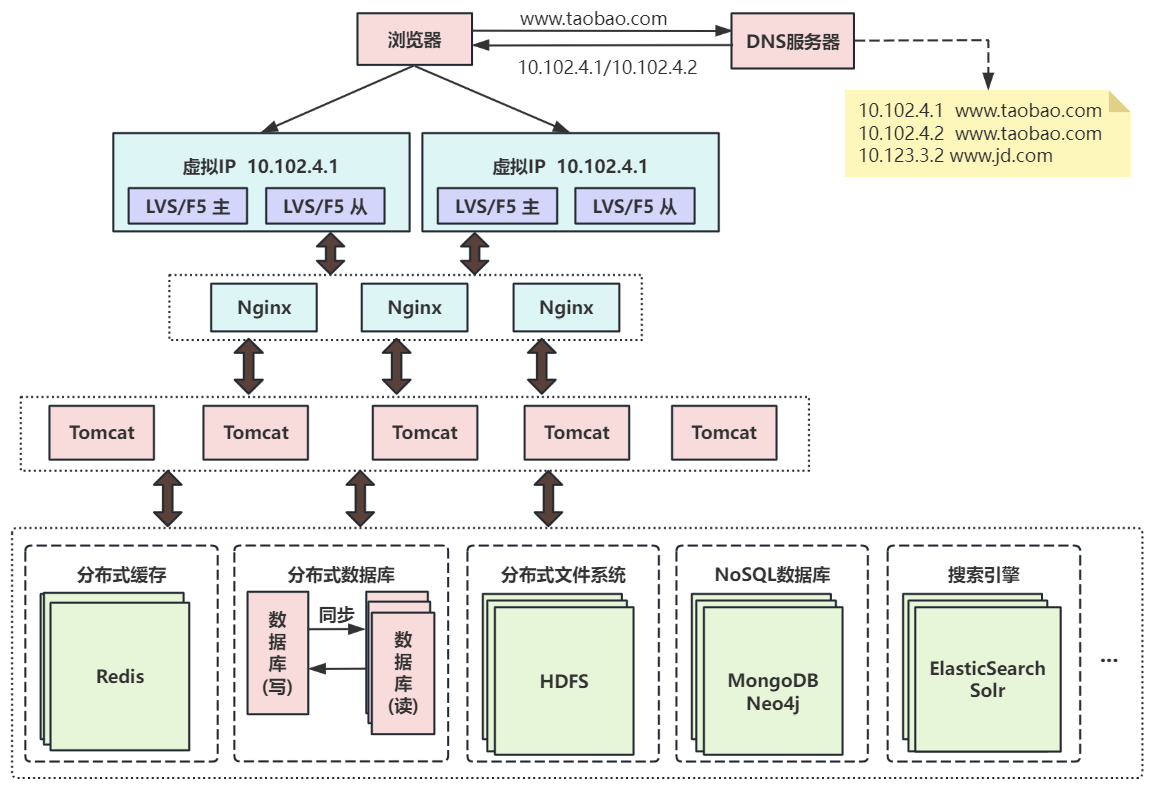
第十次演进:大应用拆分为小应用
为了应对日益复杂的业务场景,通过使用分而治之的手段将整个网站业务拆分成不同的产品线,通过分布式服务来协同工作。
按照业务板块来划分应用代码,使单个应用的职责更清晰,相互之间可以做到独立升级迭代。这时候应用之间可能会涉及到一些公共配置,可以通过分布式配置中心Zookeeper来解决。
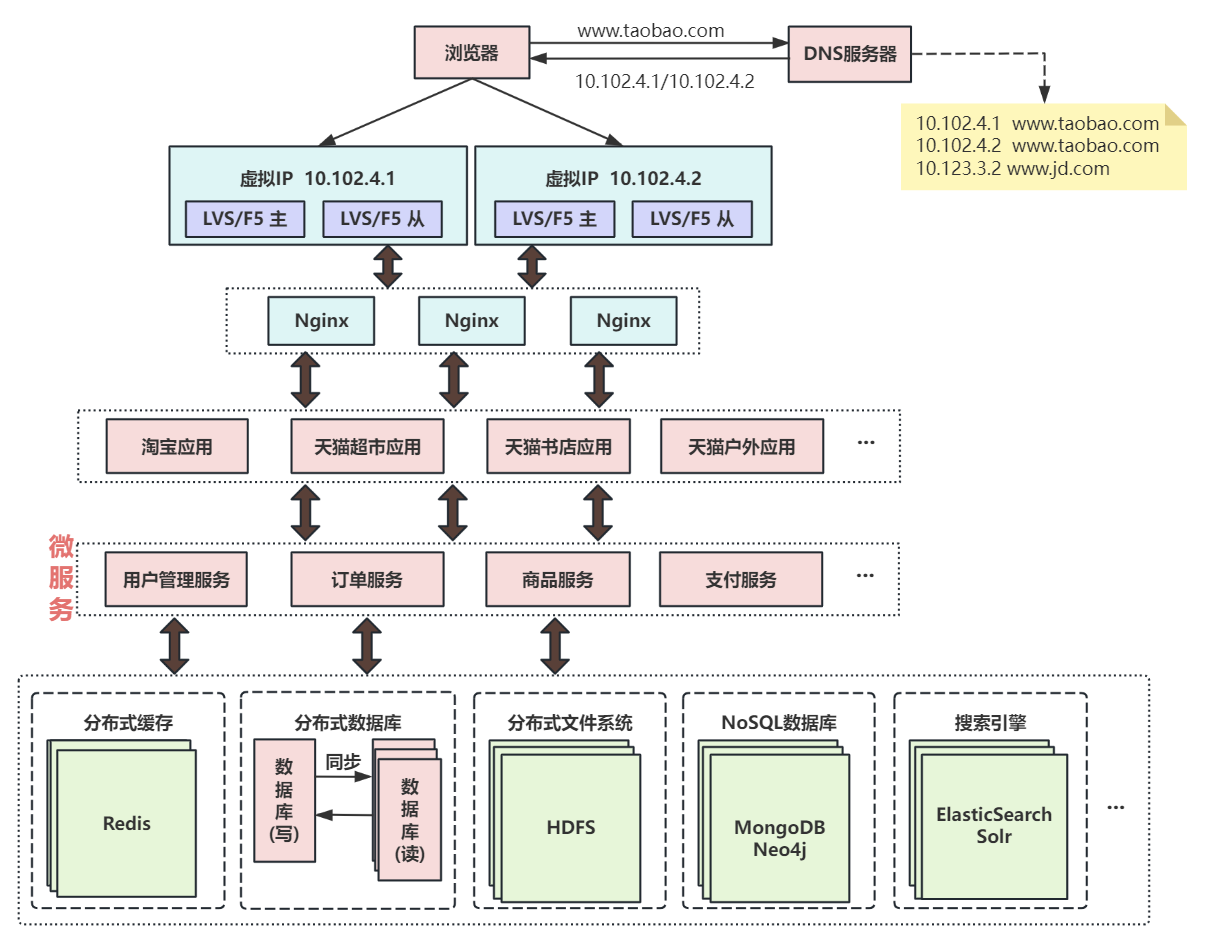
第十一次演进:复用的功能抽离成微服务
如用户管理、订单、支付、鉴权等功能在多个应用中都存在,那么可以把这些功能的代码单独抽取出来形成一个单独的服务来管理,这样的服务就是所谓的微服务。应用通过HTTP、TCP或RPC请求等多种方式来访问服务,每个单独的服务都可以由单独的团队来管理。
此外,可以通过Dubbo、SpringCloud等框架实现服务治理、限流、熔断、降级等功能,提高服务的稳定性和可用性。
5、微服务架构的优缺点
1、优点
更易于开发和维护
快速迭代+灵活
系统的伸缩性增强
技术选型灵活
错误隔离
2、缺点
落地一个微服务架构项目比较复杂
服务依赖和调用链路更复杂
微服务架构中的单个微服务,不可避免地会出现依赖性及由此导致的问题。比如,H服务依赖S服务,S服务依赖A服务,如果A服务在线上出现问题或A服务需要修改部分逻辑,那么S服务和H服务也可能受到牵连,或者级联修改。虽然已经做了服务拆分,影响范围不大,但是这些问题还是存在的。
数据一致性问题
问题排查的链路加长
学习成本高





)










)


