
目录
KV算子
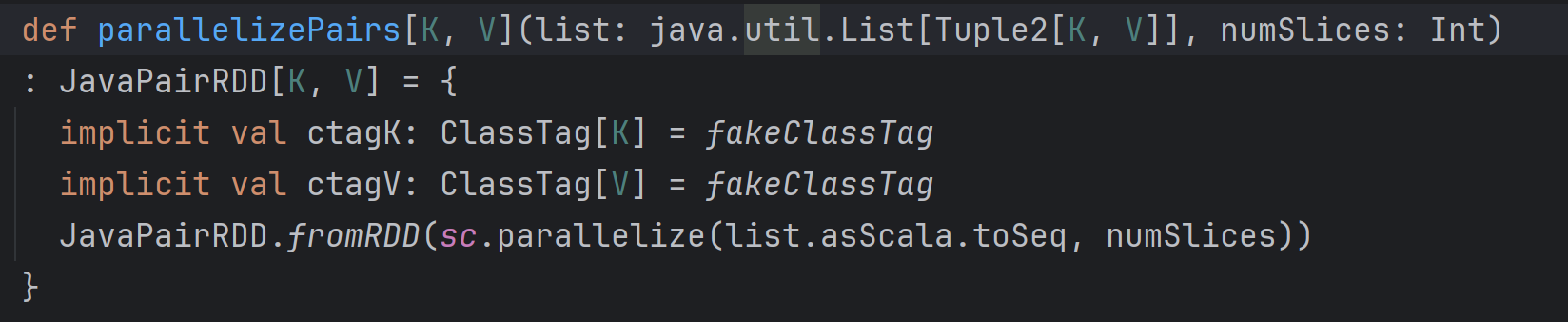
parallelizePairs
mapToPair
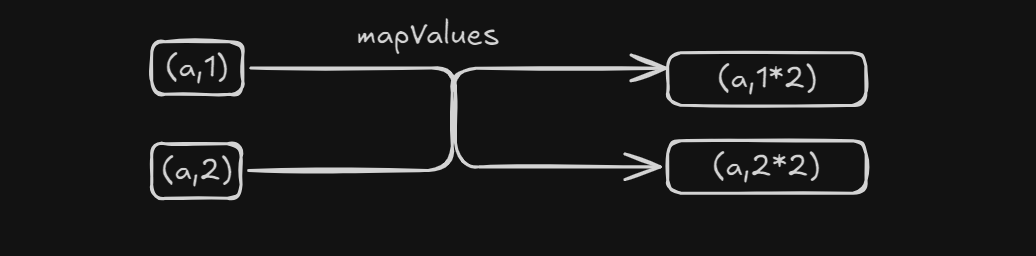
mapValues
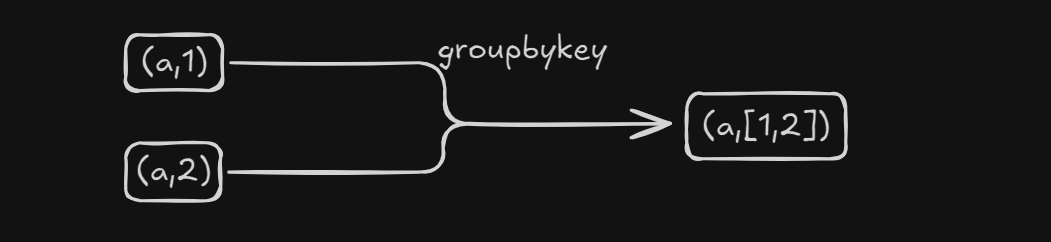
groupByKey
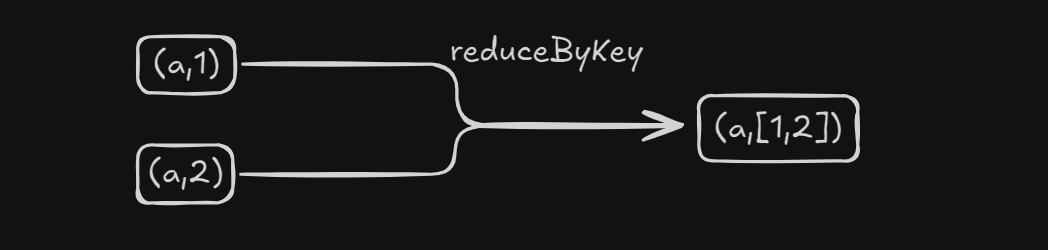
reduceByKey
sortByKey
算子应用理解
reduceByKey和groupByKey的区别
groupByKey+mapValues实现KV数据的V的操作
改进用reduceByKey
groupby通过K和通过V分组的模板代码
问题集锦
宝贵的经验
这里会讲到之前还未讲到过的KV算子。我们之前的操作都是单值操作,这一篇我们会着重讲到KV操作、行动算子和持久化等知识。
KV算子
作用:操作KV流数据,能够分别操作K和V
出现JavaPairRDD就表示出现了成对KV数据流
parallelizePairs
作用:封装Tuple2集合形成RDD
细节源码如下
mapToPair
作用:配合parallelizePairs方法将
1.单值数据转化成KV对数据
2.Tuple元组整体转化成KV键值对形式
两者一起的代码JavaPairRDD<String, Integer> JRD = sc.parallelizePairs(Arrays.asList(a, a1, a2, a3));JRD.mapToPair( tuple -> new Tuple2<>(tuple._1, tuple._2*2)).collect().forEach(System.out::println);
mapValues
作用:K不变,操作KV流中的V,并且只要类型是JavaPairRDD就可以用此方法
示意图
代码实现List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);sc.parallelize(list).mapToPair(integer -> new Tuple2<Integer,Integer>(integer, integer * 2)).mapValues(int1 -> int1 * 2).collect().forEach(System.out::println);这里配合一个wordcount案例加深一下理解
思考链条:
读取文件textFile --> flatmap扁平化流数据(String[] -> String)->groupby分组 ->mapValues按照V来计算
代码//TODO 写一个wordcountJavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));JavaRDD<String> rdd = javaSparkContext.textFile("E:\\ideaProjects\\spark_project\\data\\wordcount");rdd.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String s) throws Exception {return Arrays.asList(s.split(" ")).iterator();}}).groupBy(n -> n).mapValues(iter -> {int sum = 0;for (String word : iter) {sum++;}return sum;}).collect().forEach(System.out::println);javaSparkContext.close();所以,整个转换过程是:
- 输入:一行字符串(`String`)
- 用`split`方法:将该行字符串分割成字符串数组(`String[]`)
- 用`Arrays.asList`:将字符串数组转换为字符串列表(`List<String>`)
- 调用列表的`iterator`方法:得到字符串的迭代器(`Iterator<String>`)
- 在`flatMap`中,Spark会遍历这个迭代器,将每个字符串(单词)作为新元素放入结果RDD。flatmap本质:都是将数组转换成一个可以逐个访问其元素的迭代器

groupByKey
作用:将KV对按照K对V进行分组
代码实现
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));Tuple2<String, Integer> a = new Tuple2<>("a", 1);Tuple2<String, Integer> b = new Tuple2<>("b", 2);Tuple2<String, Integer> c = new Tuple2<>("a", 3);Tuple2<String, Integer> d = new Tuple2<>("b", 4);javaSparkContext.parallelizePairs(Arrays.asList(a, b, c, d)).collect().forEach(System.out::println);System.out.println();javaSparkContext.parallelizePairs(Arrays.asList(a, b, c, d)).groupByKey(3).collect().forEach(System.out::println);reduceByKey
作用:在KV对中,按照K对V进行聚合操作,(底层会在分区内进行预聚合优化)
代码实现
对二元组进行按照K对V相加的聚合操作
javaSparkContext.parallelizePairs(tuple2s).reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1 + v2;}}).collect().forEach(System.out::println);sortByKey
作用:按照K进行XXX的升序/降序排列
代码实现JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));Tuple2<String, Integer> aa0 = new Tuple2<>("a", 4);Tuple2<String, Integer> aa1 = new Tuple2<>("a", 1);Tuple2<String, Integer> aa2 = new Tuple2<>("a", 2);Tuple2<String, Integer> bb1 = new Tuple2<>("b", 2);Tuple2<String, Integer> aa3 = new Tuple2<>("a", 3);Tuple2<String, Integer> bb2 = new Tuple2<>("b", 1);ArrayList<Tuple2<String, Integer>> tuple2s = new ArrayList<>(Arrays.asList(aa0,aa1, aa2, aa3, bb1, bb2));javaSparkContext.parallelizePairs(tuple2s).sortByKey().collect().forEach(System.out::println);javaSparkContext.close();传入参数为false时
Comparable接口的使用
利用自定义类型进行排序操作JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));Artist at1 = new Artist("小王", 100);Artist at2 = new Artist("小李", 1000);Artist at3 = new Artist("小赵", 10000);Artist at4 = new Artist("小宇", 100000);Tuple2<Artist, Integer> artistIntegerTuple2 = new Tuple2<>(at1, 1);Tuple2<Artist, Integer> artistIntegerTuple3 = new Tuple2<>(at2, 2);Tuple2<Artist, Integer> artistIntegerTuple4 = new Tuple2<>(at3, 3);Tuple2<Artist, Integer> artistIntegerTuple5 = new Tuple2<>(at4, 4);JavaPairRDD<Artist, Integer> artistIntegerJavaPairRDD = javaSparkContext.parallelize(Arrays.asList(artistIntegerTuple2, artistIntegerTuple3, artistIntegerTuple4, artistIntegerTuple5)).mapToPair(t -> t);artistIntegerJavaPairRDD.sortByKey().collect().forEach(System.out::println);javaSparkContext.close();class Artist implements Serializable, Comparable<Artist> {String name;int salary;public Artist(String name, int salary) {this.name = name;this.salary = salary;}@Overridepublic int compareTo(Artist o) {return o.salary - this.salary;}@Overridepublic String toString() {return "Artist{" +"name='" + name + '\'' +", salary=" + salary +'}';} }coalesce
作用:缩减分区,不会自动进行shuffle
示意图
代码实现List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);javaSparkContext.parallelize(tuple2s).coalesce(2).collect().forEach(System.out::println);javaSparkContext.close();
repartition
作用:调整分区数,等价于coalesce的shuffle=true时
示意图
代码实现
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);javaSparkContext.parallelize(tuple2s).repartition(2).saveAsTextFile("out2");javaSparkContext.close();


算子应用理解
reduceByKey和groupByKey的区别
性能更高:在shuffle之前有一个预聚合的功能Combine,可以将分区中的小文件合并,减少shuffle落盘的数据量
因此在实际开发中
groupByKey+mapValues实现KV数据的V的操作
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));Tuple2<String, Integer> a = new Tuple2<>("a", 1);Tuple2<String, Integer> b = new Tuple2<>("b", 2);Tuple2<String, Integer> c = new Tuple2<>("a", 3);Tuple2<String, Integer> d = new Tuple2<>("b", 4);System.out.println();javaSparkContext.parallelizePairs(Arrays.asList(a, b, c, d)).groupByKey(3).mapValues(new Function<Iterable<Integer>, Integer>() {@Overridepublic Integer call(Iterable<Integer> v1) throws Exception {int sum = 0;for (Integer v2 : v1) {sum += v2;}return sum;}}).collect().forEach(System.out::println);javaSparkContext.close();改进用reduceByKey
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));Tuple2<String, Integer> a = new Tuple2<>("a", 1);Tuple2<String, Integer> b = new Tuple2<>("b", 1);Tuple2<String, Integer> c = new Tuple2<>("a", 2);Tuple2<String, Integer> d = new Tuple2<>("b", 2);ArrayList<Tuple2<String, Integer>> tuple2s = new ArrayList<>(Arrays.asList(a, b, c, d)); javaSparkContext.parallelizePairs(tuple2s).reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1 + v2;}}).collect().forEach(System.out::println);javaSparkContext.close();groupby通过K和通过V分组的模板代码
JavaSparkContext javaSparkContext = new JavaSparkContext(new SparkConf().setMaster("local[*]").setAppName("artical4"));Tuple2<String, Integer> a = new Tuple2<>("a", 1);Tuple2<String, Integer> b = new Tuple2<>("b", 1);Tuple2<String, Integer> c = new Tuple2<>("a", 2);Tuple2<String, Integer> d = new Tuple2<>("b", 2);System.out.println();javaSparkContext.parallelizePairs(Arrays.asList(a, b, c, d)).groupBy(new Function<Tuple2<String, Integer>, Integer>() {@Overridepublic Integer call(Tuple2<String, Integer> v1) throws Exception {return v1._2(); //通过Values分组 将2改为1就是通过K分组}}).collect().forEach(System.out::println);javaSparkContext.close();数据转换图

问题集锦
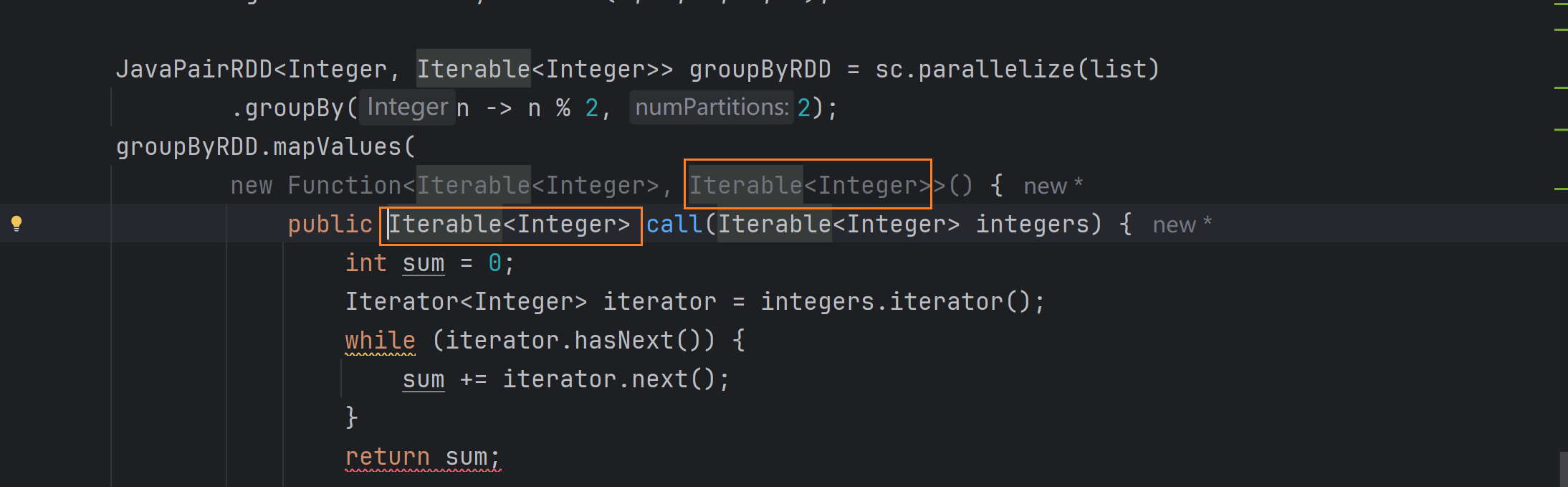
1.iterator迭代器怎么迭代,它在mapValues方法中的传出类型是iterator类型,并且在将Lambda和匿名内部类互转的时候注意传出泛型即可。(其中封装了两种迭代方法)
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);JavaPairRDD<Integer, Iterable<Integer>> groupByRDD = sc.parallelize(list).groupBy(n -> n % 2, 2);groupByRDD.mapValues(new Function<Iterable<Integer>, Integer>() {public Integer call(Iterable<Integer> integers) {int sum = 0;Iterator<Integer> iterator = integers.iterator();while (iterator.hasNext()) {sum += iterator.next();}return sum;
// int sum = 0;
// for (Integer i : integers) {
// sum += i;
// }
// return sum;}}).collect().forEach(System.out::println);宝贵的经验
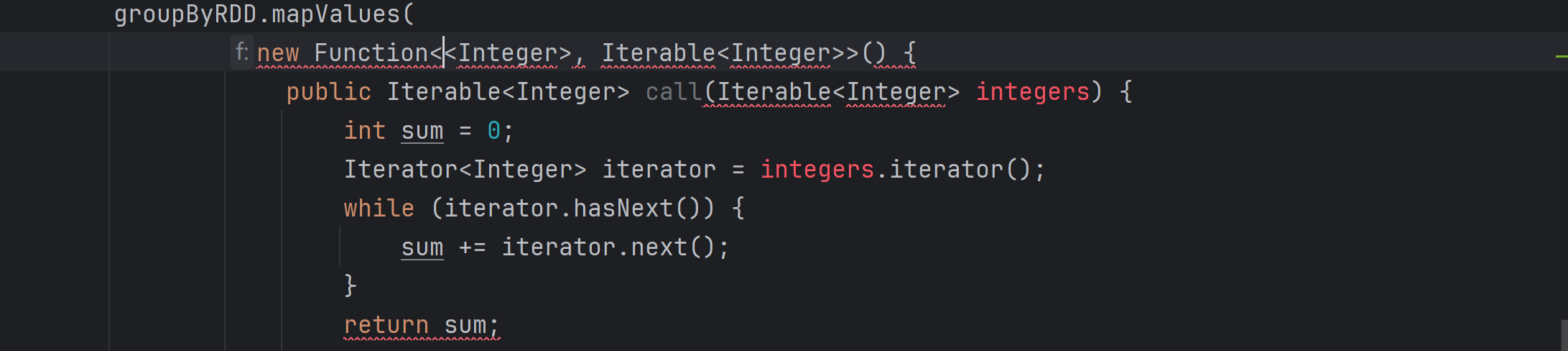
1.function函数传入泛型不能修改,但是传出泛型可以修改
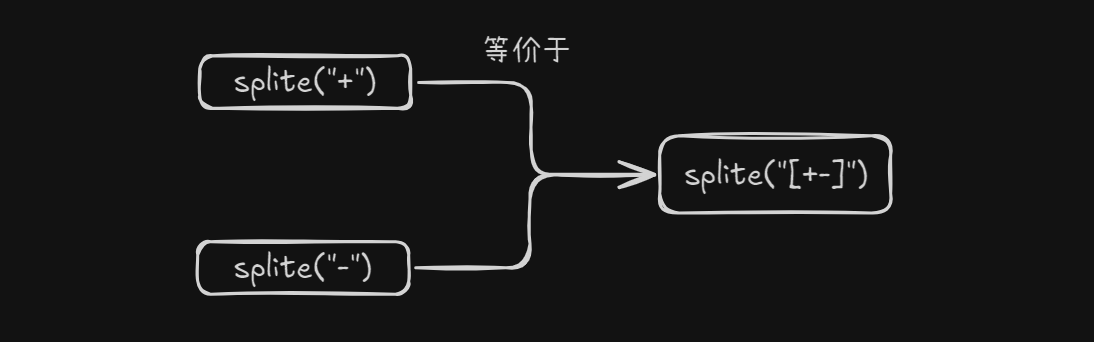
2.正则表达式可以通过中括号将多次分割的逻辑封装到一行代码中
3.RDD采用了和javaIO一样的设计模式-装饰者设计模式,将对象嵌套实现功能



)


:vi/vim)






:PWM(脉冲宽度调制))
)






