主页:ComfyUI | 用AI生成视频、图像、音频
https://github.com/comfyanonymous/ComfyUI
安装环境
我的环境是mac,芯片为M4pro。首先从github中下载工程,clone失败就直接下载zip压缩包。在model文件夹中,可以看到很多大名鼎鼎的模型,如lora,controlnet。
其中一个依赖环境是av,PyAV 是一个强大的库,用于处理视频和音频流(基于 FFmpeg)。PyAV 依赖 FFmpeg,如果系统未安装 FFmpeg,可能会报错。Conda 会自动处理 FFmpeg 依赖
conda install -c conda-forge avOMP: Error #15: Initializing libomp.dylib, but found libomp.dylib already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program.使用命令:find / -name "libomp.dylib" 2>/dev/null
发现虚拟环境下有很多个:
I/lib/libomp.dylib/anaconda3/envs/comfUI/lib/python3.12/site-packages/torch/lib/libomp.dylib/anaconda3/envs/comfUI/lib/python3.12/site-packages/skimage/.dylibs/libomp.dylib但是更改环境变量也没解决;
import os
os.environ['DYLD_LIBRARY_PATH'] = f"{os.environ['CONDA_PREFIX']}/lib"最终是靠conda重新安装torch解决。
conda uninstall numpy scipy mkl torch # 卸载可能依赖 MKL 的包
conda install numpy scipy mkl torch # 重新安装(conda 会自动处理依赖)requirements.txt中的comfyui-frontend-package则需要pip安装
下载模型
打开网页就可以看到一个可视化的工作流。工作流有一些模板可以浏览。
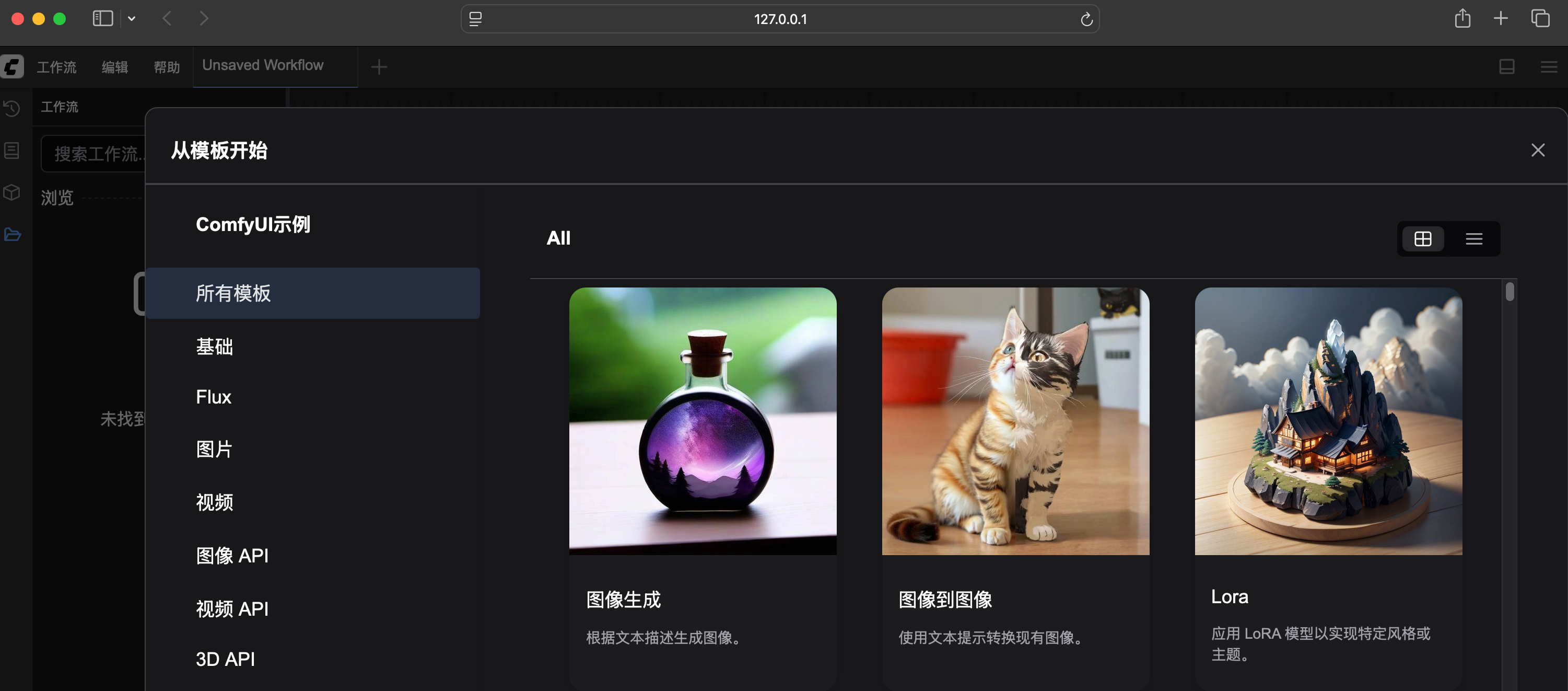
这几个模板其实就是一些jpg,只不过在图片的metadata里面保存了真正决定workflow的JSON。
点击Lora会加载工作流,刚开始会弹出提示框,缺少模型,不过没关系,可以点击下载就好了:
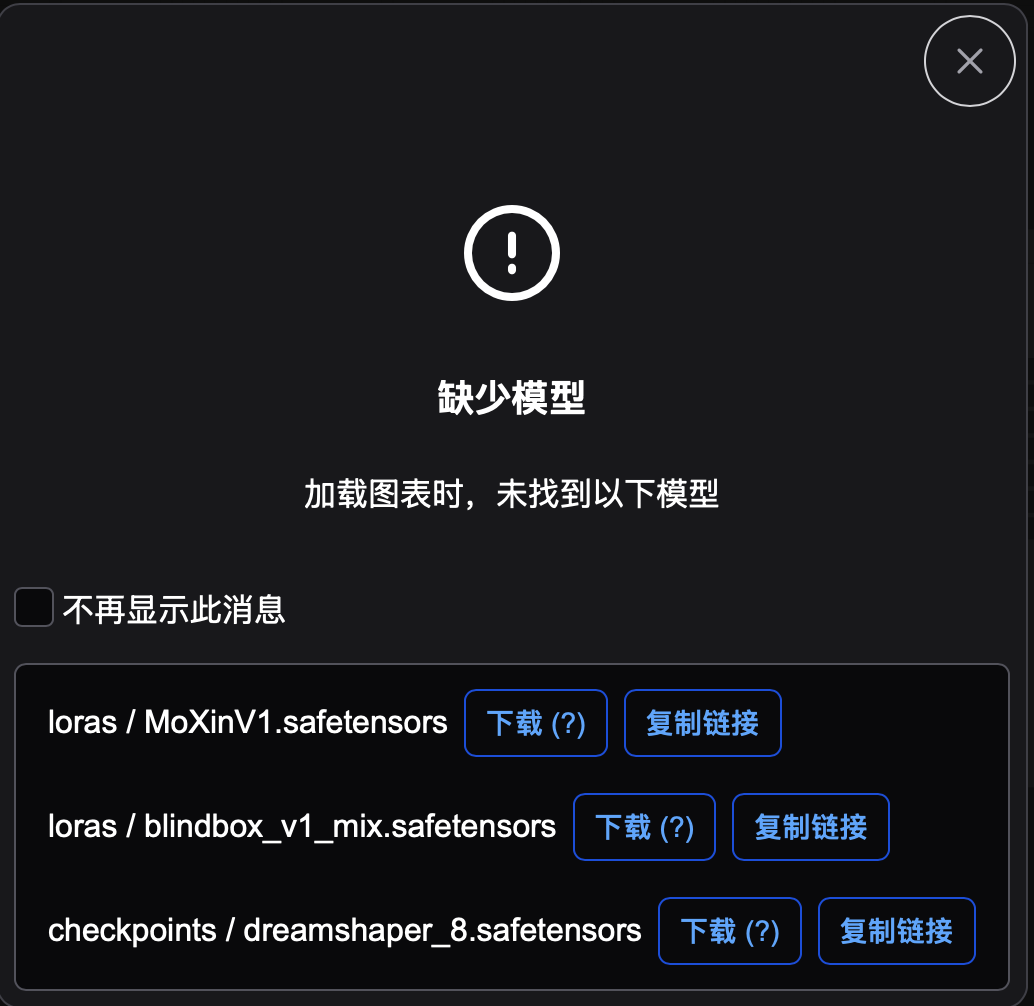
下载需要科学上网。三个模型都以safetensors结尾。下载好的 dreamshaper_8.safetensors and 放到ComfyUI/models/checkpoints下, blindbox_V1Mix and MoXinV1放到ComfyUI/models/loras文件夹下。dreamshaper是stable diffusion的checkpoint model,是很大的模型,所以看大小有2.13GB,而Lora只有151.1MB。
可以看到这个工作流同时使用了两个Lora,模板自带的notes解释了为什么需要两个lora:blindbox_V1Mix and MoXinV1,因为这样可以得到更balance的结果:
| blindbox_V1Mix and MoXinV1. | blend | |
 |  |
大模型除了dreamshaper,还有Stable diffusion v1.4,Stable diffusion v1.5,Realistic Vision,majicMIX realistic,Deliberate v2,F222等。dreamshaper生成的是近似于AnythingV5(属于SDXL模型)的漫画和majicMIX realistic逼真之间的形象:

启动
模型准备好之后就可以运行了,会比较慢,网页的标签页上会显示进度。
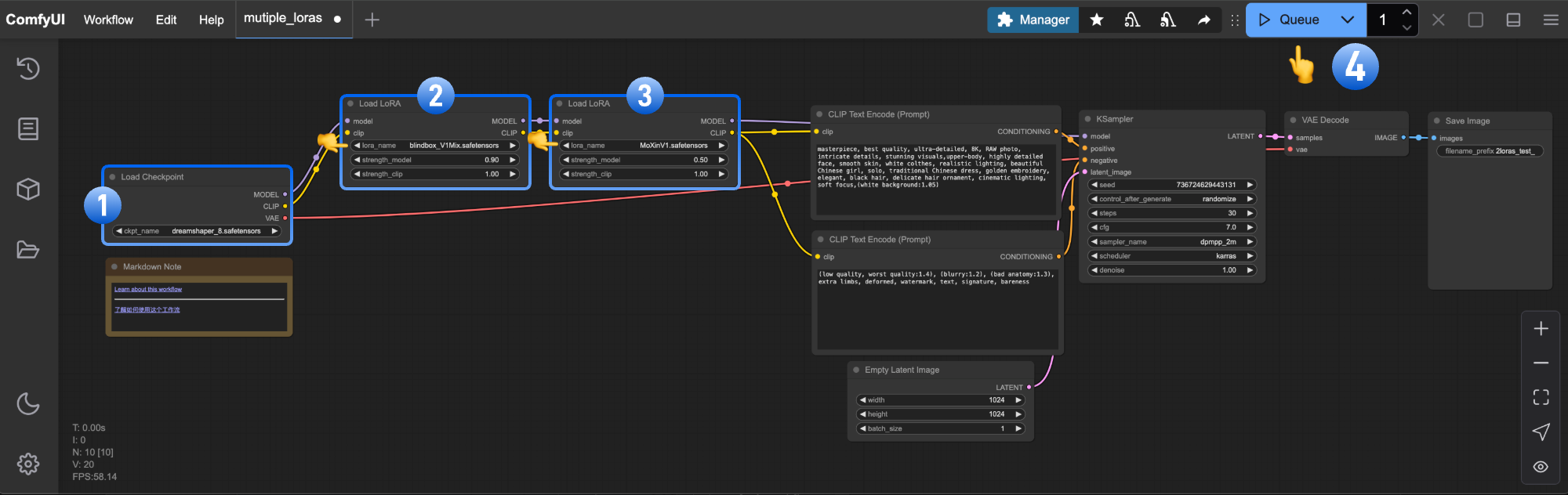
这是我生成的一幅图:

对应的提示词是:
upperbody shot, 1girl,solo,chibi,long hairs, happy, laugh, hugging a teddy bear, looking at viewers, dancing stand, cute, soft color, flowers in background, many flowers, among flowers, best quality, highres, delicate details,
上半身特写,一位女孩,单人,Q版(或“迷你角色”/“简笔画风格可爱小人”,根据“chibi”具体语境调整),长发,面带笑容,开怀大笑,抱着泰迪熊,注视着观众,舞姿站立,可爱,柔和色调,背景有花朵,繁花似锦,置身花丛,最佳画质,高分辨率,细节精致
对比之下,生成的数目不对,手里的也不是泰迪熊。
除了正向的提示词,还有负向的:
(worst quality, low quality:1.4), (bad anatomy), text, error, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry, deformed face在提示词之外,还可以控制图像尺寸,采样器,步数等参数:
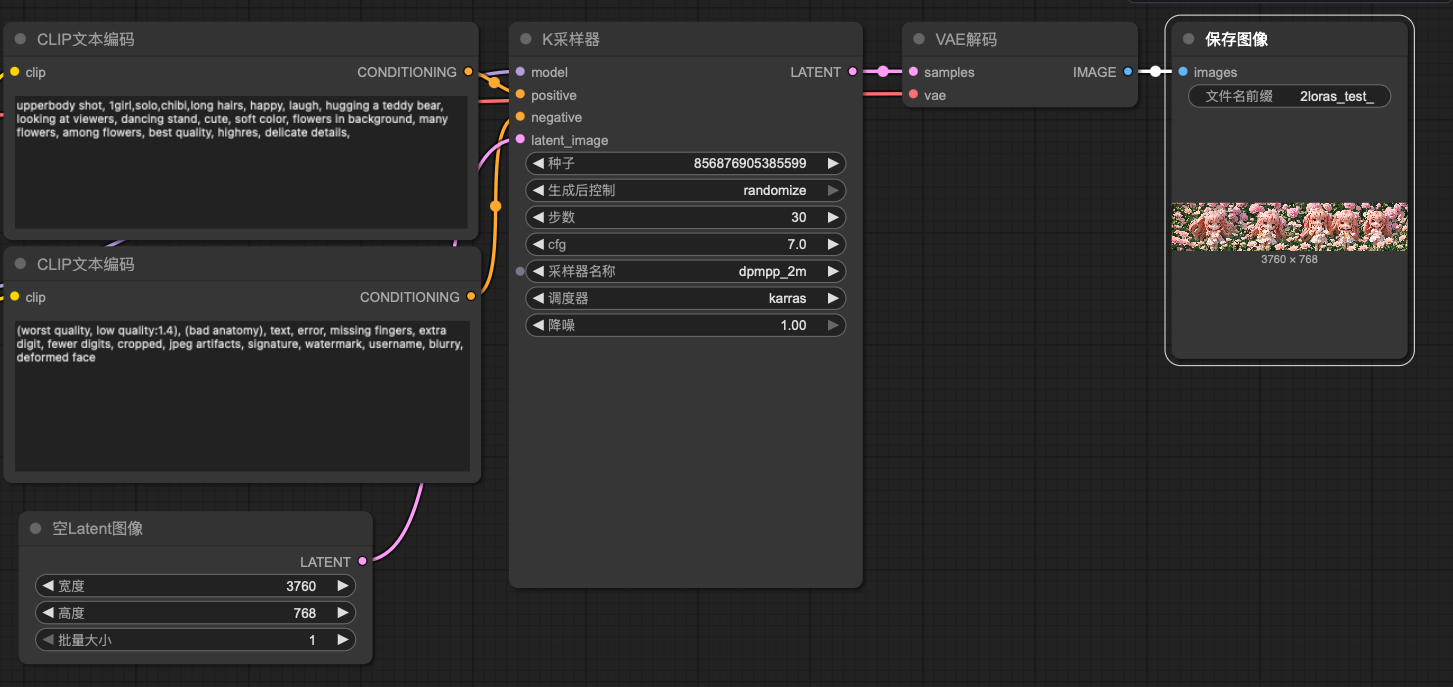
reference:
1.怎么使用Stable diffusion中的models-腾讯云开发者社区-腾讯云
2.
)


















