> 一次流量突增引发的生产事故,如何催生出融合流日志、机器学习与自动化告警的智能监控体系
深夜2点,电商平台运维负责人李明的手机疯狂报警——北美用户下单量断崖式下跌。他紧急登录系统,发现跨境专线延迟飙升至2000ms。**经过3小时的排查**,罪魁祸首竟是新部署的CDN节点异常触发跨洋链路拥塞。这类问题在混合云架构中日益频繁,而传统监控工具往往**在问题爆发后才后知后觉**。
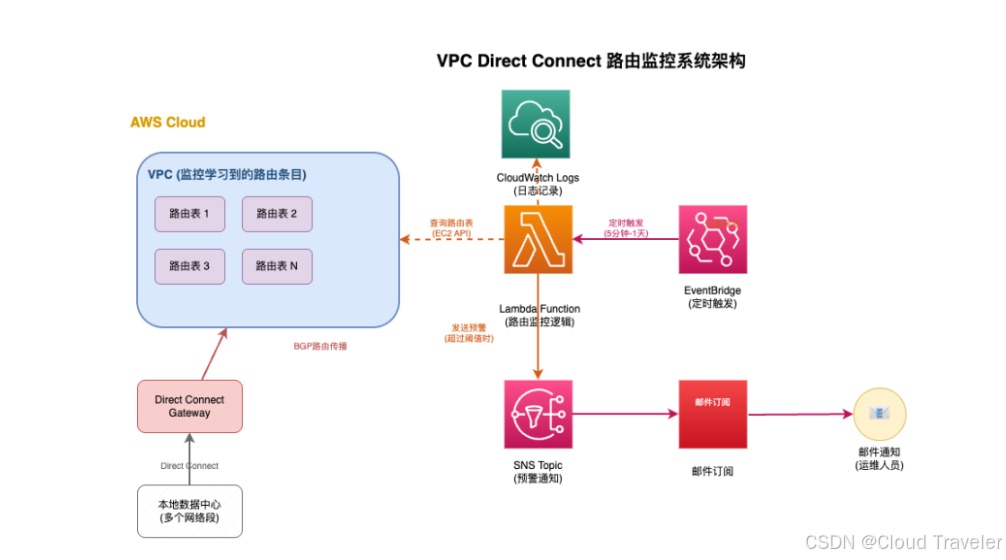
本文将详解如何构建**AI增强的Direct Connect路由监控系统**,实现从被动救火到主动预防的进化。以下为系统核心架构图:
![智能监控系统架构图]
├─ 数据采集层(VPC流日志+Transit Gateway日志)
├─ 核心监控层(CloudWatch指标聚合)
├─ AI分析引擎(异常检测/容量预测/根因分析)
└─ 自动化响应(自愈脚本+SNS告警)
---
### 一、问题深挖:Direct Connect监控的挑战与机遇
**跨境网络链路监控的三大痛点**:
- **延迟敏感型业务容忍度极低**:金融交易系统要求延迟≤100ms,而传统ICMP探测精度不足
- **海量日志中的关键信号被淹没**:单个VPC每日产生GB级流日志,人工分析如大海捞针
- **故障定位跨多层架构**:需穿透物理专线、虚拟接口、路由表、安全策略等多层组件
**Amazon Direct Connect的核心监控盲区**:
```py


:冒泡排序、快速排序)







 加权稀疏迭代最近点算法(matlab版))


)


|所有权机制 Ownership)


 关键字搜索 API 实战:从认证到商品列表获取全流程解析)