大语言模型(LLM)的快速发展正在重塑各行各业的智能化进程,但其落地应用仍面临技术适配、场景融合、成本控制等多重挑战。本文将系统解析大模型落地的四大核心方向 ——微调技术、提示词工程、多模态应用和企业级解决方案,通过代码示例、流程图解、Prompt 模板和架构设计,全面呈现大模型从实验室到产业界的完整落地路径。
一、大模型微调:让通用能力适配专属场景
大模型预训练阶段已经吸收了海量通用知识,但在垂直领域(如医疗、法律、制造)的专业任务中往往表现不足。微调(Fine-tuning)通过在特定领域数据上的二次训练,使模型适配专属场景需求。
1. 微调技术体系
大模型微调可根据参数更新范围分为三类:
| 微调方式 | 特点 | 适用场景 | 资源需求 |
|---|---|---|---|
| 全参数微调 | 更新所有模型参数 | 数据量充足(10 万 + 样本)、任务复杂 | 极高(需多 GPU 集群) |
| 部分参数微调 | 仅更新部分层参数(如最后几层) | 中等数据量(1 万 - 10 万样本) | 中高 |
| 参数高效微调(PEFT) | 冻结主模型,仅训练新增的少量参数(如 LoRA、Prefix-Tuning) | 小数据量(千级样本)、资源有限场景 | 低 |
当前企业级落地中,LoRA(Low-Rank Adaptation) 是最主流的参数高效微调方法,通过低秩矩阵分解减少可训练参数,在保持效果的同时降低计算成本。
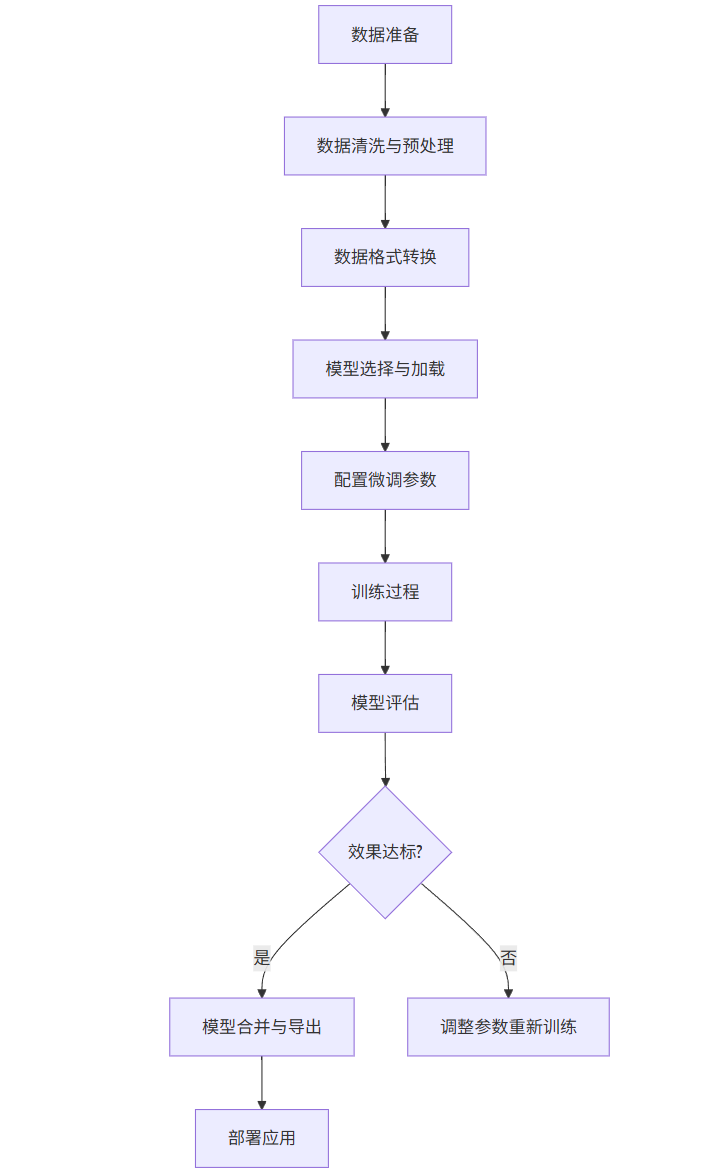
2. 微调完整流程(附代码与流程图)
(1)微调流程图
graph TD
A[数据准备] --> B[数据清洗与预处理]
B --> C[数据格式转换]
C --> D[模型选择与加载]
D --> E[配置微调参数]
E --> F[训练过程]
F --> G[模型评估]
G --> H{效果达标?}
H -->|是| I[模型合并与导出]
H -->|否| J[调整参数重新训练]
I --> K[部署应用]
(2)LoRA 微调代码示例(基于 Hugging Face 生态)
python
运行
# 安装必要库
!pip install transformers datasets accelerate peft bitsandbytesimport torch
from datasets import load_dataset
from transformers import (AutoModelForCausalLM,AutoTokenizer,TrainingArguments,Trainer,BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model# 1. 加载数据集(以法律问答数据集为例)
dataset = load_dataset("json", data_files="legal_qa_dataset.json")
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-7B")
tokenizer.pad_token = tokenizer.eos_token# 2. 数据预处理
def preprocess_function(examples):# 构建输入格式:问题+答案prompts = [f"问题:{q}\n答案:{a}" for q, a in zip(examples["question"], examples["answer"])]# 分词处理inputs = tokenizer(prompts,max_length=512,truncation=True,padding="max_length",return_tensors="pt")# 设置标签(与输入相同,因果语言模型任务)inputs["labels"] = inputs["input_ids"].clone()return inputstokenized_dataset = dataset.map(preprocess_function,batched=True,remove_columns=dataset["train"].column_names
)# 3. 量化配置(4-bit量化降低显存占用)
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.float16
)# 4. 加载基础模型
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-7B",quantization_config=bnb_config,device_map="auto",trust_remote_code=True
)# 5. 配置LoRA参数
lora_config = LoraConfig(r=8, # 低秩矩阵维度lora_alpha=32,target_modules=["W_pack"], # 目标模块(不同模型模块名不同)lora_dropout=0.05,bias="none",task_type="CAUSAL_LM"
)# 6. 应用LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 查看可训练参数比例(通常<1%)# 7. 配置训练参数
training_args = TrainingArguments(output_dir="./legal_model_lora",per_device_train_batch_size=4,gradient_accumulation_steps=4,learning_rate=2e-4,num_train_epochs=3,logging_steps=10,save_strategy="epoch",optim="paged_adamw_8bit", # 8-bit优化器report_to="tensorboard"
)# 8. 初始化Trainer并训练
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset["train"],eval_dataset=tokenized_dataset["validation"]
)trainer.train()# 9. 保存LoRA适配器
model.save_pretrained("legal_lora_adapter")# 10. 推理示例
inputs = tokenizer("问题:劳动合同到期后未续签但继续工作,视为自动续约吗?\n答案:", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100, temperature=0.7)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
3. 微调关键注意事项
-** 数据质量优先 :微调效果高度依赖数据质量,需确保数据准确、无偏见、覆盖场景全面。建议通过人工审核 + 自动化清洗(去重、纠错、过滤敏感信息)提升数据质量。
- 过拟合防控 **:小数据集微调易发生过拟合,可采用以下方法:
- 增加正则化(Dropout、权重衰减)
- 使用早停策略(Early Stopping)
- 引入领域内通用数据作为补充
-** 增量微调 **:对于持续更新的领域知识(如金融政策、医疗指南),可采用增量微调方式,在原有微调模型基础上继续训练,避免知识遗忘。
二、提示词工程:释放大模型原生能力的艺术
提示词工程(Prompt Engineering)通过精心设计输入文本,引导大模型在不改变参数的情况下更好地完成任务。对于中小微企业或资源有限的团队,提示词工程是成本最低、见效最快的大模型落地方式。
1. 提示词设计核心原则
有效的提示词应遵循CLEAR原则:
-** C (Clear):指令清晰明确,避免模糊表述
- L (Logical):逻辑连贯,按任务流程组织信息
- E (Explicit):明确输出格式和要求
- A (Appropriate):匹配模型能力,不过度要求
- R **(Relevant):提供与任务相关的背景信息
2. 实用提示词技巧与示例
(1)角色设定法
通过赋予模型特定角色,使其从对应视角思考问题,提升专业度。
Prompt 示例(法律咨询场景):
plaintext
你是一名拥有10年经验的劳动法律师,擅长处理劳动合同纠纷。请以专业、严谨的语气回答以下问题,需引用相关法律条文,并给出具体解决方案。用户问题:我在公司工作3年,公司未缴纳社保,现在被辞退,能要求哪些赔偿?
(2)少样本学习(Few-shot Learning)
提供少量示例,让模型理解任务模式,适用于格式化输出场景。
Prompt 示例(客户投诉分类):
plaintext
请将客户投诉按问题类型分类,类型包括:产品质量、物流配送、客服态度、价格问题。示例1:
投诉内容:收到的手机屏幕有划痕,明显是二手货
分类结果:产品质量示例2:
投诉内容:下单后一周还没发货,客服也不回复
分类结果:物流配送需要分类的投诉:
"这个价格比昨天贵了50元,太坑了,再也不买了"
(3)思维链(Chain-of-Thought, CoT)
引导模型分步推理,提升复杂问题解决能力,尤其适用于数学计算、逻辑推理场景。
Prompt 示例(数学应用题):
plaintext
请一步一步分析并解答问题,先说明解题思路,再计算结果。问题:某商店进了一批商品,进价每件20元,售价每件30元。当卖到还剩10件时,除去成本后获利500元。问这批商品共有多少件?
模型优化输出:
plaintext
解题思路:
1. 先计算每件商品的利润:售价 - 进价 = 30 - 20 = 10元
2. 设这批商品共有x件,已卖出的数量为x - 10件
3. 总利润 = 已卖出数量 × 每件利润,即500 = (x - 10) × 10
4. 解方程:x - 10 = 500 ÷ 10 = 50,所以x = 50 + 10 = 60答案:这批商品共有60件。
(4)输出格式控制
通过模板约束输出格式,便于后续程序处理(如 JSON、表格、Markdown 等)。
Prompt 示例(信息抽取):
plaintext
请从以下招聘信息中提取关键信息,按JSON格式输出,包含:岗位名称、薪资范围、工作地点、学历要求、经验要求。招聘信息:
"【高级Python开发工程师】薪资25K-40K·13薪,北京朝阳区,本科及以上学历,3年以上后端开发经验,熟悉Django/Flask框架,有分布式系统经验优先。"
期望输出:
json
{"岗位名称": "高级Python开发工程师","薪资范围": "25K-40K·13薪","工作地点": "北京朝阳区","学历要求": "本科及以上","经验要求": "3年以上后端开发经验"
}
3. 提示词效果优化方法
| 优化方向 | 具体做法 | 效果提升 |
|---|---|---|
| 指令细化 | 将模糊指令拆解为多个明确步骤 | ★★★★☆ |
| 增加约束 | 限定输出长度、风格、专业术语 | ★★★☆☆ |
| 反向提示 | 明确告知模型不应出现的内容 | ★★☆☆☆ |
| 多轮交互 | 通过追问补充信息,逐步逼近答案 | ★★★★☆ |
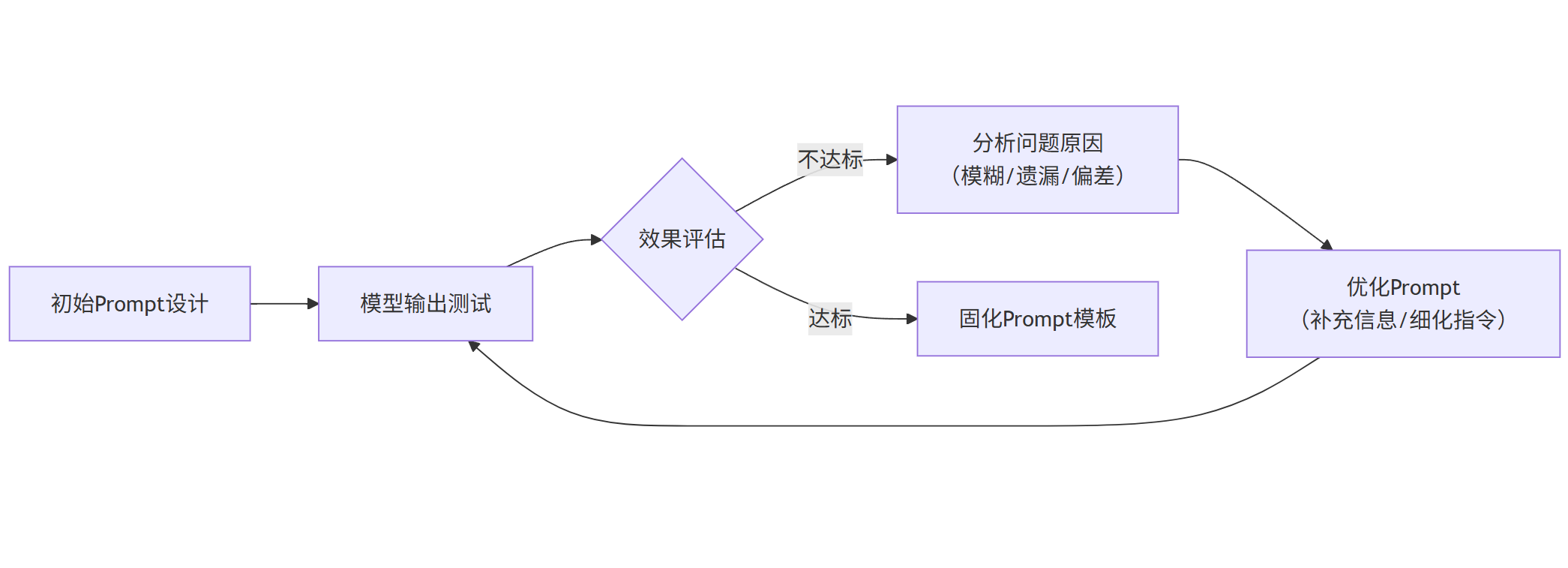
提示词迭代流程图:
graph LR
A[初始Prompt设计] --> B[模型输出测试]
B --> C{效果评估}
C -->|不达标| D[分析问题原因<br>(模糊/遗漏/偏差)]
D --> E[优化Prompt<br>(补充信息/细化指令)]
E --> B
C -->|达标| F[固化Prompt模板]
三、多模态应用:打破数据类型边界的融合智能
多模态大模型(如图文、音视频融合)能够同时处理文本、图像、音频等多种数据类型,极大扩展了大模型的应用场景。从图文生成到视频分析,多模态技术正在成为企业智能化的核心竞争力。
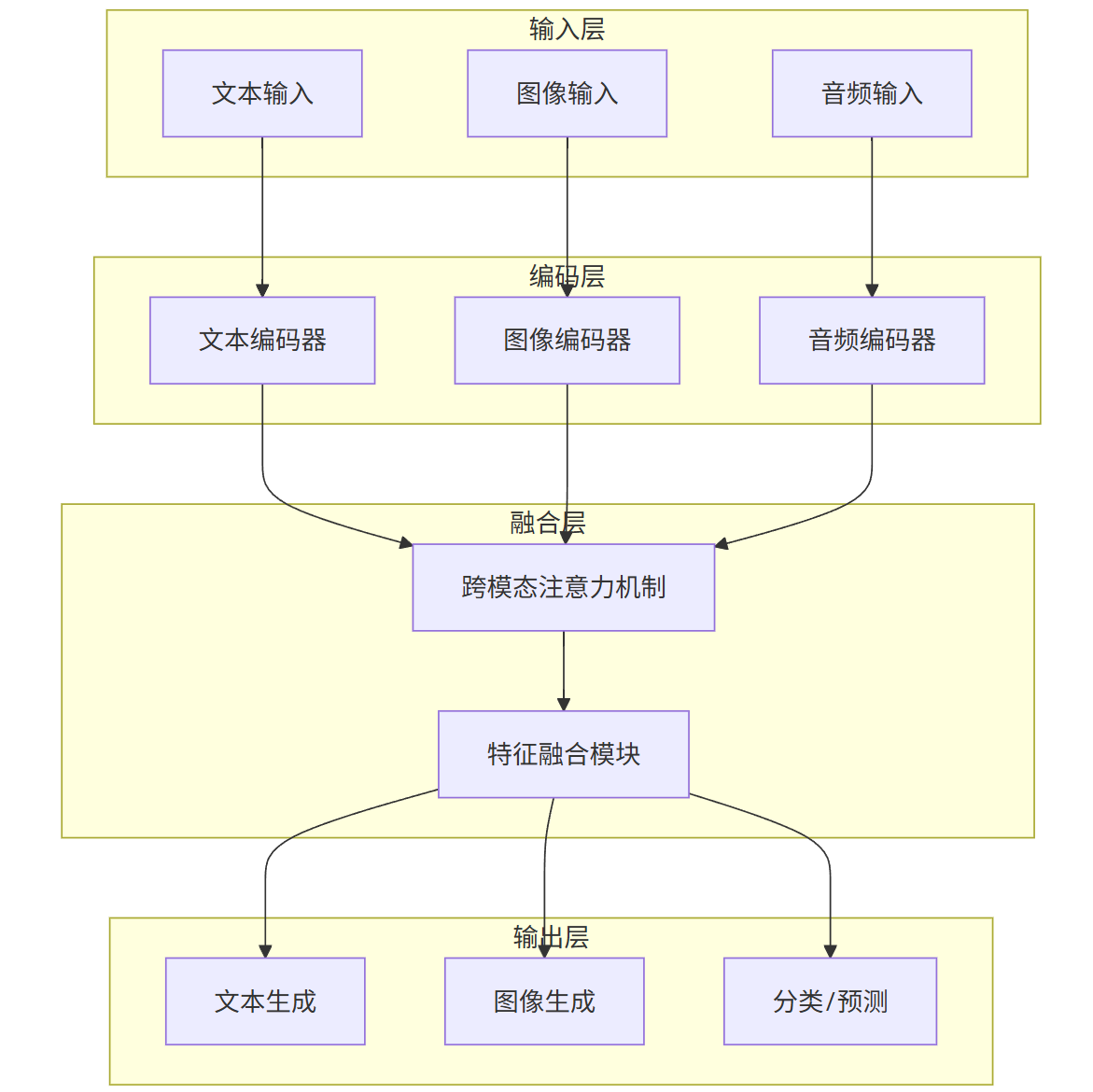
1. 多模态技术架构
多模态应用的核心是解决跨模态语义对齐问题,主流架构分为两类:
-** 单流架构 :将不同模态数据通过统一编码器转化为相同维度的特征向量,如 CLIP、DALL・E 3
- 双流架构 **:不同模态使用专属编码器,通过跨注意力机制实现交互,如 BLIP、GPT-4V
多模态模型通用架构图:
graph TD
subgraph 输入层
A[文本输入]
B[图像输入]
C[音频输入]
end
subgraph 编码层
D[文本编码器]
E[图像编码器]
F[音频编码器]
end
subgraph 融合层
G[跨模态注意力机制]
H[特征融合模块]
end
subgraph 输出层
I[文本生成]
J[图像生成]
K[分类/预测]
end
A --> D
B --> E
C --> F
D --> G
E --> G
F --> G
G --> H
H --> I
H --> J
H --> K
2. 典型多模态应用场景与代码示例
(1)图文生成:从文本描述创建图像
应用场景:广告设计、电商商品图生成、创意设计辅助
python
运行
# 基于Stable Diffusion的图文生成示例
!pip install diffusers transformers acceleratefrom diffusers import StableDiffusionPipeline
import torch
from PIL import Image# 加载模型
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5",torch_dtype=torch.float16
).to("cuda")# 文本提示词(正向提示词+反向提示词)
prompt = "a high-quality product image of a wireless headphone, minimalist design, white background, studio lighting"
negative_prompt = "blurry, low resolution, messy, text, watermark"# 生成图像
image = pipe(prompt,negative_prompt=negative_prompt,num_inference_steps=50,guidance_scale=7.5
).images[0]# 保存图像
image.save("wireless_headphone.png")
image.show()
(2)图像理解:从图像提取结构化信息
应用场景:工业质检、OCR 识别、医学影像分析
python
运行
# 基于GPT-4V的图像理解示例(API调用)
import requests
import jsonapi_key = "your_api_key"
url = "https://api.openai.com/v1/chat/completions"headers = {"Content-Type": "application/json","Authorization": f"Bearer {api_key}"
}# 图像编码为base64(此处省略编码过程)
image_b64 = "base64_encoded_image_data"data = {"model": "gpt-4-vision-preview","messages": [{"role": "user","content": [{"type": "text", "text": "请分析这张工厂生产线的图片,判断是否存在安全隐患,列出问题点和改进建议。"},{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}]}],"max_tokens": 500
}response = requests.post(url, headers=headers, json=data)
result = json.loads(response.text)
print(result["choices"][0]["message"]["content"])
(3)视频分析:多模态内容理解与摘要
应用场景:监控录像分析、视频内容审核、会议纪要生成
视频分析通常采用 "帧采样 + 图文理解" 的方案:
- 从视频中抽取关键帧(每 3-5 秒 1 帧)
- 对关键帧进行图像理解,生成帧描述
- 结合音频转文本(ASR)结果,生成视频摘要
python
运行
# 视频关键帧提取示例
import cv2
import osdef extract_keyframes(video_path, output_dir, interval=5):"""每隔interval秒提取一帧关键帧"""os.makedirs(output_dir, exist_ok=True)cap = cv2.VideoCapture(video_path)fps = cap.get(cv2.CAP_PROP_FPS)frame_interval = int(fps * interval)frame_count = 0keyframe_count = 0while cap.isOpened():ret, frame = cap.read()if not ret:breakif frame_count % frame_interval == 0:output_path = os.path.join(output_dir, f"keyframe_{keyframe_count}.jpg")cv2.imwrite(output_path, frame)keyframe_count += 1frame_count += 1cap.release()return keyframe_count# 提取示例
extract_keyframes("factory_monitor.mp4", "keyframes", interval=3)
3. 多模态应用落地挑战
-** 数据壁垒 :多模态数据采集成本高,尤其高质量标注数据稀缺,可通过半监督学习、数据增强技术缓解。
- 计算成本 :多模态模型参数量巨大(通常 100 亿 +),推理延迟较高,需通过模型压缩、量化部署优化。
- 模态偏差 **:不同模态数据分布不均(如文本信息丰富,图像信息稀疏),需设计平衡的融合策略。
四、企业级解决方案:从技术到价值的闭环
企业级大模型应用需解决安全性、可控性、可扩展性三大核心问题,构建从需求分析到持续优化的完整闭环。
1. 企业级大模型架构设计
分层架构图:
graph TD
subgraph 基础设施层
A[GPU集群]
B[分布式存储]
C[容器编排(K8s)]
D[监控告警系统]
end
subgraph 模型层
E[基础大模型]
F[领域微调模型]
G[多模态模型]
H[模型仓库]
end
subgraph 平台层
I[模型服务化]
J[Prompt管理]
K[数据处理管道]
L[权限管理]
end
subgraph 应用层
M[智能客服]
N[内容生成]
O[数据分析]
P[流程自动化]
end
A --> E
B --> K
E --> F
E --> G
F --> H
G --> H
H --> I
I --> J
K --> I
L --> I
I --> M
I --> N
I --> O
I --> P
(1)基础设施层
-** 计算资源 :根据模型规模选择合适配置(如 7B 模型需 16GB + 显存,13B 模型需 32GB + 显存)
- 存储方案 :采用对象存储(如 S3)存储模型权重和训练数据,支持高并发访问
- 部署架构 **:使用 Kubernetes 实现模型服务的弹性扩缩容,应对流量波动
(2)模型层
- 采用 "基础模型 + 领域适配器" 的混合架构,平衡通用性和专业性
- 建立模型版本管理机制,支持 A/B 测试和灰度发布
- 实施模型监控,检测性能衰减和偏差漂移
(3)平台层
核心功能包括:
-** 模型服务化 :提供 RESTful API 和 SDK,支持同步 / 异步调用
- Prompt 工程平台 : Prompt 模板管理、效果评估、自动优化
- 数据安全 **:实现输入输出过滤、敏感信息脱敏、数据加密传输
(4)应用层
针对不同行业场景定制化开发,如:
- 金融:智能投顾、风险评估、反欺诈检测
- 制造:设备故障诊断、生产流程优化
- 医疗:病历分析、医学影像辅助诊断
- 零售:智能推荐、客户画像分析
2. 企业级部署关键技术
(1)模型服务化框架
推荐使用vLLM或Text Generation Inference (TGI) 作为模型服务框架,相比原生 Hugging Face 推理速度提升 5-10 倍:
bash
# 使用vLLM部署模型示例
python -m vllm.entrypoints.api_server \--model baichuan-inc/Baichuan-13B-Chat \--port 8000 \--tensor-parallel-size 2 \ # 多GPU并行--max-num-batched-tokens 4096 \--quantization awq # 量化部署
(2)安全管控方案
-** 输入过滤 :拦截恶意 Prompt(如注入攻击、敏感内容)
- 输出审查 :使用分类模型检测生成内容是否合规
- 数据隔离 **:不同租户数据物理隔离,模型访问权限精细化控制
python
运行
# 输入安全过滤示例
def filter_prompt(prompt):# 敏感词列表sensitive_words = ["攻击", "诈骗", "暴力",... ]# 检测注入模式injection_patterns = [r"忽略以上指令", r"system prompt", r"重置"]# 敏感词检测for word in sensitive_words:if word in prompt:return False, f"包含敏感词:{word}"# 注入模式检测import refor pattern in injection_patterns:if re.search(pattern, prompt, re.IGNORECASE):return False, "检测到潜在注入攻击"return True, "通过检测"
(3)性能优化策略
| 优化方向 | 技术手段 | 效果 |
|---|---|---|
| 推理加速 | 量化(INT4/INT8)、KV 缓存、投机解码 | 提速 3-10 倍 |
| 成本控制 | 模型动态调度、非高峰时段资源释放 | 降本 30-50% |
| 可用性保障 | 多模型冗余部署、自动故障转移 | 可用性达 99.9% |
3. 典型企业案例分析
(1)金融行业:智能投研系统
架构:
- 基础模型:GPT-4、LLaMA 2 70B
- 微调数据:10 年财报数据、研报、新闻
- 核心功能:
- 多文档解析(PDF/Excel/Word)
- 财务指标对比分析
- 行业趋势预测
- 自动生成研报
价值:分析师工作效率提升 40%,报告生成时间从 3 天缩短至 2 小时。
(2)制造行业:设备故障诊断
架构:
- 多模态模型:融合文本(故障手册)、图像(设备照片)、传感器数据
- 部署方式:边缘 + 云端协同(边缘侧轻量化模型实时检测,云端深度分析)
- 核心流程:
- 传感器数据实时采集
- 异常检测触发预警
- 多模态分析定位故障原因
- 生成维修步骤和备件清单
价值:设备停机时间减少 35%,维修成本降低 28%。
4. 企业落地实施路径
需求验证阶段(1-2 周)
- 明确核心痛点和 KPI
- 用 Prompt 工程快速验证可行性
- 输出 POC 报告
技术选型阶段(2-4 周)
- 评估自研 vs. 采购模型
- 搭建测试环境
- 完成小范围试点
规模化部署阶段(1-3 个月)
- 数据准备与模型微调
- 构建生产级平台
- 分阶段上线应用
持续优化阶段(长期)
- 监控模型效果与成本
- 定期更新模型与数据
- 拓展新应用场景
总结与展望
大模型落地是一个技术适配与场景创新相辅相成的过程:微调技术解决模型的专业化问题,提示词工程降低应用门槛,多模态扩展应用边界,企业级方案保障落地效果。未来,随着模型效率的提升和成本的降低,大模型将从 "锦上添花" 的辅助工具,逐渐成为企业核心业务的 "基础设施"。
企业在落地过程中需避免 "技术崇拜",坚持问题导向:从实际业务痛点出发,选择合适的技术路径,小步快跑、快速迭代,才能在大模型浪潮中真正实现价值转化。









)

)

论文解析技巧)

Flink的机制)
)
http参数过滤)

