1 fasttext工具介绍
1.1 介绍
-
fasttext 是 Facebook AI Research(FAIR)开发的开源 NLP 工具包,专门用来解决文本相关任务,比如情感分析、文本分类(判断新闻属于体育/财经等)、识别“人名/地名”这类实体,甚至辅助机器翻译;
-
其核心功能聚焦 2 件事:
-
文本分类:给文本贴标签、分类别(比如判断评论是“正面”还是“负面”);
-
训练词向量:把词语转换成计算机能理解的数字向量,捕捉词语语义(比如 “国王”和“王后”的向量,会比“国王”和“苹果”的向量更接近);
-
-
最大优势:正如其名。它能在保证较高精度的前提下,大幅加速训练和预测过程,处理大规模文本数据时效率更高;
-
优势原因:
- fasttext工具包中内含的fasttext模型,模型结构简单;
- 使用fasttext模型训练词向量时,使用层次softmax结构,来提升超多类别下的模型性能;
- 采用负采样(negative sampling),每次训练仅仅更新一小部分的权重,降低梯度下降过程中的计算量;
- fasttext模型过于简单无法捕捉词序特征,可采用n-gram特征提取文本特征以弥补模型缺陷提升精度。
1.2 安装
-
安装 Python 3.8.12 的 Conda 环境:
conda create -n py3812 python=3.8.12 -
激活环境:
conda activate py3812 -
若直接安装官方源码版,由于此处使用的是 Windows 操作系统,需要安装 Visual Studio 或配置编译环境,所以选择安装
fasttext-wheel预编译轮子版:pip install fasttext-wheel-
推荐使用 Linux 系统,按照下面的方式安装:
git clone https://github.com/facebookresearch/fastText.git cd fastText sudo pip install .
-
-
验证:
(py3812) C:\Windows\System32>python Python 3.8.12 (default, Oct 12 2021, 03:01:40) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import fasttext >>>
1.3 fasttext模型架构
1.3.1 三层架构
-
fasttext 架构和 Word2Vec 里的CBOW 模型很像,但目标不同:
-
CBOW 是“预测中间词”(比如用上下文猜中间的词);
-
fasttext 是“预测文本标签/类别”(比如判断文本是“体育新闻”还是“财经新闻”);
-
-
fasttext 模型分 3 层:
-
输入层:把文本拆成可计算的向量
-
输入的是文档 embedding 后的向量,而且不只是单个词,还包含N-gram 特征;
-
作用:弥补模型“太简单,抓不住词序”的问题,用 N-gram 保留局部短语信息;
-
-
隐藏层:平均汇总
-
对输入层的所有向量(单个词 + N-gram 等),直接求和、平均,得到一个汇总后的向量;
-
特点:计算极简单,没有复杂的变换,所以速度快,但也会损失一些细节;
-
-
输出层:预测文本的标签/类别
-
输出的是文档对应的 label(标签/类别),比如“正面情感”“体育分类”等;
-
关键优化:为了让多分类更高效,没用传统的 Softmax,而是用层次 Softmax;
-
-
-
层次 Softmax(Hierarchical Softmax)
-
传统 Softmax 计算多分类概率时,要遍历所有类别算概率,类别越多越慢。fasttext 用哈夫曼树优化;
-
把类别建成一棵树,叶子节点是类别。计算概率时,只需要从根到叶子走一条路径,不用遍历所有类别,大幅减少计算量,让预测/训练速度飞起。
-
1.3.2 层次 Softmax
-
为什么层次 Softmax 比普通 Softmax 计算概率分布要快?
-
普通 Softmax 计算多分类概率时,要遍历所有类别算指数、归一化,类别越多越慢;
-
层次 Softmax 用**哈夫曼树(带权二叉树)**重构计算方式,把“遍历所有类别”改成“走一条路径”,直接砍半计算量——这是它“更快”的本质;
-
哈夫曼树:“让高频类别‘更近’”
-
所有单词(或类别)挂在叶子节点,树的构建按照“出现频率”分配:频率越高的单词,离根节点越近(路径越短);
-
效果:高频词计算时,少走很多“弯路”,整体平均计算步骤更少。
-
-
概率计算:从遍历所有到走一条路
-
普通 Softmax(以计算单词w2w_2w2概率为例):分母要把所有VVV个类别的指数都算一遍,类别越多,计算量爆炸(比如10万类别,就要算10万次指数);
p(w2)=evw2∑i=1Vevwip(w2) = \frac{e^{v_{w2}}}{\sum_{i=1}^V e^{v_{w_i}}} p(w2)=∑i=1Vevwievw2 -
层次Softmax(同样算w2w_2w2概率):把“算单个单词概率”,拆成“走哈夫曼树路径上的多个二分类概率乘积”;
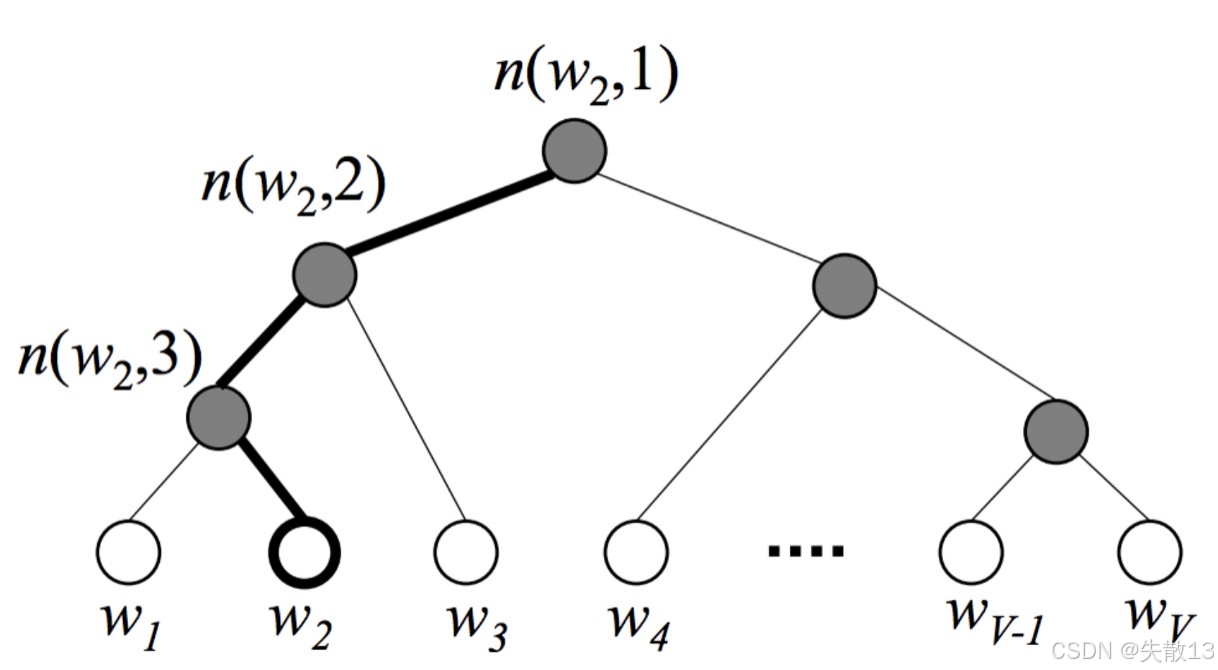
-
比如w2w_2w2的路径是“根→节点A→节点B→叶子w2w_2w2”,每一步都是“左/右子树”的二分类概率(类似“选左的概率是0.6,选右是0.4”),最后把这些概率相乘,就是w2w_2w2的概率;
-
效果:不需要遍历所有类别,只需要算“路径长度”次二分类(路径长度远小于总类别数VVV),计算量直接砍半;
-
-
-
-
例:
-
哈夫曼树结构
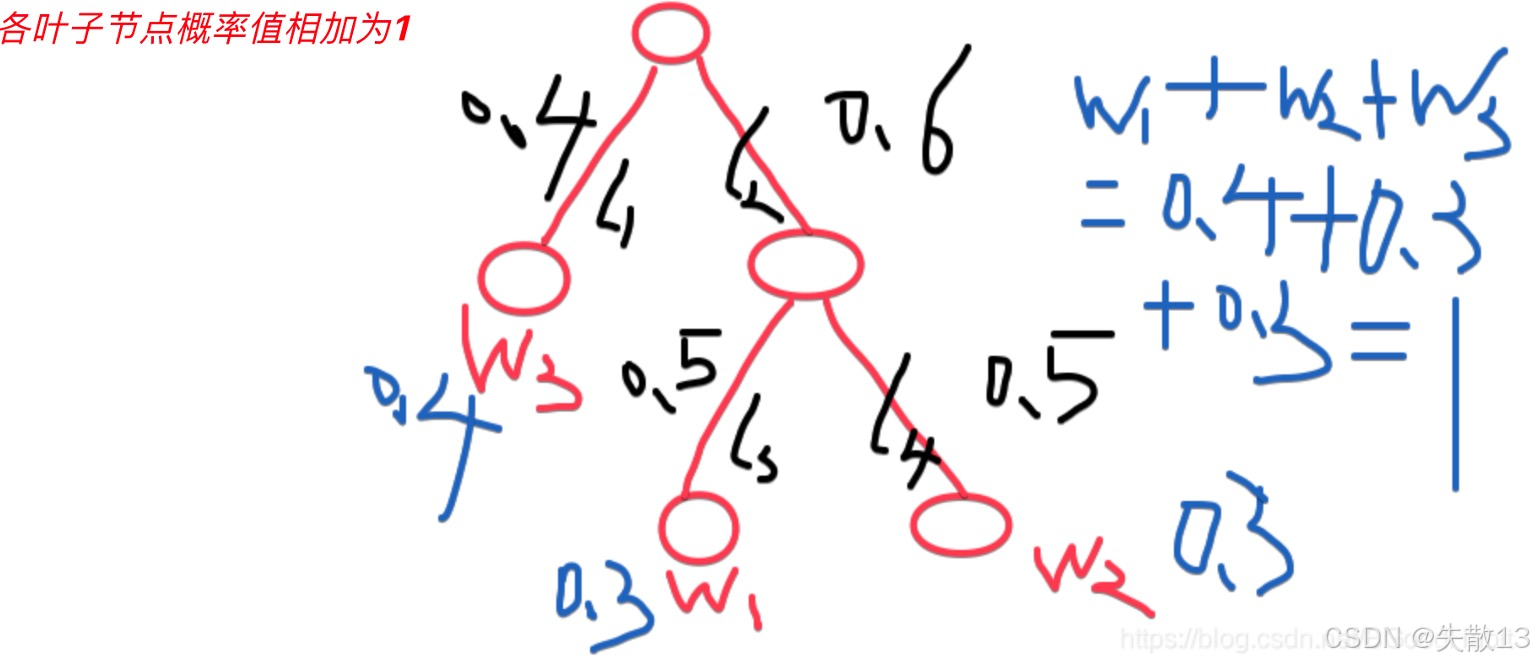
- 假设有3个词w1w_1w1,w2w_2w2,w3w_3w3,由于每个中间节点是一个二分类,则p(left)+p(right)=1p(left)+p(right)=1p(left)+p(right)=1
- 如图:w3w_3w3=0.4、w1=0.6∗0.5=0.3w_1=0.6*0.5=0.3w1=0.6∗0.5=0.3、w2=0.6∗0.5=0.3w_2=0.6*0.5=0.3w2=0.6∗0.5=0.3、w1+𝑤2+𝑤3=1w_1+ 𝑤_2+𝑤_3 = 1w1+w2+w3=1
-
普通Softmax:要算ew1+ew2+ew3e^{w_1}+e^{w_2}+e^{w_3}ew1+ew2+ew3,然后再归一化;
-
层次Softmax:算w2w_2w2概率时,走“根→右子树→左子树→w2w_2w2”,概率是 “根选右(0.6)×下一层选左(0.5)×再下一层选左(0.3)”,最后相乘得到w2w_2w2的概率;
-
-
总结:
-
层次Softmax把**“多分类问题”拆解成“多个二分类问题的乘积”**,不需要遍历所有类别,计算量随“哈夫曼树深度”线性增长(而普通Softmax是随类别数VVV线性增长);
-
代价:精度会略降(因为路径拆分后,不是直接算所有类别概率),但换来的是速度大幅提升,尤其类别数极多(比如10万+类别)时,优势碾压。
-
1.3.3 哈夫曼树的简介、构建和训练
-
哈夫曼树的本质是带权路径最短的二叉树
-
WPL(Weighted Path Length):带权路径长度
WPL=∑(节点权重×该节点到根的路径长度)WPL = \sum (\text{节点权重} \times \text{该节点到根的路径长度}) WPL=∑(节点权重×该节点到根的路径长度) -
WPL最小的二叉树就是哈夫曼树;
-
例:叶子节点是 3、5、7、9,构建哈夫曼树后:WPL=3×3+5×3+7×2+9×1=47WPL = 3 \times 3 + 5 \times 3 + 7 \times 2 + 9 \times 1 = 47WPL=3×3+5×3+7×2+9×1=47,路径越短,权重×长度的和越小;
-
-
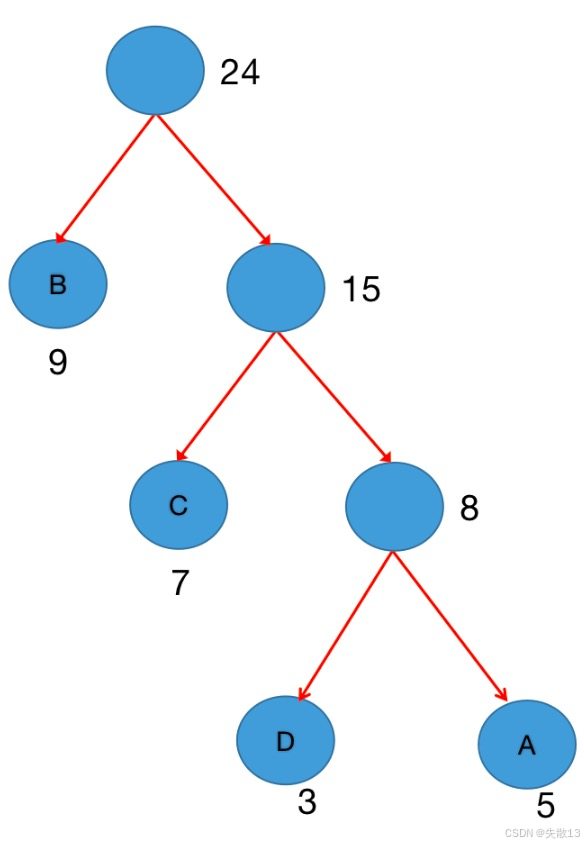
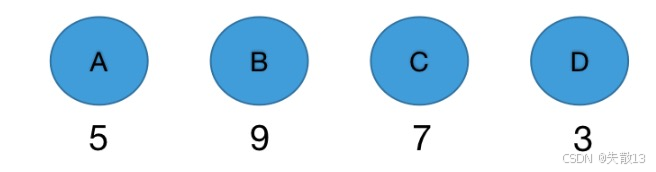
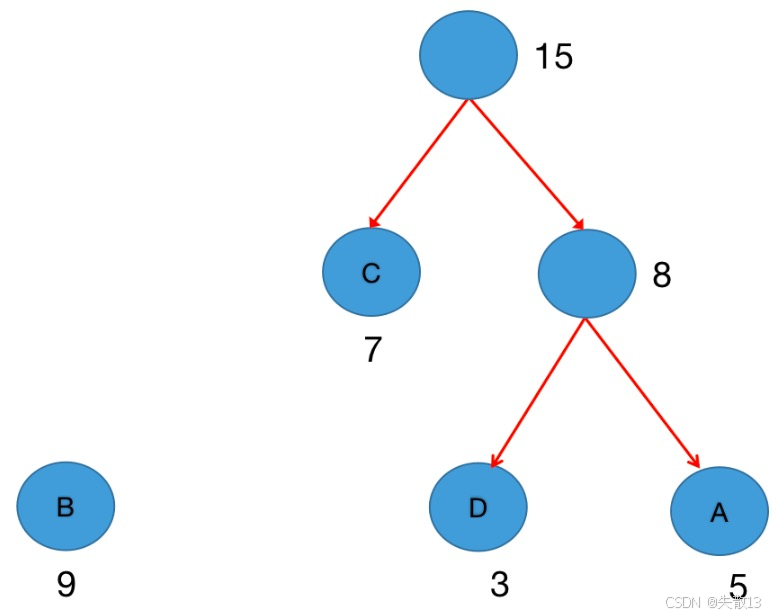
例:假设有四个Label分别为:A~D,统计其在语料库出现的频数为A(5次)、B(9次)、C(7次)、D(3次)
-
步骤1:初始化森林。每个Label(A/B/C/D)单独成树,权重是它们的出现频率(5、9、7、3);
-
步骤2:选权重最小的两棵树合并
-
第一次合并:选最小的 D(3) 和 A(5),合并成新树,权重=3+5=8。此时森林里剩下:B(9)、C(7)、新树(8);

-
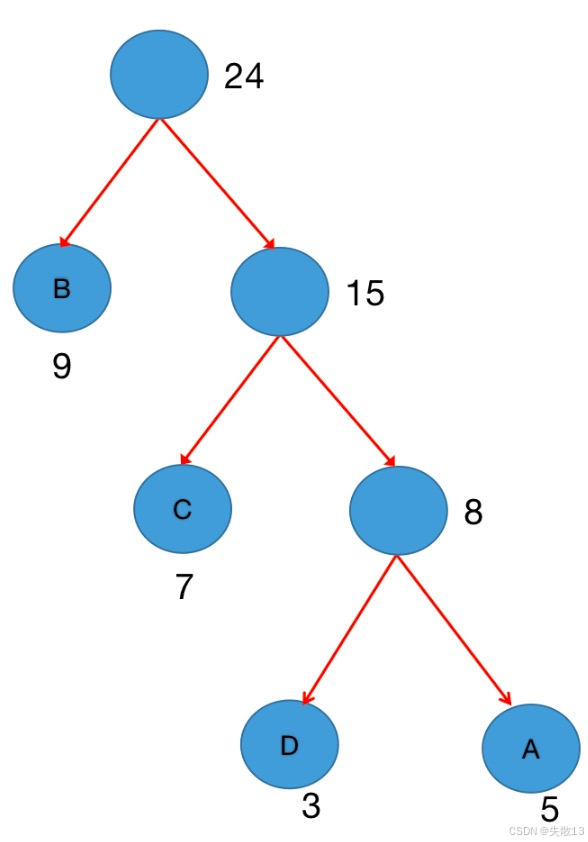
第二次合并:选次小的 C(7) 和 新树(8),合并成新树,权重=7+8=15。此时森林里剩下:B(9)、新树(15);
-
第三次合并:合并 B(9) 和 新树(15),权重=9+15=24。此时森林只剩1棵树——哈夫曼树构建完成!
-
-
-
哈夫曼树建好后,如何训练哈夫曼树?
-
构建好霍夫曼树后,所有单词都会挂在叶子节点上;
-
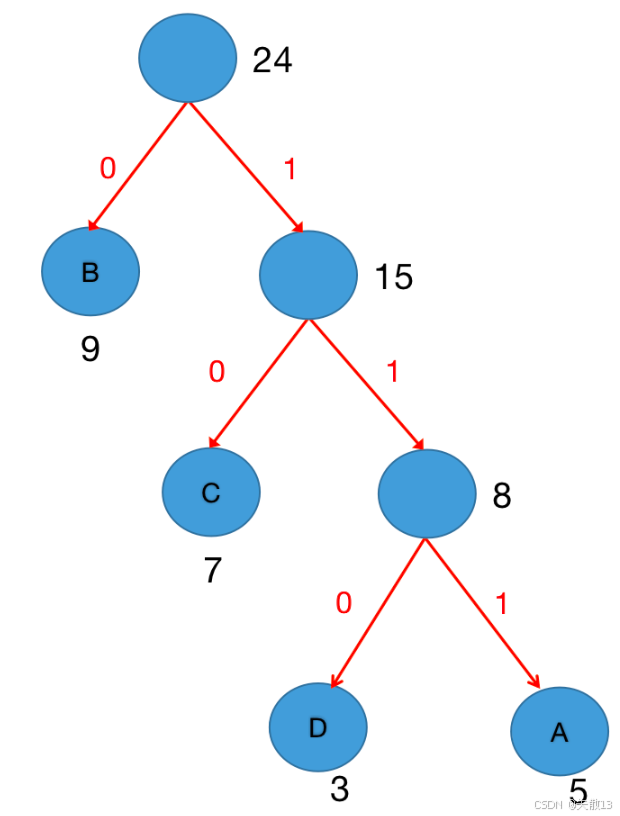
给每个叶子节点创建哈夫曼编码:给每个节点编二进制码
-
规则:左分支记0,右分支记1,从根到叶子的路径上的0/1序列,就是该叶子节点的哈夫曼编码;
-
例子:D的路径是“根→右→右→左”,编码可能是:110;
-
-
训练模型:用路径概率乘积优化参数
-
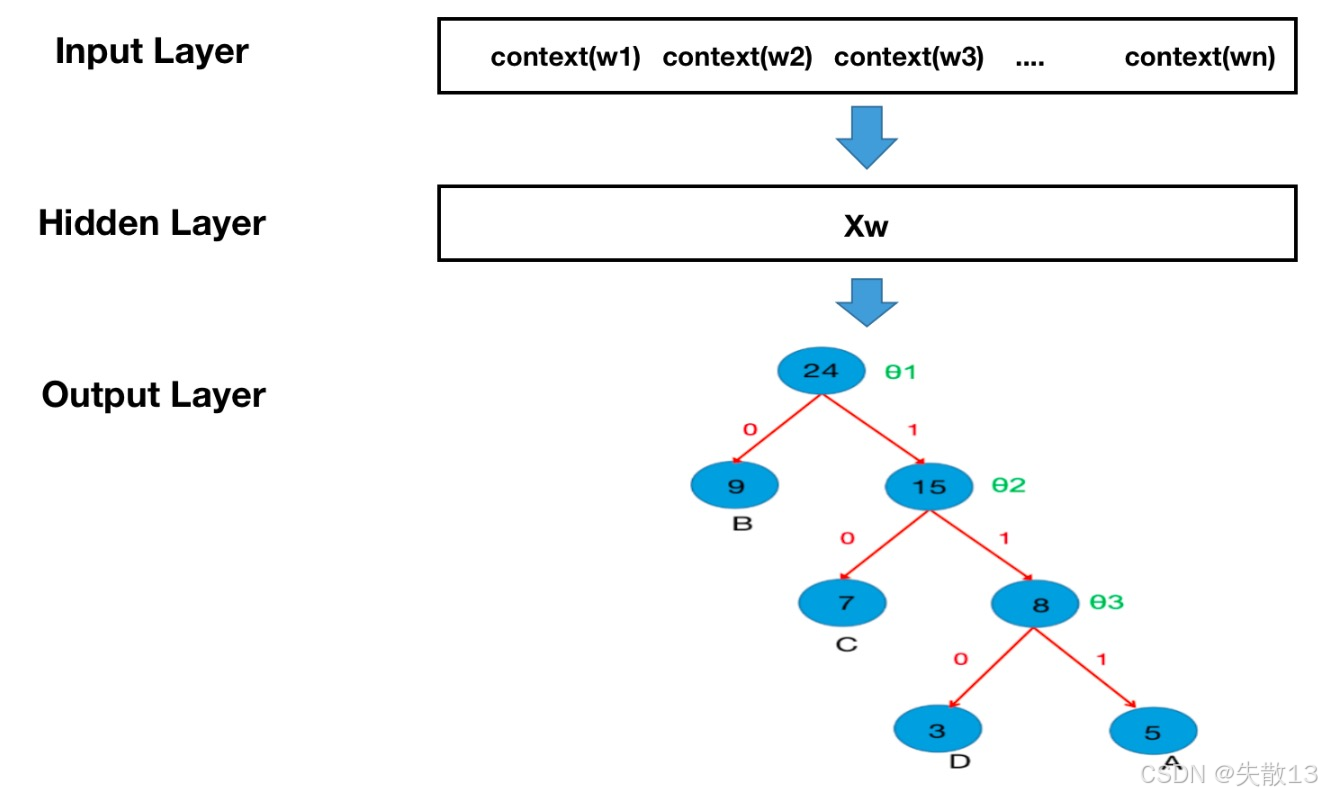
任务:比如用上下文预测单词D,需要从根节点出发,沿着D的编码路径(比如110)走;
-
计算:每一步是二分类概率(走左/右的概率),把这些概率相乘,用极大似然估计(让预测概率尽可能大)反向更新模型参数(比如中间节点的权重);
-
极大似然估计(Maximum Likelihood Estimation,MLE)是一种在统计学和机器学习中广泛使用的参数估计方法,它的目标是利用已知的样本数据,来估计模型中未知参数的值,使得模型产生这些样本数据的概率最大;
基本思想
- 假设我们有一组来自某个概率分布的样本数据,而这个概率分布由一些未知参数决定;
- 极大似然估计的核心想法是,找到这样一组参数值,在这组参数值下,我们现有的样本数据出现的可能性最大;
- 比如,我们抛一枚硬币,不知道它是否是均匀的(即不知道正面朝上的概率 ppp 是多少),现在抛了10次,得到7次正面,3次反面。按照极大似然估计的思想,我们要找到一个 ppp 的值,使得出现 “7次正面,3次反面” 这种结果的概率最大;
计算步骤
- 确定似然函数:
- 对于离散型随机变量,设样本 X1,X2,…,XnX_1, X_2, \ldots, X_nX1,X2,…,Xn 来自概率质量函数为 P(X;θ)P(X; \theta)P(X;θ) 的总体(其中 θ\thetaθ 是未知参数),似然函数 L(θ)L(\theta)L(θ) 就是在参数 θ\thetaθ 下,样本出现的联合概率,即 L(θ)=∏i=1nP(Xi;θ)L(\theta)=\prod_{i = 1}^{n}P(X_i; \theta)L(θ)=∏i=1nP(Xi;θ) ;
- 对于连续型随机变量,设样本 X1,X2,…,XnX_1, X_2, \ldots, X_nX1,X2,…,Xn 来自概率密度函数为 f(X;θ)f(X; \theta)f(X;θ) 的总体,似然函数 L(θ)=∏i=1nf(Xi;θ)L(\theta)=\prod_{i = 1}^{n}f(X_i; \theta)L(θ)=∏i=1nf(Xi;θ) ;
- 对似然函数取对数:取对数后的对数似然函数 lnL(θ)\ln L(\theta)lnL(θ) 与原似然函数在相同的参数值处取得极值,而且取对数后可以将连乘运算转化为连加运算,简化计算,即 lnL(θ)=∑i=1nlnP(Xi;θ)\ln L(\theta)=\sum_{i = 1}^{n}\ln P(X_i; \theta)lnL(θ)=∑i=1nlnP(Xi;θ)(离散型)或 lnL(θ)=∑i=1nlnf(Xi;θ)\ln L(\theta)=\sum_{i = 1}^{n}\ln f(X_i; \theta)lnL(θ)=∑i=1nlnf(Xi;θ)(连续型);
- 求对数似然函数的导数:对 lnL(θ)\ln L(\theta)lnL(θ) 关于未知参数 θ\thetaθ 求导;
- 令导数为0,求解参数:通过求解导数为0的方程,得到使似然函数最大的参数估计值 θ^\hat{\theta}θ^ ;
示例:以抛硬币为例,设正面朝上的概率为 ppp,抛 nnn 次硬币,出现 kkk 次正面。每次抛硬币是独立的伯努利试验,其概率质量函数为 P(X=1;p)=pP(X = 1; p)=pP(X=1;p)=p(正面朝上,X=1X = 1X=1 ),P(X=0;p)=1−pP(X = 0; p)=1 - pP(X=0;p)=1−p(反面朝上,X=0X = 0X=0 );
- 确定似然函数:抛 nnn 次硬币,出现 kkk 次正面的似然函数为 L(p)=Cnkpk(1−p)n−kL(p)=C_{n}^{k}p^{k}(1 - p)^{n - k}L(p)=Cnkpk(1−p)n−k,其中 Cnk=n!k!(n−k)!C_{n}^{k}=\frac{n!}{k!(n - k)!}Cnk=k!(n−k)!n! 是组合数;
- 取对数:对数似然函数为 lnL(p)=lnCnk+klnp+(n−k)ln(1−p)\ln L(p)=\ln C_{n}^{k}+k\ln p+(n - k)\ln(1 - p)lnL(p)=lnCnk+klnp+(n−k)ln(1−p) ;
- 求导数:对 lnL(p)\ln L(p)lnL(p) 关于 ppp 求导,得到 dlnL(p)dp=kp−n−k1−p\frac{d\ln L(p)}{dp}=\frac{k}{p}-\frac{n - k}{1 - p}dpdlnL(p)=pk−1−pn−k ;
- 令导数为0求解:令 dlnL(p)dp=0\frac{d\ln L(p)}{dp}=0dpdlnL(p)=0,解得 p^=kn\hat{p}=\frac{k}{n}p^=nk 。例如前面抛10次硬币出现7次正面的情况,按照极大似然估计得到正面朝上的概率估计值为 710=0.7\frac{7}{10}=0.7107=0.7 ;
在机器学习中的应用
- 在机器学习里,极大似然估计常用于估计模型参数。比如:
- 在逻辑回归中,通过极大似然估计来确定模型中参数的值,使得模型对给定训练数据的预测概率最大;
- 在朴素贝叶斯分类器中,也利用极大似然估计来估计各类别下特征的概率,从而进行分类预测 。
-
1.3.4 负采样
-
为什么需要负采样样(Negative Sampling)?
- 训练模型时,最大的痛点是计算量爆炸;
- 神经网络经过一个训练样本的训练, 它的权重就会进行一次调整;
- 比如利用 Skip-Gram 进行词向量训练,用 Softmax 算概率时,输出层要对所有单词 算指数、归一化,每次训练都要更新所有权重;
- 假设有词汇量 1 万,每次训练就要算 1 万次指数 + 反向传播更新 1 万组权重,训练速度肉眼可见地慢,根本跑不动大规模数据;
- 训练模型时,最大的痛点是计算量爆炸;
-
而负采样的本质是砍计算量:
- 每次训练时,不更新所有单词的权重,只挑一小部分“负样本”(不需要预测正确的单词)和“正样本”(需要预测正确的单词)来更新;
- 相当于把“更新 1 万次”砍成“更新 5 - 20 次”,直接让训练速度起飞;
-
以训练词向量的场景为例(输入“hello”,输出“man”):
-
传统 Softmax 的问题
-
输入“hello”,输出层要预测“man”是正样本(期望输出 1),剩下 9999 个单词都是负样本(期望输出 0);
-
用 Softmax 的话,得给这 9999 个负样本都算概率、反向更新权重,计算量直接拉满;
-
-
负采样的操作
-
只挑一小部分负样本:比如随机选 5 个负样本(比如“apple”“dog”“book”…),只更新这些负样本 + 正样本(“man”)的权重;
-
效果:原本要更新 10000 个权重,现在只更新 6 个(5 负 + 1 正),计算量直接砍到 0.06%(比如 300 万权重,现在只算 1800 个);
-
-
-
负采样的优势
-
训练速度爆炸提升:少更新 99% 的权重,训练时间直接腰斩甚至更多,大规模数据也能跑起来;
-
模型更稳、泛化更好:加入“负样本噪声”(随机选负样本),相当于让模型“见更多错误案例”,能模拟真实场景的噪声,反而让模型更鲁棒(不容易过拟合),预测更准。
-
2 fasttext文本分类
2.1 文本分类介绍
-
概念
- 简单说,就是给文本贴标签、归类:把邮件、帖子、评论、新闻……这类文本,按照规则分到对应的类别里(比如“这封邮件是垃圾邮件/正常邮件”“这条评论是正面/负面”);
- 关键点: 需要有监督学习。即训练模型时,得先给一批文本标好标签(比如人工标“垃圾邮件”“正面评论”),模型才能学怎么分类;
-
种类
-
二分类
-
特点:文本只能“非此即彼”,分到 2 个类别里的 1 个;
-
例子:判断评论是“好评”还是“差评”;识别邮件是“垃圾邮件”还是“正常邮件”;
-
-
单标签多分类
-
特点:文本从多个类别里选 1 个 标签,多选一;
-
例子:识别“人名”属于哪个国家(比如“张三”→“中国”;“玛丽”→“美国”);新闻分类(“体育新闻”“财经新闻”选一个);
-
-
多标签多分类
-
特点:文本可以同时贴多个标签,多选多;
-
例子:一段讨论“既聊美食,又聊体育、游戏”,就同时打“美食”“体育”“游戏”标签。
-
-
2.2 使用fasttext做文本分类
2.2.1 获取数据
-
数据集下载地址:
https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz && tar xvzf cooking.stackexchange.tar.gz; -
本案例使用烹饪相关的数据集, 它是由 Facebook AI 实验室提供的演示数据:
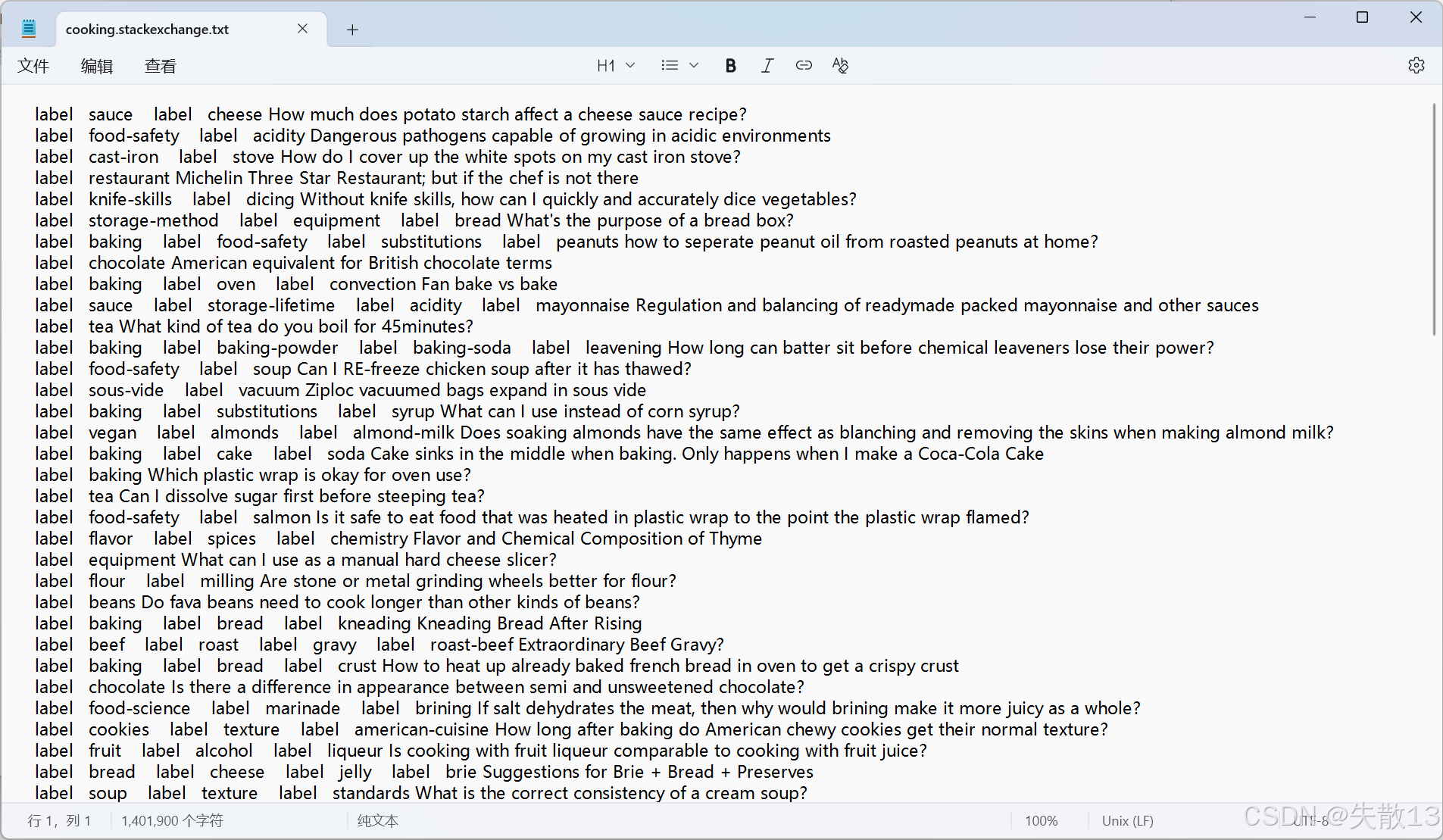
-
每行是标签 + 文本内容结构
label AAA label BBB text1 text2...- 比如:
label sauce label cheese How much does potato starch affect a cheese sauce recipe? - 这里
label sauce label cheese是标签(代表文本分类类别,说明文本和 “酱料、奶酪” 相关),后半句是具体问题文本;
- 比如:
-
每条文本可对应多个标签,属于多标签文本分类问题。
2.2.2 训练集与验证集的划分
-
12404条数据作为训练数据,3000条数据作为验证数据:

-
可以使用一些系统指令,取出
cooking.stackexchange中的从头开始多少行或从尾部开始多少行,分别作为训练集和数据集,以Linux为例:# 12404条数据作为训练数据 $ head -n 12404 cooking.stackexchange.txt > cooking.train # 3000条数据作为验证数据 $ tail -n 3000 cooking.stackexchange.txt > cooking.valid
2.2.3 训练模型
-
将 PyCharm 切换至创建的 py3812 环境:
-
以管理员权限打开 Anaconda,然后激活 py3812 环境,再安装 jupyter:
- 由于 Python 3.8 的版本有点老了,所以一些依赖问题需要自己处理;
ipykernel是一个 Python 包,在 Jupyter 生态系统中扮演着关键角色,它的主要作用是作为 Jupyter Notebook、JupyterLab 等交互式开发环境与 Python 解释器之间的桥梁;
pip install pywinpty==2.0.10 pip install jupyter conda install ipykernel -
重启 PyCharm(这同时也重启了 Anaconda)
-
导包:
import fasttext -
使用 fasttext 的
train_supervised方法进行文本分类模型的训练# 使用fasttext的train_supervised方法进行文本分类模型的训练 model = fasttext.train_supervised(input="cooking_data/cooking.train")
2.2.4 模型的保存和重加载
# 模型的保存和重加载
model.save_model("cooking_data/model/model_cooking.bin")
model = fasttext.load_model("cooking_data/model/model_cooking.bin")
# 重加载后的模型使用方法
model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.01)
k=-1表示返回所有可能分类(按预测概率排序);threshold=0.01是概率阈值,分类预测概率 ≥0.01 才会被输出;
(('__label__baking','__label__food-safety','__label__bread','__label__substitutions','__label__equipment','__label__chicken','__label__eggs','__label__storage-method','__label__cake','__label__sauce','__label__meat','__label__coffee','__label__chocolate','__label__freezing','__label__flavor','__label__cheese'),array([0.06340391, 0.04024106, 0.0361773 , 0.03421036, 0.02819154,0.01837722, 0.01678729, 0.01484748, 0.01481829, 0.01259199,0.01250622, 0.01226074, 0.01125562, 0.01081415, 0.01021101,0.01014362]))
2.2.5 使用模型进行预测并评估
model.predict("Which baking dish is best to bake a banana bread ?")
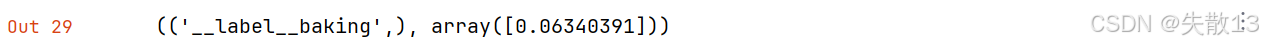
- 标签:
__label__baking→ 模型判断文本属于“烘焙”类别; - 概率:
0.0634→ 模型对该分类的“置信度”,数值低,说明把握不大; - 预测正确,但是概率不大;
model.predict("Why not put knives in the dishwasher?")
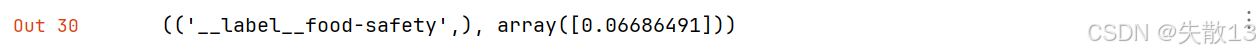
- 预测错误;
# 为了评估模型到底表现如何, 下面在3000条的验证集上进行测试
model.test("cooking_data/cooking.valid")

-
3000:验证集样本总数;
-
0.148:准确率(Precision) → 模型预测为 “正确” 的样本中,实际真正确的比例。数值低(仅 14.8%),说明模型容易 “乱分类”,很多预测的标签是错的;
-
0.064:召回率(Recall) → 实际为正类的样本中,被模型正确预测为正类的比例。数值极低(6.4%),说明大量真实正类样本没被模型识别出来。
-
由此可见:训练出来的模型准确率非常低,需要模型调优,有以下方法
- 数据方面:重新处理数据
- 增加训练轮数
- 调整学习率
- 增加n-gram特征
- 修改损失计算方式
- 自动超参数调优
- 实际生产中多标签多分类问题的损失计算方式
2.3 fasttext模型调优
2.3.1 原始数据处理
-
通过查看数据,可以发现数据中存在许多标点符号与单词相连以及大小写不统一,这些因素对我们最终的分类目标没有益处,反而是增加了模型提取分类规律的难度,因此我们选择将它们去除或转化;
-
如果使用的是 Linux 操作系统,可以使用终端执行下面的命令,进行简单的数据预处理:
# 使标点符号与单词分离并统一使用小写字母 cat cooking.stackexchange.txt | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > cooking.preprocessed.txt head -n 12404 cooking.preprocessed.txt > cooking.pre.train tail -n 3000 cooking.preprocessed.txt > cooking.pre.valid -
完成以上的数据处理操作后,进行训练:
# 原始数据处理后的训练 model = fasttext.train_supervised(input="cooking_data/cooking.train", epoch=25) model.test("cooking_data/cooking.pre.valid")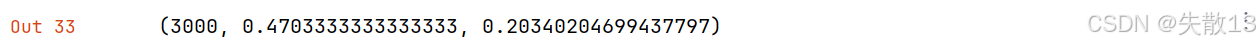
- 准确率提升到了 47%;
- 召回率提升到了 20%。
2.3.2 增加训练轮次
# 增加训练轮次
model = fasttext.train_supervised(input="cooking_data/cooking.train", epoch=50)
model.test("cooking_data/cooking.pre.valid")
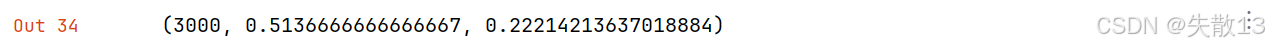
2.3.3 调整学习率
# 调整学习率
model = fasttext.train_supervised(input="cooking_data/cooking.train", lr=1.0, epoch=50)
model.test("cooking_data/cooking.pre.valid")
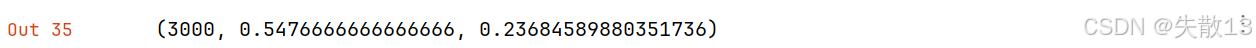
2.3.4 增加n-gram特征
- 设置
train_supervised方法中的参数 wordNgrams 来添加 n-gram 特征,默认是1,也就是没有n-gram特征; - 下面将其设置为2意味着添加2-gram特征,这些特征帮助模型捕捉前后词汇之间的关联,更好的提取分类规则用于模型分类,当然这也会增加模型训时练占用的资源和时间;
# 调整学习率
model = fasttext.train_supervised(input="cooking_data/cooking.train", lr=1.0, epoch=50, wordNgrams=2)
model.test("cooking_data/cooking.pre.valid")
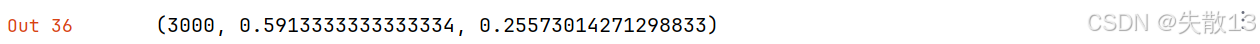
2.3.5 修改损失计算方式
- 随着不断添加优化策略,模型训练速度也越来越慢;
- 为了能够提升 fasttext 模型的训练效率,缩短训练时间,可以设置
train_supervised方法中的参数 loss 来修改损失计算方式(等效于输出层的结构);- 默认是softmax层结构;
- 下面将其设置为
'hs',代表层次softmax结构,意味着输出层的结构(计算方式)发生了变化,将以一种更低复杂度的方式来计算损失;
# 修改损失计算方式
model = fasttext.train_supervised(input="cooking_data/cooking.train", lr=1.0, epoch=50, wordNgrams=2, loss='hs')
model.test("cooking_data/cooking.pre.valid")
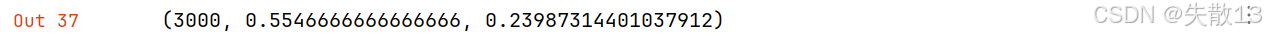
- 虽然精度和召回率稍有波动,但训练时间能感受到明显加快。
2.3.6 自动超参数调优
-
手动调节和寻找超参数是非常困难的,因为参数之间可能相关,并且不同数据集需要的超参数也不同;
-
因此可以使用 fasttext 的 autotuneValidationFile 参数进行自动超参数调优;
- autotuneValidationFile 参数需要指定验证数据集所在路径,它将在验证集上使用随机搜索方法寻找可能最优的超参数;
- 使用 autotuneDuration 参数可以控制随机搜索的时间,默认是300s,根据不同的需求,可以延长或缩短时间;
-
注意:
- autotuneValidationFile 和 lr 参数不会直接冲突,但存在一定的优先级关系;
- autotuneValidationFile 开启后,lr 等手动指定的参数会被视为初始值或候选值,自动调优过程可能会根据验证集表现调整 lr 的值(例如增大或减小),最终选择更优的学习率;
# 自动超参数调优
model = fasttext.train_supervised(input="cooking_data/cooking.train", lr=1.0, epoch=50, wordNgrams=2, loss='hs', autotuneValidationFile='cooking_data/cooking.pre.valid', autotuneDuration=600)
model.test("cooking_data/cooking.pre.valid")
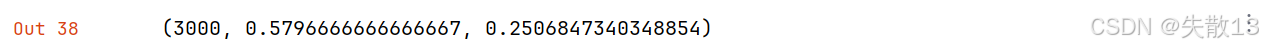
2.3.7 实际生产中多标签多分类问题的损失计算方式
- 针对多标签多分类问题,使用 softmax 或者 hs 有时并不是最佳选择,因为我们最终得到的应该是多个标签,而softmax却只能最大化一个标签;
- 所以我们往往会选择为每个标签使用独立的二分类器作为输出层结构,对应的损失计算方式为
'ova',表示one vs all; - 这种输出层的改变意味着我们在统一语料下同时训练多个二分类模型,对于二分类模型来讲,lr不宜过大,下面设置为0.2;
# 实际生产中多标签多分类问题的损失计算方式
model = fasttext.train_supervised(input="cooking_data/cooking.train", lr=0.2, epoch=50, wordNgrams=2, loss='ova')
model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.5)

- 输出结果输出了它的三个最有可能的标签。
3 fasttext词向量迁移
3.1 介绍
-
**词向量迁移(Word Vector Transfer)**概念:复用预训练词向量,加速模型开发
-
直接用别人在大规模语料(比如全网文本、维基百科)训好的词向量模型,不用自己从头训练;
-
举例:你想做“美食评论分类”,但自己数据少。可以先下载 fasttext 预训练的词向量,再用自己的“美食评论数据”微调,这就是迁移;
-
-
fasttext 官方开源了两类预训练词向量:
-
第一类(157 种语言)
-
训练数据:CommonCrawl(超大网络文本库) + Wikipedia(维基百科)
-
训练模式:CBOW
-
词向量规格:300 维(每个单词用 300 个数表示,维度越高语义信息越细)
-
获取地址:
https://fasttext.cc/docs/en/crawl-vectors.html
-
-
第二类(294 种语言)
-
训练数据:Wikipedia
-
训练模式:Skipgram
-
词向量规格:300 维
-
获取地址:
https://fasttext.cc/docs/en/pretrained-vectors.html
-
-
-
词向量迁移的优势:省时间、省资源、提效果
-
不用自己训:训词向量需要超大规模语料(比如几十 GB 文本) + 超长训练时间(可能跑几天),普通开发者根本扛不住。直接用预训练的,1 分钟下载,直接开干;
-
语义基础好:CommonCrawl、Wikipedia 是“通用语义富矿”,训出来的词向量已经包含“单词的通用语义”(比如
apple既知道是“苹果”,也知道和fruit相关)。你用这些词向量做任务,相当于默认带了“通用知识”,再用自己数据微调,效果比“从零训”好很多; -
跨任务适配:不管你是做“情感分析”“文本分类”“机器翻译”,都能先用预训练词向量打基础,再针对具体任务微调。迁移性极强,适合小数据场景。
-
3.2 使用fasttext进行词向量迁移
-
中文词向量模型:
cc.zh.300.bin;- 地址:dl.fbaipublicfiles.com/fasttext/vectors-crawl/crawl.zh.300.bin.gz;
- 大小:2.01GB
- 解压缩后大小:6个多G
- 读入到内存:需要8个G
-
使用fasttext进行词向量迁移的步骤:
- 下载词向量模型压缩的 bin.gz 文件
- 解压 bin.gz 文件到 bin 文件
- 加载 bin 文件获取词向量
- 利用邻近词进行效果检验
import fasttext
model = fasttext.load_model("model/cc.zh.300.bin")
# 查看前100个词汇(这里的词汇是广义的, 可以是中文符号或汉字)
model.words[:100]

model.get_word_vector("音乐")
# 以'音乐'为例,返回的邻近词基本上与音乐都有关系,如乐曲、音乐会、声乐等
model.get_nearest_neighbors("音乐")
[(0.6703276634216309, '乐曲'),(0.6565821170806885, '声乐'),(0.6540279388427734, '音乐会'),(0.6502416133880615, '配乐'),(0.6501686573028564, '艺术'),(0.6489475965499878, '音乐人'),(0.6426260471343994, '音乐界'),(0.6395964026451111, '非音乐'),(0.639589250087738, '原声'),(0.637651264667511, '交响乐')]
# 以'美术'为例,返回的邻近词基本上与美术都有关系,如艺术、绘画、霍廷霄(满城尽带黄金甲的美术师)等
model.get_nearest_neighbors("美术")
[(0.724744975566864, '艺术'),(0.7165924310684204, '绘画'),(0.7006476521492004, '中国画系'),(0.6706337332725525, '版画系'),(0.6470299363136292, '纯艺'),(0.6455479860305786, '环艺系'),(0.6304370164871216, '美院'),(0.6295372247695923, '国画系'),(0.6293253898620605, '钟志鹏'),(0.627504825592041, '中国画')]
# 以'周杰伦'为例,返回的邻近词基本上与明星有关系,如杰伦、周董、陈奕迅等
model.get_nearest_neighbors("周杰伦")
[(0.7129376530647278, '杰伦'),(0.6841713786125183, '周董'),(0.6783010959625244, '周杰倫'),(0.6644064784049988, '陈奕迅'),(0.6536471843719482, '张韶涵'),(0.6481418609619141, '叶惠美'),(0.6470388174057007, '周华健'),(0.643777072429657, '张靓颖'),(0.6342697143554688, '张惠妹'),(0.6318544149398804, '林俊杰')]














)


 D-F 题解)

